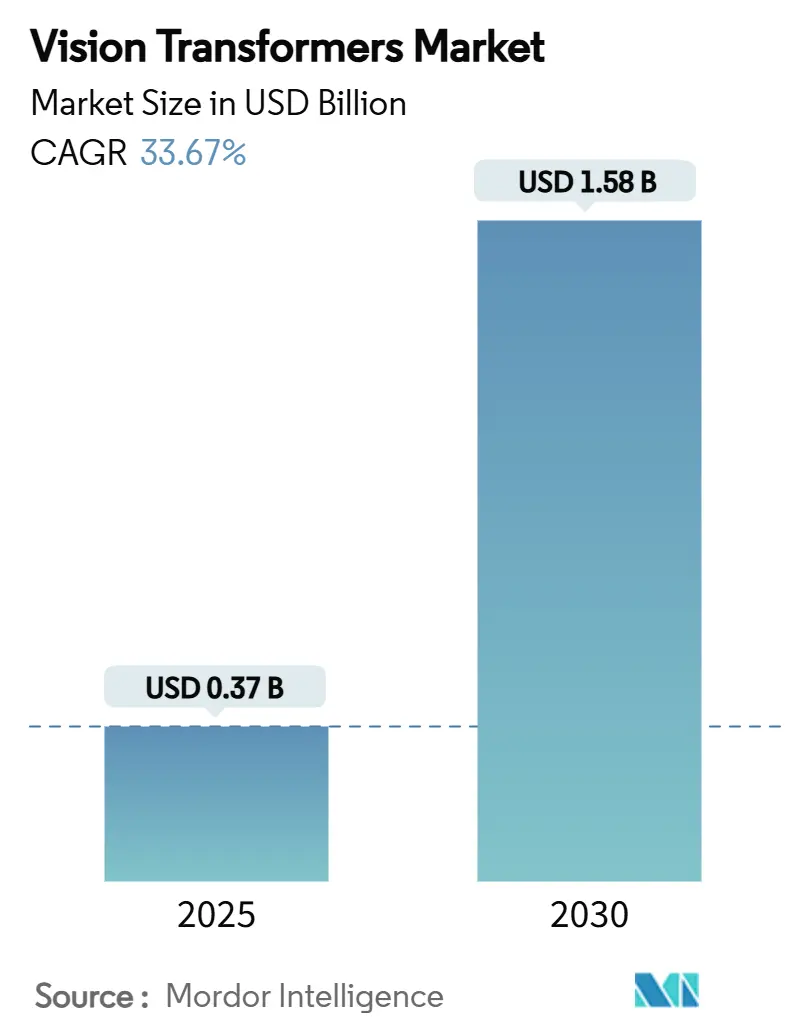
Größe und Marktanteil des Marktes für Vision Transformers
Marktübersicht
| Studienzeitraum | 2019 - 2030 |
|---|---|
| Marktgröße (2025) | 0.37 Milliarden US-Dollar |
| Marktgröße (2030) | 1.58 Milliarden US-Dollar |
| Wachstumsrate (2025 - 2030) | 33.67% CAGR |
| Schnellstwachsender Markt | Asien-Pazifik |
| Größter Markt | Nordamerika |
| Marktkonzentration | Mittel |
Hauptakteure *Haftungsausschluss: Hauptakteure in keiner bestimmten Reihenfolge sortiert Bild © Mordor Intelligence. Wiederverwendung erfordert Namensnennung gemäß CC BY 4.0. | |
Marktanalyse für Vision Transformers von Mordor Intelligence
Die Marktgröße für Vision Transformers beläuft sich im Jahr 2025 auf 0,37 Milliarden USD und wird voraussichtlich bis 2030 1,58 Milliarden USD übersteigen, mit einer Expansion bei einer CAGR von 33,67 %. Diese Beschleunigung spiegelt einen Wertzuwachs von 327 % über den Zeitraum wider, angetrieben durch Transformer-Architekturen, die globalen Bildkontext erfassen und Legacy-CNN-Modelle konsistent übertreffen. Die wachsende Unternehmensnachfrage nach hochauflösender visueller Erkennung, die Einführung von H100/H200-GPUs und ausgereifte Edge-Inferenz-Frameworks stärken den Schwung. Die Wettbewerbsdifferenzierung dreht sich nun um optimierte Self-Attention-Beschleuniger, Open-Source-Modellveröffentlichungen und Cloud-Edge-Orchestrierungsstrategien. Gleichzeitig dämpfen Lieferkettendrücke rund um fortschrittliche Verpackung und Hochbandbreitenspeicher die kurzfristige Kapazität, doch eine Preisentlastung wird prognostiziert, wenn Kapazitätserweiterungen in Südkorea und Taiwan in Betrieb gehen. Erweiterte staatliche KI-Budgets in Nordamerika, China, Indien und Japan verstärken die Mittelflüsse in transformerbasierte Forschung und Entwicklung, während regulatorische Klarheit rund um den realen Einsatz eine breitere Unternehmensübernahme fördert.
Wichtigste Erkenntnisse des Berichts
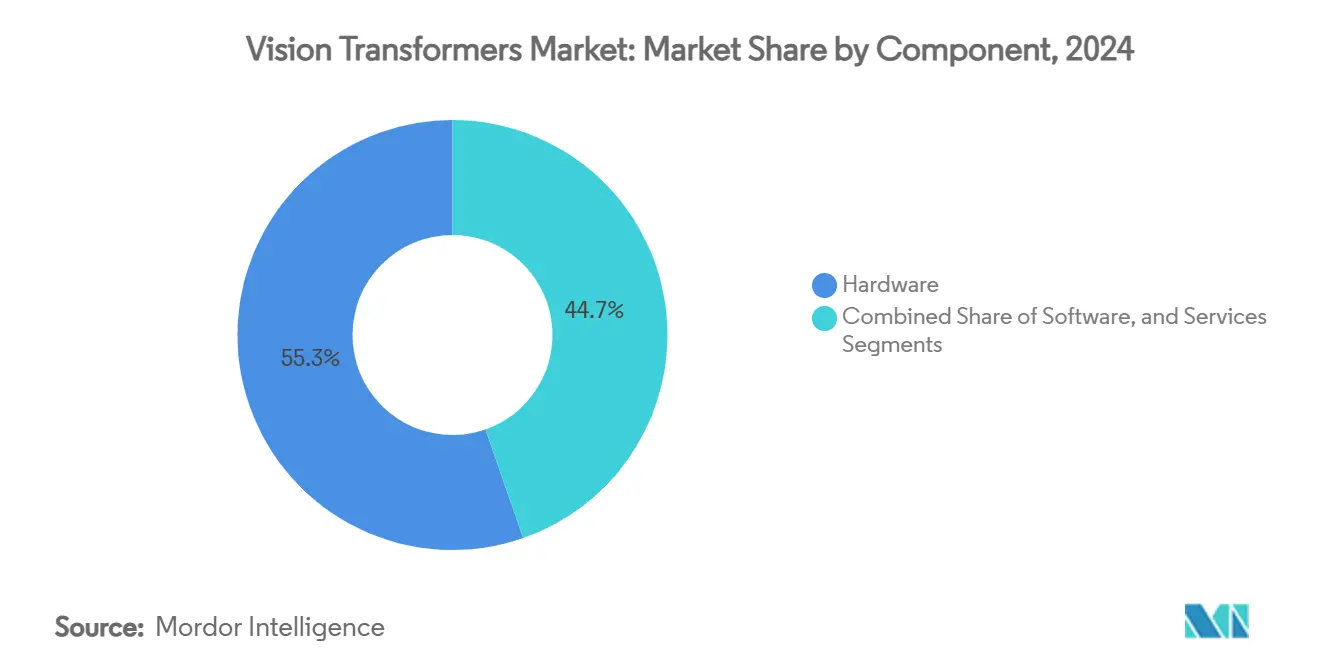
- Nach Komponente führte Hardware im Jahr 2024 mit einem Umsatzanteil von 55,34 %, während Edge-KI-Chipsätze bis 2030 eine CAGR von 33,73 % verzeichneten.
- Nach Anwendung hielt Bildklassifizierung im Jahr 2024 einen Anteil von 46,98 % am Markt für Vision Transformers, und Bildbeschriftung wird voraussichtlich bis 2030 mit einer CAGR von 33,87 % wachsen.
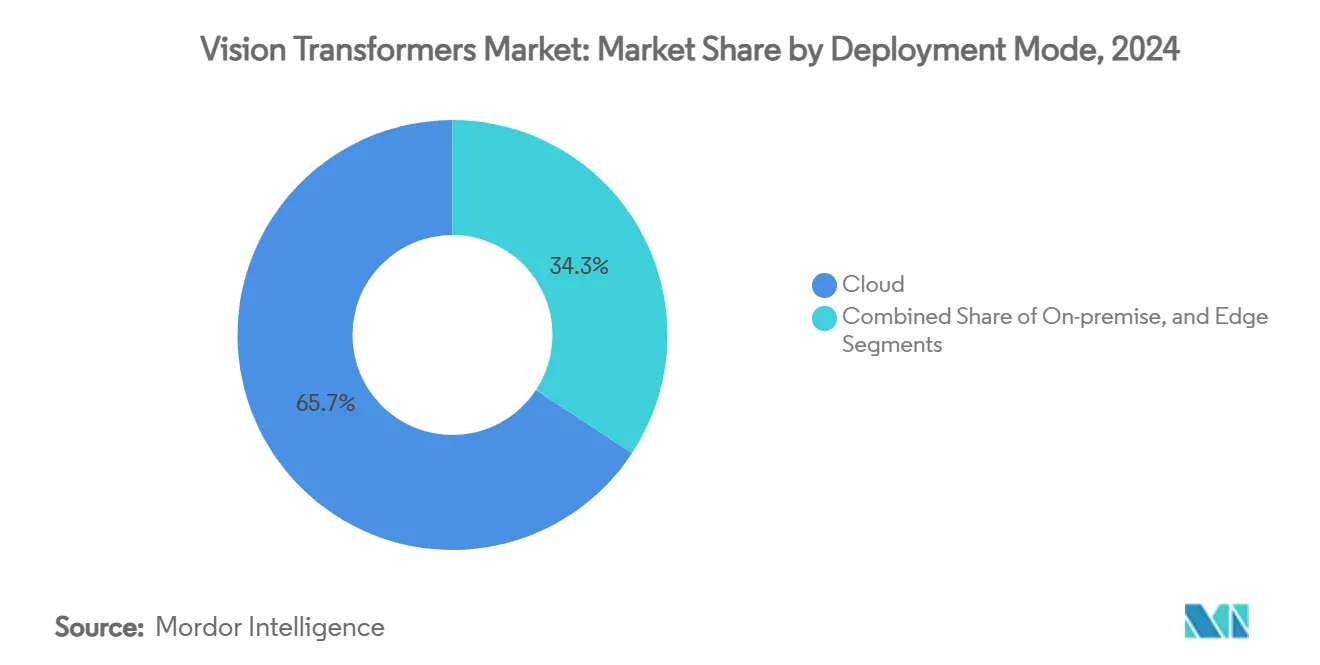
- Nach Bereitstellungsmodus erfassten Cloud-Plattformen im Jahr 2024 einen Anteil von 65,74 % an der Marktgröße für Vision Transformers; Edge-Bereitstellung schreitet mit einer CAGR von 33,79 % voran.
- Nach Endnutzer beherrschten Gesundheitswesen und Biowissenschaften im Jahr 2024 einen Anteil von 28,41 %, während Regierung und Verteidigung die schnellste CAGR von 33,94 % bis 2030 verzeichnet.
- Nach Geografie entfiel im Jahr 2024 ein Anteil von 38,34 % des Marktes für Vision Transformers auf Nordamerika, doch für den asiatisch-pazifischen Raum wird bis 2030 eine CAGR von 34,17 % prognostiziert.
Globale Trends und Erkenntnisse des Marktes für Vision Transformers
Analyse der Auswirkungen von Treibern*
| Treiber | (~) % Auswirkung auf die CAGR-Prognose | Geografische Relevanz | Zeithorizont der Auswirkung |
|---|---|---|---|
| Breite Einführung in bildorientierten KI-Aufgaben | +8.2% | Nordamerika / Europa als Erstanwender | Mittelfristig (2–4 Jahre) |
| Verbreitung fortschrittlicher GPUs, TPUs und Edge-KI-Chips | +7.8% | Fertigungsstätten in den USA, China und Taiwan | Kurzfristig (≤ 2 Jahre) |
| Bedarf autonomer Systeme an Echtzeit-Wahrnehmung | +6.9% | Globale Automobil- und Verteidigungszentren | Mittelfristig (2–4 Jahre) |
| Aufstieg multimodaler Vision-Sprach-Transformer-Stacks | +5.4% | Globaler Übertrag auf Schwellenmärkte | Langfristig (≥ 4 Jahre) |
| Durchbrüche bei Edge-orientierter Sparsität und Quantisierung | +4.1% | Fertigung im asiatisch-pazifischen Raum, Forschung und Entwicklung in Nordamerika | Kurzfristig (≤ 2 Jahre) |
| Open-Source-Basis-ViT-Modelle senken Einstiegshürden | +3.8% | Entwicklungsmärkte | Mittelfristig (2–4 Jahre) |
| Quelle: Mordor Intelligence | |||
Breite Einführung in bildorientierten KI-Aufgaben
Unternehmenseinführungen haben die Labore verlassen, da Unternehmen erhebliche Genauigkeitsgewinne in komplexen visuellen Arbeitsabläufen berichten. Pathologiezentren, die Modelle mit 632 Millionen Parametern einsetzen, erreichen eine diagnostische Sensitivität von 94,11 % bei der Erkennung mehrerer Krebsklassen und beschleunigen die Entscheidungsunterstützung in der Onkologie. [1]Shakarami, "DepViT-CAD: Einsetzbarer auf Vision Transformer basierender Krebsdiagnose," arxiv.orgHersteller integrieren aufmerksamkeitsreiche Modelle, um kleinste Oberflächenfehler zu lokalisieren, die CNNs häufig übersehen, und reduzieren die manuelle Inspektionszeit um 38 %. Teams in der finanziellen Sachbearbeitung verlassen sich auf ViT-gestützte Dokumentenanalyse, die eine Feldgenauigkeit von 98 % erreicht, papierbasierte Fehler reduziert und die Rechnungsabstimmung beschleunigt. Diese Leistungsgewinne ermutigen Chief Technology Officers, visuelle Abläufe auf Transformer-Grundlagen zu migrieren, was die Marktentwicklung für Vision Transformers stärkt.
Verbreitung fortschrittlicher GPUs, TPUs und Edge-KI-Chips
Hardware-Zyklen verkürzen sich, da Hyperscaler und System-on-Chip-Designer neue Speicherbandbreite und Rechendichte erschließen. NVIDIA H200-Boards werden zu einem Preis von etwa 30.000 USD angeboten und liefern einen Durchsatz von 4,8 TB/s, sodass ViTs mit 70 Milliarden Parametern in 30 % weniger Epochen trainiert werden können. Gleichzeitig demonstriert Microsofts Florence-2-Inferenz-Stack einen Edge-Betrieb mit 15 W auf Raspberry-Pi-ähnlichen Geräten und erweitert die Relevanz von Transformern auf ressourcenbeschränkte Endpunkte.[2]Hackster.io, "Vision-Sprach-Modelle am Edge," hackster.io Engpässe bei Hochbandbreitenspeicher bleiben ein Flaschenhals, entspannen sich jedoch, da neue Modullieferanten in Japan und Südkorea skalieren.
Bedarf autonomer Systeme an Echtzeit-Wahrnehmung
Selbstfahrprogramme von Tesla bis hin zu europäischen Lkw-Platooning-Konsortien stützen sich auf kamerabasierte Wahrnehmung, die von leichtgewichtigen ViTs angetrieben wird, die die Rechenkosten um 90 % senken und dabei die Kontextpräzision beibehalten. Im Verteidigungsbereich ermöglichen FPGA-beschleunigte ViTs eine blitzschnelle Zielerkennung bei Synthetic-Aperture-Radar-Feeds und erlauben es Seefernaufklärungsflugzeugen, Kampf- von Zivilschiffen in unübersichtlichen Szenen zu unterscheiden. Diese latenzempfindlichen Szenarien unterstreichen die Nachfrage nach sparsifizierten Aufmerksamkeitsblöcken und gemischtpräziser Arithmetik, die Transformer-Logik in strenge Leistungsbudgets einpasst.
Aufstieg multimodaler Vision-Sprach-Transformer-Stacks
Entwickler verbinden Vision Transformers mit großen Sprachmodellen, um reichhaltigeres domänenübergreifendes Schlussfolgern zu ermöglichen. Microsofts Phi-3 Vision mit 4,2 Milliarden Parametern komprimiert multimodale Fähigkeiten in einen Edge-fähigen Formfaktor, während NVIDIAs VILA-Architektur ViT-Encoder mit quantisierten Sprach-Decodern kombiniert, um bei Video-Frage-und-Antwort-Aufgaben zu glänzen und größere Basismodelle zu übertreffen. E-Commerce-Suchmaschinen, die Bild-Text-Ausrichtung nutzen, verzeichnen eine Klickrate von 4,95 % mehr, da Käufer relevantere visuelle Treffer erhalten. Die multimodale Dynamik erweitert die adressierbare Basis des Marktes für Vision Transformers und berührt Kundenservice-, Robotik- und Content-Moderations-Workflows.
Analyse der Auswirkungen von Hemmnissen*
| Hemmnis | (~) % Auswirkung auf die CAGR-Prognose | Geografische Relevanz | Zeithorizont der Auswirkung |
|---|---|---|---|
| Hohe Rechenkosten und Stromverbrauch | -4.7% | Entwicklungsländer am stärksten betroffen | Kurzfristig (≤ 2 Jahre) |
| Datenintensive Vortrainingsanforderungen | -3.2% | Domänenspezifische Branchen | Mittelfristig (2–4 Jahre) |
| Patentdickicht bei Aufmerksamkeitsbeschleunigung | -2.1% | Rechtsstreitigkeiten in den USA und der EU | Langfristig (≥ 4 Jahre) |
| Regulatorische und sicherheitsbezogene Risiken durch Transformer-Halluzinationen | -1.8% | Nordamerika und Europa | Mittelfristig (2–4 Jahre) |
| Quelle: Mordor Intelligence | |||
Hohe Rechenkosten und Stromverbrauch
Die Preise für cloudbasierte H100-GPU-Knoten liegen zwischen 2,80 USD und 10,00 USD pro Stunde, was Experimente für kleinere Unternehmen unerschwinglich macht.[3]Cyfuture Cloud, "Nvidia H100 GPU Preis 2025," cyfuture.cloud Der Energieverbrauch von Rechenzentren steigt ebenfalls stark an: Ein ViT mit 70 Milliarden Parametern kann während eines einzigen Mehrfach-Epochen-Trainingslaufs 1,2 MWh verbrauchen, was Einrichtungen ohne erneuerbare Energieausgleiche belastet. Organisationen mindern Kosten durch hybride Pipelines – Training in der Cloud, dann Export quantisierter INT4-Gewichte auf Edge-Beschleuniger. Speicher-Pooling und strukturierte Sparsität reduzieren die aktive Leistungsaufnahme weiter, doch ihre Einführung bleibt in der Legacy-Infrastruktur uneinheitlich.
Datenintensive Vortrainingsanforderungen
Grundlegende ViTs erfordern oft Millionen von beschrifteten Bildern zur Generalisierung, was in regulierten Bereichen wie dem Gesundheitswesen eine Hürde darstellt. Das Virchow-Pathologiemodell benötigte 1,5 Millionen Schnitte, um einen AUC von 0,949 zu erreichen. Ähnliche Datensatzknappheit tritt bei der industriellen Inspektion auf, wo proprietäre Bilder aufgrund von Geheimhaltungsvereinbarungen nicht extern geteilt werden können. Synthetische Datenpipelines helfen, erfordern jedoch eine robuste Validierung, um Überanpassung und Halluzinationen zu verhindern. Regionen mit strengen Datensouveränitätsgesetzen, wie die EU, stehen vor zusätzlicher Komplexität bei der föderativen Schulung über Grenzen hinweg, was Entwicklungszyklen verlängert und den Wachstumsimpuls des Marktes für Vision Transformers dämpft.
*Unsere Prognosen behandeln die Auswirkungen von Treibern und Einschränkungen als richtungsweisend und nicht additiv. Die Wirkungsprognosen berücksichtigen Basiswachstum, Mischungseffekte und Wechselwirkungen zwischen Variablen.
Segmentanalyse
Nach Komponente: Hardware-Infrastruktur treibt die Einführung voran
Hardware befehligte 55,34 % des Umsatzes im Jahr 2024 und unterstreicht, wie die Verfügbarkeit von Rechenkapazität den Markt für Vision Transformers unterstützt. Flaggschiff-H200-GPUs werden mit 141 GB HBM und 4,8 TB/s Bandbreite geliefert, bieten 50 % schnellere Inferenz als Vorgänger und verkürzen die Iterationszeiten für Unternehmen, die im großen Maßstab experimentieren. Die Dienstleistungsschicht expandiert ebenfalls, da Cloud-Anbieter containerisierte ViT-Pipelines in verwaltete Angebote einbetten und den DevOps-Aufwand für mittelständische Anwender eliminieren.
Edge-KI-Chips stehen im Mittelpunkt des Wachstums. Mit einer CAGR von 33,73 % wandeln sie Rechenzentrums-Intelligenz in feldtaugliche Plattformen um. Microsofts Florence-2 zeigt, dass ein Einplatinencomputer für 60 USD einen sparsifizierten ViT hosten und eine Inferenz mit 20 fps innerhalb eines Leistungsrahmens von 15 W aufrechterhalten kann. Die enge Integration zwischen Silizium, Firmware und Modellkomprimierungsmethoden gestaltet ein Komponentenökosystem, in dem der Wert zu vertikal optimierten Stacks migriert.



Nach Anwendung: Bildklassifizierung behält die Führung; Bildbeschriftung wächst stark
Bildklassifizierung behielt im Jahr 2024 einen Anteil von 46,98 %, gestützt durch Fertigung, Einzelhandel und medizinische Diagnostik, die globale Pixelkontexterfassung anstreben. In der Onkologie treibt DepViT-CAD die Marktgröße für Vision Transformers in der Krebsdiagnostik mit einer Sensitivität von 94,11 % bei 11 Krebsarten voran.
Bildbeschriftung ist jedoch mit einer CAGR von 33,87 % der am schnellsten wachsende Bereich. E-Commerce-Portale betten ViT-Text-Decoder ein, um Katalogmetadaten anzureichern und automatisierte Beschreibungen zu generieren, die die Auffindbarkeit von Produkten steigern. Unterdessen nutzen Objekterkennungssegmente Transformer-Grundlagen für Verteidigung und autonomes Fahren, wo Aufmerksamkeitsschichten LiDAR-freie Kamera-Arrays zu einem kohärenten Szenenverständnis zusammenführen. Der Marktanteil für Vision Transformers bei Segmentierungsaufgaben steigt ebenfalls, da annotationseffiziente ViTs die Kosten für pixelgenaue Beschriftung senken.
Nach Bereitstellungsmodus: Cloud dominiert; Edge beschleunigt sich
Cloud-Plattformen hielten im Jahr 2024 einen Anteil von 65,74 % dank nutzungsbasierter GPU-Flotten bei AWS, GCP und Azure. Der bedarfsgesteuerte Zugang zu H200-Clustern zu einem Preis von etwa 10 USD pro Stunde demokratisiert groß angelegte Experimente ohne anfängliche Investitionsausgaben. Dennoch steigen Edge-Bereitstellungen mit einer CAGR von 33,79 %, da Robotik, Smart Cities und industrielles IoT eine Latenz von unter 100 ms und datensouveräne Inferenz fordern.
Hybride Topologien entstehen: Das Training bleibt Cloud-zentriert, während destillierte oder quantisierte Modelle auf Edge-Gateways oder Fahrzeugrechenmodulen residieren. Jetson-ähnliche Boards führen INT4-ViTs bei unter 15 W aus und zeigen tragfähige Wirtschaftlichkeit für batteriebetriebene Robotik. Da Sparsitätskompiler reifen, wird der Edge-Inferenzdurchsatz bis 2027 voraussichtlich verdreifacht, was die Marktgröße für Vision Transformers zwischen Cloud- und On-Premise-Footprints weiter umverteilt.
Nach Endnutzer: Gesundheitswesen dominiert den Wert; Verteidigung führt das Wachstum an
Gesundheitswesen und Biowissenschaften machen 28,41 % der Ausgaben im Jahr 2024 aus und nutzen ViTs in der Radiologie, Pathologie und Ophthalmologie. Der AUC von 0,949 des Virchow-Modells bei 17 Krebsarten veranschaulicht, wie domänenspezifisches Vortraining strenge klinische Genauigkeitsschwellen erfüllt.
Regierung und Verteidigung ist mit einer CAGR von 33,94 % der am schnellsten wachsende Bereich. Maritime Überwachungsprogramme integrieren nun ViT-gestützte SAR-Verarbeitung an Bord von Patrouillenflugzeugen und automatisieren die Schiffsklassifizierung und Anomalieerkennung. Automobilhersteller steigern ebenfalls ihre Investitionen, da kamerabasierte Robotaxis der kommerziellen Reife nahe kommen. Einzelhandel, E-Commerce und Medienunternehmen folgen dicht dahinter, angetrieben durch visuelle Suche und Content-Personalisierung.
Geografische Analyse
Nordamerika trug im Jahr 2024 38,34 % des Wertes bei. Ein dichtes Cluster aus GPU-Lieferanten, Cloud-Hyperscalern und akademischen Laboren beschleunigt Kommerzialisierungszyklen. Schnellverfahren der FDA für KI-gestützte Diagnostik steigern zudem Gesundheitsbereitstellungen.
Der asiatisch-pazifische Raum verzeichnet die höchste CAGR von 34,17 %. Chinas staatlich geförderte Programme leiten Kapital in Transformer-Silizium-Startups und treiben prognostizierte KI-Ausgaben von 98 Milliarden USD im Jahr 2025 voran. Japan hat 960 Millionen USD für Rechencluster bereitgestellt, die japanischsprachige ViTs bevorzugen, und Indiens IndiaAI-Mission finanziert einen souveränen Supercluster mit 4.096 GPUs.
Europa betont ethische KI. Der EU-KI-Act drängt Unternehmen zu Edge-lastigen Bereitstellungen und föderiertem Lernen, was datenschutzfreundliches ViT-Training begünstigt. Subventionen für kohlenstoffarme Rechenzentren in Skandinavien ziehen ebenfalls Transformer-Workloads an und gleichen regionale Energiebeschränkungen aus.


Wettbewerbslandschaft
Der Markt für Vision Transformers weist eine moderate Konzentration auf. NVIDIAs Hardware-Stack treibt die Bildung von Markteintrittsbarrieren voran, doch die Softwareführerschaft wird zwischen Google (Universal-Transformer-Patente), Microsoft (Phi-3 Vision Edge-Modelle) und Meta (Open-Source-ViT-Derivate) umkämpft. Cloud-Incumbents verkaufen GPUs zusammen mit schlüsselfertigen DevOps-Lösungen und verkürzen die Zeit bis zum Proof-of-Concept.
Der strategische Fokus verlagert sich auf vertikale Modelle: Lockheed Martin passt verteidigungstaugliche ViTs mit geräteseitiger kryptografischer Härtung an, und aufstrebende Medizintechnikunternehmen streben die FDA-Zulassung für Pathologie- und Radiologie-Workloads an. Patentstreitigkeiten rund um Aufmerksamkeitskerne und speichereffiziente Transformer schaffen Lizenzkomplexität, die IP unter einer Handvoll Lizenzgeber konsolidieren könnte.
Edge-optimierte Toolchains sind das nächste Schlachtfeld. Qualcomms Cross-View-Attention-Patent und ARM-basierte NPU-Integrationen zielen darauf ab, NVIDIA bei stromsparenden Endpunkten zu rivalisieren, während Graphcore und AMD auf hochdichte Rechenzentrumsszenarien abzielen. Strategische Allianzen zwischen Siliziumanbietern und Softwarestudios – wie Jetson-VILA-Bundles – werden die Wertschöpfung bis 2030 bestimmen.
Marktführer der Branche der Vision Transformers
NVIDIA Corporation
Google LLC (Alphabet)
Microsoft Corporation
Meta Platforms Inc.
Amazon Web Services Inc.
- *Haftungsausschluss: Hauptakteure in keiner bestimmten Reihenfolge sortiert

Jüngste Branchenentwicklungen
- Juli 2025: Lockheed Martin stellte ViT-gestützte Synthetic-Aperture-Radar-Analytik für autonome maritime Überwachung vor und integrierte bordeigene MLOps-Pipelines.
- Juli 2025: Ausländische Investitionen in chinesische KI-Unternehmen werden voraussichtlich 98 Milliarden USD erreichen, wobei Startups Mittel in die Forschung und Entwicklung des Marktes für Vision Transformers lenken.
- Juni 2025: SoftBank skizzierte eine Zuweisung von 33,2 Milliarden USD für OpenAI-ausgerichtete Superintelligenzprogramme und plant, ViTs in Portfoliounternehmen einzubetten.
- Juni 2024: Tesla begann Robotaxi-Tests in Austin unter Verwendung kamerabasierter ViT-Wahrnehmungsstacks für vollautonome Fahrnavigation.


Berichtsumfang des globalen Marktes für Vision Transformers
| Hardware |
| Software |
| Dienstleistungen |
| Bildklassifizierung |
| Bildbeschriftung |
| Bildsegmentierung |
| Objekterkennung |
| Weitere Anwendungen |
| Cloud |
| On-Premise |
| Edge |
| Einzelhandel und E-Commerce |
| Medien und Unterhaltung |
| Automobilindustrie |
| Regierung und Verteidigung |
| Gesundheitswesen und Biowissenschaften |
| Weitere Endnutzer |
| Nordamerika | Vereinigte Staaten | |
| Kanada | ||
| Mexiko | ||
| Südamerika | Brasilien | |
| Argentinien | ||
| Übriges Südamerika | ||
| Europa | Deutschland | |
| Vereinigtes Königreich | ||
| Frankreich | ||
| Russland | ||
| Übriges Europa | ||
| Asiatisch-pazifischer Raum | China | |
| Japan | ||
| Indien | ||
| Südkorea | ||
| Australien | ||
| Übriger asiatisch-pazifischer Raum | ||
| Naher Osten und Afrika | Naher Osten | Saudi-Arabien |
| Vereinigte Arabische Emirate | ||
| Übriger Naher Osten | ||
| Afrika | Südafrika | |
| Ägypten | ||
| Übriges Afrika | ||
| Nach Komponente | Hardware | ||
| Software | |||
| Dienstleistungen | |||
| Nach Anwendung | Bildklassifizierung | ||
| Bildbeschriftung | |||
| Bildsegmentierung | |||
| Objekterkennung | |||
| Weitere Anwendungen | |||
| Nach Bereitstellungsmodus | Cloud | ||
| On-Premise | |||
| Edge | |||
| Nach Endnutzer | Einzelhandel und E-Commerce | ||
| Medien und Unterhaltung | |||
| Automobilindustrie | |||
| Regierung und Verteidigung | |||
| Gesundheitswesen und Biowissenschaften | |||
| Weitere Endnutzer | |||
| Nach Geografie | Nordamerika | Vereinigte Staaten | |
| Kanada | |||
| Mexiko | |||
| Südamerika | Brasilien | ||
| Argentinien | |||
| Übriges Südamerika | |||
| Europa | Deutschland | ||
| Vereinigtes Königreich | |||
| Frankreich | |||
| Russland | |||
| Übriges Europa | |||
| Asiatisch-pazifischer Raum | China | ||
| Japan | |||
| Indien | |||
| Südkorea | |||
| Australien | |||
| Übriger asiatisch-pazifischer Raum | |||
| Naher Osten und Afrika | Naher Osten | Saudi-Arabien | |
| Vereinigte Arabische Emirate | |||
| Übriger Naher Osten | |||
| Afrika | Südafrika | ||
| Ägypten | |||
| Übriges Afrika | |||


Im Bericht beantwortete Schlüsselfragen
Welcher Umsatzwert wird für Vision Transformers bis 2030 prognostiziert?
Die Marktgröße für Vision Transformers wird voraussichtlich bis 2030 1,58 Milliarden USD erreichen, gestützt durch eine CAGR von 33,67 %.
Welche Anwendung dominiert derzeit die Ausgaben?
Bildklassifizierung führt mit einem Anteil von 46,98 % im Jahr 2024 aufgrund der weit verbreiteten Einführung in Gesundheitswesen, Fertigung und visuellen Einzelhandels-Workflows.
Warum wachsen Edge-Bereitstellungen schneller als Cloud?
Edge-Inferenz reduziert die Latenz, senkt Bandbreitenkosten und erleichtert die Einhaltung von Datensouveränitätsvorschriften, was seine CAGR-Wachstumsrate von 33,79 % erklärt.
Welche Region bietet das höchste Wachstumspotenzial?
Der asiatisch-pazifische Raum wird voraussichtlich mit einer CAGR von 34,17 % expandieren, angetrieben durch groß angelegte staatliche KI-Investitionen in China, Indien und Japan.
Wie wirken sich Rechenkosten auf die Einführung aus?
Hohe GPU-Preise und Energieverbrauch reduzieren die prognostizierte CAGR um etwa 4,7 Prozentpunkte und veranlassen Unternehmen, Quantisierung, Sparsität und hybride Cloud-Edge-Strategien zu verfolgen.
Welche Sektoren entwickeln sich jenseits von Gesundheitswesen und Verteidigung?
Einzelhandel und E-Commerce setzen ViT-gestützte visuelle Suche ein, Automobilunternehmen treiben kamerabasierte Autonomie voran, und Medienunternehmen erkunden automatisierte Content-Beschriftung.
Seite zuletzt aktualisiert am:




