Taille et part de marché des grands modèles de langage (LLM)
VUE D’ENSEMBLE DU MARCHÉ
| Période d'étude | 2020 - 2031 |
|---|---|
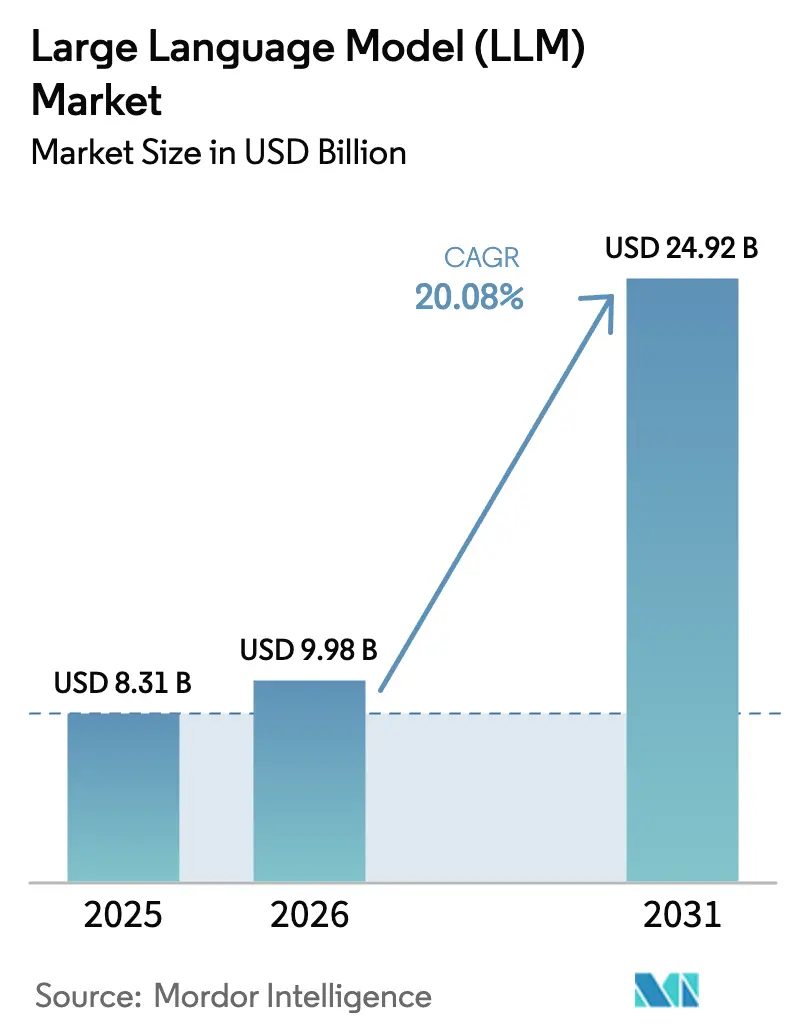
| Taille du Marché (2026) | 9.98 Milliards de dollars |
| Taille du Marché (2031) | 24.92 Milliards de dollars |
| Taux de croissance (2026 - 2031) | 20.08% CAGR |
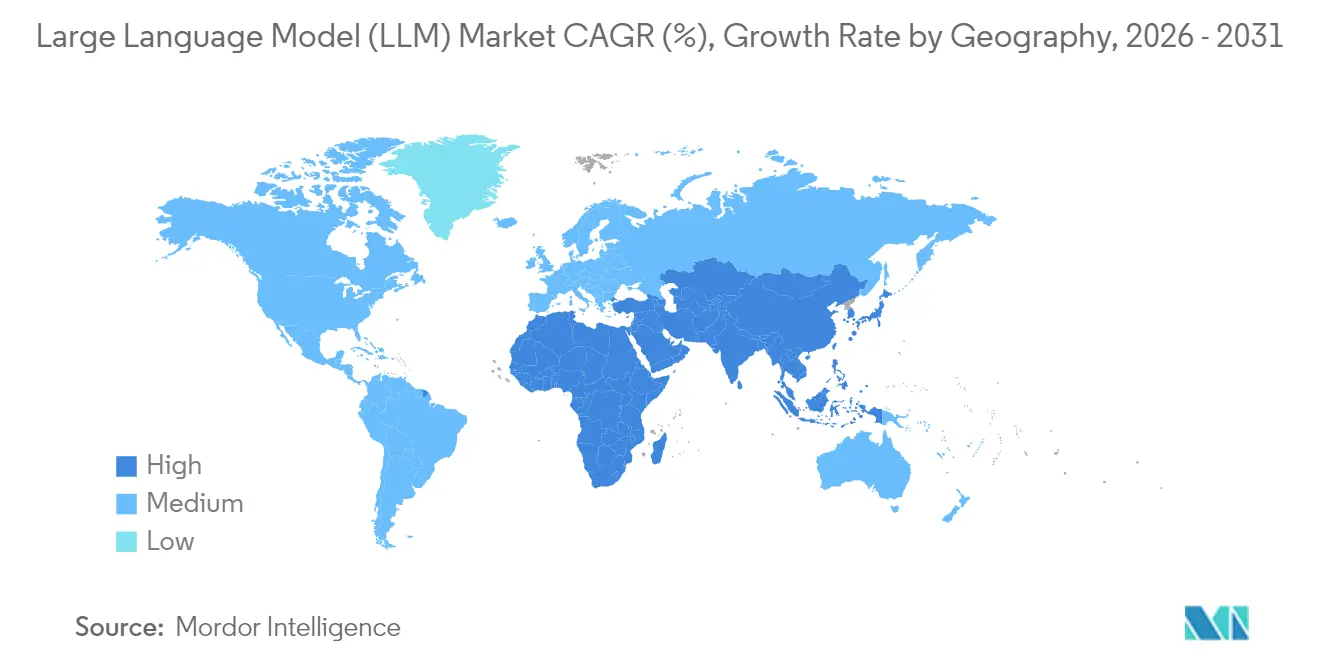
| Marché à la Croissance la Plus Rapide | Asie-Pacifique |
| Plus Grand Marché | Amérique du Nord |
| Concentration du Marché | Moyen |
Acteurs majeurs *Avis de non-responsabilité : les principaux acteurs sont triés sans ordre particulier Image © Mordor Intelligence. La réutilisation nécessite une attribution sous CC BY 4.0. | |
Analyse du marché des grands modèles de langage (LLM) par Mordor Intelligence
La taille du marché des grands modèles de langage a été évaluée à 8,31 milliards USD en 2025 et devrait croître de 9,98 milliards USD en 2026 pour atteindre 24,92 milliards USD d'ici 2031, à un TCAC de 20,08 % pendant la période de prévision (2026-2031). Les innovations en matière de GPU, telles que la plateforme Blackwell de Nvidia et AWS Trainium2, réduisent les coûts de possession et suppriment les barrières à l'échelle, incitant les entreprises de toutes tailles à piloter des initiatives de LLM internes ou gérées.[1]Nvidia Corporation, "La plateforme NVIDIA Blackwell arrive pour inaugurer une nouvelle ère de l'informatique," nvidianews.nvidia.com Les architectures multimodales qui traitent le texte, l'image et l'audio dans un seul pipeline passent des bancs de recherche aux offres commerciales, élargissant l'adoption au-delà de l'IA conversationnelle vers la conception, le diagnostic et la publicité. Les réglementations nationales en matière d'IA poussent les acheteurs vers des déploiements formés régionalement ou sur site, tandis que les API spécifiques à un domaine dans les secteurs bancaire et de la santé supplantent les modèles génériques en réduisant le risque d'hallucination et en facilitant la conformité. Les petits modèles de langage optimisés pour la périphérie remodèlent les feuilles de route des appareils pour les smartphones, les objets connectés portables et les OEM industriels, ouvrant de nouveaux flux de revenus pour les fournisseurs de puces et les prestataires d'inférence en tant que service. Ensemble, ces forces indiquent une décennie au cours de laquelle le marché des grands modèles de langage évolue de charges de travail cloud concentrées vers un tissu d'intelligence omniprésent et à plusieurs niveaux.
Principaux enseignements du rapport
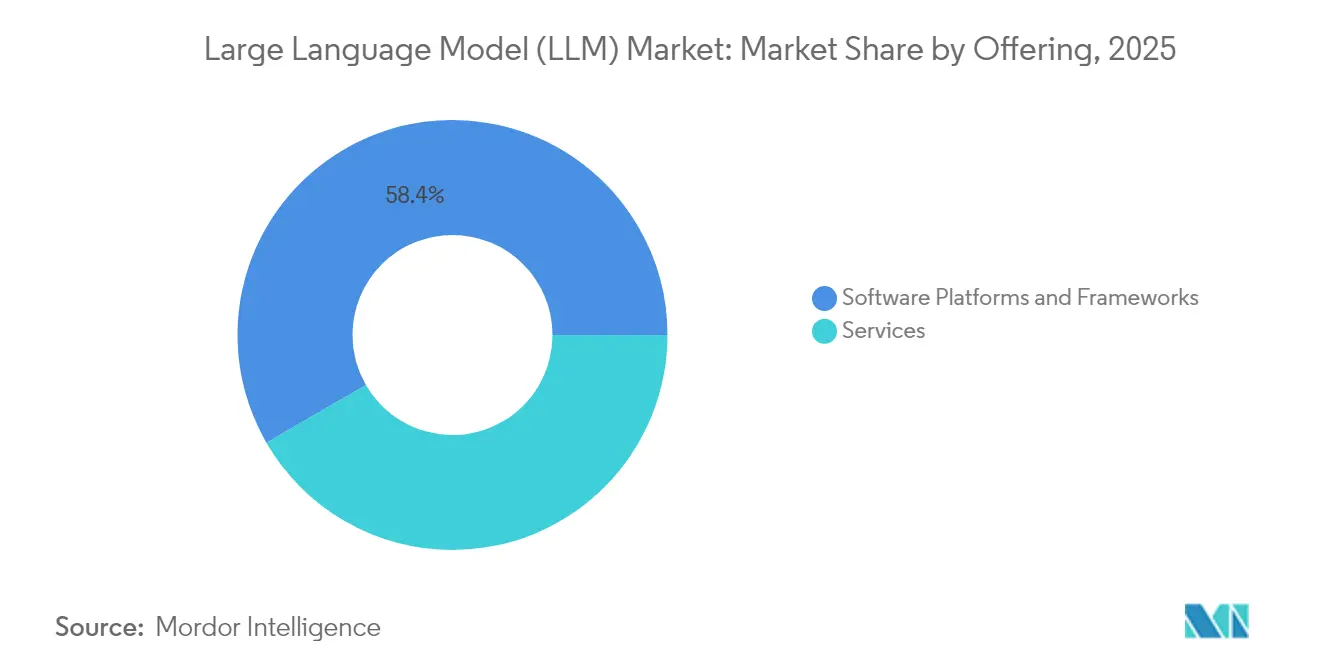
- Par offre, les plateformes logicielles ont représenté 58,35 % de la part de marché des grands modèles de langage en 2025 ; les services devraient se développer à un TCAC de 24,26 % jusqu'en 2031.
- Par déploiement, les solutions sur site ont dominé avec 51,85 % de la taille du marché des grands modèles de langage en 2025, tandis que les déploiements en périphérie/sur appareil progressent à un TCAC de 27,25 % jusqu'en 2031.
- Par taille de modèle, les modèles de moins de 100 milliards de paramètres ont capturé 69,20 % de la part de marché des grands modèles de langage en 2025 ; les modèles de plus de 300 milliards de paramètres devraient croître à un TCAC de 29,05 %.
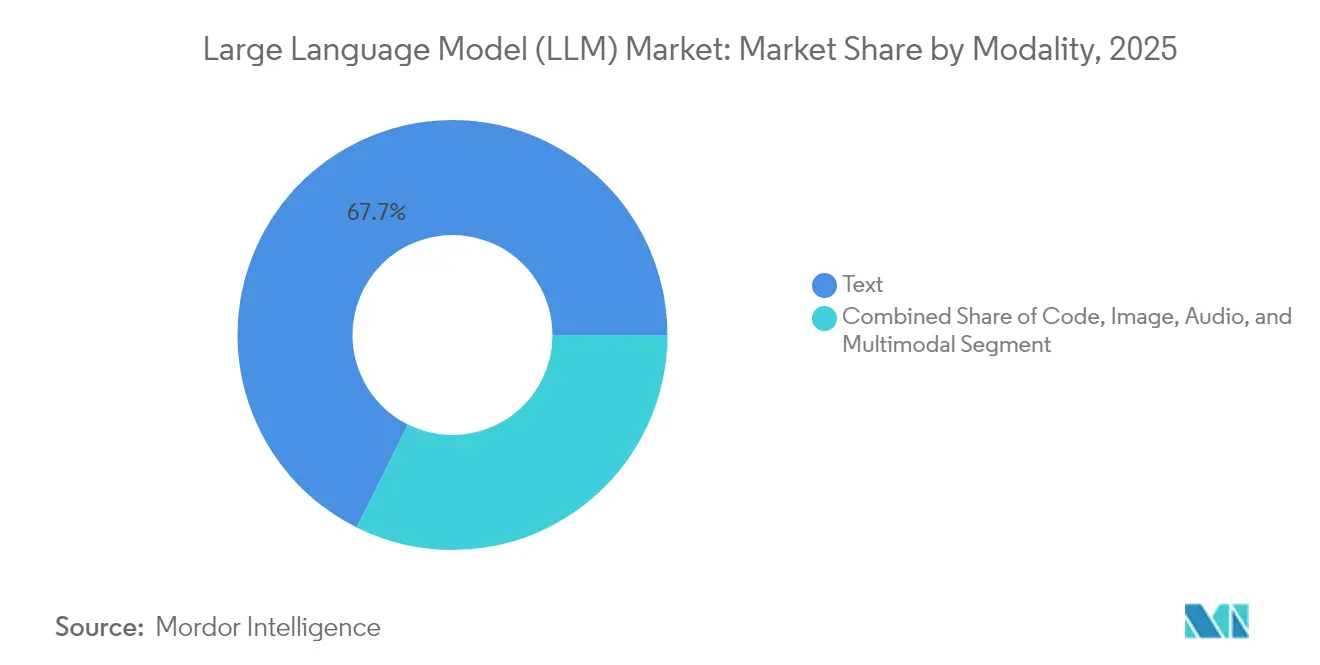
- Par modalité, les modèles axés sur le texte ont représenté 67,65 % des revenus en 2025 ; les modèles multimodaux devraient afficher un TCAC de 28,95 % jusqu'en 2031.
- Par application, les chatbots et assistants virtuels ont représenté 26,35 % de la taille du marché des grands modèles de langage en 2025, tandis que les outils de génération de code évolueront à un TCAC de 24,75 %.
- Par secteur d'activité des utilisateurs finaux, le commerce de détail et le commerce électronique ont dominé avec 26,75 % des revenus en 2025 ; la santé progressera à un TCAC de 25,95 % jusqu'en 2031.
- Par géographie, l'Amérique du Nord a représenté 31,70 % des revenus de 2025, tandis que l'Asie-Pacifique est en passe d'atteindre un TCAC de 31,40 % entre 2026 et 2031.
Remarque : Les chiffres de la taille du marché et des prévisions de ce rapport sont générés à l’aide du cadre d’estimation propriétaire de Mordor Intelligence, mis à jour avec les données et analyses les plus récentes disponibles en 2026.
Tendances et perspectives du marché mondial des grands modèles de langage (LLM)
Analyse de l'impact des moteurs*
| Moteur | (~) % d'impact sur les prévisions de TCAC | Pertinence géographique | Calendrier d'impact |
|---|---|---|---|
| Baisse rapide des coûts de calcul GPU via Nvidia Blackwell et AWS Trainium2 | +5.2% | Mondial, avec concentration en Amérique du Nord et en Asie de l'Est | Moyen terme (2-4 ans) |
| API LLM de niveau entreprise et spécifiques à un domaine dans les secteurs BFSI et santé (Amérique du Nord) | +4.3% | Amérique du Nord, avec répercussions en Europe | Court terme (≤ 2 ans) |
| Politiques nationales d'IA imposant une formation locale (ex. : règles provisoires chinoises 2024) | +3.1% | Chine, UE, avec implications mondiales | Moyen terme (2-4 ans) |
| Opportunité de vente incitative SaaS grâce aux fonctionnalités LLM intégrées (CRM/ERP européens) | +2.8% | Europe, Amérique du Nord | Court terme (≤ 2 ans) |
| Forte demande de contenu multimodal de la part des agences AdTech mondiales | +2.5% | Mondial, avec concentration en Amérique du Nord et en Europe | Moyen terme (2-4 ans) |
| Petits modèles de langage optimisés pour la périphérie (moins de 2 milliards de paramètres) pour smartphones | +3.7% | Mondial, avec adoption précoce en Asie-Pacifique | Long terme (≥ 4 ans) |
| Source: Mordor Intelligence | |||
Baisse rapide des coûts de calcul GPU via Nvidia Blackwell et AWS Trainium2
La famille Blackwell de Nvidia, dévoilée en 2024, réduit le coût total de possession pour la formation et l'inférence à grande échelle jusqu'à 25 fois par rapport à la génération précédente, diminuant à la fois les dépenses d'investissement et la consommation d'énergie. AWS Trainium2 étend ces économies aux clouds gérés, offrant aux éditeurs de logiciels de taille intermédiaire une voie économique vers l'expérimentation à l'échelle du billion de paramètres. L'efficacité du capital qui en résulte supprime un avantage historique dont bénéficiaient les grands hyperscalers, permettant aux fournisseurs régionaux et aux consortiums open source de publier des points de contrôle compétitifs. L'élasticité des coûts amplifie également l'expérimentation dans les approches d'ajustement fin à efficacité paramétrique qui améliorent la précision sans mises à niveau matérielles supplémentaires. Collectivement, ces économies accélèrent les déploiements dans des secteurs allant de la fabrication de précision à l'éducation personnalisée, élargissant le marché adressable des grands modèles de langage.
API LLM de niveau entreprise et spécifiques à un domaine dans les secteurs BFSI et santé
Les banques intègrent des modèles adaptés à la finance pour le triage du risque de crédit, le filtrage des sanctions et les conseils personnalisés aux clients, réduisant les cycles de révision manuelle tout en respectant les normes d'audit. Les réseaux de santé pilotent des assistants cliniquement alignés qui analysent les notes médicales et la littérature pour améliorer les décisions diagnostiques, le triage des patients et la découverte de médicaments. Les fournisseurs mettent l'accent sur un ancrage strict des invites et la génération augmentée par récupération pour supprimer les hallucinations et satisfaire aux exigences réglementaires. Les modèles d'abonnement qui mesurent les jetons ou les résultats s'adaptent aux normes d'approvisionnement existantes, facilitant les cycles de vente. Avec des règles strictes de gouvernance des données dans les deux secteurs, ces API spécialisées supplantent les modèles généraux et cimentent un niveau premium sur le marché des grands modèles de langage.
Politiques nationales d'IA imposant une formation locale
Les mesures provisoires chinoises et la loi européenne sur l'IA exigent une classification des risques, des dépôts de sécurité et, dans de nombreux cas, une formation locale des modèles en matière de stratégie numérique.[3]Commission européenne, "Cadre réglementaire sur l'IA," digital-strategy.ec.europa.eu Les entreprises évaluent désormais la fragmentation juridictionnelle par rapport à l'efficacité, se tournant vers des clouds souverains ou des clusters sur site pour protéger leurs données propriétaires. Les intégrateurs de systèmes répondent en lançant des hubs de modèles régionaux, souvent cofinancés par des opérateurs télécoms ou des fonds publics, pour assurer une couverture linguistique et une autorisation gouvernementale plus rapide. Ce changement fait émerger de nouveaux champions régionaux et érode la thèse du modèle universel qui a dominé la croissance initiale du marché des grands modèles de langage. Parallèlement, la formation locale produit des résultats culturellement alignés, améliorant l'acceptation des utilisateurs dans des secteurs tels que les services publics et les médias audiovisuels.
Opportunité de vente incitative SaaS grâce aux fonctionnalités LLM intégrées
Les plateformes CRM, ERP et de travail collaboratif intègrent des fonctions génératives — rédaction automatique d'e-mails, résumé des risques liés aux transactions, réconciliation de clôture financière — directement dans leurs interfaces existantes. Les fournisseurs ont commencé à s'éloigner de la tarification par siège vers des niveaux basés sur l'utilisation qui alignent mieux la valeur avec la consommation de calcul.[4]Commission européenne, "Cadre réglementaire sur l'IA," digital-strategy.ec.europa.eu Les stratégies de vente incitative reposent sur l'exploitation des données clients déjà présentes dans la pile SaaS, fournissant des réponses riches en contexte que les concurrents peinent à reproduire. Pour les acheteurs, le modèle minimise les frais d'intégration et réalise le retour sur investissement en quelques semaines, incitant à allouer des budgets précédemment réservés aux projets pilotes d'IA discrets. Cette dynamique élargit le marché total accessible des grands modèles de langage au-delà des équipes IA vers les parties prenantes métier.
Analyse de l'impact des freins*
| Frein | (~) % d'impact sur les prévisions de TCAC | Pertinence géographique | Calendrier d'impact |
|---|---|---|---|
| Hausse des coûts d'énergie d'inférence (0,12 USD/1 000 jetons) limitant l'adoption par les PME (Amérique du Sud) | -2.1% | Amérique du Sud, Afrique, Asie du Sud-Est | Court terme (≤ 2 ans) |
| Surcoûts de conformité à haut risque liés à la loi européenne sur l'IA | -1.8% | Union européenne, avec des implications mondiales pour les entreprises desservant les marchés de l'UE | Moyen terme (2-4 ans) |
| Pénurie de données d'entraînement multilingues pour les langues africaines | -1.3% | Afrique, avec des implications mondiales pour une IA inclusive | Long terme (≥ 4 ans) |
| Contrôle des hyperscalers sur l'approvisionnement en GPU H100 contraignant le calcul haute performance sur site | -1.9% | Mondial, avec un impact particulier sur les marchés émergents | Moyen terme (2-4 ans) |
| Source: Mordor Intelligence | |||
Hausse des coûts d'énergie d'inférence limitant l'adoption par les PME
L'exécution d'un assistant de 20 milliards de paramètres peut consommer plusieurs kilowattheures par million de jetons, ce qui se traduit par 0,12 USD de frais d'électricité pour chaque 1 000 jetons traités dans les régions où les tarifs du réseau dépassent 0,10 USD/kWh. Pour les petites entreprises de commerce électronique ou de logistique opérant avec de faibles marges au Brésil ou au Kenya, le calcul compromet le retour sur investissement. Les fournisseurs cloud co-localisent un refroidissement ultra-efficace et des énergies renouvelables, mais les taux de répercussion restent volatils. Des compilateurs sensibles à l'énergie et des techniques de parcimonie émergent, mais peu atteignent la production avec les budgets typiques des équipes informatiques des PME. Tant que la densité d'inférence ne s'améliore pas, de nombreuses petites entreprises resteront sur des chatbots traditionnels, plafonnant une partie du marché des grands modèles de langage à court terme.
Surcoûts de conformité à haut risque liés à la loi européenne sur l'IA
La loi européenne sur l'IA, en vigueur depuis février 2025, qualifie de nombreux déploiements de LLM dans le scoring de crédit, le recrutement ou le soutien médical comme à haut risque, déclenchant des évaluations d'impact obligatoires, des boucles de supervision humaine et des registres publics. Des pénalités pouvant atteindre 35 millions EUR ou 7 % du chiffre d'affaires mondial élèvent le niveau de scrutin au niveau du conseil d'administration. Les charges de documentation ralentissent les cycles de publication et exigent de nouveaux outils pour la traçabilité des ensembles de données, l'explicabilité et la surveillance des biais. Les grandes entreprises peuvent amortir les dépenses sur plusieurs lignes de produits, tandis que les startups font face à des retards d'entrée sur le marché, les poussant vers des juridictions moins réglementées. Collectivement, ces frictions réduisent les points de croissance régionale au sein du marché des grands modèles de langage.
*Nos prévisions considèrent les impacts des moteurs et des contraintes comme directionnels et non additifs. Les prévisions d'impact reflètent la croissance de référence, les effets de composition et les interactions entre variables.
Analyse des segments
Par offre : les plateformes logicielles stimulent l'adoption en entreprise
Les plateformes logicielles ont représenté 58,35 % des revenus de 2025, servant d'échafaudage pour l'expérimentation, le chaînage des invites et les flux de travail d'ajustement fin. Les kits de fonctionnalités qui abstraient la tokenisation, la recherche vectorielle et les filtres de sécurité permettent aux développeurs d'intégrer des fonctions génératives sans connaissance approfondie des modèles. Sur la fenêtre de prévision, les services de conseil et d'ajustement se développeront à un TCAC de 24,26 % à mesure que les entreprises cherchent de l'aide pour aligner les résultats sur le ton de la marque, la politique de risque et les budgets de latence. Les plans d'inférence gérée évoluent également, permettant aux entreprises de répartir les appels entre GPU, ASIC et CPU en fonction des courbes de coûts en temps réel. Cette couche de services pousse le marché des grands modèles de langage vers un paradigme en tant que service.
La demande croissante de piles verticales clés en main encourage les entreprises de plateformes à ajouter des préréglages réglementaires, des vocabulaires de domaine et des tableaux de bord de référence. Les véhicules contractuels regroupent de plus en plus les licences, l'analyse d'utilisation et les rapports de conformité, reflétant les normes d'approvisionnement dans la finance et la santé. Les éditeurs de logiciels indépendants intègrent ces plateformes, alimentant un écosystème de partenaires qui élargit la portée des canaux. En conséquence, le marché des grands modèles de langage récompense particulièrement les fournisseurs qui associent des outils ouverts à des connecteurs de données organisés et à des fonctionnalités de gouvernance robustes.



Par déploiement : l'informatique en périphérie remodèle l'architecture de l'IA
Les installations sur site ont dominé 51,85 % des dépenses de 2025, les banques, les hôpitaux et les agences publiques ayant privilégié la souveraineté et le contrôle de la latence. Les réglementations exigeant le traitement des données dans le pays ont encore orienté les budgets vers des clusters privés et des clouds souverains. Pourtant, la traction la plus rapide se situe en périphérie, où des points de contrôle quantifiés de 4 Go s'adaptent désormais aux smartphones haut de gamme et aux contrôleurs industriels. Avec un TCAC de 27,25 % jusqu'en 2031, l'inférence en périphérie supprime les délais d'aller-retour et allège la charge de bande passante, très appréciée dans les drones d'inspection autonomes et les objets connectés portables pour les services sur le terrain. Les premiers pilotes en Corée du Sud et en Inde démontrent une réponse inférieure à 100 millisecondes sur des SoC mobiles de 6 W, marquant un nouveau chapitre pour le marché des grands modèles de langage.
Des topologies hybrides se cristallisent : les invites à haute précision s'initient dans le cloud, tandis que les continuations à faible risque se produisent sur l'appareil, réduisant considérablement les frais de sortie cloud. Les fabricants de puces livrent des NPU adaptés aux transformeurs en 4 bits, et les mises à jour du micrologiciel permettent aux OEM de livrer des agents linguistiques à valeur ajoutée après l'achat. Ensemble, ces tendances brouillent la frontière entre cloud et produit, diffusant l'intelligence du marché des grands modèles de langage dans toute la pile d'appareils.
Par taille de modèle : l'efficacité paramétrique stimule l'innovation
Les entreprises ont privilégié les modèles de moins de 100 milliards de paramètres, qui ont capturé 69,20 % des revenus de 2025 et fonctionnent généralement confortablement sur des clusters de huit GPU. La conception à efficacité paramétrique réduit les jetons tout en préservant les fenêtres de contexte, comme en témoigne l'architecture récurrente de xLSTM 7B qui offre une inférence rapide sur des serveurs standard. De telles empreintes s'alignent sur les plafonds de coûts dans l'automatisation des centres de contact ou le chat des assurés dans l'assurance, maintenant le marché des grands modèles de langage accessible aux entreprises de taille intermédiaire.
À l'autre extrême, les modèles de plus de 300 milliards de paramètres afficheront un TCAC de 29,05 %, portés par des cas d'utilisation complexes de raisonnement, de découverte scientifique et de composition multimodale. Les alliances de recherche entre les géants pharmaceutiques et les plateformes cloud visent à comprimer les calendriers d'entraînement grâce à l'apprentissage par curriculum et aux données synthétiques, poussant des percées dans le repliement des protéines et la conception de matériaux. À mesure que les outils permettant de distiller les connaissances de ces géants vers des têtes de service plus petites arrivent à maturité, la valeur créée au sommet se répercute sur les applications commerciales quotidiennes, élargissant le marché total des grands modèles de langage.
Par modalité : les capacités multimodales élargissent le champ d'application
Les architectures axées sur le texte ont généré 67,65 % des revenus de 2025, alimentant la synthèse, la gestion des connaissances et le support conversationnel. Cependant, les équipes d'engagement client, les agences publicitaires et les cliniciens exigent de plus en plus des modèles capables d'ingérer des diagrammes, des images et des formes d'onde en plus du texte. Les piles multimodales progresseront à un TCAC de 28,95 % d'ici 2031, stimulées par des innovations dans les jetons visuels et les espaces d'intégration conjoints. Les applications immobilières décrivent désormais les photos de propriétés en plusieurs langues, et les assistants en radiologie croisent les images avec les dossiers des patients pour signaler les anomalies, ouvrant de nouvelles voies sur le marché des grands modèles de langage.
Les entrées augmentées par l'audio améliorent la précision dans le contrôle qualité des centres d'appels, et les prototypes de geste vers code suggèrent un changement d'interface imminent. Les fournisseurs qui maîtrisent l'alignement inter-modal et l'optimisation de la latence acquièrent un avantage concurrentiel, car les pipelines de données et les protocoles d'évaluation deviennent nettement plus complexes que les variantes texte uniquement. Par conséquent, la profondeur technique dans la pré-formation multimodale détermine de plus en plus le leadership sur le marché des grands modèles de langage.
Par application : la génération de code accélère la productivité des développeurs
Les chatbots et assistants virtuels ont dominé la demande de 2025 avec une part de 26,35 %, automatisant le support de premier niveau, les services d'assistance RH et les services de conciergerie virtuelle. Ils restent une porte d'entrée, mais les équipes logicielles représentent la progression la plus forte. Les outils de génération et de révision de code croîtront à un TCAC de 24,75 %, accélérant les sprints en suggérant automatiquement des fonctions, en détectant les failles de sécurité et en produisant des suites de tests. Les équipes utilisant des programmeurs en binôme LLM signalent moins de bogues reportés et des cadences de publication plus serrées, démontrant un retour sur investissement tangible pour les directeurs financiers et élargissant l'entonnoir du marché des grands modèles de langage.
Au-delà du code, les pipelines de création de contenu intègrent la rédaction, la mise en page et la génération de voix off sous une seule couche d'orchestration. Les agents autonomes fusionnent les API de récupération, de raisonnement et d'action pour naviguer dans des flux de travail complexes tels que le triage des sinistres d'assurance ou la gestion des exceptions de la chaîne d'approvisionnement. Ces modèles émergents soulignent un passage des invites à tour unique à l'orchestration en plusieurs étapes, approfondissant la valeur capturée par le marché des grands modèles de langage.
Par secteur d'activité des utilisateurs finaux : les innovations dans la santé stimulent la croissance
Le commerce de détail et le commerce électronique ont capturé 26,75 % des revenus de 2025, tirant parti des questions-réponses sur les produits en temps réel, du contenu publicitaire et du reclassement dynamique des recherches. Les institutions financières se sont tournées vers l'analyse anti-fraude et le conseil contextuel aux clients, stimulant la vente croisée sans augmenter les effectifs. Pourtant, la santé affichera un TCAC de 25,95 % jusqu'en 2031, les LLM cliniques soutenant le raisonnement diagnostique, la synthèse de la littérature et les instructions de sortie personnalisées. Les premiers pilotes montrent des taux de réadmission réduits lorsque les notes de sortie sont automatiquement adaptées au niveau de littératie des patients, prouvant un impact direct sur les résultats et renforçant les dépenses sur le marché des grands modèles de langage.
Les chercheurs en sciences de la vie alimentent des modèles affinés avec des protocoles de laboratoire, des données omiques et des corpus de brevets pour accélérer l'identification des cibles. Les organismes gouvernementaux et de défense expérimentent la synthèse de renseignements multilingues, tandis que les prestataires d'éducation testent le tutorat adaptatif qui mêle explication des concepts et questionnement socratique. Dans ces secteurs verticaux, les protocoles de confidentialité des données et les pistes d'audit sont devenus des éléments standard des listes de contrôle des appels d'offres, poussant les fournisseurs à intégrer des primitives de gouvernance au cœur de la conception des produits.
Analyse géographique
L'Amérique du Nord a contribué à hauteur de 31,70 % des revenus de 2025, portée par le financement par capital-risque, les viviers de talents universitaires et l'approvisionnement en GPU cloud. Les entreprises y ont été les premières à déployer des assistants spécifiques à un domaine pour la gestion de patrimoine, le soutien à la décision en oncologie et la recherche juridique. Les lois sur la confidentialité au niveau des États et l'attention fédérale portée aux biais algorithmiques stimulent la demande de modules d'explicabilité, mais la politique globale reste favorable à l'innovation. Le déploiement continu de centres de données prêts pour l'IA par les hyperscalers soutient le débit régional, garantissant que le marché des grands modèles de langage conserve un noyau nord-américain important.
L'Asie-Pacifique enregistrera le TCAC le plus rapide à 31,40 % à mesure que les gouvernements financent des initiatives de modèles souverains et que la diversité linguistique stimule les points de contrôle locaux. Les mesures provisoires chinoises imposent une formation sur site, stimulant la conception d'accélérateurs domestiques et les services cloud. Le Japon encourage l'IA à fort impact dans le cadre de sa stratégie Jardin numérique 2025, tandis que la mission IndiaAI de l'Inde ouvre des ensembles de données publics et des crédits GPU aux startups. Les petits modèles de langage natifs pour la périphérie trouvent un écho dans les marchés centrés sur les smartphones tels que l'Indonésie et les Philippines, élargissant la couverture rurale et gonflant le marché des grands modèles de langage.
L'Europe équilibre ambition et prudence sous la loi européenne sur l'IA. Les entreprises poursuivent des déploiements hybrides pour concilier résidence des données et évolutivité, utilisant des clusters privés pour les charges de travail sensibles et des clouds publics pour la capacité de pointe. L'Espagne, la France et l'Italie développent des fermes de serveurs prêtes pour l'IA, souvent alimentées par des énergies renouvelables pour atteindre les objectifs de durabilité. La vague de vente incitative SaaS y est prononcée, avec des fournisseurs ERP qui intègrent des fonctionnalités de chat multilingue et de réconciliation des factures satisfaisant aux normes d'audit locales. Collectivement, les régimes d'application nationaux divergents fragmentent les plans de mise sur le marché mais génèrent également une demande d'outils de conseil et de conformité, maintenant le marché régional des grands modèles de langage sur une trajectoire de croissance stable.

Paysage concurrentiel
Les cinq premiers fournisseurs contrôlent ensemble plus de 85 % des revenus, ancrés par des piles intégrées qui s'étendent du silicium au logiciel. Nvidia a renforcé sa position en acquérant des actifs d'orchestration logicielle début 2025, se positionnant comme un fournisseur de plateforme IA tout-en-un nvidianews.nvidia.com. Microsoft a approfondi ses partenariats avec OpenAI et le laboratoire émergent xAI, répartissant le risque lié aux modèles et élargissant l'attrait auprès des clients blogs.microsoft.com. Oracle s'est aligné avec Microsoft et OpenAI pour offrir des régions IA multi-cloud, mariant conformité et échelle GPU élastique.
Les challengers open source et les spécialistes régionaux se distinguent en publiant des points de contrôle efficaces qui rivalisent avec les bases de licence commerciale à moindre coût. Claude 4 d'Anthropic a repoussé les limites des benchmarks de raisonnement en plusieurs étapes, tandis que les ajustements fins en précision mixte des modèles dérivés de Meta dominent les classements communautaires. Les opérateurs télécoms en Corée du Sud et en Allemagne lancent des clouds IA souverains, visant à capter les charges de travail réglementées et à prendre des parts aux hyperscalers américains. Les startups qui regroupent des données verticales, des suites d'évaluation de domaine et des API de déploiement rapide sécurisent des contrats dans l'assurance, la logistique et l'exploitation minière, insufflant un dynamisme nouveau sur le marché des grands modèles de langage.
Les alliances stratégiques, et non les seuls poids des modèles, décident désormais des appels d'offres en entreprise. Les fournisseurs proposant des architectures de référence, des simulateurs de coûts et des tableaux de bord de conformité gagnent en traction lors des achats. L'efficacité énergétique, la résilience de la chaîne d'approvisionnement et les métriques d'utilisation transparentes figurent en bonne place dans les accords de service maîtres, signalant un manuel d'achat en maturation. Avec les poids ouverts qui érodent les avantages propriétaires, les acteurs établis se différencient de plus en plus sur les outils de déploiement, les intégrations de sécurité et la capacité de distribution mondiale.
Leaders du secteur des grands modèles de langage (LLM)
Alibaba Group Holding Limited
Amazon Web Services (AWS)
Anthropic
Baidu, Inc.
Google LLC
- *Avis de non-responsabilité : les principaux acteurs sont triés sans ordre particulier

Développements récents dans le secteur
- Mai 2025 : Anthropic a lancé les modèles Claude 4 avec un raisonnement en plusieurs étapes amélioré.
- Mai 2025 : Microsoft a intégré des technologies d'Anthropic et de xAI, diversifiant sa pile IA.
- Mai 2025 : OpenAI a introduit Codex, un agent pour les tâches de développement logiciel.
- Avril 2025 : Google a adopté le protocole d'interopérabilité d'Anthropic pour les agents IA.
- Avril 2025 : Nvidia a annoncé des acquisitions élargissant son contrôle IA à pile complète.
- Mars 2025 : EY Inde a dévoilé un LLM BFSI affiné construit sur LLAMA 3.1-8B.
- Mars 2025 : Google a investi dans Anthropic, renforçant leur partenariat IA.
- Mars 2025 : Nebius et YTL ont lancé des instances GPU Blackwell Ultra.


Cadre de la méthodologie de recherche et portée du rapport
Définitions du marché et couverture principale
Notre étude définit le marché des grands modèles de langage (LLM) comme les revenus générés par les plateformes logicielles, les frameworks et les services d'intégration ou d'ajustement fin associés qui permettent aux modèles basés sur des transformeurs dépassant un milliard de paramètres d'être entraînés, déployés ou consommés sur site, dans le cloud ou en périphérie. Selon Mordor Intelligence, la valeur est capturée au moment où les logiciels ou services atteignent les utilisateurs payants, qu'ils soient facturés par appel API, par abonnement ou par licence entreprise.
Exclusion du périmètre : les modèles génératifs de vision par ordinateur autonomes et les ventes de GPU, ASIC ou serveurs sont hors du champ de cette étude.
Aperçu de la segmentation
- Par offre
- Plateformes logicielles et frameworks
- Plateformes LLM à usage général
- Solutions LLM spécifiques à un domaine
- Services
- Conseil et intégration de systèmes
- Ajustement fin et personnalisation
- Inférence gérée et hébergement
- Plateformes logicielles et frameworks
- Par déploiement
- Cloud (public et privé)
- Sur site / clusters IA dédiés
- Périphérie / intégré dans l'appareil
- Par taille de modèle - Paramètres
- Moins de 7 milliards de paramètres
- 7 - 70 milliards de paramètres
- 70 - 300 milliards de paramètres
- Plus de 300 milliards de paramètres
- Par modalité
- Texte
- Code
- Image
- Audio
- Multimodal
- Par application
- Chatbots et assistants virtuels
- Génération et révision de code
- Génération de contenu et de médias
- Automatisation du service client
- Traduction linguistique et localisation
- Analyse des sentiments et des intentions
- Agents autonomes et automatisation robotisée des processus
- Par secteur d'activité des utilisateurs finaux
- BFSI
- Santé et sciences de la vie
- Commerce de détail et commerce électronique
- Médias et divertissement
- Technologies de l'information et télécommunications
- Éducation
- Industrie manufacturière
- Gouvernement et défense
- Par géographie
- Amérique du Nord
- États-Unis
- Canada
- Mexique
- Europe
- Allemagne
- Royaume-Uni
- France
- Italie
- Espagne
- Reste de l'Europe
- Asie-Pacifique
- Chine
- Japon
- Corée du Sud
- Inde
- Asie du Sud-Est
- Reste de l'Asie-Pacifique
- Amérique du Sud
- Brésil
- Reste de l'Amérique du Sud
- Moyen-Orient et Afrique
- Moyen-Orient
- Émirats arabes unis
- Arabie saoudite
- Reste du Moyen-Orient
- Afrique
- Afrique du Sud
- Reste de l'Afrique
- Moyen-Orient
- Amérique du Nord
Méthodologie de recherche détaillée et validation des données
Recherche primaire
Pour ancrer les résultats secondaires, nous avons interrogé des responsables de produits IA, des architectes d'opérations cloud, des responsables de la conformité et des chercheurs universitaires en Amérique du Nord, en Europe et dans les principaux centres d'Asie-Pacifique. Des questionnaires structurés ont sondé les modèles de tarification, les préférences en matière de nombre de paramètres, les ratios coût de calcul/inférence et les cycles de mise à niveau prévus, nous permettant de combler les lacunes de données et de tester les hypothèses modélisées.
Recherche documentaire
Les analystes de Mordor ont rassemblé des données fondamentales à partir de sources de premier rang accessibles au public, telles que les dépôts de l'Office américain des brevets et des marques sur les nouvelles architectures de transformeurs, les indicateurs de l'économie numérique de l'OCDE suivant l'adoption de l'IA, les codes douaniers de l'Organisation mondiale du commerce couvrant les exportations de logiciels IA, et les documents de politique du groupe de travail sur la loi européenne sur l'IA. Nous avons enrichi ces informations avec les rapports annuels 10-K des entreprises, les transcriptions des conférences de développeurs et les notes d'information d'associations professionnelles réputées (par exemple, les projets LF-AI de la Fondation Linux).
Les bases de données d'abonnement que nous maintenons, D&B Hoovers pour les données financières, Dow Jones Factiva pour les flux de transactions et Questel pour les paysages de brevets, ont fourni des signaux quantitatifs supplémentaires sur la dynamique des revenus des fournisseurs et l'intensité de l'innovation.
Les sources citées illustrent l'étendue des documents consultés ; de nombreuses références supplémentaires ont soutenu la collecte, la validation et la clarification des données.
Dimensionnement du marché et prévisions
Nous employons une approche mixte descendante et ascendante. Les dépenses mondiales en logiciels d'entreprise et les données de facturation du cloud public établissent le bassin de demande, qui est ensuite validé par rapport aux prix de vente moyens échantillonnés multipliés par le volume de déploiement des fournisseurs sélectionnés. Les variables clés de notre modèle comprennent (1) le nombre moyen de jetons générés par utilisateur par mois, (2) la part des déploiements fonctionnant sur des clusters privés par rapport au cloud public, (3) le nombre moyen de paramètres livrés dans les versions commerciales, (4) la croissance des contrats de services d'ajustement fin, et (5) les incitations des politiques régionales d'IA. La régression multivariée combinée à l'analyse de scénarios projette chaque moteur jusqu'en 2030 ; le consensus des analystes issu de la recherche primaire informe le scénario de base, tandis que les plages de sensibilité capturent la volatilité. Lorsque les regroupements de fournisseurs manquent de divulgation complète, les valeurs partielles sont comblées à l'aide de ratios standard du secteur dérivés des années auditées précédentes.
Validation des données et cycle de mise à jour
Les résultats passent des contrôles d'anomalies par rapport à des métriques indépendantes telles que les expéditions de serveurs IA et les heures d'inférence cloud, suivis d'une révision par les pairs à plusieurs niveaux. Les rapports sont mis à jour annuellement, avec des révisions en milieu de cycle déclenchées par des tours de financement importants, des changements réglementaires ou des publications de modèles révolutionnaires. Juste avant la livraison, un analyste relit le fichier afin que les clients reçoivent la vue la plus récente.
Pourquoi notre référence sur les grands modèles de langage est fiable
Les estimations publiées divergent souvent parce que les entreprises choisissent des années de base différentes, regroupent les revenus matériels ou supposent une tarification uniforme.
Les principaux facteurs d'écart comprennent un périmètre plus étroit qui omet les services, une extrapolation agressive de la croissance des jetons sans plafonds sur le nombre de paramètres, et des conversions de devises figées à des taux de change plus anciens avant la récente vigueur du dollar.
Comparaison de référence
| Taille du marché | Source anonymisée | Principal facteur d'écart |
|---|---|---|
| 8,31 milliards USD (2025) | ||
| 6,4 milliards USD (2024) | Cabinet de conseil mondial A | Matériel regroupé, taux de change anciens |
| 5,62 milliards USD (2024) | Cabinet de conseil régional A | Exclut les services d'ajustement fin |
| 5,72 milliards USD (2024) | Revue professionnelle B | Suppose un TCAC uniforme de 40 % sans validation |
La comparaison montre comment les choix de périmètre, les hypothèses de prix et la cadence de mise à jour remodèlent les totaux. La sélection rigoureuse des variables de Mordor, les mises à jour annuelles et la logique de modèle transparente offrent aux décideurs un point de départ fiable et équilibré pour la planification stratégique.


Questions clés auxquelles le rapport répond
Quelle est la valorisation actuelle du marché des grands modèles de langage ?
La taille du marché des grands modèles de langage est de 9,98 milliards USD en 2026 et devrait atteindre 24,92 milliards USD d'ici 2031.
Quelle région connaît la croissance la plus rapide ?
L'Asie-Pacifique mène la croissance avec un TCAC prévu de 31,40 % jusqu'en 2031, soutenu par les investissements gouvernementaux et la demande de modèles multilingues.
Pourquoi les déploiements en périphérie sont-ils importants pour la croissance future ?
Les modèles en périphérie offrent une latence plus faible, une meilleure confidentialité et des coûts de bande passante réduits, menant le segment de déploiement avec une perspective de TCAC de 27,25 %.
Quel secteur vertical investira le plus agressivement ?
La santé devrait croître à un TCAC de 25,95 % grâce aux applications de soutien à la décision clinique, d'accélération de la recherche et d'engagement des patients.
Comment les réglementations influenceront-elles l'adoption ?
Des politiques telles que les mesures provisoires chinoises et la loi européenne sur l'IA encouragent la formation locale, augmentent les coûts de conformité et orientent les acheteurs vers des modèles explicables hébergés régionalement.
Les modèles plus petits remplacent-ils les modèles géants ?
Les entreprises privilégient les modèles de moins de 100 milliards de paramètres pour une inférence rentable, mais les modèles ultra-larges de plus de 300 milliards de paramètres dominent toujours les tâches de raisonnement complexe et croissent à un TCAC de 29,05 %.
Dernière mise à jour de la page le:




