Tamanho e Participação do Mercado de Transformadores de Visão
Visão Geral do Mercado
| Período de Estudo | 2019 - 2030 |
|---|---|
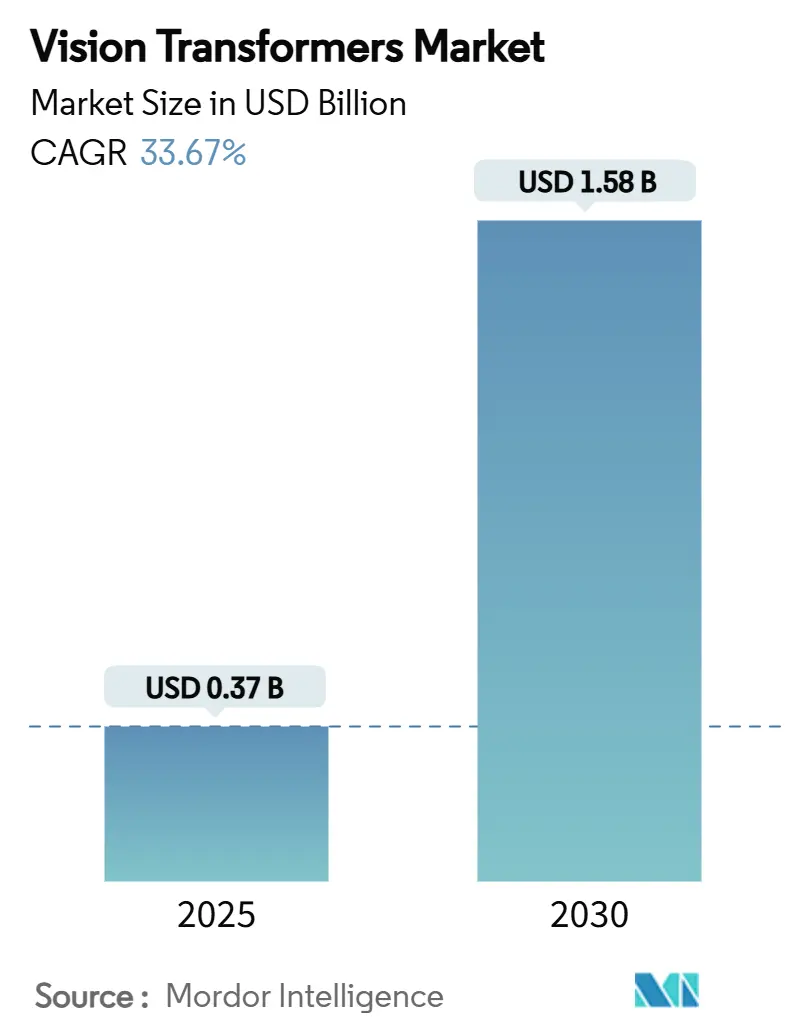
| Tamanho do Mercado (2025) | 0.37 Bilhões de dólares |
| Tamanho do Mercado (2030) | 1.58 Bilhões de dólares |
| Taxa de crescimento (2025 - 2030) | 33.67% CAGR |
| Mercado de Crescimento Mais Rápido | Ásia-Pacífico |
| Maior Mercado | América do Norte |
| Concentração do Mercado | Médio |
Principais jogadores *Isenção de responsabilidade: Principais participantes classificados em nenhuma ordem específica Imagem © Mordor Intelligence. O reuso requer atribuição conforme CC BY 4.0. | |
Análise do Mercado de Transformadores de Visão por Mordor Intelligence
O tamanho do mercado de transformadores de visão está em USD 0,37 bilhão em 2025 e deve superar USD 1,58 bilhão até 2030, expandindo-se a uma CAGR de 33,67%. Essa aceleração reflete um salto de valor de 327% ao longo do período, impulsionado por arquiteturas de transformadores que capturam o contexto global de imagens e superam consistentemente os modelos CNN legados. A crescente demanda empresarial por reconhecimento visual de alta resolução, o lançamento das GPUs H100/H200 e os frameworks de inferência de borda em maturação estão reforçando o momentum. A diferenciação competitiva agora gira em torno de aceleradores de autoatenção otimizados, lançamentos de modelos de código aberto e estratégias de orquestração nuvem-borda. Simultaneamente, as pressões na cadeia de suprimentos em torno de embalagens avançadas e memória de alta largura de banda moderam a capacidade de curto prazo, mas o alívio de preços é projetado à medida que as adições de capacidade na Coreia do Sul e em Taiwan entram em operação. Os ampliados orçamentos governamentais de IA na América do Norte, China, Índia e Japão amplificam os fluxos de financiamento para P&D baseado em transformadores, enquanto a clareza regulatória em torno da implantação no mundo real promove uma adoção empresarial mais ampla.
Principais Conclusões do Relatório
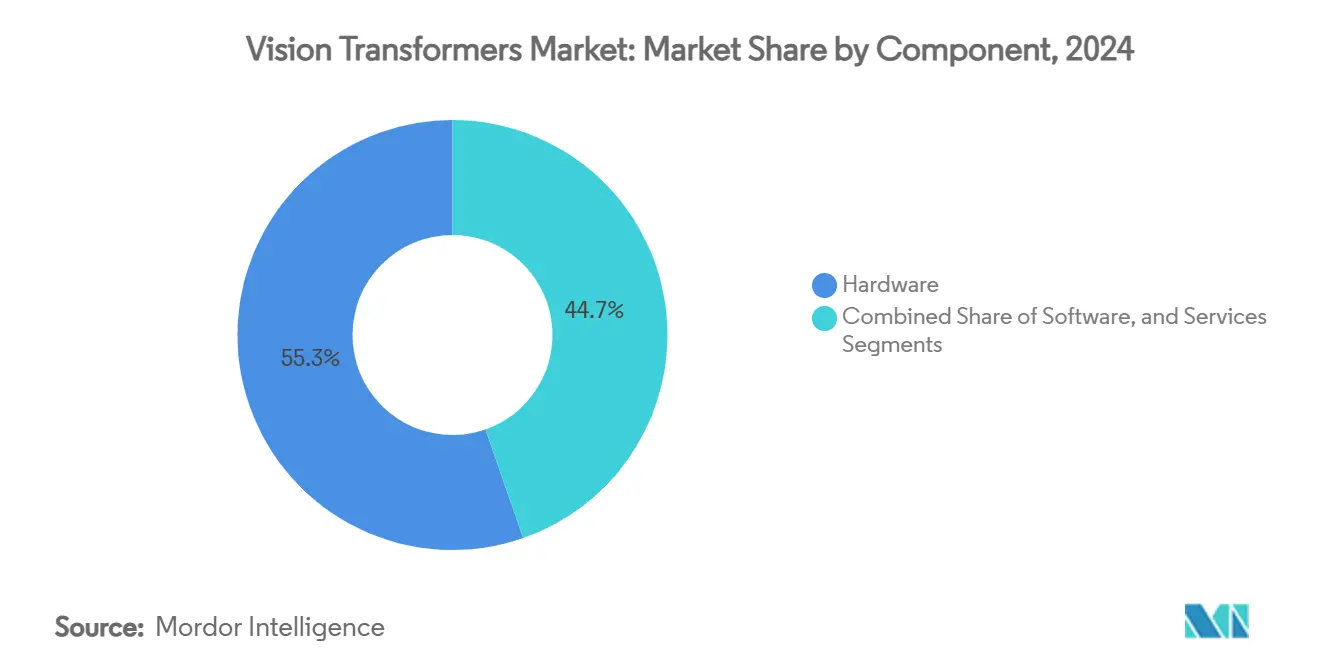
- Por componente, o hardware liderou com 33,34% de participação na receita em 2024, enquanto os chipsets de IA de borda registraram uma CAGR de 33,73% até 2030.
- Por aplicação, a classificação de imagens deteve 46,98% da participação do mercado de transformadores de visão em 2024, e a legendagem de imagens deve crescer a uma CAGR de 33,87% até 2030.
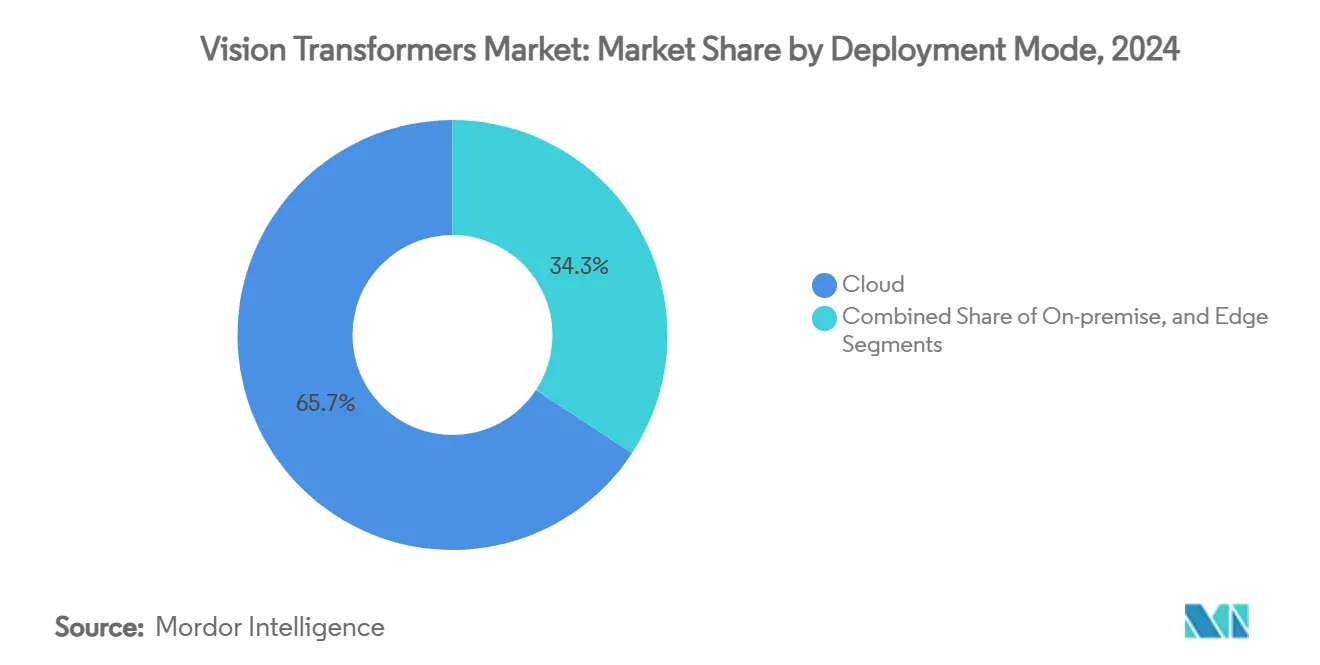
- Por modo de implantação, as plataformas em nuvem capturaram 65,74% da participação do tamanho do mercado de transformadores de visão em 2024; a implantação em borda avança a uma CAGR de 33,79%.
- Por usuário final, saúde e ciências da vida comandaram 28,41% de participação em 2024, enquanto governo e defesa registra a CAGR mais rápida de 33,94% até 2030.
- Por geografia, a América do Norte respondeu por 38,34% do mercado de transformadores de visão em 2024, mas a Ásia-Pacífico deve registrar uma CAGR de 34,17% até 2030.
Tendências e Perspectivas do Mercado Global de Transformadores de Visão
Análise de Impacto dos Impulsionadores*
| Impulsionador | (~) % de Impacto na Previsão de CAGR | Relevância Geográfica | Prazo de Impacto |
|---|---|---|---|
| Adoção generalizada em tarefas de IA centradas em imagens | +8.2% | América do Norte / Europa como pioneiros | Médio prazo (2 a 4 anos) |
| Proliferação de GPUs avançadas, TPUs e chips de IA de borda | +7.8% | Fábricas dos EUA, China e Taiwan | Curto prazo (≤ 2 anos) |
| Necessidade de percepção em tempo real por sistemas autônomos | +6.9% | Centros globais automotivos e de defesa | Médio prazo (2 a 4 anos) |
| Ascensão de pilhas de transformadores multimodais de visão e linguagem | +5.4% | Expansão global para mercados emergentes | Longo prazo (≥ 4 anos) |
| Avanços em esparsidade e quantização orientados à borda | +4.1% | Manufatura da Ásia-Pacífico, P&D da América do Norte | Curto prazo (≤ 2 anos) |
| Modelos ViT fundamentais de código aberto reduzindo barreiras | +3.8% | Mercados em desenvolvimento | Médio prazo (2 a 4 anos) |
| Fonte: Mordor Intelligence | |||
Adoção Generalizada em Tarefas de IA Centradas em Imagens
As implantações empresariais avançaram além dos laboratórios à medida que as empresas relatam ganhos significativos de precisão em fluxos de trabalho visuais complexos. Centros de patologia que implantam modelos de 632 milhões de parâmetros alcançam 94,11% de sensibilidade diagnóstica na detecção de câncer multiclasse, acelerando o suporte à decisão em oncologia. [1]Shakarami, "DepViT-CAD: Transformador de Visão Implantável para Diagnóstico de Câncer," arxiv.orgOs fabricantes integram modelos ricos em atenção para identificar defeitos mínimos de superfície que as CNNs frequentemente perdem, reduzindo o tempo de inspeção manual em 38%. As equipes de back-office financeiro dependem da análise de documentos habilitada por ViT que atinge 98% de precisão no nível de campo, reduzindo erros baseados em papel e agilizando a reconciliação de faturas. Esses ganhos de desempenho estão incentivando os diretores de tecnologia a migrar as operações visuais para backbones de transformadores, reforçando a trajetória do mercado de transformadores de visão.
Proliferação de GPUs Avançadas, TPUs e Chips de IA de Borda
Os ciclos de hardware estão se encurtando à medida que os hiperscalers e os designers de sistema em chip desbloqueiam nova largura de banda de memória e densidade de computação. As placas NVIDIA H200 são listadas a aproximadamente USD 30.000 e entregam 4,8 TB/s de throughput, permitindo que ViTs de 70 bilhões de parâmetros treinem em 30% menos épocas. Simultaneamente, a pilha de inferência Florence-2 da Microsoft demonstra operação de borda de 15 W em dispositivos da classe Raspberry Pi, estendendo a relevância dos transformadores a endpoints com recursos limitados.[2]Hackster.io, "Modelos de Visão e Linguagem na Borda," hackster.io As escassez de memória de alta largura de banda permanecem um gargalo, mas estão diminuindo à medida que novos fornecedores de módulos escalam no Japão e na Coreia do Sul.
Necessidade de Percepção em Tempo Real por Sistemas Autônomos
Programas de direção autônoma, da Tesla a consórcios europeus de comboios de caminhões, dependem de percepção baseada apenas em câmeras, alimentada por ViTs leves que reduzem o custo computacional em 90%, mas mantêm a precisão de contexto. Na defesa, ViTs acelerados por FPGA permitem o reconhecimento de alvos em frações de segundo em feeds de Radar de Abertura Sintética, permitindo que aeronaves de patrulha marítima diferenciem embarcações combatentes de civis em cenas congestionadas. Esses cenários sensíveis à latência ressaltam a demanda por blocos de atenção esparsos e aritmética de precisão mista que comprimem a lógica dos transformadores em orçamentos de energia rigorosos.
Ascensão de Pilhas de Transformadores Multimodais de Visão e Linguagem
Os desenvolvedores estão fundindo transformadores de visão com grandes modelos de linguagem para desbloquear um raciocínio entre domínios mais rico. O Phi-3 Vision de 4,2 bilhões de parâmetros da Microsoft comprime capacidades multimodais em um footprint implantável na borda, enquanto a arquitetura VILA da NVIDIA combina codificadores ViT com decodificadores de linguagem quantizados para se destacar em perguntas e respostas em vídeo, superando baselines maiores. Mecanismos de busca de comércio eletrônico que usam alinhamento imagem-texto registram um aumento de 4,95% na taxa de cliques, pois os compradores recebem correspondências visuais mais relevantes. A tração multimodal amplia a base endereçável do mercado de transformadores de visão, tocando fluxos de trabalho de atendimento ao cliente, robótica e moderação de conteúdo.
Análise de Impacto das Restrições*
| Restrição | (~) % de Impacto na Previsão de CAGR | Relevância Geográfica | Prazo de Impacto |
|---|---|---|---|
| Alto custo de computação e consumo de energia | -4.7% | Economias em desenvolvimento mais afetadas | Curto prazo (≤ 2 anos) |
| Requisitos de pré-treinamento com grande volume de dados | -3.2% | Verticais específicas de domínio | Médio prazo (2 a 4 anos) |
| Emaranhados de patentes de propriedade intelectual de aceleração de atenção | -2.1% | Litígios nos EUA e na UE | Longo prazo (≥ 4 anos) |
| Riscos regulatórios e de segurança decorrentes de alucinações de transformadores | -1.8% | América do Norte e Europa | Médio prazo (2 a 4 anos) |
| Fonte: Mordor Intelligence | |||
Alto Custo de Computação e Consumo de Energia
Os preços dos nós de GPU H100 baseados em nuvem variam entre USD 2,80 e USD 10,00 por hora, colocando a experimentação fora do alcance de empresas menores.[3]Cyfuture Cloud, "Preço da GPU Nvidia H100 em 2025," cyfuture.cloud O consumo de energia dos data centers também aumenta acentuadamente: um ViT de 70 bilhões de parâmetros pode consumir 1,2 MWh durante uma única execução de treinamento com múltiplas épocas, sobrecarregando instalações que carecem de compensações de energia renovável. As organizações mitigam os custos por meio de pipelines híbridos — treinamento na nuvem e, em seguida, exportação de pesos INT4 quantizados para aceleradores de borda. O agrupamento de memória e a esparsidade estruturada estão reduzindo ainda mais a potência ativa, mas sua adoção permanece desigual em toda a infraestrutura legada.
Requisitos de Pré-Treinamento com Grande Volume de Dados
Os ViTs fundamentais frequentemente exigem milhões de imagens rotuladas para generalizar, um obstáculo em domínios regulamentados como a saúde. O modelo de patologia Virchow exigiu 1,5 milhão de lâminas para atingir uma AUC de 0,949. Escassez semelhante de conjuntos de dados aparece na inspeção industrial, onde imagens proprietárias não podem ser compartilhadas externamente sob restrições de não divulgação. Os pipelines de dados sintéticos ajudam, mas implicam validação robusta para evitar sobreajuste e alucinação. Regiões com leis rigorosas de soberania de dados, como a UE, enfrentam complexidade adicional ao federar o treinamento entre fronteiras, prolongando os ciclos de desenvolvimento e amortecendo o impulso de crescimento do mercado de transformadores de visão.
*Nossas previsões tratam os impactos dos impulsionadores e restrições como direcionais, e não aditivos. As previsões de impacto refletem o crescimento de base, os efeitos de composição e as interações entre variáveis.
Análise de Segmentos
Por Componente: A Infraestrutura de Hardware Impulsiona a Adoção
O hardware comandou 55,34% da receita de 2024, ressaltando como a disponibilidade de computação sustenta o mercado de transformadores de visão. As GPUs H200 de ponta são fornecidas com 141 GB de HBM e 4,8 TB/s de largura de banda, oferecendo inferência 50% mais rápida do que as predecessoras e reduzindo os tempos de iteração para empresas que experimentam em escala. A camada de serviços também está se expandindo à medida que os fornecedores de nuvem envolvem pipelines ViT em contêineres em ofertas gerenciadas, eliminando a sobrecarga de DevOps para adotantes do mercado intermediário.
Os chips de IA de borda estão no centro do crescimento. Com uma CAGR de 33,73%, eles convertem a inteligência de classe de data center em plataformas implantáveis em campo. O Florence-2 da Microsoft mostra que um computador de placa única de USD 60 pode hospedar um ViT esparso e sustentar inferência de 20 fps dentro de um envelope de energia de 15 W. A integração estreita entre silício, firmware e métodos de compressão de modelos está moldando um ecossistema de componentes onde o valor migra para pilhas verticalmente otimizadas.



Por Aplicação: Classificação de Imagens Mantém a Liderança; Legendagem Cresce Rapidamente
A classificação de imagens manteve 46,98% de participação em 2024, impulsionada pela manufatura, varejo e diagnósticos médicos que buscam captura de contexto global de pixels. Em oncologia, o DepViT-CAD impulsiona o tamanho do mercado de transformadores de visão para diagnósticos de câncer com 94,11% de sensibilidade em 11 malignidades.
A legendagem de imagens, no entanto, é o segmento de crescimento mais rápido, com uma CAGR de 33,87%. Os portais de comércio eletrônico incorporam decodificadores de texto ViT para enriquecer os metadados do catálogo, gerando descrições automatizadas que aumentam a descoberta de produtos. Enquanto isso, os segmentos de detecção de objetos aproveitam os backbones de transformadores para defesa e direção autônoma, onde as camadas de atenção fundem arrays de câmeras sem LiDAR em uma compreensão de cena coesa. A participação do mercado de transformadores de visão em tarefas de segmentação também está aumentando, à medida que os ViTs eficientes em anotação reduzem o custo da rotulagem pixel a pixel.
Por Modo de Implantação: Nuvem Domina; Borda Acelera
As plataformas em nuvem detinham 65,74% de participação em 2024, graças às frotas de GPU com pagamento conforme o uso na AWS, GCP e Azure. O acesso sob demanda a clusters H200 com preços próximos a USD 10 por hora democratiza a experimentação em grande escala sem despesas de capital iniciais. No entanto, as implantações de borda estão crescendo a uma CAGR de 33,79%, pois robótica, cidades inteligentes e IoT industrial exigem latência inferior a 100 ms e inferência soberana de dados.
Topologias híbridas estão emergindo: o treinamento permanece centrado na nuvem, enquanto modelos destilados ou quantizados residem em gateways de borda ou módulos de computação veicular. As placas da classe Jetson executam ViTs INT4 com menos de 15 W, mostrando uma economia viável para robótica alimentada por bateria. À medida que os compiladores de esparsidade amadurecem, o throughput de inferência de borda deve triplicar até 2027, redistribuindo ainda mais o tamanho do mercado de transformadores de visão entre footprints de nuvem e locais.
Por Usuário Final: Saúde Comanda o Valor; Defesa Lidera o Crescimento
Saúde e ciências da vida respondem por 28,41% dos gastos de 2024, aproveitando os ViTs em radiologia, patologia e oftalmologia. A AUC de 0,949 do modelo Virchow em 17 cânceres exemplifica como o pré-treinamento específico de domínio atende aos rigorosos limites de precisão clínica.
Governo e defesa é o segmento de movimento mais rápido, com uma CAGR de 33,94%. Os programas de vigilância marítima agora integram o processamento de SAR habilitado por ViT a bordo de aeronaves de patrulha, automatizando a classificação de embarcações e a detecção de anomalias. As montadoras automotivas também intensificam os investimentos à medida que os robotáxis baseados apenas em câmeras se aproximam da prontidão comercial. Varejo, comércio eletrônico e empresas de mídia ficam logo atrás, impulsionados pela busca visual e pela personalização de conteúdo.
Análise Geográfica
A América do Norte contribuiu com 38,34% do valor de 2024. Um denso cluster de fornecedores de GPU, hiperscalers de nuvem e laboratórios acadêmicos acelera os ciclos de comercialização. As vias de aprovação acelerada da FDA para diagnósticos auxiliados por IA elevam ainda mais as implantações na área de saúde.
A Ásia-Pacífico registra a maior CAGR de 34,17%. Os programas apoiados pelo Estado chinês canalizam capital para startups de silício de transformadores, impulsionando os gastos projetados de USD 98 bilhões em IA em 2025. O Japão destinou USD 960 milhões para clusters de computação que favorecem ViTs em língua japonesa, e a Missão IndiaAI da Índia financia um supercluster soberano de 4.096 GPUs.
A Europa enfatiza a IA ética. A Lei de IA da UE incentiva as empresas a adotarem implantações com maior peso na borda e aprendizado federado, favorecendo o treinamento de ViT com preservação de privacidade. Os subsídios para data centers de baixo carbono em toda a Escandinávia também estão atraindo cargas de trabalho de transformadores, equilibrando as restrições de energia regionais.


Cenário Competitivo
O mercado de transformadores de visão apresenta concentração moderada. A pilha de hardware da NVIDIA impulsiona a formação de barreiras, mas a liderança em software é disputada entre Google (patentes de Transformador Universal), Microsoft (modelos de borda Phi-3 Vision) e Meta (derivados de ViT de código aberto). Os incumbentes de nuvem vendem GPUs em conjunto com DevOps prontos para uso, reduzindo o tempo para prova de conceito.
O foco estratégico está se deslocando para modelos verticais: a Lockheed Martin adapta ViTs de grau de defesa com proteção criptográfica no dispositivo, e empresas emergentes de tecnologia médica buscam a aprovação da FDA para cargas de trabalho de patologia e radiologia. O litígio de patentes em torno de kernels de atenção e transformadores com eficiência de memória cria complexidade de licenciamento que pode consolidar a propriedade intelectual sob um punhado de licenciadores.
As cadeias de ferramentas otimizadas para borda são o próximo campo de batalha. A patente de atenção de visão cruzada da Qualcomm e as integrações de NPU baseadas em ARM visam rivalizar com a NVIDIA em endpoints de baixa potência, enquanto a Graphcore e a AMD miram cenários de data center de alta densidade. As alianças estratégicas entre fornecedores de silício e estúdios de software — como os pacotes Jetson-VILA — ditarão a captura de valor até 2030.
Líderes do Setor de Transformadores de Visão
NVIDIA Corporation
Google LLC (Alphabet)
Microsoft Corporation
Meta Platforms Inc.
Amazon Web Services Inc.
- *Isenção de responsabilidade: Principais participantes classificados em nenhuma ordem específica

Desenvolvimentos Recentes do Setor
- Julho de 2025: A Lockheed Martin apresentou análises de Radar de Abertura Sintética alimentadas por ViT para vigilância marítima autônoma, integrando pipelines de MLOps a bordo.
- Julho de 2025: O investimento estrangeiro em empreendimentos de IA chineses deve atingir USD 98 bilhões, com startups canalizando fundos para P&D do mercado de transformadores de visão.
- Junho de 2025: O SoftBank delineou uma alocação de USD 33,2 bilhões para programas de superinteligência alinhados à OpenAI, planejando incorporar ViTs em empresas do portfólio.
- Junho de 2024: A Tesla iniciou testes de robotáxi em Austin usando pilhas de percepção ViT baseadas apenas em câmeras para navegação de direção totalmente autônoma.


Escopo do Relatório Global do Mercado de Transformadores de Visão
| Hardware |
| Software |
| Serviços |
| Classificação de Imagens |
| Legendagem de Imagens |
| Segmentação de Imagens |
| Detecção de Objetos |
| Outras Aplicações |
| Nuvem |
| Local |
| Borda |
| Varejo e Comércio Eletrônico |
| Mídia e Entretenimento |
| Automotivo |
| Governo e Defesa |
| Saúde e Ciências da Vida |
| Outros Usuários Finais |
| América do Norte | Estados Unidos | |
| Canadá | ||
| México | ||
| América do Sul | Brasil | |
| Argentina | ||
| Restante da América do Sul | ||
| Europa | Alemanha | |
| Reino Unido | ||
| França | ||
| Rússia | ||
| Restante da Europa | ||
| Ásia-Pacífico | China | |
| Japão | ||
| Índia | ||
| Coreia do Sul | ||
| Austrália | ||
| Restante da Ásia-Pacífico | ||
| Oriente Médio e África | Oriente Médio | Arábia Saudita |
| Emirados Árabes Unidos | ||
| Restante do Oriente Médio | ||
| África | África do Sul | |
| Egito | ||
| Restante da África | ||
| Por Componente | Hardware | ||
| Software | |||
| Serviços | |||
| Por Aplicação | Classificação de Imagens | ||
| Legendagem de Imagens | |||
| Segmentação de Imagens | |||
| Detecção de Objetos | |||
| Outras Aplicações | |||
| Por Modo de Implantação | Nuvem | ||
| Local | |||
| Borda | |||
| Por Usuário Final | Varejo e Comércio Eletrônico | ||
| Mídia e Entretenimento | |||
| Automotivo | |||
| Governo e Defesa | |||
| Saúde e Ciências da Vida | |||
| Outros Usuários Finais | |||
| Por Geografia | América do Norte | Estados Unidos | |
| Canadá | |||
| México | |||
| América do Sul | Brasil | ||
| Argentina | |||
| Restante da América do Sul | |||
| Europa | Alemanha | ||
| Reino Unido | |||
| França | |||
| Rússia | |||
| Restante da Europa | |||
| Ásia-Pacífico | China | ||
| Japão | |||
| Índia | |||
| Coreia do Sul | |||
| Austrália | |||
| Restante da Ásia-Pacífico | |||
| Oriente Médio e África | Oriente Médio | Arábia Saudita | |
| Emirados Árabes Unidos | |||
| Restante do Oriente Médio | |||
| África | África do Sul | ||
| Egito | |||
| Restante da África | |||


Principais Perguntas Respondidas no Relatório
Qual valor de receita é projetado para os transformadores de visão até 2030?
O tamanho do mercado de transformadores de visão deve atingir USD 1,58 bilhão até 2030, sustentado por uma CAGR de 33,67%.
Qual aplicação domina atualmente os gastos?
A classificação de imagens lidera com uma participação de 46,98% em 2024, devido à adoção generalizada em fluxos de trabalho visuais de saúde, manufatura e varejo.
Por que as implantações de borda estão crescendo mais rápido do que a nuvem?
A inferência de borda reduz a latência, diminui os custos de largura de banda e facilita a conformidade com a soberania de dados, o que explica seu ritmo de crescimento de CAGR de 33,79%.
Qual região oferece o maior potencial de crescimento?
Espera-se que a Ásia-Pacífico se expanda a uma CAGR de 34,17%, impulsionada por grandes investimentos governamentais em IA na China, Índia e Japão.
Como os custos de computação estão impactando a adoção?
Os altos preços de GPU e o consumo de energia reduzem aproximadamente 4,7 pontos percentuais da CAGR prevista, levando as empresas a adotar quantização, esparsidade e estratégias híbridas de nuvem e borda.
Quais setores estão emergindo além de saúde e defesa?
O varejo e o comércio eletrônico adotam a busca visual alimentada por ViT, as empresas automotivas avançam na autonomia baseada em câmeras e as empresas de mídia exploram a legendagem automatizada de conteúdo.
Página atualizada pela última vez em:




