分散型GPU市場規模とシェア
市場概要
| 調査期間 | 2020 - 2031 |
|---|---|
| 市場規模 (2026) | 5.34 十億米ドル |
| 市場規模 (2031) | 22.63 十億米ドル |
| 成長率 (2026 - 2031) | 33.48% CAGR |
| 最も急速に成長している市場 | アジア太平洋地域 |
| 最大市場 | 北米 |
| 市場集中度 | 高 |
主要プレーヤー *免責事項:主要選手の並び順不同 画像 © Mordor Intelligence。再利用にはCC BY 4.0の表示が必要です。 | |
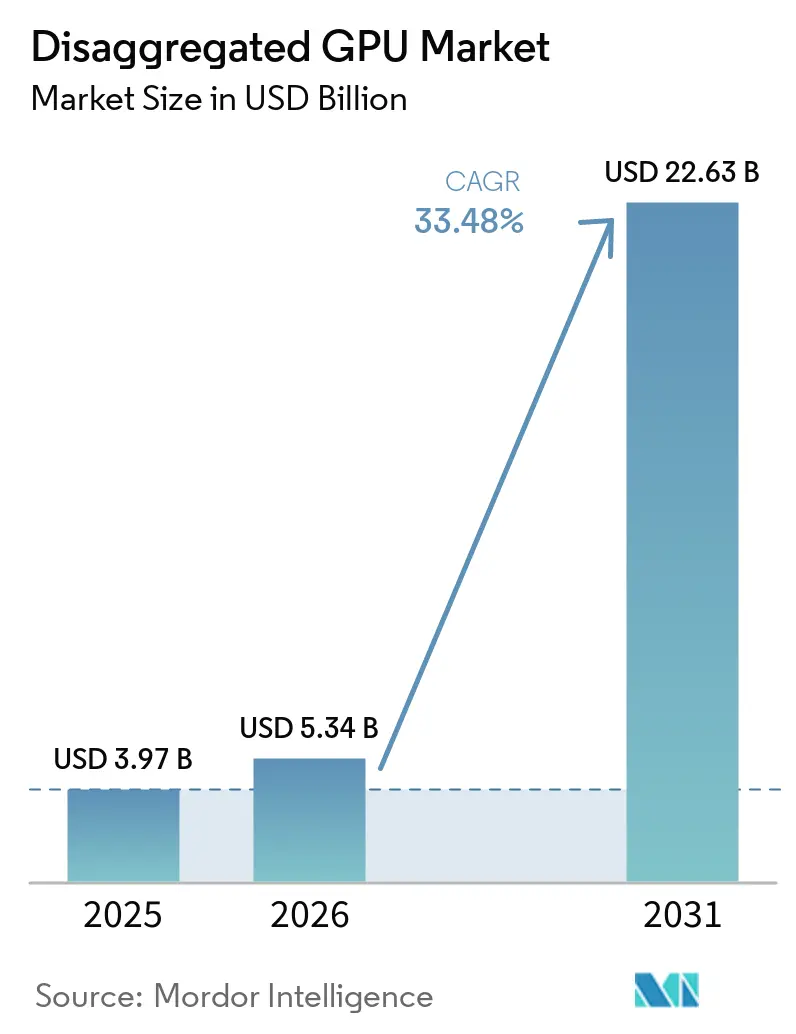
Mordor Intelligenceによる分散型GPU市場分析
分散型GPU市場規模は、2025年に39.7億米ドル、2026年に53.4億米ドルと予測され、2026年から2031年にかけてCAGR 33.48%で成長し、2031年までに226.3億米ドルに達する見込みです。分散型GPU市場は、AIコンピュートスタックが固定サーバー設計から離れ、オペレーターがGPUリソースをホストサーバーから分離して需要が最も高い場所に割り当てることを可能にするファブリック接続型アーキテクチャへと移行するにつれて拡大しています。AMDおよびNVIDIAによる大規模な資本プログラムと、主要クラウドプラットフォームによる確認済みの展開は、分散型GPU市場が孤立したハードウェアの更新サイクルではなく、広範なデータセンターの再設計と結びついていることを示しています。また、オペレーターが単にアクセラレーターを追加するだけでなく、利用率、オーケストレーション、ラックスケールの効率性をより重視するようになっているため、競争行動も変化しています。分散型GPU市場は、エージェント型AIワークロードの台頭からも恩恵を受けており、これによりトークンスループット、KVキャッシュの移動、プリフィルとデコードステージ間の低レイテンシ調整に対するより大きな負荷がかかっています。同時に、輸出規制、相互運用性のギャップ、および最新のAIラックの電力密度が成長を不均一に保ち、専用インフラと強力なエンジニアリング能力を持つオペレーターに有利な状況となっています。
主要レポートのポイント
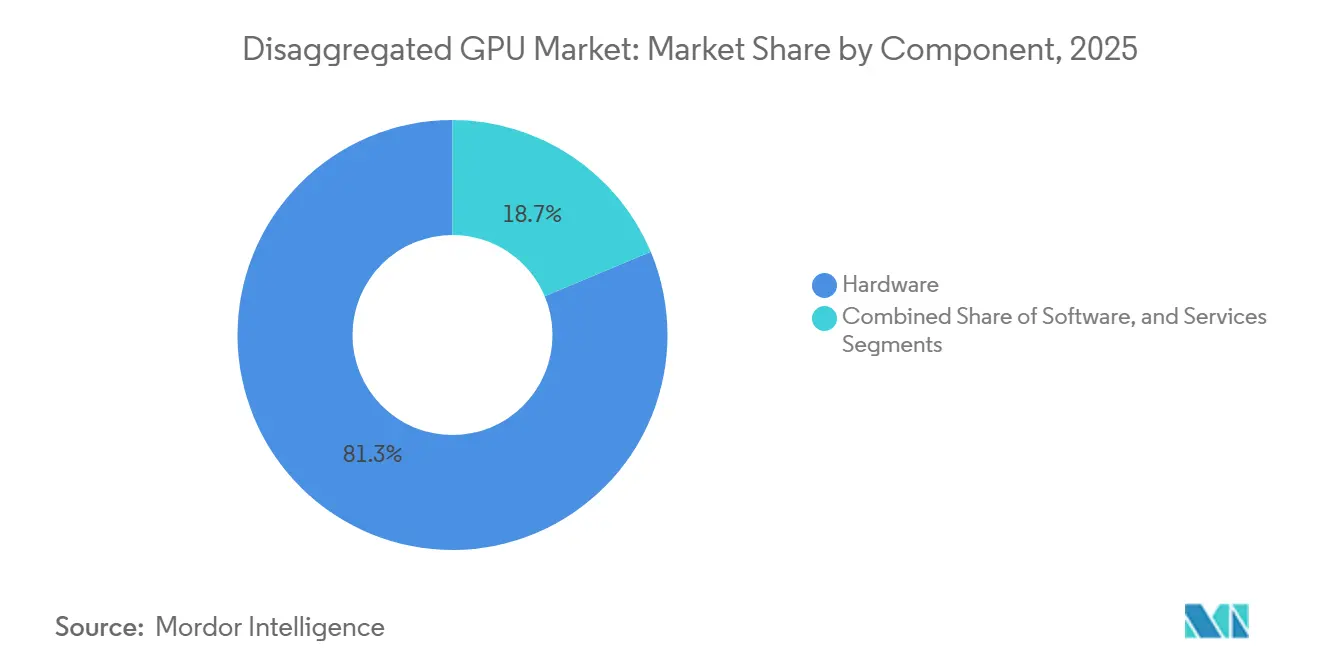
- コンポーネント別では、ハードウェアが2025年に81.32%の収益シェアをリードし、ソフトウェアは分散型GPU市場において2031年までに34.08%のCAGRで拡大する見込みです。
- アクセラレータタイプ別では、NVLink/NVSwitchベースの分散化が2025年に44.21%のシェアを保持し、CXLベースの分散化は2031年までに34.46%のCAGRで拡大する見込みです。
- 展開モード別では、クラウドベースの展開が2025年の分散型グラフィックスプロセッシングユニット(GPU)市場の61.77%を占め、2031年までに33.87%のCAGRで成長する見込みです。
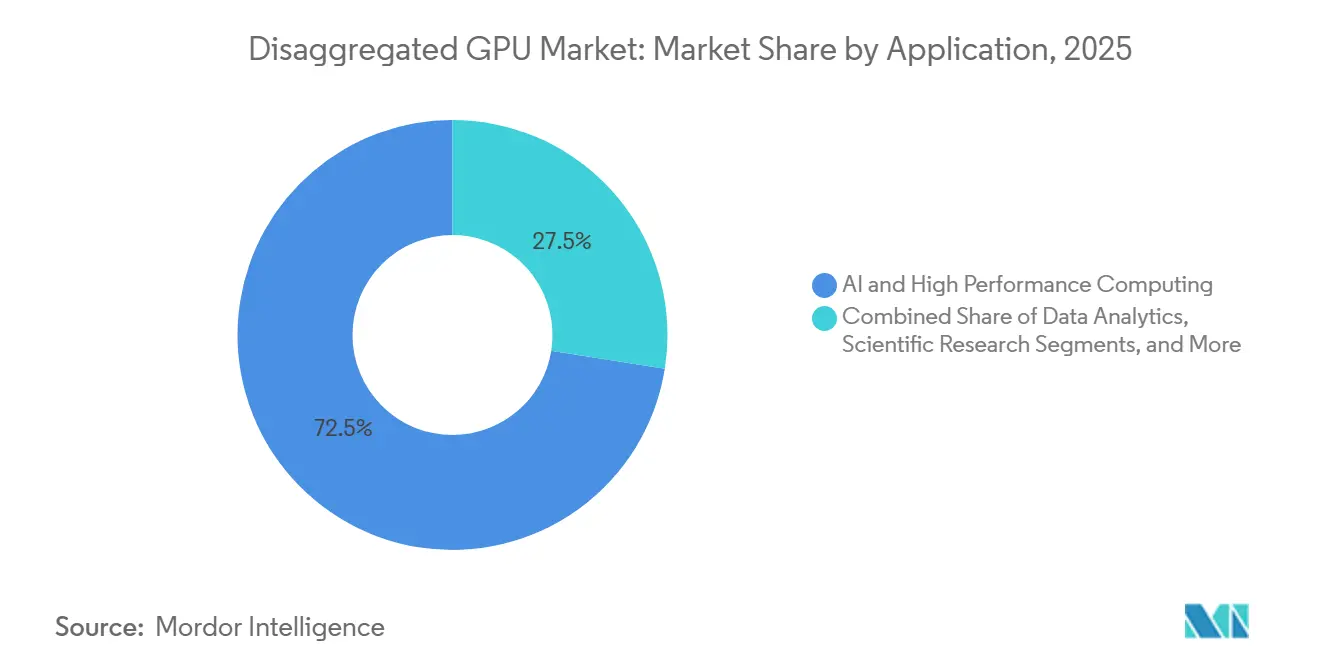
- アプリケーション別では、AIおよびハイパフォーマンスコンピューティングが2025年に市場の72.49%を占め、デジタルツインおよびシミュレーションは2031年までに34.42%のCAGRで拡大する見込みです。
- エンドユーザー別では、ハイパースケールクラウドプロバイダーが2025年に47.63%のシェアを保持し、クラウドサービスプロバイダーは2031年までに34.63%の最高CAGRを記録する見込みです。
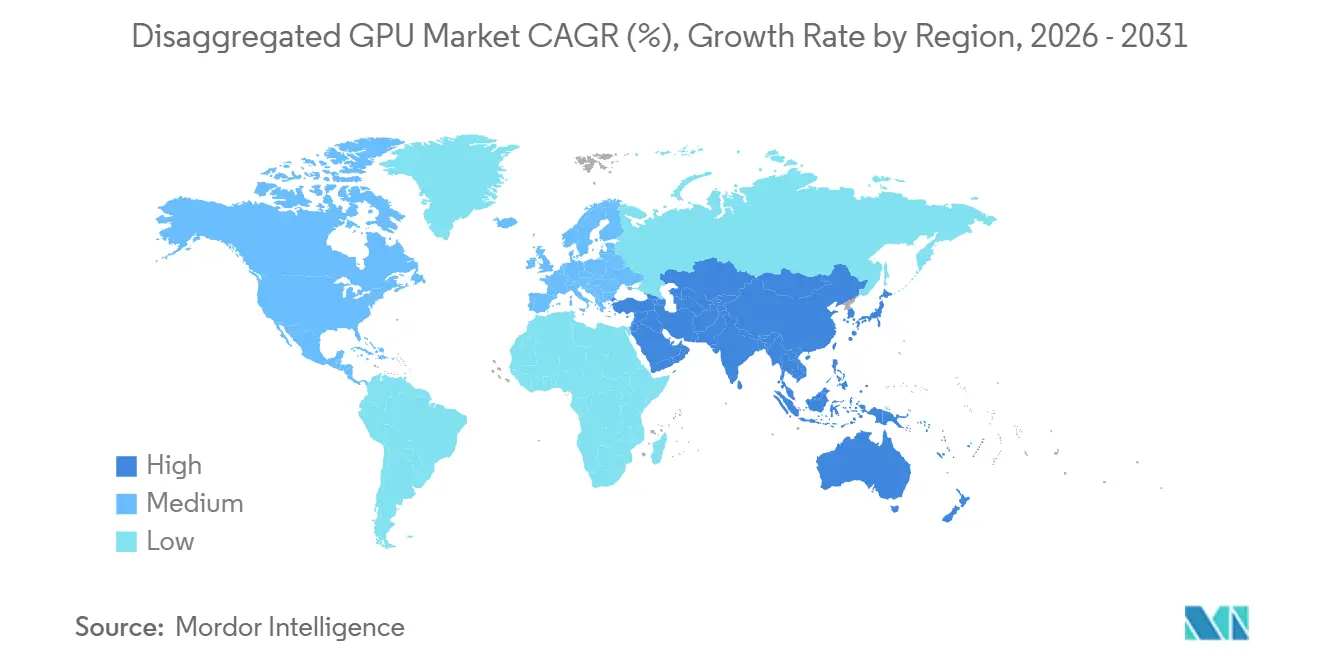
- 地域別では、北米が2025年に分散型GPU市場シェアの52.71%を保持し、アジア太平洋地域は2031年までに34.39%のCAGRで拡大する見込みです。
注:本レポートの市場規模および予測数値は、Mordor Intelligence 独自の推定フレームワークを使用して作成されており、2026年1月時点の最新の利用可能なデータとインサイトで更新されています。
グローバル分散型GPU市場のトレンドとインサイト
ドライバーの影響分析*
| ドライバー | (~)CAGRへの影響(%) | 地理的関連性 | 影響のタイムライン |
|---|---|---|---|
| AIトレーニングクラスターにおけるGPUプーリングの需要増加 | +10.2% | グローバル、北米およびアジア太平洋のハイパースケールハブに集中 | 短期(2年以内) |
| コンピュートとメモリアーキテクチャの分離への移行 | +8.5% | グローバル、CXL採用は北米および東アジアに集中 | 中期(2〜4年) |
| ハイパースケールおよびクラウドネイティブAIインフラの拡大 | +7.3% | グローバル、北米およびアジア太平洋が資本展開をリード | 短期(2年以内) |
| リソース分散化による電力・熱効率の向上 | +4.8% | グローバル、EUのエネルギー規制およびアジア太平洋の電力制約により加速 | 中期(2〜4年) |
| マルチテナントGPU割り当てによるフリート利用率の向上 | +3.6% | 北米、欧州、東南アジアのクラウドコリドー | 中期(2〜4年) |
| モジュール型データセンターアーキテクチャにおけるアップグレードサイクルの短縮 | +2.9% | グローバル、北米のグリーンフィールドAIファクトリー建設で最速 | 長期(4年以上) |
| 情報源: Mordor Intelligence | |||
AIトレーニングクラスターにおけるGPUプーリングの需要増加
分散型GPU市場は、大規模なAIトレーニングの実行が多数の物理GPUを単一の共有論理リソースとして扱うことに依存するようになったため、GPUプーリングから直接的な支持を得ています。NVIDIAの第6世代NVLinkはGPUあたり1.8 TB/sの双方向帯域幅を提供し、NVLink Switchシステムは単一のNVL72ラック内で72個のGPUをサポートし、130 TB/sの集約ドメイン内帯域幅を提供することで、隣接するラックを孤立したコンピュートアイランドに分離していた通信上の制限を軽減しました。[1]NVIDIA デベロッパーブログ、「NVIDIA NVLinkおよびNVLink FusionによるAI推論パフォーマンスと柔軟性のスケーリング」、NVIDIA デベロッパーブログ、developer.nvidia.com この変化は、メモリと帯域幅の負荷が単一ノード内ではなく完全なトレーニングクラスター全体に及ぶようになったため、兆パラメーターモデルにとって重要であり、分散型GPU市場はアイドル容量をアクティブなワークロードにより迅速に参加させるアーキテクチャで対応しています。エージェント型AIはさらなる需要の層を加えています。プリフィルステージはコンピュート集約型であり、デコードステージはメモリ帯域幅集約型であるため、このパターンはプールを低速な手動スケジューリングサイクルではなく数秒で再割り当てすることを必要とします。AWSはBlackwellノード上でllm-dとNVIDIA Inference Xfer Libraryを使用した本番環境でこの運用モデルを実証し、分散型推論が高い同時実行性において70%のスループット向上を達成しました。
コンピュートとメモリアーキテクチャの分離への移行
分散型GPU市場は、オペレーターがコンピュートをローカルメモリから分離し、メモリ容量をプールされたインフラ層として扱うようになるにつれて前進しています。清華大学科学技術誌に掲載された研究は、CXLベースのメモリ分散化を知的コンピューティングセンターにとっての主要なアーキテクチャ上のステップとして説明しており、共有メモリプールが標準的なロードおよびストア操作を通じて複数のコンピュートノードからアクセスできるためです。ByteDanceの研究者はこの方向性を拡張し、Micron CXL Type-3カードとTITAN-II CXLスイッチで構築された768 GBの共有メモリプールを実証し、アプリケーションコードの変更なしにNVIDIA H100 GPUを搭載した3ノード間での集合GPU通信を可能にしました。これは、長文脈推論が100万トークンを超え、KVキャッシュの需要が各アクセラレーターで利用可能なHBMを超えるため、GPUフリート全体を交換するよりもプールされたメモリを追加する方が実用的であるため重要です。したがって、分散型GPU市場はCXLから、エネルギー制限と利用率目標が連動する中でフルシリコン更新を強制せずにより多くのメモリ容量を必要とするオペレーターにとっての経済的な経路としてだけでなく、技術的な選択肢としても恩恵を受けています。
ハイパースケールおよびクラウドネイティブAIインフラの拡大
分散型GPU市場は、ハイパースケールおよびクラウドネイティブAIインフラへの支出規模によって押し上げられており、孤立したパイロットプロジェクトからラックスケールおよびマルチサイトの展開へと拡大しています。AMDは2026年5月に台湾エコシステムへの100億米ドル以上の投資を発表し、Sanmina、Wiwynn、Wistron、InventecなどのODMパートナーを通じてHeliosラックスケールプラットフォームをスケールアップし、2026年後半にマルチギガワット展開を目標としています。Google Cloudも、Virgoネットワークファブリックが単一のデータセンターで最大80,000台のNVIDIA Vera Rubin NVL72 GPUを接続し、複数のサイトにわたって96万台以上のGPUを接続するように設計されていると述べており、分散型GPU市場がニッチなアーキテクチャではなくデータセンターのスケールアウトの基盤となりつつあることを強調しています。同時に、AWS、Google、Microsoftのカスタムシリコンプログラムは分散型GPUシステムの必要性を排除しておらず、マルチベンダーインフラがそれらと並行して出現しています。IntelとSambaNova は2026年にこのモデルを異種推論スタックで実証し、Intel Xeon 6がオーケストレーションを担当し、SambaNova RDUがデコードを担当し、NVIDIA Blackwell GPUが単一の本番データセンターからプリフィルを担当しました。
リソース分散化による電力・熱効率の向上
分散型GPU市場は、電力供給と冷却の制約によっても形成されており、これらは今や生のコンピュート需要と同様にアーキテクチャの決定に影響を与えています。2025年10月にGoogle、Meta、Microsoftが提供したOpen Compute ProjectのDiablo仕様は、400 VDCまたは800 VDCの供給を使用して100キロワットから1メガワットのITラックをサポートする分散型電力ラック設計を定義しました。NVIDIAは2025年12月にBlackwell B200電力プロファイルで別の効率レバーを追加し、最大3%のパフォーマンス影響で最大15%のエネルギー節約を実現し、固定電力施設で最大13%の高いスループットを可能にしました。フェーズ対応の分散型推論はさらに状況を改善します。プリフィルステージがピーク電力を消費する一方、デコードステージはより低いワット数のニーズを持ち、別々のリソースプール間で異なる管理が可能です。BiScaleアーキテクチャに関する研究は、分散型プリフィルおよびデコード層全体での協調DVFSがレイテンシサービス目標を満たしながらデコードエネルギーを最大48%削減したことを示しており、エネルギー制限と利用率目標が連動する分散型グラフィックスプロセッシングユニット(GPU)市場の運用上のケースを強化しています。
制約の影響分析*
| 制約 | (~)CAGRへの影響(%) | 地理的関連性 | 影響のタイムライン |
|---|---|---|---|
| 高いインターコネクトおよびファブリック統合の複雑性 | -1.8% | グローバル、北米以外のマルチベンダー展開で最も深刻 | 短期(2年以内) |
| GPUスタック全体でのソフトウェアオーケストレーションの断片化 | -1.4% | グローバル、特にエンタープライズおよび新興市場の展開で制限的 | 中期(2〜4年) |
| レガシーデータセンターの改修における資本集約性 | -1.1% | 欧州および南米、レガシーコロケーションストックが相当量存在する地域 | 中期(2〜4年) |
| リモートメモリおよび分散型アクセスにおけるレイテンシのトレードオフ | -0.8% | グローバル、レイテンシに敏感な推論ワークロードで最も重要 | 短期(2年以内) |
| 情報源: Mordor Intelligence | |||
高いインターコネクトおよびファブリック統合の複雑性
分散型GPU市場は、多くの展開が単一クラスター内でNVLink、PCIe、InfiniBand、イーサネット、CXLを調整しなければならないため、依然として重大な統合障壁に直面しています。HotNets 2025で発表された研究は、ホスト内異種インターコネクト全体での効果的なパス管理には、PCIeスイッチ、GPUファブリックコントローラー、RDMA NIC、イーサネットスイッチの同時調整が必要であり、現在のソフトウェアスタックはその複雑性を完全に抽象化していないことを示しました。NVIDIAのNVLink Fusionは、MediaTek、Marvell、Qualcomm、FujitsuのカスタムCPUがNVIDIA GPUとネイティブに接続できるようにすることでその問題の一部を軽減しましたが、その動きは完全に中立なマルチベンダーファブリックを作成するのではなく、独自のパスを拡大しました。Ultra Accelerator Link標準はベンダー中立の代替手段を提供することを意図していますが、入力によると本番ハードウェアは2026年後半まで予定されておらず、広範な展開は2027年まで延びる可能性が高いとされています。分散型GPU市場は中国でも地域的な相互運用性の上限に直面しており、国内アクセラレーターエコシステムが互換性のない通信プロトコルを使用しているため、オペレーターが大規模に達成できる実際のプーリングの利点が制限されています。
GPUスタック全体でのソフトウェアオーケストレーションの断片化
異種GPU環境全体での統一されたオーケストレーション層の欠如も、分散型GPU市場を制約しています。断片化対応スケジューリングに関する研究は、マルチテナントスケジューラーが依然としてベンダースタック全体で異なるメモリ分離とパーティショニングアプローチを調整する必要があり、それによって統合作業が増加し展開タイムラインが延長されることを示しました。USENIX ATC 2025で発表された研究は、カーネルレベルでの時空間GPU オーケストレーションがベンダー固有のコマンドバッファとコンテキスト管理の詳細な制御に依存しており、現在標準化されたクロスベンダーのロジックファブリックやスケジューリングセマンティクスが存在しないことを示しました。[2]Shulai Zhang ら、「カーネル空間インターセプションによる互換性と分離を備えた効率的なパフォーマンス対応GPU共有」、USENIX ATC 2025、usenix.org これにより、フリート全体の分散化は、大規模なプラットフォームエンジニアリングチームを持つハイパースケーラーにとっては容易であり、混合GPU資産を管理し共通の運用層を必要とするエンタープライズバイヤーにとってははるかに困難になっています。したがって、分散型GPU市場は中期的に最大のオペレーターを引き続き優遇する可能性が高く、標準化作業はまだ初期段階にあり、独自エコシステムは迅速に収束するインセンティブをほとんど持っていません。
*当社の予測では、推進要因および抑制要因の影響を加算的ではなく方向性のあるものとして扱います。影響予測は、ベースライン成長、構成効果、および変数間の相互作用を反映しています。
セグメント分析
コンポーネント別:ハードウェアが初期支出をリードし、ソフトウェアが継続的な比重を増す
ハードウェアは2025年の分散型GPU市場の81.32%を占め、インターコネクトファブリック、スイッチトレイ、メモリモジュール、ラックスケールコンピュートシステムの高い初期コストを反映しています。各Vera Rubin NVL72ラックは、72個のBlackwell GPU、36個のVera CPU、NVLinkスイッチチップ、BlueField-4 DPU、Spectrum-Xイーサネットネットワーキングを単一のファブリックベースの資本ユニットに組み合わせており、分散型GPU市場における初期支出を大規模なハイパースケール調達サイクルに集中させています。この調達モデルは、バイヤーが孤立したカードやサーバーを購入するのではなく、単一の展開イベント内でコンピュート、ネットワーキング、管理機能をバンドルした緊密に統合されたプラットフォームにコミットしているため重要です。したがって、分散型GPU市場は現在のフェーズでハードウェア重視の収益ミックスを示しており、特にハイパースケーラーが段階的なノードごとの追加ではなくフルラックで新しいAI容量を構築しているためです。サービスは最小のコンポーネント層にとどまりましたが、統合、マネージドオペレーション、GPU-as-a-serviceの提供は、システムインテグレーターおよび専門クラウドオペレーターにとって依然として魅力的なマージンポテンシャルを持っていました。
ソフトウェアは、オーケストレーション層、分離ツール、推論フレームワークがオペレーターが各GPUから引き出す価値をますます決定するようになるにつれて、分散型GPU市場において2026年から2031年にかけて最速の34.08%のCAGRを記録する見込みです。NVIDIA Dynamoはプリフィルとデコードの割り当てを分離してファクトリースケールの利用率を向上させ、その設計はllm-dなどのオープンソースの代替手段がエンタープライズ展開のために一致させる必要がある参照点を設定しました。これにより、フトウェアのアップグレードはハードウェアの更新サイクルが遅くなったり、インストール済みのファブリックが維持されたりしても継続できるため、分散型GPUインダストリーの収益パターンが変化します。2024年および2025年に分散型ハードウェアをインストールしたオペレーターは、物理的なインターコネクト資産を交換する前に新しいオーケストレーション層を追加する可能性が高く、ラック交換のタイミングとの結びつきが少ない継続的なソフトウェア収益への道を生み出しています。時間の経過とともに、ハードウェアが絶対的な支出を引き続き支えるとしても、そのダイナミクスはソフトウェアに分散型GPU市場でより大きな役割を与えるはずです。
注記: 個々のセグメントのセグメントシェアレポート購入時に入手可能


アクセラレータタイプ別:NVLinkが現在のベースラインを設定し、CXLがアーキテクチャを拡大
NVLink/NVSwitchベースの分散化は2025年の分散型GPU市場シェアの44.21%を保持し、AIトレーニングファブリックにおけるNVIDIAの強力な地位と、緊密に結合されたGPU通信に対するインストール済みの優先性を反映しています。第6世代NVLinkは2024年にGPUあたり1.8 TB/sを提供し、新しいNVLink Switchシステムは130 TB/sの集約帯域幅で72個のGPU全体でオールツーオール通信を可能にし、分散型GPU市場に密な局所通信を必要とするスケールアップクラスターのための高性能オプションを提供しました。PCIeベースの分散化は、同レベルの独自依存性なしに広範な互換性を提供し、多くのマルチGPUシステムのベースラインファブリックとして耐久性のある役割を維持しました。InfiniBandおよびイーサネットベースのアプローチはスケールアウト設定で引き続き重要であり、特にイーサネットは、オペレーターが既存のネットワーキング投資を基盤として大規模なAIクラスターを拡張したい場合に関連性を増しました。この分割は、分散型GPU市場が一つの普遍的なファブリックに向かうのではなく、パフォーマンス、オープン性、インストール済みインフラがそれぞれ最終的なアーキテクチャに影響を与える階層型モデルに向かっていることを意味します。
CXLベースの分散化は、PCIe 7.0物理層を介して帯域幅を128 GT/sに倍増させ、はるかに高い総スループットのためのバンドルポートを導入したCXL 3.0メモリプーリングおよびCXL 4.0仕様に支えられ、2031年までに34.46%のCAGRで拡大する見込みです。清華大学科学技術誌の研究は、CXLメモリ分散化とGPUコンピュート分散化がスタックの異なる層に対応することを示しており、これは分散型GPU市場における将来の展開がそれらの間で選択を強制するのではなく、それらを組み合わせることを示唆しています。Samsung Electronicsは、HBMの制限が推論バッチサイズと作業コンテキストの深さを制限する可能性があるGPUメモリを拡張するために、MarvellおよびLiquid AIとともにPangea CXLメモリプラットフォームを開発しています。実際には、NVLinkはラック内でのGPU間の緊密に結合された通信に適しており、CXLはノードおよびより広いシステムドメイン全体でメモリ容量とメモリ共有を拡張します。この補完的な関係は、本番クラスターですでに確立された高帯域幅GPUファブリックの役割を低下させることなく、分散型GPU市場がより構成可能なアーキテクチャへと成熟するのを助けるはずです。
展開モード別:クラウド提供が標準を形成し、オンプレミスが戦略的需要を維持
クラウドベースの展開は2025年の分散型GPU市場規模の61.77%のシェアを保持し、同セグメントは2031年までに最速の33.87%のCAGRを記録する見込みです。AWSはllm-dとNVIDIA Inference Xfer Libraryを通じてSageMaker HyperPodおよびAmazon EKSで分散型推論を導入し、Elastic Fabric Adapterを使用して分散型ノード間でKVキャッシュデータを移動させ、標準展開と比較してBlackwellベースのインスタンスで最大70%高いトークン毎秒を実現しました。Google Cloudは、Virgoが単一のデータセンターで最大80,000台のVera Rubin NVL72 GPUを接続し、複数のサイトにわたって96万台以上のGPUを超えることができると述べ、分散型グラフィックスプロセッシングユニット(GPU)市場の運用モデルを設定するハイパースケーラーの役割を強化しました。クラウド提供の利点はスケールだけでなく、冷却、ファブリック構成、オーケストレーションの複雑性をマネージドサービスの背後に隠す能力にもあります。そのため、分散型GPU市場は特に、高度なAI容量へのアクセスを必要としながら専門インフラを自ら構築・運用したくないバイヤーにとって、クラウドプラットフォームに傾き続けています。
オンプレミス展開は、機密性の高いワークロードを共有パブリッククラウド環境に移行できないエンタープライズおよび公共部門組織にとって、分散型GPU市場で依然として重要です。入力は、エンタープライズバイヤーがハイパースケーラーよりも価格に敏感であり、通常はクラウドオペレーターが大規模に検証した後に分散型アーキテクチャを採用することを示しており、これによりオンプレミス需要はより遅いが依然として重要な経路に押し込まれています。政府および防衛組織は別のオンプレミスコホートを形成しており、主権AI プログラムと国家安全保障規則がしばしばエアギャップまたは管轄区域に縛られたコンピュート環境を必要とするためです。欧州連合およびアジア太平洋の一部でのデータローカライゼーション要件も、クラウドがより大きく急速に成長するモードであっても、専用インフラの下限を支えています。その結果、分散型GPU市場はクラウドプラットフォームがイノベーションのペースを設定し、コンプライアンス、制御、またはワークロードの機密性が共有アクセスを制限する場合にオンプレミス展開が重要であり続けるという二重構造を維持する可能性が高いです。
アプリケーション別:AIおよびHPCが現在の需要を牽引し、シミュレーションが新たな量を構築
AIおよびハイパフォーマンスコンピューティングは2025年の分散型GPU市場の72.49%を占め、現在の展開の主要ドライバーとなっています。最大の言語モデルと推論システムは、孤立したノードの限界を超えるメモリ容量とインターコネクトパフォーマンスを必要とするため、分散型GPU市場はフロンティアトレーニングと推論の基本要件としてプーリングとファブリック調整を中心に発展してきました。NVIDIAは、Vera Rubin NVL72が以前のGrace Blackwell世代と比較して10倍のエージェントスループットを提供できると述べており、これはハイパースケーラーがトレーニングクラスターと推論重視の推論環境の両方にこれらのプラットフォームを展開している理由を説明するのに役立ちます。科学研究もこのセグメントの一部であり続けており、ゲノミクス、気候モデリング、素粒子物理学は、ジョブ間で高価なGPUリソースをアイドル状態にすることなく大規模にプロビジョニングできるバースト対応コンピュートを必要とするためです。このミックスにより、分散型GPU市場は利用率、メモリ共有、インターコネクト効率が科学的成果またはモデルパフォーマンスに直接影響するワークロードと密接に結びついています。
デジタルツインおよびシミュレーションは、産業運営、設計検証、自律システムトレーニングにおけるGPUアクセラレーション物理モデルのより広い使用を反映して、2026年から2031年にかけて34.42%のCAGRで進展する見込みです。分散型GPU市場はここで恩恵を受けており、多くのシミュレーションワークロードが非常に高いコンピュート密度の短い期間を必要とするため、プールされたリソースが静的なサーバー割り当てよりも経済的になるためです。NVIDIAは、DSXプラットフォームがAIファクトリーの展開時間を数ヶ月から数日に短縮し、最初の収益までの時間を加速できると述べており、その商業モデルは産業ユーザーがスケーラブルなシミュレーションインフラについて考える方法に影響を与え始めています。データ分析、レンダリング、可視化は安定した成長を持つ確立されたユースケースであり、レンダリングは低フレームレイテンシを要求する没入型産業インターフェースでのリアルタイムGPUアクセラレーションから恩恵を受けています。これらのパターンを合わせると、分散型GPU市場はフロンティアAIトレーニングを超えて拡大し、運用デジタルワークロードのための柔軟な容量を重視するバイヤーからの需要が増加します。
注記: 個々のセグメントのセグメントシェアはレポート購入時に入手可能
エンドユーザー別:ハイパースケーラーが最大のベースを保持し、専門クラウドがより速く拡大
ハイパースケールクラウドプロバイダーは2025年に47.63%のシェアを保持し、分散型GPU市場で最大のポジションを持ち、アーキテクチャ標準、展開タイミング、ソフトウェア選択に強い影響力を持っています。AWS、Google Cloud、Microsoft Azure、Oracle Cloud Infrastructureは2026年後半のNVIDIA Vera Rubin NVL72システムの展開者として確認されており、分散型GPU市場が依然として初期量採用のためにハイパースケーラーに依存している程度を強化しています。彼らのファーストムーバーの役割は購買力を超えており、オーケストレーション、リソースプーリング、マネージドAIサービスが下流の顧客向けにどのようにパッケージ化されるかも形成しています。エンタープライズはより大きな採用グループになりつつありますが、通常はより厳しい予算管理、統合リスクへのより強い感度、データ露出を制限できる専用クラウドまたはオンプレミス構成への優先性を持って展開にアプローチします。政府および防衛バイヤーも引き続き関連性があり、長い調達サイクルでも主権コンピュートプログラムが前進すれば大きな契約価値をもたらす可能性があります。
クラウドサービスプロバイダーは、中間層オペレーターが専門化と価格柔軟性を中心にGPU-as-a-serviceプラットフォームを構築するにつれて、分散型GPU市場において2026年から2031年にかけて最速の34.63%のCAGRを記録する見込みです。NVIDIAはCoreWeave、Lambda、Nebius、NscaleをVera RubinおよびSpectrum-Xイーサネットフォトニクスの早期採用者として特定し、専門クラウドが最大のハイパースケーラープラットフォームを超えたトレーニングと推論の需要に対応するために容量を拡大していることを示しています。彼らのポジションは有望ですが、ハイパースケーラーでのトークンあたりコストの低下がレンタルマージンを圧縮し、より小さなプロバイダーがマネージドサービスとアプリケーション層サポートを通じて差別化を強いられる可能性があるため、露出もあります。通信プロバイダーも分散型GPUシステムのエッジ重視のユーザーとして台頭しており、研究・学術機関はより小さな収益の役割を果たしていますが、llm-dおよび関連するKubernetesネイティブツールなどのオープンソースオーケストレーション作業を通じてソフトウェア障壁を下げるのに役立っています。支配的なハイパースケーラー、急速に動く専門クラウド、および標的を絞った公共および民間バイヤーのこの組み合わせは、少数の非常に大きなオペレーターへの依存を減らすことなく、分散型GPU市場の需要基盤を拡大します。
地域分析
北米は2025年に52.71%のシェアを保持し、分散型GPU市場で最大の地域シェアを持ち、米国全体のハイパースケール建設の深さを反映しています。AWS、Google Cloud、Microsoft Azure、Oracle Cloud Infrastructureはすべて2026年後半のNVIDIA Vera Rubin NVL72システムの展開者として指名されており、主要バイヤーのこの集中が分散型GPU市場を地域に引き続き固定しています。北米はまた、密なハードウェアエコシステム、主要なAI研究活動、CoreWeave、Lambda、Nscaleなどのプロバイダーを含む成熟したGPUクラウド層からも恩恵を受けています。NVIDIAの2025年9月のIntelとのNVLinkおよびx86に基づくカスタムAIデータセンターCPUを開発するためのコラボレーションは、地域のサプライチェーンを深め、オーケストレーションCPUとGPUファブリック間のより強力な統合を可能にしました。[3]Intel Corporation、「IntelとNVIDIA、AIインフラおよびパーソナルコンピューティング製品を共同開発」、Intel ニュースルーム、newsroom.intel.com カナダは米国のハイパースケール需要への近接性と有利な電力経済性によってサポートを追加し、南米はより早い段階にあり、広範なオンプレミス展開よりもブラジルとコロンビアのハイパースケールアベイラビリティゾーンに結びついています。
欧州は分散型GPU市場で意味のあるが小さなシェアを保持しており、ユーザー入力ではドイツ、英国、フランスが主要な展開センターとなっています。欧州連合のエネルギー効率指令は、ITロードが500 kWを超えるデータセンターに対して電力使用効率の報告を義務付けており、より効率的な分散型設計を支援し、オペレーターが測定可能な施設パフォーマンスを実証することを要求しています。ドイツの自動車および精密製造基盤は、デジタルツインおよび物理シミュレーションワークロードの需要を支援しており、バーストコンピュートは固定サーバー割り当てよりもプールされたインフラを通じて正当化しやすいです。英国は活発なGPUクラウドセグメントを通じて貢献し、フランスとイタリアは分散型GPU容量を組み込んだ主権AIコンピュートプログラムを拡大しています。
アジア太平洋地域は2026年から2031年にかけて34.39%のCAGRで拡大する見込みであり、予測期間中に分散型GPU市場で最速の成長率を地域に与えています。この地域は、中国のハイパースケールAI支出、韓国の垂直統合されたメモリサプライチェーン、日本の製造および自動化ニーズ、インドとシンガポールの公共AIインフラプログラムによって牽引されています。中国は独自のインターコネクトアプローチを中心に国内の分散型アーキテクチャを構築しており、中国のスタックが分散型GPU市場の他の地域で使用されるものと異なる分割された地域構造を生み出しています。韓国はSK HynixのHBM3e出力における地位から恩恵を受けており、国内オペレーターがメモリサブシステムへのより早いアクセスを確保し、より速いデータセンター資本展開を支援するのに役立っています。インドも政府支援のAIイニシアチブとハイパースケールクラウドゾーンの拡大に伴い急速に動いており、中東およびアフリカは開発の初期段階にありますが、UAEとサウジアラビアの主権AI投資プログラムからのサポートを得ています。

競合環境
分散型GPU市場はハードウェアインターコネクト層で高度に集中したままであり、ソフトウェアとサービスはオーケストレーションベンダー、GPUクラウドプロバイダー、統合スペシャリスト全体でははるかに断片化されています。NVIDIAは、そのNVLinkエコシステム、ラックスケールプラットフォーム、本番リーチが実証済みのスケールアップファブリックと調整されたハードウェアスタックを必要とするバイヤーに強い優位性を与えるため、分散型GPU市場でペースを設定し続けています。2025年5月のNVLink Fusionの発売は、MediaTek、Marvell、Qualcomm、FujitsuなどのカスタムシリコンがNVIDIA GPUとネイティブに接続できるようにし、セミカスタムAIインフラの対応可能なエコシステムを拡大したため、注目すべき戦略的な動きでした。その動きはNVIDIAの独自技術への依存を減らしませんでしたが、NVIDIAのファブリックをより広いパートナーセット全体でシステム設計のより中心的なものにしました。実際には、分散型GPU市場はハードウェアパフォーマンスとエコシステムの成熟度が最も重要な場所でNVIDIAに最も強いポジションを与えています。
AMDは、HeliosラックスケールプラットフォームをオープンなROCmソフトウェアスタックとより広いサプライヤーベースと組み合わせた異なるルートを通じて、分散型グラフィックスプロセッシングユニット(GPU)市場でのポジションを構築しています。2026年5月に台湾エコシステムへの100億米ドル以上のコミットを決定したことは、ハードウェア生産のギャップを縮小し、地域製造パートナーを通じてラックスケールの実行を強化するための複数年の取り組みを示したため、別の主要な戦略的動きでした。[4]Advanced Micro Devices, Inc.、「AMDがAIインフラを加速するために台湾エコシステムへの100億米ドル以上の投資を発表」、AMD 投資家向け情報、ir.amd.com Intelの役割はより非対称であり、GPUファブリック層をリードしているのではなく、異種システム内のオーケストレーションCPUポジションに価値を見出しています。このアプローチはComputex 2026で明らかになり、Intel Xeon 6が単一の商業展開例でSambaNova とNVIDIAとの3ベンダー分散型推論スタック全体でオーケストレーションを可能にしました。これらの動きは、コアハードウェアファブリックが集中したままであっても、分散型GPU市場がプラットフォームレベルで競争的であることを示しています。
分散型GPU市場で最も大きなオープンエリアはマルチベンダーオーケストレーションであり、NVLink、CXL、InfiniBand、イーサネット全体でワークロードを一貫してスケジュールする広く採用された商業プラットフォームがまだ存在しないためです。Vultrと協力するExostellarなどの新興プレイヤーは、地理的に分散した異種GPUフリート全体でのワークロードレベルのオーケストレーションでそのギャップを標的にしており、Dell Technologies、Hewlett Packard Enterprise、Supermicro、Lenovoなどのサーバーベンダーはシステム統合、液体冷却、マネージドインフラサービスを通じて競争しています。標準化活動も重要であり、より開かれた分散型ファブリックへの道はエンタープライズと政府がベンダーロックインと長期調達を評価する方法に影響を与えるためです。現在のところ、分散型GPU市場は少数のハードウェアリーダーがコアアーキテクチャに影響を与え、はるかに広いフィールドが展開、オーケストレーション、サービス提供の制御を競う階層型競争構造をサポートしています。
分散型GPUインダストリーリーダー
NVIDIA Corporation
Advanced Micro Devices, Inc.
Intel Corporation
Qualcomm Incorporated
Apple Inc.
- *免責事項:主要選手の並び順不同

最近のインダストリーの動向
- 2026年6月:Amazon Web Servicesは、NVIDIA RTX PRO 4500 Blackwell Server Edition GPUを搭載したEC2 G7インスタンスの一般提供を発表し、前世代のG6比で最大4.6倍のAI推論パフォーマンスを提供します。インスタンスは最大700 GbpsのElastic Fabric Adapterネットワーキング帯域幅を備え、分散型AI推論、言語翻訳、大規模画像分析ワークロードをサポートします。
- 2026年5月:NVIDIAは、Vera Rubinプラットフォームが30カ国350の工場で完全生産に入ったことを発表し、AWS、Google Cloud、Microsoft Azure、Oracle Cloud Infrastructureが2026年後半の展開者として確認されました。このプラットフォームは、業界初の共同パッケージ光学イーサネットスイッチを本番環境で提供するSpectrum-Xイーサネットフォトニクスを導入し、従来のトランシーバーと比較して5倍の電力効率を実現し、100万GPU規模のAIファクトリー展開を可能にします。
- 2026年5月:AMDは、MI450X GPUと業界初の2.5D高架ファンアウトブリッジパッケージングを採用した第6世代EPYC Venice CPUを搭載したHeliosラックスケールプラットフォームをスケールアップするために、台湾エコシステムへの100億米ドルの投資を発表しました。ODMパートナーのSanmina、Wiwynn、Wistron、Inventecは2026年後半を目標としたマルチギガワット展開のための生産を拡大しています。
- 2026年5月:Vista Equity PartnersとCambium Capitalが支援するVector Core Computeは、Computex 2026で最初の分散型推論システムを商業的に発売し、ロサンゼルスのデータセンターからオーケストレーションにIntel Xeon 6、デコードにSambaNova SN40 RDU、プリフィルにNVIDIA Blackwell GPUを展開しました。Together.aiが最初の商業顧客として発表されました。


グローバル分散型GPU市場レポートの範囲
分散型GPU市場は、グラフィックスプロセッシングユニット(GPU)を従来のサーバーアーキテクチャから切り離し、高速インターコネクトとネットワークファブリックを通じて複数のコンピュートリソースに動的に割り当てることを可能にするハードウェア、ソフトウェア、サービスで構成されています。分散型GPUアーキテクチャにより、組織は物理的なサーバーの境界に関係なくGPUリソースをプール、共有、仮想化、オーケストレーションし、データセンター、クラウド、ハイパフォーマンスコンピューティング環境全体でリソース利用率、スケーラビリティ、運用の柔軟性、インフラ効率を向上させることができます。
分散型GPU市場レポートは、コンポーネント(ハードウェア、ソフトウェア、サービス)、アクセラレータタイプ(PCIeベースの分散化、NVLink/NVSwitchベースの分散化、イーサネットファブリックベースの分散化、InfiniBandファブリックベースの分散化、CXLベースの分散化)、展開モード(オンプレミス、クラウド)、アプリケーション(AIおよびハイパフォーマンスコンピューティング、データ分析、デジタルツインおよびシミュレーション、レンダリングおよび可視化、科学研究)、エンドユーザー(ハイパースケールクラウドプロバイダー、クラウドサービスプロバイダー、エンタープライズ、政府および防衛組織、研究・学術機関、通信プロバイダー)、地域(北米、欧州、アジア太平洋、南米、中東およびアフリカ)別にセグメント化されています。市場予測は金額ベース(米ドル)で提供されます。
| ハードウェア |
| ソフトウェア |
| サービス |
| PCIeベースの分散化 |
| NVLink/NVSwitchベースの分散化 |
| イーサネットファブリックベースの分散化 |
| InfiniBandファブリックベースの分散化 |
| CXLベースの分散化 |
| オンプレミス |
| クラウドベース |
| AIおよびハイパフォーマンスコンピューティング |
| データ分析 |
| デジタルツインおよびシミュレーション |
| レンダリングおよび可視化 |
| 科学研究 |
| ハイパースケールクラウドプロバイダー |
| クラウドサービスプロバイダー |
| エンタープライズ |
| 政府および防衛組織 |
| 研究・学術機関 |
| 通信プロバイダー |
| 北米 | 米国 |
| カナダ | |
| メキシコ | |
| 欧州 | ドイツ |
| 英国 | |
| フランス | |
| イタリア | |
| その他の欧州 | |
| アジア太平洋 | 中国 |
| 日本 | |
| 韓国 | |
| インド | |
| 東南アジア | |
| その他のアジア太平洋 | |
| 南米 | |
| 中東およびアフリカ |
| コンポーネント別 | ハードウェア | |
| ソフトウェア | ||
| サービス | ||
| アクセラレータタイプ別 | PCIeベースの分散化 | |
| NVLink/NVSwitchベースの分散化 | ||
| イーサネットファブリックベースの分散化 | ||
| InfiniBandファブリックベースの分散化 | ||
| CXLベースの分散化 | ||
| 展開モード別 | オンプレミス | |
| クラウドベース | ||
| アプリケーション別 | AIおよびハイパフォーマンスコンピューティング | |
| データ分析 | ||
| デジタルツインおよびシミュレーション | ||
| レンダリングおよび可視化 | ||
| 科学研究 | ||
| エンドユーザー別 | ハイパースケールクラウドプロバイダー | |
| クラウドサービスプロバイダー | ||
| エンタープライズ | ||
| 政府および防衛組織 | ||
| 研究・学術機関 | ||
| 通信プロバイダー | ||
| 地域別 | 北米 | 米国 |
| カナダ | ||
| メキシコ | ||
| 欧州 | ドイツ | |
| 英国 | ||
| フランス | ||
| イタリア | ||
| その他の欧州 | ||
| アジア太平洋 | 中国 | |
| 日本 | ||
| 韓国 | ||
| インド | ||
| 東南アジア | ||
| その他のアジア太平洋 | ||
| 南米 | ||
| 中東およびアフリカ | ||


レポートで回答される主要な質問
分散型GPU市場の現在の規模はどのくらいですか?
分散型GPU市場は2025年に39.7億米ドルと評価され、2026年には53.4億米ドルとなり、33.48%のCAGRで2031年までに226.3億米ドルに達すると予測されています。
AIインフラにおける分散型GPUの採用が増加している理由は何ですか?
GPUプーリングが利用率を向上させ、エージェント型AIがトークンスループットのニーズを増加させ、メモリと帯域幅の制約がオペレーターをプールされたコンピュートおよびメモリアーキテクチャに向かわせているため、採用が増加しています。
現在最も多くの収益をもたらしているコンポーネントはどれですか?
ハードウェアは2025年に収益の81.32%をリードし、初期展開がラック、ファブリック、スイッチ、メモリモジュール、緊密に統合されたコンピュートシステムへの大規模な支出を必要としたためです。
最も速く成長しているアクセラレータアプローチはどれですか?
CXLベースの分散化は、共有メモリプーリングとより柔軟な構成可能なシステム計に支えられ、2031年までに34.46%のCAGRで成長する見込みです。
最も速く拡大している地域はどこですか?
アジア太平洋地域は、中国のハイパースケールAI支出、韓国のHBM供給の強さ、インドとシンガポールの公共AIインフラプログラムに支えられ、2031年までに34.39%のCAGRで成長する見込みです。
より広い展開を妨げている主な障壁は何ですか?
最大の制約は、インターコネクトの複雑性、GPUスタック全体での断片化されたオーケストレーション、および密なAIラックの電力と冷却ニーズに施設を適応させるコストです。
最終更新日:




