大規模言語モデル(LLM)市場規模とシェア
市場概要
| 調査期間 | 2020 - 2031 |
|---|---|
| 市場規模 (2026) | 9.98 十億米ドル |
| 市場規模 (2031) | 24.92 十億米ドル |
| 成長率 (2026 - 2031) | 20.08% CAGR |
| 最も急速に成長している市場 | アジア太平洋 |
| 最大市場 | 北米 |
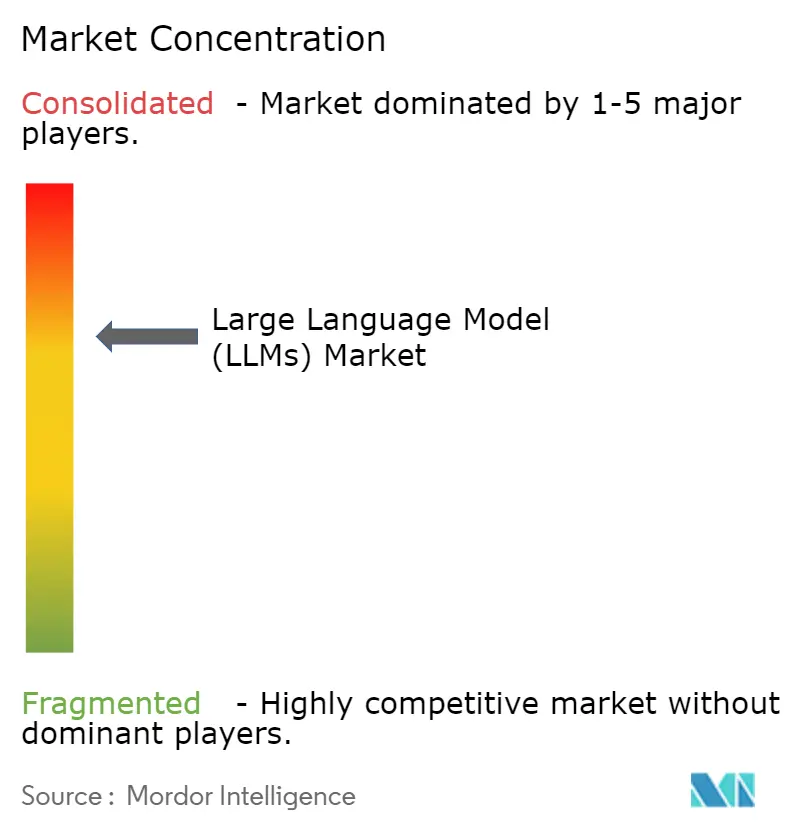
| 市場集中度 | 中 |
主要プレーヤー *免責事項:主要選手の並び順不同 画像 © Mordor Intelligence。再利用にはCC BY 4.0の表示が必要です。 | |
Mordor Intelligenceによる大規模言語モデル(LLM)市場分析
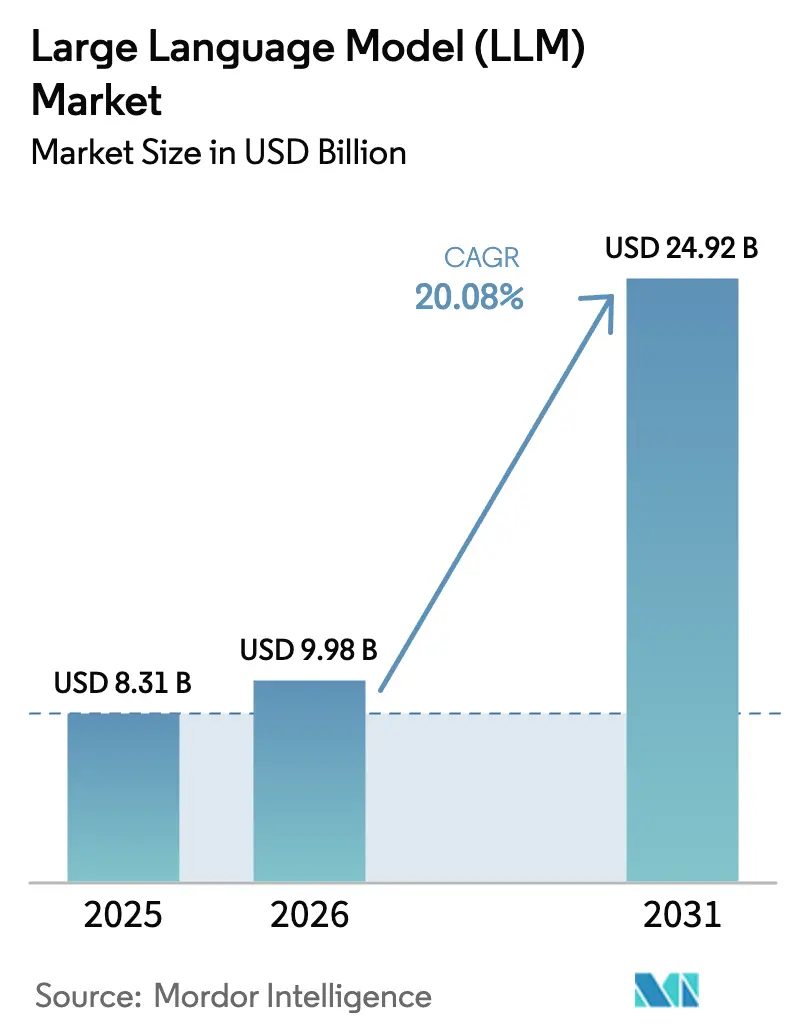
大規模言語モデル市場規模は2025年に83億1,000万米ドルと評価され、2026年の99億8,000万米ドルから2031年には249億2,000万米ドルに達すると推定されており、予測期間(2026年〜2031年)のCAGRは20.08%です。NvidiaのBlackwellプラットフォームやAWS Trainium2などのGPUイノベーションが所有コストを圧縮し、スケールの障壁を取り除いており、あらゆる規模の企業が社内またはマネージドLLMイニシアチブの試験導入を進めています。[1]Nvidia Corporation、「NVIDIAブラックウェルプラットフォームが新たなコンピューティング時代を切り拓く」、nvidianews.nvidia.com テキスト・画像・音声を一つのパイプラインで処理するマルチモーダルアーキテクチャが研究段階から商業的な提供へと移行しており、会話型AIを超えてデザイン・診断・広告分野への普及が拡大しています。各国のAI規制は購買者を地域でトレーニングされたモデルまたはオンプレミス展開へと誘導しており、銀行・医療分野のドメイン特化型APIは幻覚リスクを低減しコンプライアンスを容易にすることで汎用モデルを置き換えています。エッジ最適化された小規模言語モデルはスマートフォン・ウェアラブル・産業用OEMのデバイスロードマップを再形成し、チップベンダーおよびサービスとしての推論プロバイダーに新たな収益源を開いています。これらの力が合わさり、大規模言語モデル市場が集中したクラウドワークロードから階層化されたあらゆる場所に存在するインテリジェンスファブリックへと進化する10年を示しています。
レポートの主要ポイント
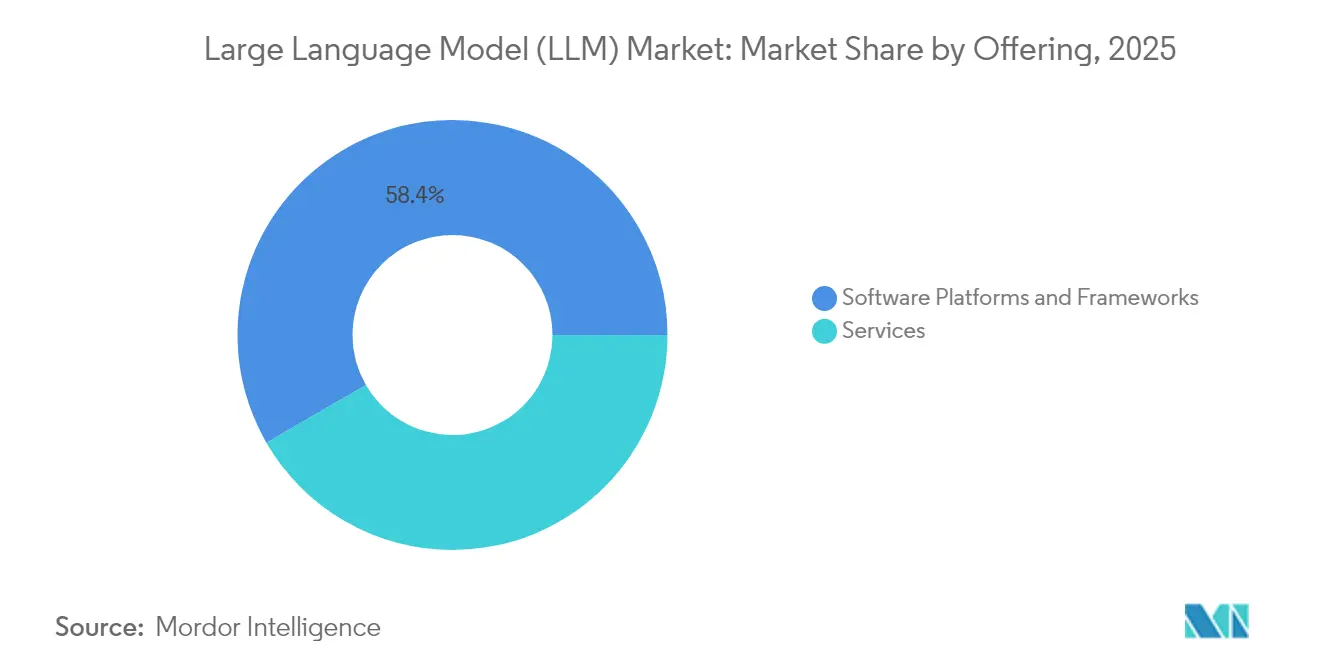
- 提供内容別では、ソフトウェアプラットフォームが2025年の大規模言語モデル市場シェアの58.35%を占め、サービスは2031年にかけてCAGR 24.26%で拡大する見込みです。
- 展開形態別では、オンプレミスソリューションが2025年の大規模言語モデル市場規模の51.85%をリードし、エッジ・デバイス展開は2031年にかけてCAGR 27.25%で進展しています。
- モデルサイズ別では、1,000億パラメータ未満のモデルが2025年の大規模言語モデル市場シェアの69.20%を獲得し、3,000億パラメータ超のモデルはCAGR 29.05%で成長すると予測されています。
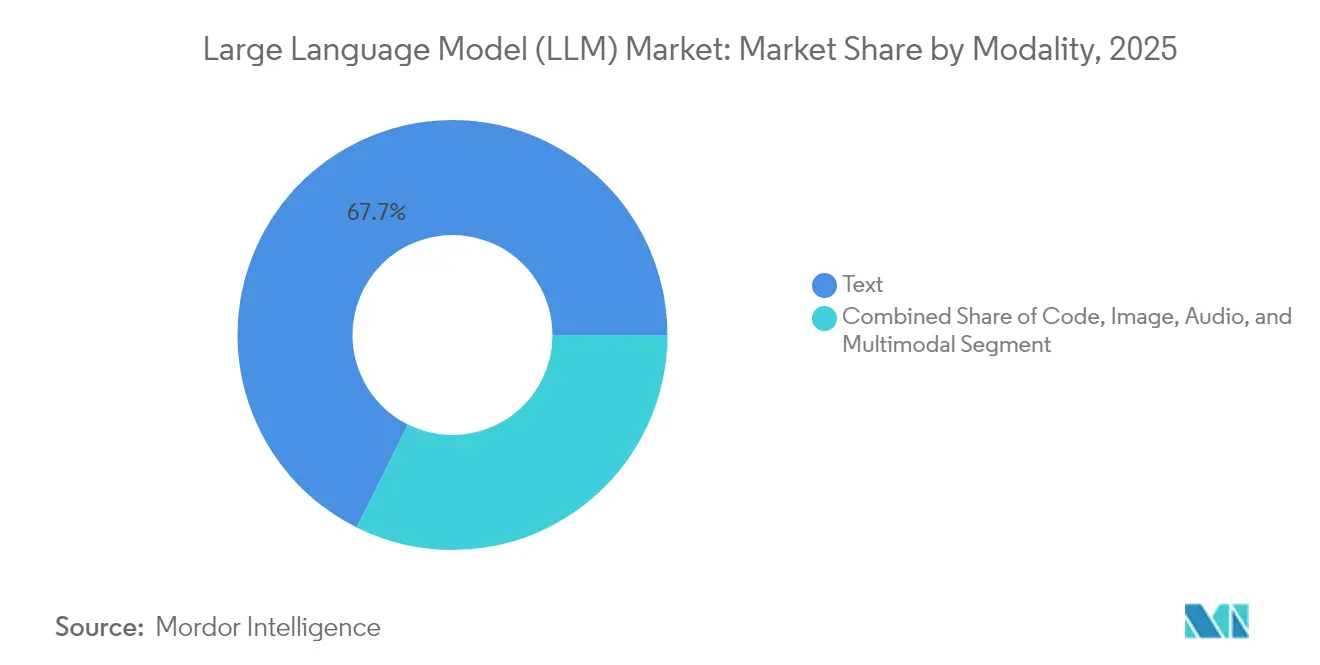
- モダリティ別では、テキスト中心モデルが2025年に67.65%の収益を占め、マルチモーダルモデルは2031年にかけてCAGR 28.95%を記録すると予測されています。
- アプリケーション別では、チャットボットおよびバーチャルアシスタントが2025年の大規模言語モデル市場規模の26.35%を占め、コード生成ツールはCAGR 24.75%で拡大する見込みです。
- エンドユーザー産業別では、小売・eコマースが2025年に26.75%の収益でリードし、医療はCAGR 25.95%で2031年にかけて成長する見込みです。
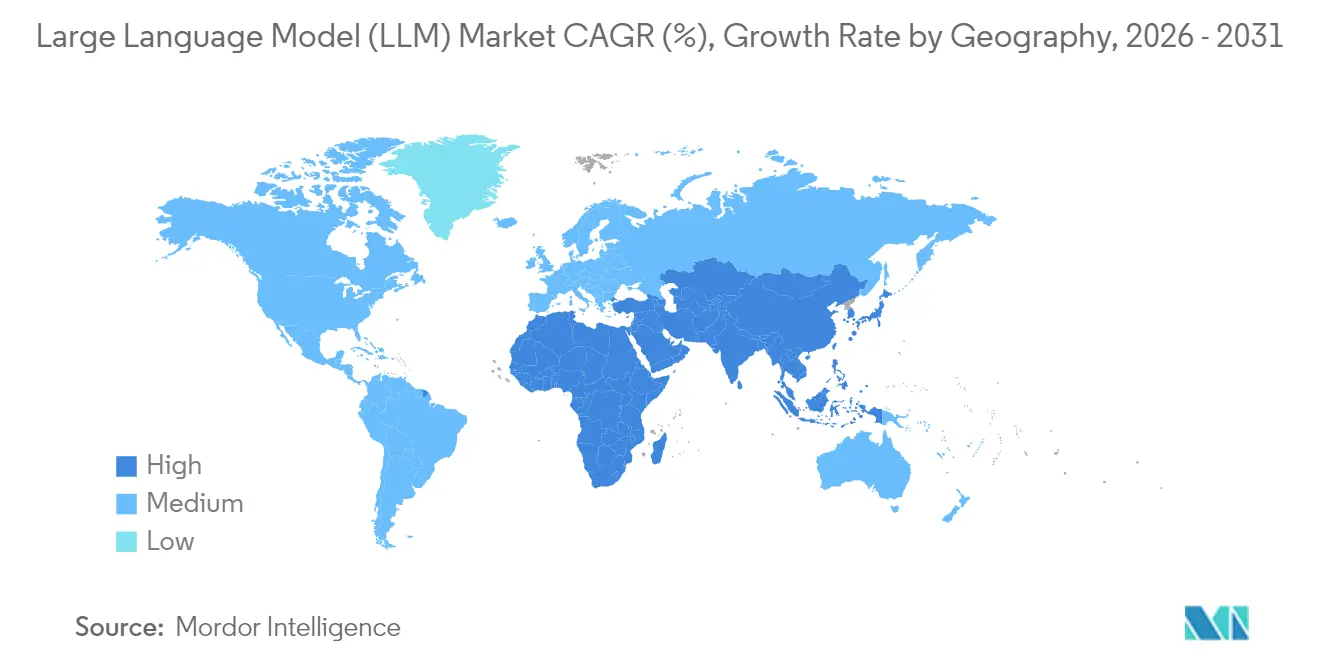
- 地域別では、北米が2025年収益の31.70%を占め、アジア太平洋は2026年〜2031年にかけてCAGR 31.40%を達成する軌道にあります。
注記:本レポートの市場規模および予測値は、Mordor Intelligence の独自推定フレームワークを使用して算出され、2026年時点で入手可能な最新のデータと洞察に基づいて更新されています。
グローバル大規模言語モデル(LLM)市場のトレンドとインサイト
ドライバーの影響分析*
| ドライバー | CAGRへの影響(概算%) | 地理的関連性 | 影響のタイムライン |
|---|---|---|---|
| NvidiaブラックウェルおよびAWS Trainium2によるGPUコンピュートコストの急速な低下 | +5.2% | グローバル(北米および東アジアに集中) | 中期(2〜4年) |
| 北米におけるBFSIおよび医療向けエンタープライズグレードのドメイン特化型LLM API | +4.3% | 北米(欧州への波及あり) | 短期(2年以内) |
| ローカルトレーニングを強制する各国AI政策(例:中国の2024年暫定規則) | +3.1% | 中国・EU(グローバルへの影響あり) | 中期(2〜4年) |
| 欧州CRM・ERPへの組み込みLLM機能によるSaaSアップセル機会 | +2.8% | 欧州・北米 | 短期(2年以内) |
| グローバル広告テクノロジー代理店によるマルチモーダルコンテンツ需要の急増 | +2.5% | グローバル(北米および欧州に集中) | 中期(2〜4年) |
| スマートフォン向けエッジ最適化小規模言語モデル(20億パラメータ未満) | +3.7% | グローバル(アジア太平洋での早期採用) | 長期(4年以上) |
| 情報源: Mordor Intelligence | |||
NvidiaブラックウェルおよびAWS Trainium2によるGPUコンピュートコストの急速な低下
2024年に発表されたNvidiaのBlackwellファミリーは、大規模トレーニングおよび推論の総所有コストを前世代比で最大25倍削減し、設備投資とエネルギー消費の両方を低減します。AWS Trainium2はこれらのコスト削減をマネージドクラウドにまで拡張し、中堅ソフトウェアベンダーに1兆パラメータ規模の実験へのコスト経路を提供します。この資本効率の向上により、大規模ハイパースケーラーが享受してきた歴史的な参入障壁が取り除かれ、地域プロバイダーやオープンソースコンソーシアムが競争力のあるチェックポイントをリリースできるようになります。コスト弾力性はまた、ハードウェアのアップグレードなしに精度を向上させるパラメータ効率の高いファインチューニングアプローチの実験を加速させています。これらの経済効果が総合的に、精密製造から個別化教育に至る幅広いセクターへの展開を加速させ、大規模言語モデル市場のアドレス可能な規模を拡大しています。
BFSIおよび医療向けエンタープライズグレードのドメイン特化型LLM API
銀行は信用リスクのトリアージ、制裁スクリーニング、個別化された顧客アドバイスに金融特化型モデルを統合し、監査基準を満たしながら手動レビューサイクルを短縮しています。医療ネットワークは、診断判断・患者トリアージ・創薬を改善するために医療記録や文献を解析する臨床的に整合されたアシスタントを試験導入しています。ベンダーは幻覚を抑制し規制審査を通過するために、厳密なプロンプトグラウンディングと検索拡張生成を強調しています。トークンまたは成果を課金するサブスクリプションモデルは既存の調達規範に適合し、販売サイクルを容易にします。両産業における厳格なデータガバナンス規則により、これらの特化型APIは汎用モデルを置き換え、大規模言語モデル市場においてプレミアム層を確立しています。
ローカルトレーニングを強制する各国AI政策
中国の暫定措置とEU AI法は、リスク分類、セキュリティ申告、そして多くの場合ローカルモデルトレーニングを要求しています。[3]欧州委員会、「AIに関する規制フレームワーク」、digital-strategy.ec.europa.eu 企業は今や管轄区域の断片化と効率性を天秤にかけ、独自データを保護するためにソブリンクラウドまたはオンプレミスクラスターへと傾いています。システムインテグレーターは、言語カバレッジと政府承認の迅速化を確保するために、しばしば通信事業者や国家資金と共同出資して地域モデルハブを立ち上げることで対応しています。この転換は新たな地域チャンピオンを生み出し、大規模言語モデル市場の初期成長を支配していた「一つのモデルがすべてに対応する」という考え方を侵食しています。並行して、ローカルトレーニングは文化的に整合した出力を生み出し、公共サービスや放送メディアなどのセクターでのユーザー受容を高めています。
組み込みLLM機能によるSaaSアップセル機会
CRM・ERP・ワークプレイスプラットフォームは、自動メール下書き・案件リスク要約・財務決算照合などの生成機能を既存のインターフェースに直接組み込んでいます。ベンダーはシートごとの価格設定から、コンピュート消費との価値整合性を高める使用量ベースの段階的価格設定へと移行し始めています。[4]欧州委員会、「AIに関する規制フレームワーク」、digital-strategy.ec.europa.eu アップセル戦略は、SaaSスタックにすでに存在する顧客データを活用し、競合他社が複製困難なコンテキスト豊富な回答を提供することに依存しています。購買者にとって、このモデルは統合オーバーヘッドを最小化し、数週間以内に価値実現時間を達成するため、以前は個別AIパイロットに充てられていた予算の配分を促します。このダイナミクスにより、大規模言語モデル市場のアクセス可能な総規模がAIチームを超えて事業部門のステークホルダーにまで拡大します。
制約要因の影響分析*
| 制約要因 | CAGRへの影響(概算%) | 地理的関連性 | 影響のタイムライン |
|---|---|---|---|
| 推論エネルギーコストの上昇(1,000トークンあたり0.12米ドル)による中南米でのSMB採用の制限 | -2.1% | 南米・アフリカ・東南アジア | 短期(2年以内) |
| EU AI法の高リスクコンプライアンスオーバーヘッド | -1.8% | 欧州連合(EUマーケットにサービスを提供する企業へのグローバルな影響あり) | 中期(2〜4年) |
| アフリカ言語向け多言語トレーニングデータの不足 | -1.3% | アフリカ(包括的AIへのグローバルな影響あり) | 長期(4年以上) |
| オンプレミスHPCを制約するハイパースケーラーによるH100 GPU供給の支配 | -1.9% | グローバル(新興市場への特定の影響あり) | 中期(2〜4年) |
| 情報源: Mordor Intelligence | |||
推論エネルギーコストの上昇によるSMB採用の制限
200億パラメータのアシスタントを実行すると、100万トークンあたり数キロワット時を消費する可能性があり、グリッド料金が1kWhあたり0.10米ドルを超える地域では1,000トークンの処理ごとに0.12米ドルの電気料金に換算されます。ブラジルやケニアで薄い利益率で事業を営む小規模なeコマースや物流企業にとって、この計算はROIを損ないます。クラウドプロバイダーは超効率的な冷却と再生可能エネルギーを共同設置していますが、転嫁率は依然として不安定です。エネルギー対応コンパイラとスパース性技術が登場しつつありますが、SMBのITチームの予算では本番環境に到達するものはほとんどありません。推論密度が改善されるまで、多くの中小企業はレガシーチャットボットにとどまり、近期の大規模言語モデル市場の一部を制限することになります。
EU AI法の高リスクコンプライアンスオーバーヘッド
2025年2月に施行されたEU AI法は、信用スコアリング・採用・医療支援における多くのLLM展開を高リスクとして分類し、義務的な影響評価・人間による監視ループ・公開登録簿を要求します。最大3,500万ユーロまたはグローバル売上高の7%の罰則が取締役会レベルの精査を高めます。文書化の負担がリリースサイクルを遅らせ、データセットの系譜・説明可能性・バイアス監視のための新たなツールを必要とします。大企業は製品ライン全体でコストを償却できますが、スタートアップは市場参入の遅延に直面し、規制の緩い管轄区域へと誘導されます。これらの摩擦が総合的に、大規模言語モデル市場内の地域成長からポイントを削ります。
*当社の予測では、推進要因および抑制要因の影響を加算的ではなく方向性のあるものとして扱います。影響予測は、ベースライン成長、構成効果、および変数間の相互作用を反映しています。
セグメント分析
提供内容別:ソフトウェアプラットフォームがエンタープライズ採用を牽引
ソフトウェアプラットフォームは2025年収益の58.35%を占め、実験・プロンプトチェーニング・ファインチューニングワークフローの足場として機能しています。トークン化・ベクトル検索・安全フィルターを抽象化する機能キットにより、開発者は深いモデル知識なしに生成機能を統合できます。予測期間中、企業がブランドトーン・リスクポリシー・レイテンシ予算に出力を整合させる支援を求めるにつれ、コンサルティングおよびチューニングサービスはCAGR 24.26%で拡大する見込みです。マネージド推論プランも拡大しており、企業はリアルタイムのコスト曲線に基づいてGPU・ASIC・CPU間で呼び出しを分散できます。このサービス層が大規模言語モデル市場をサービスとしてのパラダイムへと推進しています。
ターンキー型垂直スタックへの需要の高まりにより、プラットフォーム企業は規制プリセット・ドメイン語彙・ベンチマークダッシュボードを追加するよう促されています。契約形態はライセンス・使用状況分析・コンプライアンスレポートをバンドルするようになっており、金融・医療における調達規範を反映しています。独立系ソフトウェアベンダーがこれらのプラットフォームを組み込み、チャネルリーチを広げるパートナーエコシステムを育成しています。その結果、大規模言語モデル市場は特に、オープンツールとキュレートされたデータコネクタおよび堅牢なガバナンス機能を組み合わせるプロバイダーに報いています。
注記: すべての個別セグメントのセグメントシェアはレポート購入時に入手可能


展開形態別:エッジコンピューティングがAIアーキテクチャを再形成
銀行・病院・公共機関が主権とレイテンシ制御を優先したため、オンプレミスインストールが2025年支出の51.85%を支配しました。国内データ処理を要求する規制がさらに予算をプライベートクラスターおよびソブリンクラウドへと傾けました。しかし最も急速な牽引力はエッジにあり、量子化された4GBチェックポイントが現在フラッグシップスマートフォンや産業用コントローラーに収まるようになっています。2031年にかけてCAGR 27.25%で、エッジ推論はラウンドトリップ遅延を排除し帯域幅負荷を軽減し、自律検査ドローンやフィールドサービスウェアラブルで重宝されています。韓国とインドでの初期パイロットは6Wモバイルシステムオンチップで100ミリ秒未満の応答を実証し、大規模言語モデル市場の新たな章を浮き彫りにしています。
ハイブリッドトポロジーが結晶化しつつあります:高精度プロンプトはクラウドで開始され、低リスクの継続はデバイス上で行われ、クラウドのエグレス費用を削減します。チップメーカーは4ビットトランスフォーマー向けに調整されたNPUを出荷しており、ファームウェアアップデートによりOEMは購入後に付加価値のある言語エージェントを提供できます。これらのトレンドが合わさり、クラウドと製品の境界を曖昧にし、大規模言語モデル市場のインテリジェンスをデバイススタック全体に広げています。
モデルサイズ別:パラメータ効率がイノベーションを牽引
企業は1,000億パラメータ未満のモデルを好み、これらは2025年収益の69.20%を獲得し、通常8基のGPUクラスターで快適に動作します。パラメータ効率の高い設計はコンテキストウィンドウを維持しながらトークンを削減し、コモディティサーバーで高速推論を提供するxLSTM 7Bの再帰型アーキテクチャによって実証されています。このようなフットプリントは、コンタクトセンター自動化や保険における保険契約者チャットのコスト上限と整合し、大規模言語モデル市場を中堅企業にとってアクセス可能に保っています。
一方の極端では、3,000億パラメータ超のモデルが複雑な推論・科学的発見・マルチモーダル構成のユースケースに牽引されてCAGR 29.05%を記録する見込みです。製薬大手とクラウドプラットフォームの研究アライアンスは、カリキュラム学習と合成データでトレーニングスケジュールを圧縮し、タンパク質折り畳みと材料設計のブレークスルーを推進することを目指しています。これらの巨大モデルから小規模なサービングヘッドへ知識を蒸留するツールが成熟するにつれ、上位で生み出された価値が日常のビジネスアプリケーションに波及し、大規模言語モデル市場全体を拡大します。
モダリティ別:マルチモーダル機能がアプリケーション範囲を拡大
テキスト優先アーキテクチャが2025年収益の67.65%を獲得し、要約・知識管理・会話型サポートを支えています。しかし、顧客エンゲージメントチーム・広告代理店・臨床医はテキストと並んで図表・画像・波形を取り込むモデルをますます必要としています。マルチモーダルスタックは視覚トークンと共同埋め込み空間のイノベーションに後押しされ、2031年にかけてCAGR 28.95%で急増する見込みです。不動産アプリは現在複数の言語で物件写真を説明し、放射線科アシスタントは画像と患者記録を相互参照して異常を検出し、大規模言語モデル市場に新たな道を開いています。
音声拡張入力はコールセンターQAの精度を高め、ジェスチャーからコードへのプロトタイプは差し迫ったインターフェースの転換を示唆しています。クロスモーダルアライメントとレイテンシ最適化を習得したベンダーは、データパイプラインと評価プロトコルがテキストのみのバリアントよりも著しく複雑になるため、参入障壁を獲得します。その結果、マルチモーダル事前トレーニングにおける技術的深度が大規模言語モデル市場のリーダーシップをますます決定するようになっています。
注記: すべての個別セグメントのセグメントシェアはレポート購入時に入手可能
アプリケーション別:コード生成が開発者の生産性を加速
チャットボットおよびバーチャルアシスタントが2025年需要の26.35%シェアでリードし、第一層サポート・人事ヘルプデスク・バーチャルコンシェルジュサービスを自動化しています。これらは依然として入口となっていますが、ソフトウェアチームが最も急峻な上昇を示しています。コード生成・レビューツールはCAGR 24.75%で成長し、関数の自動提案・セキュリティ欠陥の検出・テストスイートの生成によってスプリントを加速します。LLMペアプログラマーを使用するチームはロールオーバーバグの減少とリリースサイクルの短縮を報告しており、CFOに対して具体的なROIを実証し、大規模言語モデル市場のファネルを広げています。
コードを超えて、コンテンツ制作パイプラインはコピー・レイアウト・ボイスオーバー生成を一つのオーケストレーション層の下に統合しています。自律エージェントは検索・推論・アクションAPIを融合させ、保険請求トリアージやサプライチェーン例外処理などの複雑なワークフローをナビゲートします。これらの新興パターンは、シングルターンプロンプトからマルチステップオーケストレーションへの転換を強調し、大規模言語モデル市場が獲得する価値を深めています。
エンドユーザー産業別:医療イノベーションが成長を牽引
小売・eコマースが2025年収益の26.75%を獲得し、リアルタイムの製品Q&A・広告コピー・動的検索再ランキングを活用しています。金融機関は不正防止分析とコンテキスト型顧客アドバイザリーに転換し、人員を増やすことなくクロスセリングを推進しています。しかし医療は、臨床LLMが診断推論・文献合成・個別化された退院指示をサポートするにつれ、2031年にかけてCAGR 25.95%を記録する見込みです。退院メモが患者のリテラシーレベルに自動的に合わせられた場合に再入院率が低下することを初期パイロットが示しており、直接的な成果への影響を証明し、大規模言語モデル市場への支出を強化しています。
ライフサイエンス研究者は、標的同定を加速するためにラボプロトコル・オミクス・特許コーパスをファインチューニングされたモデルに投入しています。政府・防衛機関は多言語インテリジェンス要約を実験し、教育プロバイダーは概念説明とソクラテス式質問を組み合わせた適応型チュータリングをテストしています。これらの垂直市場全体で、データプライバシープロトコルと監査証跡が標準的なRFPチェックリストの一部となり、ベンダーはガバナンスプリミティブを製品設計の深部に組み込むよう促されています。
地域分析
北米は2025年収益の31.70%を占め、ベンチャー資金・大学の人材プール・クラウドGPU供給に支えられています。同地域の企業は、資産管理・腫瘍学的意思決定支援・法律調査向けのドメイン特化型アシスタントの展開においてファーストムーバーでした。州レベルのプライバシー法案とアルゴリズムバイアスへの連邦の注目が説明可能性モジュールへの需要を高めていますが、全体的な政策はイノベーション友好的なままです。ハイパースケーラーによるAI対応データセンターの継続的な展開が地域のスループットを支え、大規模言語モデル市場が相当規模の北米核を維持することを確保しています。
アジア太平洋は、政府がソブリンモデルイニシアチブを支援し言語的多様性が地域チェックポイントを促進するにつれ、最速のCAGR 31.40%を記録する見込みです。中国の暫定措置は国内トレーニングを義務付け、国内アクセラレータ設計とクラウドサービスを刺激しています。日本は2025年デジタルガーデン戦略の下で高インパクトAIを奨励し、インドのIndiaAIミッションはスタートアップに公開データセットとGPUクレジットを開放しています。エッジネイティブの小規模言語モデルはインドネシアやフィリピンなどのスマートフォン中心市場で共鳴し、農村部のカバレッジを拡大し大規模言語モデル市場を拡大しています。
欧州はEU AI法の下で野心と慎重さのバランスを取っています。企業はデータ居住性とスケーラビリティを調和させるためにハイブリッド展開を追求し、機密ワークロードにはプライベートクラスターを、バースト容量にはパブリッククラウドを使用しています。スペイン・フランス・イタリアはAI対応サーバーファームを増強しており、しばしば持続可能性目標を達成するために再生可能エネルギーで稼働しています。SaaSアップセルの波はここで顕著であり、ERPベンダーが地域の監査基準を満たす多言語チャットと請求書照合機能を組み込んでいます。総合的に、各国の異なる執行体制が市場参入計画を断片化しますが、コンサルティングおよびコンプライアンスツールの需要も生み出し、地域の大規模言語モデル市場を安定した成長軌道に保っています。

競合環境
上位5社のベンダーが合わせて収益の85%超を支配しており、シリコンからソフトウェアに至る統合スタックに支えられています。Nvidiaは2025年初頭にソフトウェアオーケストレーション資産を取得することで地位を強化し、ワンストップAIプラットフォームプロバイダーとして自社を位置付けました(nvidianews.nvidia.com)。MicrosoftはOpenAIと新興ラボxAIの両方とのパートナーシップを深め、モデルリスクを分散し顧客への訴求力を広げました(blogs.microsoft.com)。OracleはMicrosoftおよびOpenAIと連携してマルチクラウドAIリージョンを提供し、コンプライアンスと弾力的なGPUスケールを組み合わせました。
オープンソースの挑戦者と地域専門企業は、より低コストで商業ライセンスのベースラインに匹敵する効率的なチェックポイントをリリースすることで存在感を示しています。AnthropicのClaude 4はマルチステップ推論ベンチマークを押し上げ、Metaから派生したモデルの混合精度ファインチューニングがコミュニティリーダーボードを席巻しています。韓国とドイツの通信事業者はソブリンAIクラウドを立ち上げ、規制対象ワークロードを獲得し米国ハイパースケーラーからシェアを奪うことを目指しています。垂直データ・ドメイン評価スイート・迅速な展開APIをパッケージ化したスタートアップが保険・物流・鉱業で契約を獲得し、大規模言語モデル市場に新たなダイナミズムを注入しています。
戦略的アライアンスが、純粋なモデルの重みではなく、エンタープライズRFPを決定するようになっています。参照アーキテクチャ・コストシミュレーター・コンプライアンスダッシュボードを提供するベンダーが調達の牽引力を得ています。エネルギー効率・サプライチェーンの回復力・透明な使用状況メトリクスがマスターサービス契約で重要視されており、購買者のプレイブックの成熟を示しています。オープンウェイトが独自の参入障壁を侵食するにつれ、既存企業は展開ツール・安全統合・グローバル配布能力でますます差別化しています。
大規模言語モデル(LLM)産業リーダー
Alibaba Group Holding Limited
Amazon Web Services (AWS)
Anthropic
Baidu, Inc.
Google LLC
- *免責事項:主要選手の並び順不同

最近の産業動向
- 2025年5月:Anthropicがマルチステップ推論を改善したClaude 4モデルを発表。
- 2025年5月:MicrosoftがAnthropicおよびxAIの技術を統合し、AIスタックを多様化。
- 2025年5月:OpenAIがソフトウェア開発タスク向けエージェントCodexを発表。
- 2025年4月:GoogleがAIエージェント向けAnthropicの相互運用性プロトコルを採用。
- 2025年4月:NvidiaがフルスタックのAI制御を拡大する買収を発表。
- 2025年3月:EYインドがLLAMA 3.1-8Bをベースにしたファインチューニング済みBFSI LLMを発表。
- 2025年3月:GoogleがAnthropicに投資し、AIパートナーシップを強化。
- 2025年3月:NebiusとYTLがBlackwell Ultra GPUインスタンスをリリース。


研究方法のフレームワークとレポートの範囲
市場定義と主要カバレッジ
本調査では、大規模言語モデル(LLM)市場を、10億パラメータを超えるトランスフォーマーベースのモデルをオンプレミス・クラウド・エッジでトレーニング・展開・利用可能にするソフトウェアプラットフォーム・フレームワーク・関連統合またはファインチューニングサービスから生み出される収益として定義しています。Mordor Intelligenceによれば、価値はソフトウェアまたはサービスが有料ユーザーに届く時点で捕捉され、API呼び出しごと・サブスクリプション・エンタープライズライセンスのいずれかで課金されます。
調査範囲の除外:スタンドアロンのコンピュータビジョン生成モデルおよびGPU・ASIC・サーバーの販売は本調査の対象外です。
セグメンテーション概要
- 提供内容別
- ソフトウェアプラットフォームおよびフレームワーク
- 汎用LLMプラットフォーム
- ドメイン特化型LLMソリューション
- サービス
- コンサルティングおよびシステムインテグレーション
- ファインチューニングおよびカスタマイズ
- マネージド推論およびホスティング
- ソフトウェアプラットフォームおよびフレームワーク
- 展開形態別
- クラウド(パブリックおよびプライベート)
- オンプレミス・専用AIクラスター
- エッジ・デバイス組み込み
- モデルサイズ(パラメータ)別
- 70億パラメータ未満
- 70億〜700億パラメータ
- 700億〜3,000億パラメータ
- 3,000億パラメータ超
- モダリティ別
- テキスト
- コード
- 画像
- 音声
- マルチモーダル
- アプリケーション別
- チャットボットおよびバーチャルアシスタント
- コード生成およびレビュー
- コンテンツおよびメディア生成
- カスタマーサービス自動化
- 言語翻訳およびローカライゼーション
- 感情・意図分析
- 自律エージェントおよびRPA
- エンドユーザー産業別
- BFSI
- 医療およびライフサイエンス
- 小売およびeコマース
- メディアおよびエンターテインメント
- 情報技術および通信
- 教育
- 製造
- 政府および防衛
- 地域別
- 北米
- 米国
- カナダ
- メキシコ
- 欧州
- ドイツ
- 英国
- フランス
- イタリア
- スペイン
- その他欧州
- アジア太平洋
- 中国
- 日本
- 韓国
- インド
- 東南アジア
- その他アジア太平洋
- 南米
- ブラジル
- その他南米
- 中東およびアフリカ
- 中東
- アラブ首長国連邦
- サウジアラビア
- その他中東
- アフリカ
- 南アフリカ
- その他アフリカ
- 中東
- 北米
詳細な調査方法論とデータ検証
一次調査
二次調査の結果を裏付けるために、北米・欧州・主要なアジア太平洋ハブのAI製品リーダー・クラウドオペレーションアーキテクト・コンプライアンスオフィサー・学術研究者にインタビューを実施しました。構造化されたアンケートは価格モデル・パラメータ数の好み・コンピュートから推論へのコスト比率・予想されるアップグレードサイクルを調査し、データギャップを埋めモデル化された前提をストレステストすることを可能にしました。
デスクリサーチ
Mordorのアナリストは、新しいトランスフォーマーアーキテクチャに関する米国特許商標庁の出願・AI採用を追跡するOECDデジタル経済指標・AIソフトウェア輸出をカバーする世界貿易機関の関税コード・EU AI法ワーキンググループの政策文書などの公開されている第一級情報源から基礎データを収集しました。これらの洞察を企業の10-K・開発者会議の議事録・信頼できる業界団体のブリーフィング(例:Linux FoundationのLF-AIプロジェクト)で補完しました。
財務情報のためのD&B Hoovers・取引フローのためのDow Jones Factiva・特許ランドスケープのためのQuestelなど、当社が維持するサブスクリプションデータベースが、ベンダーの収益モメンタムとイノベーション強度に関する追加の定量的シグナルを提供しました。
引用された情報源は参照された資料の幅広さを示しており、データ収集・検証・明確化を支援した多くの追加参照資料があります。
市場規模算定と予測
当社はトップダウンとボトムアップを組み合わせたアプローチを採用しています。グローバルエンタープライズソフトウェア支出とパブリッククラウドの請求データが需要プールを確立し、選定されたベンダーからの展開量に平均販売価格を乗じたサンプルに対して検証されます。モデル内の主要変数には、(1)ユーザーあたり月間平均生成トークン数、(2)プライベートクラスターとパブリッククラウドで実行される展開のシェア、(3)商業リリースで出荷される平均パラメータ数、(4)ファインチューニングサービス契約の成長、(5)地域のAI政策インセンティブが含まれます。シナリオ分析と組み合わせた多変量回帰が各ドライバーを2030年まで予測し、一次調査からのアナリストコンセンサスがベースラインシナリオを形成し、感度バンドがボラティリティを捕捉します。サプライヤーのロールアップが完全な開示を欠く場合、部分的な値は過去の監査済み年度から導出された業界標準比率を使用してギャップフィルされます。
データ検証と更新サイクル
出力はAIサーバー出荷量やクラウド推論時間などの独立したメトリクスに対する異常チェックを経て、多段階のピアレビューが行われます。レポートは年次で更新され、重要な資金調達ラウンド・規制変更・ブレークスルーモデルのリリースによって中間改訂が行われます。納品直前にアナリストがファイルを再読し、クライアントが最新の見解を受け取れるようにします。
当社の大規模言語モデルベースラインが信頼性を持つ理由
公表された推定値はしばしば乖離しますが、これは企業が異なる基準年を選択したり、ハードウェア収益を含めたり、均一な価格設定を前提としたりするためです。
主要なギャップ要因には、サービスを省略した狭い調査範囲・パラメータ数の上限なしにトークン成長を積極的に外挿すること・最近のドル高以前の古い為替レートで固定された通貨換算が含まれます。
ベンチマーク比較
| 市場規模 | 匿名化された情報源 | 主要なギャップ要因 |
|---|---|---|
| 83億1,000万米ドル(2025年) | ||
| 64億米ドル(2024年) | グローバルコンサルタンシーA | ハードウェアのバンドル、古い為替レート |
| 56億2,000万米ドル(2024年) | 地域コンサルタンシーA | ファインチューニングサービスを除外 |
| 57億2,000万米ドル(2024年) | 業界誌B | 検証なしに均一なCAGR 40%を前提 |
この比較は、調査範囲の選択・価格前提・更新頻度が合計値をどのように変えるかを示しています。Mordorの厳格な変数選択・年次更新・透明なモデルロジックが、意思決定者に戦略的計画のための信頼性の高いバランスの取れた出発点を提供します。


レポートで回答される主要な質問
大規模言語モデル市場の現在の評価額はいくらですか?
大規模言語モデル市場規模は2026年に99億8,000万米ドルであり、2031年までに249億2,000万米ドルに達すると予測されています。
最も急速に拡大している地域はどこですか?
アジア太平洋が2031年にかけてCAGR 31.40%の予測で最も高い成長をリードしており、政府投資と多言語モデル需要に支えられています。
エッジ展開が将来の成長にとって重要な理由は何ですか?
エッジモデルはより低いレイテンシ・強化されたプライバシー・削減された帯域幅コストを提供し、CAGR 27.25%の見通しで展開セグメントをリードしています。
どの産業垂直市場が最も積極的に投資しますか?
医療は、臨床意思決定支援・研究加速・患者エンゲージメントアプリケーションにより、CAGR 25.95%で成長すると予測されています。
規制は採用にどのような影響を与えますか?
中国の暫定措置やEU AI法などの政策はローカルトレーニングを促進し、コンプライアンスコストを引き上げ、購買者を説明可能で地域にホストされたモデルへと誘導します。
小規模モデルは巨大モデルを置き換えていますか?
企業はコスト効率の高い推論のために1,000億パラメータ未満のモデルを好みますが、3,000億パラメータ超の超大規模モデルは依然として複雑な推論タスクを支配しており、CAGR 29.05%で成長しています。
最終更新日:




