Taille et parts du marché du traitement automatique du langage naturel
VUE D’ENSEMBLE DU MARCHÉ
| Période d'étude | 2020 - 2031 |
|---|---|
| Taille du Marché (2026) | 47.37 Milliards de dollars |
| Taille du Marché (2031) | 117.57 Milliards de dollars |
| Taux de croissance (2026 - 2031) | 19.94% CAGR |
| Marché à la Croissance la Plus Rapide | Asie-Pacifique |
| Plus Grand Marché | Amérique du Nord |
| Concentration du Marché | Moyen |
Acteurs majeurs *Avis de non-responsabilité : les principaux acteurs sont triés sans ordre particulier Image © Mordor Intelligence. La réutilisation nécessite une attribution sous CC BY 4.0. | |
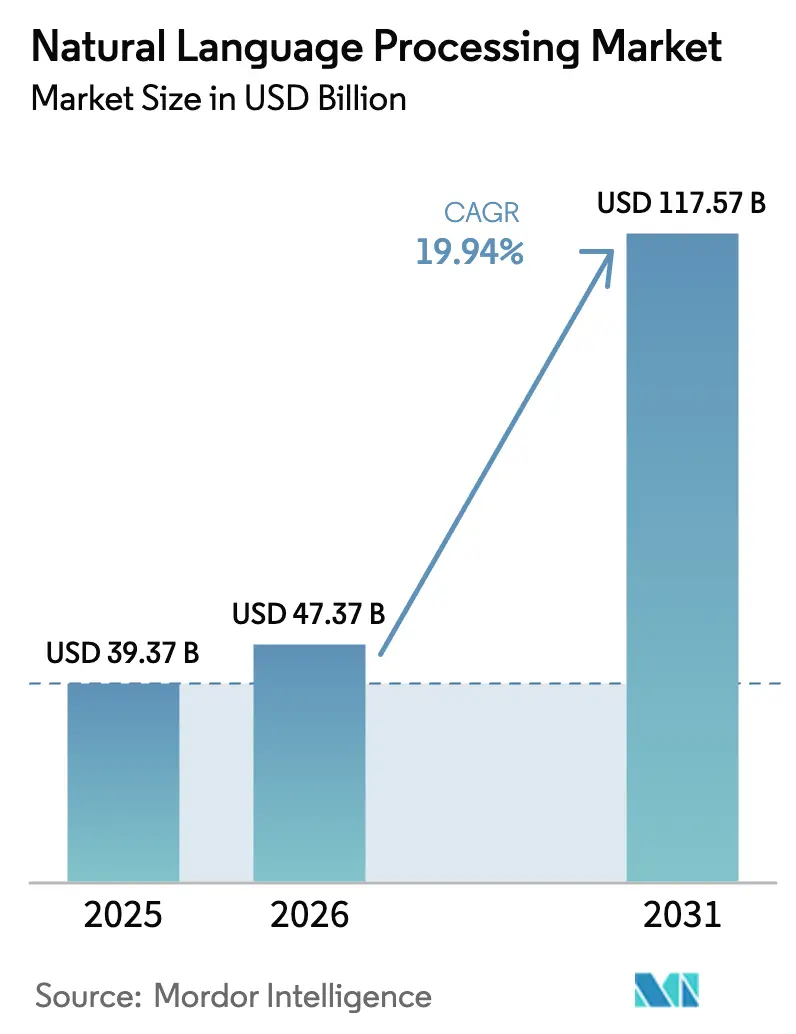
Analyse du marché du traitement automatique du langage naturel par Mordor Intelligence
La taille du marché du traitement automatique du langage naturel devrait s'étendre de 39,37 milliards USD en 2025 et 47,37 milliards USD en 2026 à 117,57 milliards USD d'ici 2031, enregistrant un TCAC de 19,94 % entre 2026 et 2031. Cette progression est ancrée dans les améliorations des transformeurs qui augmentent la précision spécifique au domaine de plusieurs dizaines de points de pourcentage, les synergies cloud-périphérie qui réduisent la latence d'inférence en dessous de 100 millisecondes, et la clarté réglementaire qui oriente les budgets des preuves de concept vers la production complète. Les acheteurs en entreprise considèrent désormais les modèles de fondation comme une infrastructure essentielle plutôt que comme des compléments expérimentaux, réaffectant les budgets analytiques vers les outils d'intégration, l'audit des biais et les options de calcul neutres en carbone. La concurrence entre fournisseurs se concentre sur la réduction du coût par jeton, la pré-certification des modules à haut risque pour la loi européenne sur l'IA, et la conquête des segments de langues à faibles ressources qui restent mal desservis par les systèmes centrés sur l'anglais. Les flux de capitaux reflètent ces priorités, les hyperscalers orientant l'approvisionnement en GPU vers des plateformes gérées tandis que les leaders de l'automobile et de la santé financent des projets d'inférence en périphérie pour garantir une latence déterministe.
Points clés du rapport
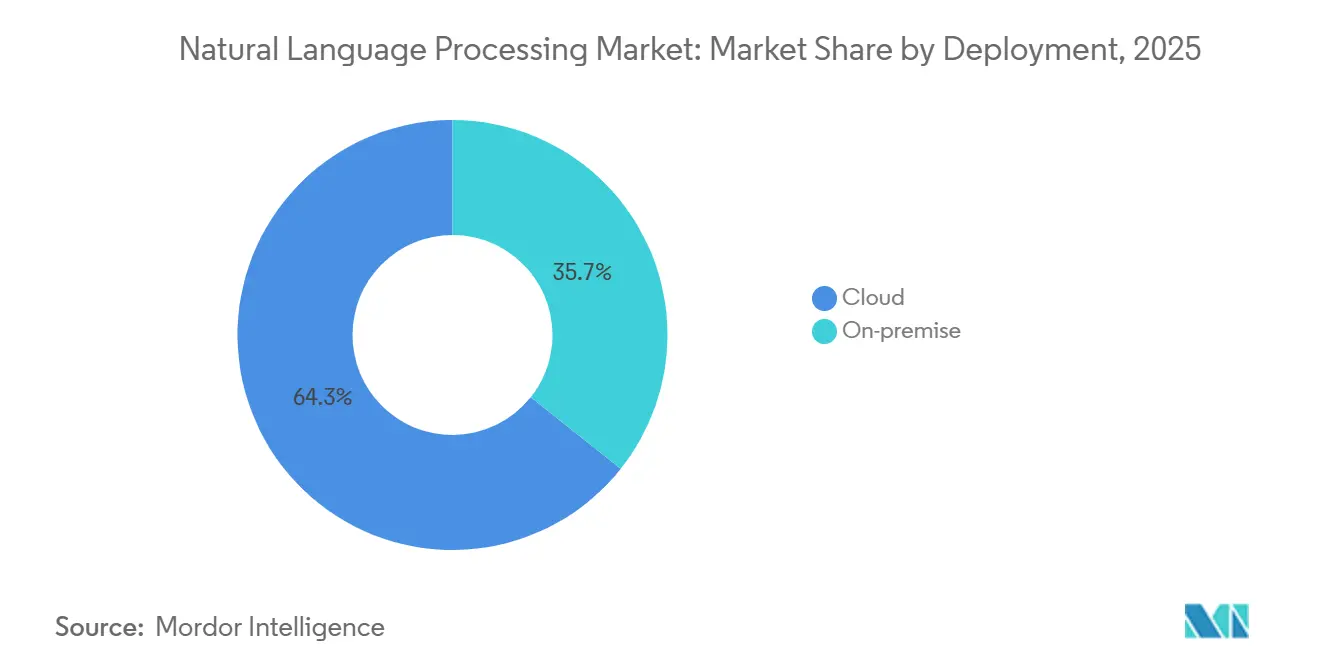
- Par déploiement, le cloud a capturé 64,31 % des parts du marché du traitement automatique du langage naturel en 2025, tandis que les services ont enregistré le TCAC projeté le plus rapide à 22,62 % jusqu'en 2031.
- Par taille d'organisation, les grandes entreprises détenaient 73,13 % du marché du traitement automatique du langage naturel en 2025, tandis que les petites et moyennes entreprises devraient se développer à un TCAC de 19,98 % jusqu'en 2031.
- Par composant, le logiciel représentait 46,14 % de la taille du marché du traitement automatique du langage naturel en 2025, mais les services progressent à un TCAC de 22,62 % jusqu'en 2031.
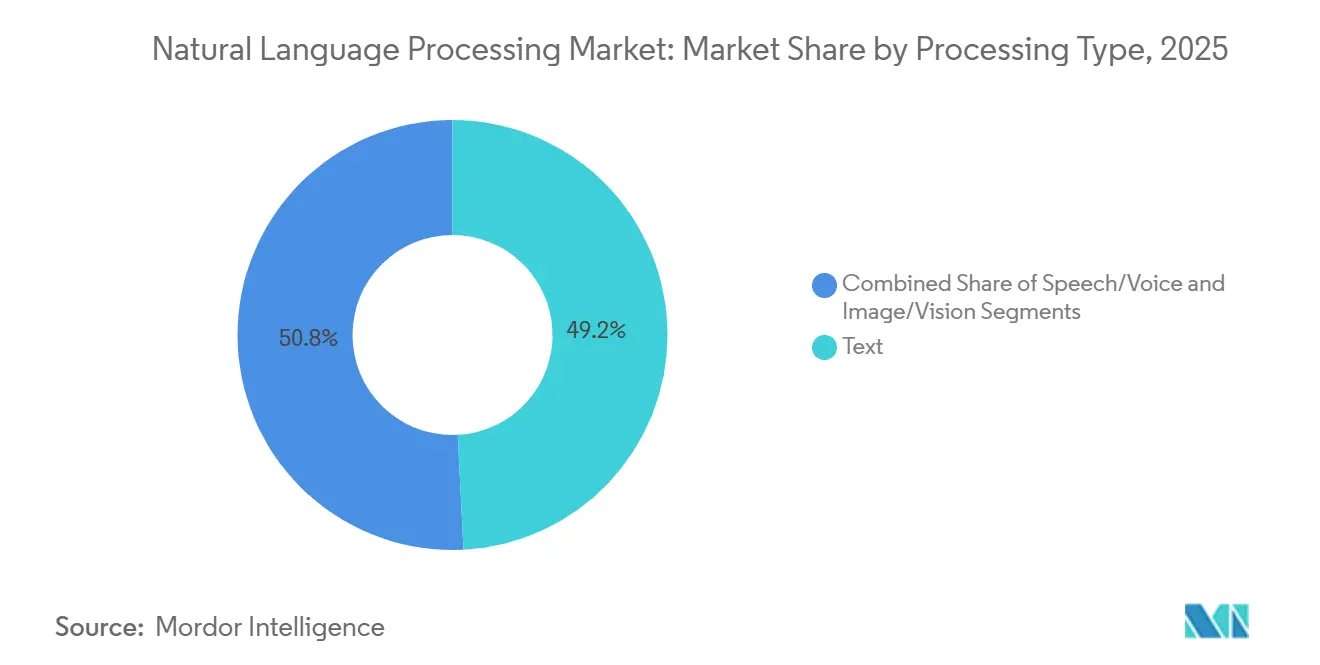
- Par type de traitement, le traitement de texte était en tête avec 49,18 % de parts en 2025 et la reconnaissance vocale devrait afficher un TCAC de 22,41 % entre 2026 et 2031.
- Par secteur d'utilisation final, le BFSI représentait 20,13 % de la taille du marché du traitement automatique du langage naturel en 2025, tandis que la santé et les sciences de la vie affichent la trajectoire de croissance la plus élevée à un TCAC de 24,84 % jusqu'en 2031.
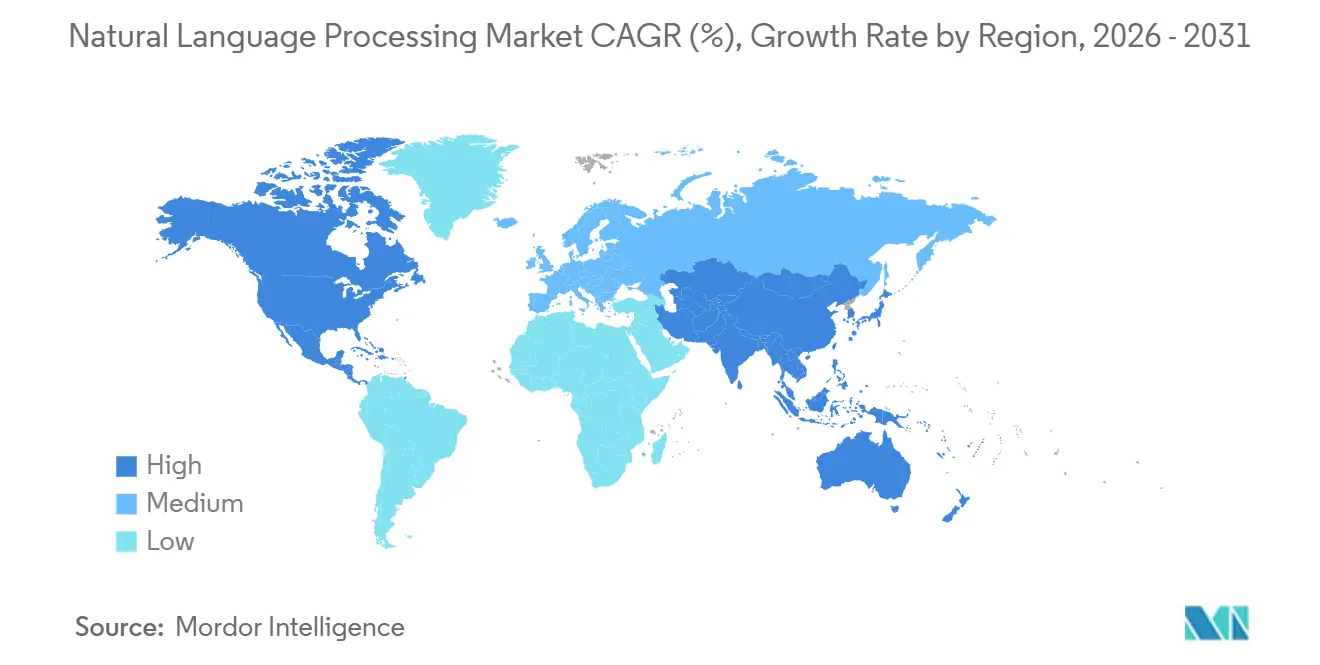
- Par géographie, l'Amérique du Nord a conservé 37,92 % des parts en 2025 et l'Asie-Pacifique est positionnée pour la progression la plus rapide à un TCAC de 22,13 % jusqu'en 2031.
Note : La taille du marché et les prévisions figurant dans ce rapport sont générées à l'aide du cadre d'estimation exclusif de Mordor Intelligence, mis à jour avec les dernières données et informations disponibles en janvier 2026.
Tendances et perspectives mondiales du marché du traitement automatique du langage naturel
Analyse de l'impact des moteurs*
| Moteur | (~) % d'impact sur les prévisions de TCAC | Pertinence géographique | Horizon temporel de l'impact |
|---|---|---|---|
| Gains de précision des modèles alimentés par l'IA générative | +4.5% | Mondial, concentré en Amérique du Nord et en Asie-Pacifique | Moyen terme (2 à 4 ans) |
| Essor de l'adoption de l'IA conversationnelle dans le service client | +3.8% | Mondial, porté par l'Amérique du Nord et l'Europe, en expansion vers l'Asie-Pacifique | Court terme (≤ 2 ans) |
| Intégration du traitement automatique du langage naturel dans les appareils embarqués ou en périphérie | +3.2% | Cœur en Asie-Pacifique, débordement vers l'Amérique du Nord et l'Europe | Moyen terme (2 à 4 ans) |
| Prolifération des grands modèles de langage spécifiques aux domaines pour les secteurs réglementés | +2.9% | Amérique du Nord et Europe, adoption progressive en Asie-Pacifique | Long terme (≥ 4 ans) |
| Demande croissante de reconnaissance vocale en temps réel dans l'automobile et les appareils intelligents | +2.4% | Mondial, leadership précoce en Amérique du Nord, en Europe et en Chine | Moyen terme (2 à 4 ans) |
| Modèles de fondation multimodaux ouvrant de nouveaux secteurs verticaux | +2.1% | Mondial, concentré dans les pôles technologiques d'Amérique du Nord et d'Asie-Pacifique | Long terme (≥ 4 ans) |
| Source: Mordor Intelligence | |||
Gains de précision des modèles alimentés par l'IA générative
Les versions de fondation en 2025 ont affiché des bonds de 18 à 23 points de pourcentage sur des benchmarks spécialisés lors d'un affinage sur moins de 10 000 étiquettes, réduisant considérablement les budgets d'annotation et ouvrant des flux de travail à haute responsabilité tels que l'extraction de clauses juridiques et le codage CIM-10.[1]Nature Staff, "Les grands modèles de langage encodent les connaissances cliniques," Nature, nature.com Gemini 2.0 Flash de Google a réduit la latence d'inférence de 40 %, permettant des tâches de conversation et de résumé qui nécessitaient autrefois un traitement par lots. Le routage par mélange d'experts ne maintient actifs que 10 à 15 % d'un billion de paramètres par requête, réduisant la consommation d'énergie sans nuire à la précision. Le modèle o3 d'OpenAI a enregistré 87,5 % sur ARC-AGI, signalant que le raisonnement en plusieurs étapes entre dans le champ de l'automatisation. Ensemble, ces avancées ont alimenté la confiance au niveau des conseils d'administration que le marché du traitement automatique du langage naturel peut soutenir des opérations critiques.
Essor de l'adoption de l'IA conversationnelle dans le service client
Une inflation salariale de 12 à 18 % pour les agents de premier niveau a poussé les centres de contact vers l'automatisation, et la génération augmentée par récupération a porté la résolution au premier contact à 75-85 % à mi-2025.[2]Équipe de presse Salesforce, "Agentforce 2.0 : Agents autonomes pour chaque entreprise," salesforce.com Agentforce 2.0 de Salesforce orchestre les flux CRM, de facturation et d'inventaire sans transferts, réduisant le temps de traitement moyen jusqu'à 40 %. Les plateformes cloud ont intégré les API de chat dans les contrats d'entreprise existants, réduisant les cycles pilotes de plusieurs trimestres à quelques semaines. La loi européenne sur l'IA a classé la plupart des robots de service client comme à risque limité, les dispensant d'examens de conformité et accélérant l'adoption dans l'ensemble du bloc commercial.[3]Commission européenne, "Cadre réglementaire sur l'intelligence artificielle," digital-strategy.ec.europa.eu
Intégration du traitement automatique du langage naturel dans les appareils embarqués ou en périphérie
Les puces de smartphones intégrant des unités neuronales exécutent désormais localement des modèles à 7 milliards de paramètres, supprimant les 200 à 500 millisecondes de latence aller-retour liées aux appels cloud et apaisant les craintes en matière de confidentialité. L'Intelligence d'Apple traite 80 % des requêtes Siri sur l'appareil, un changement qui s'aligne sur les règles strictes de localisation des données en Chine et en Inde. Mercedes-Benz a intégré un modèle de domaine précis à 95 % dans son cockpit MBUX, démontrant que l'inférence en périphérie peut satisfaire les besoins automobiles en temps réel sans connectivité. Le marché du traitement automatique du langage naturel s'oriente par conséquent vers des boîtes à outils sur appareil qui garantissent des temps de réponse déterministes et la conformité aux mandats de résidence des données.
Prolifération des grands modèles de langage spécifiques aux domaines pour les secteurs réglementés
Les modèles verticaux affinés sur des corpus sélectionnés ont surpassé leurs homologues génériques de 12 à 18 points, justifiant des dépenses de formation 3 à 5 fois plus élevées dans les secteurs où une mauvaise classification entraîne des amendes. Le DAX Copilot de Nuance a traité plus d'un million de consultations cliniques, réduisant de moitié les tâches de documentation et atténuant l'épuisement professionnel. Les banques ont adopté des modèles entraînés sur des dépôts réglementaires pour réduire les faux positifs dans la lutte contre le blanchiment d'argent de 95 % à moins de 70 %. La loi européenne sur l'IA exige l'explicabilité pour la notation de crédit, incitant les fournisseurs à adopter des architectures transparentes et des chaînes d'outils certifiées.
Analyse de l'impact des freins*
| Frein | (~) % d'impact sur les prévisions de TCAC | Pertinence géographique | Horizon temporel de l'impact |
|---|---|---|---|
| Pénurie de données d'entraînement de haute qualité et sans biais | -1.8% | Mondial, aigu dans les langues non anglophones et à faibles ressources | Court terme (≤ 2 ans) |
| Escalade des coûts d'inférence pour les grands modèles | -1.5% | Mondial, plus prononcé en Amérique du Nord et en Europe | Moyen terme (2 à 4 ans) |
| Obstacles à la conformité transfrontalière en matière de résidence des données | -1.2% | Mondial, concentré en Europe, en Chine et en Inde | Long terme (≥ 4 ans) |
| Empreinte environnementale du calcul d'entraînement à grande échelle | -0.9% | Mondial, pression réglementaire la plus forte en Europe | Long terme (≥ 4 ans) |
| Source: Mordor Intelligence | |||
Pénurie de données d'entraînement de haute qualité et sans biais
Les audits ont montré que 70 à 80 % des corpus restent en anglais, entraînant des baisses de 15 à 25 points dans d'autres langues et exposant les entreprises à des risques de conformité dans les régions multilingues. Les générateurs synthétiques comblent les lacunes mais risquent un effondrement de mode après des affinages répétés. Les dossiers de santé sont cloisonnés derrière la loi HIPAA, tandis que la norme PCI-DSS verrouille les journaux de transactions, fragmentant les pools d'entraînement. Sans tests de biais standardisés, les entreprises inventent des audits sur mesure qui ralentissent les achats. Ce frein pèse lourdement sur les marchés nationaux cherchant une autonomie souveraine en matière d'IA.
Escalade des coûts d'inférence pour les grands modèles
Faire fonctionner des systèmes à 100 milliards de paramètres avec une latence inférieure à la seconde nécessite 8 à 16 GPU par instance, portant les factures de calcul jusqu'à 100 000 USD par mois pour 1 million d'utilisateurs quotidiens. La quantification et l'élagage réduisent de moitié les paramètres mais diminuent la précision de plusieurs points, une perte que de nombreux gestionnaires de risques rejettent. Des chaînes d'outils telles que NVIDIA TensorRT-LLM triplent le débit, mais des courbes d'apprentissage abruptes retardent le déploiement. La tarification cloud par paliers ajoute de la volatilité lors des pics de trafic. Ce vent contraire des coûts oblige les équipes produit à peser la qualité par rapport à la marge, freinant le marché du traitement automatique du langage naturel dans les applications sensibles aux prix.
*Nos prévisions considèrent les impacts des moteurs et des contraintes comme directionnels et non additifs. Les prévisions d'impact reflètent la croissance de référence, les effets de composition et les interactions entre variables.
Analyse des segments
Par déploiement : la domination du cloud masque l'élan de la périphérie
Le cloud a conservé 64,31 % des parts du marché du traitement automatique du langage naturel en 2025, les entreprises privilégiant la mise à l'échelle élastique et les services d'IA groupés. D'ici 2031, le segment croît à 20,01 % alors que les hyperscalers fidélisent les charges de travail en intégrant des modèles propriétaires dans des contrats plus larges. Les clusters sur site persistent dans les banques et les hôpitaux qui doivent auditer chaque flux de données, même lorsque ce choix augmente les coûts jusqu'à 50 %. AWS Bedrock et les enclaves confidentielles Azure brouillent désormais la frontière, permettant aux clients de conserver les charges utiles sensibles dans des clouds privés virtuels tout en s'appuyant sur une orchestration gérée.
L'adoption en périphérie progresse rapidement alors que la pénétration des smartphones dépasse 70 % en Asie-Pacifique et que les constructeurs automobiles exigent un contrôle vocal déterministe. L'AI Edge SDK de Google compresse Gemini Nano à moins de 2 Go, prouvant que le traitement automatique du langage naturel de haute qualité peut fonctionner sur des appareils de milieu de gamme. Mercedes-Benz et BMW affichent des gains de 20 points dans la précision de l'intention vocale après la localisation de l'inférence. Le traitement des données sur l'appareil satisfait la loi chinoise sur la protection des informations personnelles sans modification architecturale, et des dynamiques similaires se jouent sous la loi indienne sur la protection des données personnelles numériques. Cette évolution à double trajectoire signifie que le marché du traitement automatique du langage naturel valorise désormais la parité cloud et périphérie plutôt que la suprématie d'un seul lieu.


Par taille d'organisation : les PME comblent l'écart
Les grandes entreprises détenaient 73,13 % des parts du marché du traitement automatique du langage naturel en 2025, tirant parti de pétaoctets de données et d'équipes MLOps dédiées. Pourtant, les PME devraient les dépasser à un TCAC de 19,98 % grâce aux agents sans code et aux modèles à paiement par jeton qui éliminent les barrières en capital. Les hubs Hugging Face et la tarification cloud basée sur la consommation font passer les coûts d'expérimentation en dessous de 20 000 USD, abordables même pour les startups en phase d'amorçage. Des cycles de décision rapides permettent aux PME de piloter des robots de commerce vocal ou des analyseurs de contrats en quelques semaines, devançant souvent les acteurs établis lents sur les opportunités de niche.
Les grandes entreprises conservent un avantage dans les intégrations multi-systèmes qui exploitent simultanément les flux ERP, CRM et chaîne d'approvisionnement. Elles supportent également des audits plus lourds au titre de la loi européenne sur l'IA qui peuvent prolonger le déploiement jusqu'à un an, une charge que les plus petites entreprises évitent lorsque leurs cas d'usage relèvent de classifications à risque limité. Sur l'horizon de prévision, une convergence est probable, les outils matures effaçant les écarts techniques et obligeant les deux cohortes à se différencier sur la profondeur d'intégration des flux de travail plutôt que sur la puissance de calcul brute.
Par composant : les services progressent rapidement à mesure que la complexité d'intégration s'intensifie
Le logiciel a capturé 46,14 % des dépenses du marché du traitement automatique du langage naturel en 2025 grâce à la concession de licences de modèles de fondation et de plateformes d'affinage. Pourtant, les services, dont la croissance annuelle est prévue à 22,62 %, deviennent le poste budgétaire à la croissance la plus rapide alors que les entreprises font face à la dérive des modèles, à la surveillance des biais et aux audits de conformité européens. Accenture, Deloitte et PwC regroupent désormais la sélection des fournisseurs, la construction des pipelines de données et le support MLOps sur 24 mois dans des forfaits à prix fixe dépassant 5 millions USD pour les déploiements Fortune 500.
Le matériel reste essentiel, les GPU NVIDIA conservant plus de 80 % des puces d'entraînement expédiées, mais leur part diminue légèrement à mesure que les ASIC personnalisés des hyperscalers trouvent leur place dans les charges de travail d'inférence. La taille du marché du traitement automatique du langage naturel pour les services dépassera probablement le matériel d'ici 2028, marquant un pivot des dépenses d'investissement vers les dépenses d'exploitation à mesure que la complexité supplante la rareté du silicium brut.
Par type de traitement : la reconnaissance vocale gagne du terrain
Le traitement de texte a maintenu 49,18 % des parts en 2025 grâce à des outils matures d'exploration de documents et d'analyse des sentiments. La reconnaissance vocale, cependant, est en voie d'atteindre un TCAC de 22,41 % car la transcription en temps réel débloque la documentation clinique ambiante et les assistants vocaux embarqués dans les véhicules. L'intelligence ambiante dans les cliniques supprime 40 à 50 % des minutes de paperasserie par consultation, un soulagement face aux pénuries de médecins. Les équipementiers automobiles déploient des assistants entièrement hors ligne, éliminant les zones blanches de couverture et les préoccupations en matière de confidentialité.
Les modèles multimodaux tels que GPT-4V relient les images au texte, élargissant la portée à la recherche de produits en commerce de détail ou à l'interprétation de radiographies. À mesure que les modules de vision arrivent à maturité, le marché du traitement automatique du langage naturel évolue vers une arène multimodale où les claviers rivalisent avec les caméras et les microphones pour la saisie de données.
Note: Les parts de segments de tous les segments individuels sont disponibles à l'achat du rapport
Par secteur d'utilisation final : la santé mène la courbe d'adoption
La santé et les sciences de la vie progressent à un TCAC de 24,84 % jusqu'en 2031, portées par la prise de notes ambiante, l'automatisation du codage et l'exploration de la littérature pour la découverte de médicaments. Le DAX Copilot de Nuance traite plus d'un million de consultations, permettant aux prestataires de voir deux patients supplémentaires par jour sans prolonger les horaires. Les services financiers, détenant 20,13 % des parts en 2025, se concentrent sur la détection des fraudes qui réduit les faux positifs d'un quart et accélère le blocage des transactions suspectes à moins de deux secondes.
Les canaux de commerce de détail exploitent la recherche visuelle qui transforme les photos en listes de produits, augmentant les conversions de deux chiffres dans les pilotes. La fabrication tire parti de l'analyse des journaux pour la maintenance prédictive, réduisant les temps d'arrêt imprévus jusqu'à 30 %. Dans tous les secteurs, le succès dépend de plus en plus de la profondeur d'intégration des flux de travail et de la gouvernance des biais plutôt que de l'analyse de texte basique.
Analyse géographique
L'Amérique du Nord a conservé 37,92 % des parts en 2025, ancrée par l'infrastructure des hyperscalers et des adopteurs précoces tolérants au risque. Les entreprises bénéficient d'un financement en capital-risque généreux, et les bacs à sable réglementaires permettent aux banques de tester des modèles génératifs sous supervision. Cependant, la saturation et la charge croissante de conformité tempèrent la croissance à la fin des années dix.
L'Asie-Pacifique enregistre la progression la plus rapide à un TCAC de 22,13 % alors que la poussée souveraine en IA de 50 milliards USD de la Chine, la pile numérique publique de l'Inde et les pressions liées au vieillissement de la population au Japon convergent. Les entreprises d'État chinoises imposent le déploiement de modèles domestiques, stimulant l'adoption de Baidu et Alibaba. L'Interface de Paiement Unifiée de l'Inde alimente des milliards d'enregistrements multilingues dans des modèles de fraude et de crédit. Les hôpitaux japonais bénéficient d'allègements fiscaux lors de l'installation de la documentation ambiante, stimulant les déploiements de traitement automatique du langage naturel clinique.
L'Europe bénéficie de la clarté de la loi européenne sur l'IA, bien que les examens de conformité ajoutent 6 à 12 mois aux lancements à haut risque. Les constructeurs automobiles allemands intègrent des assistants vocaux locaux pour satisfaire le RGPD. Le Royaume-Uni encourage l'automatisation KYC pour réduire les coûts de conformité. L'Amérique du Sud adopte des robots de service client adaptés aux dialectes régionaux, tandis que le Moyen-Orient finance l'IA souveraine comme piliers de diversification économique. L'adoption en Afrique se concentre au Nigeria et au Kenya où le traitement automatique du langage naturel axé sur le mobile soutient la messagerie fintech et d'extension agricole. Malgré des points de départ disparates, chaque région positionne le marché du traitement automatique du langage naturel comme une infrastructure numérique essentielle d'ici la fin de la décennie.

Paysage réglementaire
L'environnement réglementaire du NLP est façonné par des régimes horizontaux de gouvernance de l'IA qui s'appliquent à la fois aux systèmes linguistiques à usage général et à haut risque dans les flux de travail réglementés. Dans l'UE, l'AI Act (règlement (UE) 2024/1689) crée des obligations applicables à partir du 2 août 2026, avec des attentes de conformité liées à des informations techniques documentées (Annexe IV) et des voies de conformité liées aux normes harmonisées (article 40). L'AI Office de l'UE gère également un vérificateur de conformité officiel en version bêta, que les opérateurs utilisent pour cartographier les exigences applicables à l'IA conversationnelle destinée aux clients ainsi qu'aux applications à plus haut risque telles que le soutien à la décision en matière de crédit et d'emploi.
Aux États-Unis, la politique fédérale continue de privilégier l'innovation par le biais d'une approche relativement moins prescriptive, s'appuyant sur des pratiques volontaires de gestion des risques telles que le NIST AI Risk Management Framework. Le décret exécutif 14365 de décembre 2025 oriente la gouvernance de l'IA autour de la réduction des obstacles à la commercialisation, tandis qu'un cadre de politique nationale de la Maison-Blanche de mars 2026 recommande une action du Congrès visant à prévaloir sur les lois d'IA fragmentées des États et à promouvoir une norme nationale uniforme, ce qui affecte le déploiement multi-États des API cloud de NLP. Au Japon, les directives gouvernementales de juin 2026 relatives aux achats publics et à l'utilisation de l'IA générative imposent la présence de Chief AI Officers (CAIO) dans tous les ministères et agences, faisant de la gouvernance et des contrôles de risque un prérequis d'achat pour les systèmes basés sur le NLP vendus dans le cadre de programmes du secteur public.
Paysage concurrentiel
Microsoft, Google, Amazon, OpenAI et NVIDIA, les cinq premiers fournisseurs, représentent environ 60 % des dépenses des entreprises, indiquant une concentration modérée sur le marché du traitement automatique du langage naturel. Les hyperscalers tirent parti de leur pouvoir de distribution grâce à des crédits groupés et à des MLOps intégrés. Pendant ce temps, des concurrents open source comme Llama 3 de Meta et Mistral réduisent les écarts de précision. Ce changement oblige les acteurs établis à prioriser la latence, la conformité et les écosystèmes de domaine plutôt que le simple nombre de paramètres. Les manœuvres stratégiques notables incluent les réductions de latence de Google avec Gemini Flash, l'introduction par Microsoft d'Azure AI Foundry pour des transitions de modèles transparentes, et le lancement du GPU H200 de NVIDIA, qui affiche un débit d'inférence doublé.
Les startups trouvent leur place dans des domaines tels que la génération augmentée par récupération, les données synthétiques et la compression sur appareil. Cohere fait des progrès dans la génération augmentée par récupération en entreprise, affichant des taux d'hallucination impressionnement faibles. Hugging Face a transformé sa plateforme, qui accueille désormais 500 000 développeurs, en un atout communautaire redoutable, rivalisant même avec les catalogues propriétaires. Une augmentation de 35 % d'une année sur l'autre des dépôts de brevets souligne l'escalade des batailles de propriété intellectuelle, notamment dans des domaines tels que l'apprentissage en quelques exemples et l'atténuation des biais. Les réglementations sont utilisées comme outils stratégiques ; les fournisseurs disposant de modules à haut risque pré-certifiés récoltent les avantages du premier entrant dans l'UE, une tendance susceptible de se répercuter dans d'autres régions adoptant des cadres réglementaires similaires.
De plus, les partenariats et collaborations façonnent le paysage concurrentiel. Par exemple, la collaboration d'OpenAI avec des fournisseurs de logiciels d'entreprise permet des solutions sur mesure pour des secteurs spécifiques, tandis qu'Amazon intègre ses capacités de traitement automatique du langage naturel dans les services AWS pour améliorer l'accessibilité pour les développeurs. Ces alliances devraient stimuler l'innovation et élargir l'adoption des technologies de traitement automatique du langage naturel dans divers secteurs au cours de la période de prévision.
Leaders du secteur du traitement automatique du langage naturel
Microsoft Corporation
SAS Institute Inc.
IBM Corporation
Google LLC (Alphabet)
NVIDIA Corp.
- *Avis de non-responsabilité : les principaux acteurs sont triés sans ordre particulier

Opportunités de marché et perspectives d'avenir
Les acheteurs en entreprise passent de pilotes à modèle unique à des déploiements agentiques gouvernés qui connectent le NLP aux systèmes métiers. Cette évolution crée un espace vacant pour les services d'intégration, les chaînes d'outils de surveillance et les piles RAG auditables qui répondent aux exigences de documentation et d'explicabilité dans les cas d'usage réglementés. Elle est également soutenue par des mouvements au niveau des plateformes, comme Azure AI Foundry de Microsoft, positionné pour permettre le changement de modèle sans réécriture, ainsi que par le regroupement, par les fournisseurs, de cadres agentiques de bout en bout dans des suites telles que SAS Viya, où des assistants agentiques et des accélérateurs sont introduits en tenant compte de la gouvernance.
L'opportunité à court terme se concentre sur les déploiements vocaux et en périphérie (edge), où les exigences de latence déterministe et de résidence des données sont plus difficiles à satisfaire avec des flux de travail purement cloud, ce qui correspond à la demande croissante de reconnaissance vocale en temps réel dans l'automobile et la documentation clinique ambiante. Un deuxième domaine d'opportunité est l'efficacité des modèles en tant que critère d'achat principal, les fournisseurs se faisant concurrence sur le coût par jeton, la latence et l'optimisation tenant compte du matériel, plutôt que sur la seule performance en matière de benchmarks. Les sorties de juillet 2026 illustrent cette orientation, avec OpenAI introduisant la famille GPT-5.6 avec des options échelonnées axées sur la performance par dollar et l'efficacité des jetons pour les tâches d'entreprise, Anthropic publiant Claude Sonnet 5 pour les flux de travail d'agents autonomes avec utilisation d'outils et améliorations de codage, et Thinking Machines Lab publiant le modèle Inkling MoE à poids ouverts avec une fenêtre de contexte très longue et une optimisation explicite pour les systèmes NVIDIA Blackwell. Ces mises à jour élargissent le choix des acheteurs entre approches propriétaires et à poids ouverts et augmentent la demande pour des outils d'évaluation, de routage et de déploiement capables d'opérationnaliser des portefeuilles multi-modèles sous contraintes de conformité et de budget.
Développements récents du secteur
- Juillet 2026 : OpenAI a publié la famille de modèles GPT-5.6 (niveaux Sol, Terra et Luna) visant une meilleure performance par dollar et une efficacité de jetons améliorée pour le codage et les charges de travail d'entreprise. La gamme échelonnée soutient des schémas d'achat où les équipes standardisent une plateforme tout en sélectionnant différents niveaux de modèles selon la criticité de la tâche et les contraintes de latence ou de coût.
- Juin 2026 : Microsoft a annoncé MAI-Transcribe-1.5, un modèle de reconnaissance vocale multilingue prenant en charge 43 langues et positionné pour un déploiement en production, y compris l'intégration dans Copilot, Teams, GitHub et Dynamics 365 Contact Center. Cette sortie renforce les piles NLP vocales de bout en bout au sein d'applications d'entreprise largement déployées, accélérant l'automatisation vocale dans le support client et les flux de travail intellectuels.
- Février 2025 : IBM a élargi sa famille de modèles Granite avec de nouveaux modèles multimodaux et axés sur le raisonnement, conçus pour un usage en entreprise. Cela a élargi l'ensemble des modèles de fondation pris en charge commercialement disponibles pour les charges de travail intensives en NLP, augmentant la pression concurrentielle sur les hyperscalers et offrant aux acheteurs des options supplémentaires pour des déploiements gouvernés.


Cadre de la méthodologie de recherche et portée du rapport
Définition et périmètre du marché
Pour cette étude, le marché du traitement du langage naturel est défini comme les revenus générés par les logiciels, services et matériels connexes de NLP qui permettent aux systèmes de comprendre, interpréter et générer le langage humain dans des situations réelles.
Exclusions du périmètre : Les dépenses de calcul et de stockage à usage général sont exclues, sauf si elles sont réalisées spécifiquement pour exécuter des charges de travail de NLP.
Aperçu de la segmentation
- Par déploiement
- Sur site
- Cloud
- Par taille d'organisation
- Grandes entreprises
- Petites et moyennes entreprises (PME)
- Par composant
- Matériel
- Logiciel
- Services
- Par type de traitement
- Texte
- Parole ou voix
- Image ou vision
- Par secteur d'utilisation final
- BFSI
- Santé et sciences de la vie
- Informatique et télécommunications
- Commerce de détail et commerce électronique
- Fabrication
- Médias et divertissement
- Éducation
- Autres secteurs d'utilisation final
- Par géographie
- Amérique du Nord
- États-Unis
- Canada
- Mexique
- Amérique du Sud
- Brésil
- Argentine
- Reste de l'Amérique du Sud
- Europe
- Allemagne
- Royaume-Uni
- France
- Italie
- Espagne
- Reste de l'Europe
- Asie-Pacifique
- Chine
- Japon
- Corée du Sud
- Inde
- Australie
- Nouvelle-Zélande
- Reste de l'Asie-Pacifique
- Moyen-Orient et Afrique
- Moyen-Orient
- Émirats arabes unis
- Arabie saoudite
- Turquie
- Reste du Moyen-Orient
- Afrique
- Afrique du Sud
- Nigeria
- Kenya
- Reste de l'Afrique
- Moyen-Orient
- Amérique du Nord
Sources de données, dimensionnement du marché et validation
Recherche documentaire
La recherche documentaire a été utilisée pour établir des limites claires et ancrer le modèle avec des indicateurs fiables et accessibles au public. Nous nous sommes principalement appuyés sur des sources telles que le US Bureau of Labor Statistics (séries de salaires et d'emploi pour les rôles pertinents), le US Census Bureau et UN Comtrade (signaux commerciaux pour certaines catégories de matériel), ainsi que la Banque mondiale (contexte macroéconomique et de dépenses informatiques) afin de maintenir un environnement de demande réaliste.
Pour convertir ces signaux en données pertinentes pour le marché, nous avons également examiné des articles évalués par des pairs provenant de sources telles qu'arXiv et l'IEEE, des mises à jour réglementaires et normatives telles que celles du NIST et de la Commission européenne, ainsi que des rapports annuels, des présentations de résultats et de la documentation produit provenant de fournisseurs et d'adoptants clés. Dans quelques cas, des abonnements payants ont été utilisés uniquement pour les données financières des entreprises, les recherches de brevets et les vérifications d'importation et d'exportation au niveau des expéditions lorsque les détails publics étaient limités. Ces exemples ne sont pas exhaustifs, et de nombreuses autres sources publiques ont été consultées pour recueillir des données, valider des chiffres et clarifier des hypothèses.
Entretiens et enquêtes primaires
Les travaux primaires ont porté sur la confirmation de la manière dont le NLP est acheté et monétisé selon les configurations de déploiement, les tailles de clients et les secteurs d'utilisateurs finaux. Nous nous sommes entretenus avec un ensemble de fournisseurs de solutions, d'intégrateurs de systèmes et d'acheteurs en entreprise dans les régions APAC, EMEA et Amériques, afin d'ajuster les hypothèses relatives au rythme d'adoption, à la tarification et à l'attachement des services en fonction de ce qui est observé dans les transactions et les déploiements.
Répartition des répondants au travail de terrain de la recherche primaire
| Type d'entreprise | Poste du répondant | Région |
|---|---|---|
| Premier niveau : 39 % | Dirigeants (CXO) : 14 % | APAC : 45 % |
| Niveau intermédiaire : 44 % | Responsables fonctionnels/d'unité : 28 % | EMEA : 29 % |
| Acteurs plus petits : 17 % | Managers : 58 % | Amériques : 26 % |
Dimensionnement du marché et prévisions
Le dimensionnement commence par une construction descendante où les dépenses technologiques totales adressables sont reconstruites en un bassin de demande de NLP, en utilisant l'adoption et la pénétration des charges de travail par région et par grands secteurs d'utilisation finale. Une fois ce bassin de demande constitué, il est réparti entre types de composants (logiciels, services et matériel) et modes de déploiement, à l'aide de signaux sur la manière dont les entreprises mettent en œuvre et maintiennent le NLP dans le temps.
Plusieurs empreintes de marché sont utilisées comme intrants afin que les totaux restent ancrés dans la réalité, telles que la répartition cloud contre sur site, les taux d'adoption en entreprise de l'IA conversationnelle et de l'analyse de texte, l'attachement typique des services pour l'intégration et l'ajustement des modèles, ainsi que l'évolution de la tarification moyenne, passant d'une tarification à l'usage vers des achats groupés ou basés sur une plateforme. Nous suivons également le rythme d'expansion de la couverture linguistique, les coûts de préparation réglementaire (par exemple, l'effort d'audit et de documentation), et la transition des programmes pilotes vers une utilisation en production à grande échelle, ce qui modifie l'intensité des dépenses. Les résultats sont ensuite corroborés par des approximations ascendantes sélectives, y compris une agrégation échantillonnée des revenus des fournisseurs et des vérifications de canaux sur les valeurs contractuelles moyennes, et les écarts sont traités en appliquant des références conservatrices lorsque la divulgation est limitée.
Pour les prévisions, une analyse de scénarios est utilisée, guidée par des retours primaires sur la rapidité avec laquelle les entreprises opérationnalisent le NLP, la manière dont la tarification évolue avec l'efficacité des modèles, et la manière dont les coûts de conformité évoluent. Les scénarios sont rattachés à des moteurs mesurables tels que les dépenses informatiques, les cycles d'investissement en IA, l'adoption du cloud et la maturité de déploiement au niveau sectoriel, puis ajustés lorsque les tendances régionales ou verticales divergent de la tendance mondiale.
Validation des données et cycle de mise à jour
La validation s'effectue par le biais de plusieurs vérifications qui comparent les résultats du modèle avec des signaux indépendants, puis examinent les valeurs aberrantes avant que les chiffres ne soient finalisés. Nous recherchons les incohérences entre régions, les changements brusques dans les hypothèses de tarification, et les sauts d'adoption irréalistes par secteur, et nous revisitons ces domaines par le biais d'appels de suivi ou de vérifications documentaires supplémentaires.
Avant validation finale, le travail est examiné par étapes afin que les définitions, les calculs et les hypothèses restent alignés, et tout écart important par rapport à l'orientation publiquement visible des fournisseurs est expliqué. Les rapports sont actualisés chaque année, avec des mises à jour intermédiaires lorsque des événements significatifs susceptibles de faire évoluer la demande ou la tarification se produisent, et une dernière vérification d'actualité est effectuée avant livraison afin que les clients reçoivent la vue la plus récente.
Comparaison du dimensionnement du marché du traitement du langage naturel de Mordor Intelligence avec d'autres estimations publiées
Les valeurs publiées du marché du NLP varient souvent car les groupes de recherche ne comptabilisent pas les mêmes flux de revenus, et ils choisissent également des années de base et des configurations de croissance différentes. Les écarts s'accentuent lorsqu'une estimation intègre des catégories d'IA adjacentes dans le NLP ou suppose une expansion tarifaire plus rapide sans la faire correspondre à la réalité de l'adoption.
Le tableau montre un écart autour de la valeur de départ de 2025, et le modèle de Mordor Intelligence restreint le total aux revenus spécifiques au NLP couvrant les logiciels, les services et le matériel connexe. La ventilation est organisée selon le déploiement, la taille de l'organisation, le type de traitement et les secteurs d'utilisateurs finaux, plutôt que d'englober des dépenses de plateforme IA plus larges. Les écarts proviennent également de la rapidité supposée de la hausse de la tarification à l'usage, de la manière dont l'attachement des services est traité lors de la mise à l'échelle, et du fait que la conversion des devises utilise des moyennes annuelles ou des taux ponctuels, ce qui peut modifier un total en USD.
Comparaison de référence
| Source | Taille du marché | Lacunes dans la méthodologie de recherche |
|---|---|---|
| Mordor Intelligence | 39,37 milliards USD (2025) | |
| Revue professionnelle A | 36,80 milliards USD (2025) | Utilise une lentille de solution plus étroite dans certaines parties de l'analyse, avec une clarté limitée quant à savoir si le matériel et les services de mise en œuvre sont pleinement comptabilisés, ce qui peut tirer le total déclaré vers le bas. |
| Cabinet de conseil mondial B | 42,47 milliards USD (2025) | Applique une configuration de croissance plus agressive et une cartographie segmentaire plus large qui peut inclure des lignes de revenus d'IA adjacentes, et se montre moins explicite sur la séparation des dépenses NLP pures des ensembles plus larges d'automatisation et d'analytique. |
Lorsque le périmètre est maintenu cohérent et que les dépenses sont rattachées à des intrants pratiques d'adoption et de tarification, l'écart entre les chiffres publiés devient plus facile à expliquer. Notre approche vise à maintenir la valeur de 2025 traçable à des moteurs de demande clairs et à des hypothèses reproductibles, ce qui rend les mises à jour annuelles et les comparaisons régionales plus fiables.


Questions clés auxquelles le rapport répond
À quelle vitesse les dépenses mondiales en solutions de traitement automatique du langage naturel se développent-elles ?
Entre 2026 et 2031, le marché du traitement automatique du langage naturel croît à un TCAC de 19,94 %, portant la valeur de 47,37 milliards USD à 117,57 milliards USD.
Quelle région affiche le momentum de croissance le plus fort ?
L'Asie-Pacifique affiche un TCAC de 22,13 % grâce aux mandats d'IA souveraine en Chine, à la pile numérique publique de l'Inde et à la numérisation des soins de santé au Japon qui stimulent une adoption accélérée.
Pourquoi les services dépassent-ils les logiciels dans les budgets futurs ?
Les entreprises ont besoin d'intégration, de surveillance des biais et d'audits de conformité, poussant les services à un TCAC de 22,62 % et les positionnant pour dépasser les dépenses en matériel d'ici 2028.
Qu'est-ce qui fait de la santé le segment d'utilisation final à la croissance la plus rapide ?
L'intelligence clinique ambiante, l'automatisation du codage et l'exploration de textes pour la découverte de médicaments réduisent la paperasserie jusqu'à 50 % et libèrent des capacités, propulsant une croissance à un TCAC de 24,84 %.
Dernière mise à jour de la page le:




