Tamanho e Participação do Mercado de Infraestrutura de IA
Visão Geral do Mercado
| Período de Estudo | 2020 - 2031 |
|---|---|
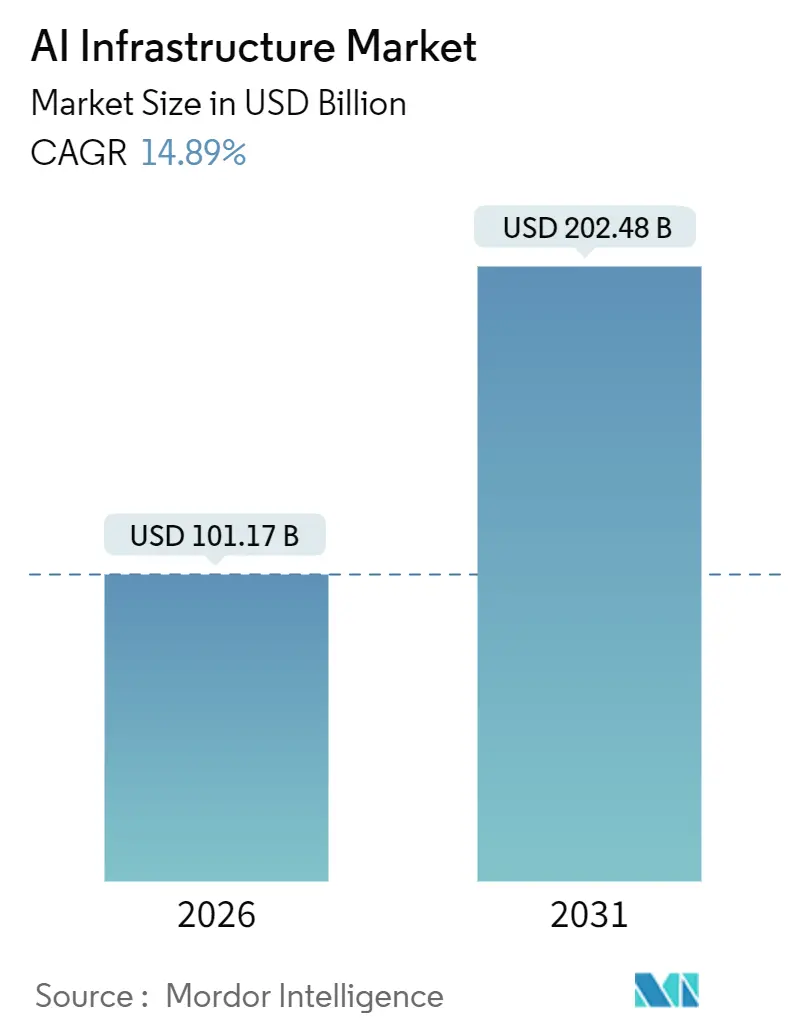
| Tamanho do Mercado (2026) | 101.17 Bilhões de dólares |
| Tamanho do Mercado (2031) | 202.48 Bilhões de dólares |
| Taxa de crescimento (2026 - 2031) | 14.89% CAGR |
| Mercado de Crescimento Mais Rápido | Ásia-Pacífico |
| Maior Mercado | América do Norte |
| Concentração do Mercado | Médio |
Principais jogadores *Isenção de responsabilidade: Principais participantes classificados em nenhuma ordem específica Imagem © Mordor Intelligence. O reuso requer atribuição conforme CC BY 4.0. | |
Análise do Mercado de Infraestrutura de IA por Mordor Intelligence
Análise de Mercado
O tamanho do mercado de infraestrutura de IA atingiu USD 101,17 bilhões em 2026 e está projetado para alcançar USD 202,48 bilhões até 2031, refletindo uma CAGR de 14,89% ao longo do período de previsão. A expansão está alinhada com alocações sustentadas para cargas de trabalho intensivas em computação, contínuos influxos de subsídios para fábricas de semicondutores avançados e um prêmio persistente sobre memória de alta largura de banda que prolonga os prazos de entrega para GPUs de alto nível. A crescente adoção de resfriamento líquido mitiga racks que agora superam 100 quilowatts, enquanto os controles de exportação promulgados pelos Estados Unidos em 2023 aceleram projetos soberanos de IA no Oriente Médio e na Ásia-Pacífico. A política de semicondutores tornou-se um catalisador de crescimento, pois os incentivos do tipo CHIPS sustentam as expansões de fábricas nos Estados Unidos, na Europa e no Japão. Os hiperscalers, enfrentando atrasos de vários anos para os aceleradores NVIDIA H100 e H200, responderam pré-encomendando dispositivos de próxima geração e projetando ASICs personalizados para garantir capacidade.
Principais Conclusões do Relatório
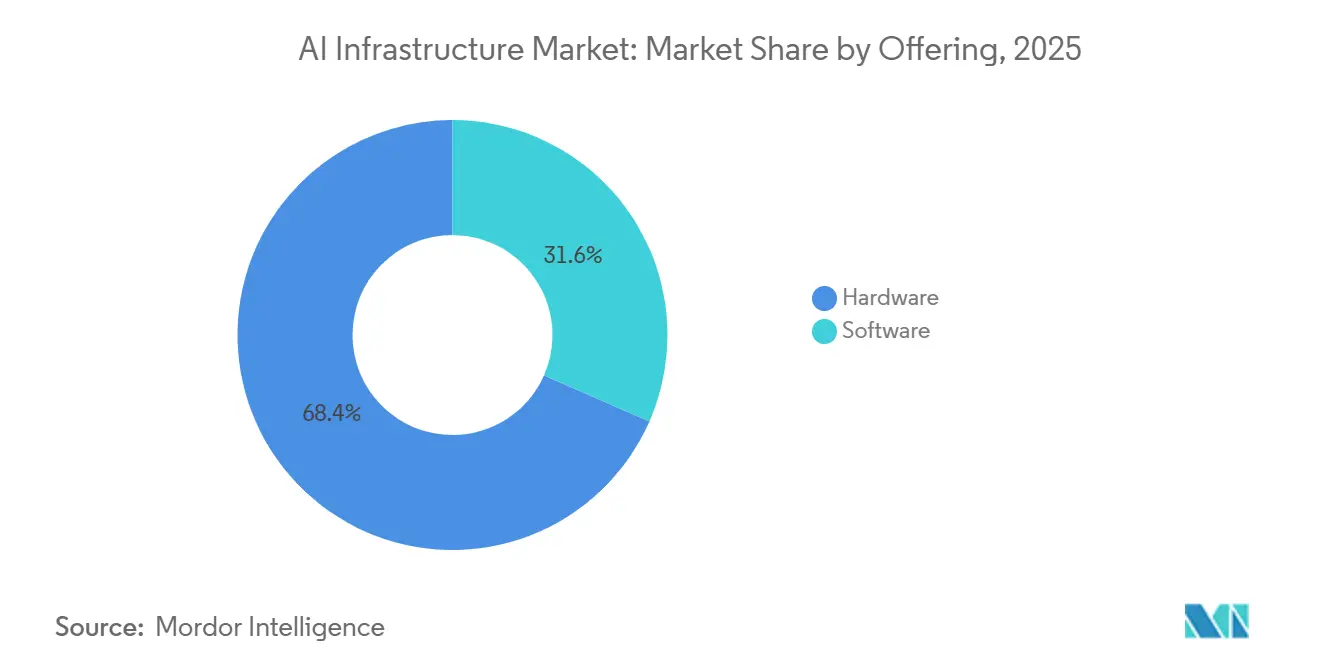
- Por oferta, o hardware liderou com 68,42% da receita em 2025; o segmento de software deve expandir-se a uma CAGR de 16,02% até 2031.
- Por implantação, as arquiteturas locais detinham 57,46% da participação do mercado de infraestrutura de IA em 2025, enquanto as implantações em nuvem estão projetadas para avançar a uma CAGR de 15,76% até 2031.
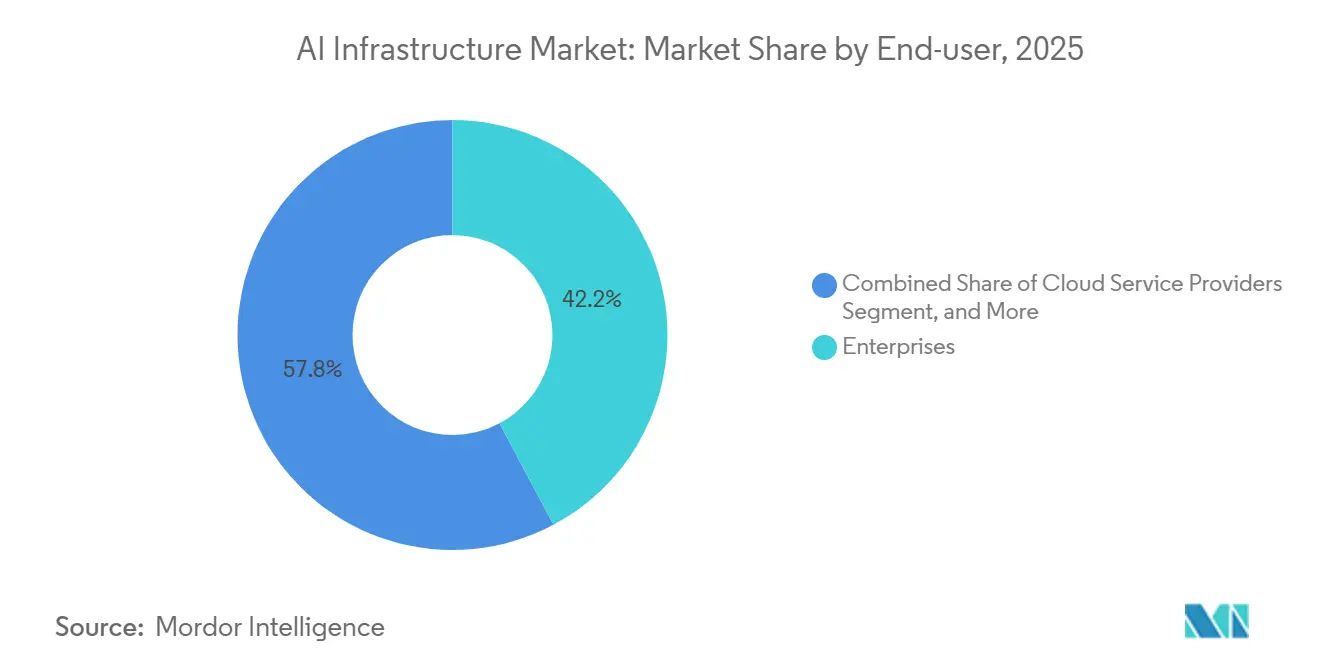
- Por usuário final, as empresas comandavam 42,22% da participação do tamanho do mercado de infraestrutura de IA em 2025; os provedores de serviços em nuvem representam o segmento de crescimento mais rápido, a uma CAGR de 15,24% até 2031.
- Por arquitetura de processador, as GPUs retiveram 88,82% da receita em 2025, enquanto as alternativas FPGA e ASIC estão preparadas para crescer a uma CAGR de 16,89% até 2031.
- Por geografia, a América do Norte representou 39,56% da receita de 2025; espera-se que a Ásia-Pacífico expanda-se a uma CAGR de 16,44% entre 2026-2031.
Nota: O tamanho do mercado e os números de previsão neste relatório são gerados usando a estrutura de estimativa proprietária da Mordor Intelligence, atualizada com os dados e percepções mais recentes disponíveis em janeiro de 2026.
Tendências e Perspectivas do Mercado Global de Infraestrutura de IA
Análise de Impacto dos Fatores Impulsionadores*
| Fator Impulsionador | (~) % de Impacto na Previsão de CAGR | Relevância Geográfica | Prazo de Impacto |
|---|---|---|---|
| Atrasos elevados nas GPUs H100 e H200 | +3.2% | Global, concentrado na América do Norte e Ásia-Pacífico | Médio prazo (2-4 anos) |
| Tecidos de rede específicos para IA de rápida adoção | +2.8% | Global, adoção inicial na América do Norte e Europa | Médio prazo (2-4 anos) |
| Adoção de resfriamento líquido com eficiência energética | +2.1% | Global, liderado pela América do Norte e Europa | Longo prazo (≥ 4 anos) |
| Subsídios governamentais do tipo CHIPS para fábricas de IA | +2.5% | América do Norte, Europa, Ásia-Pacífico | Longo prazo (≥ 4 anos) |
| Instâncias de aceleradores de IA nativos de nuvem | +2.4% | Global, mais forte na América do Norte e Ásia-Pacífico | Curto prazo (≤ 2 anos) |
| Otimização de frameworks de IA de código aberto | +1.9% | Global | Médio prazo (2-4 anos) |
| Fonte: Mordor Intelligence | |||
Atrasos Elevados nas GPUs H100 e H200 entre Hiperscalers
A NVIDIA relatou que os pré-pedidos de 2025 para dispositivos H100 e H200 triplicaram a oferta disponível, levando a Microsoft a reservar USD 80 bilhões para alocações plurianuais e a AWS a expandir seu orçamento de infraestrutura em USD 100 bilhões até 2028.[1]Microsoft Communications, "Microsoft Announces USD 80 Billion AI Datacenter Investment," Microsoft, microsoft.com Os gargalos de memória de alta largura de banda intensificaram o desequilíbrio, já que a SK Hynix e a Samsung controlavam 95% da produção de HBM3E. Os hiperscalers agora co-projetam o empacotamento de memória diretamente com as fábricas, enfraquecendo o poder de negociação dos fornecedores tradicionais de GPU. A capacidade de 3 nanômetros da TSMC permaneceu sobrecarregada, estendendo os prazos de entrega de dispositivos além de 12 meses e acelerando uma mudança em direção a ASICs personalizados, como o Google TPU v6e. As empresas, enfrentando cronogramas de entrega imprevisíveis, recorrem cada vez mais ao aluguel de instâncias garantidas de provedores de nuvem, mesmo quando os preços sob demanda excedem USD 30 por hora para pacotes de oito GPUs.
Tecidos de Rede Específicos para IA de Rápida Adoção (InfiniBand NDR, Ethernet 800G)
O InfiniBand NDR operava a 400 Gbps e conectava cerca de 70% dos clusters de treinamento de IA em 2025, oferecendo latência 40% menor do que a Ethernet tradicional.[2]NVIDIA Networking Team, "InfiniBand Solutions," nvidia.com Os hiperscalers, no entanto, começaram a avaliar Ethernet de 800 Gbps à medida que o Tomahawk 5 e o Spectrum-X da Broadcom comutavam o tráfego com latências competitivas e uma redução de 25% no custo de capital. A Meta validou o desempenho da Ethernet escalando seu Supercluster de Pesquisa de IA com 10.000 GPUs em links de 800 Gbps, ampliando a escolha de fornecedores e corroendo o aprisionamento ao InfiniBand. O trabalho do IEEE 802.3df em Ethernet de 1,6 Tbps continua, sinalizando maior convergência entre cargas de trabalho de IA e de centros de dados convencionais.
Adoção de Resfriamento Líquido com Eficiência Energética
A penetração do resfriamento líquido aumentou para 18% dos racks de IA em 2025, à medida que as densidades de energia ultrapassaram 100 quilowatts, um limiar em que os sistemas de ar têm dificuldade para remover o calor. As soluções diretas ao chip reduziram o consumo de energia das instalações em até 40% e liberaram 60% do espaço de chão em comparação com os equivalentes resfriados a ar. A Microsoft pilotou banhos de imersão monofásicos que reduziram os custos de infraestrutura de resfriamento em 45% e pretende implementar a abordagem em campi hiperscale a partir de 2026. Os incentivos regulatórios na União Europeia, incluindo os iminentes mecanismos de precificação de carbono, reforçam a adoção, enquanto as implantações na Ásia-Pacífico ficam atrás devido às tarifas de eletricidade mais baixas.
Subsídios Governamentais do Tipo CHIPS para Fábricas de IA
Os Estados Unidos alocaram USD 52,7 bilhões para a fabricação doméstica de semicondutores, desembolsando USD 8,5 bilhões para a Intel, USD 6,6 bilhões para a TSMC e USD 6,4 bilhões para a Samsung. A Europa aprovou sua Lei de Chips no valor de EUR 43 bilhões (USD 47 bilhões) para dobrar a produção regional de wafers até 2030. O Japão reservou JPY 2 trilhões (USD 13,5 bilhões) para apoiar a planta de Kumamoto da TSMC e um roteiro de 2 nanômetros liderado pela Rapidus. Os subsídios aceleram a capacidade de empacotamento avançado e reduzem o risco de concentração geopolítica em Taiwan, porém a Associação da Indústria de Semicondutores projeta uma lacuna de 67.000 profissionais que pode atrasar a plena utilização.
Análise de Impacto das Restrições*
| Restrição | (~) % de Impacto na Previsão de CAGR | Relevância Geográfica | Prazo de Impacto |
|---|---|---|---|
| GPUs de classe IA em escassez crônica até 2026 | -2.8% | Global, aguda na Ásia-Pacífico e Europa | Curto prazo (≤ 2 anos) |
| Limites de conversão de energia de 400 V e 48 V em instalações legadas | -1.9% | Global, concentrado na América do Norte e Europa | Médio prazo (2-4 anos) |
| Controles de exportação de IA soberana | -2.3% | Global, mais grave na Ásia-Pacífico | Longo prazo (≥ 4 anos) |
| Custos crescentes de conformidade com emissões de Escopo 2 | -1.6% | Europa, emergindo na América do Norte | Médio prazo (2-4 anos) |
| Fonte: Mordor Intelligence | |||
GPUs de Classe IA em Escassez Crônica até 2026
Os prazos de entrega para os cartões H200 se estenderam além de 52 semanas em 2025, enquanto o atraso do MI300X da AMD espelhava a restrição.[3]Reuters Staff, "NVIDIA AI Chip Orders Exceed Supply, Lead Times Stretch," Reuters, reuters.com A capacidade de empacotamento CoWoS da TSMC atingiu 35.000 inícios de wafer por mês, muito abaixo das estimativas de demanda acima de 100.000 equivalentes. A memória de alta largura de banda permanece escassa porque cada dispositivo H100 necessita de 80 GB de HBM3 empilhado em cinco camadas. As empresas, consequentemente, adiaram implantações em grande escala e repriorizaram arquiteturas de modelos que requerem menos parâmetros. As plataformas em nuvem responderam com superprovisionamento de estoque, queda nas taxas de utilização e cobrança de preços spot elevados, uma tática que distorce os sinais de oferta e suprime a adoção do mercado no curto prazo.
Controles de Exportação de IA Soberana
As regulamentações de outubro de 2023 proibiram o envio não licenciado dos dispositivos A100, H100 e H800 da NVIDIA para a China. A China respondeu com um programa de chips de USD 50 bilhões, e o Ascend 910C da Huawei alcançou paridade com o A100 em alguns testes de inferência em 2025. A Lei de IA da União Europeia adiciona EUR 5-15 milhões (USD 5,5-16,5 milhões) em custos de conformidade por implantação transfronteiriça. Padrões divergentes arriscam um ecossistema bifurcado e elevam os custos de migração para empresas internacionais.
*Nossas previsões tratam os impactos dos impulsionadores e restrições como direcionais, e não aditivos. As previsões de impacto refletem o crescimento de base, os efeitos de composição e as interações entre variáveis.
Análise de Segmentos
Por Oferta: O Software Ganha Espaço à Medida que a Otimização de Inferência Supera o Processamento Bruto
O hardware comandou 68,42% dos gastos de 2025, refletindo clusters de GPU intensivos em capital, memória de alta largura de banda e tecidos NVMe que impulsionam as densidades de rack além de 100 quilowatts. O software está projetado para crescer a uma CAGR de 16,02% até 2031, à medida que as empresas enfatizam a eficiência de inferência, a observabilidade de modelos e a automação de MLOps. Ferramentas como o Triton Inference Server comprimem a latência em até 50% por meio de quantização e fusão de kernel. Os fornecedores de sistemas agora agrupam frameworks de orquestração com painéis de observabilidade, convertendo licenças únicas em assinaturas. O tamanho do mercado de infraestrutura de IA atribuído ao software está, portanto, expandindo-se mais rapidamente do que o investimento de capital em GPU, mesmo que os gastos absolutos em aceleradores permaneçam maiores. As cargas de trabalho de treinamento permanecerão centradas em GPU, mas a inferência já está se movendo em direção a ASICs construídos para fins específicos que reduzem o custo total de propriedade para pipelines de produção. As empresas que obtêm alívio de custos redirecionam os orçamentos liberados para iniciativas de qualidade de dados e pipelines de geração aumentada por recuperação, impulsionando a adoção de middleware.
Um segundo catalisador é a ascensão das ofertas de modelo de linguagem de grande porte como serviço que incorporam salvaguardas de segurança de conteúdo e mitigação de viés. Os fornecedores que empacotam middleware com modelos pré-treinados garantem receita recorrente e aprofundam o aprisionamento do cliente. Os provedores independentes de software respondem fortalecendo as pilhas de implantação de código aberto, garantindo que o licenciamento proprietário não impeça a portabilidade do modelo. A dinâmica emergente eleva as margens brutas de software para 75%, bem acima dos níveis de revenda de hardware, sublinhando por que os investidores favorecem código em vez de silício nas rodadas de financiamento em estágio avançado. O mercado de infraestrutura de IA, portanto, passa de um ciclo de despesas de capital para um modelo misto onde a receita de assinatura estabiliza os ganhos e mitiga a volatilidade de atualização de hardware.


Por Implantação: Instâncias em Nuvem Corroem as Vantagens Locais Apesar das Preocupações com Soberania
A infraestrutura local detinha 57,46% dos gastos em 2025, impulsionada por mandatos de residência de dados e frameworks setoriais como o HIPAA. As implantações em nuvem estão previstas para crescer a uma CAGR de 15,76%, à medida que as instâncias AWS Trainium2 e Google TPU v6e oferecem desempenho de múltiplos petaflops com economia favorável. O tamanho do mercado de infraestrutura de IA associado às ofertas em nuvem está, portanto, expandindo-se mais rapidamente do que o capex empresarial, especialmente à medida que os hiperscalers padronizam a precificação por inferência. As instituições financeiras que antes insistiam em hospedagem soberana agora pilotam enclaves de computação confidencial que mantêm as chaves de criptografia sob controle do cliente, reduzindo o atrito regulatório.
Padrões híbridos proliferam à medida que as empresas treinam modelos sensíveis localmente e depois transferem a inferência para nós de borda geográficos que reduzem a latência para os usuários finais. As iniciativas de IA soberana na Arábia Saudita e nos Emirados Árabes Unidos injetam mais de USD 140 bilhões para construir campi hiperscale domésticos, sustentando uma demanda contrária por implantações locais. Os provedores de nuvem acomodam a soberania oferecendo regiões dedicadas com redes, certificações e auditorias circunscritas jurisdicionalmente. A longo prazo, no entanto, os ciclos de obsolescência de hardware de 18 a 24 meses inclinam a curva de custos em direção à infraestrutura compartilhada, obrigando os defensores locais a adotar designs modulares que substituem placas de nó sem recabear salas inteiras.
Por Usuário Final: Provedores de Serviços em Nuvem Superam Empresas em Gastos para Garantir Vantagens Competitivas
As empresas representaram 42,22% da participação do mercado de infraestrutura de IA em 2025, refletindo casos de uso diversificados em manufatura, varejo e serviços profissionais. Os provedores de serviços em nuvem estão projetados para registrar uma CAGR de 15,24%, à medida que os hiperscalers pré-comprometem blocos multibilionários de aceleradores conectados a HBM3E. As compras em grande volume garantem preços unitários mais baixos, permitindo que os hiperscalers ofereçam clusters de treinamento burstáveis a taxas horárias ainda abaixo do custo amortizado de equivalentes de propriedade empresarial. Agências governamentais e de defesa adotam compartimentos de alto secreto com air gap que isolam cargas de trabalho classificadas, mas se beneficiam de software de gerenciamento semelhante ao de nuvem.
As empresas que avaliam entre construir ou alugar devem navegar pelo risco de capital, escassez de pessoal e incerteza de garantia. Um cluster privado de 1.000 GPUs custa de USD 15-30 milhões inicialmente e torna-se parcialmente obsoleto em dois anos, enquanto os modelos de assinatura convertem esse gasto em despesa operacional previsível. Os hiperscalers ampliam a vantagem com serviços integrados de rotulagem de dados, MLOps e ajuste fino. Os governos, no entanto, veem a soberania de IA como estratégica. O Ministério da Defesa do Japão orçou JPY 500 bilhões (USD 3,4 bilhões) para sistemas indígenas, refletindo urgência geopolítica e não apenas considerações de custo.

Por Arquitetura de Processador: Alternativas FPGA e ASIC Desafiam a Hegemonia das GPUs na Inferência
As GPUs controlavam 88,82% da receita de 2025 devido ao ecossistema CUDA consolidado e aos requisitos de paralelismo do treinamento de transformadores. Os dispositivos FPGA e ASIC estão previstos para expandir-se a uma CAGR de 16,89%, à medida que as cargas de trabalho de inferência priorizam a eficiência energética e a latência previsível. O Intel Gaudi 3 oferece 50% melhor desempenho por watt do que o H100 para inferência de transformadores, enquanto o Cerebras WSE-3 empacota 900.000 núcleos em um die de escala de wafer adequado para simulações físicas. O TPU v6e do Google já executa inferência em produção com 2,5 vezes a eficiência energética das GPUs.
O mercado de infraestrutura de IA, portanto, fragmenta-se entre GPUs de propósito geral e ASICs específicos de domínio. O silício personalizado carrega altos custos de engenharia não recorrentes, limitando a viabilidade a hiperscalers com trilhões de consultas de inferência por trimestre. Os FPGAs servem a um nicho intermediário em telecomunicações e automotivo, onde os algoritmos evoluem rapidamente e a flexibilidade de atualização em campo é crucial. Os fornecedores agora desenvolvem SoCs baseados em chiplets que se interconectam por meio de links die-a-die como UCIe, reduzindo o tempo de comercialização e permitindo atualizações incrementais de memória. A aquisição de IP de interposer pela NVIDIA e o investimento da AMD em empacotamento de chiplets sinalizam um futuro em que substratos modulares diluem a dominância de um único fornecedor.
Análise Geográfica
A América do Norte comandou 39,56% dos gastos de 2025, apoiada por USD 52,7 bilhões em subsídios da Lei CHIPS e por hiperscalers que operam cerca de 60% da capacidade global de IA. A Associação da Indústria de Semicondutores alerta para uma escassez de 67.000 trabalhadores até 2030, o que poderia desacelerar as rampas de fábricas mesmo com capital abundante. O Canadá posiciona Toronto e Montreal como centros de pesquisa apoiados por uma política de imigração favorável, enquanto as questões de confiabilidade da rede elétrica do México dificultam construções em grande escala. O Departamento de Defesa dos Estados Unidos concedeu à Amazon um contrato de nuvem de USD 50 bilhões, sublinhando que as preocupações de segurança soberana coexistem com uma mudança mais ampla em direção à computação gerenciada centralmente.
Espera-se que a Ásia-Pacífico cresça a uma CAGR de 16,44% até 2031, impulsionada pelo fundo de semicondutores de USD 50 bilhões da China e pelos compromissos de hiperscalers de USD 15 bilhões da Índia. A Alibaba implantou 100.000 aceleradores Huawei Ascend 910C em 2025, ilustrando o rápido progresso indígena apesar dos controles de exportação. O Japão alocou JPY 2 trilhões (USD 13,5 bilhões) para o local de Kumamoto da TSMC e para P&D de 2 nanômetros para reduzir a exposição geopolítica. A Coreia do Sul detém 95% da participação no fornecimento de HBM3E, um ponto de estrangulamento essencial na cadeia de fornecimento de IA. As altas tarifas de energia da Austrália limitam o hiperscale, mas Sydney e Melbourne ainda atraem operadores de colocalização em busca de conectividade resiliente com cabos submarinos.
O crescimento da Europa modera-se à medida que a conformidade com a Lei de IA adiciona EUR 5-15 milhões (USD 5,5-16,5 milhões) em custos incrementais por implantação multinacional. A Alemanha e a França lideram os subsídios para semicondutores, enquanto a Suécia aproveita o clima frio e a energia hidrelétrica para atrair hiperscalers; a Microsoft confirmou um campus em Estocolmo de USD 3,2 bilhões para 2026. O Reino Unido enfrenta fricções de transferência de dados pós-Brexit que adicionam latência e sobrecarga jurídica aos serviços em todo o continente. Os fundos soberanos de riqueza do Oriente Médio comprometem USD 140 bilhões para convergir a vantagem energética com as ambições de IA, apoiando os corredores de centros de dados de Riade e Abu Dhabi que operam amplamente fora dos regimes de controle de exportação ocidentais.


Cenário Competitivo
A estrutura oligopolista permanece evidente na camada de silício, onde a NVIDIA capturou cerca de 80% da receita de aceleradores de 2025 e mantém uma vantagem de 4 milhões de desenvolvedores no ecossistema CUDA. Os hiperscalers responderam projetando ASICs como o Google TPU v6e, o AWS Trainium2 e o Microsoft Maia 100, que devem alcançar 20% das horas de treinamento até 2026, pressionando os preços de tabela da NVIDIA em até 30% para pedidos em volume. O MI325X da AMD aproveita 288 GB de HBM3E para superar o H200 em preço por gigabyte, encontrando tração inicial nas implantações da Oracle Cloud. O Gaudi 3 da Intel enfatiza a conectividade Ethernet, atraindo empresas cautelosas com ecossistemas de fornecedor único.
A camada de interconexão testemunha consolidação em torno de roteiros ópticos, com o Tomahawk 6 da Broadcom oferecendo comutação de 1,6 Tbps alinhada com os marcos do IEEE 802.3df. Os registros de patentes tendem para chiplets e protocolos die-a-die como UCIe, indicando que a integração modular pode diluir as vantagens dos incumbentes ao encurtar o tempo de comercialização para os desafiantes. O Triton Inference Server e o Apache TVM detêm crescente participação de mercado, permitindo que os clientes troquem de hardware sem reescritas completas de código, corroendo assim as margens de middleware proprietário. A inferência de borda, definida por orçamentos de energia abaixo de 75 watts, atrai startups como a Tenstorrent e a Graphcore, embora as implantações permaneçam em escala piloto hoje.
O escrutínio ambiental cresce. Os mecanismos europeus de carbono podem adicionar 5-8% às despesas operacionais até 2028, incentivando os provedores em direção à energia renovável e ao resfriamento líquido. Os hiperscalers lideram acordos de compra de energia renovável superiores a 25 GW acumulados, colocando a sustentabilidade em paridade com a latência como fator competitivo. A escassez de talentos também molda a rivalidade; a NVIDIA e a AMD abriram academias de treinamento combinadas para 30.000 engenheiros por ano para defender a lealdade ao ecossistema. Em geral, a intensidade competitiva aumenta, mas o aprisionamento arquitetônico começou a se erosar à medida que os padrões abertos amadurecem.
Líderes do Setor de Infraestrutura de IA
NVIDIA Corporation
Intel Corporation
Advanced Micro Devices (AMD)
Microsoft Corporation
Amazon Web Services, Inc.
- *Isenção de responsabilidade: Principais participantes classificados em nenhuma ordem específica

Desenvolvimentos Recentes do Setor
- Janeiro de 2026: A NVIDIA apresentou a GPU Blackwell B200 com 208 bilhões de transistores e 20 petaflops de throughput FP4; a Microsoft e a AWS pré-encomendaram 50.000 unidades cada para entrega no terceiro trimestre de 2026.
- Dezembro de 2025: A NVIDIA apresentou a GPU Blackwell B200 com 208 bilhões de transistores e 20 petaflops de throughput FP4; a Microsoft e a AWS pré-encomendaram 50.000 unidades cada para entrega no terceiro trimestre de 2026.
- Novembro de 2025: A Amazon Web Services introduziu instâncias Trainium3, triplicando o throughput da geração anterior ao mesmo preço.
- Outubro de 2025: A SK Hynix entrou em produção em massa de pilhas HBM3E de 16 camadas, aumentando a capacidade por GPU para 128 GB.


Estrutura da metodologia de pesquisa e escopo do relatório
Definições de mercado e cobertura principal
Nosso estudo trata o mercado de infraestrutura de IA como todas as receitas geradas por hardware especializado, software em nível de sistema e soluções de data center de alto desempenho que permitem o treinamento e a inferência de cargas de trabalho de aprendizado de máquina em escala. Isso abrange GPUs, aceleradores de IA, armazenamento e memória associados, camadas de orquestração e modelos de entrega na nuvem ou no local.
Exclusão do âmbito: Estão excluídos os dispositivos de ponta para consumidores e os serviços de TI genéricos que não aceleram diretamente as cargas de trabalho de IA.
Visão geral da segmentação
- Por Oferta
- Hardware
- Processador
- Armazenamento
- Memória
- Software
- Otimização de Sistema
- Middleware de IA e MLOps
- Hardware
- Por Implantação
- Local
- Nuvem
- Por Usuário Final
- Empresas
- Governo e Defesa
- Provedores de Serviços em Nuvem
- Por Arquitetura de Processador
- CPU
- GPU
- FPGA/ASIC (TPU, Inferentia, Gaudi, Cerebras)
- Outras Arquiteturas de Processador
- Por Geografia
- América do Norte
- Estados Unidos
- Canadá
- México
- América do Sul
- Brasil
- Argentina
- Restante da América do Sul
- Europa
- Reino Unido
- Alemanha
- França
- Suécia
- Restante da Europa
- Ásia-Pacífico
- China
- Japão
- Índia
- Austrália
- Coreia do Sul
- Restante da Ásia-Pacífico
- Oriente Médio
- Arábia Saudita
- Emirados Árabes Unidos
- Turquia
- Restante do Oriente Médio
- África
- África do Sul
- Nigéria
- Restante da África
- América do Norte
Metodologia de investigação pormenorizada e validação de dados
Investigação primária
Para validar as descobertas da mesa, os analistas da Mordor entrevistaram designers de centros de dados, arquitectos de nuvens de hiperescala, gestores de roteiros de semicondutores e líderes de aquisições na América do Norte, Europa e Ásia-Pacífico. Conversas guiadas esclareceram os preços médios de venda de servidores com GPUs densas, as cadências de atualização esperadas e o ritmo realista de retrofits de refrigeração líquida, preenchendo lacunas que as fontes públicas deixaram em aberto.
Pesquisa documental
Os analistas começaram com dados fundamentais de fontes de nível 1, como a Administração de Informações sobre Energia dos EUA para tendências de energia de data center, a Associação da Indústria de Semicondutores e o WSTS para volumes de remessa de chips e o Observatório de Políticas de IA da OCDE para fatores de política. Organismos comerciais como o Open Compute Project, a AI Infrastructure Alliance e o Uptime Institute forneceram referências de custo, densidade de rack e refrigeração que alimentam nosso modelo de construção do lado da oferta. Os registos 10-K da empresa, as apresentações para investidores e as chamadas de resultados deram pistas de preços do mundo real, e os feeds com curadoria da Dow Jones Factiva e da D&B Hoovers sinalizaram novos anúncios de capacidade. Esta lista é ilustrativa; muitas outras referências públicas e pagas foram analisadas para cruzamento de dados.
Uma segunda análise recolheu sinais de importação-exportação do Volza, patentes recentes de refrigeração líquida através da Questel e estatísticas regionais de despesas de capital dos jornais oficiais dos Estados Unidos, da China e da UE, o que nos ajudou a ancorar os spreads regionais e as curvas de adoção de tecnologia.
Dimensionamento e previsão de mercado
Uma construção de cima para baixo começa com o stock nacional de centros de dados e o capex anual ligado à IA, que são depois reconciliados com registos de envios de GPU e ASPs de servidores para aproximar o valor atual. Os totais são ajustados com base em roll-ups selecionados, receitas de fornecedores, verificações de canais e divulgações de utilização da nuvem antes de um ciclo de triangulação. As principais variáveis no nosso modelo incluem a taxa de ligação de GPU por bastidor, ASP mediana de servidor, crescimento global de capex de cloud, penetração de arrefecimento líquido e mudanças na eficácia da utilização de energia; cada série tem tendência para 2030.
Para efeitos de previsão, uma regressão multivariada associa essas variáveis a indicadores macro, como o crescimento do volume de trabalho da IA e os incentivos à computação soberana. A análise de cenários testa os picos de preços da energia e os choques no fornecimento de silício, e as lacunas nos dados de nível micro são colmatadas com estimativas de coeficientes regionais avaliadas por especialistas no domínio.
Validação de dados e ciclo de atualização
Os resultados são submetidos a uma revisão por pares em duas etapas, análises de anomalias em relação a indicadores de terceiros e aprovação da direção. Os modelos são actualizados anualmente, com actualizações intercalares desencadeadas por grandes movimentos de capacidade fabril ou inflexões de gastos na nuvem.
Porque é que a linha de base da infraestrutura de IA de Mordor exige fiabilidade
Os números publicados divergem frequentemente porque as empresas variam o âmbito (por exemplo, algumas incluem servidores genéricos nos totais) e aplicam cadências de atualização diferentes. Nosso filtro disciplinado bloqueia o hardware e o software do sistema diretamente vinculados à aceleração da IA e atualizamos assim que novas remessas ou dados de capex chegam, mantendo os clientes à frente da curva.
Os principais factores de divergência incluem cabazes de componentes mais alargados em alguns estudos, pressupostos de conversão de moeda agressivos ou extrapolações que carecem de validação de preços no terreno. A combinação de dados primários de ASP da Mordor, a manutenção anual do modelo e as exclusões específicas do segmento reduzem esse desvio.
Comparação de benchmarks
| Dimensão do mercado | Fonte anónima | Principal fator de lacuna |
|---|---|---|
| USD 87,60 B (2025) | Inteligência de Mordor | - |
| USD 58,78 B (2025) | Consultoria Global A | Inclui apenas cargas de trabalho na nuvem, omitindo o ciclo de atualização no local |
| USD 135,81 B (2024) | Analista internacional B | Adiciona servidores genéricos e equipamento de rede, utiliza taxas de câmbio únicas |
Em suma, a Mordor Intelligence fornece uma linha de base equilibrada e transparente ancorada em variáveis claramente rastreáveis e passos repetíveis, dando aos decisores uma visão fiável do panorama da infraestrutura de IA em rápida evolução.


Principais Questões Respondidas no Relatório
Qual é o valor projetado do mercado de infraestrutura de IA em 2031?
O mercado deve atingir USD 202,48 bilhões até 2031, expandindo-se a uma CAGR de 14,89% ao longo do período.
Qual região crescerá mais rapidamente nos gastos com infraestrutura de IA?
Espera-se que a Ásia-Pacífico registre uma CAGR de 16,44% até 2031, impulsionada por grandes fundos de semicondutores na China e expansões de hiperscalers na Índia.
Quão dominantes são as GPUs na receita atual de aceleradores de IA?
As GPUs detinham 88,82% da receita de arquitetura de processadores em 2025, embora os dispositivos ASIC e FPGA estejam agora crescendo mais rapidamente para cargas de trabalho de inferência.
Por que os centros de dados com resfriamento líquido estão ganhando impulso?
O aumento das densidades de rack acima de 100 quilowatts e a precificação de carbono mais rigorosa tornam o resfriamento líquido essencial, reduzindo o consumo de energia das instalações em até 40%.
Como os controles de exportação influenciam a estratégia de infraestrutura de IA?
As restrições dos EUA ao envio de GPUs de alto desempenho para a China impulsionam investimentos paralelos em chips domésticos, levando a pilhas tecnológicas divergentes e maiores custos de conformidade para implantações multinacionais.
Página atualizada pela última vez em:



