Taille et part du marché de la classification des données
VUE D’ENSEMBLE DU MARCHÉ
| Période d'étude | 2020 - 2031 |
|---|---|
| Taille du Marché (2026) | 2.28 Milliards de dollars |
| Taille du Marché (2031) | 5.98 Milliards de dollars |
| Taux de croissance (2026 - 2031) | 21.28% CAGR |
| Marché à la Croissance la Plus Rapide | Asie-Pacifique |
| Plus Grand Marché | Amérique du Nord |
| Concentration du Marché | Moyen |
Acteurs majeurs *Avis de non-responsabilité : les principaux acteurs sont triés sans ordre particulier Image © Mordor Intelligence. La réutilisation nécessite une attribution sous CC BY 4.0. | |
Analyse du marché de la classification des données par Mordor Intelligence
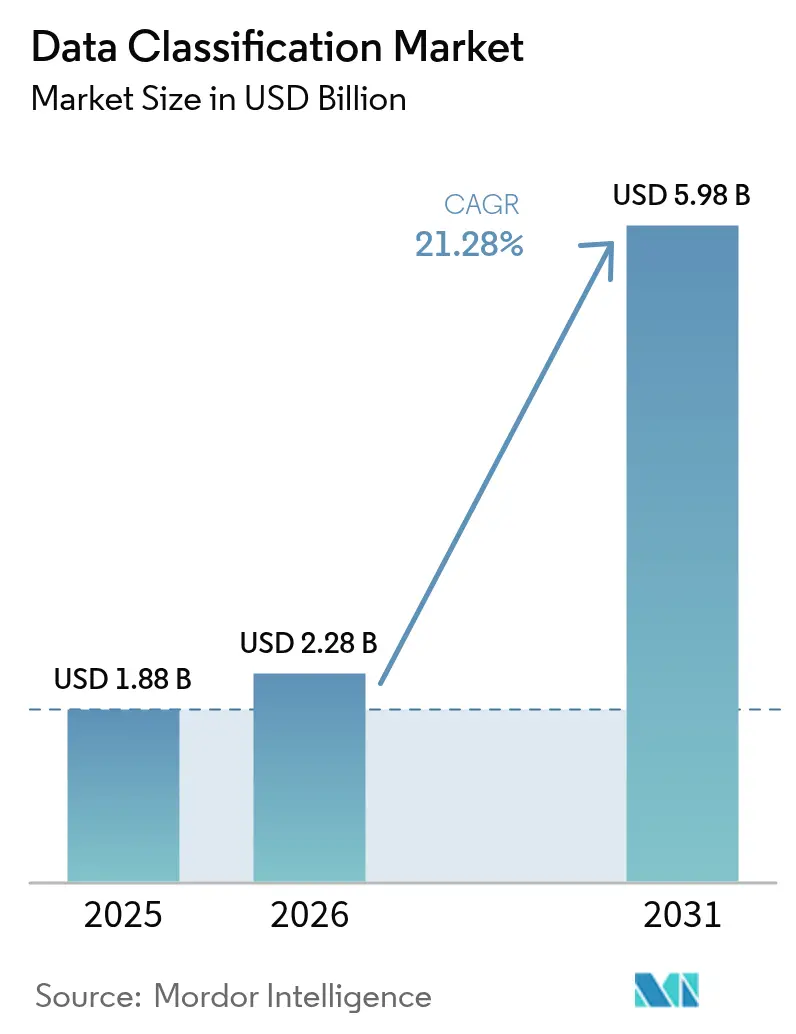
La taille du marché de la classification des données en 2026 est estimée à 2,28 milliards USD, en hausse par rapport à la valeur de 2025 de 1,88 milliard USD, avec des projections pour 2031 indiquant 5,98 milliards USD, croissant à un TCAC de 21,28 % sur la période 2026-2031. La croissance rapide des données, estimée à 328,77 millions de To créés chaque jour, et des mandats mondiaux de confidentialité plus stricts poussent les entreprises à adopter l'étiquetage des données en temps réel, alimenté par l'IA, qui s'adapte aux environnements cloud hybrides. Les moteurs de classification alimentés par l'IA intégrés dans des architectures cloud natives détectent désormais les informations sensibles dans les référentiels non structurés, tandis que les initiatives de cloud souverain en Asie-Pacifique stimulent la demande régionale. Le paysage des menaces croissant, où le coût moyen d'une violation dans le secteur de l'énergie a atteint 4,78 millions USD en 2024, souligne davantage l'urgence d'une gouvernance automatisée. Les investissements des hyperscalers tels qu'AWS et Microsoft dans des centres de données régionaux ajoutent de l'élan en réduisant la latence et en respectant les règles de résidence des données.
Points clés du rapport
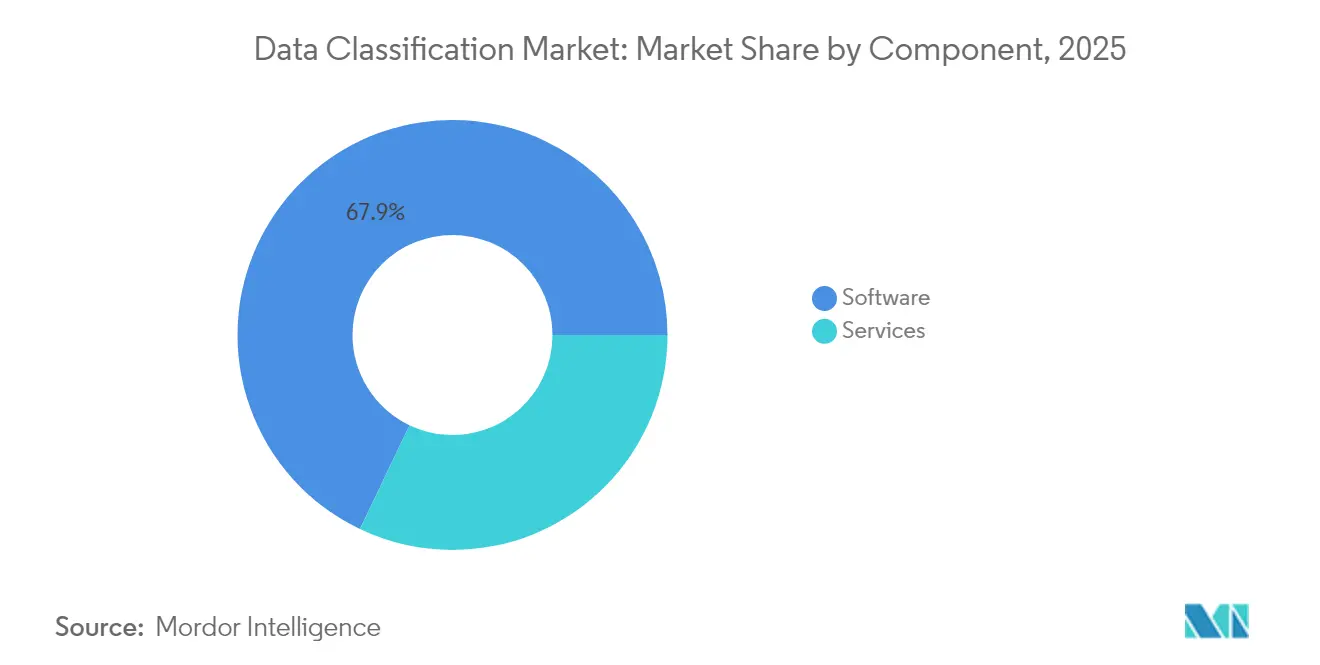
- Par composant, les logiciels ont dominé avec une part de revenus de 67,92 % en 2025, tandis que les services devraient croître à un TCAC de 23,62 % jusqu'en 2031.
- Par méthode de classification, les modèles basés sur le contenu ont capturé une part de 42,76 % en 2025 ; les approches pilotées par l'apprentissage automatique devraient se développer à un TCAC de 22,44 % jusqu'en 2031.
- Par taille d'organisation, les grandes entreprises détenaient 70,55 % de la part du marché de la classification des données en 2025, tandis que le segment des PME devrait croître à un TCAC de 23,29 %.
- Par application, le contrôle d'accès et l'IAM représentaient 56,12 % de la taille du marché de la classification des données en 2025 ; la gouvernance et la conformité progressent à un TCAC de 22,91 %.
- Par secteur vertical, le BFSI a contribué à hauteur de 35,12 % des revenus en 2025 ; le gouvernement et la défense sont positionnés pour une croissance de 21,78 % de TCAC.
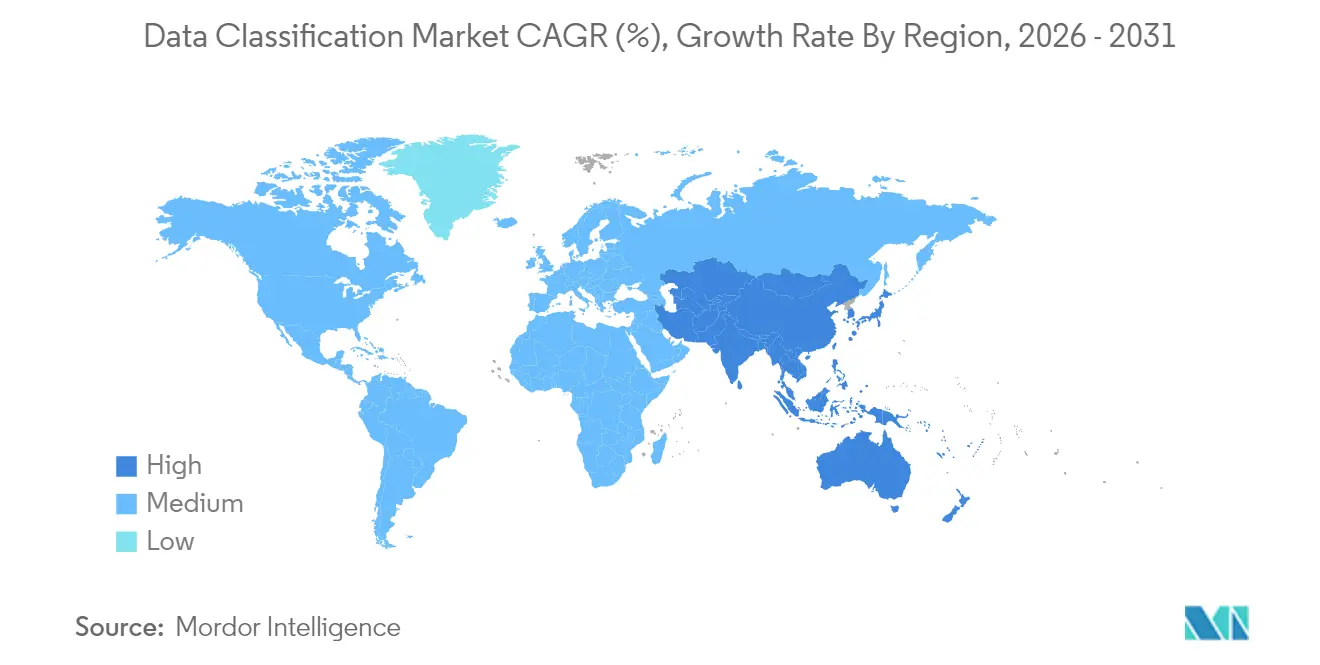
- Par géographie, l'Amérique du Nord commandait 40,62 % de part en 2025, mais l'Asie-Pacifique devrait enregistrer un TCAC de 22,07 % jusqu'en 2031.
Remarque : Les chiffres de la taille du marché et des prévisions de ce rapport sont générés à l’aide du cadre d’estimation propriétaire de Mordor Intelligence, mis à jour avec les données et analyses les plus récentes disponibles en 2026.
Tendances et perspectives du marché mondial de la classification des données
Analyse de l'impact des moteurs*
| Moteur | (~) % d'impact sur les prévisions de TCAC | Pertinence géographique | Horizon temporel d'impact |
|---|---|---|---|
| Expansion des mandats mondiaux de confidentialité | +4.2% | Mondial, avec un impact concentré dans l'UE, l'Amérique du Nord et l'APAC | Moyen terme (2-4 ans) |
| Croissance explosive des données non structurées et risque de violation | +3.8% | Mondial, particulièrement aigu en Amérique du Nord et en Europe | Court terme (≤ 2 ans) |
| Demande de classification des données cloud native | +3.5% | Cœur APAC, débordement vers le Moyen-Orient et l'Afrique et l'Amérique latine | Moyen terme (2-4 ans) |
| Classification automatique alimentée par l'IA/apprentissage automatique atteignant la production à grande échelle | +3.1% | Amérique du Nord et UE en tête, adoption rapide en APAC | Court terme (≤ 2 ans) |
| Jeux de puces d'informatique confidentielle permettant l'étiquetage en ligne | +2.4% | Amérique du Nord et certains marchés de l'UE | Long terme (≥ 4 ans) |
| Sécurité de l'IA générative nécessitant un étiquetage des données à granularité fine | +2.7% | Mondial, avec une adoption précoce dans les secteurs réglementés | Moyen terme (2-4 ans) |
| Source: Mordor Intelligence | |||
Expansion des mandats mondiaux de confidentialité
Les règles européennes DORA et les normes HIPAA mises à jour font passer la conformité des audits planifiés à la vérification continue, obligeant les entreprises à intégrer la logique de classification directement dans les flux de traitement des données[1]Registre fédéral américain, "Contrôles de sécurité et de confidentialité pour les systèmes d'information fédéraux," federalregister.gov. Les entreprises multinationales opérant dans plusieurs juridictions appliquent souvent l'exigence mondiale la plus stricte comme référence, ce qui accélère le déploiement d'architectures de classification unifiées. Les institutions financières doivent satisfaire aux obligations de déclaration anti-blanchiment d'argent en quelques minutes, ce qui accroît la demande de découverte pilotée par des politiques. Une pression similaire provient des lois latino-américaines sur la souveraineté des données qui s'alignent sur le RGPD. Ensemble, ces mandats raccourcissent les cycles d'approvisionnement, incitant même les entreprises de taille moyenne à adopter des outils SaaS qui mettent à jour les politiques automatiquement.
Croissance explosive des données non structurées et risque de violation
Les référentiels non structurés croissent de 62 % chaque année, laissant les équipes de sécurité aveugles quant aux détenteurs d'enregistrements sensibles. Les entreprises signalent des autorisations excessives sur 82 % des partages de fichiers, ce qui expose des conceptions précieuses et des données clients. Les services publics d'énergie subissent désormais 1 100 cyberattaques hebdomadaires, et les enquêtes sur les violations révèlent que des documents mal classifiés en sont une cause profonde. Les cabinets juridiques souffrent d'une exposition similaire car les fichiers clients se trouvent dans des lecteurs partagés sans étiquettes. La reconnaissance de modèles pilotée par l'IA est de plus en plus choisie car les ensembles de règles statiques ne peuvent pas suivre le rythme des plateformes de collaboration dynamiques.
Demande de classification des données cloud native
Soixante-quatre pour cent des organisations australiennes testent des stratégies de souveraineté, et près de la moitié des agences du secteur public de l'APAC prévoient d'adopter de tels contrôles dans l'année. Les moteurs de classification doivent fonctionner sur des empreintes multi-cloud tout en respectant les contraintes de résidence locales. Le partenariat de Microsoft d'une valeur de 1,5 milliard USD avec G42, basé aux Émirats arabes unis, met en évidence l'expansion régionale du calcul qui dépend de l'étiquetage intégré pour séparer les charges de travail réglementées. L'adoption du cloud souverain oblige les entreprises à maintenir des couches de politique doubles : des normes mondiales et des étiquettes spécifiques à la juridiction. Les fournisseurs qui automatisent ce mappage obtiennent une différenciation claire.
Classification automatique alimentée par l'IA/apprentissage automatique atteignant la production à grande échelle
Les entreprises signalent désormais des améliorations de 96 % de la qualité des données après avoir superposé l'apprentissage automatique aux pipelines de découverte existants. Forcepoint a intégré le modèle auto-apprenant de Getvisibility pour éliminer la création de règles longues, permettant à la précision de s'améliorer grâce aux retours en temps réel. Microsoft Purview fournit plus de 200 types d'informations intégrés qui étiquettent automatiquement le contenu dans Exchange, SharePoint et les ressources SQL. L'amélioration de la précision des modèles réduit les faux positifs, ce qui à son tour réduit la charge du service d'assistance et accélère l'adoption par les utilisateurs. Les PME en bénéficient le plus car elles manquaient auparavant de ressources pour le réglage manuel.
Analyse de l'impact des contraintes*
| Contrainte | (~) % d'impact sur les prévisions de TCAC | Pertinence géographique | Horizon temporel d'impact |
|---|---|---|---|
| Absence de normes de taxonomie intersectorielles | -2.1% | Mondial, avec des défis particuliers dans les marchés émergents | Long terme (≥ 4 ans) |
| Coût d'intégration élevé dans les environnements existants | -1.8% | Amérique du Nord et Europe avec une infrastructure informatique établie | Moyen terme (2-4 ans) |
| « Dette de classification » due à la prolifération des données synthétiques | -1.5% | Mondial, concentré dans les secteurs et régions à forte intensité d'IA | Moyen terme (2-4 ans) |
| Chiffrement homomorphe retardant l'inspection en texte clair | -1.2% | Amérique du Nord et UE en tête de l'adoption, déploiement sélectif en entreprise | Long terme (≥ 4 ans) |
| Source: Mordor Intelligence | |||
Absence de normes de taxonomie intersectorielles
Les régulateurs financiers classifient les données de risque différemment des autorités médicales, obligeant les fournisseurs à maintenir des bibliothèques de règles spécifiques au secteur. Les multinationales doivent concilier la terminologie du RGPD avec la définition chinoise des « données importantes » lors du transfert de fichiers. Cette fragmentation entraîne des efforts de codage personnalisé, accroît les craintes de dépendance vis-à-vis des fournisseurs et ralentit les décisions d'achat. Les alliances industrielles élaborent des propositions de schémas ouverts, mais l'adoption reste inégale. En conséquence, les intégrateurs tirent des revenus considérables des ateliers de mappage plutôt que des licences logicielles pures.
Coût d'intégration élevé dans les environnements existants
Les fournisseurs d'infrastructures critiques exploitent encore des systèmes mis en service il y a plus de 20 ans, dont beaucoup manquent d'API modernes[2]Thales Group, "Rapport sur la cybersécurité des infrastructures critiques," thalesgroup.com. La mise à niveau de la classification dans de tels environnements dépasse souvent 18 mois, pendant lesquels les risques de conformité restent non résolus. Les PME connaissent des frictions similaires car le personnel de sécurité rare doit équilibrer les opérations quotidiennes avec les projets de transformation. Les responsables budgétaires reportent parfois les déploiements de classification jusqu'à ce que des mises à niveau ERP plus larges soient planifiées. Les fournisseurs promeuvent désormais des connecteurs sans agent et des pipelines préconstruits pour réduire ces coûts, mais la complexité reste un inhibiteur clé.
*Nos prévisions considèrent les impacts des moteurs et des contraintes comme directionnels et non additifs. Les prévisions d'impact reflètent la croissance de référence, les effets de composition et les interactions entre variables.
Analyse des segments
Par composant : les services propulsent la croissance au-delà des licences logicielles
Les logiciels ont continué à générer les revenus les plus élevés, représentant 67,92 % du marché de la classification des données en 2025. Les ventes de licences se sont concentrées sur les moteurs de politique, les robots d'exploration de découverte et les tableaux de bord SaaS. Néanmoins, les services professionnels et gérés se développent à un TCAC de 23,62 % car les entreprises ont besoin de conseils pour résorber la dette de classification accumulée. Les engagements commencent souvent par des analyses de plusieurs pétaoctets qui alimentent les arriérés de remédiation et sollicitent les ressources internes. Les fournisseurs de services gérés comblent les lacunes en compétences en gérant le réentraînement des modèles, les mises à jour réglementaires et le tri des tickets sur une base d'abonnement. Ces contrats peuvent s'étendre sur plusieurs années, ce qui fait passer les dépenses d'une dépense en capital unique à des dépenses d'exploitation récurrentes. Cette approche est bien accueillie par les conseils d'administration qui recherchent des budgets prévisibles et des preuves prêtes pour l'audit. En termes monétaires, les services pourraient représenter 2,16 milliards USD de la taille du marché de la classification des données d'ici 2031, reflétant leur importance stratégique. Les éditeurs de logiciels regroupent donc des capacités de conseil dans des niveaux premium pour protéger leurs marges.
Les implémentations de deuxième génération reposent sur un réglage continu plutôt que sur des bilans de santé annuels. Les partenaires de service construisent des pipelines DevSecOps qui déclenchent la classification chaque fois que de nouvelles données arrivent dans le stockage d'objets. Ils codifient également des taxonomies partagées entre les unités commerciales, ce qui comprime les délais d'intégration pour les acquisitions. La tendance élargit le marché de la classification des données car les entreprises de taille intermédiaire peuvent louer une expertise plutôt que d'embaucher des spécialistes rares. Les places de marché des fournisseurs répertorient désormais des offres de services organisées alignées sur les modèles ISO 27001, HIPAA ou PCI, démocratisant davantage l'adoption. À mesure que les revenus des services s'accélèrent, les intégrateurs de systèmes acquièrent des cabinets de conseil spécialisés pour renforcer les connaissances du domaine et sécuriser leur part de portefeuille.



Par méthode de classification : l'apprentissage automatique redéfinit les références de précision
L'inspection basée sur le contenu détenait 42,76 % des dépenses en 2025 en exploitant les expressions régulières et les empreintes digitales pour signaler la propriété intellectuelle. Pourtant, les modèles pilotés par l'apprentissage automatique et sémantiques se développent à un TCAC de 22,44 % en apprenant le contexte à partir de millions de documents étiquetés. Les capacités aveugles aux modèles, telles que les réseaux de transformateurs qui analysent la structure des phrases, améliorent les taux de rappel et réduisent les fausses alertes. Microsoft Purview s'entraîne sur la télémétrie mondiale, ce qui alimente des actualisations régulières des modèles sans action du client. Digital Guardian superpose des signaux contextuels tels que la localisation et la posture de l'appareil sur les indices de contenu, permettant un étiquetage pondéré par le risque. Les approches combinées sont désormais livrées sous forme de packs préconfigurés afin que les administrateurs puissent intégrer progressivement de nouveaux moteurs sans perturber les activités.
Les premiers adoptants rapportent que l'apprentissage automatique améliore la productivité des examinateurs de 35 %, car moins d'éléments nécessitent une adjudication humaine. Les organisations disposant d'archives multilingues bénéficient d'avantages mesurables car les modèles sémantiques gèrent mieux la variance linguistique que les listes de mots-clés manuelles. Les fournisseurs ouvrent des API pour intégrer des ontologies spécifiques aux clients, apportant une précision sur mesure sans développement de zéro. Ce changement stimule le marché de la classification des données car il transforme ce qui était autrefois une capacité d'élite en une case à cocher SaaS. Les données d'entraînement restent néanmoins un goulot d'étranglement pour les domaines de niche, ce qui incite certaines entreprises à partager des corpus anonymisés dans le cadre d'accords de bénéfice mutuel. Sur l'horizon de prévision, l'adoption de l'apprentissage automatique devrait réduire le délai de rentabilisation de plusieurs trimestres à quelques semaines, cimentant son rôle de méthodologie par défaut.
Par taille d'organisation : les plateformes cloud natives démocratisent l'étiquetage de niveau entreprise
Les grandes entreprises ont contribué à hauteur de 70,55 % des revenus de 2025 en raison de leur exposition réglementaire et de leur capacité budgétaire. Elles ont été les premières à adopter des suites de gouvernance intégrées couvrant les serveurs de fichiers sur site et les environnements multi-cloud. Néanmoins, les PME représentent désormais la cohorte à la croissance la plus rapide avec un TCAC de 23,29 %, bénéficiant des offres SaaS sans infrastructure. La plupart des plateformes se provisionnent en quelques heures et ne nécessitent que des connecteurs légers pour la messagerie, la collaboration et le stockage d'objets. Les niveaux d'abonnement alignent le coût sur l'utilisation, rendant les points d'entrée viables pour les entreprises de moins de 500 employés. Les modèles adaptés au contenu de santé, financier et juridique accélèrent le déploiement car les PME manquent de responsables de la conformité à temps plein.
Les ressources éducatives, telles que les ateliers communautaires de Microsoft, abaissent davantage les barrières en formant les généralistes informatiques à gérer les politiques de classification. Le cadre PUZZLE fournit des listes de contrôle pratiques qui permettent aux PME d'intégrer une sécurité minimale viable dans les charges de travail cloud. Les associations industrielles diffusent également des packs de règles open source afin que les membres puissent démarrer sans partir de pages blanches. À mesure que l'adoption s'élargit, les éditeurs de plateformes collectent des données de télémétrie qui améliorent la précision de l'apprentissage automatique pour tous les locataires, créant un effet d'entraînement qui bénéficie de manière disproportionnée aux petites entreprises. Ce modèle incite les places de marché à répertorier des connecteurs de niche pour les systèmes de comptabilité, de ressources humaines et de gestion de la relation client populaires dans le marché intermédiaire, élargissant la couverture sans scripts sur mesure.
Par application : la gouvernance et la conformité passent au premier plan
Le contrôle d'accès et l'IAM ont absorbé 56,12 % des dépenses en 2025 car les autorisations pilotées par étiquettes constituent l'épine dorsale des politiques de confiance zéro. La protection des e-mails et des appareils mobiles a suivi, car les effectifs distribués partagent des documents sensibles via des canaux de messagerie instantanée et des appareils personnels. La croissance la plus rapide, à un TCAC de 22,91 %, se situe dans les tableaux de bord de gouvernance et de conformité qui présentent des métriques aux régulateurs et aux conseils d'administration. Ces outils s'appuient sur la télémétrie de classification pour visualiser la résidence, la rétention et la lignée des données. Ils exportent des rapports lisibles par machine pour les portails d'assurance automatisés, réduisant la préparation des audits de plusieurs semaines à quelques heures. La capacité devient critique dans le cadre de mandats de divulgation quasi en temps réel tels que la règle de cybersécurité de la SEC.
Les intégrations avec les moteurs de notation des risques permettent aux équipes de conformité de prioriser la remédiation en fonction de la criticité des données plutôt que du nombre de fichiers. Les tableaux de bord avancés intègrent des analyses prédictives qui estiment les amendes potentielles si des enregistrements mal étiquetés quittent une région. Par conséquent, les schémas de dépenses passent des plugins DLP ponctuels aux plateformes unifiées avec des analyses intégrées. Les fournisseurs positionnent les modules de conformité comme des leviers de croissance pilotés par les produits, offrant des niveaux de licence freemium qui révèlent les résultats de risque et orientent les ventes incitatives vers des suites complètes. La transparence qui en résulte favorise le parrainage des dirigeants, élargissant le marché de la classification des données au-delà du département de sécurité.

Par secteur vertical : le gouvernement et la défense accélèrent leur trajectoire de dépenses
Le BFSI a généré 35,12 % des revenus de 2025, alimenté par les règles de capital de Bâle III et les obligations de détection du blanchiment d'argent. Le secteur de la santé a suivi, porté par la modernisation de HIPAA et la poussée vers les dossiers de santé électroniques. L'expansion la plus rapide, à un TCAC de 21,78 %, concerne le gouvernement et la défense, où les exigences de confiance zéro et les flux de travail d'informations classifiées exigent un étiquetage précis. Le programme de sécurité de l'information du DoD mis à jour oblige les contractants à appliquer des règles de marquage uniformes dans les e-mails, les plateformes de collaboration et le stockage cloud. Les fenêtres de validation pour les restrictions de données techniques s'étendent désormais à 6 ans, garantissant des revenus de services soutenus. Les agences de défense investissent également dans l'étiquetage en ligne aux passerelles réseau pour prendre en charge des solutions sécurisées inter-domaines.
Les opérateurs d'infrastructures critiques, tels que les services publics expérimentant l'analyse de réseau intelligent, reproduisent de plus en plus les pratiques de niveau défense pour bloquer les menaces étatiques. Les stratégies nationales de données appellent à des installations cloud souveraines, qui à leur tour nécessitent une segmentation multi-locataires appliquée par des étiquettes de classification. Les grands intégrateurs de systèmes forment des coentreprises avec des entités du secteur public pour aligner les feuilles de route des produits sur les besoins opérationnels. Comme ces contrats spécifient souvent un hébergement domestique, la localisation renforce les empreintes SaaS régionales. La spécialisation verticale devient donc un différenciateur concurrentiel et assure des flux réguliers vers le marché de la classification des données.
Analyse géographique
L'Amérique du Nord a conservé son leadership avec 40,62 % des revenus de 2025 car des réglementations strictes et une adoption précoce de l'IA ont poussé les entreprises à moderniser leurs programmes de découverte. Le tour de financement de 60 millions USD de BigID en 2025 illustre l'appétit du capital-risque pour les solutions qui automatisent l'hygiène des données avant les nouvelles règles de divulgation de la SEC. Les institutions financières déploient l'étiquetage pour satisfaire aux obligations de reporting intrajournalier, tandis que les prestataires de soins de santé intègrent des étiquettes dans les dossiers médicaux électroniques pour se conformer aux évolutions des extensions HIPAA. Les lois provinciales canadiennes sur la confidentialité reflètent les exigences fédérales, renforçant une demande constante. Les clusters technologiques mexicains adoptent des plateformes hébergées dans le cloud pour satisfaire aux clauses de transfert de données de l'ACEUM, bien que l'adoption se concentre dans les filiales multinationales.
L'Asie-Pacifique est la région à la croissance la plus rapide avec un TCAC de 22,07 %, reflétant les mandats de cloud souverain et les lourds investissements en infrastructure des hyperscalers. AWS a promis 6 milliards USD à la Malaisie et NTT s'est engagé à hauteur de 90 millions USD pour des centres de données à Bangkok, créant un calcul local qui réduit la latence pour les moteurs de politique. La Chine propose d'assouplir l'approbation des données sortantes mais étiquette toujours de nombreux ensembles de données comme « importants », imposant des contrôles doubles. Le Japon et la Corée du Sud déploient la classification dans la fabrication 5G pour protéger les secrets commerciaux. Les exportateurs de services informatiques indiens exigent un étiquetage multi-locataires pour séparer les données des clients, élargissant le pool adressable d'abonnés cloud.
L'Europe se classe solidement en deuxième position par valeur, portée par la loi sur la résilience opérationnelle numérique qui exige des tests de contrôle continus d'ici 2025. Les usines Industrie 4.0 allemandes étiquettent les données opérationnelles pour protéger la propriété intellectuelle et se conformer aux audits de sécurité de la chaîne d'approvisionnement. Le Royaume-Uni équilibre l'adéquation post-Brexit avec les règles d'innovation nationales, de sorte que les entreprises surveillent les flux transfrontaliers sous des politiques doubles. La France promeut des zones cloud souveraines pour héberger les charges de travail du secteur public, tandis que l'Italie renforce les protections des infrastructures critiques. Les pays nordiques, premiers adoptants du RGPD, pilotent désormais des puces d'informatique confidentielle qui permettent l'étiquetage en ligne sans exposer le texte en clair, positionnant la région pour l'innovation de prochaine génération.

Paysage concurrentiel
Le marché de la classification des données présente une fragmentation modérée car les fournisseurs cloud hyperscale et les entreprises de sécurité spécialisées se disputent la part de plateforme. Microsoft Purview intègre l'étiquetage dans Azure, Microsoft 365 et les services SQL, offrant une gouvernance en guichet unique qui attire les grandes entreprises. AWS, Google Cloud et IBM intègrent des contrôles similaires dans les API de stockage, réduisant les frictions d'adoption pour les développeurs. Des fournisseurs spécialisés tels que Varonis et BigID se différencient par des analyses de contenu approfondies et des tableaux de bord de confidentialité qui visualisent la lignée des données. Des acteurs émergents comme Cyera se concentrent sur la gestion de la posture de sécurité des données cloud native, attirant des financements rapides et accélérant l'innovation.
L'activité d'acquisition remodèle la dynamique concurrentielle. Forcepoint a acquis Getvisibility pour associer des modèles auto-apprenants à son moteur DLP, améliorant la précision dans les clouds hybrides. Capgemini a racheté Syniti pour fusionner les services de qualité des données avec le conseil en gouvernance, élargissant les offres à valeur ajoutée. L'acquisition de Reka AI par Snowflake et l'achat de MosaicML par Databricks illustrent la convergence des capacités d'analyse, d'IA et d'étiquetage. Ces mouvements répondent à la préférence des acheteurs pour des plateformes consolidées qui réduisent la complexité des licences et intègrent les preuves de conformité.
Les modèles de tarification évoluent vers des niveaux basés sur la consommation liés aux téraoctets analysés et aux utilisateurs protégés. Les fournisseurs regroupent des kits de démarrage avec des taxonomies préconstruites pour accélérer le délai de rentabilisation. Les partenaires de distribution construisent des accélérateurs verticaux qui codifient les réglementations sectorielles, créant des écosystèmes fidélisants. L'avantage concurrentiel se concentre de plus en plus sur le retour sur investissement démontrable, les fournisseurs mettant en avant l'évitement des coûts de violation et les économies de ressources d'audit. Les nouveaux entrants proposant des solutions ponctuelles étroites subissent des pressions à mesure que les clients se consolident autour de suites intégrées soutenues par des réseaux de support mondiaux.
Leaders du secteur de la classification des données
Amazon Web Services, Inc.
Boldon James Ltd (QinetiQ)
IBM Corporation
Microsoft Corporation
Broadcom Inc. (Symantec Corporation)
- *Avis de non-responsabilité : les principaux acteurs sont triés sans ordre particulier

Développements récents du secteur
- Avril 2025 : Kyndryl a lancé des services de gestion de la posture de sécurité des données avec Microsoft, offrant une découverte et une classification automatisées qui réduisent les coûts opérationnels de 31 %.
- Avril 2025 : Forcepoint a lancé sa plateforme Data Security Cloud combinant les fonctions DSPM et DDR pour offrir un contrôle unifié dans les environnements hybrides.
- Avril 2025 : Forcepoint a finalisé l'acquisition de Getvisibility, ajoutant une classification adaptative pilotée par l'IA à sa pile de sécurité.
- Mars 2025 : BigID a obtenu un financement de série E de 60 millions USD pour étendre ses fonctionnalités d'hygiène des données et de confidentialité.


Cadre de la méthodologie de recherche et portée du rapport
Définitions du marché et couverture principale
Notre étude définit le marché de la classification des données comme l'ensemble des plateformes logicielles et des services professionnels ou gérés associés qui étiquettent, labellisent et appliquent des règles de traitement aux données structurées, semi-structurées et non structurées dans les environnements sur site, cloud et hybrides. Selon Mordor Intelligence, les suites groupées de découverte, de catalogue, de sauvegarde ou de sécurité plus larges ne sont incluses que lorsque le module de classification est tarifé et déclaré séparément.
Exclusion du périmètre : Les outils destinés principalement à la découverte de données, à la gestion de catalogues ou à l'étiquetage de jeux de données pour l'entraînement de modèles d'IA sont hors périmètre.
Aperçu de la segmentation
- Par composant
- Logiciels
- Services
- Par méthode de classification
- Basée sur le contenu
- Basée sur le contexte
- Basée sur l'utilisateur/le rôle
- Pilotée par l'apprentissage automatique et sémantique
- Par taille d'organisation
- Grandes entreprises
- Petites et moyennes entreprises (PME)
- Par application
- Contrôle d'accès et IAM
- Gouvernance et conformité
- Protection des e-mails et des appareils mobiles
- Par secteur vertical
- BFSI
- Santé et sciences de la vie
- Gouvernement et défense
- Technologies de l'information et télécommunications
- Énergie et services publics
- Autres secteurs verticaux
- Par géographie
- Amérique du Nord
- États-Unis
- Canada
- Mexique
- Europe
- Allemagne
- Royaume-Uni
- France
- Italie
- Espagne
- Reste de l'Europe
- Asie-Pacifique
- Chine
- Japon
- Inde
- Corée du Sud
- Australie
- Reste de l'Asie-Pacifique
- Amérique du Sud
- Brésil
- Argentine
- Reste de l'Amérique du Sud
- Moyen-Orient et Afrique
- Moyen-Orient
- Arabie saoudite
- Émirats arabes unis
- Turquie
- Reste du Moyen-Orient
- Afrique
- Afrique du Sud
- Égypte
- Nigéria
- Reste de l'Afrique
- Moyen-Orient
- Amérique du Nord
Méthodologie de recherche détaillée et validation des données
Recherche primaire
Nous avons mené des entretiens structurés avec des directeurs de la sécurité des systèmes d'information dans les secteurs bancaire, de la santé, des télécommunications et des organismes publics en Amérique du Nord, en Europe et en Asie-Pacifique. Nous avons ensuite réalisé des enquêtes auprès de distributeurs et d'auditeurs en cybersécurité. Leurs éclairages sur les déclencheurs d'adoption, les fourchettes de tarification par utilisateur et la vitesse de migration vers le cloud ont permis aux analystes de Mordor de corriger les hypothèses issues de la recherche documentaire.
Recherche documentaire
Notre équipe a commencé par des sources ouvertes telles que les archives d'incidents du National Institute of Standards and Technology des États-Unis, la base de données des violations de l'Agence de l'Union européenne pour la cybersécurité, les journaux de sanctions de l'ICO britannique et les données d'expédition Volza qui référencent les codes SH des logiciels de sécurité. Les rapports de résultats et les formulaires 10-K ont révélé les prix de vente moyens et la pénétration par poste selon le secteur vertical, tandis que D&B Hoovers, Dow Jones Factiva et les analyses de brevets Questel ont contribué à évaluer l'envergure des fournisseurs et l'innovation. Les sources citées sont illustratives et non exhaustives de l'ensemble des documents examinés.
Dimensionnement du marché et prévisions
Une approche descendante relie le nombre d'entreprises par pays et les charges de travail sur données réglementées aux taux de pénétration de la classification observés, qui sont ensuite multipliés par les prix mixtes de licence et de services. Les agrégations fournisseurs, les vérifications de canaux et les valeurs de contrats anonymisées offrent une vérification ascendante. Les variables clés comprennent les postes utilisateurs soumis à des obligations de conformité, le volume de données non structurées, le coût moyen des licences, la part du stockage cloud, la fréquence des amendes réglementaires et la croissance des budgets de sécurité. Une régression multivariée sur ces facteurs projette la demande jusqu'en 2030, tandis que l'analyse de scénarios teste des régimes de confidentialité plus stricts ou assouplis. Les lacunes dans la couverture ascendante sont comblées par des dispersions de prix régionales et des volumes médians.
Cycle de validation des données et de mise à jour
Les résultats du modèle sont soumis à des contrôles de variance par rapport aux indices de dépenses externes et aux résultats des fournisseurs avant validation par les responsables seniors. Les rapports sont actualisés annuellement, avec des révisions intermédiaires en cas de violations majeures ou d'évolutions réglementaires, garantissant aux clients la référence la plus récente.
Pourquoi la référence de Mordor en matière de classification des données est fiable
Les estimations publiées diffèrent souvent parce que les éditeurs choisissent des périmètres, des variables d'entrée et des cadences de mise à jour différents. Les limites rigoureuses de Mordor, ses facteurs mis à jour annuellement et sa réconciliation équilibrée descendante et ascendante minimisent ces distorsions pour les décideurs.
Les principaux facteurs d'écart comprennent : certaines études ne comptabilisent que les revenus des solutions, d'autres extrapolent des courbes agressives de postes cloud, et plusieurs sont actualisées tous les deux ans, créant un décalage par rapport à l'évolution rapide des lois sur la confidentialité.
Comparaison de référence
| Taille du marché | Source anonymisée | Principal facteur d'écart |
|---|---|---|
| 1,88 Md USD (2025) | Mordor Intelligence | |
| 1,85 Md USD (2024) | Global Consultancy A | Périmètre limité aux solutions et hypothèse de TCAC de 35 % |
| 1,66 Md USD (2024) | Industry Research B | Exclut les services professionnels et trois régions émergentes |
Ces contrastes montrent comment notre périmètre clairement défini, la validation au niveau des variables et les mises à jour régulières font de Mordor Intelligence la référence fiable pour les planificateurs et les investisseurs.


Questions clés auxquelles le rapport répond
Quelle est la taille actuelle du marché de la classification des données ?
Le marché est évalué à 2,28 milliards USD en 2026 et devrait atteindre 5,98 milliards USD d'ici 2031, représentant un TCAC de 21,28 %.
Quelle région connaît la croissance la plus rapide ?
L'Asie-Pacifique affiche la croissance la plus élevée, avec un marché de la classification des données qui devrait afficher un TCAC de 22,07 % jusqu'en 2031 en raison des mandats de cloud souverain et des investissements en infrastructure.
Quel segment de composant se développe le plus rapidement ?
Les services croissent à un TCAC de 23,62 % car les organisations ont besoin de conseils professionnels pour déployer et maintenir l'étiquetage alimenté par l'IA dans les environnements hybrides.
Comment les méthodes d'apprentissage automatique impactent-elles l'adoption ?
La classification pilotée par l'apprentissage automatique améliore la précision, réduit les faux positifs et diminue le réglage manuel, aidant les petites entreprises à accéder à une protection de niveau entreprise.
Quels secteurs investissent le plus massivement ?
Le BFSI est en tête des dépenses actuelles grâce à des réglementations strictes, tandis que le gouvernement et la défense affichent la croissance la plus rapide à un TCAC de 21,78 % en raison des exigences de sécurité nationale.
Quelle est la principale contrainte à un déploiement plus large ?
L'intégration de la classification dans les environnements existants reste coûteuse et chronophage, en particulier pour les secteurs d'infrastructures critiques qui exploitent encore des systèmes obsolètes.
Dernière mise à jour de la page le:




