Marktgröße und Marktanteil der Computationalen Biologie
Marktübersicht
| Studienzeitraum | 2020 - 2031 |
|---|---|
| Marktgröße (2026) | 8.17 Milliarden US-Dollar |
| Marktgröße (2031) | 14.89 Milliarden US-Dollar |
| Wachstumsrate (2026 - 2031) | 12.78% CAGR |
| Schnellstwachsender Markt | Asien-Pazifik |
| Größter Markt | Nordamerika |
| Marktkonzentration | Mittel |
Hauptakteure *Haftungsausschluss: Hauptakteure in keiner bestimmten Reihenfolge sortiert Bild © Mordor Intelligence. Wiederverwendung erfordert Namensnennung gemäß CC BY 4.0. | |
Marktanalyse der Computationalen Biologie von Mordor Intelligence
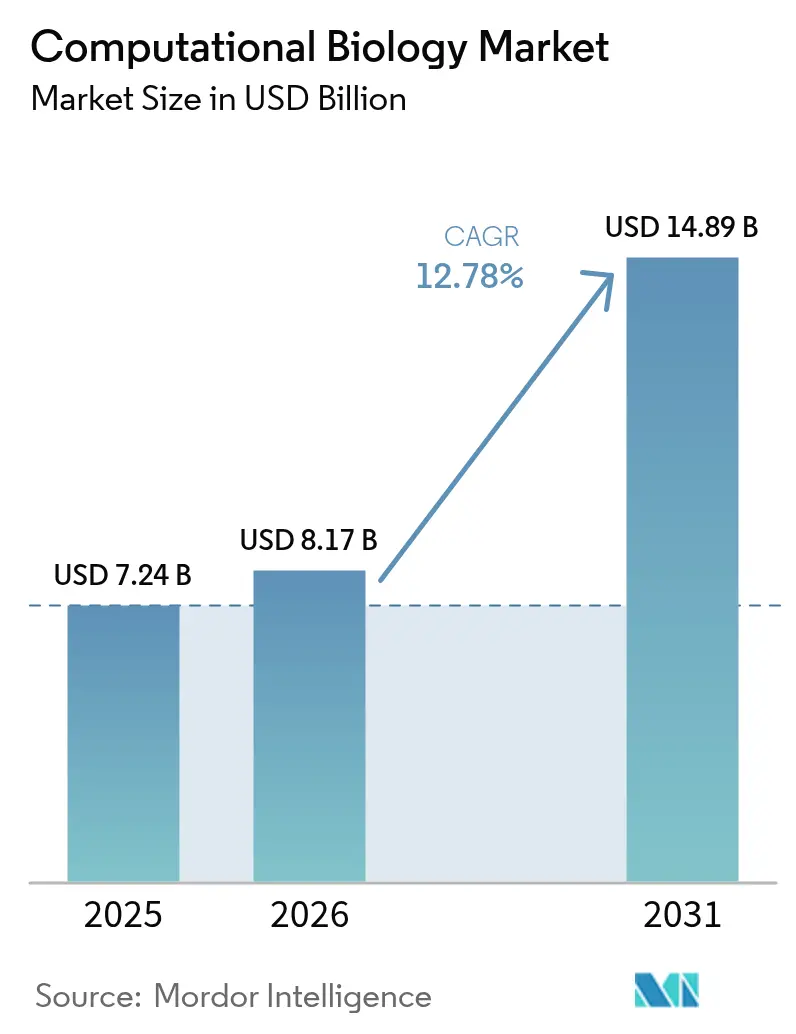
Die Marktgröße der Computationalen Biologie wird im Jahr 2026 auf 8,17 Milliarden USD geschätzt, ausgehend von einem Wert von 7,24 Milliarden USD im Jahr 2025, mit Prognosen für 2031 von 14,89 Milliarden USD, was einem Wachstum von 12,78 % CAGR über den Zeitraum 2026–2031 entspricht. Diese Aussicht signalisiert, wie transformatorbasierte Genomsprachmodelle, digitale Zwillinge der synthetischen Biologie und eine breitere KI-Nutzung nun jede Anwendungsschicht des Marktes für Computationale Biologie prägen. Ein starker Anstieg von Multi-Omics-Datensätzen, anhaltende Verlagerungen hin zu Auftragsforschungsdienstleistungen und der Bedarf an skalierbarer Cloud-Infrastruktur treiben die Nachfrage weiter an. Nordamerika verankert den Markt für Computationale Biologie weiterhin dank ausgereifter Biotechnologieregulierung, aber die Supercomputer-Investitionen im asiatisch-pazifischen Raum und die expandierende pharmazeutische Fertigungsbasis positionieren die Region als nächste Wachstumslokomotive. Unterdessen spiegeln strategische Akquisitionen wie Siemens' 5,1-Milliarden-USD-Deal für Dotmatics die zunehmende Plattformkonsolidierung im Markt für Computationale Biologie wider.
Wichtigste Erkenntnisse des Berichts
- Nach Anwendung entfiel auf zelluläre und biologische Simulation im Jahr 2025 ein Anteil von 32,10 % am Markt für Computationale Biologie, während Wirkstoffforschung und Krankheitsmodellierung bis 2031 mit einer CAGR von 15,33 % wachsen sollen.
- Nach Werkzeug hielten Datenbanken im Jahr 2025 den größten Anteil von 35,95 % an der Marktgröße der Computationalen Biologie; Analysesoftware und -dienstleistungen sollen jedoch bis 2031 mit einer CAGR von 14,49 % expandieren.
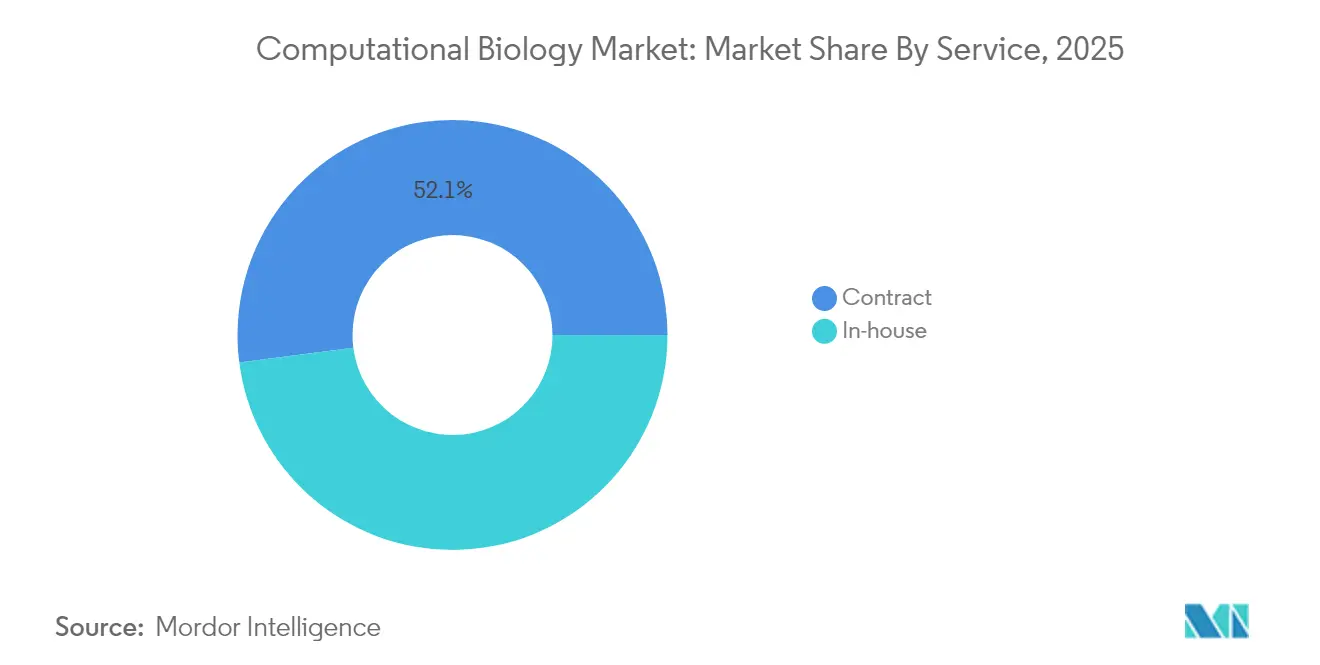
- Nach Dienstleistungsmodell entfielen auf Auftragsvereinbarungen im Jahr 2025 52,05 % des Marktanteils der Computationalen Biologie, und es wird prognostiziert, dass sie bis 2031 mit einer CAGR von 15,72 % wachsen.
- Nach Endnutzer hielt die Wissenschaft im Jahr 2025 einen Umsatzanteil von 44,10 %, während Industrie- und Gewerbenutzer bis 2031 eine CAGR von 14,27 % erzielen sollen.
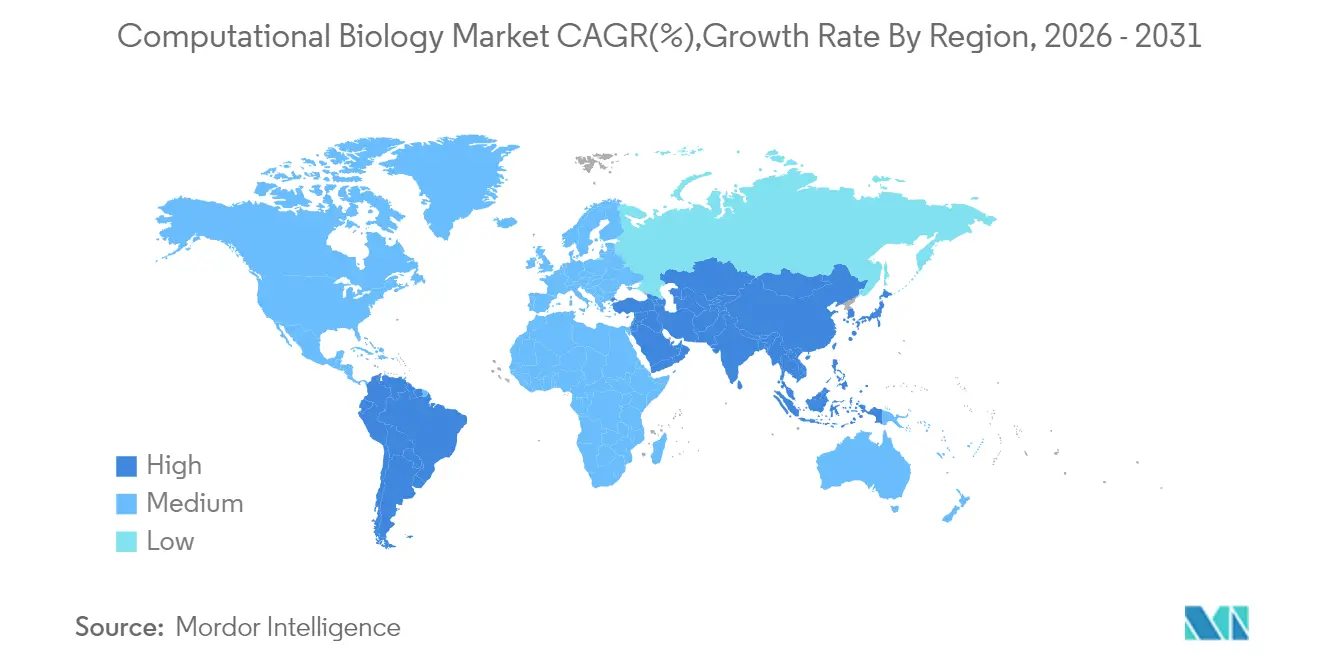
- Nach Region führte Nordamerika im Jahr 2025 mit einem Marktanteil von 42,30 % an der Computationalen Biologie; der asiatisch-pazifische Raum weist bis 2031 die schnellste CAGR-Prognose von 16,02 % auf.
Hinweis: Die Marktgrößen- und Prognosezahlen in diesem Bericht werden mithilfe des proprietären Schätzrahmens von Mordor Intelligence erstellt und mit den neuesten verfügbaren Daten und Erkenntnissen bis 2026 aktualisiert.
Globale Trends und Erkenntnisse im Markt für Computationale Biologie
Analyse der Treiberwirkung*
| Treiber | (~) % Auswirkung auf die CAGR-Prognose | Geografische Relevanz | Zeithorizont der Auswirkung |
|---|---|---|---|
| Steigendes Volumen an Omics-Daten und bioinformatischer Forschung | +2.8% | Global, konzentriert in Nordamerika und der EU | Mittelfristig (2–4 Jahre) |
| Beschleunigter Einsatz in der Wirkstoffforschung und Krankheitsmodellierung | +3.1% | Global, angeführt von Nordamerika, Ausweitung auf den asiatisch-pazifischen Raum | Kurzfristig (≤ 2 Jahre) |
| Ausweitung klinischer pharmakogenomischer und pharmakokinetischer Studien | +1.9% | Nordamerika und EU, aufkommend im asiatisch-pazifischen Raum | Mittelfristig (2–4 Jahre) |
| Transformatorbasierte Genomsprachmodelle ermöglichen schnelle Annotation | +2.2% | Global, frühe Übernahme durch Forschungsinstitute | Kurzfristig (≤ 2 Jahre) |
| Digitale Zwillinge der synthetischen Biologie für In-silico-Workflows | +1.7% | Nordamerika und EU, Pilotprojekte im asiatisch-pazifischen Raum | Langfristig (≥ 4 Jahre) |
| Open-Source-Einzelzell-Abstammungsverfolgungsalgorithmen | +1.5% | Global, akademisch geführt mit industrieller Übernahme | Mittelfristig (2–4 Jahre) |
| Quelle: Mordor Intelligence | |||
Steigendes Volumen an Omics-Daten und bioinformatischer Forschung
Terabyte-skalige Einzelzell-RNA-Sequenzierung, Multi-Omics-Integration und sinkende Sequenzierungskosten weiten die Datenflüsse in den Markt für Computationale Biologie weiter aus. Fortschritte in der Sequenzierung haben die RNA-Seq-Kosten um 50–70 % gesenkt und den Zugang zu Präzisionsmedizin-Datensätzen erweitert. Große Sprachmodelle automatisieren nun 94 % der gängigen Datenelement-Zuordnung und fördern die Interoperabilität.[1]Rodney Alan Long, Jordan Klebanoff und Vince D. Calhoun, „Ein neuer KI-gestützter Datenstandard beschleunigt die Interoperabilität in der biomedizinischen Forschung”, medRxiv, medrxiv.orgDie daraus resultierenden Datennetzwerkeffekte stärken die Vorteile der Erstmover für Akteure, die die größten Repositorien kontrollieren. Cloud-Bioinformatikplattformen sind daher zu einer obligatorischen Infrastruktur für Organisationen geworden, denen lokale Hochleistungsrechner fehlen.
Beschleunigter Einsatz in der Wirkstoffforschung und Krankheitsmodellierung
Protein-Sprachmodelle wie ESM-3 simulieren evolutionäre Prozesse und erzeugen neuartige Proteinkandidaten in einem Tempo, das Arzneimittelentwickler vor einigen Jahren nicht erreichen konnten. Hybride KI-Quantensysteme, exemplarisch durch Model Medicines' GALILEO, liefern nun antivirale Screens mit einer Trefferquote von 100 %.[2]Model Medicines Communications Team, „Die Zukunft der Wirkstoffforschung: 2025 als Wendepunkt für hybride KI und Quantencomputing”, Model Medicines, modelmedicines.comDigitale Zwillinge ermöglichen es Forschern, Millionen virtueller Experimente durchzuführen und damit Hypothesentestzyklen zu verkürzen und Nasslab-Kosten zu senken. Ein Benchmark mit 479.000 maschinellen Lernversuchen liefert beispiellose Trainingsdaten für die Optimierung des Studiendesigns. Fusionen und Übernahmen, wie die 688-Millionen-USD-Fusion von Recursion und Exscientia, zeigen, dass etablierte Unternehmen darum wetteifern, diese KI-Vorteile zu internalisieren und Plattformen zu konsolidieren.
Ausweitung klinischer pharmakogenomischer und pharmakokinetischer Studien
Präventive pharmakogenomische Tests reduzierten psychiatrische unerwünschte Arzneimittelreaktionen um 34,1 % und Krankenhauseinweisungen um 41,2 %.[3]Maria Skokou, Konstantinos Tziomalos und Georgios Papazisis, „Klinische Implementierung präventiver Pharmakogenomik in der Psychiatrie”, eBioMedicine, thelancet.com Reale Panels zeigen, dass 60,4 % der Patienten mindestens eine umsetzbare Verschreibung erhalten. Die UCLA nutzte eine Biobank mit 342.000 Personen, um 156 Gene zu identifizieren, die die Statin-Wirksamkeit modulieren, und lieferte damit den Beweis, dass genetische Vielfalt die Dosierungsgenauigkeit verbessert. KI-gestützte PK/PD-Modelle berücksichtigen nun populationsspezifische Varianten, eine Anforderung, da die Übernahme der Pharmakogenomik im asiatisch-pazifischen Raum zunimmt.
Transformatorbasierte Genomsprachmodelle ermöglichen schnelle Annotation
Open-Source-Proteinmodelle liefern AlphaFold-ähnliche Leistung und benötigen dabei nur handelsübliche GPUs. Bidirektionale DNA-Grundlagenmodelle wie JanusDNA verarbeiten 1 Million Basenpaare ohne spezialisierte Hardware. Parametereffiziente Feinabstimmungsmethoden wie LoRA senken die Trainingskosten und erhalten oder verbessern gleichzeitig die nachgelagerte Vorhersagegenauigkeit. Diese Fortschritte demokratisieren fortgeschrittene Analysen und senken Eintrittsbarrieren, wodurch der Markt für Computationale Biologie weit über traditionelle Bioinformatikzentren hinaus ausgedehnt wird.
Analyse der Hemmnisauswirkungen*
| Hemmnis | (~) % Auswirkung auf die CAGR-Prognose | Geografische Relevanz | Zeithorizont der Auswirkung |
|---|---|---|---|
| Mangel an multidisziplinären Fachkräften | -1.8% | Global, akut in Nordamerika und der EU | Kurzfristig (≤ 2 Jahre) |
| Interoperabilitäts- und Datenstandardisierungslücken | -1.2% | Global, insbesondere bei grenzüberschreitenden Kooperationen | Mittelfristig (2–4 Jahre) |
| Steigende Cloud- und Rechenkosten | -0.9% | Global, stärkste Auswirkung in kostenempfindlichen Märkten | Kurzfristig (≤ 2 Jahre) |
| Biosicherheits- und Dual-Use-Regulierungsüberprüfung | -0.7% | Hauptsächlich Nordamerika und EU, weltweite Ausweitung | Langfristig (≥ 4 Jahre) |
| Quelle: Mordor Intelligence | |||
Mangel an multidisziplinären Fachkräften
Die Nachfrage nach Fachleuten mit Kenntnissen in Biologie, Softwareentwicklung und Statistik übersteigt das Angebot. Arbeitgeber in den Biowissenschaften rechnen bis 2030 mit einem Fehlbestand von 35 %, wobei die Einstellungsnachfrage voraussichtlich mit einer jährlichen Rate von 11,75 % wachsen wird. Gehaltsinflation und Projektverzögerungen sind die Folge, insbesondere für mittelgroße Biotechnologieunternehmen, die mit Technologiegiganten konkurrieren, die in das Feld eintreten. Kompetenzbasierte Einstellung, Ausbildungsprogramme und branchenübergreifende Rekrutierung sind vorübergehende Abhilfestrategien.
Interoperabilitäts- und Datenstandardisierungslücken
Während Matrix- und Analyse-Metadatenstandards (MAMS) beginnen, Einzelzell-Datensätze anzugleichen, bleibt eine breite Harmonisierung schwer erreichbar. Semantische Zuordnungswerkzeuge können unstrukturierte Gesundheitsakten integrieren; jedoch verlangsamen Implementierungsaufwände ihre Übernahme. Föderierte Lernpiloten schützen die Privatsphäre, stehen aber weiterhin vor regulatorischer Unsicherheit, sodass multinationale Studien auf manuelle Datenbereinigung angewiesen sind.
*Unsere Prognosen behandeln die Auswirkungen von Treibern und Einschränkungen als richtungsweisend und nicht additiv. Die Wirkungsprognosen berücksichtigen Basiswachstum, Mischungseffekte und Wechselwirkungen zwischen Variablen.
Segmentanalyse
Nach Anwendung: Wirkstoffforschung und Krankheitsmodellierung treiben Workflows der nächsten Generation an
Wirkstoffforschung und Krankheitsmodellierung verzeichnen bereits die schnellste CAGR von 15,33 %, während zelluläre und biologische Simulation bis 2025 einen Anteil von 32,10 % an der Marktgröße der Computationalen Biologie hielt. KI-gestützte Zielidentifikation und Lead-Optimierung ermöglichen es Unternehmen wie Insilico Medicine, Millionen von Verbindungen in silico zu screenen. Präklinische Teams integrieren nun genomische, proteomische und metabolomische Datensätze, um die Erfolgswahrscheinlichkeit von der Verbindung bis zur Klinik zu erhöhen. Klinische Studienoperationen nutzen retrieval-augmentierte Systeme, die eine Genauigkeit von 97,9 % bei der Eignungsüberprüfung erreichen und damit Rekrutierungsengpässe reduzieren. Eine wachsende Zahl von Forschern nutzt digitale Zwillinge für virtuelle Dosis-Wirkungs-Studien und verkürzt damit die Nasslab-Zeitpläne. Folglich erlebt der Markt für Computationale Biologie ein tieferes pharmazeutisches Engagement in jeder Phase der Forschung und Entwicklung.
Simulationssoftware für den menschlichen Körper entwickelt sich zu einem hochpotentiellen Teilsegment. Stanfords KI-gestützte „virtuelle Zelle” veranschaulicht, wie integrierte Multi-Omics- und biophysikalische Modelle Signalwegstörungen für individualisierte Therapiestrategien kartieren können. Diese Entwicklung erweitert den Markt für Computationale Biologie auf Kliniker der Präzisionsmedizin an vorderster Front. Da die Genauigkeit digitaler Zwillinge zunimmt, beginnen Versicherer, Erstattungsmodelle für computeroptimierte Behandlungspläne zu evaluieren, was auf potenzielle Möglichkeiten für nachgelagerte Einnahmequellen hinweist.




Nach Werkzeug: Analysesoftware beschleunigt die KI-Integration
Datenbanken machen weiterhin 35,95 % des Marktanteils der Computationalen Biologie aus, aber Analysesoftware und -dienstleistungen verzeichnen das schnellste Wachstum mit einer CAGR von 14,49 %. Protein- und Genomsprachmodelle veranlassen Organisationen, in analytische Kapazitäten zu investieren, anstatt statische Archive zu pflegen. Anbieter integrieren multimodale Datenpipelines, die genomische, proteomische und klinische Datenströme zusammenführen. Die Verlagerung fördert auch akademisch-industrielle Konsortien zur gemeinsamen Entwicklung von Open-Source-Stacks; Boltz-1's AlphaFold-vergleichbare Genauigkeit auf Standard-GPUs unterstreicht, wie Community-Innovation eine breitere Übernahme fördert.
Lokale Hochleistungsrechner bleiben wichtig für die Verarbeitung sensibler Datensätze; jedoch fördern Cloud-Kostenkurven und die Reife verwalteter Dienste die Migration. Anbieter differenzieren sich durch automatische Skalierungsalgorithmen und Sicherheitszertifizierungen. Datenbankinhaber reagieren, indem sie Analyseebenen auf Repositorien aufbauen, um ihre installierte Basis zu verteidigen. Der Nettoeffekt erhöht den Wettbewerb, hebt aber die Gesamtsoftwarequalität an und unterstützt ein nachhaltiges Wachstum im Markt für Computationale Biologie.
Nach Dienstleistung: Auftragsmodelle dominieren das Wachstum
Auftragsforschungsdienstleistungen führen sowohl bei Anteil als auch bei Dynamik – 52,05 % im Jahr 2025 und eine CAGR-Prognose von 15,72 % –, da Pharmaunternehmen komplexe In-silico-Workflows auslagern. Auftragsforschungsorganisationen bündeln nun Genomanalyse, KI-Modellentwicklung und virtuelles Screening in einheitlichen Abonnements. Interne Teams behalten kernige, IP-intensive Algorithmen, arbeiten aber extern für rechenintensive Simulationen zusammen.
Hybride Dienstleistungsrahmen gewinnen an Bedeutung. Unternehmen pflegen Datenverwaltungsknoten vor Ort und nutzen gleichzeitig Cloud-basierte Auftragsforschungsplattformen für Spitzenlasten. Strategische Allianzen verteilen das Risiko: Kunden zahlen nutzungsbasierte Gebühren, während Anbieter Service-Level-Vereinbarungen garantieren, die regulatorische Unterstützung umfassen. Mit zunehmender Übernahme integriert sich der Markt für Computationale Biologie weiter in traditionelle Wertschöpfungsketten der Arzneimittelentwicklung.
Nach Endnutzer: Industrielle Übernahme beschleunigt sich
Die Wissenschaft kontrollierte im Jahr 2025 44,10 % des Umsatzes, doch Industrienutzer gewannen mit einer CAGR von 14,27 % bis 2031 an Dynamik. Sinkende Sequenzierungskosten, validierte KI-Pipelines und dringende therapeutische Zeitpläne treiben die pharmazeutische Übernahme voran. Unternehmenskäufer suchen schlüsselfertige Lösungen, die Prüfpfade einbetten und GxP-Vorschriften entsprechen.
Akademische Einrichtungen bleiben Wissensmotoren und entwickeln Algorithmen, die später kommerziell lizenziert werden. Um Budgetbeschränkungen entgegenzuwirken, erweitern Universitäten Partnerschaftsmodelle, bei denen Technologieanbieter Rechenkapazitätsguthaben im Austausch für Mitautorenschaft und frühen Zugang zu Feedback bereitstellen. Diese Symbiose erhält Innovationstrichter für die Branche der Computationalen Biologie aufrecht.
Geografische Analyse
Nordamerika, das im Jahr 2025 42,30 % des Umsatzes auf sich vereint, profitiert von tiefem Biotechnologie-Risikokapital, ausgereiftem Regulierungsengagement und einem dichten Talentpool. Der sich entwickelnde KI-Rahmen der FDA bietet lokalen Unternehmen einen unkomplizierteren Kommerzialisierungsweg als vielen ihrer Mitbewerber. Thermo Fishers 2-Milliarden-USD-Mehrjahresinvestition im Inland unterstreicht das Vertrauen in die Infrastrukturskalierbarkeit; dennoch dämpfen Arbeitskräftemangel und steigende Cloud-Kosten die Beschleunigung.
Der asiatisch-pazifische Raum verzeichnet die höchste CAGR von 16,02 %. Regierungen finanzieren Exaflop-Supercomputer – Südkoreas Plan zielt auf eine Inbetriebnahme bis 2025 ab –, während Chinas verteilte nationale Zentren bereits Multi-Omics-Projekte vorantreiben. Die regionale pharmazeutische Fertigung boomt, und genetische Diversitätsforschungsprogramme passen KI-Modelle an lokale Bevölkerungen an und schaffen Randdaten-Assets, die anderswo nicht verfügbar sind. Dezentralisierte klinische Studien-Piloten und der Aufbau von mRNA-Plattformen stärken die langfristige Nachfrage nach Fähigkeiten im Markt für Computationale Biologie.
Europa verzeichnet ein stetiges Wachstum, verankert durch grenzüberschreitende Konsortien und robuste Datenschutzmaßnahmen. Ethische KI-Initiativen erhöhen den Compliance-Aufwand, fördern aber auch das Vertrauen bei Kostenträgern und Regulierungsbehörden. Digitale Zwillings-Piloten richten sich an öffentlichen Gesundheitszielen zur Optimierung der Ressourcennutzung aus. Unterdessen machen Lateinamerika, Afrika und der Nahe Osten Fortschritte, da die Internetinfrastruktur und bioinformatische Lehrpläne expandieren. Partnerschaften mit multinationalen Pharmagruppen kompensieren lokale Finanzierungslücken und gewährleisten eine schrittweise, aber beständige Marktdurchdringung in der Computationalen Biologie.

Wettbewerbslandschaft
Der Markt für Computationale Biologie bleibt mäßig fragmentiert, zeigt aber einen klaren Trend zu Fusionen und Übernahmen. Siemens' 5,1-Milliarden-USD-Übernahme von Dotmatics integriert Labor-Informatik mit industriellen Angeboten für digitale Zwillinge und spiegelt den Wunsch der Käufer nach End-to-End-Stacks wider. Danaher hat Genedata in sein Portfolio aufgenommen und folgt damit derselben Logik. Illumina arbeitet mit NVIDIA zusammen, um GPU-gestützte Omics-Analysen zu beschleunigen – ein Beispiel für die Konvergenz von Technologie und Biotechnologie.
Start-ups nutzen Open-Source-Gemeinschaften, um über ihre Gewichtsklasse hinaus zu agieren. EvolutionaryScale sammelte 142 Millionen USD ein, um proteingenerierendeKI zu kommerzialisieren, die direkt mit den proprietären Chemien der etablierten Unternehmen konkurriert. Patentanmeldungen rund um hybride Quanten-klassische Modelle und Abstammungsverfolgungsalgorithmen deuten auf eine Intensivierung von IP-Kämpfen hin. Der Wettbewerbserfolg wird vom Zugang zu kuratierten Datensätzen, skalierbaren Rechenkapazitäten und integrierten Workflows abhängen, die die Wechselkosten minimieren.
Große Anbieter verfolgen Ökosystem-Lock-in durch Abonnementlizenzierung und Datennetzwerkeffekte. Mittelgroße Akteure differenzieren sich durch vertikale Spezialisierung – Einzelzellanalysen, Engines für digitale Zwillinge oder pharmakogenomische Toolkits. Der Preiswettbewerb ist gedämpft, da Genauigkeit, regulatorische Compliance und Durchlaufgeschwindigkeit entscheidende Kaufkriterien bleiben.
Marktführer der Computationalen Biologie
Dassault Systèmes SE
Schrödinger Inc.
Certara
Simulation Plus Inc.
Illumina Inc.
- *Haftungsausschluss: Hauptakteure in keiner bestimmten Reihenfolge sortiert

Jüngste Branchenentwicklungen
- Juni 2025: Illumina erwarb SomaLogic für bis zu 425 Millionen USD, um Proteomik- und Biomarkerfähigkeiten zu erweitern und sein Multi-Omics-Portfolio zu vergrößern.
- April 2025: Siemens schloss die 5,1-Milliarden-USD-Übernahme von Dotmatics ab und fusionierte F&E-Informatik mit industriellen Rahmenwerken für digitale Zwillinge.
- Februar 2025: Illumina veröffentlichte konstellationskartierte Reads und 5-Basen-Sequenzierungslösungen, die für den kommerziellen Rollout im Jahr 2026 vorgesehen sind.
- Januar 2025: Illumina ging eine Partnerschaft mit NVIDIA ein, um Multi-Omics-Datenpipelines mithilfe von GPUs zu beschleunigen und eine schnellere therapeutische Entdeckung anzustreben.


Rahmen der Forschungsmethodik und Umfang des Berichts
Marktdefinitionen und wesentliche Abdeckung
Unsere Studie definiert den Markt für Computational Biology als alle Software-Plattformen, Infrastruktur-Tools und spezialisierten Datenbanken, die mathematische Modellierung, Datenanalytik und Simulationstechniken einsetzen, um biologische, chemische und klinische Datensätze in den Bereichen Wirkstoffforschung, Krankheitsmodellierung, Genomik und Proteomik-Workflows zu untersuchen. Gemäß Mordor Intelligence werden Umsätze an dem Punkt erfasst, an dem ein Anbieter eine Lösung oder Dienstleistung an einen Endnutzer lizenziert oder bereitstellt, unabhängig vom Hosting-Modell oder der kommerziellen Stufe.
Ausschluss aus dem Geltungsbereich: Akademische Freeware und Open-Source-Codes, die ohne monetisierten Support vertrieben werden, werden nicht berücksichtigt.
Segmentierungsübersicht
- Nach Anwendung
- Zelluläre und Biologische Simulation
- Computergestützte Genomik
- Computergestützte Proteomik
- Pharmakogenomik
- Sonstige Simulationen (Transkriptomik/Metabolomik)
- Wirkstoffforschung und Krankheitsmodellierung
- Zielidentifikation
- Zielvalidierung
- Lead-Entdeckung
- Lead-Optimierung
- Präklinische Wirkstoffentwicklung
- Pharmakokinetik
- Pharmakodynamik
- Klinische Studien
- Phase I
- Phase II
- Phase III
- Simulationssoftware für den menschlichen Körper
- Zelluläre und Biologische Simulation
- Nach Werkzeug
- Datenbanken
- Infrastruktur (Hardware)
- Analysesoftware und -dienstleistungen
- Nach Dienstleistung
- Intern
- Auftrag
- Nach Endnutzer
- Wissenschaft
- Industrie und Gewerbe
- Nach Geografie
- Nordamerika
- Vereinigte Staaten
- Kanada
- Mexiko
- Europa
- Deutschland
- Vereinigtes Königreich
- Frankreich
- Italien
- Spanien
- Übriges Europa
- Asiatisch-pazifischer Raum
- China
- Japan
- Indien
- Australien
- Südkorea
- Übriger asiatisch-pazifischer Raum
- Naher Osten und Afrika
- Golfkooperationsrat
- Südafrika
- Übriger Naher Osten und Afrika
- Südamerika
- Brasilien
- Argentinien
- Übriges Südamerika
- Nordamerika
Detaillierte Forschungsmethodik und Datenvalidierung
Primärforschung
Mordor-Analysten führten anschließend Interviews mit Software-Architekten, CRO-Bioinformatikern, Leitern akademischer Kerneinrichtungen und Beschaffungsverantwortlichen in Nordamerika, Europa und wichtigen Zentren im asiatisch-pazifischen Raum. Die Gespräche validierten Ausgabenbereiche, typische Preispunkte, Adoptionskurven für Hochleistungsrechen-Cluster und aufkommende KI-gestützte Workflows, was es uns ermöglichte, Modellannahmen zu verfeinern, die sekundäre Quellen nicht quantifizieren konnten.
Desk Research
Wir haben zunächst das Universum der adressierbaren Ausgaben durch öffentliche Quellen wie Haushaltspläne des US-amerikanischen NIH, klinische Studienregister der FDA, Eurostat-Dateien zu F&E-Ausgaben, Projektkataloge des chinesischen Ministeriums für Wissenschaft sowie Patentanzahlen der Questel-Plattform kartiert. Diese legen fest, wie viel geförderte Forschung in eine bezahlte Nachfrage nach Computational Tools umgewandelt werden könnte. Ergänzende Eingaben stammten aus 10-K-Berichten von Unternehmen, Investorenpräsentationen, auf PubMed indizierten, von Fachleuten begutachteten Zeitschriften, Verbandsportalen wie der International Society for Computational Biology sowie kuratierten Nachrichtenströmen, die über Dow Jones Factiva abgerufen wurden. Die Desk-Recherche bildete ein sachliches Grundgerüst und hob gleichzeitig Datenlücken hervor, die eine direkte Kontaktaufnahme erforderten. Diese Liste ist illustrativ; viele weitere Referenzen flossen in Zwischenprüfungen und Klärungen ein.
Marktgröße & Prognose
Ein Top-down-Konstrukt, das auf öffentlich bekannt gegebenen F&E-Ausgaben der Biowissenschaften, Sequenzierungsvolumina der nächsten Generation und vorherrschenden Lizenz-Penetrationsraten basiert, legt den Ausgangswert für 2025 fest. Anbieter-Rollups aus Stichproben-Durchschnittsverkaufspreisen multipliziert mit der installierten Basis, Channel-Checks zu Cloud-Nutzungsgebühren und Importstatistiken für dedizierte Hardware dienen als selektive Bottom-up-Spiegel zur Abstimmung der Gesamtwerte. Zu den erfassten Kernvariablen gehören: a) geförderte Genomik-Projekte, b) Trends bei den Kosten pro Genom, c) durchschnittliche Rechenstunden pro In-silico-Experiment, d) Anzahl der Biologika-Pipelines, e) Ankündigungen öffentlich-privater KI-Partnerschaften und f) Server-GPU-Lieferungen an BioPharma-Cluster. Prognosen verwenden multivariate Regression kombiniert mit Szenarioanalysen, wobei die Gewichtungen einem Stresstest anhand des Expertenkonsenses unterzogen werden, bevor der Fünfjahresausblick festgelegt wird. Verbleibende Lücken in den Anbieterdaten werden durch konservative Interpolation mithilfe regionsspezifischer Nutzungskoeffizienten überbrückt.
Datenvalidierung & Aktualisierungszyklus
Die Ergebnisse durchlaufen eine dreistufige Prüfung: Varianzprüfungen gegenüber historischen Reihen, Quervergleiche mit alternativen Datensignalen und Prüfungen durch leitende Analysten. Das Modell wird jährlich aktualisiert, und eine Zwischenüberprüfung wird ausgelöst, wenn Finanzierungsschocks, bedeutende M&A-Aktivitäten oder disruptive regulatorische Änderungen eintreten; eine abschließende Überprüfung vor der Veröffentlichung stellt sicher, dass Kunden stets die aktuellste Sichtweise erhalten.
Warum Mordors Computational-Biology-Baseline Vertrauen verdient
Veröffentlichte Schätzungen weichen häufig voneinander ab, weil Unternehmen den Markt unterschiedlich abgrenzen, Währungen auf Basis verschiedener Basisjahre umrechnen oder ungeprüfte Wachstumsprämien einbeziehen.
Zu den wesentlichen Treibern dieser Lücken zählen, ob kostenlose akademische Software berücksichtigt wird, wie hybride Cloud-Abonnements annualisiert werden und ob in größere Bioinformatik-Suiten gebündelte Tools einzeln ausgewiesen werden. Mordors Geltungsbereich schließt nicht-monetisierte Freeware aus, wendet eine transparente Währungsbasis für 2025 an und überprüft die Adoptionsraten alle zwölf Monate neu, um Über- oder Unterschätzungen zu vermeiden, die entstehen können, wenn Aktualisierungszyklen länger werden.
Benchmark-Vergleich
| Marktgröße | Anonymisierte Quelle | Primärer Lückentreiber |
|---|---|---|
| USD 7,24 Mrd. (2025) | Mordor Intelligence | - |
| USD 5,90 Mrd. (2024) | Global Consultancy A | Berücksichtigt nur Software-Plattformumsätze; lässt Infrastruktur- und Datenbankebenen außer Acht |
| USD 7,18 Mrd. (2025) | Industry Association B | Zählt einige staatlich geförderte Open-Source-Projekte als bezahlte Äquivalente |
| USD 9,13 Mrd. (2025) | Regional Consultancy C | Aggregiert angrenzende Bioinformatik-Dienstleistungen und erhöht dadurch den Gesamtwert |
Zusammenfassend lässt sich sagen, dass die disziplinierte Geltungsbereichsdefinition, die zweifach geprüften Variablen und der zeitnahe Aktualisierungszyklus von Mordor Intelligence Entscheidungsträgern eine ausgewogene, nachvollziehbare Baseline liefern, die sowohl optimistische Überschätzungen als auch konservative Unterschätzungen vermeidet, wie sie andernorts häufig vorkommen.


Im Bericht beantwortete Schlüsselfragen
Wie groß ist der aktuelle Markt für Computationale Biologie?
Der Markt für Computationale Biologie generiert im Jahr 2026 einen Umsatz von 8,17 Milliarden USD und ist auf dem Weg, bis 2031 einen Wert von 14,89 Milliarden USD zu erreichen.
Welcher Anwendungsbereich wächst am schnellsten?
Wirkstoffforschung und Krankheitsmodellierung verzeichnet bis 2031 die höchste CAGR von 15,33 %, angetrieben durch KI-gestützte Zielidentifikation und Workflows mit digitalen Zwillingen.
Warum wachsen Auftragsforschungsdienstleistungen so schnell?
Pharmaunternehmen lagern datenintensive Modellierung an spezialisierte Auftragsforschungsorganisationen aus, was Auftragsdienstleistungen einen Anteil von 52,05 % und eine Wachstumsrate von 15,72 % beschert.
Welche Region wird am meisten zum zukünftigen Wachstum beitragen?
Der asiatisch-pazifische Raum führt mit einer CAGR von 16,02 % dank staatlicher Supercomputer-Projekte und einer rasch expandierenden pharmazeutischen Fertigung.
Was hindert eine breitere Übernahme von Plattformen der Computationalen Biologie?
Ein Mangel an multidisziplinären Fachkräften, steigende Cloud-Rechenkosten und sich entwickelnde Biosicherheitsvorschriften sind die wesentlichen Einschränkungen.
Seite zuletzt aktualisiert am:




