Marktgröße und Marktanteil für KI-Rechenhardware
Marktübersicht
| Studienzeitraum | 2020 - 2031 |
|---|---|
| Marktgröße (2026) | 47.43 Milliarden US-Dollar |
| Marktgröße (2031) | 77.55 Milliarden US-Dollar |
| Wachstumsrate (2026 - 2031) | 10.33% CAGR |
| Schnellstwachsender Markt | Asien-Pazifik |
| Größter Markt | Nordamerika |
| Marktkonzentration | Niedrig |
Hauptakteure *Haftungsausschluss: Hauptakteure in keiner bestimmten Reihenfolge sortiert Bild © Mordor Intelligence. Wiederverwendung erfordert Namensnennung gemäß CC BY 4.0. | |
Analyse des Marktes für KI-Rechenhardware von Mordor Intelligence
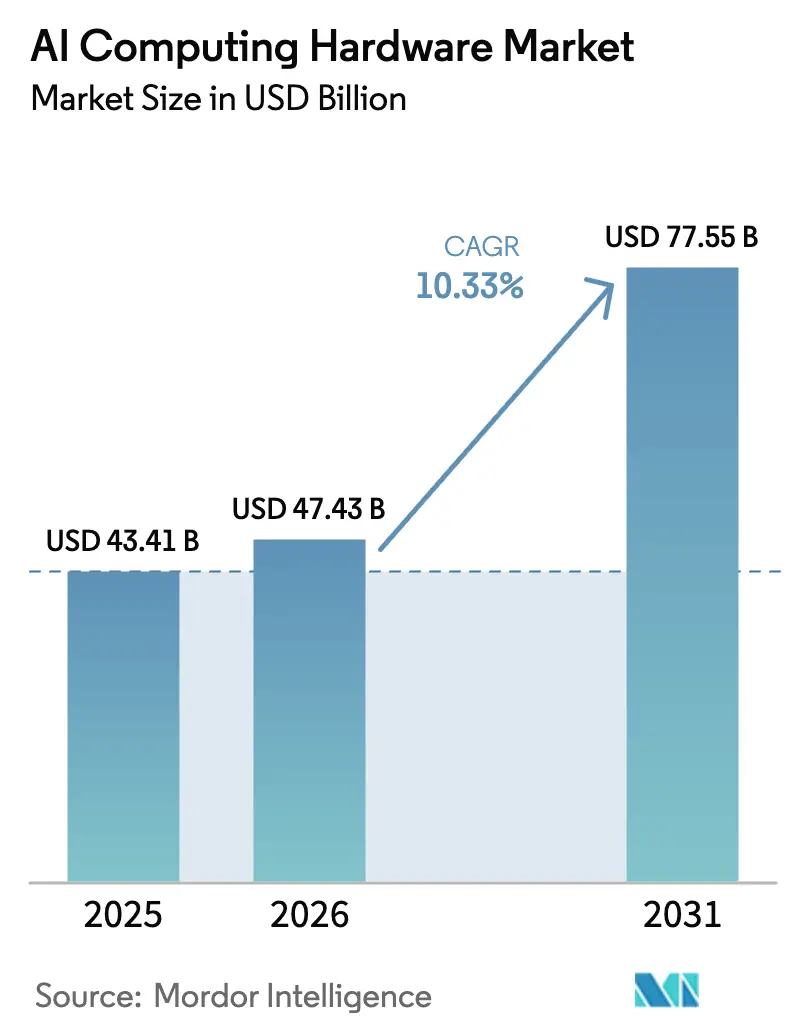
Die Marktgröße für KI-Rechenhardware wird voraussichtlich von 43,41 Milliarden USD im Jahr 2025 auf 47,43 Milliarden USD im Jahr 2026 steigen und bis 2031 77,55 Milliarden USD erreichen, mit einer CAGR von 10,33 % über den Zeitraum 2026–2031.
Das Wachstum folgt einem klaren Wandel im Systemdesign, da Inferenz-Workloads Produktionsbereitstellungen dominieren und die Kapazitätsplanung, Infrastrukturgestaltung und Beschleunigerauswahl neu gestalten. Die Kapitalausgaben der Hyperscaler verstärken diese Entwicklung, mit groß angelegten Programmen, die auf Server, Beschleuniger, Hochgeschwindigkeitsverbindungen und Flüssigkühlung ausgerichtet sind, die eine höhere thermische Designleistung im Rack unterstützen. Jährliche Produktauffrischungszyklen und der Übergang zu integrierten Rack-Scale-Systemen ermöglichen es Betreibern, die Bereitstellungszeit zu verkürzen und Leistungsprofile über regionale Standorte hinweg zu standardisieren. Stromverfügbarkeit, Speicherversorgung und Exportrichtlinien bleiben die primären Reibungspunkte; langfristige Verträge und vorab festgelegte Stromstrategien helfen jedoch, Investitionsentscheidungen im Markt für KI-Rechenhardware zu stabilisieren. Der Markt für KI-Rechenhardware kalibriert sich weiterhin rund um skalierbare, produktionsreife Inferenz als primären Treiber wiederkehrender Ausgaben, und diese Betonung der Echtzeitbereitstellung prägt die thermischen, Netzwerk- und Speicherdesignentscheidungen der Betreiber. Rack-Level-Integration und co-verpackte Optik gewinnen an Bedeutung, da Betreiber bestrebt sind, die Leistung pro Bit zu reduzieren und die Cluster-Resilienz in groß angelegten Trainings- und Inferenz-Fabrics zu verbessern.[1]NVIDIA Newsroom, "OpenAI und NVIDIA kündigen strategische Partnerschaft zur Bereitstellung von 10 Gigawatt NVIDIA-Systemen an," NVIDIA, nvidianews.nvidia.com Strategische Partnerschaften zwischen Chipherstellern und Plattformanbietern unterstreichen den langfristigen Charakter von KI-Ausbauprojekten, einschließlich Verpflichtungen zu Multi-Gigawatt-Bereitstellungen für Systeme der nächsten Generation. Der Markt für KI-Rechenhardware spiegelt daher sowohl technische als auch betriebliche Veränderungen wider, die mit großen, vertraglich gesicherten Nachfrageprofilen in führenden Regionen übereinstimmen.
Wichtigste Erkenntnisse des Berichts
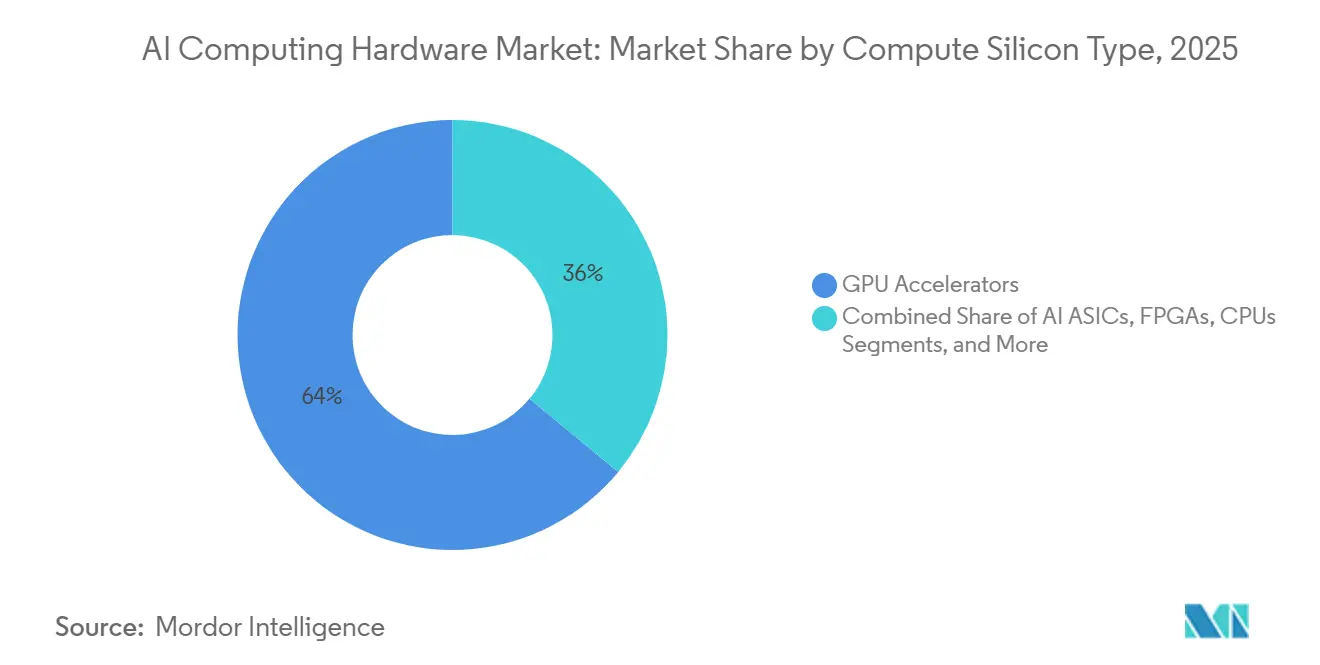
- Nach Compute-Siliziumtyp führten GPU-Beschleuniger im Jahr 2025 mit einem Umsatzanteil von 64 %, während KI-ASICs bis 2031 voraussichtlich mit einer CAGR von 10,6 % wachsen werden.
- Nach Systemformfaktor entfielen auf KI-Server im Jahr 2025 ein Anteil von 78 %, und integrierte Rack-Scale-Plattformen verzeichneten mit einer CAGR von 10,7 % bis 2031 das höchste Wachstum.
- Nach Bereitstellungsstandort hielten Cloud-Rechenzentren im Jahr 2025 einen Anteil von 44 %, während Edge- und Endpunktstandorte mit der schnellsten Rate wuchsen, mit einer CAGR von 10,9 % von 2026 bis 2031.
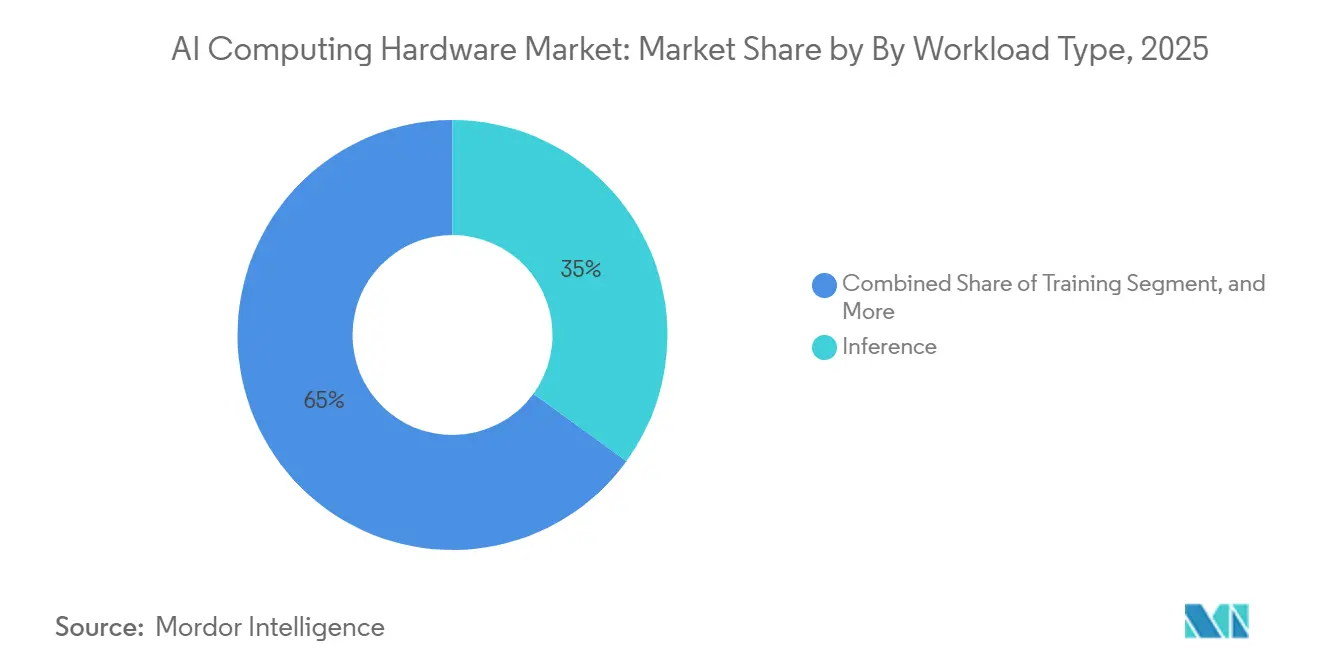
- Nach Workload-Typ erfasste Inferenz im Jahr 2025 einen Anteil von 35 % und wird voraussichtlich bis 2031 mit einer CAGR von 11,2 % wachsen.
- Nach Endbenutzerbranche entfielen auf Hyperscaler und Cloud-Dienstleister im Jahr 2025 57,4 % der Ausgaben, während das Gesundheitswesen und die Biowissenschaften mit einer CAGR von 10,9 % bis 2031 wuchsen.
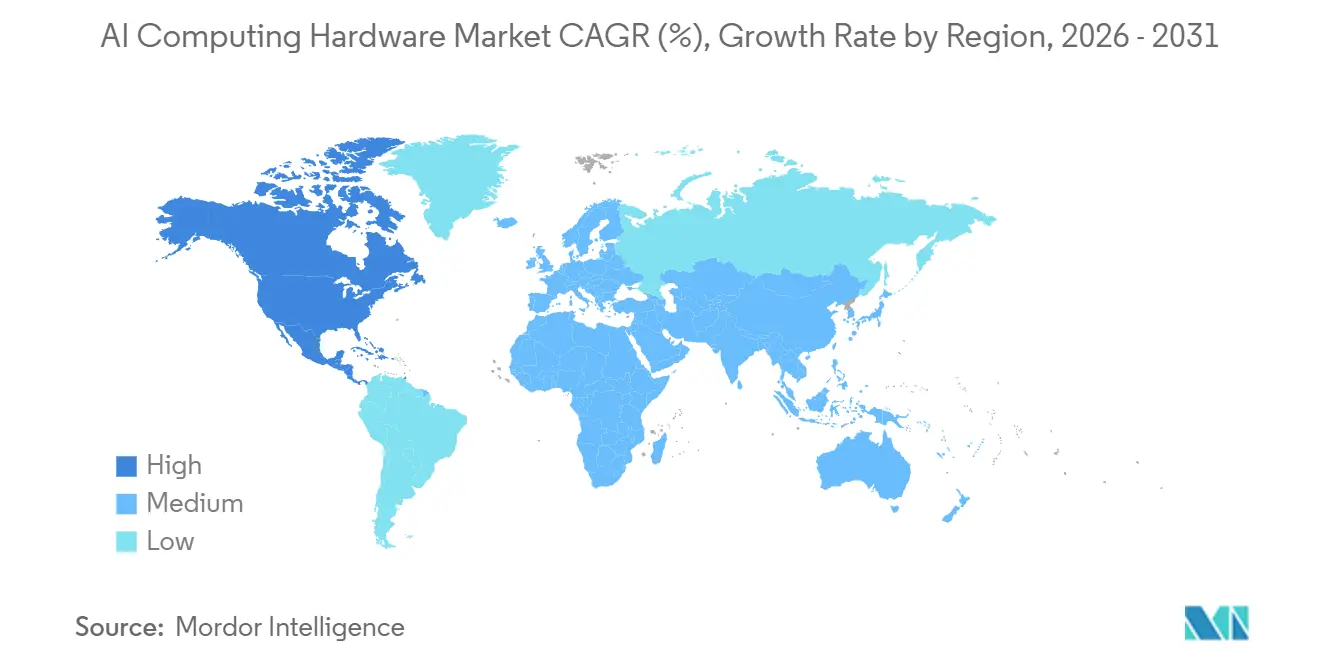
- Nach Geografie entfiel auf Nordamerika im Jahr 2025 ein Anteil von 35,7 %, und der asiatisch-pazifische Raum führt das Wachstum mit einer CAGR von 11,0 % bis 2031 an.
Hinweis: Die Marktgröße und Prognosezahlen in diesem Bericht werden mithilfe des proprietären Schätzungsrahmens von Mordor Intelligence erstellt und mit den neuesten verfügbaren Daten und Erkenntnissen vom Januar 2026 aktualisiert.
Globale Trends und Erkenntnisse im Markt für KI-Rechenhardware
Analyse der Auswirkungen von Treibern*
| Treiber | (~) % Auswirkung auf die CAGR-Prognose | Geografische Relevanz | Zeithorizont der Auswirkung |
|---|---|---|---|
| Ausweitung der Kapitalausgaben für KI-Infrastruktur bei Hyperscalern | +3.2% | Global, konzentriert in nordamerikanischen und asiatisch-pazifischen Hyperscaler-Hubs | Mittelfristig (2–4 Jahre) |
| Verlagerung vom Training zur Inferenz erhöht das Rechenvolumen | +2.8% | Global, mit frühen Gewinnen in Nordamerika, Europa und städtischen asiatisch-pazifischen Märkten | Mittelfristig (2–4 Jahre) |
| Schnelle Produktzyklen bei High-End-KI-GPUs und Rack-Scale-Systemen | +1.7% | Global, angeführt von fortschrittlichen Halbleiterfertigungsknoten in Taiwan und Südkorea | Kurzfristig (≤ 2 Jahre) |
| Beschleunigte Server dominieren die KI-Infrastrukturausgaben | +2.1% | Global, Hyperscale-Rechenzentren in Northern Virginia, Santa Clara, Singapur, Frankfurt | Mittelfristig (2–4 Jahre) |
| Einführung co-verpackter Optik für Hochbandbreiten-Verbindungen | +0.8% | Global, erste Bereitstellung in Hyperscale-KI-Clustern, Nordamerika und Europa führend | Langfristig (≥ 4 Jahre) |
| Durchdringung der Flüssigkühlung erschließt KI-Systeme mit höherer thermischer Designleistung | +1.5% | Global, schnelle Einführung in China, Nordamerika und nordeuropäischen Rechenzentrumskorridoren | Kurzfristig (≤ 2 Jahre) |
| Quelle: Mordor Intelligence | |||
Ausweitung der Kapitalausgaben für KI-Infrastruktur bei Hyperscalern treibt die Nachfrage nach Beschleunigern an
Die Kapitalprogramme der Hyperscaler skalieren weiter, wobei die aggregierten Ausgaben für 2026 in die Hunderte von Milliarden gehen und jährlich im mittleren Dreißig-Prozent-Bereich wachsen. Der Schwerpunkt liegt auf KI-spezifischer Infrastruktur, die Server mit Beschleunigern, Hochgeschwindigkeits-Netzwerk-Fabrics und flüssiggekühlte Rack-Designs umfasst, die eine höhere Dichte pro Rack aufrechterhalten. Mega-Bereitstellungen, die sich zu Multi-Gigawatt-Systemfußabdrücken verpflichten, bestätigen weiterhin das Ausmaß und die Dauerhaftigkeit der Betreibernachfrage in Trainings- und Inferenz-Anwendungsfällen. Strategische Allianzen zwischen Plattformanbietern konzentrieren Investitionen auch in integrierte Lösungen, einschließlich CPU-Plattformkooperationen, die Scale-out-Bereitstellungen in KI-Clustern rationalisieren. Die breitere Einführung von Flüssigkühlung und Rack-Scale-Baugruppen reduziert Bereitstellungsreibung durch Vorintegration thermischer und Stromversorgungssubsysteme für Hochleistungs-Beschleuniger.[2]nVent Electric plc, "nVent stellt neues Flüssigkühlungs- und Stromportfolio auf der SC25 vor," nVent Investor Relations, investors.nvent.com Der Markt für KI-Rechenhardware profitiert von dieser Beschleunigung der Kapitalausgaben, da er von Pilotprojekten zu skalierten Produktionsfußabdrücken in mehreren Regionen übergeht.
Die Verlagerung von Inferenz-Workloads definiert die Rechenzentrumsökonomie neu
Das Gleichgewicht der Rechenzyklen verlagert sich in Richtung Inferenz, was wiederkehrende Verbrauchsmuster antreibt und die Bereitstellungsleistung zur zentralen Designbeschränkung für Flotten macht. Diese Veränderung begünstigt Beschleuniger und Systeme, die auf Kosten pro Token, niedrige Latenz und effiziente Speicherhierarchien ausgerichtet sind, was sich von trainingsoptimierten Profilen unterscheidet. Speicher-Footprints und Bandbreite werden für die schnelle Token-Generierung entscheidend, und neue Speichermodule, die die Zeit bis zum ersten Token verkürzen, verstärken den Wert speicherreicher Designs in Produktionsumgebungen. Die Notwendigkeit, Inferenz näher an die Benutzer zu bringen, erhöht auch die Attraktivität kleinerer, regionaler Bereitstellungen, die Latenz und Stromverfügbarkeit ausbalancieren, ohne die Zuverlässigkeit zu beeinträchtigen. Betreiberstrategien priorisieren nun konsistente Rollouts inferenzfähiger Kapazitäten neben Trainingsclustern, um gleichmäßige Workloads zu bedienen. Der Markt für KI-Rechenhardware spiegelt diese Prioritäten sowohl in Silizium-Roadmaps als auch in integrierten Rack-Angeboten wider, die Rechenleistung, Speicher, Netzwerk und Kühlung konsolidieren.
Schnelle GPU- und Rack-Scale-Produktzyklen verkürzen Auffrischungszyklen
Führende Anbieter arbeiten mit beschleunigten Aktualisierungszyklen für Top-Beschleuniger und Rack-Scale-Systeme, was die Auffrischungsplanung für große Betreiber auf ungefähr jährliche Horizonte komprimiert. Rack-Scale-Plattformen, die Rechenleistung, Hochbandbreiten-Netzwerk und Flüssigkühlung integrieren, ermöglichen eine schnellere Inbetriebnahme und bieten konsistente Leistungsprofile über Einrichtungen hinweg. Co-verpackte Optik entsteht in Rechenzentrum-Fabrics, um die Leistung pro Bit zu reduzieren und die Systemresilienz zu verbessern, und diese Richtung beeinflusst das Netzwerkdesign sowohl für Trainings- als auch für Inferenzcluster. Der Rhythmus wird durch vertikale Partnerschaften unterstützt, die CPU-Plattformen mit KI-Beschleunigern und zugehörigen Fabrics ausrichten, um die Clusterintegration zu vereinfachen.[3]Intel Newsroom, "Intel und NVIDIA entwickeln gemeinsam KI-Infrastruktur und Produkte für das persönliche Computing," Intel, newsroom.intel.com Infolgedessen bewerten Betreiber Full-Stack-Lösungen und vorkonfigurierte Racks, die die Bereitstellungskomplexität reduzieren und gleichzeitig flüssiggekühlte Roadmaps mit höherer thermischer Designleistung unterstützen. Der Markt für KI-Rechenhardware richtet daher Investitionszyklen an schnellen Produkteinführungen aus, um wettbewerbsfähige Leistung und Energieeffizienz aufrechtzuerhalten.
Beschleunigte Server-Architekturen dominieren die KI-Infrastrukturausgaben
Server mit eingebetteten GPUs und benutzerdefinierten Beschleunigern machen den Löwenanteil der neuen KI-Infrastrukturausgaben aus, da große Transformer-Modelle und Scale-out-Training Tausende von eng vernetzten Beschleunigern erfordern. Vorintegrierte Rack-Systeme von führenden Anbietern verkürzen Vorlaufzeiten, indem sie Rechenleistung, Fabrics und Flüssigkühlung in einheitliche Bausteine kombinieren, die im großen Maßstab repliziert werden können. Multi-Gigawatt-Bereitstellungsverpflichtungen führender KI-Entwickler verstärken weiter, dass große, beschleunigerreiche Cluster der primäre Weg sind, um Trainings- und Bereitstellungsziele zu erfüllen. Gleichzeitig unterstützen Netzwerk-Roadmaps, die co-verpackte Optik einführen, die Bandbreite und Zuverlässigkeit, die für All-Reduce- und Echtzeit-Inferenzmuster innerhalb und zwischen Racks erforderlich sind. Das unterstützende Ökosystem für Strom und Kühlung reagiert mit modularen, wartbaren Designs, die auf flüssiggekühlte Racks ausgerichtet sind, die 100 Kilowatt pro Rack überschreiten. Da diese Elemente konvergieren, konsolidiert der Markt für KI-Rechenhardware die Ausgaben rund um beschleunigte Server, Rack-Scale-Architektur und fortschrittliche Verbindungen.
Analyse der Auswirkungen von Hemmnissen*
| Hemmnis | (~) % Auswirkung auf die CAGR-Prognose | Geografische Relevanz | Zeithorizont der Auswirkung |
|---|---|---|---|
| Strom- und Netzengpässe für KI-Rechenzentren | -2.3% | Global, akut in PJM, ERCOT, Northern Virginia; aufkommend in Dublin, Frankfurt, Singapur | Langfristig (≥ 4 Jahre) |
| Versorgungsengpässe bei HBM und fortschrittlicher Verpackung | -1.9% | Globale Lieferkette, Fertigung konzentriert in Südkorea (SK Hynix, Samsung), USA (Micron), Taiwan (TSMC CoWoS) | Mittelfristig (2–4 Jahre) |
| Exportkontrollen und technologische Fragmentierung | -0.7% | US-chinesischer Technologiekorridor, Spillover-Effekte in Europa, Japan, Südkorea | Langfristig (≥ 4 Jahre) |
| Wartbarkeit und Ökosystemkomplexität für fortschrittliche Kühlung | -0.4% | Global, am akutesten in Nachrüstungsszenarien für Altanlagen in Tier-1-Metropolen-Rechenzentrumsmarkten | Mittelfristig (2–4 Jahre) |
| Quelle: Mordor Intelligence | |||
Strom- und Netzengpässe drosseln die Bereitstellungsgeschwindigkeit
Stromverfügbarkeit und Netzanschlusszeitpläne bestimmen, wo und wie Betreiber KI-Kapazitäten bereitstellen, und Engpässe in wichtigen Metropolen verlängern die Inbetriebnahmepläne für große Campusse. Um höhere Dichte und anhaltende Lastprofile zu bewältigen, setzen Betreiber auf Flüssigkühlung und modulare Stromarchitekturen, die auf Beschleuniger-Roadmaps mit höherer thermischer Designleistung ausgerichtet sind. Netzwerkinnovationen wie co-verpackte Optik helfen auch, die Leistungsstrafe pro Bit zu reduzieren, was indirekt die anlagenweiten Energiebudgets am Rand entlastet. Diese Maßnahmen beseitigen keine Standortherausforderungen, verbessern jedoch die Leistungs-pro-Watt-Hülle sowohl für Trainings- als auch für Inferenzcluster. Der Markt für KI-Rechenhardware ist daher empfindlich gegenüber regionalen Netzdynamiken und strebt eine Standardisierung rund um integrierte, flüssiggekühlte Racks an, um konsistentes thermisches und elektrisches Verhalten zu gewährleisten. Große Abnahmeverpflichtungen von KI-Plattformführern signalisieren, dass eine langfristige Kapazitätsplanung im Gange ist, um Netzengpässe durch diversifizierte Standortwahl und stufenweise Ausbauten zu mildern.
Lieferkettenengpässe bei HBM und fortschrittlicher Verpackung schränken die Skalierung ein
Hochbandbreitenspeicher und fortschrittliche Verpackung bleiben limitierende Faktoren für Beschleunigerlieferungen, und das Nachfragewachstum belastet weiterhin die verfügbare Kapazität über kurzfristige Horizonte hinaus. Speicherdichte und Bandbreite sind zentral für die Inferenzeffizienz, und neue energiesparende Module, die für KI-Server vermarktet werden, zielen auf eine schnellere Zeit bis zum ersten Token und verbesserte Leistung pro Watt ab. Anbieter reagieren mit Designentscheidungen, die SRAM, HBM und Verbindungstopologie ausbalancieren, um einen höheren Durchsatz für die Token-Generierung bei vorhersehbaren Leistungsbudgets zu erzielen. Anhaltende Engpässe bei Verpackung und Speicherversorgung leiten Kunden zu längerfristigen Beschaffungsvereinbarungen und Diversifizierungsstrategien. Infolgedessen kalibriert der Markt für KI-Rechenhardware weiterhin Systemdesigns rund um die Speicherverfügbarkeit, während neue Formfaktoren eingeführt werden, die die Wartungskomplexität in flüssiggekühlten Bereitstellungen reduzieren. Exportregelungen fügen eine weitere Planungskomplexitätsebene für die grenzüberschreitende Beschaffung fortschrittlicher Beschleuniger und Komponenten hinzu, was den Wert resilienter lokaler Versorgungsstrategien erhöht.
*Unsere Prognosen behandeln die Auswirkungen von Treibern und Einschränkungen als richtungsweisend und nicht additiv. Die Wirkungsprognosen berücksichtigen Basiswachstum, Mischungseffekte und Wechselwirkungen zwischen Variablen.
Segmentanalyse
Nach Compute-Siliziumtyp: Benutzerdefinierte ASICs fordern GPU-Dominanz trotz unterlegener Ökosysteme heraus
GPU-Beschleuniger werden voraussichtlich im Jahr 2025 mit 64 % den größten Anteil ausmachen, unterstützt durch ausgereifte Software-Stacks und geschultes Ingenieurtalent, das die Wechselkosten hoch hält. KI-ASICs verzeichnen mit einer CAGR von 10,6 % bis 2031 das schnellste Wachstum, da große Betreiber die Effizienz pro Token und eine engere Workload-Ausrichtung für die Produktionsinferenz priorisieren. Im gesamten Markt für KI-Rechenhardware reduzieren von Hyperscalern entworfene Chips die Abhängigkeit von Merchant-Silizium und unterstützen die Optimierung von Strom, Speicher und Netzwerk auf Rack-Ebene. FPGAs bleiben am Edge für deterministische Latenz und Feldrekonfigurierbarkeit in Sicherheits- und Automatisierungsumgebungen relevant. In Client-Geräten eingebettete NPUs adressieren Datenschutz und Latenz für On-Device-Aufgaben innerhalb engerer thermischer und Leistungsbudgets. CPUs verankern weiterhin Steuerungsebenenaufgaben, Speicherorchestrierung und allgemeine Aufgaben, während sie schwere Matrixworkloads an angeschlossene Beschleuniger übergeben.
ASIC-Momentum und GPU-Incumbency koexistieren als Software-Ökosysteme, wobei Entwicklervertrautheit und Anbieter-Toolchains weiterhin Plattformentscheidungen beeinflussen. Interoperabilitätsstandards in Fabrics und Netzwerken sind zu wichtigen Differenzierungsmerkmalen geworden, da Käufer Anbieterabhängigkeit gegen Kosten, Verfügbarkeit und Leistung abwägen. Der Markt für KI-Rechenhardware verzeichnet auch Interesse an aufkommenden Architekturen wie neuromorphen und photonischen Prozessoren, obwohl diese Bemühungen noch in den Anfängen stecken. Für speicherintensive Inferenz betonen Produktentscheidungen Hochbandbreitenspeicherkapazität und Speicherbandbreite zur Aufrechterhaltung des Durchsatzes. Infolgedessen balanciert die Plattformauswahl nun Spitzenrechenleistung gegen Speicher-, Netzwerk- und thermische Eigenschaften, die für die Echtzeitbereitstellung relevant sind. KI-Beschleuniger von führenden Anbietern verankern diese Entscheidungen innerhalb von Rack-Scale-Blueprints, die Rechenleistung, Fabric und Kühlung vereinen.



Nach Systemformfaktor: Rack-Scale-Integration beschleunigt sich, da Leistungsdichteanforderungen Flüssigkühlung erfordern
KI-Server hielten im Jahr 2025 den dominanten Anteil von 78 %, und integrierte Rack-Scale-Lösungen verzeichnen mit einer CAGR von 10,7 % das schnellste Wachstum. GPU-Auffrischungsrhythmus, Speicheranforderungen und thermische Hüllen drängen Betreiber zu vorintegrierten Racks, die vorhersehbare Leistung liefern und die Inbetriebnahme in flüssiggekühlten Umgebungen vereinfachen. In den Jahren 2025 bis 2026 haben mehrere Anbieter Rack-Scale-Plattformen weiterentwickelt, die Beschleuniger, Netzwerk und Kühlung in standardisierte Bausteine konsolidieren, um Kapazitätserweiterungen zu rationalisieren. Dieser Ansatz reduziert das Integrationsrisiko und richtet sich gleichzeitig an standortbezogene elektrische und mechanische Einschränkungen aus. Im Markt für KI-Rechenhardware verbessern Rack-Level-Architekturen auch die Wartbarkeit und reduzieren die Verkabelungskomplexität im Vergleich zu maßgeschneiderten Systemkombinationen.
Beschleunigerkarten und -module bleiben wichtig für Nachrüstungen und inkrementelle Upgrades in Einrichtungen, die noch nicht auf Hochdichte-Racks migriert sind. Edge-Geräte und Gateways füllen latenzempfindliche Rollen, bei denen niedrige Leistungsbudgets und kompakte Formfaktoren wesentlich sind. Der Markt für KI-Rechenhardware profitiert von Anbieterökosystemen, die Referenzdesigns, validierte Fabrics und auf den Rack-Level-Betrieb abgestimmte Kühllösungen umfassen. Da diese Plattformen reifen, schätzen Käufer Interoperabilität und Standardsbeteiligung, die langlebige Bereitstellungen schützen. Anbieter koppeln Silizium-Roadmaps mit Flüssigkühlungs- und Fabric-Strategien, um vorhersehbare Leistung über Produktgenerationen hinweg zu gewährleisten. Co-verpackte Optik wird eine wachsende Rolle in Top-of-Rack- und Spine-Schichten spielen, da die Datenraten steigen und Betreiber sich auf die Leistung pro Bit konzentrieren.
Nach Bereitstellungsstandort: Inferenzmigration zum Edge fragmentiert den zentralisierten Trainings-Footprint
Cloud-Rechenzentren machen im Jahr 2025 einen Anteil von 44 % aus, da Trainings- und große Inferenzcluster zweckgebaute Standorte mit hoher Leistungsdichte und fortschrittlichem Netzwerk bevorzugen. Edge- und Endpunktstandorte wachsen mit einer CAGR von 10,9 % bis 2031 am schnellsten, da latenzempfindliche Inferenz näher an die Benutzer in regionalen Metropolen rückt. Im Markt für KI-Rechenhardware gewährleistet diese Verteilung eine latenzarme Bereitstellung für Anwendungen, die schnelle Token-Generierung und lokale Datenverarbeitung erfordern. Betreiber kombinieren zentralisierte Trainings-Footprints mit verteilter Inferenzkapazität, um sowohl Entwicklungs- als auch Produktionsanforderungen zu erfüllen. On-Premises-Unternehmensbereitstellungen unterstützen regulierte Workloads und Datensouveränitätsmandate.
Altanlagen rüsten weiterhin Strom und Kühlung nach, um Hochdichte-Racks aufzunehmen, während neue Bauten von Anfang an flüssiggekühlte Designs bevorzugen. Die KI-Rechenhardwarebranche konvergiert auf Rack-Scale-Produkte, die Wärmedichte, Wartbarkeit und interoperable Fabrics ausbalancieren. Die Beschaffung umfasst nun längere Planungshorizonte für Strom und Netzanschluss neben mehrjährigen Vereinbarungen für Beschleuniger und Speicher. Strategische Partnerschaften zwischen Anbietern zielen darauf ab, Integrationsreibung zu reduzieren und CPU-, Beschleuniger- und Netzwerk-Roadmaps auszurichten. Der Markt für KI-Rechenhardware verteilt daher Kapazitäten über zentrale Cloud-Hubs und Edge-Standorte, während das Anlagendesign auf Bereitstellungs- und Trainingsrollen ausgerichtet wird.
Nach Workload-Typ: Inferenzdominanz gestaltet Hardwareanforderungen in Richtung Kosten pro Abfrage um
Inferenz hält im Jahr 2025 einen Workload-Anteil von 35 % und wächst mit einer CAGR von 11,2 %, was den kontinuierlichen Charakter von Bereitstellungs-Workloads nach dem anfänglichen Modelltraining widerspiegelt. Diese Realität treibt Designentscheidungen an, die Kosten pro Token, Durchsatz pro Watt und Zeit bis zum ersten Token wertschätzen. Speicherdichte ist ein Differenzierungsmerkmal für das Hosting großer Kontextmodelle in weniger Geräten, und Komponentenanbieter führen energiesparende Module ein, die die Token-Generierung beschleunigen. Der Markt für KI-Rechenhardware balanciert daher Spitzenrechenleistung mit Speicher- und Fabric-Entscheidungen, die gleichmäßige Bereitstellungslasten aufrechterhalten. Training bleibt in großen Standorten mit hoher Stromverfügbarkeit und Bisektionsbandbreitenbedarf zentriert.
Bereitstellungsdeployments bevorzugen regionale Standorte, die Latenz reduzieren und die Benutzererfahrung für Echtzeitanwendungen verbessern. Betreiber standardisieren auf Rack-Scale-Baugruppen, um den Rollout zu vereinfachen und das Inbetriebnahmerisiko über Geografien hinweg zu reduzieren. Netzwerk-Upgrades, einschließlich co-verpackter Optik, verbessern Resilienz und Energieeffizienz bei höheren Verbindungsgeschwindigkeiten. Der Markt für KI-Rechenhardware profitiert von diesen Verbesserungen durch konsistente Skalierungspfade von der Entwicklung zur Produktion.
Nach Endbenutzerbranche: Gesundheitswesen wächst stark, da On-Premises-Compliance die Beschleunigerverbreitung vorantreibt
Hyperscaler und Cloud-Dienstleister machen im Jahr 2025 57,4 % der Ausgaben aus, da Plattformdienste die Nachfrage nach Training und Inferenz aggregieren. Gesundheitswesen und Biowissenschaften verzeichnen bis 2031 eine CAGR von 10,9 % dank diagnostischer Bildgebung, klinischer Entscheidungsunterstützung und Entdeckungs-Workloads, die Hochdurchsatz-, konforme und häufig On-Premises-Bereitstellungen bevorzugen. Der Markt für KI-Rechenhardware liefert Beschleuniger und Rack-Systeme, die Zertifizierungs- und Verfügbarkeitsanforderungen in regulierten Umgebungen erfüllen. Finanzdienstleistungen, Technologieplattformen und Medien erweitern den Einsatz von Inferenz bei der Betrugsprävention, Empfehlungen und Code-Generierung. Automobil und Fertigung integrieren KI über Edge-Workloads für Sicherheit und Inspektion.
In Branchen mit strengen Datensidenzanforderungen bleiben On-Premises-Cluster oder Sovereign-Cloud-Modelle wichtige Beschaffungswege. Der Markt für KI-Rechenhardware unterstützt sowohl den cloudbasierten Zugang zu fortschrittlichen Beschleunigern als auch On-Premises-Konfigurationen, die auf Datenschutz- und Governance-Richtlinien ausgerichtet sind. Anbieterökosysteme helfen Unternehmen, Software-Portabilität und Modellbereitstellung über Standorte hinweg zu navigieren. Käuferpräferenzen spiegeln nun eine Mischung aus Hyperscale-Verbrauch für Frontier-Modelle und lokalisierter Inferenz für Echtzeitaufgaben wider. Infolgedessen übernehmen Branchen Kombinationen aus Cloud-Training und verteilter Bereitstellung, die spezifischen Compliance- und Latenzanforderungen entsprechen.
Geografische Analyse
Nordamerika macht im Jahr 2025 einen Umsatzanteil von 35,7 % aus, da globale Hyperscaler Hauptsitze, Plattform-Engineering und fortschrittliche Designpartnerschaften in der Region konzentrieren. Der asiatisch-pazifische Raum verzeichnet mit einer CAGR von 11,0 % bis 2031 die schnellste Expansion, da Sovereign-Cloud-Initiativen und regionale digitale Dienste lokale Rechen-Footprints vergrößern. Im Markt für KI-Rechenhardware wird das nordamerikanische Wachstum durch Strom- und Netzanschlussengpässe in mehreren Tier-1-Metropolen gedämpft, was zur Diversifizierung in benachbarte Märkte führt. Europa balanciert Datensidenz und Stromverfügbarkeit, und Betreiber verteilen Bereitstellungen über Regionen, die Land, Netzkapazität und erneuerbare Quellen bereitstellen können. Der Nahe Osten investiert weiterhin in groß angelegte KI-Infrastruktur, die westliche Technologie-Stacks ergänzt.
Exportkontrollen prägen Beschaffungs- und Bereitstellungsentscheidungen entlang des US-chinesischen Korridors, was Planungskomplexität für grenzüberschreitende Kapazitätszuweisung und Chip-Verfügbarkeit einführt. Betreiber reagieren, indem sie Multi-Regionen-Ausbauten staffeln und längerfristige Beschaffungsverpflichtungen für Beschleuniger und Komponenten verfolgen. Im asiatisch-pazifischen Raum verstärkt die wachsende Nachfrage nach regionalem Modell-Serving Investitionen in Edge-Standorte, die Latenz und Stromzugang ausbalancieren. Der Markt für KI-Rechenhardware expandiert daher durch einen verteilten Footprint, der Training und Serving über Anlagenklassen segmentiert. Partnerschaften, die große Systembereitstellungen sichern, veranschaulichen das regionsweite Ausmaß zukünftiger Ausbauten über Training und Inferenz hinweg. Insgesamt konvergieren regionale Strategien auf flüssiggekühlte Rack-Scale-Systeme und Hochgeschwindigkeits-Fabrics, um schnelles Wachstum aufrechtzuerhalten.

Wettbewerbslandschaft
Der Markt für KI-Rechenhardware weist eine moderate Konsolidierung auf, wobei ein Anbieter bis 2025 einen Anteil von nahezu 70 % bei KI-Beschleunigern hält und andere durch benutzerdefinierte Silizium-Programme und offene Ökosystem-Positionierung gewinnen. NVIDIA behauptet seine Marktführerschaft mit einem Full-Stack-Ansatz, der GPUs, Fabrics und Software koppelt, was Wechselkosten für Unternehmen und Entwickler schafft. AMD verfolgt einen offenen, interoperablen Ansatz über Scale-up- und Scale-out-Fabrics und kombiniert diesen mit einer Rack-Scale-Plattform, die Flüssigkühlung und Netzwerk als vorkonfigurierten Baustein integriert. Intel und NVIDIA haben eine strategische Zusammenarbeit bei benutzerdefinierten x86-CPUs angekündigt, die in NVIDIA-KI-Plattformen integriert sind, was CPU- und Beschleuniger-Roadmaps für Rechenzentrumsbereitstellungen ausrichtet. Diese Schritte stimmen mit dem Wandel des Marktes hin zu verpackten Rack-Lösungen und integrierten Fabrics überein.
Flüssigkühlungslieferanten und Stromverteilungsanbieter sind für Systemleistung, Wartbarkeit und Verfügbarkeit zentral geworden. Neue Kühlmittelverteilungseinheiten, Verteiler und intelligente Stromverteilungseinheiten werden als modulare Angebote eingeführt, die mit Beschleunigern mit höherer thermischer Designleistung und Rack-Dichten skalieren. Partnerschaften zwischen Kühlungs- und Industrietechnologieunternehmen zielen darauf ab, Referenzarchitekturen für Hyperscale-KI-Standorte zu liefern, was das Designrisiko und die Bereitstellungszeit für Betreiber reduziert. Auf der Netzwerkseite reduziert die Einführung co-verpackter Optik die Leistung pro Bit und verbessert die Fabric-Robustheit, was co-verpackte Optik als kritischen Enabler zukünftiger KI-Fabrics positioniert. Der Markt für Rechenhardware spiegelt daher eine engere Integration über Rechen-, Kühlungs- und Netzwerkanbieter hinweg wider.
Skalenverpflichtungen führender KI-Entwickler gestalten auch die Versorgungsausrichtung neu. Multi-Gigawatt-Partnerschaften setzen neue Baselines für Systembereitstellungs-Footprints und dafür, wie Anbieter CPU-Plattformen, Beschleuniger, Verbindungen und Stromversorgung auf Rack-Ebene koordinieren. Als Reaktion darauf richten Chiphersteller Silizium-Roadmaps an System-Blueprints aus, die Flüssigkühlung, hohe Speicherkapazität und schnelle Fabrics betonen. Offene Software-Stacks und standardsbasierte Fabrics bleiben ein Hebel für Käufer, die hohe Wechselkosten und langfristige Abhängigkeiten vermeiden möchten. Der Markt für KI-Rechenhardware balanciert weiterhin Anbieter-Incumbency mit steigender Nachfrage nach interoperablen und wartbaren Rack-Scale-Systemen, die die Bereitstellung über diverse Geografien hinweg vereinfachen.
Marktführer in der KI-Rechenhardwarebranche
NVIDIA Corporation
Intel Corporation
Huawei Technologies Co., Ltd.
International Business Machines Corporation
Dell Technologies Inc.
- *Haftungsausschluss: Hauptakteure in keiner bestimmten Reihenfolge sortiert

Jüngste Branchenentwicklungen
- Januar 2026: AMD erweiterte sein KI-Portfolio auf der CES 2026 mit Ryzen AI 400 Series Prozessoren und stellte die Ryzen AI Halo Developer Platform vor, einen Mini-PC für die lokale Entwicklung und Inferenz großer Modelle.
- Oktober 2025: AMD stellte auf dem OCP 2025 Summit die Helios Rack-Scale-KI-Plattform vor, die auf Open Rack Wide-Spezifikationen basiert und auf kommenden Instinct-Beschleunigern zentriert ist, mit Schwerpunkt auf offener Interoperabilität für Hyperscale-KI.
- Oktober 2025: Micron gab die Bemusterung seines 192-GB-SOCAMM2-LPDDR5X-Moduls für KI-Rechenzentren bekannt und verwies auf verbesserte Zeit bis zum ersten Token für Echtzeit-Inferenz und Wartbarkeitsgewinne für flüssiggekühlte Server.
- September 2025: Intel und NVIDIA kündigten eine Partnerschaft zur gemeinsamen Entwicklung von KI-Infrastruktur und Produkten für das persönliche Computing an, einschließlich NVIDIA-benutzerdefinierter x86-CPUs, die über NVLink integriert sind, und PC-SoCs mit NVIDIA-GPU-Chiplets.


Globaler Berichtsumfang des Marktes für KI-Rechenhardware
KI-Rechenhardware ist eine Klasse von Mikroprozessoren oder Mikrochips, die für eine schnellere Verarbeitung von KI-Anwendungen entwickelt wurden. Die Studie über den Markt umfasst eigenständige Bildprozessoren und eingebettete Soundprozessoren, unter anderem, die von verschiedenen Akteuren an verschiedene Endbenutzer angeboten werden, darunter BFSI, Automobil, IT und Telekommunikation.
Der Markt für KI-Rechenhardware ist segmentiert nach Compute-Siliziumtyp (GPU-Beschleuniger, KI-ASICs, FPGAs, CPUs, NPUs (Edge), andere Compute-Siliziumtypen), Systemformfaktor (KI-Server, Beschleunigerkarten und -module (PCIe, OAM, SXM), integrierte Systeme und Appliances, Edge-Geräte und Gateways, andere Systemformfaktoren), Bereitstellungsstandort (Cloud-Rechenzentren, Unternehmens- und On-Premises-Rechenzentren, Edge und Endpunkt, andere Bereitstellungsstandorte), Workload-Typ (Training, Inferenz, andere Workload-Typen), Endbenutzerbranche (Hyperscaler und Cloud-Dienstleister, Technologie- und Internetunternehmen, Finanzdienstleistungen, Gesundheitswesen und Biowissenschaften, Automobil und Fertigung, Telekommunikation, Einzelhandel und Verbraucher, öffentlicher Sektor, andere Endbenutzerbranchen) und Geografie (Nordamerika (Vereinigte Staaten, Kanada, Mexiko), Südamerika (Brasilien, Argentinien, Chile, Rest von Südamerika), Europa (Deutschland, Vereinigtes Königreich, Frankreich, Italien, Spanien, Niederlande, Russland, Rest von Europa), asiatisch-pazifischer Raum (China, Japan, Südkorea, Indien, Australien, Singapur, Taiwan, Rest des asiatisch-pazifischen Raums), Naher Osten (Vereinigte Arabische Emirate, Saudi-Arabien, Türkei, Israel, Rest des Nahen Ostens), Afrika (Südafrika, Ägypten, Nigeria, Rest von Afrika)). Die Marktprognosen werden in Wertangaben (USD) bereitgestellt.
| GPU-Beschleuniger |
| KI-ASICs |
| FPGAs |
| CPUs |
| NPUs (Edge) |
| Andere Compute-Siliziumtypen |
| KI-Server |
| Beschleunigerkarten und -module (PCIe, OAM, SXM) |
| Integrierte Systeme und Appliances |
| Edge-Geräte und Gateways |
| Andere Systemformfaktoren |
| Cloud-Rechenzentren |
| Unternehmens- und On-Premises-Rechenzentren |
| Edge und Endpunkt |
| Andere Bereitstellungsstandorte |
| Training |
| Inferenz |
| Andere Workload-Typen |
| Hyperscaler und Cloud-Dienstleister |
| Technologie- und Internetunternehmen |
| Finanzdienstleistungen |
| Gesundheitswesen und Biowissenschaften |
| Automobil und Fertigung |
| Telekommunikation |
| Einzelhandel und Verbraucher |
| Öffentlicher Sektor |
| Andere Endbenutzerbranchen |
| Nordamerika | Vereinigte Staaten |
| Kanada | |
| Mexiko | |
| Südamerika | Brasilien |
| Argentinien | |
| Chile | |
| Rest von Südamerika | |
| Europa | Deutschland |
| Vereinigtes Königreich | |
| Frankreich | |
| Italien | |
| Spanien | |
| Niederlande | |
| Russland | |
| Rest von Europa | |
| Asiatisch-pazifischer Raum | China |
| Japan | |
| Südkorea | |
| Indien | |
| Australien | |
| Singapur | |
| Taiwan | |
| Rest des asiatisch-pazifischen Raums | |
| Naher Osten | Vereinigte Arabische Emirate |
| Saudi-Arabien | |
| Türkei | |
| Israel | |
| Rest des Nahen Ostens | |
| Afrika | Südafrika |
| Ägypten | |
| Nigeria | |
| Rest von Afrika |
| Nach Compute-Siliziumtyp | GPU-Beschleuniger | |
| KI-ASICs | ||
| FPGAs | ||
| CPUs | ||
| NPUs (Edge) | ||
| Andere Compute-Siliziumtypen | ||
| Nach Systemformfaktor | KI-Server | |
| Beschleunigerkarten und -module (PCIe, OAM, SXM) | ||
| Integrierte Systeme und Appliances | ||
| Edge-Geräte und Gateways | ||
| Andere Systemformfaktoren | ||
| Nach Bereitstellungsstandort | Cloud-Rechenzentren | |
| Unternehmens- und On-Premises-Rechenzentren | ||
| Edge und Endpunkt | ||
| Andere Bereitstellungsstandorte | ||
| Nach Workload-Typ | Training | |
| Inferenz | ||
| Andere Workload-Typen | ||
| Nach Endbenutzerbranche | Hyperscaler und Cloud-Dienstleister | |
| Technologie- und Internetunternehmen | ||
| Finanzdienstleistungen | ||
| Gesundheitswesen und Biowissenschaften | ||
| Automobil und Fertigung | ||
| Telekommunikation | ||
| Einzelhandel und Verbraucher | ||
| Öffentlicher Sektor | ||
| Andere Endbenutzerbranchen | ||
| Nach Geografie | Nordamerika | Vereinigte Staaten |
| Kanada | ||
| Mexiko | ||
| Südamerika | Brasilien | |
| Argentinien | ||
| Chile | ||
| Rest von Südamerika | ||
| Europa | Deutschland | |
| Vereinigtes Königreich | ||
| Frankreich | ||
| Italien | ||
| Spanien | ||
| Niederlande | ||
| Russland | ||
| Rest von Europa | ||
| Asiatisch-pazifischer Raum | China | |
| Japan | ||
| Südkorea | ||
| Indien | ||
| Australien | ||
| Singapur | ||
| Taiwan | ||
| Rest des asiatisch-pazifischen Raums | ||
| Naher Osten | Vereinigte Arabische Emirate | |
| Saudi-Arabien | ||
| Türkei | ||
| Israel | ||
| Rest des Nahen Ostens | ||
| Afrika | Südafrika | |
| Ägypten | ||
| Nigeria | ||
| Rest von Afrika | ||


Im Bericht beantwortete Schlüsselfragen
Wie groß ist der aktuelle Markt für KI-Rechenhardware und wie ist der Wachstumsausblick bis 2031?
Die Kategorie steht im Jahr 2026 bei 47,43 Milliarden USD und wird voraussichtlich bis 2031 mit einer CAGR von 10,3 % 77,55 Milliarden USD erreichen.
Welcher Compute-Siliziumtyp führt im Markt für KI-Rechenhardware und welcher wächst am schnellsten?
GPU-Beschleuniger führen mit einem Anteil von 64 % im Jahr 2025, während KI-ASICs mit einer CAGR von 10,6 % bis 2031 am schnellsten wachsen.
Welche Bereitstellungsstandorte werden bis 2031 für KI-Rechenhardware am schnellsten expandieren?
Edge- und Endpunktstandorte steigen mit einer CAGR von 10,9 %, da latenzempfindliche Inferenz näher an die Benutzer rückt, während Cloud-Rechenzentren mit einem Anteil von 44 % im Jahr 2025 die größte Basis bleiben.
Was ist der primäre Workload, der das Systemdesign im Markt für KI-Rechenhardware prägt?
Inferenz ist zentral, mit einem Anteil von 35 % im Jahr 2025 und einer CAGR von 11,2 %, was die Designprioritäten in Richtung Kosten pro Token, Speicherkapazität und Energieeffizienz verschiebt.
Welche Endbenutzersegmente treiben die Nachfrage nach KI-Rechenhardware im Jahr 2025 an?
Hyperscaler und Cloud-Dienstleister machen 57,4 % der Ausgaben im Jahr 2025 aus, und Gesundheitswesen und Biowissenschaften wachsen mit einer CAGR von 10,9 % am schnellsten.
Welche Region führt und welche Region wächst am schnellsten im Bereich KI-Rechenhardware?
Nordamerika führt mit einem Anteil von 35,7 % im Jahr 2025, und der asiatisch-pazifische Raum wächst mit einer CAGR von 11,0 % bis 2031 am schnellsten.
Seite zuletzt aktualisiert am:




