Data-Lake-Marktgröße und Marktanteil
Marktübersicht
| Studienzeitraum | 2020 - 2031 |
|---|---|
| Marktgröße (2026) | 22.8 Milliarden US-Dollar |
| Marktgröße (2031) | 61.84 Milliarden US-Dollar |
| Wachstumsrate (2026 - 2031) | 22.08% CAGR |
| Schnellstwachsender Markt | Asien |
| Größter Markt | Nordamerika |
| Marktkonzentration | Mittel |
Hauptakteure *Haftungsausschluss: Hauptakteure in keiner bestimmten Reihenfolge sortiert Bild © Mordor Intelligence. Wiederverwendung erfordert Namensnennung gemäß CC BY 4.0. | |
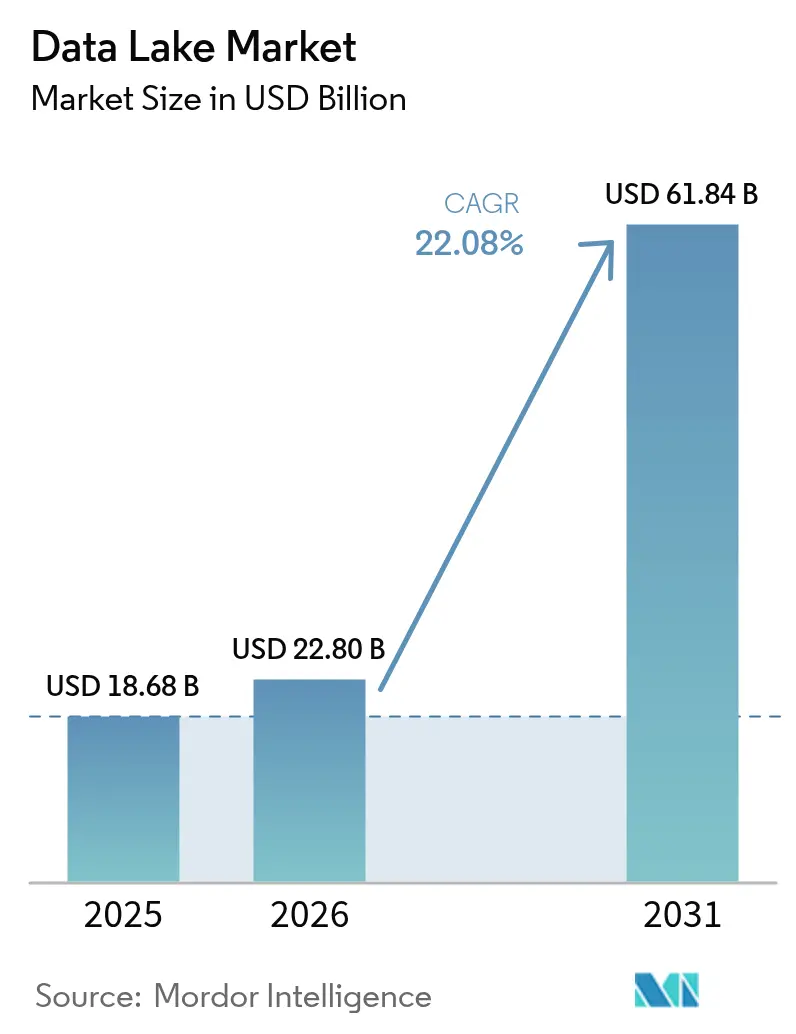
Data-Lake-Marktanalyse von Mordor Intelligence
Die Größe des Data-Lake-Marktes wird voraussichtlich von 18,68 Milliarden USD im Jahr 2025 auf 22,8 Milliarden USD im Jahr 2026 wachsen und bis 2031 bei einem CAGR von 22,08 % über den Zeitraum 2026–2031 voraussichtlich 61,84 Milliarden USD erreichen. Das Wachstum resultiert aus dem rasant steigenden Volumen unstrukturierter Daten, die durch generative KI-Pipelines erzeugt werden, aus erweiterten regulatorischen Anforderungen zur Aufzeichnungsführung sowie aus dem Wandel hin zu Lakehouse-Architekturen, die See- und Warehouse-Strukturen in einer einzigen Ebene zusammenführen. Fortune-500-Unternehmen berichten von Gesamtkosteneinsparungen von 35–40 % nach der Einführung von Lakehouses, während Echtzeit-ESG- und Risikostresstestarbeitslasten die Anwendungsfälle auf industrielle und finanzielle Bereiche ausweiten. Serverlose offene Tabellenformate bilden nun den Kern von Multi-Cloud-Portabilitätsstrategien, und automatisierte Governance-Schichten entstehen, um „Sumpf”-Fallstricke zu verhindern, ohne die Innovation zu bremsen.
Wichtigste Erkenntnisse des Berichts
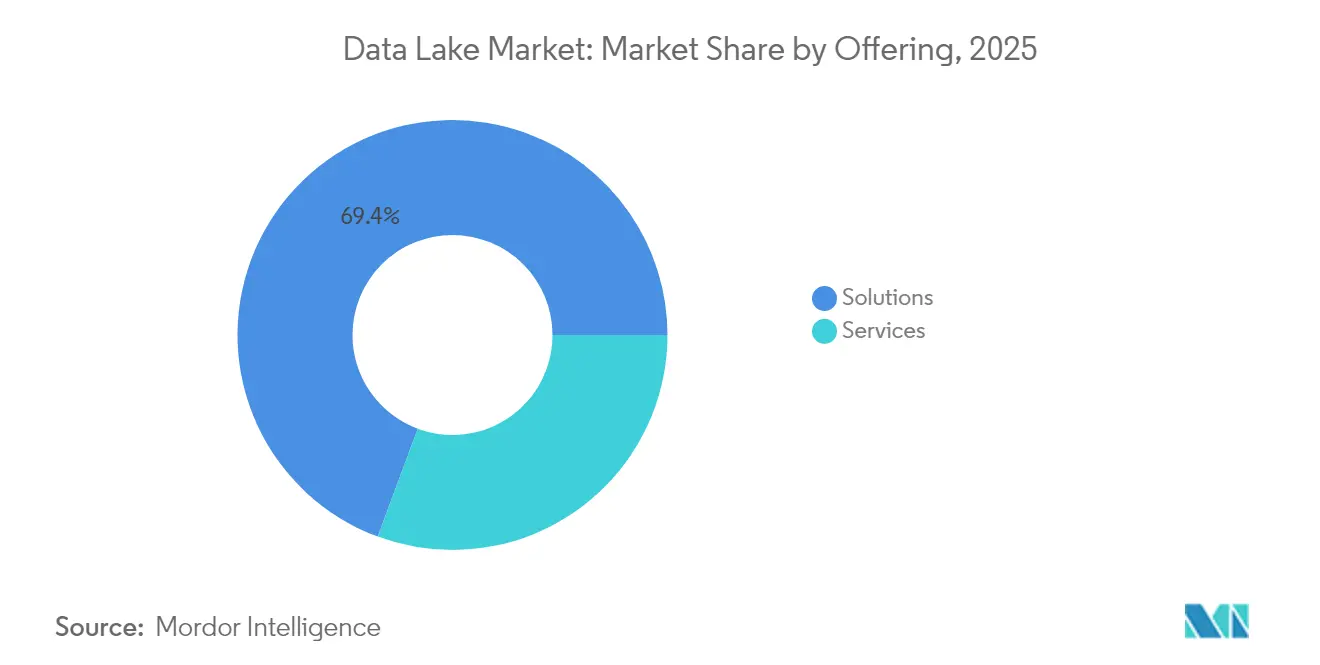
- Nach Angebot führten Lösungen im Jahr 2025 mit einem Umsatzanteil von 69,35 %; Dienstleistungen werden bis 2031 voraussichtlich mit einem CAGR von 24,77 % wachsen.
- Nach Bereitstellung entfiel im Jahr 2025 ein Marktanteil von 64,20 % auf Cloud-Lösungen, während Hybrid/Multi-Cloud zwischen 2026 und 2031 voraussichtlich mit einem CAGR von 23,1 % wachsen wird.
- Nach Unternehmensgröße entfielen im Jahr 2025 71,10 % der Data-Lake-Marktgröße auf Großunternehmen; KMU sind mit einem CAGR von 26,1 % bis 2031 die am schnellsten wachsende Gruppe.
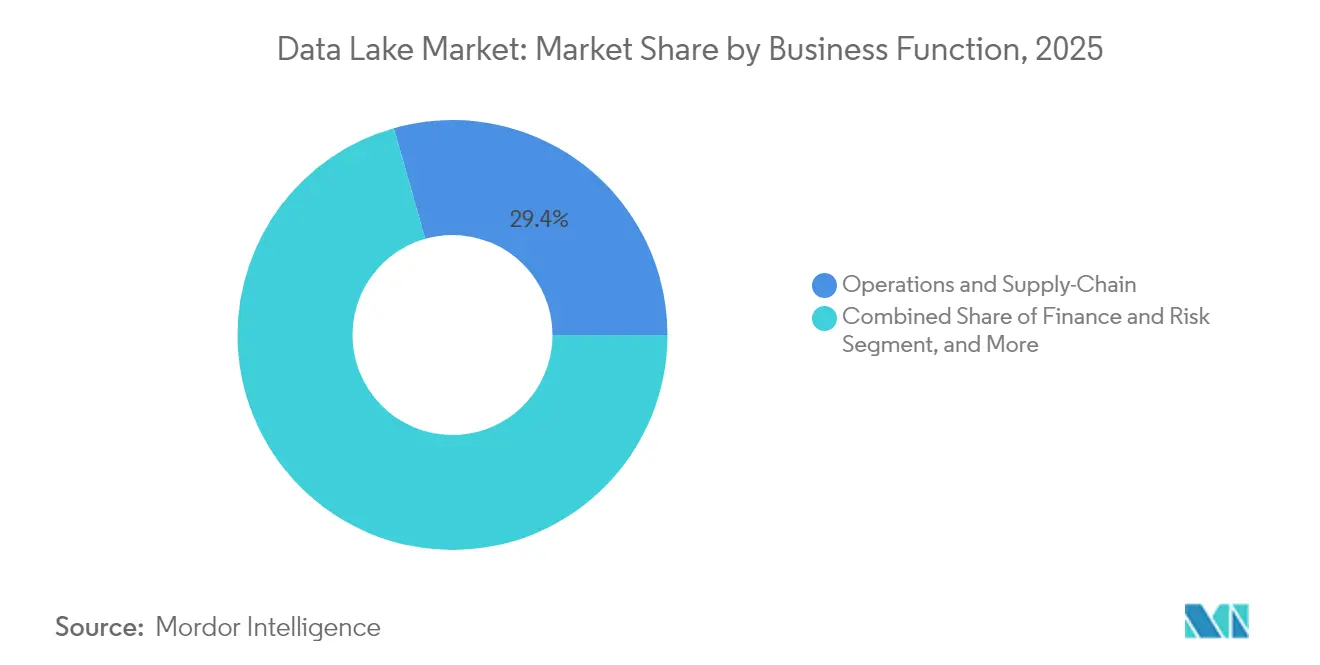
- Nach Geschäftsfunktion hielt Betrieb und Lieferkette im Jahr 2025 einen Anteil von 29,40 % am Data-Lake-Markt, während Finanzen und Risiko bis 2031 mit einem CAGR von 25,2 % wächst.
- Nach Endnutzerbranche führte IT und Telekommunikation im Jahr 2025 mit einem Umsatzanteil von 21,60 %; Gesundheitswesen und Biowissenschaften wird bis 2031 voraussichtlich mit einem CAGR von 25,6 % wachsen.
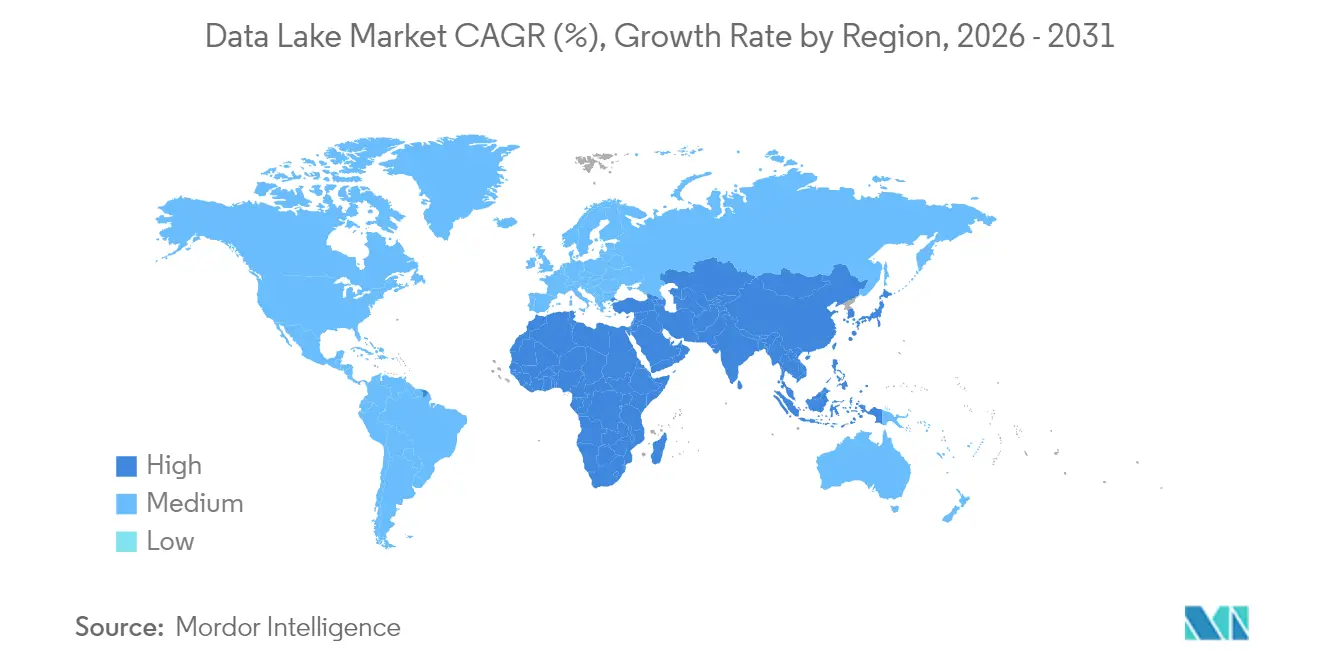
- Nach Geografie dominierte Nordamerika im Jahr 2025 mit einem Anteil von 37,40 %, während Asien bis 2031 voraussichtlich mit einem CAGR von 23,5 % wachsen wird.
Hinweis: Die Marktgrößen- und Prognosezahlen in diesem Bericht werden mithilfe des proprietären Schätzrahmens von Mordor Intelligence erstellt und mit den neuesten verfügbaren Daten und Erkenntnissen bis 2026 aktualisiert.
Globale Data-Lake-Markttrends und Erkenntnisse
Analyse der Auswirkungen von Treibern*
| Treiber | (~) % Auswirkung auf die CAGR-Prognose | Geografische Relevanz | Auswirkungszeitraum |
|---|---|---|---|
| Explosion unstrukturierter und multimodaler Daten aus generativen KI-Arbeitslasten | +7.5% | Global mit Schwerpunkt in Nordamerika und Westeuropa | Mittelfristig (2–4 Jahre) |
| Datenspeicherungsvorschriften in Europa beschleunigen die Einführung cloudbasierter Data Lakes | +5.2% | Europäische Union, Vereinigtes Königreich, Schweiz und APAC | Kurzfristig (≤ 2 Jahre) |
| Lakehouse-Konvergenz treibt 35–40 % TCO-Einsparungen für Fortune-500-Unternehmen | +6.3% | Global mit früher Einführung in Nordamerika | Mittelfristig (2–4 Jahre) |
| Serverlose Tabellenformate (Iceberg/Delta) ermöglichen Multi-Cloud-Portabilität | +4.8% | Global, am stärksten dort, wo Multi-Cloud-Strategien aktiv sind | Mittelfristig (2–4 Jahre) |
| Echtzeit-ESG-Scope-3-Datenerfassungsanforderungen im Industriesektor | +3.2% | Europa, Nordamerika, fortgeschrittene APAC-Volkswirtschaften | Langfristig (≥ 4 Jahre) |
| Regulatorische Stresstests im Finanzdienstleistungsbereich erfordern jahrzehntelange Tick-Daten-Aufbewahrung | +2.9% | Globale Finanzzentren (New York, London, Singapur, Hongkong) | Mittelfristig (2–4 Jahre) |
| Quelle: Mordor Intelligence | |||
Explosion unstrukturierter und multimodaler Daten aus generativen KI-Arbeitslasten
Generative KI-Anwendungen erzeugen umfangreiche Bild-, Audio- und Textdaten, die eine Schema-on-Read-Speicherung erfordern. Unternehmen erwarten, dass bis 2025 30 % der globalen 175-Zettabyte-Datensphäre eine Echtzeitverarbeitung erfordern werden – ein Profil, das für starre Warehouses ungeeignet ist. Data Lakes werden daher zur Standard-Landezone für multimodale Korpora, die in Prompt-Engineering-Schleifen verwendet werden.[1]Acceldata, "Enterprise Data Lakes: Revolutionizing Business Data," acceldata.ioDer Lakehouse-Entwurf von Google Cloud zeigt, wie die Speicherung im nativen Format in Kombination mit Vektorindizierung die Feinabstimmung von Foundation-Modellen beschleunigt und gleichzeitig die Speicherkosten senkt. Unternehmen, die die Einführung verzögern, riskieren langsamere Innovationszyklen und höhere Stückkosten bei KI-Arbeitslasten.
Datenspeicherungsvorschriften in Europa beschleunigen die Einführung cloudbasierter Data Lakes
Das EU-Datenverwaltungsgesetz und das Datengesetz verpflichten Organisationen zur Lokalisierung sensibler Arbeitslasten. Hyperscaler reagieren darauf: AWS investiert 7,8 Milliarden EUR in eine souveräne Cloud-Region, die mit integrierten Datenspeicherungskontrollen ausgeliefert wird.[2]Databricks, "Databricks Agrees to Acquire Tabular," databricks.com Unternehmen setzen nun regionssegmentierte Data Lakes ein, die Speicherungsvorschriften erfüllen und dennoch über föderierte Engines abfragbar bleiben, was die Nachfrage nach metadatenreichen Katalogen ankurbelt, die in der Lage sind, grenzüberschreitende Datennutzung in Prüfberichten aufzuzeigen.
Lakehouse-Konvergenz liefert 35–40 % TCO-Einsparungen
Ein einstufiges Lakehouse beseitigt die Duplizierung, die früher separate Seen und Warehouses belastete. Befragte Unternehmen, die Analyseaufgaben auf Lakehouse-Engines verlagern, berichten von halbierten Datenübertragungskosten und komprimierungsbedingten Speichereinsparungen. Leistungsgewinne durch vektorbewusste Abfrageplaner reduzieren die Rechenzeiten weiter und setzen Budget für KI-Experimente frei. Einundachtzig Prozent der Unternehmen trainieren ML-Modelle nun direkt auf Lakehouse-Tabellen, was darauf hindeutet, dass die Konvergenz keine Randerscheinung mehr ist, sondern ein Mainstream-Muster.
Serverlose Tabellenformate ermöglichen Multi-Cloud-Portabilität
Apache Iceberg, Delta Lake und Hudi führen ACID-Transaktionen, Schema-Evolution und Zeitreisen in Objektspeicher ein. Die Formate entkoppeln Compute von Storage und ermöglichen es Analyse-Engines in konkurrierenden Clouds, dieselben Datensätze ohne Replikation abzufragen. Die Übernahme von Tabular durch Databricks im Jahr 2024 unterstreicht den strategischen Wert offener Tabellenmetadaten, während die Omni-Funktion von Google BigLake Iceberg-Partitionen in konkurrierenden Clouds abfragt und damit die These des neutralen Formats bestätigt.[3]Europäische Kommission, "Eine europäische Datenstrategie," digital-strategy.ec.europa.eu
Analyse der Auswirkungen von Hemmnissen*
| Hemmnis | (~) % Auswirkung auf die CAGR-Prognose | Geografische Relevanz | Auswirkungszeitraum |
|---|---|---|---|
| Metadatendrift führt zu „Datensümpfen” | -3.8% | Global, stärker ausgeprägt bei Legacy-Implementierungen | Kurzfristig (≤ 2 Jahre) |
| Mangel an qualifizierten Data-Lake-Ingenieuren | -2.9% | APAC, Lateinamerika, Naher Osten und Afrika | Mittelfristig (2–4 Jahre) |
| Latenzempfindliche Anwendungsfälle bevorzugen weiterhin Warehouses | -2.1% | Finanz- und Telekommunikationszentren weltweit | Kurzfristig (≤ 2 Jahre) |
| Intransparente verbrauchsbasierte Cloud-Preisgestaltung | -1.7% | Mittelständische Unternehmen weltweit | Mittelfristig (2–4 Jahre) |
| Quelle: Mordor Intelligence | |||
Metadatendrift führt zu „Datensümpfen”
Wenn die Datenaufnahme die Katalogaktualisierungen überholt, werden Data Lakes zu nicht durchsuchbaren Repositories. Bis 2025 wird das globale Datenvolumen 163 Zettabyte erreichen, was das Risiko isolierter Dateien ohne Kontext erhöht. Unternehmen reagieren darauf, indem sie automatisierte Herkunfts-Tracker wie Unity Catalog einsetzen, der jeden Lese-/Schreibvorgang protokolliert und verwaiste Assets kennzeichnet. Ohne ähnliche Kontrollen kann der Governance-Aufwand die prognostizierten Einsparungen aus der Lakehouse-Konsolidierung zunichtemachen.
Mangel an qualifizierten Lake-Ingenieuren in aufstrebenden Regionen
Unternehmen in APAC und Lateinamerika beklagen einen Mangel an Ingenieuren, die verteilte Dateisysteme, offene Tabellenformate und Cloud-Kostenoptimierung beherrschen. POPsights-Daten zeigen, dass die KI-getriebene Schaffung neuer Stellen das lokale Ausbildungsangebot übersteigt. OECD-Forschungen heben eine wachsende Stadt-Land-Kluft beim Zugang zu fortgeschrittenen Datenkenntnissen hervor.[4]OECD, "Schaffung von Arbeitsplätzen und lokale Wirtschaftsentwicklung 2024," oecd.org Verwaltete Dienste und Low-Code-Pipelines mildern den Mangel, doch der Talentmangel verlängert weiterhin die Implementierungszyklen und verlangsamt die Marktdurchdringung von Data Lakes.
*Unsere Prognosen behandeln die Auswirkungen von Treibern und Einschränkungen als richtungsweisend und nicht additiv. Die Wirkungsprognosen berücksichtigen Basiswachstum, Mischungseffekte und Wechselwirkungen zwischen Variablen.
Segmentanalyse
Nach Angebot: Lösungen führen, Dienstleistungen wachsen stark
Lösungen generierten im Jahr 2025 69,35 % des Data-Lake-Marktumsatzes, was einer Data-Lake-Marktgröße von 12,95 Milliarden USD entspricht. Die Dominanz resultiert daraus, dass Unternehmen Speicher-Engines, Abfragebeschleuniger und Governance-Suiten standardisieren, die das Rückgrat KI-fähiger Umgebungen bilden. Anbieter bündeln Kostenoptimierungs-Dashboards, automatisiertes Tiering und native Unterstützung offener Tabellenformate und bleiben damit relevant, wenn sich Arbeitslasten weiterentwickeln.
Das Dienstleistungssegment wächst mit einem CAGR von 24,77 % bis 2031 rasant, was die Nachfrage nach Migrationsplänen, Leistungsoptimierung und 24×7-Managed-Operations widerspiegelt. Vielen Unternehmen fehlt Personal, das Legacy-Hadoop-Umgebungen neu aufsetzen kann, weshalb sie Spezialisten beauftragen, die vorhersehbare SLA-Ergebnisse versprechen. Der angespannte Talentmarkt stellt sicher, dass die Buchungen für professionelle Dienstleistungen schneller wachsen werden als der gesamte Data-Lake-Markt.



Nach Bereitstellung: Cloud dominiert, Hybrid beschleunigt
Cloud-Bereitstellungen entfielen im Jahr 2025 auf 64,20 % des Data-Lake-Marktanteils, da Organisationen sofortige Skalierbarkeit und integrierte Sicherheit anstrebten. Elastische Objektspeicher wie Amazon S3 eliminieren Investitionsausgaben und bieten gleichzeitig Lifecycle-Automatisierung, die kalte Daten automatisch in kostengünstige Klassen verschiebt. Analyse-Engines werden dann bei Bedarf hochgefahren, wodurch die Rechenausgaben mit dem Projekttempo in Einklang gebracht werden.
Hybrid- und Multi-Cloud-Konfigurationen wachsen bis 2031 mit einem CAGR von 23,1 %. Offene Tabellenformate ermöglichen es, eine Metadatendefinition über lokale und öffentliche Cloud-Buckets hinweg zu verwenden, was den Replikationsbedarf drastisch reduziert. Regionale Compliance-Vorschriften treiben Hybrid-Strategien weiter voran, da Unternehmen regulierte Arbeitslasten in souveränen Regionen verankern und dennoch über Cloud-übergreifende Fabrics abfragen. Infolgedessen steigt die Data-Lake-Marktgröße für Hybrid-Umgebungen im Gleichschritt mit souveränen Cloud-Einführungen.
Nach Unternehmensgröße: Großunternehmen dominieren, KMU gewinnen an Tempo
Großunternehmen machten im Jahr 2025 71,10 % der Data-Lake-Marktgröße aus, was ungefähr 13,28 Milliarden USD entspricht. Ihre komplexen, Petabyte-großen Umgebungen erfordern erweitertes RBAC, automatisierte Herkunftsverfolgung und FinOps-Governance. Banken, Hersteller und Telekommunikationsunternehmen verlassen sich auf Lakehouses, um Silos zu konsolidieren und Echtzeit-KI-Anwendungen zu unterstützen.
Kleine und mittlere Unternehmen verzeichnen mit einem CAGR von 26,1 % das schnellste Wachstum, da von Anbietern verwaltete Pläne nun eine „Pay-as-processed”-Abrechnung anbieten. Low-Code-Orchestrierung und vorlagengesteuerte Schemata verkürzen die Implementierungszyklen. Community-Editionen von Iceberg und Delta bieten unternehmensgerechte Funktionen ohne Lizenzgebühren und ermöglichen es ressourcenbeschränkten Unternehmen, in den Data-Lake-Markt-Mainstream einzusteigen.
Nach Geschäftsfunktion: Betrieb stabil, Finanzen und Risiko wachsen stark
Betriebs- und Lieferkettenarbeitslasten generierten im Jahr 2025 29,40 % der Ausgaben, wobei Hersteller IoT-Telemetrie, Lieferanten-EDI und Logistikdaten für die vorausschauende Wartung zusammenführen. Die Schema-on-Read-Flexibilität macht Data Lakes ideal für die Zusammenführung halbstrukturierter Sensordateien mit ERP-Tabellen und unterstützt Control-Tower-Dashboards, die Ausfallzeitrisiken aufzeigen.
Finanz- und Risikoanwendungen wachsen mit einem CAGR von 25,2 %. Regulatoren erwarten nun jahrzehntelange Tick-Historien, und Lakehouses speichern diese Volumina effizient. Der Vorschlag der US-Notenbank vom April 2025 zur Überarbeitung der Stresspufferberechnungen unterstreicht die Notwendigkeit, Kapitalauswirkungen unter Stressbedingungen zu modellieren. Banken, die Risiko-, Treasury- und ESG-Daten in einem verwalteten Data Lake zentralisieren, eliminieren Abstimmungsverzögerungen und gewinnen Berichtsflexibilität.
Nach Endnutzerbranche: IT und Telekommunikation führen, Gesundheitswesen wächst
IT- und Telekommunikationsbetreiber hielten im Jahr 2025 21,60 % des Umsatzes. Netzbetreiber nehmen Anrufdetailaufzeichnungen, Netz-KPIs und Support-Transkripte in Data Lakes auf und führen dann Betrugserkennung und Abwanderungsanalysen durch, die den Lifetime Value verbessern. Softteco weist darauf hin, dass Vodafone und AT&T KI-gesteuerte Lake-Architekturen nutzen, um Sendemasten zu optimieren und Angebote zu personalisieren.
Gesundheitswesen und Biowissenschaften werden voraussichtlich mit einem CAGR von 25,6 % wachsen. Krankenhäuser verbinden elektronische Gesundheitsakten, Bildgebung und Genomik in einheitlichen Repositories, die Präzisionsmedizinstudien ermöglichen. Microsoft-Fabric-Implementierungen veranschaulichen, wie einheitliche Aufnahmepipelines die Datenvorbereitung verkürzen und Echtzeit-klinische Warnmeldungen ermöglichen. Pharmaunternehmen nutzen wiederholbare Lake-Workflows, um Entdeckungszyklen zu verkürzen, was nachhaltige Investitionen in den Data-Lake-Markt antreibt.
Geografische Analyse
Nordamerika generierte im Jahr 2025 37,40 % des Umsatzes und setzt weiterhin Maßstäbe in der Architekturreife. Finanzinstitute verlängern die Zeitreihenaufbewahrung, um sich entwickelnden Stresstest-Vorlagen gerecht zu werden, während Krankenhausnetzwerke multimodale Patientengraphen aufbauen, die KI-gestützte Diagnostik unterstützen. Risikokapital fördert auch die Bildung von Governance-Start-ups und sorgt für ein lebendiges Ökosystem.
Asien-Pazifik ist die am schnellsten wachsende Region mit einem CAGR von 23,5 % bis 2031. Regierungen in Japan, Indien und Singapur fördern souveräne Cloud-Projekte und treiben die Nachfrage nach regionenkonformen Lake-Zonen an. Telekommunikationsunternehmen in China analysieren umfangreiche 5G-Protokolle für die Kapazitätsplanung, während indonesische Fintechs Betrugserkennungs-Lakes teilen, um Cyberkriminalität einzudämmen. Anbieter, die APAC-Hauptsitze einrichten, wie Wasabi in Japan, zielen darauf ab, den prognostizierten IaaS-Anstieg von 36 % zu nutzen.
Europa beschleunigt die Einführung unter strengen Datensouveränitätsmandaten. Die europäische Datenstrategie treibt Investitionen in lokales Hosting voran, und AWS wird bis Ende 2025 eine Region in Brandenburg eröffnen, um Speicherungsvorschriften zu erfüllen. Hersteller speichern Echtzeit-Scope-3-Emissionen für die CSRD-Berichterstattung, und Banken verfeinern Basel-III-Berechnungen in prüfungssicheren Data Lakes. Die Stresstest-Vorlagen der Europäischen Bankenaufsichtsbehörde für 2025 verstärken die technischen Anforderungen, die Lakehouses erfüllen.

Wettbewerbslandschaft
Der Data-Lake-Markt ist mäßig fragmentiert. Hyperscaler – AWS, Microsoft Azure, Google Cloud – dominieren die Infrastruktur und nutzen globale Regionen und integrierte Governance. Spezialisierte Plattformen wie Databricks und Snowflake heben sich durch Leistung, Notebook-Integration und Lakehouse-Vollständigkeit ab. Open-Source-Gemeinschaften steuern Iceberg, Delta und Hudi und geben Käufern Formatoptionen, die die Anbieterabhängigkeit lockern.
Strategische Übernahmen gestalten Wertschöpfungsketten um. Databricks erwarb Tabular im Jahr 2024, um die Iceberg-Herkunft in Delta-Workflows zu integrieren, was auf eine Wette auf universelle Metadaten hindeutet. Fivetran kaufte Census im Jahr 2025 und vereinte Datenaufnahme und Reverse-ETL, um den Aktivierungskreislauf zu schließen. Das Clumio-Geschäft von Commvault im Jahr 2024 fügt Ransomware-Wiederherstellungs-Snapshots für S3-Data-Lakes hinzu. Diese Schritte deuten auf eine Zukunft hin, in der integrierte Suiten Aufnahme, Governance, Schutz und Aktivierung umfassen.
Trotz der Stärke der Hyperscaler erfassen die fünf größten Anbieter etwa 55 % der Gesamtausgaben, was Raum für Innovatoren lässt, die sich auf Kostenoptimierung, Cloud-übergreifende Abfragebeschleunigung und branchenspezifische Governance-Pläne spezialisieren. KI-gestützte Datenqualitätsbeobachtung und souveräne Cloud-Governance sind zwei aufkommende Lücken, die wahrscheinlich neue Marktteilnehmer anziehen werden.
Marktführer der Data-Lake-Branche
Microsoft Corporation
Amazon.com Inc.
Capgemini SE
Oracle Corporation
Teradata Corporation
- *Haftungsausschluss: Hauptakteure in keiner bestimmten Reihenfolge sortiert

Jüngste Branchenentwicklungen
- Mai 2025: Fivetran übernahm Census und fügte Reverse-ETL-Funktionen hinzu, die Daten in operativen Systemen aktivieren.
- April 2025: Die US-Notenbank schlug Überarbeitungen der Stresspufferberechnungen vor, was die Nachfrage nach jahrzehntelangen Risikodaten erhöht.
- Januar 2025: Das US-Finanzministerium veröffentlichte einen Bericht darüber, wie die Bankgröße die Effizienz der Kapitalmärkte beeinflusst, und unterstrich damit differenzierte Datenverwaltungsanforderungen.
- November 2024: Die Europäische Bankenaufsichtsbehörde veröffentlichte Stresstest-Vorlagen für 2025, die Dateneingabestandards formalisieren.


Berichtsumfang des globalen Data-Lake-Marktes
Ein Data Lake ist ein zentralisiertes Repository, das es Nutzern ermöglicht, alle halbstrukturierten, strukturierten und unstrukturierten Daten in beliebigem Umfang zu speichern. Nutzer können ihre Daten so speichern, wie sie sind, ohne sie zunächst strukturieren zu müssen. Sie können verschiedene Arten von Analysen durchführen, von Dashboards und Visualisierungen über Big-Data-Verarbeitung, Echtzeitanalysen bis hin zu maschinellem Lernen, um bessere Entscheidungen zu treffen.
Der Data-Lake-Markt ist segmentiert nach Angebot (Lösung, Dienstleistung), nach Bereitstellung (Cloud, vor Ort), nach Endnutzerbranche (IT und Telekommunikation, BFSI, Gesundheitswesen, Einzelhandel, Fertigung, andere Endnutzerbranchen), nach Geografie (Nordamerika (Vereinigte Staaten, Kanada), Europa (Vereinigtes Königreich, Deutschland, Frankreich, Italien, Rest von Europa), Asien-Pazifik (China, Japan, Indien, Rest von Asien-Pazifik), Lateinamerika (Mexiko, Brasilien, Argentinien, Rest von Lateinamerika), Naher Osten und Afrika (Vereinigte Arabische Emirate, Saudi-Arabien, Südafrika, Rest des Nahen Ostens und Afrikas)).
Die Marktgrößen und Prognosen werden für alle oben genannten Segmente in Werten in USD angegeben.
| Lösungen | Datenerkennung und Katalogisierung |
| Datenintegration und ETL/ELT | |
| Analyse- und Visualisierungstools | |
| Governance- und Sicherheitsplattformen | |
| Dienstleistungen | Professionelle Dienstleistungen (Beratung, Integration) |
| Verwaltete Dienste |
| Cloud | Öffentliche Cloud |
| Private Cloud | |
| Hybrid/Multi-Cloud | |
| Vor Ort |
| Großunternehmen |
| Kleine und mittlere Unternehmen (KMU) |
| Betrieb und Lieferkette |
| Finanzen und Risiko |
| Vertrieb und Marketing |
| Personalwesen |
| IT und Telekommunikation |
| BFSI |
| Gesundheitswesen und Biowissenschaften |
| Einzelhandel und E-Commerce |
| Fertigung und Industrie |
| Medien und Unterhaltung |
| Regierung und öffentlicher Sektor |
| Energie und Versorgungsunternehmen |
| Sonstige (Bildung, Gastgewerbe) |
| Nordamerika | Vereinigte Staaten |
| Kanada | |
| Mexiko | |
| Südamerika | Brasilien |
| Argentinien | |
| Chile | |
| Peru | |
| Rest von Südamerika | |
| Europa | Deutschland |
| Vereinigtes Königreich | |
| Frankreich | |
| Italien | |
| Spanien | |
| Rest von Europa | |
| Asien-Pazifik | China |
| Japan | |
| Indien | |
| Australien | |
| Neuseeland | |
| Rest von Asien-Pazifik | |
| Naher Osten | Vereinigte Arabische Emirate |
| Saudi-Arabien | |
| Türkei | |
| Rest des Nahen Ostens | |
| Afrika | Südafrika |
| Rest von Afrika |
| Nach Angebot | Lösungen | Datenerkennung und Katalogisierung |
| Datenintegration und ETL/ELT | ||
| Analyse- und Visualisierungstools | ||
| Governance- und Sicherheitsplattformen | ||
| Dienstleistungen | Professionelle Dienstleistungen (Beratung, Integration) | |
| Verwaltete Dienste | ||
| Nach Bereitstellung | Cloud | Öffentliche Cloud |
| Private Cloud | ||
| Hybrid/Multi-Cloud | ||
| Vor Ort | ||
| Nach Unternehmensgröße | Großunternehmen | |
| Kleine und mittlere Unternehmen (KMU) | ||
| Nach Geschäftsfunktion | Betrieb und Lieferkette | |
| Finanzen und Risiko | ||
| Vertrieb und Marketing | ||
| Personalwesen | ||
| Nach Endnutzerbranche | IT und Telekommunikation | |
| BFSI | ||
| Gesundheitswesen und Biowissenschaften | ||
| Einzelhandel und E-Commerce | ||
| Fertigung und Industrie | ||
| Medien und Unterhaltung | ||
| Regierung und öffentlicher Sektor | ||
| Energie und Versorgungsunternehmen | ||
| Sonstige (Bildung, Gastgewerbe) | ||
| Nach Geografie | Nordamerika | Vereinigte Staaten |
| Kanada | ||
| Mexiko | ||
| Südamerika | Brasilien | |
| Argentinien | ||
| Chile | ||
| Peru | ||
| Rest von Südamerika | ||
| Europa | Deutschland | |
| Vereinigtes Königreich | ||
| Frankreich | ||
| Italien | ||
| Spanien | ||
| Rest von Europa | ||
| Asien-Pazifik | China | |
| Japan | ||
| Indien | ||
| Australien | ||
| Neuseeland | ||
| Rest von Asien-Pazifik | ||
| Naher Osten | Vereinigte Arabische Emirate | |
| Saudi-Arabien | ||
| Türkei | ||
| Rest des Nahen Ostens | ||
| Afrika | Südafrika | |
| Rest von Afrika | ||


Im Bericht beantwortete Schlüsselfragen
Warum wechseln Unternehmen von Warehouses zu Lakehouses?
Lakehouses senken die Analyse-TCO um 35–40 % und unterstützen das Training von KI-Modellen auf Rohdaten, während ACID-Leistungsgarantien erhalten bleiben.
Wie groß ist der Data-Lake-Markt im Jahr 2026?
Der Data-Lake-Markt wird im Jahr 2026 auf 22,8 Milliarden USD geschätzt und wird bis 2031 voraussichtlich 61,84 Milliarden USD erreichen.
Welche Region wächst bei der Data-Lake-Einführung am schnellsten?
Asien-Pazifik führt mit einem prognostizierten CAGR von 23,5 % zwischen 2026 und 2031, angetrieben durch rasante digitale Transformation und Investitionen in souveräne Cloud-Infrastrukturen.
Was ist die größte Herausforderung, die Data Lakes daran hindert, Mehrwert zu liefern?
Metadatendrift kann Data Lakes in „Datensümpfe” verwandeln, was Investitionen in automatisierte Kataloge und Herkunftsverfolgung erforderlich macht, um das Vertrauen zu erhalten.
Wie wirken sich offene Tabellenformate auf die Anbieterabhängigkeit aus?
Formate wie Apache Iceberg und Delta Lake ermöglichen Multi-Cloud-Portabilität, indem sie Storage von Compute-Engines entkoppeln und es Teams ermöglichen, dieselben Daten über verschiedene Clouds hinweg abzufragen.
Welche Branche wird voraussichtlich am schnellsten wachsen?
Gesundheitswesen und Biowissenschaften werden bis 2031 voraussichtlich mit einem CAGR von 25,6 % wachsen und Data Lakes für Präzisionsmedizin und Echtzeit-Patientenanalysen nutzen.
Seite zuletzt aktualisiert am:




