AI Computing Hardware Market Size and Share
Market Overview
| Study Period | 2020 - 2031 |
|---|---|
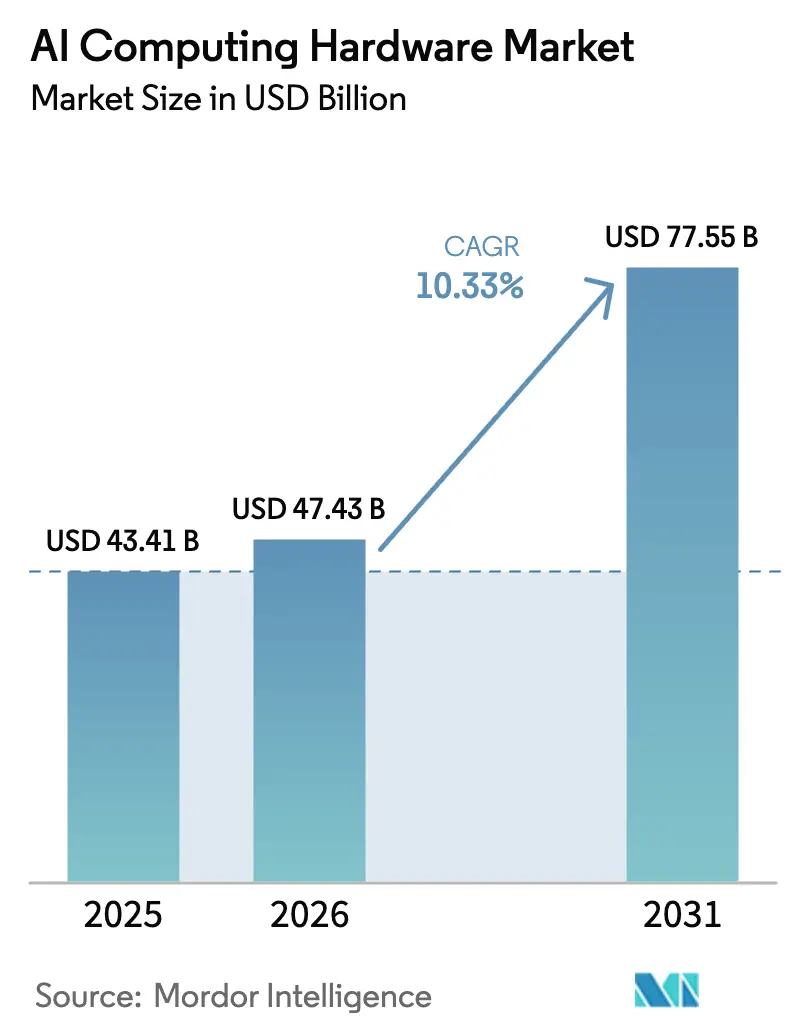
| Market Size (2026) | USD 47.43 Billion |
| Market Size (2031) | USD 77.55 Billion |
| Growth Rate (2026 - 2031) | 10.33% CAGR |
| Fastest Growing Market | Asia Pacific |
| Largest Market | North America |
| Market Concentration | Low |
Major Players *Disclaimer: Major Players sorted in no particular order Image © Mordor Intelligence. Reuse requires attribution under CC BY 4.0. | |
AI Computing Hardware Market Analysis by Mordor Intelligence
The AI Computing Hardware Market size is expected to increase from USD 43.41 billion in 2025 to USD 47.43 billion in 2026 and reach USD 77.55 billion by 2031, growing at a CAGR of 10.33% over 2026-2031.
Growth follows a clear shift in system design, as inference workloads dominate production deployments, reshaping capacity planning, infrastructure design, and accelerator selection. Capital spending by hyperscalers reinforces this trajectory, with large-scale programs centered on servers, accelerators, high-speed interconnects, and liquid cooling that support higher thermal design power at the rack. Annual product refresh cycles and the shift to integrated rack-scale systems enable operators to compress the time to deploy and standardize performance envelopes across regional sites. Power availability, memory supply, and export policies remain the primary friction points; however, long-term contracts and pre-committed power strategies help stabilize investment decisions in the AI computing hardware market. The AI computing hardware market continues to recalibrate around scalable, production-grade inference as the primary driver of recurring spend, and this emphasis on real-time serving is shaping thermal, networking, and memory design choices across operators. Rack-level integration and co-packaged optics are gaining traction as operators strive to reduce power per bit and enhance cluster resiliency in large-scale training and inference fabrics.[1]NVIDIA Newsroom, “OpenAI and NVIDIA Announce Strategic Partnership to Deploy 10 Gigawatts of NVIDIA Systems,” NVIDIA, nvidianews.nvidia.com Strategic partnerships between chipmakers and platform providers underscore the long-term nature of AI buildouts, including commitments to multi-gigawatt deployments for next-generation systems. The AI computing hardware market therefore reflects both technical and operational shifts that align with large, contracted demand profiles across leading regions.
Key Report Takeaways
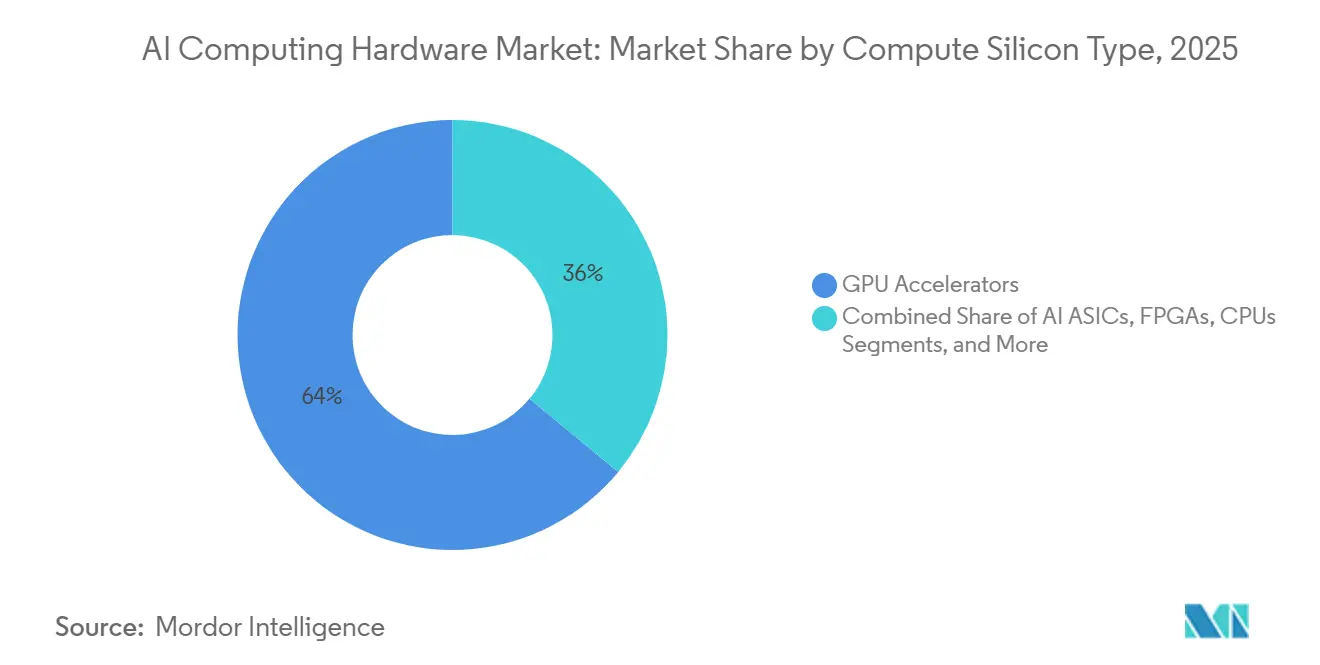
- By compute silicon type, GPU accelerators led with 64% revenue share in 2025, while AI ASICs are projected to expand at a 10.6% CAGR through 2031.
- By system form factor, AI servers accounted for a 78% share in 2025, and integrated rack-scale platforms posted the highest growth at a 10.7% CAGR through 2031.
- By deployment location, cloud data centers held a 44% share in 2025, while edge and endpoint sites grew at the fastest rate, with a 10.9% CAGR from 2026 to 2031.
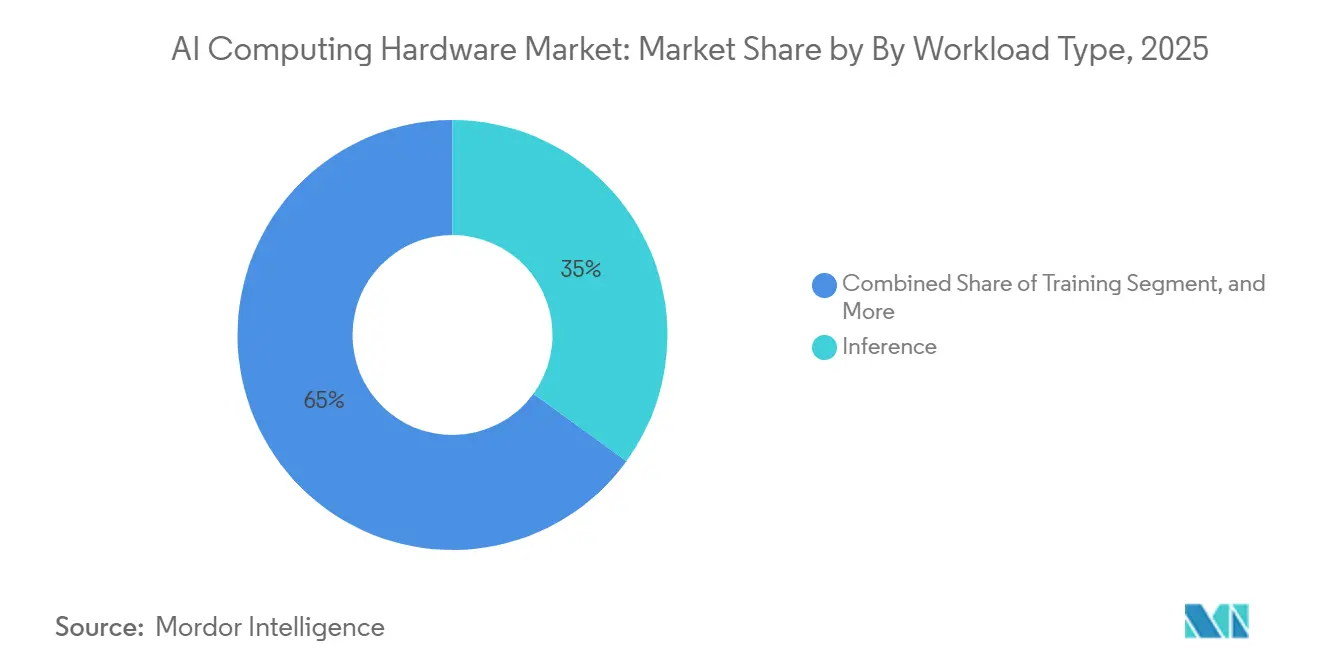
- By workload type, inference captured a 35% share in 2025 and is expected to advance at a 11.2% CAGR through 2031.
- By end-user industry, hyperscalers and cloud service providers accounted for 57.4% of spending in 2025, while healthcare and life sciences grew at a 10.9% CAGR through 2031.
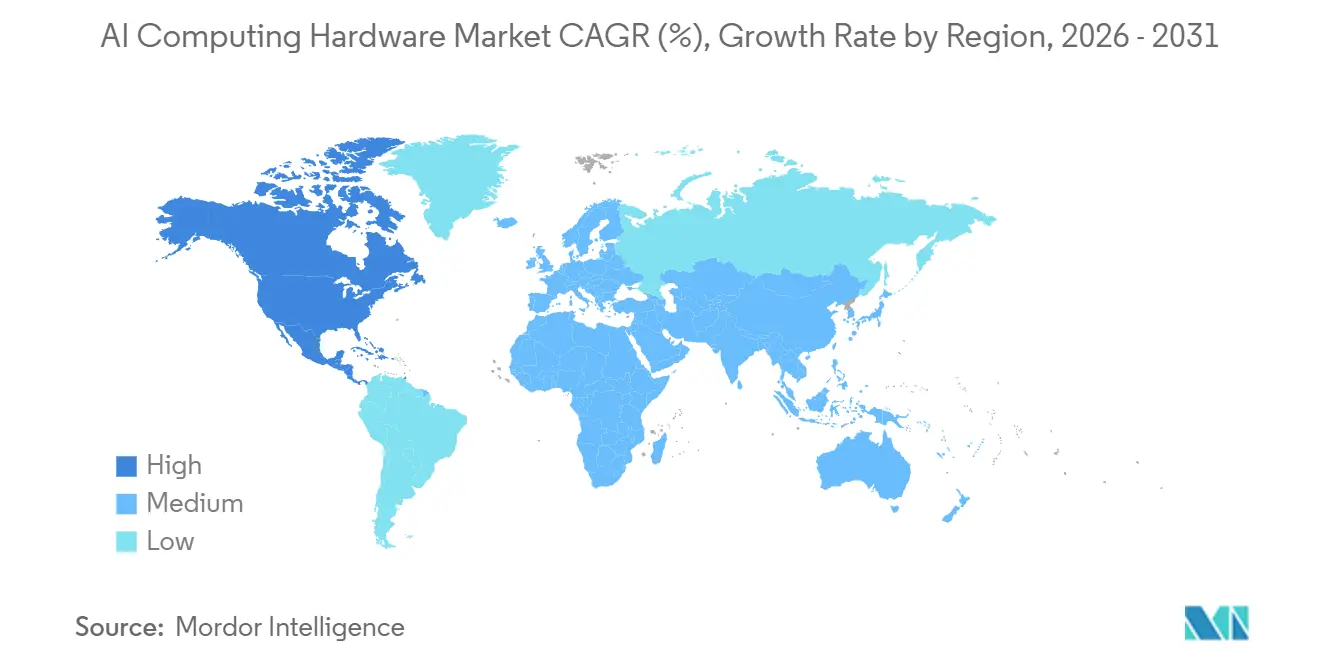
- By geography, North America accounted for a 35.7% share in 2025, and Asia-Pacific leads growth at an 11.0% CAGR through 2031.
Note: Market size and forecast figures in this report are generated using Mordor Intelligence’s proprietary estimation framework, updated with the latest available data and insights as of January 2026.
Global AI Computing Hardware Market Trends and Insights
Drivers Impact Analysis*
| Driver | (~) % Impact on CAGR Forecast | Geographic Relevance | Impact Timeline |
|---|---|---|---|
| Hyperscaler AI Infrastructure Capex Expansion | +3.2% | Global, concentrated in North America and Asia-Pacific hyperscale hubs | Medium term (2-4 years) |
| Shift From Training To Inference Increases Compute Volume | +2.8% | Global, with early gains in North America, Europe, and urban Asia-Pacific markets | Medium term (2-4 years) |
| Rapid Product Cadence In High-End AI GPUs and Rack-Scale Systems | +1.7% | Global, led by advanced semiconductor manufacturing nodes in Taiwan, South Korea | Short term (≤ 2 years) |
| Accelerated Servers Dominate AI Infrastructure Spending | +2.1% | Global, hyperscale data centers in Northern Virginia, Santa Clara, Singapore, Frankfurt | Medium term (2-4 years) |
| Co-Packaged Optics Adoption For High-Bandwidth Interconnects | +0.8% | Global, initial deployment in hyperscale AI clusters, North America and Europe lead | Long term (≥ 4 years) |
| Liquid Cooling Penetration Unlocks Higher-TDP AI Systems | +1.5% | Global, rapid adoption in China, North America, Northern Europe data center corridors | Short term (≤ 2 years) |
| Source: Mordor Intelligence | |||
Hyperscaler AI Infrastructure Capex Expansion Fuels Accelerator Demand
Hyperscaler capital programs continue to scale, with aggregate outlays crossing into the hundreds of billions for 2026 and growing year on year in the mid-thirties percent range. Momentum is centered on AI-specific infrastructure that includes servers with accelerators, high-speed networking fabrics, and liquid-cooled rack designs that sustain higher density per rack. Mega-deployments that commit to multi-gigawatt system footprints further validate the scale and durability of operator demand across training and inference use cases. Strategic alliances between platform vendors also concentrate investment in integrated solutions, including CPU platform collaborations that streamline scale-out deployments in AI clusters. Broadening adoption of liquid cooling and rack-scale assemblies reduces deployment friction by pre-integrating thermal and power subsystems for high-TDP accelerators.[2]nVent Electric plc, “nVent Unveils New Liquid Cooling and Power Portfolio at SC25,” nVent Investor Relations, investors.nvent.com The AI computing hardware market benefits from this acceleration in capital spending, as it transitions from pilot projects to scaled production footprints across multiple regions.
Inference Workload Shift Redefines Data Center Economics
The balance of compute cycles is shifting toward inference, which drives recurring consumption patterns and turns serving performance into the central design constraint for fleets. This change favors accelerators and systems tuned for cost per token, low latency, and efficient memory hierarchies, which differs from training-optimized profiles. Memory footprints and bandwidth become critical for rapid token generation, and new memory modules that shorten time to first token reinforce the value of memory-rich designs in production environments. The need to place inference closer to users also increases the attractiveness of smaller, regional deployments that balance latency and power availability without compromising reliability. Operator strategies now prioritize consistent rollouts of inference-capable capacity alongside training clusters to serve steady workloads. The AI computing hardware market reflects these priorities in both silicon roadmaps and integrated rack offerings that consolidate compute, memory, networking, and cooling.
Rapid GPU and Rack-Scale Product Cadence Compresses Refresh Cycles
Leading vendors are operating on accelerated update cycles for top-end accelerators and rack-scale systems, which compresses refresh planning to roughly annual horizons for large operators. Rack-scale platforms that integrate compute, high-bandwidth networking, and liquid cooling allow faster commissioning and offer consistent performance envelopes across facilities. Co-packaged optics is emerging in data center fabrics to reduce power per bit and improve system resiliency, and this direction is informing network design for both training and inference clusters. The cadence is supported by vertical partnerships that align CPU platforms with AI accelerators and related fabrics to simplify cluster integration.[3]Intel Newsroom, “Intel and NVIDIA to Jointly Develop AI Infrastructure and Personal Computing Products,” Intel, newsroom.intel.com As a result, operators evaluate full-stack solutions and pre-configured racks that reduce deployment complexity while supporting liquid-cooled, higher-TDP roadmaps. The AI computing hardware market therefore aligns capex cycles with rapid product introductions to maintain competitive performance and energy efficiency.
Accelerated Server Architectures Dominate AI Infrastructure Spending
Servers embedding GPUs and custom accelerators account for the lion’s share of new AI infrastructure spending as large transformer models and scale-out training require thousands of tightly networked accelerators. Pre-integrated rack systems from major vendors shorten lead times by combining compute, fabrics, and liquid cooling into uniform building blocks that can be replicated at scale. Multi-gigawatt deployment commitments by leading AI developers further reinforce that large, accelerator-rich clusters are the primary path to meet training and serving targets. At the same time, networking roadmaps that introduce co-packaged optics support the bandwidth and reliability required for all-reduce and real-time inference patterns within and across racks. The supporting ecosystem for power and cooling is responding with modular, serviceable designs that align with liquid-cooled racks exceeding 100 kilowatts per rack. As these pieces converge, the AI computing hardware market consolidates spend around accelerated servers, rack-scale architecture, and advanced interconnects.
Restraints Impact Analysis*
| Restraint | (~) % Impact on CAGR Forecast | Geographic Relevance | Impact Timeline |
|---|---|---|---|
| Power and Grid Constraints For AI Data Centers | -2.3% | Global, acute in PJM, ERCOT, Northern Virginia; emerging in Dublin, Frankfurt, Singapore | Long term (≥ 4 years) |
| Supply Constraints In HBM and Advanced Packaging | -1.9% | Global supply chain, manufacturing concentrated in South Korea (SK Hynix, Samsung), U.S. (Micron), Taiwan (TSMC CoWoS) | Medium term (2-4 years) |
| Export Controls and Tech Fragmentation | -0.7% | U.S.-China technology corridor, spillover effects in Europe, Japan, South Korea | Long term (≥ 4 years) |
| Serviceability and Ecosystem Complexity For Advanced Cooling | -0.4% | Global, most acute in retrofit scenarios for legacy facilities in Tier 1 metro data center markets | Medium term (2-4 years) |
| Source: Mordor Intelligence | |||
Power and Grid Constraints Throttle Deployment Velocity
Power availability and interconnection timelines shape where and how operators deploy AI capacity, and constraints in key metros are extending commissioning schedules for large campuses. To manage higher density and sustained load profiles, operators adopt liquid cooling and modular power architectures that align with higher-TDP accelerator roadmaps. Networking innovations such as co-packaged optics also help reduce the power penalty per bit, which indirectly eases facility-scale energy budgets at the margins. These measures do not remove siting challenges, yet they improve the performance-per-watt envelope for both training and inference clusters. The AI computing hardware market is therefore sensitive to regional grid dynamics and seeks standardization around integrated, liquid-cooled racks to ensure consistent thermal and electrical behavior. Large offtake commitments by AI platform leaders signal that long-term capacity planning is underway to mitigate grid bottlenecks through diversified siting and staged buildouts.
HBM and Advanced Packaging Supply Chain Bottlenecks Constrain Scaling
High-bandwidth memory and advanced packaging remain gating factors for accelerator shipments, and demand growth continues to pressure available capacity across near-term horizons. Memory density and bandwidth are central to inference efficiency, and new low-power modules marketed for AI servers are targeting faster time-to-first-token and improved performance per watt. Vendors are responding with design choices that balance SRAM, HBM, and interconnect topology to achieve higher throughput for token generation at predictable power budgets. Persistent tightness in packaging and memory supply guides customers toward longer-term procurement agreements and diversification strategies. As a result, the AI computing hardware market continues to calibrate system designs around memory availability while ramping new form factors that reduce service complexity in liquid-cooled deployments. Export regimes add another layer of planning complexity for cross-border sourcing of advanced accelerators and components, which increases the value of resilient local supply strategies.
*Our forecasts treat driver/restraint impacts as directional, not additive. The impact forecasts reflect baseline growth, mix effects, and variable interactions.
Segment Analysis
By Compute Silicon Type: Custom ASICs Challenge GPU Dominance Despite Inferior Ecosystems
GPU accelerators are expected to account for the largest share in 2025 at 64%, supported by mature software stacks and trained engineering talent that keep switching costs high. AI ASICs post the fastest growth at a 10.6% CAGR through 2031 as large operators prioritize per-token efficiency and tighter workload alignment for production inference. Across the AI computing hardware market, hyperscaler-designed chips reduce reliance on merchant silicon and support optimization of power, memory, and networking at rack scale. FPGAs remain relevant at the edge for deterministic latency and field reconfigurability in safety and automation settings. NPUs embedded in client devices address privacy and latency for on-device tasks within tighter thermal and power budgets. CPUs continue to anchor control-plane duties, storage orchestration, and general-purpose tasks while handing heavy matrix workloads to attached accelerators.
ASIC momentum and GPU incumbency coexist as software ecosystems, with developer familiarity and vendor toolchains continuing to influence platform decisions. Interoperability standards in fabrics and networks have become important differentiators as buyers weigh vendor lock-in against cost, availability, and performance. The AI computing hardware market is also seeing interest in emerging architectures such as neuromorphic and photonic processors, though these efforts remain nascent. For memory-intensive inference, product choices emphasize high-bandwidth memory capacity and memory bandwidth to sustain throughput. As a result, platform selection now balances peak compute against memory, networking, and thermal characteristics that are relevant to real-time serving. AI accelerators from leading vendors anchor these decisions within rack-scale blueprints that unify compute, fabric, and cooling.



By System Form Factor: Rack-Scale Integration Accelerates as Power Density Mandates Liquid Cooling
AI servers held the dominant 2025 share at 78%, and integrated rack-scale solutions record the fastest growth at a 10.7% CAGR. GPU refresh cadence, memory requirements, and thermal envelopes push operators toward pre-integrated racks that deliver predictable performance and simplify commissioning in liquid-cooled environments. In 2025 to 2026, multiple vendors advanced rack-scale platforms that consolidate accelerators, networking, and cooling into standardized building blocks to streamline capacity additions. This approach reduces integration risk while aligning with site-level electrical and mechanical constraints. Within the AI computing hardware market, rack-level architectures also improve serviceability and reduce cabling complexity relative to bespoke system combinations.
Accelerator cards and modules remain important for retrofits and incremental upgrades in facilities that have yet to migrate to high-density racks. Edge devices and gateways fill latency-sensitive roles where low power budgets and compact footprints are essential. The AI computing hardware market benefits from vendor ecosystems that include reference designs, validated fabrics, and cooling solutions tuned to rack-level operation. As these platforms mature, purchasers value interoperability and standards participation that protect long-lived deployments. Vendors are pairing silicon roadmaps with liquid cooling and fabric strategies to ensure predictable performance across product generations. Co-packaged optics will play a growing role in top-of-rack and spine layers as data rates increase and operators focus on power per bit.
By Deployment Location: Inference Migration to Edge Fragments Centralized Training Footprint
Cloud data centers account for a 44% share in 2025 as training and large inference clusters favor purpose-built sites with high power density and advanced networking. Edge and endpoint sites grow fastest at a 10.9% CAGR to 2031 as latency-sensitive inference moves closer to users in regional metros. In the AI computing hardware market, this distribution ensures low-latency serving for applications that require rapid token generation and local data handling. Operators pair centralized training footprints with distributed inference capacity to meet both development and production requirements. On-premises enterprise deployments support regulated workloads and data sovereignty mandates.
Legacy facilities continue to retrofit power and cooling to accommodate higher-density racks while new builds favor liquid-cooled designs from day one. The AI computing hardware industry is converging on rack-scale products that balance heat density, serviceability, and interoperable fabrics. Procurement now includes longer planning horizons for power and interconnection alongside multi-year arrangements for accelerators and memory. Strategic partnerships across vendors aim to reduce integration friction and align CPU, accelerator, and networking roadmaps. The AI compute hardware market therefore distributes capacity across core cloud hubs and edge sites while aligning facility design with serving and training roles.
By Workload Type: Inference Dominance Reshapes Hardware Requirements Toward Cost per Query
Inference holds a 35% workload share in 2025 and grows at an 11.2% CAGR, reflecting the continuous nature of serving workloads after initial model training. This reality drives design choices that value cost per token, throughput per watt, and time to first token. Memory density is a differentiator for hosting large-context models in fewer devices, and component vendors are introducing low-power modules that accelerate token generation. The AI computing hardware market therefore balances peak compute with memory and fabric choices that sustain steady serving loads. Training remains centered in large sites with high power availability and bisection bandwidth needs.
Serving deployments favor regional locations that reduce latency and improve user experience for real-time applications. Operators standardize on rack-scale assemblies to simplify rollout and reduce commissioning risk across geographies. Networking upgrades, including co-packaged optics, improve resilience and power efficiency at higher link speeds. The AI computing hardware market gains from these improvements through consistent scaling paths from development to production.
By End-User Industry: Healthcare Surges as On-Premises Compliance Drives Accelerator Proliferation
Hyperscalers and cloud service providers account for 57.4% of 2025 spending as platform services aggregate demand for training and inference. Healthcare and life sciences post a 10.9% CAGR through 2031 thanks to diagnostic imaging, clinical decision support, and discovery workloads that prefer high-throughput, compliant, and frequently on-premises deployments. The AI computing hardware market supplies accelerators and rack systems that meet certification and uptime needs in regulated settings. Financial services, technology platforms, and media are expanding the use of inference in fraud prevention, recommendations, and code generation. Automotive and manufacturing integrate AI across edge workloads for safety and inspection.
In industries with strict data residency, on-premises clusters or sovereign-cloud models remain important purchasing paths. The AI computing hardware market supports both cloud-based access to advanced accelerators and on-premises configurations aligned with privacy and governance policies. Vendor ecosystems help enterprises navigate software portability and model deployment across sites. Buyer preferences now reflect a mix of hyperscale consumption for frontier models and localized inference for real-time tasks. As a result, verticals adopt combinations of cloud training and distributed serving that fit specific compliance and latency requirements.
Geography Analysis
North America accounts for a 35.7% revenue share in 2025 as global hyperscalers concentrate headquarters, platform engineering, and advanced design partnerships in the region. Asia-Pacific posts the fastest expansion at an 11.0% CAGR through 2031 as sovereign cloud initiatives and regional digital services increase local compute footprints. Within the AI computing hardware market, North American growth is tempered by power and interconnection constraints in several Tier 1 metros, prompting diversification to adjacent markets. Europe balances data residency and power availability, and operators distribute deployments across regions that can provide land, grid capacity, and renewable sourcing. The Middle East continues to invest in large-scale AI infrastructure that complements Western technology stacks.
Export controls shape sourcing and deployment decisions along the U.S.-China corridor, which introduces planning complexity for cross-border capacity allocation and chip availability. Operators respond by staging multi-region builds and by pursuing longer-term procurement commitments for accelerators and components. In Asia-Pacific, growing demand for regional model serving reinforces investments in edge sites that balance latency and power access. The AI computing hardware market therefore expands through a distributed footprint that segments training and serving across facility classes. Partnerships that secure large system deployments illustrate the region-wide scale of future buildouts across training and inference. In aggregate, regional strategies converge on liquid-cooled rack-scale systems and high-speed fabrics to sustain rapid growth.

Competitive Landscape
The AI computing hardware market has moderate consolidation, with one vendor holding near 70% share of AI accelerators through 2025 and others gaining through custom silicon programs and open ecosystem positioning. NVIDIA sustains incumbency with a full-stack approach that couples GPUs, fabrics, and software, which creates switching costs for enterprises and developers. AMD is advancing an open, interoperable approach across scale-up and scale-out fabrics and is pairing this with a rack-scale platform that integrates liquid cooling and networking as a pre-configured building block. Intel and NVIDIA announced a strategic collaboration on custom x86 CPUs integrated with NVIDIA AI platforms, which aligns CPU and accelerator roadmaps for data center deployments. These moves align with the market’s shift toward packaged rack solutions and integrated fabrics.
Liquid cooling suppliers and power distribution vendors have become central to system performance, serviceability, and uptime. New coolant distribution units, manifolds, and intelligent power distribution units are being introduced as modular offerings that scale with higher-TDP accelerators and rack densities. Partnerships between cooling and industrial technology firms aim to deliver reference architectures for hyperscale AI sites, which reduces design risk and deployment time for operators. On the networking side, the adoption of co-packaged optics reduces power per bit and improves fabric robustness, which positions CPO as a critical enabler of future AI fabrics. The computing hardware market therefore reflects tighter integration across compute, cooling, and networking vendors.
Scale commitments by leading AI developers are also reshaping supply alignment. Multi-gigawatt partnerships are setting new baselines for system deployment footprints and for how vendors coordinate CPU platforms, accelerators, interconnects, and power delivery at rack scale. In response, chipmakers are aligning silicon roadmaps with system blueprints that emphasize liquid cooling, high memory capacity, and fast fabrics. Open software stacks and standards-based fabrics remain a lever for buyers that want to avoid high switching costs and long-term lock-in. The AI computing hardware market continues to balance vendor incumbency with rising demand for interoperable and serviceable rack-scale systems that simplify deployment across diverse geographies.
AI Computing Hardware Industry Leaders
NVIDIA Corporation
Intel Corporation
Huawei Technologies Co., Ltd.
International Business Machines Corporation
Dell Technologies Inc.
- *Disclaimer: Major Players sorted in no particular order

Recent Industry Developments
- January 2026: AMD expanded its AI portfolio at CES 2026 with Ryzen AI 400 Series processors and introduced the Ryzen AI Halo Developer Platform, a mini-PC designed for local large-model development and inference.
- October 2025: AMD introduced the Helios rack-scale AI platform at the OCP 2025 Summit, built on Open Rack Wide specifications and centered on upcoming Instinct accelerators, with an emphasis on open interoperability for hyperscale AI.
- October 2025: Micron announced sampling of its 192 GB SOCAMM2 LPDDR5X module for AI data centers, citing improved time to first token for real-time inference and serviceability gains for liquid-cooled servers.
- September 2025: Intel and NVIDIA announced a partnership to co-develop AI infrastructure and personal computing products, including NVIDIA-custom x86 CPUs integrated via NVLink and PC SoCs with NVIDIA GPU chiplets.


Global AI Computing Hardware Market Report Scope
AI computing hardware is a class of microprocessors or microchips designed to enable the faster processing of AI applications. The study on the market encompasses stand-alone vision processors and embedded sound processors, among others, offered by various players to different end-users, including BFSI, automotive, IT, and telecom.
The AI computing Hardware Market Report is Segmented by Compute Silicon Type (GPU Accelerators, AI ASICs, FPGAs, CPUs, NPUs (Edge), Other Compute Silicon Types), System Form Factor (AI Servers, Accelerator Cards and Modules (PCIe, OAM, SXM), Integrated Systems and Appliances, Edge Devices and Gateways, Other System Form Factors), Deployment Location (Cloud Data Centers, Enterprise and On-Premises Data Centers, Edge and Endpoint, Other Deployment Locations), Workload Type (Training, Inference, Other Workload Types), End-user Industry (Hyperscalers and Cloud Service Providers, Technology and Internet Companies, Financial Services, Healthcare and Life Sciences, Automotive and Manufacturing, Telecommunications, Retail and Consumer, Public Sector, Other End-user Industries), and Geography (North America (United States, Canada, Mexico), South America (Brazil, Argentina, Chile, Rest of South America), Europe (Germany, United Kingdom, France, Italy, Spain, Netherlands, Russia, Rest of Europe), Asia-Pacific (China, Japan, South Korea, India, Australia, Singapore, Taiwan, Rest of Asia-Pacific), Middle East (United Arab Emirates, Saudi Arabia, Turkey, Israel, Rest of Middle East), Africa (South Africa, Egypt, Nigeria, Rest of Africa)). The Market Forecasts are Provided in Terms of Value (USD).
| GPU Accelerators |
| AI ASICs |
| FPGAs |
| CPUs |
| NPUs (Edge) |
| Other Compute Silicon Types |
| AI Servers |
| Accelerator Cards and Modules (PCIe, OAM, SXM) |
| Integrated Systems and Appliances |
| Edge Devices and Gateways |
| Other System Form Factors |
| Cloud Data Centers |
| Enterprise and On-Premises Data Centers |
| Edge and Endpoint |
| Other Deployment Locations |
| Training |
| Inference |
| Other Workload Types |
| Hyperscalers and Cloud Service Providers |
| Technology and Internet Companies |
| Financial Services |
| Healthcare and Life Sciences |
| Automotive and Manufacturing |
| Telecommunications |
| Retail and Consumer |
| Public Sector |
| Other End-user Industries |
| North America | United States |
| Canada | |
| Mexico | |
| South America | Brazil |
| Argentina | |
| Chile | |
| Rest of South America | |
| Europe | Germany |
| United Kingdom | |
| France | |
| Italy | |
| Spain | |
| Netherlands | |
| Russia | |
| Rest of Europe | |
| Asia-Pacific | China |
| Japan | |
| South Korea | |
| India | |
| Australia | |
| Singapore | |
| Taiwan | |
| Rest of Asia-Pacific | |
| Middle East | United Arab Emirates |
| Saudi Arabia | |
| Turkey | |
| Israel | |
| Rest of Middle East | |
| Africa | South Africa |
| Egypt | |
| Nigeria | |
| Rest of Africa |
| By Compute Silicon Type | GPU Accelerators | |
| AI ASICs | ||
| FPGAs | ||
| CPUs | ||
| NPUs (Edge) | ||
| Other Compute Silicon Types | ||
| By System Form Factor | AI Servers | |
| Accelerator Cards and Modules (PCIe, OAM, SXM) | ||
| Integrated Systems and Appliances | ||
| Edge Devices and Gateways | ||
| Other System Form Factors | ||
| By Deployment Location | Cloud Data Centers | |
| Enterprise and On-Premises Data Centers | ||
| Edge and Endpoint | ||
| Other Deployment Locations | ||
| By Workload Type | Training | |
| Inference | ||
| Other Workload Types | ||
| By End-user Industry | Hyperscalers and Cloud Service Providers | |
| Technology and Internet Companies | ||
| Financial Services | ||
| Healthcare and Life Sciences | ||
| Automotive and Manufacturing | ||
| Telecommunications | ||
| Retail and Consumer | ||
| Public Sector | ||
| Other End-user Industries | ||
| By Geography | North America | United States |
| Canada | ||
| Mexico | ||
| South America | Brazil | |
| Argentina | ||
| Chile | ||
| Rest of South America | ||
| Europe | Germany | |
| United Kingdom | ||
| France | ||
| Italy | ||
| Spain | ||
| Netherlands | ||
| Russia | ||
| Rest of Europe | ||
| Asia-Pacific | China | |
| Japan | ||
| South Korea | ||
| India | ||
| Australia | ||
| Singapore | ||
| Taiwan | ||
| Rest of Asia-Pacific | ||
| Middle East | United Arab Emirates | |
| Saudi Arabia | ||
| Turkey | ||
| Israel | ||
| Rest of Middle East | ||
| Africa | South Africa | |
| Egypt | ||
| Nigeria | ||
| Rest of Africa | ||


Key Questions Answered in the Report
What is the current size and growth outlook for the AI computing hardware market by 2031?
The category stands at USD 47.43 billion in 2026 and is projected to reach USD 77.55 billion by 2031 at a 10.3% CAGR.
Which compute silicon type leads in the AI computing hardware market and which grows the fastest?
GPU accelerators lead with a 64% share in 2025, while AI ASICs are the fastest-growing at a 10.6% CAGR through 2031.
Which deployment locations will expand fastest for AI computing hardware through 2031?
Edge and endpoint sites rise at a 10.9% CAGR as latency-sensitive inference moves closer to users, while cloud data centers remain the largest base at a 44% share in 2025.
What is the primary workload shaping system design in the AI computing hardware market?
Inference is central, with a 35% share in 2025 and an 11.2% CAGR, which shifts design priorities toward cost per token, memory capacity, and power efficiency.
Which end-user segments are driving demand for AI computing hardware in 2025?
Hyperscalers and cloud service providers command 57.4% of 2025 spending, and healthcare and life sciences are the fastest-growing at a 10.9% CAGR.
Which region leads and which region grows fastest in AI computing hardware?
North America leads with a 35.7% share in 2025, and Asia-Pacific grows fastest at an 11.0% CAGR through 2031.
Page last updated on:






