Taille et parts du marché de l'IA dans les sciences de la vie
VUE D’ENSEMBLE DU MARCHÉ
| Période d'étude | 2020 - 2031 |
|---|---|
| Taille du Marché (2026) | 4.51 Milliards de dollars |
| Taille du Marché (2031) | 13.64 Milliards de dollars |
| Taux de croissance (2026 - 2031) | 24.78% CAGR |
| Marché à la Croissance la Plus Rapide | Asie-Pacifique |
| Plus Grand Marché | Amérique du Nord |
| Concentration du Marché | Moyen |
Acteurs majeurs *Avis de non-responsabilité : les principaux acteurs sont triés sans ordre particulier Image © Mordor Intelligence. La réutilisation nécessite une attribution sous CC BY 4.0. | |
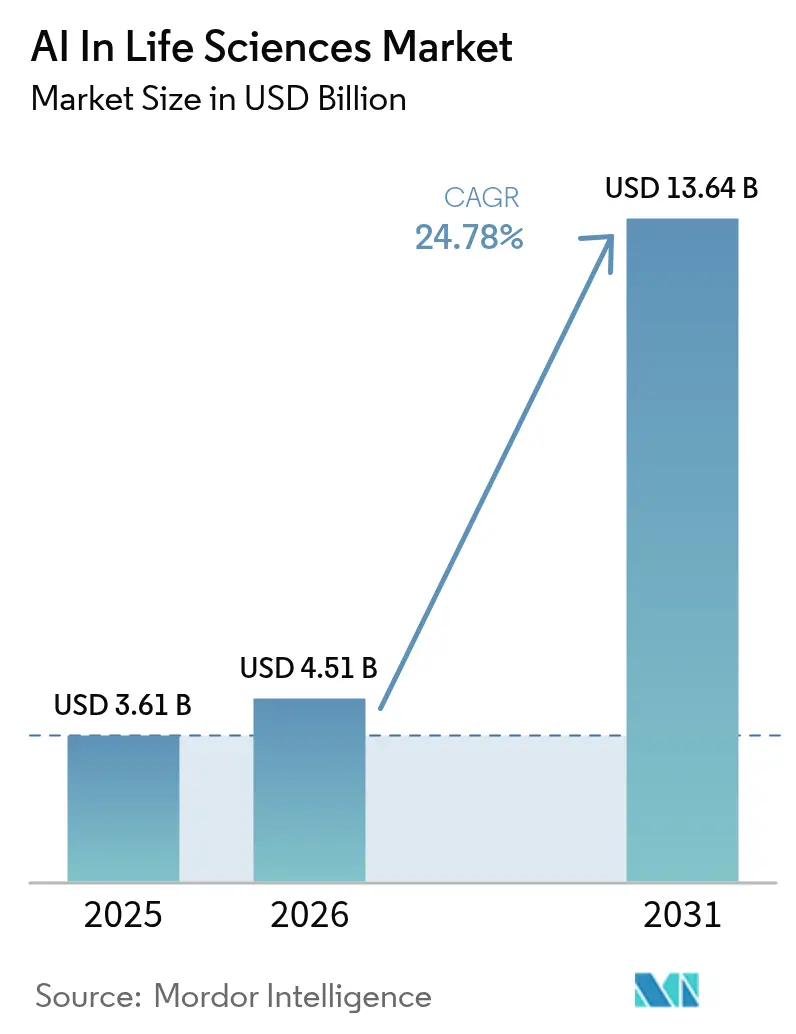
Analyse du marché de l'IA dans les sciences de la vie par Mordor Intelligence
La taille du marché de l'IA dans les sciences de la vie était évaluée à 3,61 milliards USD en 2025 et devrait croître de 4,51 milliards USD en 2026 pour atteindre 13,64 milliards USD d'ici 2031, à un CAGR de 24,78 % durant la période de prévision (2026-2031). L'adoption s'accélère parce que les régulateurs considèrent désormais les biomarqueurs dérivés de l'IA comme des preuves légitimes, et parce que les réseaux de données fédérés rendent disponibles pour l'entraînement des modèles des ensembles de données cliniques autrefois cloisonnés. Une baisse de 70 % du coût de calcul par molécule, obtenue grâce aux alliances entre hyperscalers et entreprises pharmaceutiques, élargit l'accès à la simulation à grande échelle, tandis que les flux de capital-risque vers les plateformes de conception générative de protéines ont triplé depuis 2024. Dans le même temps, seulement 6 % des données biopharma satisfont aux normes FAIR, mettant en évidence une opportunité parallèle pour les solutions de qualité des données. Sur le plan régional, l'Amérique du Nord maintient des avantages d'échelle en matière de talents et d'infrastructures, mais les programmes gouvernementaux asiatiques se traduisent par les perspectives de croissance les plus rapides.
Principaux enseignements du rapport
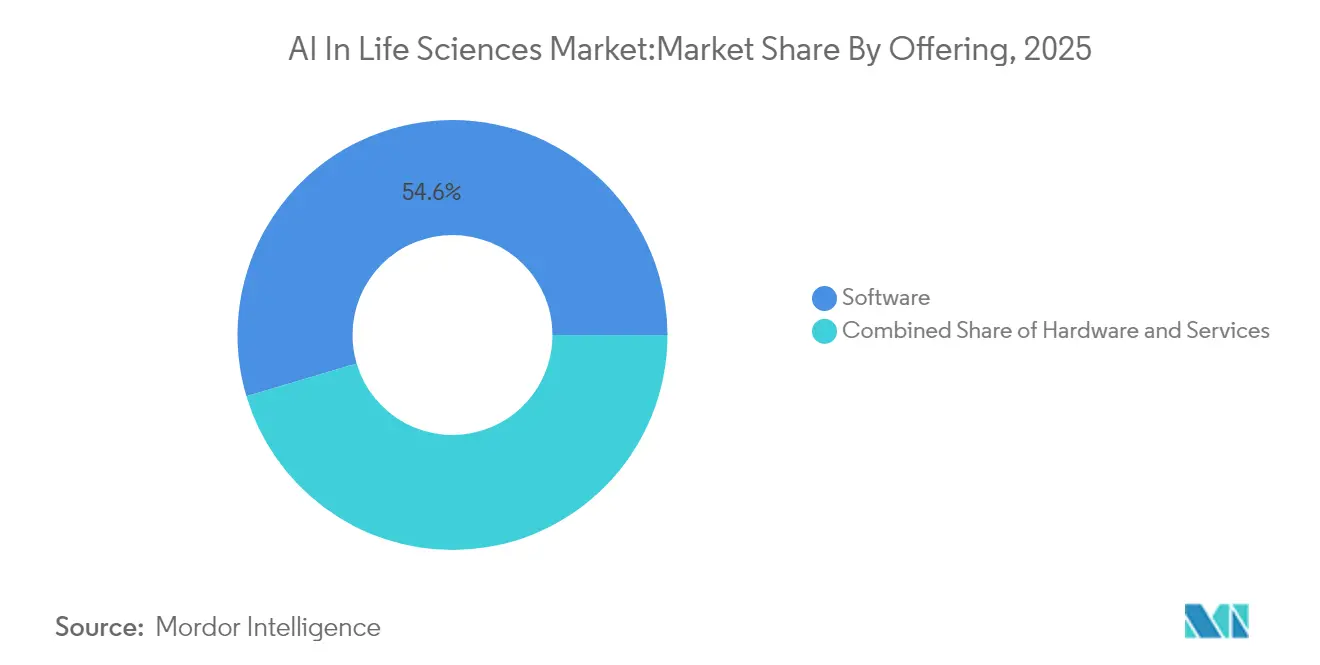
- Par offre, les logiciels ont dominé avec 54,60 % de la part du marché de l'IA dans les sciences de la vie en 2025, tandis que les services devraient enregistrer un CAGR de 22,15 % jusqu'en 2031.
- Par modèle de déploiement, les plateformes cloud représentaient 50,55 % de la base de revenus 2025 ; les solutions sur site sont sur la voie d'un CAGR de 16,3 % sur 2026-2031.
- Par type d'analyse, les systèmes prédictifs ont conservé le leadership en 2025, mais les modèles génératifs sont en passe de connaître la hausse la plus marquée avec un CAGR de 26,1 % jusqu'en 2031.
- Par application, la découverte de médicaments a capturé 25,60 % de la part des revenus en 2025, tandis que l'optimisation des essais cliniques progresse à un CAGR de 20,3 % durant la fenêtre de prévision.
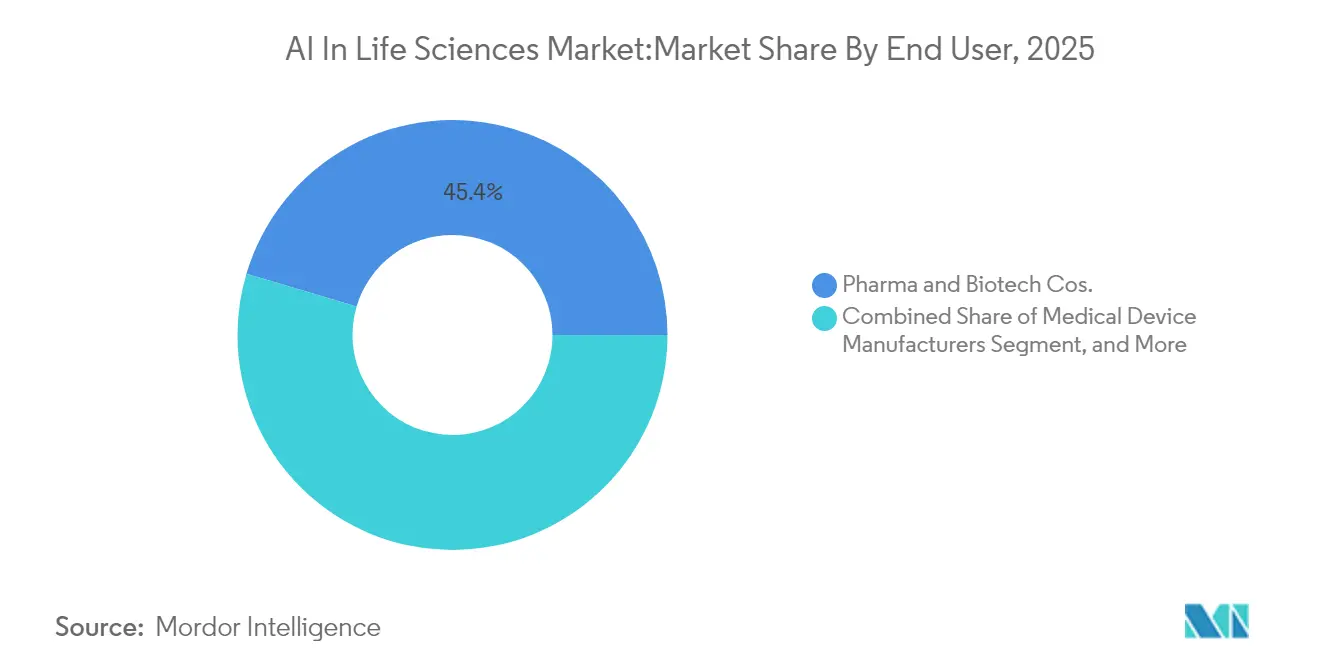
- Par utilisateur final, les entreprises pharmaceutiques et biotechnologiques contrôlaient 45,40 % de la demande 2025 ; les ORC représentent la voie d'expansion la plus rapide avec un CAGR de 17,2 % jusqu'en 2031.
- Par géographie, l'Amérique du Nord commandait 48,60 % de la part des revenus en 2025 ; l'Asie est positionnée pour le CAGR régional le plus élevé de 21,3 % jusqu'en 2031.
Remarque : Les chiffres de la taille du marché et des prévisions de ce rapport sont générés à l’aide du cadre d’estimation propriétaire de Mordor Intelligence, mis à jour avec les données et analyses les plus récentes disponibles en 2026.
Tendances et perspectives mondiales du marché de l'IA dans les sciences de la vie
Analyse de l'impact des moteurs*
| Moteur | ( ~ ) % d'impact sur les prévisions de CAGR | Pertinence géographique | Calendrier d'impact |
|---|---|---|---|
| Approbations de biomarqueurs IA activées par le programme RTOR de la FDA | 5.20% | Amérique du Nord ; répercussions vers l'Europe | Moyen terme (2-4 ans) |
| Entraînement de modèles d'IA fédérés par l'Espace européen des données de santé | 4.80% | Europe ; multinationales mondiales | Long terme (≥ 4 ans) |
| Programmes pilotes Bio-IA de la Chine | 3.70% | Asie, principalement la Chine | Moyen terme (2-4 ans) |
| Partenariats avec les hyperscalers réduisant le coût de calcul | 4.10% | Mondial ; accent sur l'Amérique du Nord et l'Europe | Court terme (≤ 2 ans) |
| Afflux de capital-risque dans la conception générative de protéines | 3.30% | Amérique du Nord et Europe ; Asie émergente | Moyen terme (2-4 ans) |
| Mandats d'essais décentralisés | 2.90% | Premiers adoptants mondiaux | Moyen terme (2-4 ans) |
| Source: Mordor Intelligence | |||
Approbations de biomarqueurs IA activées par le programme RTOR de la FDA
Le programme d'examen oncologique en temps réel de la FDA américaine a raccourci les cycles d'examen pour les biomarqueurs activés par l'IA jusqu'à 40 %, permettant aux programmes oncologiques d'atteindre le marché bien plus tôt que dans le cadre des voies réglementaires traditionnelles. Le précédent réussi en oncologie s'est élargi aux indications neurodégénératives et aux maladies rares en 2024, signalant la confiance du régulateur dans les critères d'évaluation générés par l'IA. Chaque nouvelle approbation crée une valeur en cascade car le biomarqueur validé peut être réutilisé dans des pipelines distincts, accélérant la productivité globale du portefeuille. La FDA établissant le référentiel mondial, d'autres agences évaluent déjà des voies accélérées similaires, mondialisant ainsi l'opportunité.[1]Centre d'évaluation et de recherche sur les médicaments, Administration américaine des aliments et des médicaments, « Programme pilote d'examen oncologique en temps réel », fda.gov.
L'Espace européen des données de santé débloquant l'entraînement de modèles d'IA fédérés
En vigueur depuis janvier 2025, l'Espace européen des données de santé (EEDS) offre aux développeurs en sciences de la vie un accès par API à des ensembles de données cliniques, génomiques et d'imagerie harmonisés dans 27 États membres. De manière cruciale, les règles d'apprentissage fédéré permettent l'entraînement des modèles sans transfert physique de données, préservant la confidentialité tout en éliminant une barrière historique de fragmentation. Les prévisions indiquent 11 milliards EUR d'économies d'efficacité sur dix ans grâce à la réduction des doublons et à une génération de preuves plus rapide. Les premiers adoptants restructurent leurs pipelines afin que les algorithmes puissent apprendre sur site et se mettre à jour de manière centralisée — une approche qui transforme la position stricte de l'Europe en matière de confidentialité en un différenciateur concurrentiel pour les fournisseurs conformes.[2]Commission européenne, « Fiche d'information sur l'Espace européen des données de santé », ec.europa.eu
Le 17e plan quinquennal Bio-IA de la Chine alimentant plus de 200 programmes pilotes
Le dernier plan national de la Chine désigne la convergence IA-biotechnologie comme un pilier stratégique. Plus de 200 projets pilotes couvrent la génomique, la pathologie numérique et la chimie automatisée, soutenus par des subventions et des marchés publics préférentiels. La compétition provinciale pour les financements produit des clusters régionaux denses qui combinent la fabrication locale avec la recherche académique, réduisant la dépendance aux piles logicielles importées. Le plan stratégique vise une augmentation incrémentale de 25 milliards USD pour l'économie nationale des technologies de santé et positionne les fournisseurs chinois pour exporter des solutions d'IA clés en main une fois que l'équivalence réglementaire avec les normes mondiales sera démontrée.[3]Bureau d'information du Conseil d'État de la République populaire de Chine, « 14e et 15e plans quinquennaux pour la bio-économie », gov.cn
Les partenariats avec les hyperscalers réduisant le coût de calcul par molécule de 70 %
Les initiatives d'ingénierie conjointes entre les hyperscalers et les développeurs de médicaments optimisent les configurations matérielles pour les simulations moléculaires, réduisant les dépenses de calcul par molécule d'environ 70 % depuis 2024. Un exemple phare est la collaboration de NVIDIA avec Recursion Pharmaceuticals, associant des clusters GPU personnalisés à des algorithmes de découverte de médicaments basés sur des graphes. L'efficacité des coûts signifie que des bibliothèques de milliards de composés synthétiquement accessibles peuvent être criblées en jours plutôt qu'en mois, améliorant les probabilités de taux de succès et réduisant les délais en phase précoce. Les entreprises bénéficiant d'un accès privilégié à de telles infrastructures remportent un flux de transactions disproportionné, tandis que les pairs plus petits peinent avec des prix au comptant gonflés pour des GPU rares.[4]NVIDIA Corporation, « Recursion et NVIDIA élargissent leur collaboration en matière de calcul », nvidia.com
Analyse de l'impact des freins*
| Frein | ( ~ ) % d'impact sur les prévisions de CAGR | Pertinence géographique | Calendrier d'impact |
|---|---|---|---|
| La loi européenne sur l'IA prolongeant les délais de marquage CE | −3.1% | Europe ; entreprises commercialisant vers l'UE | Moyen terme (2-4 ans) |
| Faible conformité des données biopharma aux normes FAIR | −2.8% | Mondial, en particulier les marchés matures | Court terme (≤ 2 ans) |
| Pénurie de GPU augmentant le coût d'inférence | −2.4% | Mondial ; aigu en Amérique du Nord et en Europe | Court terme (≤ 2 ans) |
| Ambiguïté en matière de propriété intellectuelle sur les molécules générées par l'IA | −1.9% | Asie (Japon et Corée du Sud) | Moyen terme (2-4 ans) |
| Source: Mordor Intelligence | |||
La loi européenne sur l'IA retardant les délais de marquage CE pour les systèmes d'IA cliniques
Classifiant la plupart des algorithmes cliniques comme « à haut risque », la loi européenne sur l'IA, en vigueur depuis août 2024, ajoute des audits de conformité supplémentaires au processus de marquage CE. Les innovateurs plus petits, souvent financés par capital-risque, sont les plus touchés car ils manquent d'équipes réglementaires internes, entraînant des retards de lancement estimés à 6 à 12 mois pour les outils d'imagerie et d'aide à la décision. Bien que les grands fabricants puissent absorber le coût, le goulot d'étranglement réduit temporairement le flux de dispositifs d'IA européens, ce qui ralentit à son tour la génération de données en aval nécessaire au perfectionnement des algorithmes.
Seulement 6 % des données biopharma sont conformes aux normes FAIR
Les enquêtes sectorielles indiquent que seulement 6 % des données actuelles de R&D satisfont aux principes FAIR, limitant la capacité des modèles d'apprentissage automatique à se généraliser entre les cohortes. Les métadonnées insuffisantes, le stockage cloisonné et les ontologies incohérentes gonflent la phase de préparation des données qui précède l'entraînement des modèles. Les organisations qui ont investi tôt dans les graphes de connaissances et les bureaux de gouvernance des données affichent une précision des modèles matériellement plus élevée, soulignant l'argument économique en faveur des améliorations de la qualité. Les fournisseurs proposant des pipelines de curation automatisés et l'alignement des ontologies sont en position de bénéficier de la réorientation des budgets pharmaceutiques vers les actifs de données fondamentaux.
*Nos prévisions considèrent les impacts des moteurs et des contraintes comme directionnels et non additifs. Les prévisions d'impact reflètent la croissance de référence, les effets de composition et les interactions entre variables.
Analyse des segments
Par offre : les logiciels dominent, les services s'accélèrent
Le composant logiciel a généré 54,60 % de la base de revenus 2025, établissant les bibliothèques de code et les suites d'algorithmes comme le principal moteur de valeur au sein du marché de l'IA dans les sciences de la vie. Les plateformes leaders analysent les données omiques, suggèrent des molécules candidates et prédisent la faisabilité du recrutement dans les essais, s'intégrant directement dans les pipelines pharmaceutiques. Les fournisseurs se différencient de plus en plus grâce à des modules d'explicabilité qui documentent la traçabilité des modèles pour les auditeurs. Les services, bien que représentant une part plus modeste, se développent à un CAGR de 22,15 % sur 2026-2031, les clients recherchant des spécialistes en intégration capables d'aligner les résultats de l'IA sur les flux de travail réglementés. Les contrats de services gérés qui regroupent les licences logicielles avec des protocoles de validation et une surveillance des performances post-commercialisation gagnent en popularité car ils transfèrent la charge de conformité des commanditaires aux fournisseurs. Le matériel, bien que modeste en part de revenus, est stratégiquement important. Les cartes accélératrices spécialisées conçues pour les solveurs d'équations différentielles stochastiques et l'amarrage à haut débit répondent aux contraintes actuelles d'approvisionnement en GPU. Les entreprises adoptent des stratégies d'infrastructure mixtes — clusters sur site pour les données sensibles et capacité en rafale vers le cloud pour les grands travaux de criblage — afin de se prémunir contre la volatilité de l'approvisionnement et d'appliquer les règles de résidence des données. La taille du marché de l'IA dans les sciences de la vie attachée aux segments matériels devrait croître à un taux à deux chiffres intermédiaires à mesure que de nouveaux entrants dans les semi-conducteurs lancent des architectures spécifiques au domaine.



Par modèle de déploiement : les plateformes cloud favorisant la collaboration
Les déploiements cloud ont capturé 50,55 % des dépenses en 2025, reflétant la reconnaissance du secteur que l'informatique élastique et la collaboration distribuée l'emportent sur les préoccupations initiales de sécurité. Les hyperscalers proposent désormais des environnements conformes aux données de santé avec des journaux d'audit préconfigurés, réduisant les cycles de validation pour la 21 CFR Partie 11 et le RGPD. Le sandboxing multi-locataires permet aux consortiums académiques et aux biotechs de partager des cohortes dé-identifiées, accélérant l'innovation externe. Les architectures hybrides deviennent cependant la norme. Les organisations conservent les archives génomiques ultra-sensibles sur site mais exécutent des charges de travail analytiques fédérées dans le cloud, améliorant les taux d'utilisation sans sacrifier la souveraineté. Les solutions sur site, stimulées par les réglementations sur le cloud souverain et les cas d'usage critiques en termes de latence, devraient délivrer un CAGR de 16,3 % sur la période. Les silos de données persistants restent un obstacle : 81 % des entreprises interrogées citent la difficulté à réconcilier les données des DSE, d'imagerie et omiques dans un seul environnement. Par conséquent, les fournisseurs de plateformes intègrent des utilitaires d'extraction-transformation-chargement et des mappeurs d'ontologies. Cette dynamique soutient des flux de revenus axés sur les services qui complètent les frais d'abonnement des licences logicielles, ancrant les taux de renouvellement à long terme au sein du marché de l'IA dans les sciences de la vie.
Par type d'analyse : l'IA générative remodèle la découverte
L'analyse prédictive a conservé le leadership en termes de revenus en 2025, soutenue par des modèles statistiques et d'apprentissage automatique qui prévoient la toxicité, la réponse des patients et la dynamique de recrutement dans les essais. Ces capacités sont créditées d'avoir augmenté les chances de succès en Phase II jusqu'à 15 points de pourcentage. Les couches descriptives et prescriptives continuent d'aider à la visualisation des données et aux décisions opérationnelles, notamment dans les boucles de contrôle qualité de la fabrication. Le segment génératif, cependant, connaît la croissance la plus rapide, certains fournisseurs enregistrant un CAGR de 26,1 % jusqu'en 2031. Les modèles de diffusion profonde et les architectures de transformateurs peuvent proposer des bibliothèques viables de petites molécules guidées par des fonctions de fitness multi-objectifs. Lorsqu'ils sont connectés à des robots de synthèse automatisés, les cycles de découverte se compriment de trimestres à semaines, déplaçant le goulot d'étranglement de la génération d'idées vers la validation biologique. La taille du marché de l'IA dans les sciences de la vie transitant par les cas d'usage génératifs devrait représenter une part croissante des dépenses logicielles globales.
Par application : l'optimisation des essais cliniques prend de l'élan
Les applications de découverte de médicaments représentaient 25,60 % du pool de revenus 2025, portées par l'identification de cibles activée par l'IA dans des ensembles de données multi-omiques. L'intégration des réseaux de neurones graphiques avec les règles chéminformatiques a élargi l'exploration des cibles « non druggables ». La part du marché de l'IA dans les sciences de la vie pour l'optimisation des essais cliniques est en passe de progresser à mesure que le segment croît à un CAGR de 20,3 % durant 2026-2031. Les algorithmes qui exploitent les données du monde réel pour affiner les critères d'inclusion réduisent les taux d'échec au criblage, tandis que les dispositifs portables de surveillance à distance alimentent des biomarqueurs continus qui améliorent la détection des signaux de sécurité. Les commanditaires pharmaceutiques rapportent des économies potentielles de 70 % des coûts lorsque les conceptions d'essais adaptatifs réduisent davantage les amendements de protocole. Les diagnostics basés sur l'imagerie, l'optimisation des bioprocédés et l'aide à la décision en médecine personnalisée restent des niches importantes, chacune bénéficiant de l'évolution des modèles fondamentaux vers une multimodalité croissante.
Par utilisateur final : le secteur pharmaceutique en tête, les ORC s'accélèrent
Les entreprises pharmaceutiques et biotechnologiques représentaient 45,40 % des dépenses en 2025, intégrant l'IA dans leurs opérations de R&D, réglementaires, de fabrication et commerciales. Les stratégies doubles sont courantes : centres d'excellence internes pour les ensembles de données propriétaires combinés à des licences externes pour les algorithmes de pointe. Les ORC constituent le groupe de clients à la croissance la plus rapide avec un CAGR de 17,2 % jusqu'en 2031, les commanditaires externalisant les tâches à forte intensité analytique à des partenaires détenant déjà des trésors de données multi-commanditaires. La taille du marché de l'IA dans les sciences de la vie liée aux contrats ORC devrait croître à mesure que les organismes réglementaires encouragent la standardisation des données qui multiplie les insights inter-études. Les fabricants de dispositifs médicaux, les instituts académiques et les payeurs constituent le reste de la demande, stimulant collectivement l'interopérabilité de l'écosystème.
Par technologie : les modèles fondamentaux transformant les capacités
Les cadres d'apprentissage automatique — gradient boosting, forêts aléatoires et réseaux de neurones profonds classiques — fournissent les outils de base pour la reconnaissance de motifs dans les ensembles de données structurées. Le traitement automatique du langage naturel digère désormais les récits cliniques, les rapports d'événements indésirables et les orientations réglementaires à grande échelle. La vision par ordinateur soutient le criblage à haut contenu et l'histopathologie, ajoutant un contexte spatial aux prédictions moléculaires. Les avancées en apprentissage profond ont catalysé des modèles fondamentaux pré-entraînés sur des centaines de millions de séquences protéiques ou de graphes moléculaires, offrant des capacités zéro-shot pour de nouvelles cibles. L'apprentissage par transfert permet un ajustement fin rapide, réduisant considérablement les besoins en données pour les maladies de niche. Les architectures génératives constituent le sous-ensemble technologique à la croissance la plus rapide : les pipelines de diffusion et d'auto-encodeurs variationnels qui intègrent les règles chimiques et les contraintes de synthétisabilité peuvent désormais produire des composés prêts pour le laboratoire in silico. Combinés à des boucles d'apprentissage actif, chaque essai expérimental renvoie des informations que le modèle réintègre en lui-même, renforçant un cycle de découverte vertueux.
Analyse géographique
L'Amérique du Nord commandait 48,60 % des revenus mondiaux 2025, ancrée par une base solide de capital-risque, des codes de remboursement favorables pour les diagnostics numériques et un engagement précoce avec les régulateurs. La taille du marché de l'IA dans les sciences de la vie aux États-Unis seuls est stimulée par le programme RTOR de la FDA, qui valide les biomarqueurs activés par l'IA réutilisables dans plusieurs programmes de développement. Les échanges d'informations de santé entre États permettent des ensembles d'entraînement plus riches, bien que les règles de confidentialité interétatiques compliquent encore la portabilité des données. L'adoption des services cloud dépasse les autres régions car les plans conformes à la HIPAA raccourcissent les audits de conformité, permettant aux biotechs de taille intermédiaire de tirer parti du calcul hyperscale sans construire de clusters internes. L'Europe reste la deuxième région, prête à s'accélérer une fois que les réseaux fédérés de l'EEDS seront à l'échelle. Les consortiums industriels reliant les centres médicaux académiques aux commanditaires pharmaceutiques pilotent l'entraînement transfrontalier préservant la confidentialité, susceptible d'augmenter la part du marché de l'IA dans les sciences de la vie capturée par les fournisseurs européens à mesure qu'ils exploitent leur familiarité réglementaire sur leur marché domestique. Contrebalançant cet élan, la classification à haut risque de la loi sur l'IA introduit des couches de documentation supplémentaires qui peuvent allonger les cycles produits. Les entreprises répondent en intégrant des points de contrôle réglementaires dans les sprints agiles, une pratique qui, bien qu'allongeant les premières itérations, réduit les coûts de remédiation en phase tardive. L'Asie affiche la trajectoire de croissance la plus élevée avec un CAGR de 21,3 % entre 2026-2031. La Chine exploite une politique industrielle coordonnée pour financer des mégaprojets de découverte de médicaments activés par l'IA ; les parcs biotechnologiques provinciaux offrent des exonérations fiscales et l'accès au supercalcul au niveau national. Le Japon et la Corée du Sud se spécialisent dans la robotique et l'automatisation, mais l'ambiguïté persistante en matière de propriété intellectuelle pour les molécules générées par l'IA crée une prime de risque de licence. L'écosystème de recherche sous contrat de l'Inde tire parti de vastes dossiers médicaux en langue anglaise, positionnant le pays comme un hub d'externalisation pour l'entraînement et la validation des algorithmes. Des règles nationales divergentes imposent une approche commerciale pays par pays, mais l'opportunité globale est convaincante, les régions cloud localisées et les initiatives d'IA souveraine débloquant de nouveaux ensembles de données auparavant inaccessibles aux acteurs mondiaux. L'Amérique du Sud et le Moyen-Orient et l'Afrique sont plus modestes aujourd'hui mais constituent d'importants segments frontières. Les programmes nationaux de génomique du Brésil et le projet génome de l'Arabie Saoudite génèrent des ensembles de données spécifiques aux populations qui attirent les développeurs d'IA en quête de diversité dans les données d'entraînement. Les gouvernements allouent des subventions à l'innovation pour attirer des partenariats multinationaux, une tendance qui pourrait augmenter la part de marché combinée des régions au cours de la prochaine décennie à mesure que les infrastructures et les compétences mûrissent.


Paysage concurrentiel
Le marché est modérément consolidé. IBM, IQVIA et Oracle fournissent des plateformes full-stack qui intègrent l'harmonisation des données, l'entraînement des modèles, la validation et la surveillance post-commercialisation. Plutôt que de poursuivre toutes les innovations en interne, ils forment des coentreprises et acquièrent des fournisseurs de niche, créant des effets de réseau grâce à des offres groupées. Les cinq premières entreprises contrôlent collectivement environ 45 % des revenus mondiaux, laissant de la place pour des challengers spécialisés.
La différenciation par la spécialisation est la marque des challengers émergents. Atomwise et Insilico Medicine déploient des systèmes en boucle fermée couplant la chimie générative à la vérification automatisée en laboratoire humide, comprimant les délais en phase précoce de années à mois. Owkin est pionnier dans l'apprentissage fédéré, permettant aux données hospitalières de rester sur site tandis que les paramètres du modèle circulent — une exigence critique dans le cadre du RGPD européen et des régimes similaires. Les crédits cloud des hyperscalers, les participations au capital et les accords de co-commercialisation sont désormais au cœur du positionnement sur le marché car ils offrent aux startups un calcul subventionné pouvant être converti en résultats rapides de preuve de concept.
Les alliances stratégiques dominent également la mise sur le marché. Les commanditaires pharmaceutiques signent des accords multi-cibles et pluriannuels combinant des liquidités initiales avec des jalons échelonnés, alignant les incitations à travers la découverte et le développement. Les méga-transactions récentes confirment que les partenaires IA fournissant des leads validés peuvent capturer des économies comparables aux accords de licence biotechnologique traditionnels. L'intensité concurrentielle se déplace donc de la performance purement algorithmique pour englober les ensembles de données d'entraînement propriétaires, l'accès au calcul et la maîtrise réglementaire.
Leaders du secteur de l'IA dans les sciences de la vie
IBM Corporation
NuMedii Inc.
Atomwise Inc.
AiCure LLC
Nuance Communications Inc.
- *Avis de non-responsabilité : les principaux acteurs sont triés sans ordre particulier

Développements récents du secteur
- Mai 2025 : Incyte et Genesis Therapeutics ont conclu une collaboration avec un paiement initial de 30 millions USD (295 millions USD par cible en jalons) pour déployer la plateforme GEMS pour la découverte de petites molécules.
- Avril 2025 : AstraZeneca et Daiichi Sankyo ont obtenu la révision prioritaire de la FDA pour Enhertu, la première thérapie HER2 agnostique de la tumeur guidée par des biomarqueurs identifiés par l'IA.
- Mars 2025 : Insilico Medicine a lancé PandaOmics Box permettant la découverte de cibles IA sur site pour les clients pharmaceutiques sensibles aux données.
- Février 2025 : Eli Lilly s'est associé à OpenAI pour accélérer la découverte antimicrobienne à l'aide de grands modèles de langage.


Portée du rapport mondial sur le marché de l'IA dans les sciences de la vie
L'intelligence artificielle (IA) dans le secteur des sciences de la vie est utilisée pour diverses applications, telles que la découverte de médicaments, la biotechnologie, le diagnostic médical, les essais cliniques, la médecine de précision et personnalisée, et la surveillance des patients. L'étude catégorise également l'impact de ces applications dans diverses régions. L'IA est une technologie hautement axée sur les données. Dans le secteur des sciences de la vie, elle est couramment employée pour établir des relations significatives à partir de données faiblement couplées. Avec l'introduction de la troisième vague de l'IA, il est anticipé que des solutions d'IA avancées pourront apprendre et évoluer au fur et à mesure qu'elles trouvent de nouvelles applications. L'étude évalue également l'impact de la COVID-19 sur le secteur.
Le marché de l'intelligence artificielle dans les sciences de la vie est segmenté par application (découverte de médicaments, diagnostic médical, biotechnologie, essais cliniques, médecine de précision et personnalisée, surveillance des patients) et par géographie (Amérique du Nord, Europe, Asie-Pacifique, Amérique latine, et Moyen-Orient et Afrique).
Les tailles de marché et les prévisions sont fournies en termes de valeur (millions USD) pour tous les segments ci-dessus.
| Logiciels |
| Services |
| Matériel |
| Cloud / À la demande |
| Sur site |
| Descriptif |
| Prédictif |
| Prescriptif |
| IA générative |
| Découverte de médicaments |
| Diagnostic médical et imagerie |
| Optimisation des essais cliniques |
| Biotechnologie et bioprocédés |
| Médecine de précision et personnalisée |
| Surveillance des patients et données du monde réel |
| Entreprises pharmaceutiques et biotechnologiques |
| Organisations de recherche sous contrat (ORC) |
| Fabricants de dispositifs médicaux |
| Instituts académiques et de recherche |
| Prestataires de soins de santé et payeurs |
| Apprentissage automatique |
| Traitement automatique du langage naturel |
| Vision par ordinateur |
| Apprentissage profond et réseaux de neurones |
| Modèles d'IA générative |
| Amérique du Nord | États-Unis |
| Canada | |
| Europe | Allemagne |
| Royaume-Uni | |
| France | |
| Pays nordiques | |
| Reste de l'Europe | |
| Asie-Pacifique | Chine |
| Japon | |
| Inde | |
| Corée du Sud | |
| Reste de l'Asie-Pacifique | |
| Amérique du Sud | Brésil |
| Reste de l'Amérique du Sud | |
| Moyen-Orient et Afrique | Arabie Saoudite |
| Émirats arabes unis | |
| Afrique du Sud | |
| Reste du Moyen-Orient et de l'Afrique |
| Par offre | Logiciels | |
| Services | ||
| Matériel | ||
| Par modèle de déploiement | Cloud / À la demande | |
| Sur site | ||
| Par type d'analyse | Descriptif | |
| Prédictif | ||
| Prescriptif | ||
| IA générative | ||
| Par application | Découverte de médicaments | |
| Diagnostic médical et imagerie | ||
| Optimisation des essais cliniques | ||
| Biotechnologie et bioprocédés | ||
| Médecine de précision et personnalisée | ||
| Surveillance des patients et données du monde réel | ||
| Par utilisateur final | Entreprises pharmaceutiques et biotechnologiques | |
| Organisations de recherche sous contrat (ORC) | ||
| Fabricants de dispositifs médicaux | ||
| Instituts académiques et de recherche | ||
| Prestataires de soins de santé et payeurs | ||
| Par technologie | Apprentissage automatique | |
| Traitement automatique du langage naturel | ||
| Vision par ordinateur | ||
| Apprentissage profond et réseaux de neurones | ||
| Modèles d'IA générative | ||
| Par géographie | Amérique du Nord | États-Unis |
| Canada | ||
| Europe | Allemagne | |
| Royaume-Uni | ||
| France | ||
| Pays nordiques | ||
| Reste de l'Europe | ||
| Asie-Pacifique | Chine | |
| Japon | ||
| Inde | ||
| Corée du Sud | ||
| Reste de l'Asie-Pacifique | ||
| Amérique du Sud | Brésil | |
| Reste de l'Amérique du Sud | ||
| Moyen-Orient et Afrique | Arabie Saoudite | |
| Émirats arabes unis | ||
| Afrique du Sud | ||
| Reste du Moyen-Orient et de l'Afrique | ||


Questions clés auxquelles répond le rapport
Quelle est la valeur actuelle du marché de l'IA dans les sciences de la vie ?
Le marché est évalué à 4,51 milliards USD en 2026 et devrait s'étendre à 13,64 milliards USD d'ici 2031 à un CAGR de 24,78 %.
Quelle région génère les revenus les plus élevés aujourd'hui ?
L'Amérique du Nord est en tête avec une part de 48,60 % grâce à un fort financement par capital-risque, des incitations réglementaires telles que le programme RTOR de la FDA et une infrastructure cloud mature.
Qu'est-ce qui stimule l'adoption rapide de l'IA dans les essais cliniques ?
Les algorithmes qui affinent les critères d'inclusion, permettent la surveillance à distance et prédisent la faisabilité du recrutement poussent le segment de l'optimisation des essais cliniques à un CAGR de 20,3 % jusqu'en 2031.
Comment l'Espace européen des données de santé influencera-t-il l'adoption de l'IA ?
L'EEDS permet l'apprentissage fédéré dans 27 États membres, réduisant les silos de données tout en préservant la confidentialité et devrait ajouter 11 milliards EUR de gains d'efficacité sur dix ans.
Pourquoi les partenariats de calcul avec les hyperscalers sont-ils importants ?
Les collaborations avec des fournisseurs comme NVIDIA ont réduit le coût de calcul par molécule d'environ 70 %, permettant aux chercheurs en médicaments de cribler des bibliothèques virtuelles bien plus grandes dans des budgets pratiques.
Quels défis pourraient ralentir la croissance du marché ?
Les principaux vents contraires comprennent l'allongement des délais de marquage CE dans le cadre de la loi européenne sur l'IA, la limitation des ensembles de données conformes aux normes FAIR et les pénuries persistantes de GPU haut de gamme qui gonflent les coûts d'inférence.
Dernière mise à jour de la page le:




