Taille et part du marché des GPU désagrégés
VUE D’ENSEMBLE DU MARCHÉ
| Période d'étude | 2020 - 2031 |
|---|---|
| Taille du Marché (2026) | 5.34 Milliards de dollars |
| Taille du Marché (2031) | 22.63 Milliards de dollars |
| Taux de croissance (2026 - 2031) | 33.48% CAGR |
| Marché à la Croissance la Plus Rapide | Asie-Pacifique |
| Plus Grand Marché | Amérique du Nord |
| Concentration du Marché | Élevé |
Acteurs majeurs
*Avis de non-responsabilité : les principaux acteurs sont triés sans ordre particulier Image © Mordor Intelligence. La réutilisation nécessite une attribution sous CC BY 4.0. |
|
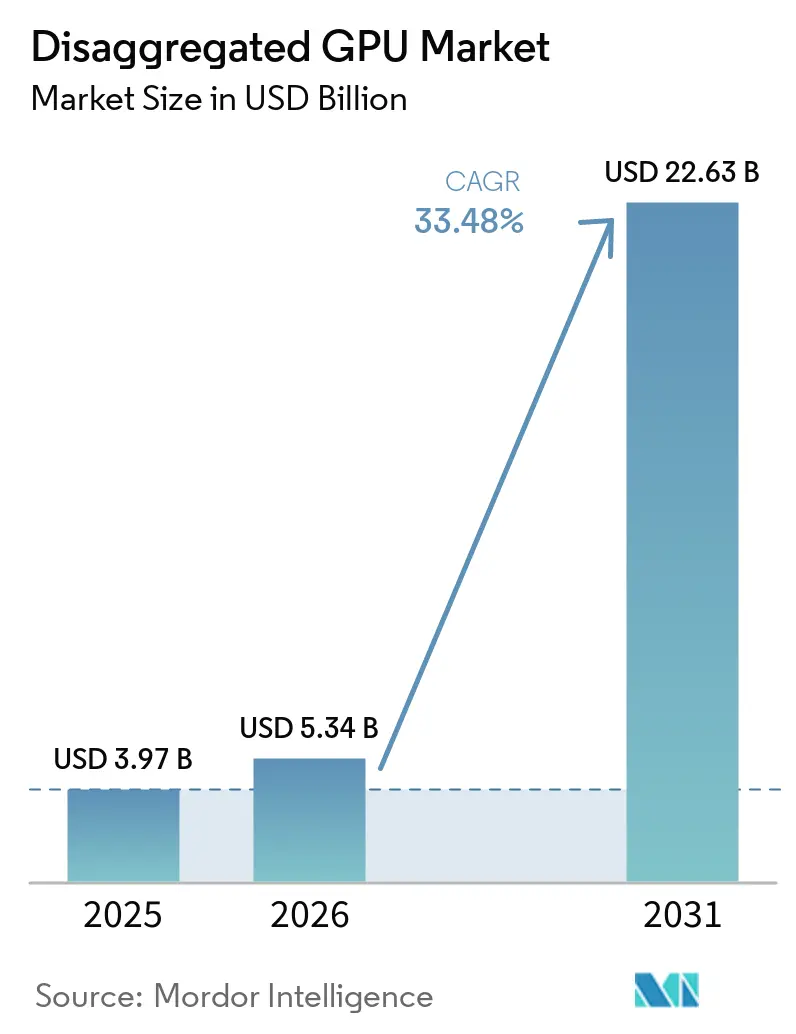
Analyse du marché des GPU désagrégés par Mordor Intelligence
La taille du marché des GPU désagrégés est projetée à 3,97 milliards USD en 2025, 5,34 milliards USD en 2026, et devrait atteindre 22,63 milliards USD d'ici 2031, avec un CAGR de 33,48 % de 2026 à 2031. Le marché des GPU désagrégés se développe à mesure que les piles de calcul IA s'éloignent des conceptions à serveurs fixes pour adopter des architectures connectées par fabric qui permettent aux opérateurs de séparer les ressources GPU des serveurs hôtes et de les allouer là où la demande est la plus forte. Les grands programmes d'investissement d'AMD et de NVIDIA, ainsi que les déploiements confirmés par les principales plateformes cloud, montrent que le marché des GPU désagrégés est désormais lié à une refonte globale des centres de données plutôt qu'à des cycles de renouvellement matériel isolés. Le comportement concurrentiel évolue également, car les opérateurs accordent davantage d'importance à l'utilisation, à l'orchestration et à l'efficacité à l'échelle du rack qu'au simple ajout d'accélérateurs supplémentaires. Le marché des GPU désagrégés bénéficie également de l'essor des charges de travail d'IA agentique, qui exercent une pression accrue sur le débit de jetons, le mouvement du cache KV et la coordination à faible latence entre les étapes de préremplissage et de décodage. Dans le même temps, les contrôles à l'exportation, les lacunes en matière d'interopérabilité et la densité de puissance des racks d'IA modernes maintiennent une croissance inégale, favorisant les opérateurs dotés d'une infrastructure dédiée et d'une solide expertise technique.
Points clés du rapport
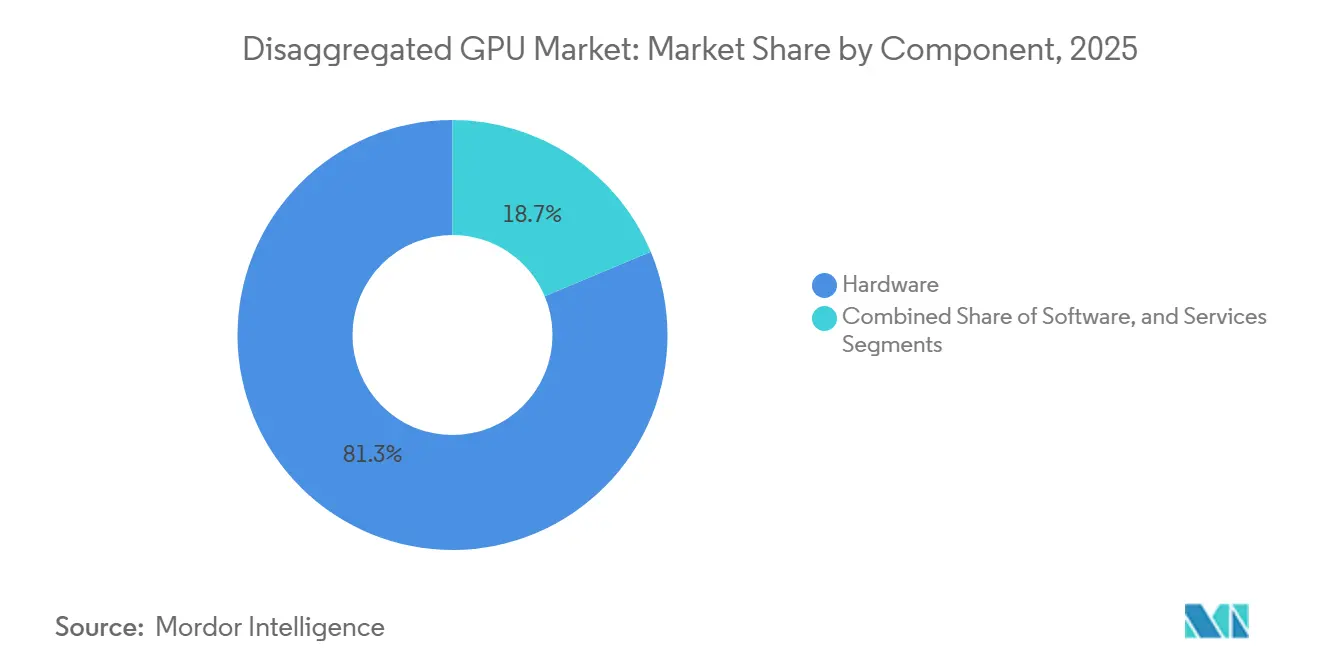
- Par composant, le matériel a dominé avec une part de revenus de 81,32 % en 2025, tandis que le logiciel devrait se développer à un CAGR de 34,08 % jusqu'en 2031 pour le marché des GPU désagrégés.
- Par type d'accélérateur, la désagrégation basée sur NVLink/NVSwitch détenait une part de 44,21 % en 2025, tandis que la désagrégation basée sur CXL devrait se développer à un CAGR de 34,46 % jusqu'en 2031.
- Par mode de déploiement, le déploiement basé sur le cloud représentait 61,77 % du marché des unités de traitement graphique (GPU) désagrégées en 2025 et devrait croître à un CAGR de 33,87 % jusqu'en 2031.
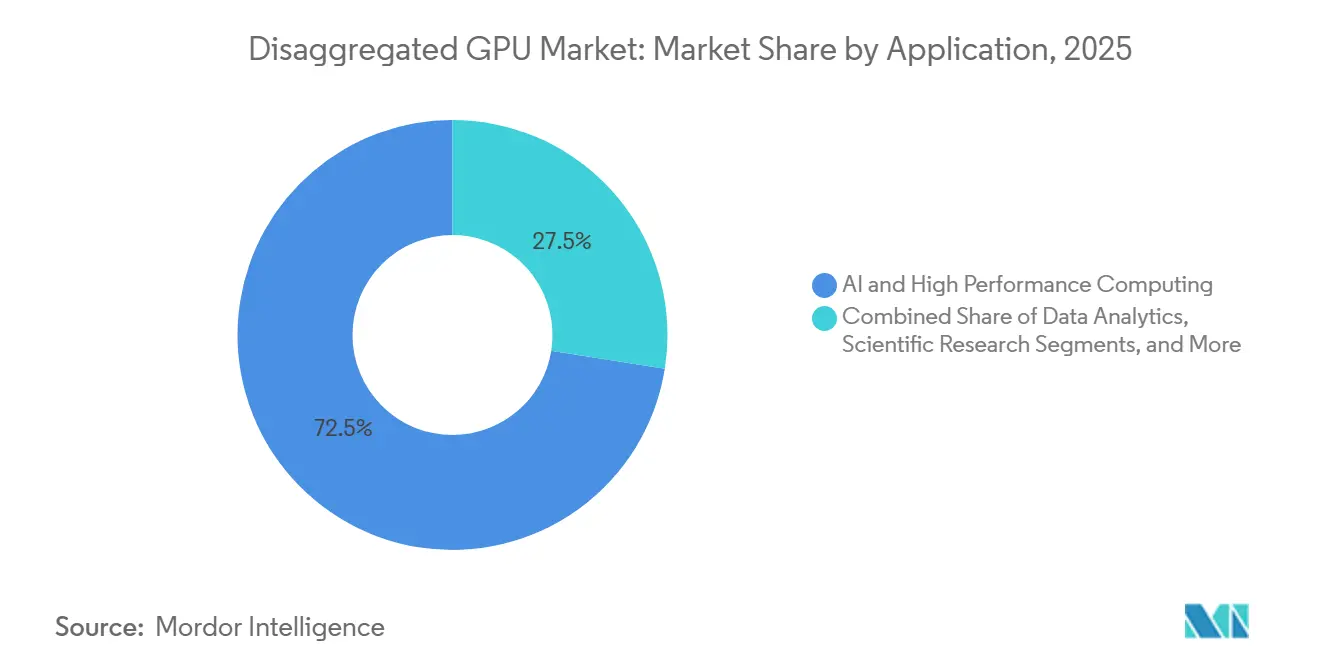
- Par application, l'IA et le calcul haute performance ont capté 72,49 % du marché en 2025, tandis que le jumeau numérique et la simulation devraient se développer à un CAGR de 34,42 % jusqu'en 2031.
- Par utilisateur final, les fournisseurs de cloud hyperscale détenaient une part de 47,63 % en 2025, tandis que les fournisseurs de services cloud devraient enregistrer le CAGR le plus élevé à 34,63 % jusqu'en 2031.
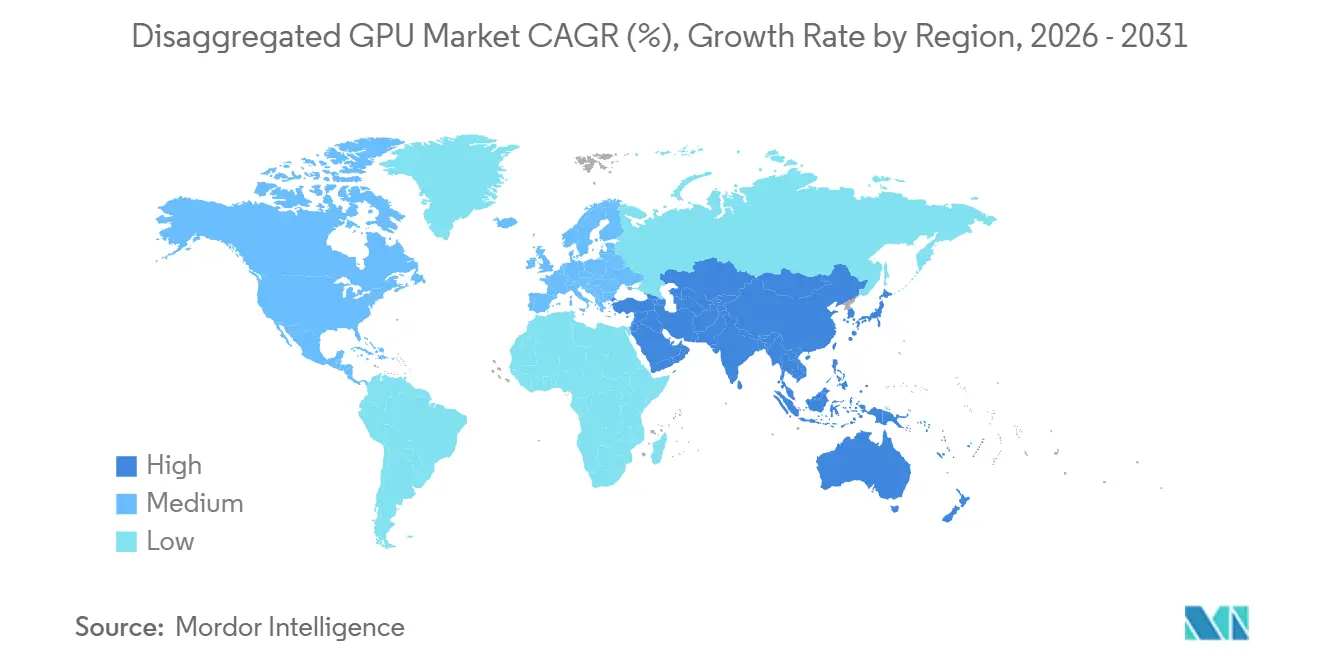
- Par géographie, l'Amérique du Nord détenait 52,71 % de la part du marché des GPU désagrégés en 2025, tandis que l'Asie-Pacifique devrait se développer à un CAGR de 34,39 % jusqu'en 2031.
Note : La taille du marché et les prévisions figurant dans ce rapport sont générées à l'aide du cadre d'estimation exclusif de Mordor Intelligence, mis à jour avec les dernières données et informations disponibles en janvier 2026.
Tendances et perspectives du marché mondial des GPU désagrégés
Analyse de l'impact des moteurs*
| Moteur | (~) % d'impact sur les prévisions de CAGR | Pertinence géographique | Horizon temporel de l'impact |
|---|---|---|---|
| Demande croissante de mise en commun des GPU dans les clusters d'entraînement IA | +10.2% | Mondial, concentré dans les hubs hyperscale d'Amérique du Nord et d'Asie-Pacifique | Court terme (≤ 2 ans) |
| Évolution vers des architectures de calcul et de mémoire séparés | +8.5% | Mondial, avec l'adoption du CXL ancrée en Amérique du Nord et en Asie de l'Est | Moyen terme (2-4 ans) |
| Expansion de l'infrastructure IA hyperscale et cloud-native | +7.3% | Mondial, avec l'Amérique du Nord et l'Asie-Pacifique en tête du déploiement des capitaux | Court terme (≤ 2 ans) |
| Gains d'efficacité énergétique et thermique grâce à la désagrégation des ressources | +4.8% | Mondial, accéléré par les réglementations énergétiques de l'UE et les contraintes d'alimentation en Asie-Pacifique | Moyen terme (2-4 ans) |
| Utilisation plus rapide des parcs grâce à l'allocation GPU multi-locataires | +3.6% | Corridors cloud d'Amérique du Nord, d'Europe et d'Asie du Sud-Est | Moyen terme (2-4 ans) |
| Cycles de mise à niveau plus courts dans les architectures de centres de données modulaires | +2.9% | Mondial, le plus rapide dans les constructions de nouvelles usines IA en Amérique du Nord | Long terme (≥ 4 ans) |
| Source: Mordor Intelligence | |||
Demande croissante de mise en commun des GPU dans les clusters d'entraînement IA
Le marché des GPU désagrégés bénéficie d'un soutien direct de la mise en commun des GPU, car les grands entraînements IA dépendent désormais du traitement de nombreux GPU physiques comme une seule ressource logique partagée. Le NVLink de sixième génération de NVIDIA a fourni 1,8 To/s de bande passante bidirectionnelle par GPU, et les systèmes NVLink Switch ont pris en charge 72 GPU dans un seul rack NVL72, offrant 130 To/s de bande passante agrégée dans le domaine, réduisant les limites de communication qui séparaient autrefois les racks adjacents en îlots de calcul isolés.[1]NVIDIA Developer Blog, "Mise à l'échelle des performances et de la flexibilité de l'inférence IA avec NVIDIA NVLink et NVLink Fusion," NVIDIA Developer Blog, developer.nvidia.com Ce changement est important pour les modèles à mille milliards de paramètres, car la pression sur la mémoire et la bande passante s'étend désormais à l'ensemble des clusters d'entraînement plutôt qu'à un seul nœud, et le marché des GPU désagrégés répond avec des architectures permettant à la capacité inactive de rejoindre les charges de travail actives beaucoup plus rapidement. L'IA agentique ajoute une autre couche de demande, car les étapes de préremplissage sont gourmandes en calcul tandis que les étapes de décodage sont gourmandes en bande passante mémoire, et ce schéma nécessite que les pools soient réaffectés en quelques secondes plutôt que par des cycles de planification manuelle plus lents. AWS a démontré ce modèle opérationnel en production en utilisant llm-d et la bibliothèque NVIDIA Inference Xfer sur des nœuds Blackwell, où l'inférence désagrégée a amélioré le débit de 70 % à haute simultanéité.
Évolution vers des architectures de calcul et de mémoire séparés
Le marché des GPU désagrégés progresse également à mesure que les opérateurs séparent le calcul de la mémoire locale et traitent la capacité mémoire comme une couche d'infrastructure mutualisée. Des recherches publiées dans Tsinghua Science and Technology ont décrit la désagrégation de mémoire basée sur CXL comme une étape architecturale majeure pour les centres de calcul intelligents, car les pools de mémoire partagée peuvent être atteints par plusieurs nœuds de calcul via des opérations standard de chargement et de stockage. Des chercheurs de ByteDance ont étendu cette direction en démontrant un pool de mémoire partagée de 768 Go construit à partir de cartes Micron CXL de type 3 et d'un commutateur CXL TITAN-II, permettant la communication GPU collective sur 3 nœuds avec des GPU NVIDIA H100 sans modification du code applicatif. Cela est important car l'inférence à contexte long dépasse 1 million de jetons et la demande de cache KV dépasse la HBM disponible sur chaque accélérateur, rendant l'ajout de mémoire mutualisée plus pratique que le remplacement de parcs GPU entiers. Le marché des GPU désagrégés bénéficie donc du CXL non seulement comme option technique, mais aussi comme voie économique pour les opérateurs ayant besoin de plus de capacité mémoire sans imposer un renouvellement complet du silicium.
Expansion de l'infrastructure IA hyperscale et cloud-native
Le marché des GPU désagrégés est porté à la hausse par l'ampleur des dépenses en infrastructure IA hyperscale et cloud-native, qui se sont élargies de projets pilotes isolés à des déploiements à l'échelle du rack et multi-sites. AMD a annoncé plus de 10 milliards USD d'investissements dans l'écosystème taïwanais en mai 2026 pour faire évoluer sa plateforme rack-scale Helios via des partenaires ODM, notamment Sanmina, Wiwynn, Wistron et Inventec, avec des déploiements multi-gigawatts ciblés pour le second semestre 2026. Google Cloud a également indiqué que son fabric réseau Virgo était conçu pour connecter jusqu'à 80 000 GPU NVIDIA Vera Rubin NVL72 dans un seul centre de données et plus de 960 000 GPU sur plusieurs sites, soulignant comment le marché des GPU désagrégés devient un fondement pour l'extension à l'échelle des centres de données plutôt qu'une architecture de niche. Dans le même temps, les programmes de silicium personnalisé chez AWS, Google et Microsoft n'éliminent pas le besoin de systèmes GPU désagrégés, car une infrastructure multi-fournisseurs émerge parallèlement à eux. Intel et SambaNova ont démontré ce modèle en 2026 avec une pile d'inférence hétérogène, où Intel Xeon 6 gérait l'orchestration, les RDU SambaNova géraient le décodage et les GPU NVIDIA Blackwell géraient le préremplissage depuis un seul centre de données en production.
Gains d'efficacité énergétique et thermique grâce à la désagrégation des ressources
Le marché des GPU désagrégés est également façonné par les contraintes de distribution d'énergie et de refroidissement, qui influencent désormais les décisions architecturales autant que la demande brute de calcul. La spécification Diablo de l'Open Compute Project, contribuée par Google, Meta et Microsoft en octobre 2025, a défini des conceptions de racks d'alimentation désagrégés prenant en charge des racks informatiques de 100 kilowatts à 1 mégawatt utilisant une distribution en 400 VCC ou 800 VCC. NVIDIA a ajouté un autre levier d'efficacité en décembre 2025 avec les profils d'alimentation Blackwell B200, offrant jusqu'à 15 % d'économies d'énergie avec un impact sur les performances inférieur à 3 %, permettant jusqu'à 13 % de débit supplémentaire dans les installations à puissance fixe. L'inférence désagrégée tenant compte des phases améliore encore la situation, car les étapes de préremplissage consomment une puissance de pointe tandis que les étapes de décodage ont des besoins en puissance plus faibles et peuvent être gérées différemment dans des pools de ressources séparés. Des recherches sur l'architecture BiScale ont montré que le DVFS coordonné entre les niveaux de préremplissage et de décodage désagrégés a réduit l'énergie de décodage jusqu'à 48 % tout en respectant les objectifs de latence de service, ce qui renforce le cas opérationnel pour le marché des unités de traitement graphique (GPU) désagrégées, où les limites énergétiques et les objectifs d'utilisation évoluent désormais conjointement.
Analyse de l'impact des freins*
| Frein | (~) % d'impact sur les prévisions de CAGR | Pertinence géographique | Horizon temporel de l'impact |
|---|---|---|---|
| Complexité élevée d'intégration des interconnexions et des fabrics | -1.8% | Mondial, plus aigu dans les déploiements multi-fournisseurs hors d'Amérique du Nord | Court terme (≤ 2 ans) |
| Fragmentation de l'orchestration logicielle entre les piles GPU | -1.4% | Mondial, particulièrement limitant dans les déploiements en entreprise et sur les marchés émergents | Moyen terme (2-4 ans) |
| Intensité capitalistique de la modernisation des centres de données existants | -1.1% | Europe et Amérique du Sud, où le parc de colocation existant est substantiel | Moyen terme (2-4 ans) |
| Compromis de latence dans l'accès à la mémoire distante et désagrégée | -0.8% | Mondial, plus critique pour les charges de travail d'inférence sensibles à la latence | Court terme (≤ 2 ans) |
| Source: Mordor Intelligence | |||
Complexité élevée d'intégration des interconnexions et des fabrics
Le marché des GPU désagrégés est encore confronté à un obstacle d'intégration significatif, car de nombreux déploiements doivent coordonner NVLink, PCIe, InfiniBand, Ethernet et CXL au sein d'un même cluster. Des recherches présentées à HotNets 2025 ont montré qu'une gestion efficace des chemins sur des interconnexions hétérogènes intra-hôte nécessite une coordination simultanée des commutateurs PCIe, des contrôleurs de fabric GPU, des cartes réseau RDMA et des commutateurs Ethernet, et que les piles logicielles actuelles n'abstraient pas entièrement cette complexité. NVLink Fusion de NVIDIA a réduit une partie de ce problème en permettant aux CPU personnalisés de MediaTek, Marvell, Qualcomm et Fujitsu de se connecter nativement aux GPU NVIDIA, mais cette démarche a élargi un chemin propriétaire plutôt que de créer un fabric multi-fournisseurs pleinement neutre. La norme Ultra Accelerator Link est censée offrir une alternative neutre vis-à-vis des fournisseurs, mais les données indiquent que le matériel de production n'était pas attendu avant fin 2026 et que les déploiements généralisés devraient s'étendre jusqu'en 2027. Le marché des GPU désagrégés est également confronté à un plafond d'interopérabilité régionale en Chine, où les écosystèmes d'accélérateurs domestiques utilisent des protocoles de communication incompatibles, limitant les avantages pratiques de mise en commun que les opérateurs peuvent atteindre à grande échelle.
Fragmentation de l'orchestration logicielle entre les piles GPU
L'absence d'une couche d'orchestration unifiée entre les environnements GPU hétérogènes freine également le marché des GPU désagrégés. Des recherches sur la planification tenant compte de la fragmentation ont montré que les planificateurs multi-locataires doivent encore concilier différentes approches d'isolation de la mémoire et de partitionnement entre les piles des fournisseurs, augmentant ainsi l'effort d'intégration et allongeant les délais de déploiement. Des travaux présentés à l'USENIX ATC 2025 ont montré que l'orchestration GPU spatio-temporelle au niveau du noyau dépend d'un contrôle détaillé des tampons de commandes et de la gestion du contexte spécifiques aux fournisseurs, sans logique de fabric ou sémantique de planification inter-fournisseurs standardisée en place aujourd'hui.[2]Shulai Zhang et al., "Partage GPU efficace et performant avec compatibilité et isolation via l'interception dans l'espace noyau," USENIX ATC 2025, usenix.org Cela rend la désagrégation à l'échelle du parc plus facile pour les hyperscalers disposant de grandes équipes d'ingénierie de plateforme et beaucoup plus difficile pour les acheteurs en entreprise qui gèrent des parcs GPU mixtes et ont besoin d'une couche opérationnelle commune. Le marché des GPU désagrégés devrait donc continuer à favoriser les plus grands opérateurs à moyen terme, car les travaux de normalisation en sont encore à leurs débuts et les écosystèmes propriétaires ont peu d'incitation à converger rapidement.
*Nos prévisions considèrent les impacts des moteurs et des contraintes comme directionnels et non additifs. Les prévisions d'impact reflètent la croissance de référence, les effets de composition et les interactions entre variables.
Analyse des segments
Par composant : le matériel domine les dépenses initiales tandis que le logiciel gagne en importance récurrente
Le matériel représentait 81,32 % du marché des GPU désagrégés en 2025, reflétant les coûts initiaux élevés des fabrics d'interconnexion, des plateaux de commutateurs, des modules de mémoire et des systèmes de calcul à l'échelle du rack. Chaque rack Vera Rubin NVL72 combinait 72 GPU Blackwell, 36 CPU Vera, des puces de commutation NVLink, des DPU BlueField-4 et la mise en réseau Ethernet Spectrum-X en une seule unité d'investissement basée sur fabric, maintenant les dépenses initiales sur le marché des GPU désagrégés concentrées dans de grands cycles d'approvisionnement hyperscale. Ce modèle d'approvisionnement est important car les acheteurs n'achètent pas des cartes ou des serveurs isolés ; ils s'engagent dans des plateformes étroitement intégrées qui regroupent les capacités de calcul, de mise en réseau et de gestion au sein d'un seul événement de déploiement. Le marché des GPU désagrégés présente donc un mix de revenus à forte composante matérielle dans sa phase actuelle, notamment à mesure que les hyperscalers construisent de nouvelles capacités IA en racks complets plutôt que par des ajouts progressifs nœud par nœud. Les services sont restés la plus petite couche de composants, mais l'intégration, les opérations gérées et la livraison de GPU en tant que service offraient encore un potentiel de marge attractif pour les intégrateurs de systèmes et les opérateurs cloud spécialisés.
Le logiciel devrait enregistrer le CAGR le plus rapide à 34,08 % de 2026 à 2031 sur le marché des GPU désagrégés, car les couches d'orchestration, les outils d'isolation et les frameworks d'inférence déterminent de plus en plus la valeur que les opérateurs extraient de chaque GPU. NVIDIA Dynamo a séparé les affectations de préremplissage et de décodage pour améliorer l'utilisation à l'échelle de l'usine, et cette conception a établi un point de référence que des alternatives open source telles que llm-d doivent désormais atteindre pour les déploiements en entreprise. Cela modifie le schéma de revenus du secteur des GPU désagrégés, car les mises à niveau logicielles peuvent se poursuivre même lorsque les cycles de renouvellement matériel ralentissent ou lorsque le fabric installé reste en place. Les opérateurs qui ont installé du matériel désagrégé en 2024 et 2025 sont susceptibles d'ajouter de nouvelles couches d'orchestration avant de remplacer les actifs d'interconnexion physique, créant une voie pour des revenus logiciels récurrents moins liés au calendrier de remplacement des racks. Au fil du temps, cette dynamique devrait donner au logiciel un rôle plus important sur le marché des GPU désagrégés, même si le matériel continue d'ancrer les dépenses absolues.



Par type d'accélérateur : NVLink établit la référence actuelle tandis que CXL élargit l'architecture
La désagrégation basée sur NVLink/NVSwitch détenait 44,21 % de la part du marché des GPU désagrégés en 2025, reflétant la forte position de NVIDIA dans les fabrics d'entraînement IA et la préférence installée pour une communication GPU étroitement couplée. Le NVLink de sixième génération a fourni 1,8 To/s par GPU en 2024, et les nouveaux systèmes NVLink Switch ont permis une communication tous-vers-tous entre 72 GPU avec 130 To/s de bande passante agrégée, offrant au marché des GPU désagrégés une option haute performance pour les clusters de montée en charge nécessitant une communication locale dense. La désagrégation basée sur PCIe a maintenu un rôle durable en tant que fabric de base dans de nombreux systèmes multi-GPU, offrant une large compatibilité sans le même niveau de dépendance propriétaire. Les approches basées sur InfiniBand et Ethernet ont continué à jouer un rôle dans les configurations de montée en charge, et Ethernet en particulier a gagné en pertinence là où les opérateurs souhaitaient étendre de grands clusters IA en s'appuyant sur des investissements réseau existants. Cette répartition signifie que le marché des GPU désagrégés ne s'oriente pas vers un fabric universel unique, mais vers un modèle en couches dans lequel les performances, l'ouverture et l'infrastructure installée influencent chacune l'architecture finale.
La désagrégation basée sur CXL devrait se développer à un CAGR de 34,46 % jusqu'en 2031, soutenue par la mise en commun de mémoire CXL 3.0 et la spécification CXL 4.0, qui a doublé la bande passante à 128 GT/s via des couches physiques PCIe 7.0 et introduit des ports groupés pour un débit total beaucoup plus élevé. Des recherches dans Tsinghua Science and Technology ont montré que la désagrégation de mémoire CXL et la désagrégation de calcul GPU servent différentes couches de la pile, ce qui suggère que les futurs déploiements sur le marché des GPU désagrégés les combineront plutôt que de forcer un choix entre eux. Samsung Electronics développe sa plateforme de mémoire CXL Pangea avec Marvell et Liquid AI pour étendre la mémoire GPU, où les limites HBM peuvent restreindre les tailles de lots d'inférence et la profondeur du contexte de travail. En pratique, NVLink est bien adapté à la communication GPU-à-GPU étroitement couplée à l'intérieur du rack, tandis que CXL étend la capacité mémoire et le partage de mémoire entre les nœuds et les domaines système plus larges. Cette relation complémentaire devrait aider le marché des GPU désagrégés à évoluer vers des architectures plus composables sans réduire le rôle des fabrics GPU à haute bande passante déjà établis dans les clusters en production.
Par mode de déploiement : la livraison cloud façonne les normes tandis que le sur site maintient une demande stratégique
Le déploiement basé sur le cloud détenait une part de 61,77 % de la taille du marché des GPU désagrégés en 2025, et le même segment devrait afficher le CAGR le plus rapide à 33,87 % jusqu'en 2031. AWS a introduit l'inférence désagrégée sur SageMaker HyperPod et Amazon EKS via llm-d et la bibliothèque NVIDIA Inference Xfer, en utilisant Elastic Fabric Adapter pour déplacer les données du cache KV entre les nœuds désagrégés et en livrant jusqu'à 70 % de jetons par seconde supplémentaires sur les instances basées sur Blackwell par rapport aux déploiements standard. Google Cloud a ajouté un autre signal en indiquant que Virgo peut connecter jusqu'à 80 000 GPU NVIDIA Vera Rubin NVL72 dans un seul centre de données et dépasser 960 000 GPU sur plusieurs sites, renforçant le rôle des hyperscalers dans la définition du modèle opérationnel pour le marché des unités de traitement graphique (GPU) désagrégées. L'avantage de la livraison cloud n'est pas seulement l'échelle, mais aussi la capacité à masquer la complexité du refroidissement, de la configuration du fabric et de l'orchestration derrière des services gérés. C'est pourquoi le marché des GPU désagrégés continue de s'orienter vers les plateformes cloud, notamment pour les acheteurs qui ont besoin d'accéder à des capacités IA avancées mais ne souhaitent pas construire et exploiter eux-mêmes une infrastructure spécialisée.
Le déploiement sur site reste important sur le marché des GPU désagrégés pour les entreprises et les organisations du secteur public qui ne peuvent pas déplacer des charges de travail sensibles vers des environnements cloud public partagés. Les données montrent que les acheteurs en entreprise sont plus sensibles aux prix que les hyperscalers et adoptent généralement des architectures désagrégées après que les opérateurs cloud les ont validées à grande échelle, ce qui place la demande sur site sur une trajectoire plus lente mais toujours importante. Les organisations gouvernementales et de défense forment une cohorte sur site distincte, car les programmes d'IA souveraine et les règles de sécurité nationale exigent souvent des environnements de calcul isolés ou liés à une juridiction. Les exigences de localisation des données dans l'Union européenne et dans certaines parties de l'Asie-Pacifique soutiennent également un plancher pour l'infrastructure dédiée, même si le cloud reste le mode le plus important et à la croissance la plus rapide. En conséquence, le marché des GPU désagrégés devrait maintenir une structure duale, avec les plateformes cloud fixant le rythme de l'innovation tandis que les déploiements sur site restent importants lorsque la conformité, le contrôle ou la sensibilité des charges de travail limitent l'accès partagé.
Par application : l'IA et le calcul haute performance stimulent la demande actuelle tandis que la simulation crée de nouveaux volumes
L'IA et le calcul haute performance représentaient 72,49 % du marché des GPU désagrégés en 2025, en faisant le principal moteur des déploiements actuels. Les plus grands modèles de langage et systèmes de raisonnement nécessitent une capacité mémoire et des performances d'interconnexion qui dépassent les limites des nœuds isolés, de sorte que le marché des GPU désagrégés s'est développé autour de la mise en commun et de la coordination des fabrics comme exigences de base pour l'entraînement et l'inférence de pointe. NVIDIA a indiqué que Vera Rubin NVL72 peut offrir un débit d'agents 10 fois supérieur à celui de la génération Grace Blackwell précédente, ce qui explique pourquoi les hyperscalers déploient ces plateformes à la fois pour les clusters d'entraînement et les environnements d'inférence à forte charge de raisonnement. La recherche scientifique fait également partie de ce segment, car la génomique, la modélisation climatique et la physique des particules nécessitent un calcul disponible à la demande pouvant être provisionné à grande échelle sans laisser des ressources GPU coûteuses inactives entre les tâches. Ce mix maintient le marché des GPU désagrégés étroitement lié aux charges de travail où l'utilisation, le partage de mémoire et l'efficacité des interconnexions affectent directement la production scientifique ou les performances des modèles.
Le jumeau numérique et la simulation devraient progresser à un CAGR de 34,42 % de 2026 à 2031, reflétant l'utilisation plus large des modèles physiques accélérés par GPU dans les opérations industrielles, la validation de conception et l'entraînement des systèmes autonomes. Le marché des GPU désagrégés en bénéficie car de nombreuses charges de travail de simulation nécessitent de courtes périodes de très haute densité de calcul, ce qui rend les ressources mutualisées plus économiques que les allocations de serveurs statiques. NVIDIA a indiqué que sa plateforme DSX peut réduire le temps de déploiement d'une usine IA de plusieurs mois à quelques jours et accélérer le délai de premier revenu, et ce modèle commercial commence à influencer la façon dont les utilisateurs industriels envisagent une infrastructure de simulation évolutive. L'analyse de données, le rendu et la visualisation restent des cas d'usage établis avec une croissance plus stable, tandis que le rendu bénéficie de l'accélération GPU en temps réel dans les interfaces industrielles immersives qui exigent une faible latence d'image. Ensemble, ces tendances élargissent le marché des GPU désagrégés au-delà de l'entraînement IA de pointe et augmentent la demande des acheteurs qui valorisent une capacité flexible pour les charges de travail numériques opérationnelles.
Par utilisateur final : les hyperscalers détiennent la plus grande base tandis que les clouds spécialisés se développent plus rapidement
Les fournisseurs de cloud hyperscale détenaient une part de 47,63 % en 2025, leur conférant la position la plus importante sur le marché des GPU désagrégés et une forte influence sur les normes architecturales, le calendrier de déploiement et les choix logiciels. AWS, Google Cloud, Microsoft Azure et Oracle Cloud Infrastructure ont été identifiés comme déployeurs au second semestre 2026 de systèmes NVIDIA Vera Rubin NVL72, ce qui renforce la mesure dans laquelle le marché des GPU désagrégés dépend encore des hyperscalers pour l'adoption précoce des volumes. Leur rôle de premier entrant va au-delà du pouvoir d'achat, car ils façonnent également la façon dont l'orchestration, la mise en commun des ressources et les services IA gérés sont packagés pour les clients en aval. Les entreprises deviennent un groupe d'adoptants plus important, mais elles abordent généralement les déploiements avec des contrôles budgétaires plus stricts, une plus grande sensibilité au risque d'intégration et une préférence pour des configurations cloud dédiées ou sur site où l'exposition des données peut être limitée. Les acheteurs gouvernementaux et de défense restent également pertinents, car de longs cycles d'approvisionnement peuvent encore générer de grandes valeurs contractuelles lorsque les programmes de calcul souverain avancent.
Les fournisseurs de services cloud devraient enregistrer le CAGR le plus rapide à 34,63 % de 2026 à 2031 sur le marché des GPU désagrégés, car les opérateurs de niveau intermédiaire construisent des plateformes de GPU en tant que service autour de la spécialisation et de la flexibilité tarifaire. NVIDIA a identifié CoreWeave, Lambda, Nebius et Nscale parmi les premiers adoptants de Vera Rubin et Spectrum-X Ethernet Photonics, démontrant comment les clouds spécialisés étendent leur capacité pour répondre à la demande d'entraînement et d'inférence au-delà des plus grandes plateformes hyperscale. Leur position est prometteuse mais aussi exposée, car la baisse des coûts par jeton chez les hyperscalers peut comprimer les marges locatives et forcer les fournisseurs plus petits à se différencier par des services gérés et un support au niveau applicatif. Les fournisseurs de télécommunications émergent également comme utilisateurs axés sur la périphérie des systèmes GPU désagrégés, tandis que les institutions de recherche et académiques jouent un rôle de revenus plus modeste mais contribuent à abaisser les barrières logicielles grâce à des travaux d'orchestration open source tels que llm-d et les outils natifs Kubernetes associés. Cette combinaison d'hyperscalers dominants, de clouds spécialisés en mouvement rapide et d'acheteurs publics et privés ciblés donne au marché des GPU désagrégés une base de demande qui s'élargit sans réduire sa dépendance à quelques très grands opérateurs.
Analyse géographique
L'Amérique du Nord détenait une part de 52,71 % en 2025, lui conférant la plus grande part régionale sur le marché des GPU désagrégés et reflétant la profondeur des constructions hyperscale à travers les États-Unis. AWS, Google Cloud, Microsoft Azure et Oracle Cloud Infrastructure ont tous été désignés comme déployeurs au second semestre 2026 de systèmes NVIDIA Vera Rubin NVL72, et cette concentration d'acheteurs de premier plan continue d'ancrer le marché des GPU désagrégés dans la région. L'Amérique du Nord bénéficie également d'un écosystème matériel dense, d'une activité de recherche IA majeure et d'une couche cloud GPU mature, incluant des fournisseurs tels que CoreWeave, Lambda et Nscale. La collaboration de NVIDIA en septembre 2025 avec Intel pour développer des CPU personnalisés pour centres de données IA basés sur NVLink et x86 a approfondi les chaînes d'approvisionnement régionales et permis une meilleure intégration entre les CPU d'orchestration et les fabrics GPU.[3]Intel Corporation, "Intel et NVIDIA développent conjointement des produits d'infrastructure IA et d'informatique personnelle," Intel Newsroom, newsroom.intel.com Le Canada apporte un soutien grâce à sa proximité avec la demande hyperscale américaine et à des conditions économiques d'alimentation favorables, tandis que l'Amérique du Sud en est à un stade plus précoce et est davantage liée aux zones de disponibilité hyperscale au Brésil et en Colombie qu'à un déploiement sur site généralisé.
L'Europe détenait une part significative mais plus modeste du marché des GPU désagrégés, avec l'Allemagne, le Royaume-Uni et la France comme principaux centres de déploiement selon les données d'entrée. La directive sur l'efficacité énergétique de l'Union européenne exige des rapports sur l'efficacité d'utilisation de l'énergie pour les centres de données avec une charge informatique supérieure à 500 kW, ce qui favorise des conceptions plus efficaces et désagrégées et oblige les opérateurs à démontrer des performances mesurables des installations. La base automobile et de fabrication de précision de l'Allemagne soutient la demande de charges de travail de jumeau numérique et de simulation physique, où le calcul en rafale est plus facile à justifier via une infrastructure mutualisée que via des allocations de serveurs fixes. Le Royaume-Uni contribue par un segment cloud GPU actif, tandis que la France et l'Italie étendent des programmes de calcul IA souverain qui intègrent une capacité GPU désagrégée.
L'Asie-Pacifique devrait se développer à un CAGR de 34,39 % entre 2026 et 2031, conférant à la région le taux de croissance le plus rapide sur le marché des GPU désagrégés pendant la période de prévision. La région est portée par les dépenses hyperscale IA de la Chine, la chaîne d'approvisionnement en mémoire verticalement intégrée de la Corée du Sud, les besoins de fabrication et d'automatisation du Japon, et les programmes d'infrastructure IA publique en Inde et à Singapour. La Chine construit des architectures désagrégées domestiques autour d'approches d'interconnexion propriétaires, créant une structure régionale divisée dans laquelle les piles chinoises diffèrent de celles utilisées ailleurs sur le marché des GPU désagrégés. La Corée du Sud bénéficie de la position de SK Hynix dans la production de HBM3e, ce qui aide les opérateurs domestiques à obtenir un accès plus précoce aux sous-systèmes de mémoire et soutient un déploiement plus rapide des capitaux dans les centres de données. L'Inde progresse également rapidement à mesure que les initiatives IA soutenues par le gouvernement et les zones cloud hyperscale se développent, tandis que le Moyen-Orient et l'Afrique en sont à un stade plus précoce de développement mais bénéficient du soutien des programmes d'investissement en IA souveraine aux Émirats arabes unis et en Arabie saoudite.

Paysage concurrentiel
Le marché des GPU désagrégés reste très concentré dans la couche d'interconnexion matérielle, tandis que les logiciels et les services sont beaucoup plus fragmentés entre les fournisseurs d'orchestration, les fournisseurs de cloud GPU et les spécialistes de l'intégration. NVIDIA continue de donner le rythme sur le marché des GPU désagrégés car son écosystème NVLink, ses plateformes à l'échelle du rack et sa portée en production lui confèrent un avantage solide là où les acheteurs ont besoin de fabrics de montée en charge éprouvés et de piles matérielles coordonnées. Son lancement en mai 2025 de NVLink Fusion a été un mouvement stratégique notable car il a permis au silicium personnalisé de MediaTek, Marvell, Qualcomm, Fujitsu et d'autres de se connecter nativement aux GPU NVIDIA et a élargi l'écosystème adressable pour l'infrastructure IA semi-personnalisée. Ce mouvement n'a pas réduit la dépendance de NVIDIA à la technologie propriétaire, mais il a rendu le fabric de NVIDIA plus central à la conception des systèmes pour un ensemble plus large de partenaires. En pratique, le marché des GPU désagrégés donne encore à NVIDIA la position la plus forte là où les performances matérielles et la maturité de l'écosystème comptent le plus.
AMD construit sa position sur le marché des unités de traitement graphique (GPU) désagrégées par une voie différente qui combine la plateforme rack-scale Helios avec la pile logicielle ouverte ROCm et une base de fournisseurs plus large. Sa décision de mai 2026 de s'engager à investir plus de 10 milliards USD dans l'écosystème taïwanais a été un autre mouvement stratégique majeur, car il a signalé un effort pluriannuel pour réduire l'écart de production matérielle et renforcer l'exécution à l'échelle du rack via des partenaires de fabrication régionaux.[4]Advanced Micro Devices, Inc., "AMD annonce plus de 10 milliards USD d'investissements dans l'écosystème taïwanais pour accélérer l'infrastructure IA," AMD Investor Relations, ir.amd.com Le rôle d'Intel est plus asymétrique, car il ne dirige pas la couche de fabric GPU mais trouve de la valeur dans la position de CPU d'orchestration au sein de systèmes hétérogènes. Cette approche était évidente au Computex 2026, où Intel Xeon 6 a permis l'orchestration dans une pile d'inférence désagrégée à trois fournisseurs avec SambaNova et NVIDIA dans un seul exemple de déploiement commercial. Ces mouvements montrent que le marché des GPU désagrégés est compétitif au niveau de la plateforme même si le fabric matériel central reste concentré.
Le plus grand espace ouvert sur le marché des GPU désagrégés est l'orchestration multi-fournisseurs, car il n'existe toujours pas de plateforme commerciale largement adoptée qui planifie de manière cohérente les charges de travail sur NVLink, CXL, InfiniBand et Ethernet. Des acteurs émergents tels qu'Exostellar, travaillant avec Vultr, ciblent cette lacune avec une orchestration au niveau des charges de travail sur des parcs GPU hétérogènes géographiquement distribués, tandis que des fournisseurs de serveurs tels que Dell Technologies, Hewlett Packard Enterprise, Supermicro et Lenovo se font concurrence via l'intégration de systèmes, le refroidissement liquide et les services d'infrastructure gérés. L'activité de normalisation est également importante car toute voie vers des fabrics désagrégés plus ouverts affecterait la façon dont les entreprises et les gouvernements évaluent la dépendance aux fournisseurs et les achats à long terme. Pour l'instant, le marché des GPU désagrégés soutient une structure concurrentielle en couches où un petit nombre de leaders matériels influencent l'architecture centrale, tandis qu'un champ beaucoup plus large se dispute le contrôle du déploiement, de l'orchestration et de la prestation de services.
Leaders du secteur des GPU désagrégés
-
NVIDIA Corporation
-
Advanced Micro Devices, Inc.
-
Intel Corporation
-
Qualcomm Incorporated
-
Apple Inc.
- *Avis de non-responsabilité : les principaux acteurs sont triés sans ordre particulier

Développements récents du secteur
- Juin 2026 : Amazon Web Services a annoncé la disponibilité générale des instances EC2 G7 alimentées par des GPU NVIDIA RTX PRO 4500 Blackwell Server Edition, offrant jusqu'à 4,6 fois les performances d'inférence IA de la génération G6 précédente. Les instances disposent d'une bande passante réseau Elastic Fabric Adapter allant jusqu'à 700 Gbps, prenant en charge les charges de travail d'inférence IA désagrégée, de traduction linguistique et d'analyse d'images à grande échelle.
- Mai 2026 : NVIDIA a annoncé que la plateforme Vera Rubin est entrée en pleine production dans 350 usines dans 30 pays, avec AWS, Google Cloud, Microsoft Azure et Oracle Cloud Infrastructure comme déployeurs confirmés au second semestre 2026. La plateforme a introduit Spectrum-X Ethernet Photonics, les premiers commutateurs Ethernet à optique co-packagée en production du secteur, offrant une efficacité énergétique 5 fois supérieure à celle des émetteurs-récepteurs traditionnels et permettant des déploiements d'usines IA à un million de GPU.
- Mai 2026 : AMD a annoncé 10 milliards USD d'investissements dans l'écosystème taïwanais pour faire évoluer la plateforme rack-scale Helios dotée de GPU MI450X et de CPU EPYC Venice de 6e génération avec un packaging à pont surélevé 2.5D inédit dans le secteur. Les partenaires ODM Sanmina, Wiwynn, Wistron et Inventec augmentent leur production pour des déploiements multi-gigawatts ciblés au second semestre 2026.
- Mai 2026 : Vector Core Compute, soutenu par Vista Equity Partners et Cambium Capital, a lancé commercialement le premier système d'inférence désagrégée au Computex 2026, déployant Intel Xeon 6 pour l'orchestration, les RDU SambaNova SN40 pour le décodage et les GPU NVIDIA Blackwell pour le préremplissage depuis un centre de données de Los Angeles. Together.ai a été annoncé comme premier client commercial.


Périmètre du rapport mondial sur le marché des GPU désagrégés
Le marché des GPU désagrégés comprend le matériel, les logiciels et les services qui permettent aux unités de traitement graphique (GPU) d'être découplées des architectures de serveurs traditionnelles et allouées dynamiquement à plusieurs ressources de calcul via des interconnexions à haute vitesse et des fabrics réseau. Les architectures GPU désagrégées permettent aux organisations de mutualiser, partager, virtualiser et orchestrer les ressources GPU indépendamment des limites physiques des serveurs, améliorant l'utilisation des ressources, l'évolutivité, la flexibilité opérationnelle et l'efficacité de l'infrastructure dans les environnements de centres de données, cloud et de calcul haute performance.
Le rapport sur le marché des GPU désagrégés est segmenté par composant (matériel, logiciel et services), type d'accélérateur (désagrégation basée sur PCIe, désagrégation basée sur NVLink/NVSwitch, désagrégation basée sur fabric Ethernet, désagrégation basée sur fabric InfiniBand et désagrégation basée sur CXL), mode de déploiement (sur site et cloud), application (IA et calcul haute performance, analyse de données, jumeau numérique et simulation, rendu et visualisation, et recherche scientifique), utilisateur final (fournisseurs de cloud hyperscale, fournisseurs de services cloud, entreprises, organisations gouvernementales et de défense, institutions de recherche et académiques, fournisseurs de télécommunications) et géographie (Amérique du Nord, Europe, Asie-Pacifique, Amérique du Sud et Moyen-Orient et Afrique). Les prévisions du marché sont fournies en termes de valeur (USD).
| Matériel |
| Logiciel |
| Services |
| Désagrégation basée sur PCIe |
| Désagrégation basée sur NVLink/NVSwitch |
| Désagrégation basée sur fabric Ethernet |
| Désagrégation basée sur fabric InfiniBand |
| Désagrégation basée sur CXL |
| Sur site |
| Basé sur le cloud |
| IA et calcul haute performance |
| Analyse de données |
| Jumeau numérique et simulation |
| Rendu et visualisation |
| Recherche scientifique |
| Fournisseurs de cloud hyperscale |
| Fournisseurs de services cloud |
| Entreprises |
| Organisations gouvernementales et de défense |
| Institutions de recherche et académiques |
| Fournisseurs de télécommunications |
| Amérique du Nord | États-Unis |
| Canada | |
| Mexique | |
| Europe | Allemagne |
| Royaume-Uni | |
| France | |
| Italie | |
| Reste de l'Europe | |
| Asie-Pacifique | Chine |
| Japon | |
| Corée du Sud | |
| Inde | |
| Asie du Sud-Est | |
| Reste de l'Asie-Pacifique | |
| Amérique du Sud | |
| Moyen-Orient et Afrique |
| Par composant | Matériel | |
| Logiciel | ||
| Services | ||
| Par type d'accélérateur | Désagrégation basée sur PCIe | |
| Désagrégation basée sur NVLink/NVSwitch | ||
| Désagrégation basée sur fabric Ethernet | ||
| Désagrégation basée sur fabric InfiniBand | ||
| Désagrégation basée sur CXL | ||
| Par mode de déploiement | Sur site | |
| Basé sur le cloud | ||
| Par application | IA et calcul haute performance | |
| Analyse de données | ||
| Jumeau numérique et simulation | ||
| Rendu et visualisation | ||
| Recherche scientifique | ||
| Par utilisateur final | Fournisseurs de cloud hyperscale | |
| Fournisseurs de services cloud | ||
| Entreprises | ||
| Organisations gouvernementales et de défense | ||
| Institutions de recherche et académiques | ||
| Fournisseurs de télécommunications | ||
| Par géographie | Amérique du Nord | États-Unis |
| Canada | ||
| Mexique | ||
| Europe | Allemagne | |
| Royaume-Uni | ||
| France | ||
| Italie | ||
| Reste de l'Europe | ||
| Asie-Pacifique | Chine | |
| Japon | ||
| Corée du Sud | ||
| Inde | ||
| Asie du Sud-Est | ||
| Reste de l'Asie-Pacifique | ||
| Amérique du Sud | ||
| Moyen-Orient et Afrique | ||


Questions clés auxquelles le rapport répond
Quelle est la taille actuelle du marché des GPU désagrégés ?
Le marché des GPU désagrégés était évalué à 3,97 milliards USD en 2025, s'établit à 5,34 milliards USD en 2026 et devrait atteindre 22,63 milliards USD d'ici 2031 à un CAGR de 33,48 %.
Pourquoi l'adoption des GPU désagrégés est-elle en hausse dans l'infrastructure IA ?
L'adoption est en hausse car la mise en commun des GPU améliore l'utilisation, l'IA agentique accroît les besoins en débit de jetons, et les contraintes de mémoire et de bande passante poussent les opérateurs vers des architectures de calcul et de mémoire mutualisées.
Quel composant contribue le plus aux revenus aujourd'hui ?
Le matériel a dominé avec 81,32 % des revenus en 2025, car les premiers déploiements nécessitaient des dépenses importantes en racks, fabrics, commutateurs, modules de mémoire et systèmes de calcul étroitement intégrés.
Quelle approche d'accélérateur connaît la croissance la plus rapide ?
La désagrégation basée sur CXL devrait croître à un CAGR de 34,46 % jusqu'en 2031, soutenue par la mise en commun de mémoire partagée et une conception de système composable plus flexible.
Quelle région se développe le plus rapidement ?
L'Asie-Pacifique devrait croître à un CAGR de 34,39 % jusqu'en 2031, soutenue par les dépenses hyperscale IA en Chine, la solidité de l'offre HBM en Corée du Sud et les programmes d'infrastructure IA publique en Inde et à Singapour.
Quel est le principal obstacle freinant un déploiement plus large ?
Les principales contraintes sont la complexité des interconnexions, la fragmentation de l'orchestration entre les piles GPU et le coût d'adaptation des installations aux besoins en alimentation et en refroidissement des racks IA denses.
Dernière mise à jour de la page le:




