Taille et Part du Marché des Transformateurs de Vision
VUE D’ENSEMBLE DU MARCHÉ
| Période d'étude | 2019 - 2030 |
|---|---|
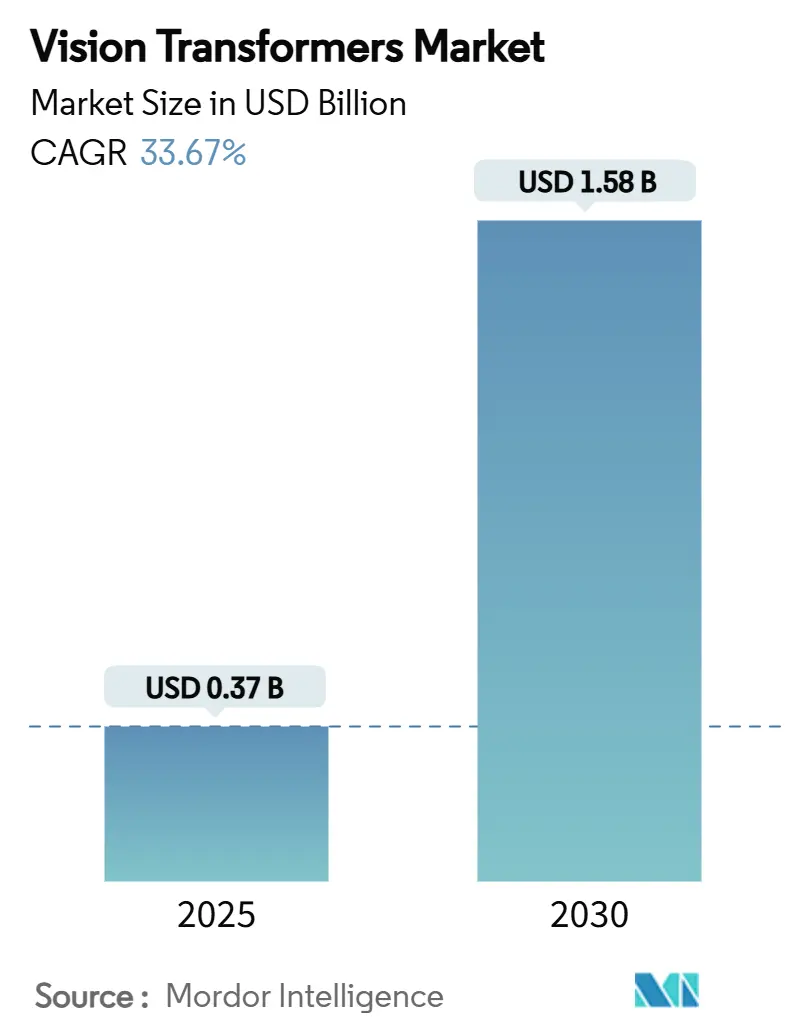
| Taille du Marché (2025) | 0.37 Milliards de dollars |
| Taille du Marché (2030) | 1.58 Milliards de dollars |
| Taux de croissance (2025 - 2030) | 33.67% CAGR |
| Marché à la Croissance la Plus Rapide | Asie-Pacifique |
| Plus Grand Marché | Amérique du Nord |
| Concentration du Marché | Moyen |
Acteurs majeurs *Avis de non-responsabilité : les principaux acteurs sont triés sans ordre particulier Image © Mordor Intelligence. La réutilisation nécessite une attribution sous CC BY 4.0. | |
Analyse du Marché des Transformateurs de Vision par Mordor Intelligence
La taille du marché des transformateurs de vision s'établit à 0,37 milliard USD en 2025 et devrait dépasser 1,58 milliard USD d'ici 2030, avec une expansion à un TCAC de 33,67 %. Cette accélération reflète une hausse de valeur de 327 % sur la période, portée par des architectures de transformateurs qui capturent le contexte global de l'image et surpassent systématiquement les modèles CNN traditionnels. La demande croissante des entreprises pour la reconnaissance visuelle haute résolution, le déploiement des GPU H100/H200 et la maturation des cadres d'inférence en périphérie renforcent la dynamique. La différenciation concurrentielle repose désormais sur des accélérateurs d'auto-attention optimisés, des publications de modèles open source et des stratégies d'orchestration cloud-périphérie. Parallèlement, les pressions sur la chaîne d'approvisionnement liées à l'emballage avancé et à la mémoire à haute bande passante freinent les capacités à court terme, mais un allègement des prix est prévu à mesure que les ajouts de capacité en Corée du Sud et à Taïwan entrent en service. L'augmentation des budgets gouvernementaux consacrés à l'IA en Amérique du Nord, en Chine, en Inde et au Japon amplifie les flux de financement dans la R&D basée sur les transformateurs, tandis que la clarté réglementaire autour du déploiement dans le monde réel favorise une adoption plus large par les entreprises.
Principaux Enseignements du Rapport
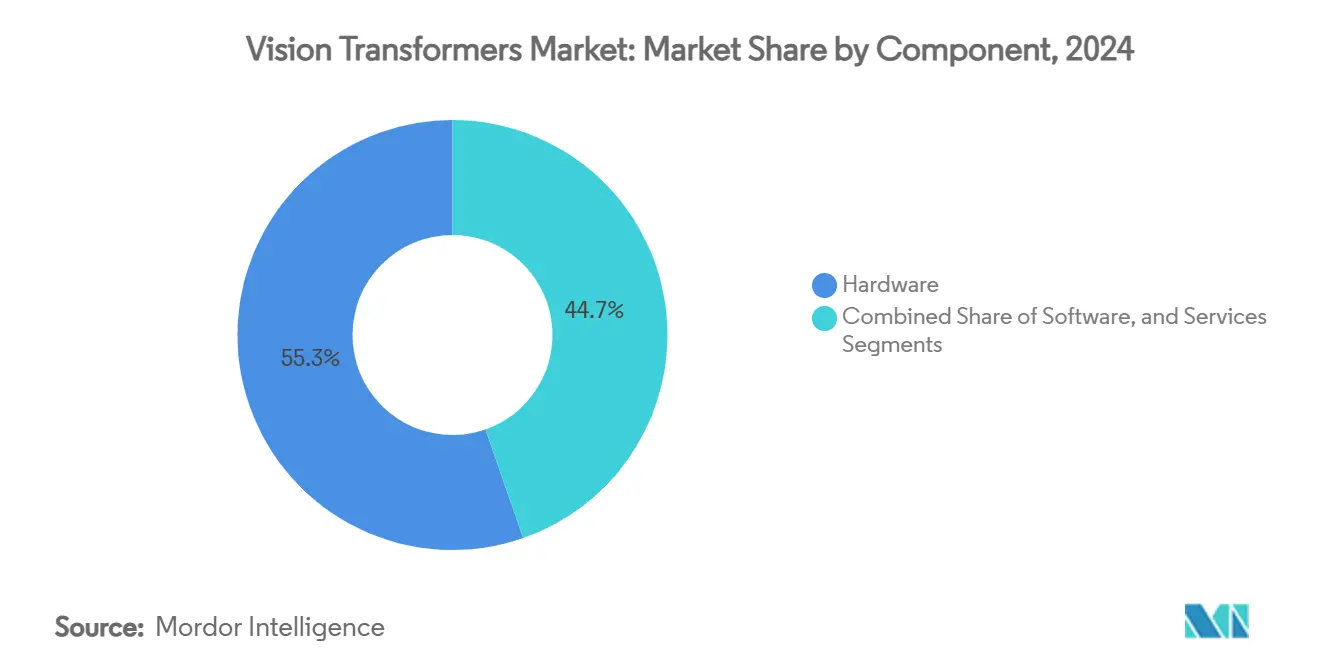
- Par composant, le matériel a dominé avec une part de revenus de 55,34 % en 2024, tandis que les puces d'IA en périphérie ont affiché un TCAC de 33,73 % jusqu'en 2030.
- Par application, la classification d'images détenait 46,98 % de la part du marché des transformateurs de vision en 2024 et le sous-titrage d'images devrait croître à un TCAC de 33,87 % jusqu'en 2030.
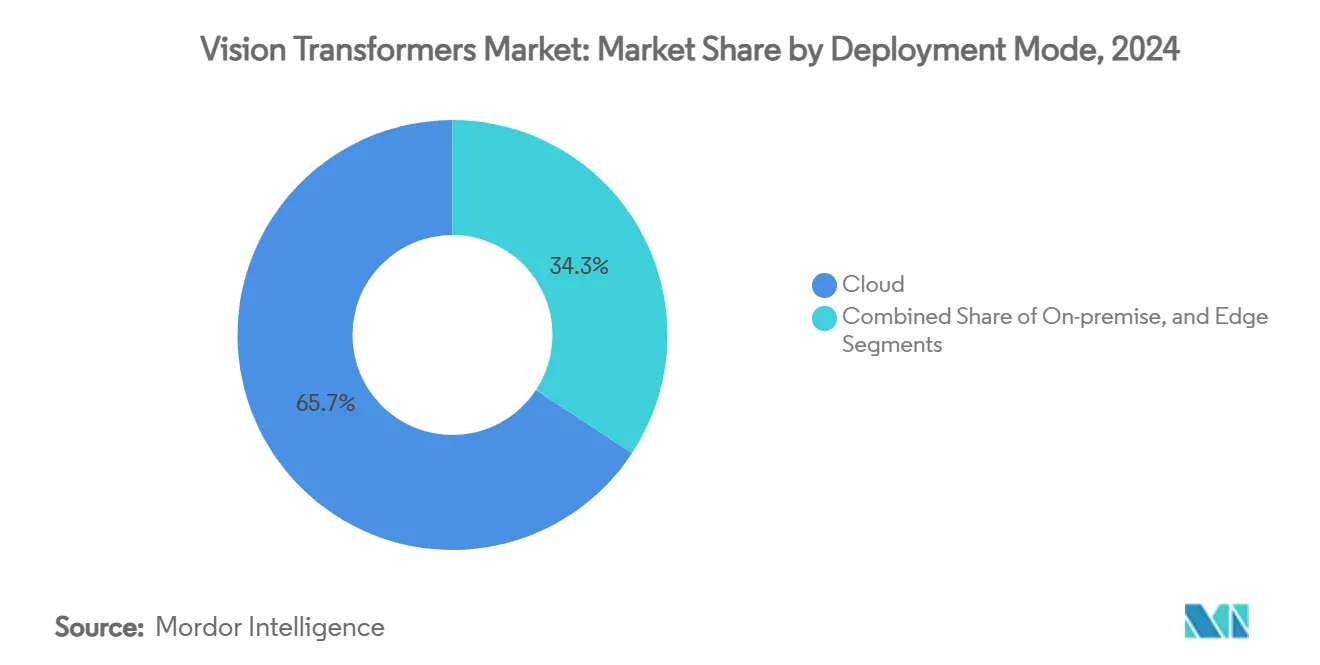
- Par mode de déploiement, les plateformes cloud ont capturé 65,74 % de la taille du marché des transformateurs de vision en 2024 ; le déploiement en périphérie progresse à un TCAC de 33,79 %.
- Par utilisateur final, la santé et les sciences de la vie ont représenté 28,41 % de la part en 2024, tandis que le gouvernement et la défense enregistrent le TCAC le plus rapide de 33,94 % jusqu'en 2030.
- Par géographie, l'Amérique du Nord représentait 38,34 % du marché des transformateurs de vision en 2024, mais l'Asie-Pacifique devrait enregistrer un TCAC de 34,17 % jusqu'en 2030.
Tendances et Perspectives du Marché Mondial des Transformateurs de Vision
Analyse de l'Impact des Moteurs*
| Moteur | (~) % d'Impact sur les Prévisions de TCAC | Pertinence Géographique | Calendrier d'Impact |
|---|---|---|---|
| Adoption généralisée dans les tâches d'IA centrées sur l'image | +8.2% | Amérique du Nord / Europe en tant que premiers adoptants | Moyen terme (2 à 4 ans) |
| Prolifération des GPU, TPU avancés et puces d'IA en périphérie | +7.8% | Usines aux États-Unis, en Chine, à Taïwan | Court terme (≤ 2 ans) |
| Besoin des systèmes autonomes en perception en temps réel | +6.9% | Pôles mondiaux de l'automobile et de la défense | Moyen terme (2 à 4 ans) |
| Essor des piles de transformateurs multimodaux vision-langage | +5.4% | Diffusion mondiale vers les marchés émergents | Long terme (≥ 4 ans) |
| Avancées en matière de rareté et de quantification orientées vers la périphérie | +4.1% | Fabrication en Asie-Pacifique, R&D en Amérique du Nord | Court terme (≤ 2 ans) |
| Modèles ViT fondamentaux open source abaissant les barrières | +3.8% | Marchés en développement | Moyen terme (2 à 4 ans) |
| Source: Mordor Intelligence | |||
Adoption Généralisée dans les Tâches d'IA Centrées sur l'Image
Les déploiements en entreprise ont dépassé le stade des laboratoires, les entreprises signalant des gains de précision significatifs dans des flux de travail visuels complexes. Les centres de pathologie déployant des modèles à 632 millions de paramètres atteignent une sensibilité diagnostique de 94,11 % dans la détection du cancer multi-classes, accélérant l'aide à la décision en oncologie. [1]Shakarami, "DepViT-CAD : Diagnostic du Cancer Basé sur un Transformateur de Vision Déployable," arxiv.orgLes fabricants intègrent des modèles riches en attention pour identifier les défauts de surface minimes que les CNN manquent fréquemment, réduisant le temps d'inspection manuelle de 38 %. Les équipes de back-office financier s'appuient sur l'analyse de documents activée par les ViT qui atteint une précision de 98 % au niveau des champs, réduisant les erreurs liées au papier et accélérant le rapprochement des factures. Ces gains de performance encouragent les directeurs techniques à migrer les opérations visuelles vers des architectures de transformateurs, renforçant la trajectoire du marché des transformateurs de vision.
Prolifération des GPU, TPU Avancés et Puces d'IA en Périphérie
Les cycles matériels se raccourcissent à mesure que les hyperscalers et les concepteurs de systèmes sur puce libèrent de nouvelles bandes passantes mémoire et densités de calcul. Les cartes NVIDIA H200 sont proposées à environ 30 000 USD et offrent un débit de 4,8 To/s, permettant aux ViT à 70 milliards de paramètres de s'entraîner en 30 % moins d'époques. Parallèlement, la pile d'inférence Florence-2 de Microsoft démontre un fonctionnement en périphérie à 15 W sur des appareils de classe Raspberry Pi, étendant la pertinence des transformateurs aux points de terminaison à ressources limitées.[2]Hackster.io, "Modèles Vision-Langage en Périphérie," hackster.io Les pénuries de mémoire à haute bande passante restent un goulot d'étranglement, mais s'atténuent à mesure que de nouveaux fournisseurs de modules montent en puissance au Japon et en Corée du Sud.
Besoin des Systèmes Autonomes en Perception en Temps Réel
Les programmes de conduite autonome, de Tesla aux consortiums européens de convois de camions, s'appuient sur une perception basée uniquement sur les caméras, alimentée par des ViT légers qui réduisent le coût de calcul de 90 % tout en conservant la précision contextuelle. Dans le domaine de la défense, les ViT accélérés par FPGA permettent une reconnaissance de cibles en une fraction de seconde sur les flux de radar à synthèse d'ouverture, permettant aux aéronefs de patrouille maritime de différencier les navires combattants des navires civils dans des scènes encombrées. Ces scénarios sensibles à la latence soulignent la demande de blocs d'attention épars et d'arithmétique en précision mixte qui intègrent la logique des transformateurs dans des budgets d'alimentation stricts.
Essor des Piles de Transformateurs Multimodaux Vision-Langage
Les développeurs fusionnent les transformateurs de vision avec de grands modèles de langage pour débloquer un raisonnement inter-domaines plus riche. Le Phi-3 Vision de Microsoft à 4,2 milliards de paramètres compresse les capacités multimodales dans une empreinte déployable en périphérie, tandis que l'architecture VILA de NVIDIA associe des encodeurs ViT à des décodeurs de langage quantifiés pour exceller dans les questions-réponses vidéo, surpassant des références plus importantes. Les moteurs de recherche de commerce électronique utilisant l'alignement image-texte enregistrent une hausse du taux de clics de 4,95 % à mesure que les acheteurs reçoivent des correspondances visuelles plus pertinentes. La traction multimodale élargit la base adressable du marché des transformateurs de vision, touchant le service client, la robotique et les flux de travail de modération de contenu.
Analyse de l'Impact des Contraintes*
| Contrainte | (~) % d'Impact sur les Prévisions de TCAC | Pertinence Géographique | Calendrier d'Impact |
|---|---|---|---|
| Coût de calcul élevé et consommation d'énergie | -4.7% | Économies en développement les plus touchées | Court terme (≤ 2 ans) |
| Exigences de pré-entraînement gourmandes en données | -3.2% | Secteurs verticaux spécifiques à un domaine | Moyen terme (2 à 4 ans) |
| Enchevêtrements de brevets sur la propriété intellectuelle d'accélération de l'attention | -2.1% | Litiges aux États-Unis et dans l'UE | Long terme (≥ 4 ans) |
| Risques réglementaires et de sécurité liés aux hallucinations des transformateurs | -1.8% | Amérique du Nord et Europe | Moyen terme (2 à 4 ans) |
| Source: Mordor Intelligence | |||
Coût de Calcul Élevé et Consommation d'Énergie
Le prix des nœuds GPU H100 basés sur le cloud varie entre 2,80 USD et 10,00 USD par heure, mettant l'expérimentation hors de portée des petites entreprises.[3]Cyfuture Cloud, "Prix du GPU Nvidia H100 2025," cyfuture.cloud La consommation d'énergie des centres de données augmente également fortement : un ViT à 70 milliards de paramètres peut consommer 1,2 MWh lors d'une seule exécution d'entraînement multi-époques, mettant à rude épreuve les installations qui manquent de compensations en énergie renouvelable. Les organisations atténuent les coûts grâce à des pipelines hybrides — entraînement dans le cloud, puis exportation des poids INT4 quantifiés vers des accélérateurs en périphérie. La mise en commun de la mémoire et la rareté structurée réduisent davantage la puissance active, mais leur adoption reste inégale dans les infrastructures héritées.
Exigences de Pré-Entraînement Gourmandes en Données
Les ViT fondamentaux exigent souvent des millions d'images étiquetées pour se généraliser, un obstacle dans les domaines réglementés tels que la santé. Le modèle de pathologie Virchow a nécessité 1,5 million de lames pour atteindre une AUC de 0,949. Une rareté similaire des ensembles de données apparaît dans l'inspection industrielle où les images propriétaires ne peuvent pas être partagées en externe en vertu de contraintes de non-divulgation. Les pipelines de données synthétiques aident, mais ils impliquent une validation robuste pour prévenir le surapprentissage et les hallucinations. Les régions soumises à des lois strictes sur la souveraineté des données, comme l'UE, font face à une complexité accrue lors de la fédération de l'entraînement au-delà des frontières, allongeant les cycles de développement et freinant l'élan de croissance du marché des transformateurs de vision.
*Nos prévisions considèrent les impacts des moteurs et des contraintes comme directionnels et non additifs. Les prévisions d'impact reflètent la croissance de référence, les effets de composition et les interactions entre variables.
Analyse des Segments
Par Composant : L'Infrastructure Matérielle Stimule l'Adoption
Le matériel a représenté 55,34 % des revenus de 2024, soulignant comment la disponibilité du calcul sous-tend le marché des transformateurs de vision. Les GPU H200 phares sont livrés avec 141 Go de HBM et une bande passante de 4,8 To/s, offrant une inférence 50 % plus rapide que leurs prédécesseurs et réduisant les temps d'itération pour les entreprises expérimentant à grande échelle. La couche de services s'étend également à mesure que les fournisseurs cloud intègrent des pipelines ViT conteneurisés dans des offres gérées, supprimant la surcharge DevOps pour les adoptants du marché intermédiaire.
Les puces d'IA en périphérie sont au cœur de la croissance. Avec un TCAC de 33,73 %, elles convertissent l'intelligence de classe centre de données en plateformes déployables sur le terrain. Florence-2 de Microsoft montre qu'un ordinateur monocarte à 60 USD peut héberger un ViT épars et maintenir une inférence à 20 images par seconde dans une enveloppe d'alimentation de 15 W. L'intégration étroite entre le silicium, le micrologiciel et les méthodes de compression de modèles façonne un écosystème de composants où la valeur migre vers des piles verticalement optimisées.
Note: Parts de segments de tous les segments individuels disponibles à l'achat du rapport


Par Application : La Classification d'Images Conserve sa Tête ; le Sous-Titrage Progresse
La classification d'images a conservé une part de 46,98 % en 2024, portée par la fabrication, le commerce de détail et les diagnostics médicaux à la recherche d'une capture globale du contexte des pixels. En oncologie, DepViT-CAD stimule la taille du marché des transformateurs de vision pour le diagnostic du cancer avec une sensibilité de 94,11 % sur 11 malignités.
Le sous-titrage d'images, cependant, est le segment à la croissance la plus rapide avec un TCAC de 33,87 %. Les portails de commerce électronique intègrent des décodeurs ViT-texte pour enrichir les métadonnées des catalogues, générant des descriptions automatisées qui améliorent la découvrabilité des produits. Pendant ce temps, les segments de détection d'objets exploitent des architectures de transformateurs pour la défense et la conduite autonome, où les couches d'attention fusionnent des réseaux de caméras sans LiDAR en une compréhension cohérente de la scène. La part du marché des transformateurs de vision dans les tâches de segmentation augmente également, à mesure que les ViT efficaces en annotation réduisent le coût de l'étiquetage pixel par pixel.
Par Mode de Déploiement : Le Cloud Domine ; la Périphérie s'Accélère
Les plateformes cloud détenaient 65,74 % de part en 2024 grâce aux flottes GPU à la demande chez AWS, GCP et Azure. L'accès à la demande aux clusters H200 à un prix proche de 10 USD par heure démocratise l'expérimentation à grande échelle sans dépenses d'investissement initiales. Pourtant, les déploiements en périphérie progressent à un TCAC de 33,79 % à mesure que la robotique, les villes intelligentes et l'IoT industriel exigent une latence inférieure à 100 ms et une inférence souveraine en matière de données.
Des topologies hybrides émergent : l'entraînement reste centré sur le cloud, tandis que les modèles distillés ou quantifiés résident sur des passerelles en périphérie ou des modules de calcul embarqués dans les véhicules. Les cartes de classe Jetson exécutent des ViT INT4 à moins de 15 W, montrant une économie viable pour la robotique alimentée par batterie. À mesure que les compilateurs de rareté arrivent à maturité, le débit d'inférence en périphérie devrait tripler d'ici 2027, redistribuant davantage la taille du marché des transformateurs de vision entre les empreintes cloud et sur site.
Note: Parts de segments de tous les segments individuels disponibles à l'achat du rapport
Par Utilisateur Final : La Santé Commande la Valeur ; la Défense Mène la Croissance
La santé et les sciences de la vie représentent 28,41 % des dépenses de 2024, exploitant les ViT en radiologie, pathologie et ophtalmologie. L'AUC de 0,949 du modèle Virchow sur 17 cancers illustre comment le pré-entraînement spécifique à un domaine répond aux seuils stricts de précision clinique.
Le gouvernement et la défense est le segment à la croissance la plus rapide avec un TCAC de 33,94 %. Les programmes de surveillance maritime intègrent désormais le traitement SAR activé par les ViT à bord des aéronefs de patrouille, automatisant la classification des navires et la détection des anomalies. Les équipementiers automobiles intensifient également leurs investissements à mesure que les robotaxis à caméra uniquement approchent de la maturité commerciale. Le commerce de détail, le commerce électronique et les médias suivent de près, stimulés par la recherche visuelle et la personnalisation du contenu.
Analyse Géographique
L'Amérique du Nord a contribué à 38,34 % de la valeur de 2024. Un dense regroupement de fournisseurs de GPU, d'hyperscalers cloud et de laboratoires académiques accélère les cycles de commercialisation. Les voies d'accélération de la FDA pour les diagnostics assistés par l'IA stimulent davantage les déploiements dans le secteur de la santé.
L'Asie-Pacifique affiche le TCAC le plus élevé de 34,17 %. Les programmes soutenus par l'État chinois canalisent des capitaux vers des startups de silicium pour transformateurs, stimulant les dépenses projetées en IA de 98 milliards USD en 2025. Le Japon a réservé 960 millions USD pour des clusters de calcul favorisant les ViT en langue japonaise, et la Mission IndiaAI de l'Inde finance un supercluster souverain de 4 096 GPU.
L'Europe met l'accent sur l'IA éthique. La loi européenne sur l'IA pousse les entreprises vers des déploiements à forte composante périphérique et l'apprentissage fédéré, favorisant l'entraînement ViT préservant la confidentialité. Les subventions pour les centres de données à faible émission de carbone en Scandinavie attirent également des charges de travail de transformateurs, équilibrant les contraintes énergétiques régionales.


Paysage Concurrentiel
Le marché des transformateurs de vision présente une concentration modérée. La pile matérielle de NVIDIA crée des barrières à l'entrée, mais le leadership logiciel est contesté entre Google (brevets Universal Transformer), Microsoft (modèles en périphérie Phi-3 Vision) et Meta (dérivés ViT open source). Les acteurs cloud établis vendent des GPU avec des services DevOps clés en main, réduisant le délai de preuve de concept.
L'accent stratégique se déplace vers les modèles verticaux : Lockheed Martin adapte des ViT de qualité défense avec un durcissement cryptographique sur l'appareil, et les entreprises émergentes de medtech poursuivent l'autorisation de la FDA pour les charges de travail de pathologie et de radiologie. Les litiges en matière de brevets autour des noyaux d'attention et des transformateurs à mémoire efficace créent une complexité de licence qui pourrait consolider la propriété intellectuelle entre les mains d'un petit nombre de concédants de licence.
Les chaînes d'outils optimisées pour la périphérie constituent le prochain champ de bataille. Le brevet d'attention multi-vues de Qualcomm et les intégrations NPU basées sur ARM visent à rivaliser avec NVIDIA sur les points de terminaison à faible consommation, tandis que Graphcore et AMD ciblent les scénarios de centres de données à haute densité. Les alliances stratégiques entre fournisseurs de silicium et studios logiciels — tels que les offres groupées Jetson-VILA — dicteront la capture de valeur jusqu'en 2030.
Leaders du Secteur des Transformateurs de Vision
NVIDIA Corporation
Google LLC (Alphabet)
Microsoft Corporation
Meta Platforms Inc.
Amazon Web Services Inc.
- *Avis de non-responsabilité : les principaux acteurs sont triés sans ordre particulier

Développements Récents du Secteur
- Juillet 2025 : Lockheed Martin a dévoilé des analyses de radar à synthèse d'ouverture alimentées par des ViT pour la surveillance maritime autonome, intégrant des pipelines MLOps embarqués.
- Juillet 2025 : Les investissements étrangers dans les entreprises d'IA chinoises devraient atteindre 98 milliards USD, les startups canalisant des fonds vers la R&D du marché des transformateurs de vision.
- Juin 2025 : SoftBank a présenté une allocation de 33,2 milliards USD aux programmes de superintelligence alignés sur OpenAI, prévoyant d'intégrer des ViT dans les entreprises de son portefeuille.
- Juin 2024 : Tesla a commencé des essais de robotaxis à Austin en utilisant des piles de perception ViT basées uniquement sur les caméras pour la navigation en conduite entièrement autonome.


Portée du Rapport sur le Marché Mondial des Transformateurs de Vision
| Matériel |
| Logiciel |
| Services |
| Classification d'Images |
| Sous-Titrage d'Images |
| Segmentation d'Images |
| Détection d'Objets |
| Autres Applications |
| Cloud |
| Sur Site |
| Périphérie |
| Commerce de Détail et Commerce Électronique |
| Médias et Divertissement |
| Automobile |
| Gouvernement et Défense |
| Santé et Sciences de la Vie |
| Autres Utilisateurs Finaux |
| Amérique du Nord | États-Unis | |
| Canada | ||
| Mexique | ||
| Amérique du Sud | Brésil | |
| Argentine | ||
| Reste de l'Amérique du Sud | ||
| Europe | Allemagne | |
| Royaume-Uni | ||
| France | ||
| Russie | ||
| Reste de l'Europe | ||
| Asie-Pacifique | Chine | |
| Japon | ||
| Inde | ||
| Corée du Sud | ||
| Australie | ||
| Reste de l'Asie-Pacifique | ||
| Moyen-Orient et Afrique | Moyen-Orient | Arabie Saoudite |
| Émirats Arabes Unis | ||
| Reste du Moyen-Orient | ||
| Afrique | Afrique du Sud | |
| Égypte | ||
| Reste de l'Afrique | ||
| Par Composant | Matériel | ||
| Logiciel | |||
| Services | |||
| Par Application | Classification d'Images | ||
| Sous-Titrage d'Images | |||
| Segmentation d'Images | |||
| Détection d'Objets | |||
| Autres Applications | |||
| Par Mode de Déploiement | Cloud | ||
| Sur Site | |||
| Périphérie | |||
| Par Utilisateur Final | Commerce de Détail et Commerce Électronique | ||
| Médias et Divertissement | |||
| Automobile | |||
| Gouvernement et Défense | |||
| Santé et Sciences de la Vie | |||
| Autres Utilisateurs Finaux | |||
| Par Géographie | Amérique du Nord | États-Unis | |
| Canada | |||
| Mexique | |||
| Amérique du Sud | Brésil | ||
| Argentine | |||
| Reste de l'Amérique du Sud | |||
| Europe | Allemagne | ||
| Royaume-Uni | |||
| France | |||
| Russie | |||
| Reste de l'Europe | |||
| Asie-Pacifique | Chine | ||
| Japon | |||
| Inde | |||
| Corée du Sud | |||
| Australie | |||
| Reste de l'Asie-Pacifique | |||
| Moyen-Orient et Afrique | Moyen-Orient | Arabie Saoudite | |
| Émirats Arabes Unis | |||
| Reste du Moyen-Orient | |||
| Afrique | Afrique du Sud | ||
| Égypte | |||
| Reste de l'Afrique | |||


Questions Clés Répondues dans le Rapport
Quelle valeur de revenus est projetée pour les transformateurs de vision d'ici 2030 ?
La taille du marché des transformateurs de vision devrait atteindre 1,58 milliard USD d'ici 2030, soutenue par un TCAC de 33,67 %.
Quelle application domine actuellement les dépenses ?
La classification d'images est en tête avec une part de 46,98 % en 2024 en raison d'une adoption généralisée dans les flux de travail visuels de la santé, de la fabrication et du commerce de détail.
Pourquoi les déploiements en périphérie croissent-ils plus vite que le cloud ?
L'inférence en périphérie réduit la latence, diminue les coûts de bande passante et facilite la conformité à la souveraineté des données, ce qui explique son rythme de croissance de TCAC de 33,79 %.
Quelle région offre le plus grand potentiel de croissance ?
L'Asie-Pacifique devrait se développer à un TCAC de 34,17 %, propulsée par des investissements gouvernementaux massifs dans l'IA en Chine, en Inde et au Japon.
Comment les coûts de calcul impactent-ils l'adoption ?
Le prix élevé des GPU et la consommation d'énergie retranchent environ 4,7 points de pourcentage du TCAC prévu, incitant les entreprises à adopter la quantification, la rareté et des stratégies hybrides cloud-périphérie.
Quels secteurs émergent au-delà de la santé et de la défense ?
Le commerce de détail et le commerce électronique adoptent la recherche visuelle alimentée par les ViT, les entreprises automobiles font progresser l'autonomie basée sur les caméras, et les entreprises médiatiques explorent le sous-titrage automatisé de contenu.
Dernière mise à jour de la page le:




