Taille et part du marché des bases de données en mémoire
VUE D’ENSEMBLE DU MARCHÉ
| Période d'étude | 2020 - 2031 |
|---|---|
| Taille du Marché (2026) | 8.05 Milliards de dollars |
| Taille du Marché (2031) | 15.31 Milliards de dollars |
| Taux de croissance (2026 - 2031) | 13.72% CAGR |
| Marché à la Croissance la Plus Rapide | Asie-Pacifique |
| Plus Grand Marché | Asie-Pacifique |
| Concentration du Marché | Moyen |
Acteurs majeurs *Avis de non-responsabilité : les principaux acteurs sont triés sans ordre particulier Image © Mordor Intelligence. La réutilisation nécessite une attribution sous CC BY 4.0. | |
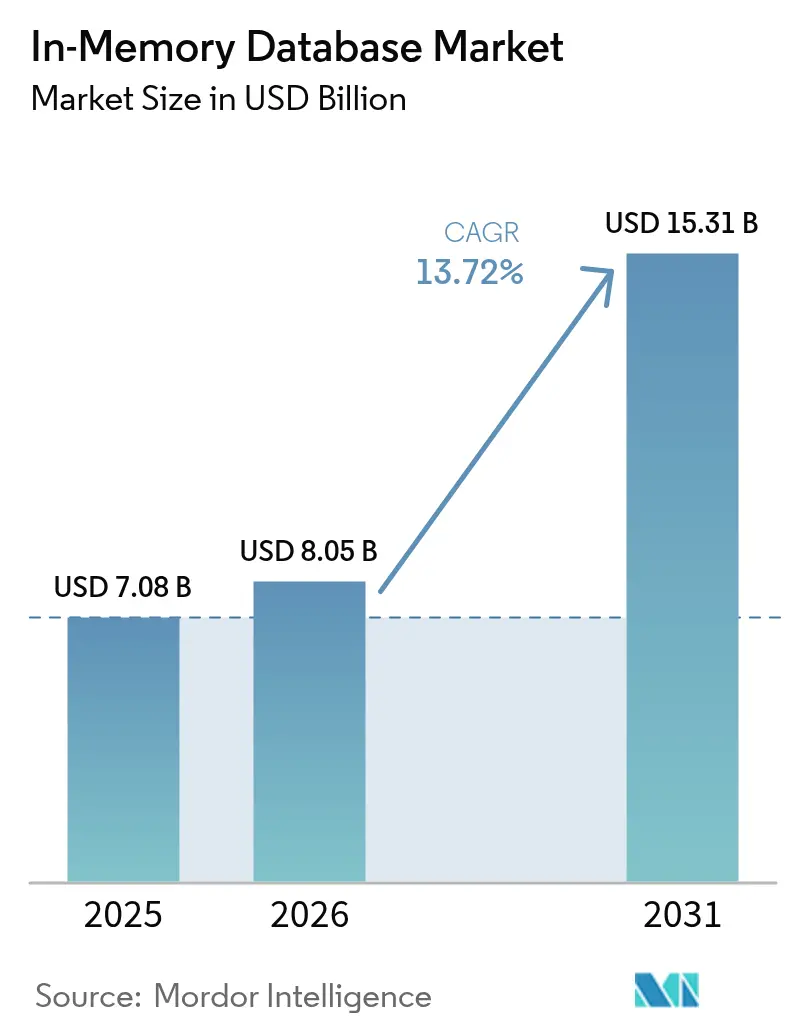
Analyse du marché des bases de données en mémoire par Mordor Intelligence
La taille du marché des bases de données en mémoire devrait passer de 7,08 milliards USD en 2025 à 8,05 milliards USD en 2026 et devrait atteindre 15,31 milliards USD d'ici 2031, à un CAGR de 13,72 % sur la période 2026-2031. Les exigences de performance en dessous de la milliseconde émanant des microservices natifs du cloud, des moteurs d'inférence d'intelligence artificielle et des plateformes d'analyse en flux ont continué à pousser les entreprises vers des architectures centrées sur la mémoire. La baisse des prix de la DRAM et l'arrivée de modules de mémoire persistante basés sur CXL ont réduit le coût total de possession, encourageant davantage de charges de travail à migrer depuis les systèmes reposant sur des disques. Les déploiements en périphérie dans les véhicules connectés et les usines de l'Internet des objets industriel ont encore élargi la demande, car le traitement local évite les pénalités de latence réseau. La dynamique concurrentielle est restée fluide, les fournisseurs traditionnels approfondissant leurs intégrations avec les clouds hyperscale tandis que les forks open source gagnaient en dynamisme, offrant aux acheteurs de nouvelles voies pour éviter la dépendance vis-à-vis d'un fournisseur.
Principaux enseignements du rapport
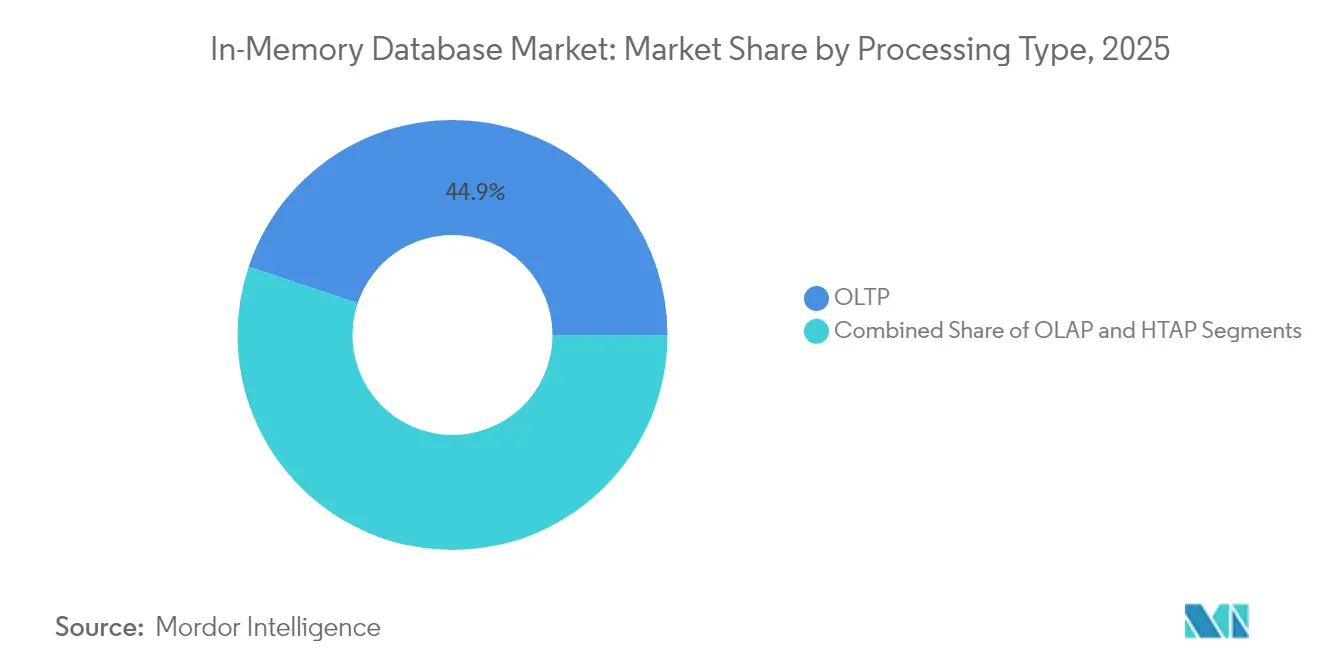
- Par type de traitement, le traitement des transactions en ligne (OLTP) a dominé avec 44,85 % de la part de marché des bases de données en mémoire en 2025, tandis que le traitement transactionnel/analytique hybride (HTAP) devrait croître à un CAGR de 20,68 % jusqu'en 2031.
- Par mode de déploiement, les installations sur site ont conservé 55,15 % de la part de revenus en 2025 ; les déploiements en périphérie et embarqués devraient se développer à un CAGR de 22,55 % jusqu'en 2031.
- Par modèle de données, le SQL relationnel a capturé une part de 59,95 % en 2025, tandis que les plateformes multi-modèles devraient afficher un CAGR de 19,6 % entre 2026 et 2031.
- Par taille d'organisation, les grandes entreprises ont détenu 70,15 % de la taille du marché des bases de données en mémoire en 2025 ; les petites et moyennes entreprises enregistreront le CAGR le plus rapide à 17,7 % jusqu'en 2031.
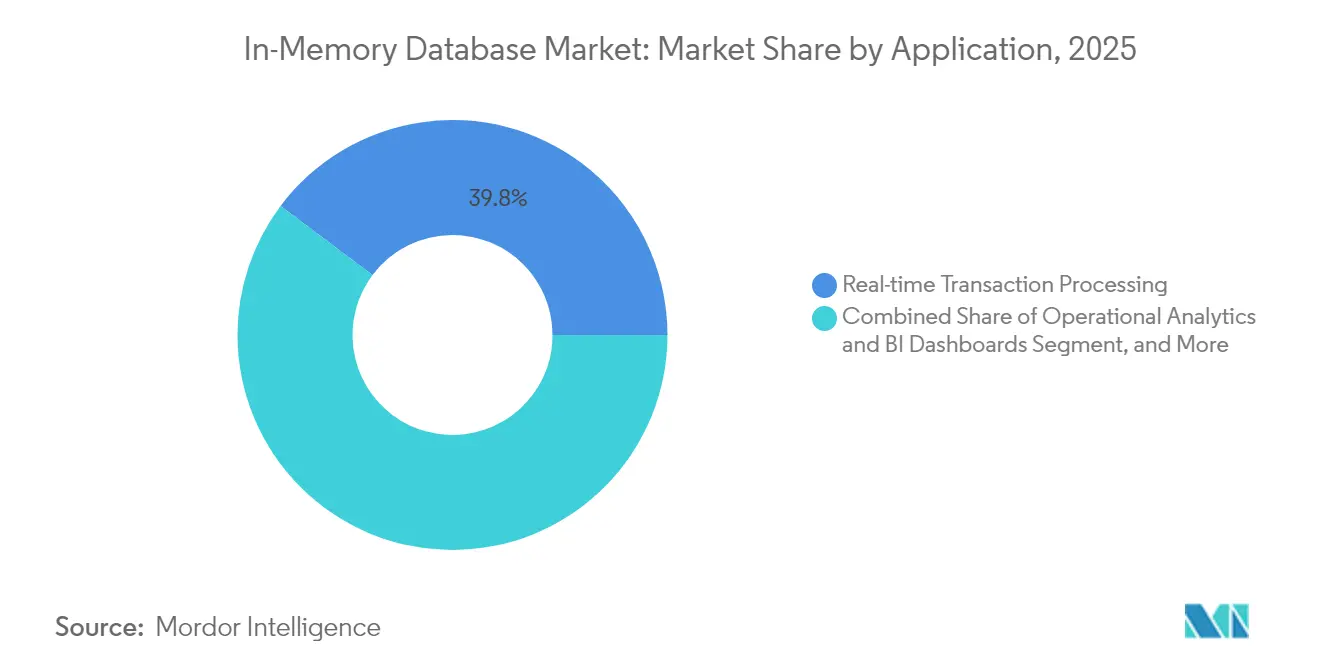
- Par application, le traitement des transactions en temps réel a représenté 39,75 % de la taille du marché des bases de données en mémoire en 2025, tandis que le service de modèles d'intelligence artificielle et d'apprentissage automatique devrait se développer à un CAGR de 23,1 % jusqu'en 2031.
- Par secteur d'activité des utilisateurs finaux, le BFSI a dominé avec 27,95 % de la part de revenus en 2025 ; la santé et les sciences de la vie sont positionnées pour un CAGR de 17,4 % jusqu'en 2031.
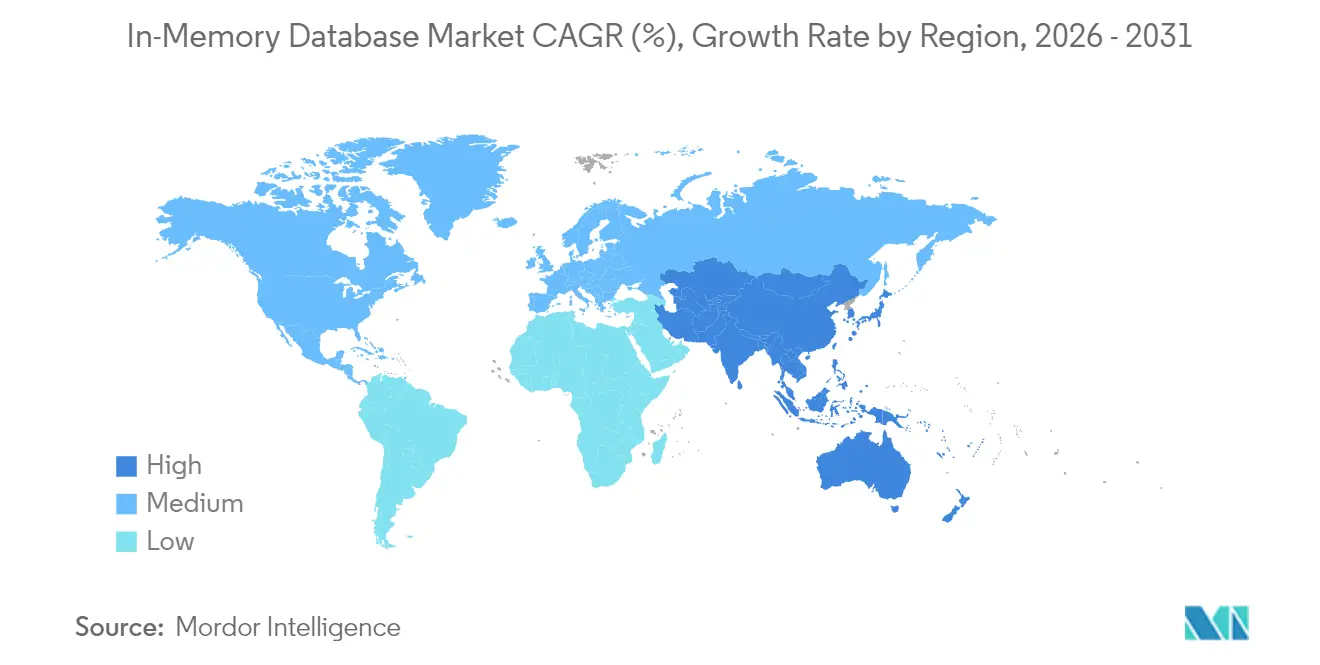
- Par géographie, l'Asie-Pacifique a représenté 31,95 % des revenus mondiaux en 2025 et reste la région à la croissance la plus rapide avec un CAGR de 16,65 % jusqu'en 2031.
Remarque : Les chiffres de la taille du marché et des prévisions de ce rapport sont générés à l’aide du cadre d’estimation propriétaire de Mordor Intelligence, mis à jour avec les données et analyses les plus récentes disponibles en 2026.
Tendances et perspectives du marché mondial des bases de données en mémoire
Analyse de l'impact des moteurs*
| Moteur | (~) % d'impact sur les prévisions de CAGR | Pertinence géographique | Calendrier d'impact |
|---|---|---|---|
| Microservices natifs du cloud exigeant une latence inférieure à la milliseconde | +3.2% | Mondial, avec une concentration en Amérique du Nord et dans l'UE | Court terme (≤ 2 ans) |
| Baisse du prix USD/Go de la DRAM et de la mémoire persistante élargissant l'écart de coût total de possession par rapport aux disques | +2.8% | Mondial, adoption précoce dans les pôles manufacturiers d'Asie-Pacifique | Moyen terme (2-4 ans) |
| Adoption de l'analyse en flux dans le BFSI et les télécommunications pour la fraude et la qualité de service réseau | +2.1% | Centres financiers d'Amérique du Nord et d'Europe, infrastructure télécom d'Asie-Pacifique | Court terme (≤ 2 ans) |
| Architectures HTAP accélérant le service de modèles d'intelligence artificielle et d'apprentissage automatique dans le secteur de la santé | +1.9% | Mondial, avec une adoption réglementaire dans l'UE et en Amérique du Nord | Moyen terme (2-4 ans) |
| Cas d'usage du calcul en périphérie (véhicules connectés, Internet des objets industriel) nécessitant des bases de données en mémoire embarquées | +2.4% | Fabrication en Asie-Pacifique, corridors automobiles en Amérique du Nord | Long terme (≥ 4 ans) |
| Source: Mordor Intelligence | |||
Microservices natifs du cloud exigeant une latence inférieure à la milliseconde
L'adoption des architectures natives du cloud a reconfiguré les références de performance, les microservices conteneurisés nécessitant un accès aux données en microsecondes. Les magasins de sessions, les moteurs de personnalisation et les plateformes de trading à haute fréquence ont migré des bases de données reposant sur des disques vers des magasins centrés sur la mémoire, car chaque milliseconde de délai réduisait les taux de conversion ou les bénéfices de trading. Dragonfly a démontré 6,43 millions d'opérations par seconde sur le silicium AWS Graviton3E, illustrant le plafond désormais attendu des niveaux de base de données.[1]DragonflyDB, "2024 New Year, New Number," dragonflydb.io Les institutions financières et les opérateurs du commerce numérique qui ont migré leurs monolithes vers des systèmes distribués ont constaté que les améliorations des temps de réponse se traduisaient par des gains de revenus tangibles, renforçant l'importance à court terme de ce moteur.
Baisse des coûts de la DRAM et de la mémoire persistante élargissant l'écart de coût total de possession
Les prix au comptant mondiaux des modules DDR4 et DDR5 ont continué de baisser, tandis que le prototype de module mémoire CXL hybride de Samsung a démontré une latence comparable à celle de la DRAM avec persistance, créant un profil de coût convaincant. Les opérateurs hyperscale ont mutualisé la mémoire entre les racks, réduisant la capacité inutilisée et les cycles de sauvegarde. Les entreprises ont réorienté leurs feuilles de route vers le déploiement en mémoire, car la prime par rapport aux baies SSD s'est réduite, notamment pour les charges de travail analytiques avec des fenêtres SLA strictes. L'effet est visible dans les pôles manufacturiers d'Asie-Pacifique, où de grands ensembles de données historiques sont transférés en mémoire pour l'analyse en temps réel des jumeaux numériques.
Adoption de l'analyse en flux dans le BFSI et les télécommunications
Les banques ont déployé des systèmes de détection de fraude en flux traitant des millions d'autorisations de cartes par seconde grâce au moteur en mémoire d'Aerospike. Les opérateurs de télécommunications déployant la 5G ont surveillé les journaux des réseaux d'accès radio en temps réel pour maintenir la qualité de service, en exploitant les recherches vectorielles sur MongoDB pour signaler les anomalies. La réglementation en Amérique du Nord et en Europe a exigé des rapports d'activités suspectes en temps réel, poussant la courbe d'adoption de ce moteur fortement à la hausse.
Architectures HTAP accélérant le service de modèles d'intelligence artificielle et d'apprentissage automatique
Le traitement transactionnel/analytique hybride a supprimé les délais d'extraction, transformation et chargement en unifiant les écritures et l'analyse dans le même pool mémoire. Oracle a intégré des grands modèles de langage dans HeatWave GenAI afin que les dossiers patients puissent être interrogés et évalués pour des décisions cliniques sans déplacement de données. Les prestataires de soins de santé ont adopté des magasins HTAP pour servir des prédictions lors des consultations, améliorant les résultats et réduisant les frais d'infrastructure, ce qui a soutenu une croissance soutenue à moyen terme.
Analyse de l'impact des freins*
| Frein | (~) % d'impact sur les prévisions de CAGR | Pertinence géographique | Calendrier d'impact |
|---|---|---|---|
| Préoccupations liées à la dépendance vis-à-vis des fournisseurs concernant les formats en mémoire propriétaires | -1.8% | Mondial, affectant particulièrement les entreprises multi-cloud | Court terme (≤ 2 ans) |
| Complexité de conception de la haute disponibilité pour les clusters de plus de 40 To | -1.2% | Déploiements en entreprise en Amérique du Nord et dans l'UE | Moyen terme (2-4 ans) |
| Lois sur la souveraineté des données (par ex., CSL chinoise, RGPD de l'UE) limitant la réplication mondiale | -0.9% | UE, Chine, avec des répercussions sur les déploiements multinationaux | Long terme (≥ 4 ans) |
| Source: Mordor Intelligence | |||
Préoccupations liées à la dépendance vis-à-vis des fournisseurs concernant les formats propriétaires
Le changement de licence de Redis en 2024 a accru la méfiance des acheteurs envers les formats propriétaires, incitant AWS, Google et Oracle à soutenir le fork Valkey sous la Linux Foundation. Les entreprises budgétisant des projets de bases de données pluriannuels ont intégré les coûts de sortie, ralentissant les cycles d'achat. Pour atténuer le risque, certaines ont adopté des couches d'orchestration multi-bases de données, mais ces abstractions ont introduit des pénalités de latence qui ont partiellement annulé les gains de vitesse liés à la mémoire.
Complexité de conception de la haute disponibilité pour les grands clusters
Les clusters de plus de 40 To ont rencontré une surcharge de protocole qui dégradait les temps de synchronisation des réplicas. L'approche gossip de Redis Cluster évoluait de manière quadratique, tandis que l'orchestration alternative de Dragonfly s'est améliorée mais nécessitait encore des scripts de surveillance complexes. Les charges de travail des services financiers exigeant une disponibilité à cinq neuf ont hésité à migrer les ensembles de données les plus volumineux entièrement en mémoire, optant pour des niveaux hybrides qui diluaient les performances de pointe.
*Nos prévisions considèrent les impacts des moteurs et des contraintes comme directionnels et non additifs. Les prévisions d'impact reflètent la croissance de référence, les effets de composition et les interactions entre variables.
Analyse des segments
Par type de traitement : le HTAP émerge comme architecture unifiée
Le segment OLTP a détenu 44,85 % de la part de marché des bases de données en mémoire en 2025, soulignant la dépendance continue aux charges de travail transactionnelles à haute intégrité dans les secteurs bancaire, du commerce électronique et des systèmes ERP. La demande a persisté car les enregistrements critiques nécessitaient toujours la conformité ACID, les entreprises payant une prime de performance pour des validations en dessous de la milliseconde. Les déploiements OLAP répondaient aux interfaces d'informatique décisionnelle établies, mais ont connu une croissance lente à mesure que l'analyse se tournait vers des moteurs plus flexibles.
Le HTAP a progressé avec un CAGR prévu de 20,68 % de 2026 à 2031, les entreprises recherchant la simplicité d'une plateforme unique. La plateforme de GridGain a démontré des accélérations allant jusqu'à 1 000 fois par rapport aux systèmes basés sur disque tout en conservant la prise en charge d'ANSI SQL-99. Les calculs de risque en temps réel et les jumeaux de chaîne d'approvisionnement nécessitaient un accès simultané en lecture-écriture, faisant du HTAP l'architecture privilégiée. La convergence a débloqué des budgets supplémentaires de départements auparavant cloisonnés entre les opérations et l'analyse, poussant le marché des bases de données en mémoire vers des conceptions unifiées.



Par mode de déploiement : le calcul en périphérie stimule la croissance embarquée
Les installations sur site ont capturé 55,15 % des revenus de 2025, car les secteurs réglementés exigeaient un contrôle total sur la résidence des données et des architectures de haute disponibilité personnalisées. Les piles logicielles d'entreprise héritées étroitement intégrées aux bases de données sur site ont ancré les dépenses même à mesure que les clouds publics mûrissaient. Les déploiements cloud ont néanmoins progressé, les entreprises nativement numériques adoptant des services gérés pour éviter l'administration de l'infrastructure.
Les déploiements en périphérie et embarqués ont affiché une perspective de CAGR de 22,55 %, alimentée par les voitures connectées et les passerelles de l'Internet des objets industriel. Les véhicules modernes génèrent environ 300 To annuellement, ce qui exige un traitement embarqué pour les fonctionnalités autonomes. TDengine a atteint une compression 10 fois supérieure à Elasticsearch dans la télémétrie des véhicules intelligents, réduisant la bande passante pour les transferts en amont. Les fabricants ont appliqué des stratégies similaires sur les lignes de production pour détecter instantanément les défauts. Ce changement a signalé que les gains de performance autrefois réservés aux centres de données étaient désormais indispensables en périphérie, élargissant l'empreinte du marché des bases de données en mémoire.
Par modèle de données : les architectures multi-modèles gagnent du terrain
Les moteurs SQL relationnels ont conservé 59,95 % des revenus en 2025, car des décennies de code applicatif et de compétences des développeurs restaient liées à ce modèle. Les entreprises ont hésité à réécrire leurs systèmes centraux, préservant la primauté relationnelle même à mesure que de nouveaux cas d'usage émergaient. Les catégories NoSQL — clé-valeur, document, graphe — répondaient à des schémas flexibles mais servaient des charges de travail plus étroites.
Les plateformes multi-modèles prévoient un CAGR de 19,6 % à mesure que les charges de travail d'intelligence artificielle exigent un stockage unifié pour les enregistrements structurés, les vecteurs et le texte non structuré. Hazelcast a ajouté la recherche vectorielle aux côtés des API clé-valeur traditionnelles. La consolidation de types de données variés dans un seul pool mémoire a réduit la complexité opérationnelle et la latence, permettant l'intelligence artificielle conversationnelle, les graphes de fraude et les pipelines de recommandation. Cette dynamique devrait élargir le marché des bases de données en mémoire à travers des paysages de données hétérogènes.

Par taille d'organisation : les PME accélèrent l'adoption du cloud
Les grandes entreprises ont représenté 70,15 % des revenus en 2025 en raison de l'intensité capitalistique des déploiements à l'échelle du pétaoctet et des exigences strictes en matière de SLA. Les banques mondiales, les opérateurs de télécommunications et les entreprises aérospatiales ont investi dans des clusters redondants avec des téraoctets de DRAM pour assurer la continuité des activités. Leur capacité budgétaire les a protégées des coûts élevés par gigaoctet.
Les petites et moyennes entreprises devraient progresser à un CAGR de 17,7 % grâce aux services gérés. AWS a introduit Aurora DSQL pour combiner la sémantique SQL distribuée avec des performances de style en mémoire. En déléguant la mise à l'échelle et les correctifs aux fournisseurs cloud, les startups ont accédé à une latence de niveau entreprise pour les produits micro-SaaS sans surcharge de personnel. La prise en charge de Valkey par ElastiCache a réduit les dépenses de licence, accélérant la démocratisation du marché des bases de données en mémoire parmi les entreprises aux budgets contraints.
Par application : le service de modèles d'intelligence artificielle et d'apprentissage automatique stimule l'innovation
Le traitement des transactions en temps réel a conservé la plus grande part à 39,75 % en 2025, avec le trading boursier, les passerelles de paiement et les systèmes d'inventaire dépendant des validations instantanées. L'analytique opérationnelle a fourni des tableaux de bord pour la fabrication et l'observabilité informatique, mais a décéléré à mesure que les nouveaux cas d'usage de l'intelligence artificielle captaient les dépenses.
Le service de modèles d'intelligence artificielle et d'apprentissage automatique devrait se développer à un CAGR de 23,1 % à mesure que les entreprises intègrent des index vectoriels et des embeddings directement dans les bases de données pour l'inférence. Microsoft a proposé la mémoire à rétention gérée pour réduire la latence dans l'exécution des grands modèles de langage. Ce modèle intègre l'inférence dans la couche transactionnelle, éliminant les sauts WAN entre les serveurs de modèles et les données sources. Les charges de travail hybrides combinant des mises à jour ACID avec des recherches de similarité vectorielle devraient dominer les revenus incrémentaux du marché des bases de données en mémoire.
Par secteur d'activité des utilisateurs finaux : la santé mène la transformation numérique
Le BFSI a représenté 27,95 % des revenus en 2025, reflétant une adoption précoce pour le trading à haute fréquence et la prévention de la fraude. Les mandats réglementaires pour les rapports en temps réel et les exigences strictes en matière d'objectif de temps de récupération ont sécurisé les investissements continus. Les télécommunications appliquent l'analyse en mémoire pour l'orchestration des réseaux et les informations sur l'expérience client, maintenant une part stable.
La santé et les sciences de la vie affichent une perspective de CAGR de 17,4 %. Corti a publié une infrastructure d'intelligence artificielle spécialisée nécessitant un accès immédiat aux données des patients pour le soutien au diagnostic. Les fournisseurs de dossiers de santé électroniques ont intégré des bases de données HTAP pour alimenter les algorithmes de décision clinique, améliorant la qualité des soins et l'efficacité opérationnelle. La fabrication a investi dans la maintenance prédictive et le commerce de détail a exploité les moteurs de personnalisation, maintenant la diversification globale du secteur des bases de données en mémoire.
Analyse géographique
L'Asie-Pacifique a enregistré les revenus régionaux les plus élevés à 31,95 % en 2025 et a maintenu une perspective de CAGR de 16,65 %. Les programmes nationaux Industrie 4.0 en Chine, au Japon et en Inde ont stimulé l'automatisation des usines qui nécessitait des bases de données historiques en mémoire pour des boucles de rétroaction MES en dessous de la seconde. General Motors a connecté plus de 100 000 connexions de technologie opérationnelle dans son déploiement MES 4.0, illustrant l'échelle des déploiements en périphérie. Des fournisseurs locaux tels que les moteurs relationnels indigènes avancés de Nautilus Technologies ont réduit la dépendance à la propriété intellectuelle étrangère.
L'Amérique du Nord a formé un marché mature mais riche en innovation, centré sur les services financiers, les clouds hyperscale et la recherche et développement en matière de véhicules autonomes. Oracle et Google ont approfondi leur partenariat pour exécuter les services Oracle Database nativement sur Google Cloud, mariant les capacités SQL d'entreprise avec les accélérateurs d'intelligence artificielle. Le financement par capital-risque de la région a soutenu des acteurs émergents tels que Dragonfly, intensifiant le renouvellement concurrentiel.
L'Europe a privilégié la conformité à la souveraineté des données dans le cadre du RGPD, stimulant l'adoption du cloud hybride et favorisant les clusters sur site combinés avec des services gérés dans des centres de données locaux. Oracle a étendu la couverture Database@Azure à des régions supplémentaires de l'UE pour satisfaire aux règles de résidence. Le continent a également vu des déploiements de bases de données HTAP dans le secteur de la santé pour alimenter les diagnostics par intelligence artificielle dans le cadre de cadres de confidentialité stricts.
Le Moyen-Orient et l'Afrique ont investi dans la fibre des villes intelligentes et les dorsales 5G, conduisant à des déploiements pilotes de l'Internet des objets industriel nécessitant une analyse en temps réel. L'Amérique du Sud a gagné du terrain dans les opérations minières et la banque numérique, où la détection de fraude à faible latence a justifié des systèmes centrés sur la mémoire premium. Bien que les dépenses absolues dans ces deux régions soient restées modestes, une croissance à deux chiffres a élargi la diversité mondiale du marché des bases de données en mémoire.

Paysage réglementaire
L'adoption de bases de données en mémoire et les choix de déploiement sont façonnés par les contrôles commerciaux transfrontaliers des semi-conducteurs et les règles de gouvernance de l'IA qui affectent l'accès aux infrastructures informatiques et mémoire haut de gamme utilisées pour exécuter des clusters de bases de données sensibles à la latence. En janvier 2026, le Département du Commerce des États-Unis, le Bureau of Industry and Security (BIS), a révisé la politique d'examen des licences pour les produits informatiques avancés exportés vers la Chine, renforçant les exigences de conformité pour les accélérateurs de pointe utilisés dans les constructions de centres de données qui s'associent couramment à des niveaux de bases de données centrés sur la mémoire.
En Europe, la réglementation est de plus en plus liée aux charges de travail pilotées par l'IA qui utilisent la recherche vectorielle intégrée à la base de données et le HTAP pour prendre en charge le service de modèles et les décisions en temps réel. La loi européenne sur l'intelligence artificielle (Règlement (UE) 2024/1689), adoptée en juin 2024, a établi un cadre harmonisé pour les systèmes d'IA, renforçant la nécessité d'une gouvernance des données solide, d'une auditabilité et de contrôles de confidentialité dans les architectures de bases de données prenant en charge des cas d'usage réglementés, notamment dans les déploiements de la santé, du BFSI et du secteur public.
Analyse de la chaîne de valeur
La chaîne de valeur des bases de données en mémoire couvre les intrants matériels et d'infrastructure (DRAM, mémoire persistante, CPU, réseaux tels que les infrastructures compatibles RDMA, et plateformes serveur), les logiciels de plateforme (moteurs en mémoire propriétaires et open-source, clustering, réplication et composants HTAP), les modèles de livraison cloud et edge (services de bases de données gérés, environnements d'exécution embarqués et couches d'orchestration), et l'intégration applicative dans les secteurs BFSI, télécom, fabrication/IIoT, commerce de détail et santé. Les déploiements sur site restent ancrés dans les secteurs réglementés qui exigent un contrôle sur la résidence des données et une conception haute disponibilité, tandis que les hyperscalers et les éditeurs de logiciels d'entreprise se différencient par des offres gérées, des intégrations natives avec les chaînes d'outils IA et des connecteurs d'écosystème.
Les contraintes en amont sur les semi-conducteurs influencent l'économie de la mise à l'échelle des architectures centrées sur la mémoire, car la tension de l'offre en mémoire haut de gamme et en emballage avancé affecte la disponibilité des serveurs et le coût par Go au niveau de la couche d'infrastructure. Les commentaires de l'industrie fin 2024 à 2025 ont signalé l'emballage avancé (par exemple, la capacité de classe CoWoS) et le resserrement de l'offre de HBM comme des goulots d'étranglement pour le matériel d'IA, ce qui à son tour façonne les cycles de renouvellement des entreprises pour les systèmes denses en mémoire hébergeant des bases de données en mémoire. En aval, les partenaires de mise en œuvre et les intégrateurs de systèmes conditionnent des architectures de référence pour SAP, Oracle et les piles cloud-natives, et les acheteurs évaluent de plus en plus les modèles de gouvernance et de licence (y compris la dynamique du fork Valkey après les changements de licence de Redis) dans le cadre de décisions d'approvisionnement à long terme.
Paysage concurrentiel
Le marché des bases de données en mémoire est resté modérément fragmenté, SAP, Oracle, Microsoft et IBM s'appuyant sur de larges suites d'entreprise pour conserver leur position d'acteurs établis. Leurs feuilles de route intègrent des magasins vectoriels en base de données et des accélérateurs d'apprentissage automatique, répondant aux demandes des clients pour des plateformes unifiées. Le changement de licence de Redis a incité les hyperscalers à approuver Valkey, illustrant comment les modèles de gouvernance peuvent remodeler les lignes concurrentielles.
Des fournisseurs spécialisés tels qu'Aerospike et Hazelcast ont rivalisé sur la prévisibilité, la faible latence à grande échelle et le coût total inférieur par gigaoctet. Le succès d'Aerospike chez PayPal a prouvé la capacité à traiter des signaux de fraude en temps réel sur du matériel standard. Hazelcast a publié la plateforme 5.5 avec des connecteurs étendus qui ont simplifié les intégrations de pipelines d'intelligence artificielle.[4]Hazelcast, "Announcing Hazelcast Platform 5.5 Release," hazelcast.com Dragonfly s'est positionné comme un remplacement direct de Redis avec une efficacité monocœur supérieure, défiant les acteurs établis dans la communauté des développeurs.
Les alliances stratégiques se sont accélérées. L'accord d'Oracle d'avril 2025 avec Google Cloud a permis aux entreprises de consolider les bases de données et les chaînes d'outils d'intelligence artificielle sans pénalités d'egress inter-cloud. AWS a formé un groupe d'intelligence artificielle agentique pour lier plus étroitement le développement de modèles aux services de données en mémoire. Les barrières à l'entrée sur le marché ont augmenté autour de la profondeur de l'écosystème et des fonctionnalités d'intelligence artificielle intégrées, consolidant la part parmi les fournisseurs capables de proposer à la fois l'excellence transactionnelle et la recherche vectorielle nativement.
Leaders du secteur des bases de données en mémoire
IBM Corporation
Microsoft Corporation
Oracle Corporation
SAP SE
TIBCO Software Inc.
- *Avis de non-responsabilité : les principaux acteurs sont triés sans ordre particulier

Opportunités de marché et perspectives d'avenir
Un espace blanc émerge à l'intersection des mises à niveau d'infrastructure optimisées pour l'IA et des architectures de bases de données qui maintiennent les données opérationnelles, les vecteurs et les fonctionnalités de streaming à proximité du calcul. Les récents mouvements d'infrastructure montrent comment les fournisseurs ciblent des empreintes mémoire plus larges et une contention réduite pour les charges de travail à forte intensité d'écriture : en mai 2026, HPE a annoncé le HPE Compute Scale-up Server 3250 pour des cas d'usage de bases de données en mémoire, prenant en charge jusqu'à 48 To de mémoire, et en juillet 2026, Oracle a introduit les fonctionnalités In-Memory Transaction Table et Commit Cache dans Oracle AI Database 26ai sur Exadata pour accélérer les recherches de transactions et le traitement des validations. Ces mises à jour de produits s'alignent sur les schémas d'entreprise où le service de modèles, la notation des fraudes et la personnalisation en temps réel s'exécutent plus près du système d'enregistrement transactionnel.
Les investissements en amont dans la mémoire avancée et l'emballage soutiennent également une mise à l'échelle plus rentable des piles centrées sur la mémoire, en particulier pour le HTAP et le service de modèles IA/ML. En juillet 2026, SK Hynix a divulgué un plan d'investissement de 100 000 milliards de KRW dans la région de Chungcheong incluant l'emballage avancé (P&T7) et une nouvelle installation NAND (M17), et Samsung Electronics et SK Hynix ont communiqué un plan plus large, soutenu par le gouvernement, autour d'un pôle de fabrication de puces à grande échelle en Corée du Sud. Pour les fournisseurs de bases de données en mémoire et les fournisseurs cloud, ces investissements renforcent l'argument en faveur du déploiement de types d'instances et d'appliances plus denses et riches en mémoire dans toutes les régions, tandis que les contraintes de souveraineté des données maintiennent une demande active pour les déploiements hybrides et les services gérés locaux en région en Europe et dans certaines parties de l'Asie-Pacifique.
Développements récents du secteur
- Juillet 2026 : Oracle a introduit les fonctionnalités In-Memory Transaction Table et Commit Cache au sein d'Oracle AI Database 26ai sur Exadata, visant des recherches de transactions et un traitement des validations plus rapides grâce à des interconnexions haute performance. Cette mise à jour renforce la poussée d'Oracle vers une infrastructure de base de données optimisée pour l'IA où les fonctionnalités d'accélération en mémoire sont conditionnées aux côtés d'Exadata pour servir des charges de travail OLTP et IA mixtes.
- Mai 2026 : HPE a annoncé le HPE Compute Scale-up Server 3250, positionné pour les déploiements de bases de données en mémoire et construit sur des processeurs Intel Xeon 6 avec prise en charge jusqu'à 48 To de mémoire. En élargissant le plafond adressable pour les configurations denses en mémoire, ce lancement soutient des clusters en mémoire plus grands et la consolidation des charges de travail d'entreprise sensibles à la latence.
- Mai 2025 : AWS a annoncé la disponibilité générale d'Amazon Aurora DSQL pour fournir une évolutivité SQL distribuée avec des caractéristiques de performance de type en mémoire. Cette sortie élargit les options de service géré pour les équipes qui souhaitent une sémantique à faible latence sans exécuter et régler de vastes empreintes mémoire sur site.


Cadre de la méthodologie de recherche et portée du rapport
Définition et périmètre du marché
Le marché des bases de données en mémoire couvre les logiciels et services associés où le jeu de données de travail principal est conservé en RAM pour offrir une latence très faible pour les transactions, l'analytique, la mise en cache et les charges de travail mixtes dans les environnements d'entreprise et cloud.
Exclusions du périmètre : nous excluons le matériel de stockage à usage général et les outils de bases de données non liés qui ne dépendent pas de manière significative du traitement en mémoire comme principal facteur de valeur.
Aperçu de la segmentation
- Par type de traitement
- OLTP
- OLAP
- Traitement transactionnel/analytique hybride (HTAP)
- Par mode de déploiement
- Sur site
- Cloud
- Périphérie/Embarqué
- Par modèle de données
- Relationnel (SQL)
- NoSQL (clé-valeur, document, graphe)
- Multi-modèle
- Par taille d'organisation
- Petites et moyennes entreprises (PME)
- Grandes entreprises
- Par application
- Traitement des transactions en temps réel
- Analytique opérationnelle et tableaux de bord d'informatique décisionnelle
- Service de modèles d'intelligence artificielle et d'apprentissage automatique
- Mise en cache et magasins de sessions
- Par secteur d'activité des utilisateurs finaux
- BFSI
- Télécommunications et informatique
- Commerce de détail et commerce électronique
- Santé et sciences de la vie
- Fabrication et Internet des objets industriel
- Médias et divertissement
- Gouvernement et défense
- Autres (énergie, éducation, etc.)
- Par géographie
- Amérique du Nord
- États-Unis
- Canada
- Mexique
- Europe
- Allemagne
- France
- Royaume-Uni
- Pays nordiques
- Reste de l'Europe
- Asie-Pacifique
- Chine
- Taïwan
- Corée du Sud
- Japon
- Inde
- Reste de l'Asie-Pacifique
- Amérique du Sud
- Brésil
- Mexique
- Argentine
- Reste de l'Amérique du Sud
- Moyen-Orient et Afrique
- Moyen-Orient
- Arabie saoudite
- Émirats arabes unis
- Turquie
- Reste du Moyen-Orient
- Afrique
- Afrique du Sud
- Reste de l'Afrique
- Moyen-Orient
- Amérique du Nord
Sources de données, dimensionnement du marché et validation
Recherche documentaire
Le travail documentaire commence par la constitution de la base factuelle autour de l'adoption des bases de données et des schémas de dépenses informatiques, puis se resserre sur les solutions où le traitement en mémoire est une caractéristique déterminante. Nous avons référencé des sources publiques telles que les dépôts SEC des États-Unis, les rapports annuels et les présentations aux investisseurs, ainsi que la documentation des fournisseurs cloud et les pages de tarification qui aident à valider les schémas de déploiement et les combinaisons de charges de travail courantes.
Pour ancrer les données, nous avons également utilisé des indicateurs non payants du US Bureau of Economic Analysis pour le contexte de l'investissement numérique, des séries macroéconomiques de la Banque mondiale et de l'OCDE pour la normalisation entre pays, et des statistiques de connectivité de l'UIT pour l'état de préparation des infrastructures. Nous avons utilisé des revues systémiques et des revues de bases de données à comité de lecture pour vérifier la cohérence des affirmations d'adoption technique. Des bases de données de brevets et un abonnement d'actualités et financier ont été utilisés de manière sélective pour suivre les sorties de produits, les fusions-acquisitions et les évolutions de fonctionnalités qui affectent ce qui est comptabilisé comme base de données en mémoire par rapport aux couches de mise en cache ou d'analytique adjacentes. Ces sources ne sont pas exhaustives, et nous avons utilisé de nombreuses autres références publiques pour la collecte de données, la validation et la clarification au fur et à mesure de la construction du modèle.
Entretiens et enquêtes primaires
Le travail primaire s'est concentré sur la vérification de ce que les acheteurs déploient réellement pour les charges de travail sensibles à la latence, et sur la manière dont les licences, abonnements et tarifications de services gérés sont conditionnés dans les transactions réelles. Nous avons échangé avec un mélange de fournisseurs de logiciels, de partenaires cloud et de distribution, et d'utilisateurs d'entreprise dans les principales régions afin de combler les lacunes des données documentaires, puis de trianguler les hypothèses sur l'adoption, la tarification et les cycles de mise à niveau.
Répartition des répondants du travail de terrain de la recherche primaire
| Type d'entreprise | Poste du répondant | Région |
|---|---|---|
| Niveau supérieur : 29 % | Dirigeants (CXO) : 19 % | APAC : 45 % |
| Niveau intermédiaire : 51 % | Responsables fonctionnels/d'unité : 25 % | EMEA : 29 % |
| Petits acteurs : 20 % | Managers : 56 % | Amériques : 26 % |
Dimensionnement du marché et prévisions
Le dimensionnement est construit selon une logique descendante et ascendante, où la vue descendante reconstruit les dépenses adressables en cartographiant les budgets de bases de données et de plateformes de données d'entreprise dans des cas d'usage en mémoire, puis en appliquant des signaux d'adoption au niveau régional et vertical. Une fois le bassin de demande formé, il est corrigé à l'aide d'approximations ascendantes issues de vérifications de tarification et de volume échantillonnées, de retours de partenaires sur le nombre de déploiements et de répartitions sélectives des revenus des fournisseurs pour garder les totaux réalistes.
Les principales entrées du modèle incluent le mix de déploiement cloud versus sur site, les valeurs contractuelles moyennes par taille d'organisation, la part des charges de travail transactionnelles versus analytiques (y compris HTAP), le calendrier de renouvellement et de mise à niveau, et le taux d'adoption des architectures riches en RAM pour les cas d'usage en temps réel. Lorsque des indicateurs de volume directs manquent, les lacunes sont comblées par des variables de substitution défendables lors des appels, telles que la pénétration des applications dans le BFSI et les télécoms, et le passage vers des services de bases de données gérés.
Les prévisions sont produites à l'aide d'une analyse de scénarios soutenue par un lissage des tendances sur les trajectoires d'adoption et de tarification, puis examinées par rapport aux attentes des personnes interrogées concernant le rythme de la migration cloud, la croissance des charges de travail IA et streaming, et la sensibilité aux coûts. La série finale reste reproductible en liant chaque étape à un petit ensemble d'entrées mesurables et d'hypothèses clairement énoncées.
Validation des données et cycle de mise à jour
La validation se fait en plusieurs passes, en commençant par des vérifications unitaires sur la tarification, l'adoption et les répartitions régionales, suivies de vérifications de variance par rapport à des signaux indépendants tels que la direction de la consommation cloud, les tendances des dépenses logicielles d'entreprise et les cycles de mise à niveau motivés par la performance rapportés. Si une entrée crée un saut inhabituel dans une région ou un secteur, elle est signalée, examinée par un autre analyste, puis revérifiée avec une nouvelle source secondaire ou en recontactant un répondant pertinent.
Le modèle et le récit sont examinés avant validation finale afin que les chiffres définitifs correspondent au périmètre et aux définitions énoncés. Les rapports sont actualisés annuellement, et des mises à jour intermédiaires sont effectuées lorsque des événements significatifs surviennent, tels que des changements majeurs de produits ou des évolutions des modèles de déploiement. Avant la livraison, nous effectuons une dernière passe afin que les chiffres du marché reflètent les informations les plus récentes disponibles.
Comparaison du dimensionnement du marché des bases de données en mémoire de Mordor Intelligence avec d'autres estimations publiées
Les valeurs de marché publiées pour les bases de données en mémoire peuvent différer car chaque éditeur fait ses propres choix sur ce qu'il faut comptabiliser, l'année considérée comme base, et la manière dont les revenus des bases de données gérées par le cloud sont traités. Des différences apparaissent également lorsqu'un modèle s'appuie davantage sur les déclarations de revenus des fournisseurs, tandis qu'un autre s'appuie sur les signaux d'adoption des acheteurs.
L'écart principal provient du fait que des couches adjacentes comme les grilles de données en mémoire, les services de mise en cache et les piles de calcul en mémoire plus larges soient ou non intégrées au total, où Mordor Intelligence ne comptabilise que les revenus des bases de données en mémoire liés aux déploiements de bases de données et aux services associés dans le périmètre défini, puis prévoit à partir d'une année de référence 2026 en utilisant des vérifications d'adoption et de tarification par région.
Comparaison de référence
| Source | Taille du marché | Lacunes de la méthodologie de recherche |
|---|---|---|
| Mordor Intelligence | 8,05 milliards USD (2026) | |
| Cabinet de conseil mondial A | 6,66 milliards USD (2025) | Utilise une année de référence différente et un périmètre plus large de services associés dans la définition de la catégorie, ce qui peut modifier ce qui est comptabilisé comme revenu de base de données par rapport aux compléments de plateforme, et change ensuite le point de départ de la trajectoire de prévision. |
| Éditeur sectoriel B | 3,90 milliards USD (2024) | Part d'une année antérieure avec un bassin d'adoption plus restreint et applique souvent des hypothèses de croissance plus lentes pour les déploiements gérés par le cloud, ce qui peut sous-estimer la part des dépenses évoluant vers une tarification par abonnement et à la consommation. |
Pris ensemble, l'écart s'explique principalement par les choix de périmètre et la sélection de l'année, suivis de la manière dont les revenus cloud sont traduits en valeur de marché. En gardant les inclusions explicites et en liant la prévision à l'adoption, au mix de déploiement et à l'évolution des prix, le chiffre final reste traçable à des étapes claires qui peuvent être répétées et examinées.


Questions clés auxquelles le rapport répond
Quelle est la valeur actuelle du marché des bases de données en mémoire ?
Le marché des bases de données en mémoire était évalué à 8,05 milliards USD en 2026 et devrait atteindre 15,31 milliards USD d'ici 2031.
Quelle région mène la croissance du marché des bases de données en mémoire ?
L'Asie-Pacifique a dominé avec 31,95 % des revenus en 2025 et devrait afficher un CAGR de 16,65 % jusqu'en 2031.
Pourquoi les architectures HTAP sont-elles importantes pour les charges de travail d'intelligence artificielle ?
Le HTAP unifie le traitement transactionnel et analytique, permettant une inférence en temps réel sans délais d'extraction, transformation et chargement, comme le montre Oracle HeatWave GenAI.
Comment la baisse des prix de la DRAM affecte-t-elle l'adoption ?
La baisse du prix USD/Go et les nouvelles options de mémoire persistante réduisent le coût total de possession, rendant les déploiements en mémoire économiquement viables.
Quels défis limitent les très grands clusters en mémoire ?
L'architecture de haute disponibilité devient complexe au-delà de 40 To, les protocoles de clustering entraînant une surcharge de performance.
Dernière mise à jour de la page le:




