Tamanho e Participação do Mercado de Reconhecimento de Voz
Visão Geral do Mercado
| Período de Estudo | 2019 - 2030 |
|---|---|
| Tamanho do Mercado (2025) | 18.39 Bilhões de dólares |
| Tamanho do Mercado (2030) | 51.72 Bilhões de dólares |
| Taxa de crescimento (2025 - 2030) | 22.97% CAGR |
| Mercado de Crescimento Mais Rápido | Ásia-Pacífico |
| Maior Mercado | América do Norte |
| Concentração do Mercado | Médio |
Principais jogadores
*Isenção de responsabilidade: Principais participantes classificados em nenhuma ordem específica Imagem © Mordor Intelligence. O reuso requer atribuição conforme CC BY 4.0. |
|
Análise do Mercado de Reconhecimento de Voz pela Mordor Intelligence
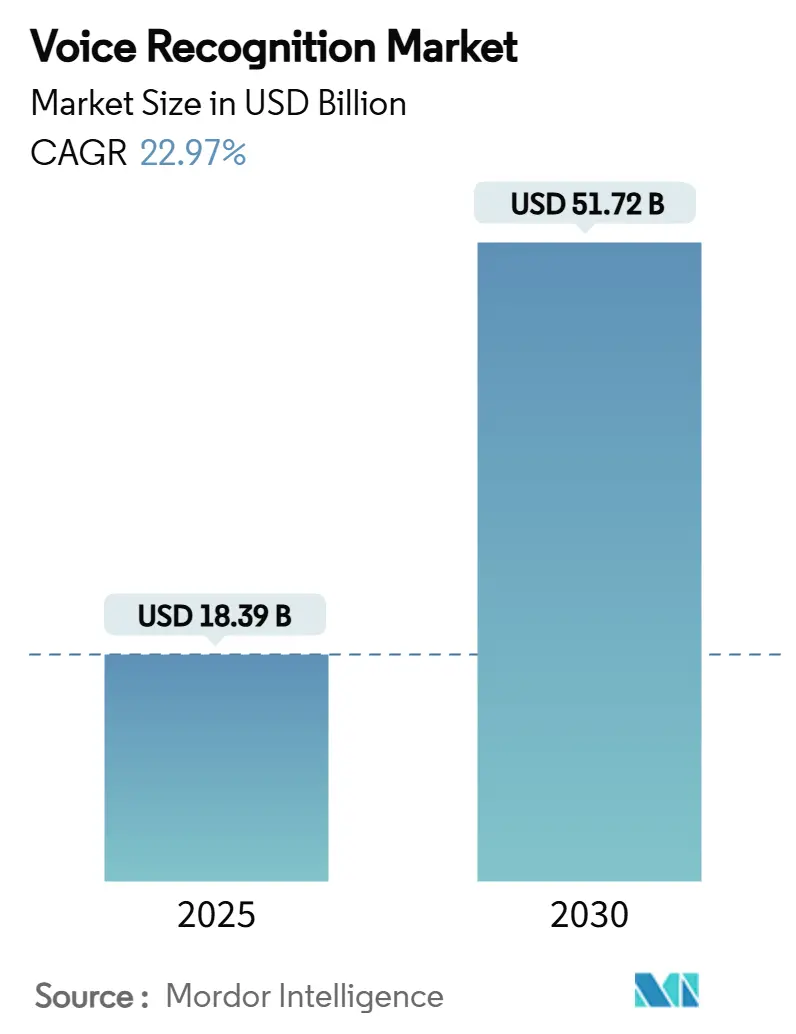
O tamanho do mercado global de reconhecimento de voz atingiu USD 18,39 bilhões em 2025 e está previsto para avançar a uma TCAC de 22,97% para alcançar USD 51,72 bilhões até 2030. A expansão do mercado reflete três forças concorrentes: o rápido lançamento de chipsets de inteligência artificial (IA) edge, pressão regulatória para modernizar redes de comunicações de emergência e migração empresarial para biometria de voz para autenticação de clientes. Arquiteturas centradas em software agora dominam porque 70,7% do valor de mercado está em kits de desenvolvimento de software e plataformas de interface de programação de aplicações, enquanto a implementação em nuvem representa 62,1% das implementações em 2024. Regionalmente, a Ásia liderou com 32,5% da participação de mercado em 2024 devido à demanda de interfaces multilíngues e fortes ecossistemas de fabricação de chips; a tecnologia de reconhecimento de fala permaneceu o principal pilar tecnológico com 81,2% de participação, ainda que o processamento embarcado no dispositivo tenha apresentado a mais rápida TCAC de 25%, mostrando uma mudança decisiva de designs somente na nuvem para motores de inferência híbridos ou totalmente locais.
Principais Destaques do Relatório
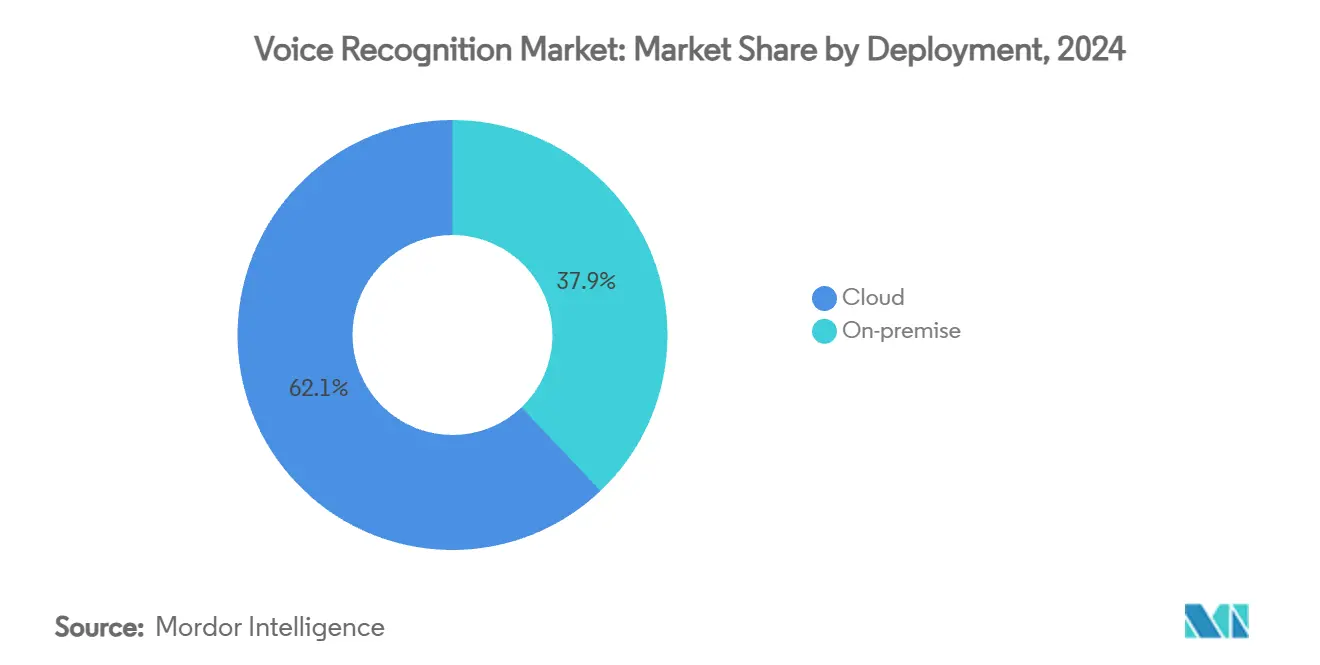
- Por implementação, plataformas em nuvem detiveram 62,1% da participação do mercado de reconhecimento de voz em 2024 e estão projetadas para expandir a uma TCAC de 24,0% até 2030.
- Por componente, software e SDKs lideraram com 70,7% da participação de receita em 2024, enquanto serviços estão posicionados para a mais alta TCAC de 23,7% até 2030.
- Por tecnologia, reconhecimento de fala comandou 81,2% da participação do tamanho do mercado de reconhecimento de voz em 2024, enquanto IA de voz edge embarcada está prevista para crescer 25,0% anualmente até 2030.
- Por dispositivo, smartphones e tablets capturaram 47,4% da participação do mercado de reconhecimento de voz em 2024; wearables exibem a mais rápida TCAC de 24,3% até 2030.
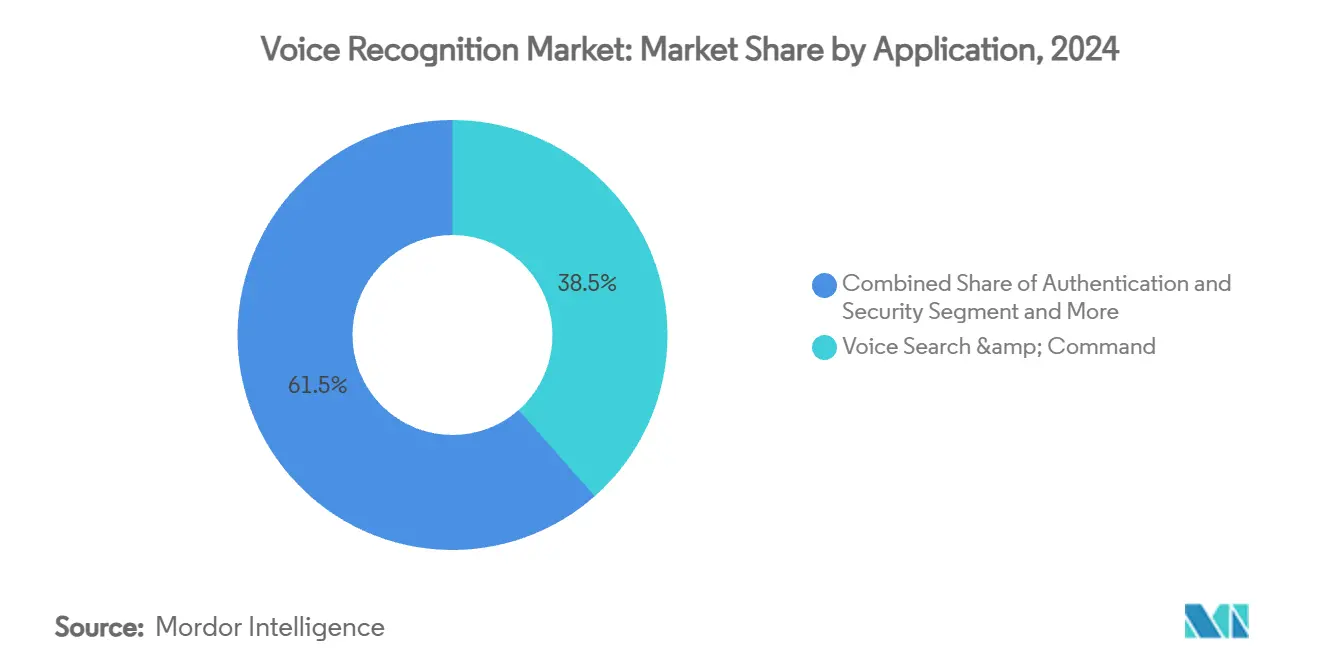
- Por aplicação, busca por voz e comando detiveram 38,5% da participação em 2024, enquanto aplicações de autenticação e segurança estão crescendo a 25,5% TCAC.
- Por vertical de usuário final, eletrônicos de consumo lideraram com 41,1% de participação, ainda que bancário e serviços financeiros seja o crescimento mais rápido a 23,1% TCAC.
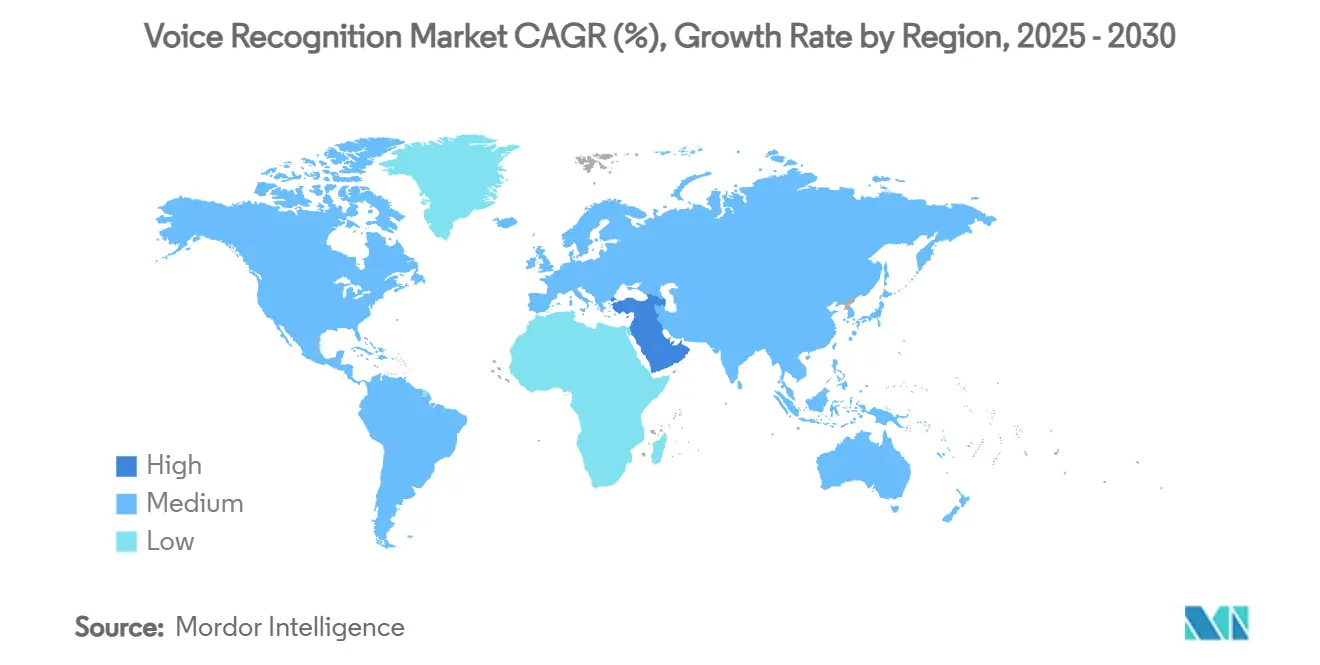
- Por geografia, a Ásia representou 32,5% da receita global em 2024, enquanto o Oriente Médio está registrando uma TCAC de 23,1% até 2030.
Tendências e Insights do Mercado Global de Reconhecimento de Voz
Análise de Impacto dos Direcionadores*
| Direcionador | (~) % Impacto na Previsão TCAC | Relevância Geográfica | Cronograma de Impacto |
|---|---|---|---|
| Explosão de Chips de IA de Voz em Dispositivos Edge na Ásia | +4.2% | Ásia-Pacífico central, expansão para mercados globais | Médio prazo (2-4 anos) |
| Pressão Regulatória para Atualizações de 911 e Despacho de Emergência Habilitados por Voz na América do Norte | +3.8% | América do Norte, com influência regulatória na Europa | Curto prazo (≤ 2 anos) |
| Mudança de OEM Automotivo para OS de Voz Embarcado para Personalização de Cockpit | +5.1% | Global, com adoção antecipada na Europa e América do Norte | Médio prazo (2-4 anos) |
| Adoção BFSI de Biometria de Voz para Substituir Autenticação Baseada em Conhecimento na Europa | + 2.9% | Europa, expandindo para Ásia-Pacífico e América do Norte | Curto prazo (≤ 2 anos) |
| Rápida Proliferação de Comércio de Voz em Residências Centradas em Smart-Speaker | +3.4% | América do Norte e Europa, emergindo na Ásia-Pacífico | Médio prazo (2-4 anos) |
| Crescimento da Demanda de UX de Voz Multilíngue em Mercados Emergentes APAC | + 2.8% | Ásia-Pacífico, com aplicações no Oriente Médio e África | Longo prazo (≥ 4 anos) |
| Fonte: Mordor Intelligence | |||
Explosão de Chips de IA de Voz em Dispositivos Edge na Ásia
O lançamento de 14 chips de fala IA offline pela Chipintelli e o modelo MR Breeze ASR 25 da MediaTek sinalizam investimento crescente em silício especializado otimizado para idiomas regionais.[1]Chipintelli Technology Co. Ltd., "Company Profile," chipintelli.com A localização oferece menor latência, resolve preocupações de privacidade ligadas ao streaming em nuvem e consolida cadeias de suprimento domésticas que historicamente dependiam de hyperscalers norte-americanos. Empresas de semicondutores asiáticas aproveitam essa vantagem para oferecer aos OEMs de dispositivos pilhas de voz completas que lidam com alternância de código em mercados como Indonésia, Vietnã e Índia, reforçando a liderança da região em inovação de inferência edge.
Pressão Regulatória para Atualizações de 911 e Despacho de Emergência Habilitados por Voz na América do Norte
Novas regras da FCC obrigam operadoras americanas a rotear chamadas 911 via Protocolo de Iniciação de Sessão baseado em IP, cortar o desroteamento abaixo de um raio de 165 metros com 90% de confiança e suportar texto e vídeo em tempo real.[2] Federal Communications Commission, "Facilitating Implementation of Next Generation 911 Services," federalregister.gov Fornecedores de reconhecimento de voz posicionados em torno de serviços de emergência ganham uma rampa de receita previsível porque os prazos de conformidade caem dentro de um horizonte de 6-12 meses para operadores nacionais e regionais. O mandato cria um modelo que provavelmente influenciará redes de segurança pública europeias, expandindo a demanda total endereçável para análise de voz que enriquece dados de incidentes com fala transcrita e metadados.
Mudança de OEM Automotivo para OS de Voz Embarcado para Personalização de Cockpit
A implementação over-the-air do Cerence Chat Pro pela Volkswagen ilustra uma mudança estratégica do espelhamento de smartphone para sistemas operacionais de voz profundamente embarcados que infundem perfis de motorista, diagnósticos de veículo e controles de infoentretenimento. O modelo CaLLM Edge da Cerence comprime 3,8 bilhões de parâmetros para executar localmente, reduzindo a dependência da cobertura de rede enquanto preserva a nuance conversacional. OEMs desbloqueiam diferenciação na experiência do usuário e cortam taxas perpétuas de processamento em nuvem, embora gastos iniciais de treinamento de modelo permaneçam altos.
Adoção BFSI de Biometria de Voz para Substituir Autenticação Baseada em Conhecimento na Europa
O compromisso de EUR 34 milhões (USD 37 milhões) do Bank of Ireland com biometria de voz evidencia um movimento amplo de serviços financeiros em direção à autenticação multifator biométrica que reduz tempos médios de manuseio de call center e bloqueia fraudes de engenharia social. Ataques de clonagem de voz, capazes de enganar sistemas com altas taxas de sucesso, têm levado a defesas em camadas que fusionam detecção passiva de vida com análise de comportamento de transação. A tendência acelera a demanda por plataformas integradas que agrupam reconhecimento de fala com pontuação de risco e gestão de consentimento.
Análise de Impacto das Restrições*
| Restrição | (~) % Impacto na Previsão TCAC | Relevância Geográfica | Cronograma de Impacto |
|---|---|---|---|
| Lacunas no Reconhecimento de Sotaque e Dialeto Limitando Adoção na África | -2.1% | África, com efeitos de transbordamento em mercados emergentes | Longo prazo (≥ 4 anos) |
| Regulamentações de Privacidade (GDPR, India DPDP) Restringindo Retenção de Dados de Voz na Nuvem | -3.2% | Europa e Índia, com implicações de conformidade global | Curto prazo (≤ 2 anos) |
| Alto Custo de Corpora de Fala Específicos de Domínio Anotados | -1.8% | Global, com maior impacto em mercados emergentes | Médio prazo (2-4 anos) |
| Atrasos Persistentes de Precisão em Ambientes Industriais Ruidosos | -2.4% | Global, concentrado em regiões de manufatura | Médio prazo (2-4 anos) |
| Fonte: Mordor Intelligence | |||
Lacunas no Reconhecimento de Sotaque e Dialeto Limitando Adoção na África
Testes em 93 sotaques africanos mostraram taxas de erro de entidade médica que ainda requeriam refinamento de 25-34% via ajuste fino específico de sotaque. O dataset de 1.800 horas da NaijaVoices cortou taxas de erro de palavra para modelos Whisper em 75,86%, mas o custo e complexidade de curar corpora culturalmente ricos tornam lentos os lançamentos comerciais. A rodada seed de USD 1,6 milhão da Intron Health sublinha o reconhecimento de investidores do problema, ainda que também destaque as demandas de capital do treinamento de modelo localizado.
Regulamentações de Privacidade (GDPR, India DPDP) Restringindo Retenção de Dados de Voz na Nuvem
Gravações de voz contam como identificadores biométricos que acionam obrigações elevadas de consentimento, armazenamento e exclusão sob GDPR e Lei de Proteção de Dados Pessoais Digitais da Índia. Não conformidade risca multas de até 4% do faturamento global.[3]HeyData, "Privacy Protection in Voice AI," heydata.eu Fornecedores de nuvem respondem com centros de dados regionalizados e criptografia mais forte, ainda que esses ajustes corroam o benefício de custo do processamento centralizado e acelerem a migração para implementações locais ou híbridas.
*Nossas previsões tratam os impactos dos impulsionadores e restrições como direcionais, e não aditivos. As previsões de impacto refletem o crescimento de base, os efeitos de composição e as interações entre variáveis.
Análise de Segmento
Por Implementação: Dominância da Nuvem Impulsiona Escalabilidade
A entrega em nuvem gerou 62,1% da receita global em 2024, e essa participação está projetada para se ampliar conforme empresas priorizam lançamento rápido, atualizações contínuas de modelo e ampla cobertura de idiomas. Instituições financeiras e provedores de saúde cada vez mais selecionam arquiteturas híbridas que mantêm gravações brutas nas instalações mas agrupam insights de treinamento de modelo na nuvem. A abordagem equilibra conformidade com os ganhos de desempenho de aprendizado agregado. Implementações locais, portanto, permanecem relevantes para mandatos de dados soberanos, explicando por que o segmento ainda posta crescimento de dois dígitos até 2030.
A demanda por endpoints de voz de alta disponibilidade tem levado hyperscalers a expor APIs completas. Consequentemente, o custo total de propriedade cai para empresas de médio porte, e barreiras de entrada diminuem para desenvolvedores independentes. O resultado é um funil de aplicação mais amplo para adoção do mercado de reconhecimento de voz, estendendo além de dispositivos de consumidor para automação de processos, logística e fluxos de trabalho de serviços de campo. O tamanho do mercado de reconhecimento de voz para implementações em nuvem está definido para se aproximar de USD 32 bilhões até 2030, refletindo tanto novas cargas de trabalho quanto expansão de implementações existentes.


Por Componente: Plataformas de Software Permitem Integração
Plataformas de software capturaram 70,7% do gasto global em 2024, uma margem decisiva que sustenta o pivô da indústria de hardware proprietário para ferramentas modulares e amigáveis ao desenvolvedor. A disponibilidade de APIs RESTful e modelos de linguagem pré-construídos remove a necessidade de silício sob medida em muitos casos de uso. Serviços, embora representando uma base menor, sobem a 23,7% TCAC conforme empresas envolvem fornecedores especialistas para ajuste de domínio, adaptação de sotaque e conformidade de segurança.
Hardware mantém relevância onde latência edge, disponibilidade offline ou formação de feixe acústico importam, como em infoentretenimento automotivo ou displays montados na cabeça industriais. Ainda que a maioria dos novos entrantes contorne hardware consumindo ofertas de plataforma-como-serviço, ilustrando uma lacuna crescente entre provedores de software orientados horizontalmente e especialistas de hardware integrados verticalmente.
Por Tecnologia: Reconhecimento de Fala Lidera com Aceleração de IA Edge
Reconhecimento de fala contribuiu com 81,2% da receita de 2024, ainda que sua taxa de crescimento cada vez mais derive de inferência embarcada que move transcrição mais próxima ao microfone. Avanços de compressão de modelo permitem redes de múltiplos bilhões de parâmetros como CaLLM Edge executar em placas de infoentretenimento de veículo ou chipsets de smartwatch sem fallback de nuvem. Execução edge diminui risco de privacidade e latência de rede, fatores-chave para cargas de trabalho de saúde e defesa.
Casos de uso de verificação de falante escalam em paralelo, apoiados por alinhamento regulatório sobre autenticação multifator em finanças. Juntos, os dois sub-segmentos reforçam a premissa comercial de que voz como modalidade requer tanto funções de reconhecimento quanto confirmação de identidade para alcançar aceitação empresarial. O tamanho do mercado de reconhecimento de voz do sub-segmento embarcado está esperado para exceder USD 10 bilhões até 2030, enquanto mantém uma liderança TCAC de 25% sobre alternativas somente na nuvem.
Por Tipo de Dispositivo: Smartphones Dominam conforme Wearables Aceleram
Aparelhos celulares permaneceram a âncora, gerando 47,4% da receita global em 2024. Sua base instalada oferece tanto escala quanto um campo de teste para avanço de modelos acústicos via aprendizado federado. Enquanto isso, wearables postam uma TCAC de 24,3% conforme OEMs embarcam arrays de microfone maiores e aceleradores neurais em fones de ouvido e relógios. A Bose adicionou um estágio de formação de feixe de triplo-microfone em seus QuietComfort Earbuds que permite detecção de palavra de ativação em condições ventosas. A EarFun integrou tradução em tempo real em fones de ouvido de menos de USD 100, sublinhando a democratização de recursos premium.
Sistemas automotivos entregam a próxima onda de volume conforme OEMs padronizam microfones embarcados em níveis de acabamento para alertas de segurança e personalização de cockpit. Fones de ouvido industriais permanecem nicho mas estratégicos, com demanda ligada à inspeção hands-free, assistência remota e conformidade de segurança em configurações ruidosas.
Por Aplicação: Comandos de Busca por Voz Lideram com Crescimento de Segurança
Funções de busca por voz e comando geraram 38,5% da receita de 2024, principalmente através de consultas de smartphone e smart-speaker. Ainda que a mais rápida TCAC de 25,5% ocorra em autenticação e segurança, uma resposta a fraude de call center e requisitos de controle de acesso sem contato em setores bancário e de infraestrutura. Serviços de transcrição aceleram porque mandatos de acessibilidade requerem legendagem multilíngue em streaming de mídia, e porque profissionais legais e médicos buscam documentação automatizada. A adoção em saúde prova-se durável. O Dragon Copilot da Microsoft alivia burnout de médicos redigindo notas diretamente em registros eletrônicos de saúde. O NHS do Reino Unido visa lançamento de voz ambiente até 2027, mostrando momentum para implementações de escala nacional.
Nota: Participações de segmento de todos os segmentos individuais disponíveis na compra do relatório
Por Vertical de Usuário Final: Eletrônicos de Consumo Lideram com Aceleração BFSI
Eletrônicos de consumo detiveram 41,1% da participação em 2024, ancorados em smartphones e expandindo para televisões, eletrodomésticos e hubs de casa inteligente. Automotivo segue de perto, impulsionado por integração de IA generativa que contextualiza comandos de voz com dados de navegação, conforto e entretenimento. Bancário e serviços financeiros, no entanto, registram a mais rápida TCAC de 23,1% impulsionada por autenticação forte de cliente mandatória por reguladores e imperativos de otimização de custos. Entidades de saúde, governo e defesa implementam modalidades de voz para acessibilidade e eficiência operacional. Usuários industriais permanecem restringidos por ruído acústico mas estão testando módulos de cancelamento de interferência que elevam precisão em até 18 pontos percentuais em configurações piloto.
Análise Geográfica
A Ásia gerou 32,5% do faturamento de 2024, refletindo a capacidade de semicondutores da região e diversidade linguística. Política doméstica apoia aceleração de IA; a iniciativa do Japão de financiar modelos de linguagem do Sudeste Asiático é um exemplo. A América do Norte permanece o hub de adoção antecipada de tecnologia mas cedeu participação para a Ásia devido à localização agressiva e menores custos de dispositivos. A Europa cresceu de forma estável, influenciada por adoção temática automotiva e BFSI.
O Oriente Médio exibe a mais rápida TCAC de 23,1% conforme programas de cidade inteligente do Golfo embarcam quiosques conversacionais em infraestrutura de serviços cidadãos. A América do Sul registra crescimento de meados dos adolescentes de busca por voz de e-commerce e autenticação bancária. A África enfrenta um atraso porque a diversidade de sotaques complica modelos universais; no entanto, projetos de linguagem financiados por doadores e atualizações de telecomunicações podem desbloquear demanda latente a partir de 2027.

Cenário Competitivo
O mercado mostra concentração moderada: os cinco principais provedores representam aproximadamente 35-40% da receita agregada, sugerindo uma pontuação de 6 em uma escala de concentração de 10 pontos. Incumbentes de tecnologia asseguram suas posições via amplitude de plataforma, dados proprietários e profundidade de integração, enquanto fornecedores automotivos fazem parceria com especialistas de IA para embarcar OS de voz em painéis. Em janeiro de 2025, a Cerence expandiu colaboração com a NVIDIA para otimizar sua suíte CaLLM no TensorRT-LLM, reforçando seu fosso em inferência de veículo de baixa latência. A rodada Série C de USD 180 milhões da ElevenLabs com valuation de USD 3,3 bilhões demonstra capital fluindo para líderes de síntese de voz de nicho que monetizam economias criativas em vez de fluxos de trabalho gerais de comando e controle.
Estratégia competitiva agora depende de quatro alavancas: (1) dados específicos de domínio que aumentam precisão em verticais de alto valor, (2) cobertura multilíngue para mercados emergentes, (3) arquiteturas que preservam privacidade como aprendizado federado, e (4) co-design silício-software para casos de uso edge. Start-ups se diferenciam abordando lacunas de dialeto ou entregando modelos ultra-pequenos para dispositivos alimentados por bateria. Grandes fornecedores de nuvem respondem através de aquisições; por exemplo, a compra da Tenyx pela Salesforce integra agentes de voz conversacionais em seu stack Service Cloud para defender contra plataformas de experiência do cliente.
Líderes da Indústria de Reconhecimento de Voz
-
Apple Inc.
-
Alphabet Inc. (Google LLC)
-
Amazon.com Inc.
-
Nuance Communications Inc. (Microsoft)
-
IBM Corporation
- *Isenção de responsabilidade: Principais participantes classificados em nenhuma ordem específica

Desenvolvimentos Recentes da Indústria
- Janeiro 2025: ElevenLabs fechou uma rodada Série C de USD 180 milhões para acelerar pesquisa de idiomas índicos e expandir serviços de IA de voz empresarial.
- Janeiro 2025: PlayAI levantou USD 21 milhões e revelou um modelo de fala conversacional multi-turno; Meta está reportadamente explorando conversas de aquisição, sinalizando uma corrida por capacidade de interface multimodal.
- Janeiro 2025: Cerence ampliou colaboração com NVIDIA para aprimorar otimização CaLLM no stack NVIDIA AI Enterprise, mirando resposta sub-150 milissegundos em painéis embarcados.
- Novembro 2024: Cerence lançou CaLLM Edge, um modelo de 3,8 bilhões de parâmetros projetado para processamento offline em veículo, reduzindo dependência celular.


Escopo do Relatório do Mercado Global de Reconhecimento de Voz
A capacidade de um computador ou software de aceitar e analisar fala ou reconhecer e seguir instruções verbais é chamada de reconhecimento de voz. Com o surgimento de IA e assistentes inteligentes, incluindo Siri da Apple, Alexa da Amazon e Cortana da Microsoft, o controle por voz aumentou sua importância e uso.
O estudo está Segmentado por Tipo de Implementação (Nuvem, Local), Usuário Final (Automotivo, Bancário, Telecomunicações, Saúde, Governo, Aplicações de Consumidor, Outros Usuários Finais), e Geografia (América do Norte, Europa, Ásia-Pacífico, Resto do Mundo). Os tamanhos e previsões de mercado são fornecidos em termos de valor em USD milhão para todos os segmentos acima.
| Nuvem |
| Local |
| Software/SDK |
| Hardware (ASIC, DSP, Arrays de Microfone) |
| Serviços (Gerenciados e Profissionais) |
| Reconhecimento de Fala |
| Biometria de Falante/Voz |
| IA de Voz Embarcada/Edge |
| Smartphones e Tablets |
| Smart Speakers e Displays |
| Infoentretenimento Automotivo e Telemática |
| Wearables (TWS, Smartwatch, AR/VR) |
| Quiosques Comerciais e PDV |
| Autenticação e Segurança |
| Busca por Voz e Comando |
| Transcrição e Legendagem |
| Assistentes Virtuais e Chatbots |
| Documentação Médica |
| Automotivo |
| Bancário e Serviços Financeiros |
| Telecomunicações |
| Provedores de Saúde |
| Governo e Defesa |
| Eletrônicos de Consumo |
| Varejo e E-commerce |
| Industrial e Manufatura |
| América do Norte | Estados Unidos | |
| Canadá | ||
| México | ||
| América do Sul | Brasil | |
| Argentina | ||
| Resto da América do Sul | ||
| Europa | Reino Unido | |
| Alemanha | ||
| França | ||
| Itália | ||
| Espanha | ||
| Resto da Europa | ||
| Ásia Pacífico | China | |
| Japão | ||
| Índia | ||
| Coreia do Sul | ||
| ASEAN | ||
| Austrália | ||
| Nova Zelândia | ||
| Resto da Ásia Pacífico | ||
| Oriente Médio e África | Oriente Médio | GCC |
| Turquia | ||
| Israel | ||
| Resto do Oriente Médio | ||
| África | África do Sul | |
| Nigéria | ||
| Egito | ||
| Resto da África | ||
| Por Implementação | Nuvem | ||
| Local | |||
| Por Componente | Software/SDK | ||
| Hardware (ASIC, DSP, Arrays de Microfone) | |||
| Serviços (Gerenciados e Profissionais) | |||
| Por Tecnologia | Reconhecimento de Fala | ||
| Biometria de Falante/Voz | |||
| IA de Voz Embarcada/Edge | |||
| Por Tipo de Dispositivo | Smartphones e Tablets | ||
| Smart Speakers e Displays | |||
| Infoentretenimento Automotivo e Telemática | |||
| Wearables (TWS, Smartwatch, AR/VR) | |||
| Quiosques Comerciais e PDV | |||
| Por Aplicação | Autenticação e Segurança | ||
| Busca por Voz e Comando | |||
| Transcrição e Legendagem | |||
| Assistentes Virtuais e Chatbots | |||
| Documentação Médica | |||
| Por Vertical de Usuário Final | Automotivo | ||
| Bancário e Serviços Financeiros | |||
| Telecomunicações | |||
| Provedores de Saúde | |||
| Governo e Defesa | |||
| Eletrônicos de Consumo | |||
| Varejo e E-commerce | |||
| Industrial e Manufatura | |||
| Por Geografia | América do Norte | Estados Unidos | |
| Canadá | |||
| México | |||
| América do Sul | Brasil | ||
| Argentina | |||
| Resto da América do Sul | |||
| Europa | Reino Unido | ||
| Alemanha | |||
| França | |||
| Itália | |||
| Espanha | |||
| Resto da Europa | |||
| Ásia Pacífico | China | ||
| Japão | |||
| Índia | |||
| Coreia do Sul | |||
| ASEAN | |||
| Austrália | |||
| Nova Zelândia | |||
| Resto da Ásia Pacífico | |||
| Oriente Médio e África | Oriente Médio | GCC | |
| Turquia | |||
| Israel | |||
| Resto do Oriente Médio | |||
| África | África do Sul | ||
| Nigéria | |||
| Egito | |||
| Resto da África | |||


Principais Perguntas Respondidas no Relatório
Qual é a avaliação atual do mercado de reconhecimento de voz?
O mercado de reconhecimento de voz está avaliado em USD 18,39 bilhões em 2025 e é esperado alcançar USD 51,72 bilhões até 2030 a uma TCAC de 22,97%.
Qual modelo de implementação detém a maior participação?
Implementação em nuvem lidera com 62,1% de participação em 2024 porque empresas preferem arquiteturas escaláveis e orientadas por API.
Por que wearables são o segmento de dispositivo de crescimento mais rápido?
Wearables postam uma TCAC de 24,3% devido a melhorias em microfones embarcados e aceleradores de IA que permitem tradução e recursos de monitoramento de saúde.
Como as regulamentações de privacidade estão moldando o design do produto?
GDPR e DPDP da Índia restringem retenção de dados de voz, levando fornecedores a adotar processamento edge ou híbrido para minimizar armazenamento em nuvem e custos de conformidade.
Página atualizada pela última vez em:




