Размер и доля рынка распознавания голоса
Обзор рынка
| Период исследования | 2019 - 2030 |
|---|---|
| Размер Рынка (2025) | 18.39 Миллиардов долларов США |
| Размер Рынка (2030) | 51.72 Миллиардов долларов США |
| Темп роста (2025 - 2030) | 22.97% CAGR |
| Самый Быстрорастущий Рынок | Азиатско-Тихоокеанский регион |
| Самый Большой Рынок | Северная Америка |
| Концентрация Рынка | Средний |
Ключевые игроки
*Отказ от ответственности: основные игроки отсортированы в произвольном порядке Изображение © Mordor Intelligence. Повторное использование требует указания авторства в соответствии с CC BY 4.0. |
|
Анализ рынка распознавания голоса от Mordor Intelligence
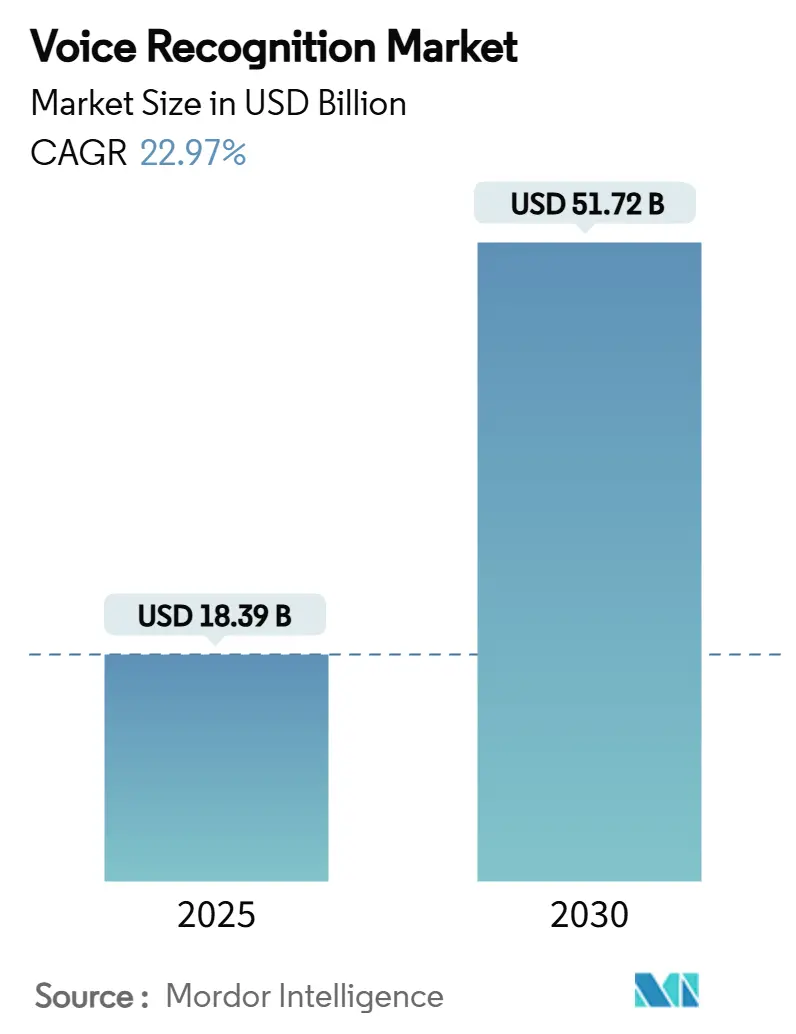
Размер мирового рынка распознавания голоса достиг 18,39 млрд долл. США в 2025 году и прогнозируется к росту со среднегодовым темпом 22,97% для достижения 51,72 млрд долл. США к 2030 году. Расширение рынка отражает три параллельных силы: быстрое развертывание периферийных наборов микросхем искусственного интеллекта (ИИ), регулятивное давление на модернизацию сетей экстренной связи и миграцию предприятий к голосовой биометрии для аутентификации клиентов. Архитектуры, ориентированные на программное обеспечение, теперь доминируют, поскольку 70,7% рыночной стоимости сосредоточено в наборах для разработки программного обеспечения и платформах интерфейса прикладного программирования, в то время как облачное развертывание составляет 62,1% внедрений в 2024 году. В региональном плане Азия лидировала с долей рынка 32,5% в 2024 году на фоне спроса на многоязычные интерфейсы и сильных экосистем производства микросхем; технология распознавания речи оставалась основным технологическим столпом с долей 81,2%, однако встроенная обработка на устройстве показала самый быстрый среднегодовой темп роста 25%, демонстрируя решительный переход от конструкций только для облака к гибридным или полностью локальным движкам вывода.
Ключевые выводы отчета
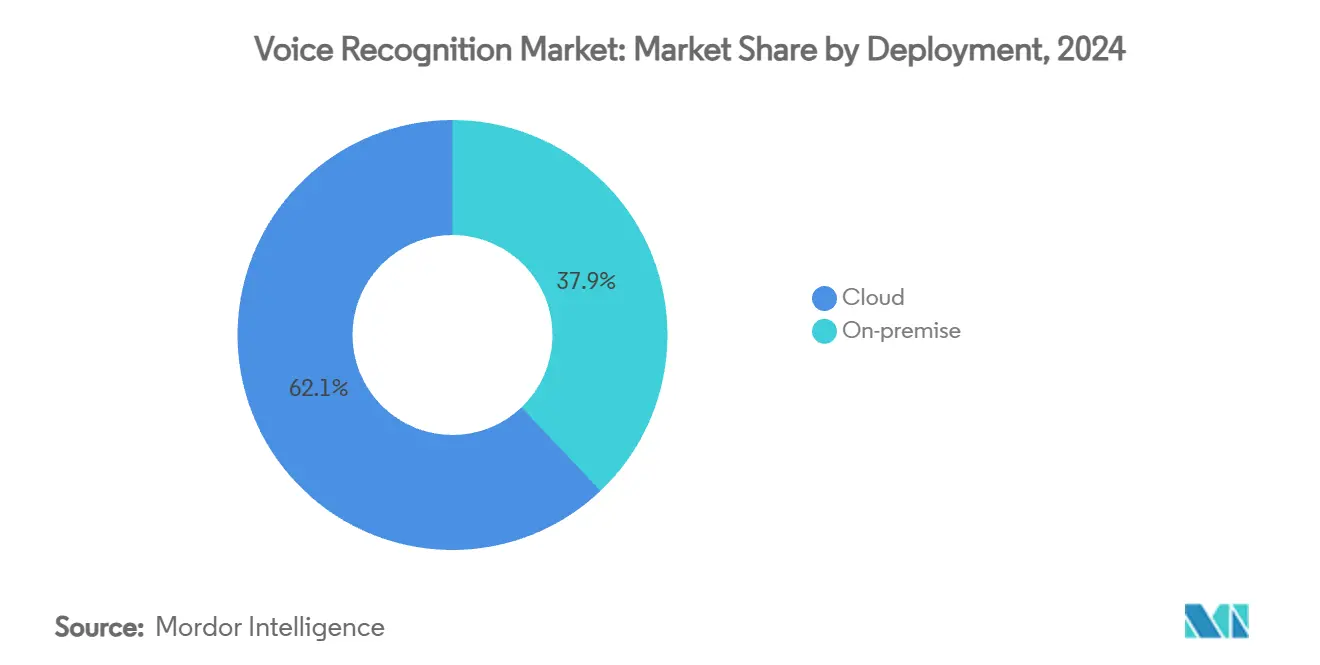
- По типу развертывания облачные платформы удерживали 62,1% доли рынка распознавания голоса в 2024 году и прогнозируются к росту со среднегодовым темпом 24,0% до 2030 года.
- По компонентам программное обеспечение и SDK лидировали с долей выручки 70,7% в 2024 году, в то время как услуги готовятся к самому высокому среднегодовому темпу роста 23,7% до 2030 года.
- По технологиям распознавание речи командовало долей 81,2% размера рынка распознавания голоса в 2024 году, тогда как встроенный периферийный голосовой ИИ прогнозируется к росту на 25,0% в год до 2030 года.
- По устройствам смартфоны и планшеты захватили 47,4% доли рынка распознавания голоса в 2024 году; носимые устройства демонстрируют самый быстрый среднегодовой темп роста 24,3% до 2030 года.
- По применению голосовой поиск и команды удерживали долю 38,5% в 2024 году, в то время как приложения аутентификации и безопасности растут со среднегодовым темпом роста 25,5%.
- По вертикальным сегментам конечных пользователей потребительская электроника лидировала с долей 41,1%, однако банковские и финансовые услуги являются самым быстрым восходящим сегментом со среднегодовым темпом роста 23,1%.
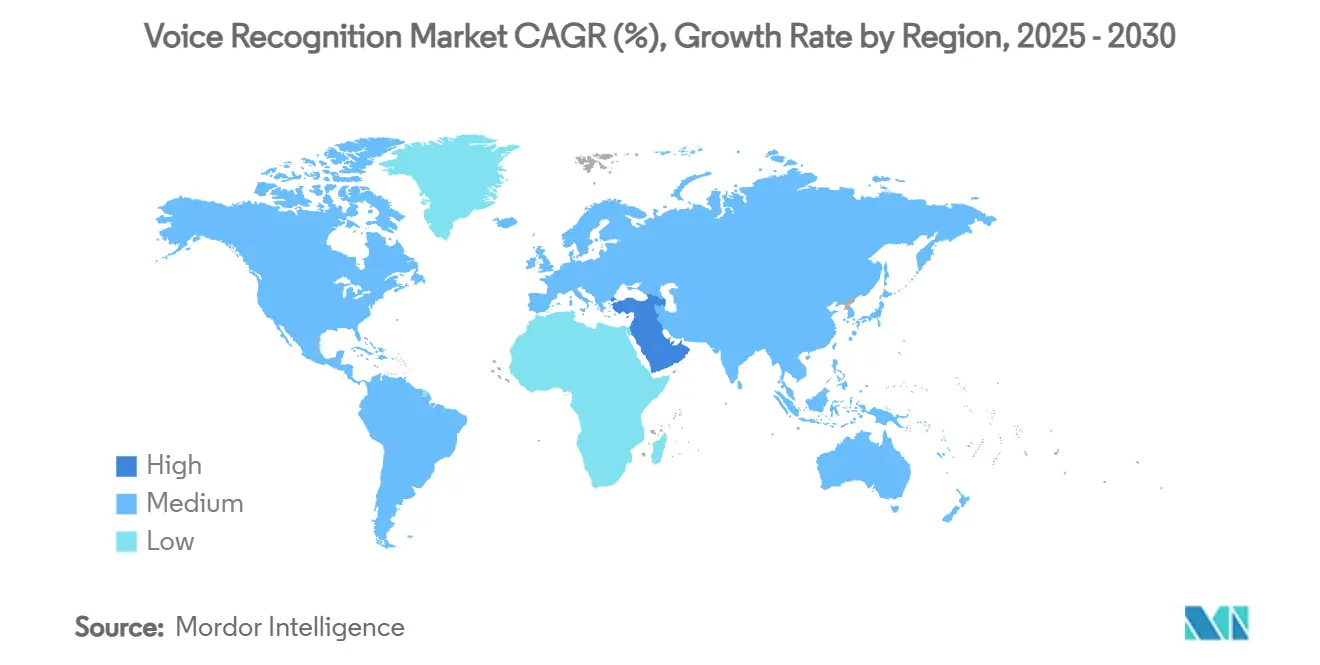
- По географии Азия составила 32,5% мирового дохода в 2024 году, тогда как Ближний Восток отслеживает среднегодовой темп роста 23,1% до 2030 года.
Глобальные тенденции и аналитические данные рынка распознавания голоса
Анализ влияния драйверов
| Драйвер | (~) % влияние на прогноз среднегодового темпа роста | Географическая релевантность | Временные рамки воздействия |
|---|---|---|---|
| Взрыв голосовых ИИ-чипов в периферийных устройствах по всей Азии | +4.2% | Азиатско-Тихоокеанский регион как ядро, распространение на глобальные рынки | Среднесрочная перспектива (2-4 года) |
| Регулятивный толчок для модернизации голосовых служб экстренного вызова 911 и экстренного диспетчерского управления в Северной Америке | +3.8% | Северная Америка, с регулятивным влиянием в Европе | Краткосрочная перспектива (≤ 2 лет) |
| Переход автомобильных OEM к встроенным голосовым ОС для персонализации кокпита | +5.1% | Глобально, с ранним внедрением в Европе и Северной Америке | Среднесрочная перспектива (2-4 года) |
| Внедрение голосовой биометрии в банковско-финансовых услугах и страховании для замены аутентификации на основе знаний в Европе | + 2.9% | Европа, с расширением в Азиатско-Тихоокеанский регион и Северную Америку | Краткосрочная перспектива (≤ 2 лет) |
| Быстрое распространение голосовой торговли в домохозяйствах, ориентированных на умные колонки | +3.4% | Северная Америка и Европа, формирующийся в Азиатско-Тихоокеанском регионе | Среднесрочная перспектива (2-4 года) |
| Рост спроса на многоязычный голосовой UX на развивающихся рынках АТЭС | + 2.8% | Азиатско-Тихоокеанский регион, с применением на Ближнем Востоке и в Африке | Долгосрочная перспектива (≥ 4 лет) |
| Источник: Mordor Intelligence | |||
Взрыв голосовых ИИ-чипов в периферийных устройствах по всей Азии
Выпуск 14 офлайн-чипов ИИ речи компанией Chipintelli и модели MR Breeze ASR 25 от MediaTek сигнализируют об эскалации инвестиций в специализированные полупроводники, оптимизированные для региональных языков.[1]Chipintelli Technology Co. Ltd., "Company Profile," chipintelli.com Локализация обеспечивает меньшую задержку, решает проблемы конфиденциальности, связанные с облачной потоковой передачей, и укрепляет отечественные цепочки поставок, которые исторически зависели от североамериканских гиперскейлеров. Азиатские полупроводниковые фирмы используют это преимущество, чтобы предложить OEM-производителям устройств комплексные голосовые стеки, которые обрабатывают переключение кодов на таких рынках, как Индонезия, Вьетнам и Индия, укрепляя лидерство региона в инновациях периферийного вывода.
Регулятивный толчок для модернизации голосовых служб экстренного вызова 911 и экстренного диспетчерского управления в Северной Америке
Новые правила FCC обязывают американских операторов маршрутизировать звонки 911 через протокол инициации сеансов на основе IP, сократить неправильную маршрутизацию ниже радиуса 165 метров с 90% уверенностью и поддерживать текст и видео в реальном времени.[2] Federal Communications Commission, "Facilitating Implementation of Next Generation 911 Services," federalregister.gov Поставщики распознавания голоса, позиционированные вокруг экстренных служб, получают предсказуемый рост доходов, поскольку сроки соответствия попадают в горизонт 6-12 месяцев для национальных и региональных операторов. Мандат создает шаблон, который, вероятно, повлияет на европейские сети общественной безопасности, расширив общий адресуемый спрос на голосовую аналитику, которая обогащает данные инцидентов транскрибированной речью и метаданными.
Переход автомобильных OEM к встроенным голосовым ОС для персонализации кокпита
Развертывание Volkswagen через эфир Cerence Chat Pro иллюстрирует стратегический поворот от зеркалирования смартфонов к глубоко встроенным голосовым операционным системам, которые наполняют профили водителя, диагностику транспортного средства и элементы управления информационно-развлекательными системами. Модель CaLLM Edge от Cerence сжимает 3,8 миллиарда параметров для локального запуска, уменьшая зависимость от покрытия сети при сохранении разговорных нюансов. OEM-производители открывают дифференциацию в пользовательском опыте и сокращают постоянные сборы за облачную обработку, хотя первоначальные расходы на обучение модели остаются высокими.
Внедрение голосовой биометрии в банковско-финансовых услугах и страховании для замены аутентификации на основе знаний в Европе
Обязательство Bank of Ireland в размере 34 млн евро (37 млн долл. США) в голосовую биометрию свидетельствует о широком движении финансовых услуг к биометрической многофакторной аутентификации, которая сокращает среднее время обработки в колл-центре и блокирует мошенничество социальной инженерии. Атаки клонирования голоса, способные обманывать системы с высокими показателями успеха, побудили к многослойной защите, которая объединяет пассивное обнаружение живости с аналитикой поведения транзакций. Тенденция ускоряет спрос на интегрированные платформы, которые объединяют распознавание речи с оценкой рисков и управлением согласием.
Анализ влияния ограничений
| Ограничение | (~) % влияние на прогноз среднегодового темпа роста | Географическая релевантность | Временные рамки воздействия |
|---|---|---|---|
| Пробелы в распознавании акцентов и диалектов, ограничивающие внедрение в Африке | -2.1% | Африка, с побочными эффектами на развивающихся рынках | Долгосрочная перспектива (≥ 4 лет) |
| Правила конфиденциальности (GDPR, India DPDP), ограничивающие хранение голосовых данных в облаке | -3.2% | Европа и Индия, с глобальными последствиями для соответствия | Краткосрочная перспектива (≤ 2 лет) |
| Высокая стоимость аннотированных корпусов речи для конкретных доменов | -1.8% | Глобально, с более высоким влиянием на развивающихся рынках | Среднесрочная перспектива (2-4 года) |
| Постоянные отставания в точности в шумных промышленных средах | -2.4% | Глобально, сконцентрировано в производственных регионах | Среднесрочная перспектива (2-4 года) |
| Источник: Mordor Intelligence | |||
Пробелы в распознавании акцентов и диалектов, ограничивающие внедрение в Африке
Тесты по 93 африканским акцентам показали уровни ошибок медицинских сущностей, которые все еще требовали 25-34% уточнения через тонкую настройку для конкретных акцентов. Набор данных NaijaVoices на 1 800 часов сократил уровни ошибок слов для моделей Whisper на 75,86%, но стоимость и сложность курирования культурно богатых корпусов замедляют коммерческие развертывания. Посевной раунд Intron Health в размере 1,6 млн долл. США подчеркивает признание инвесторами проблемы, однако также выделяет капитальные требования локализованного обучения моделей.
Правила конфиденциальности (GDPR, India DPDP), ограничивающие хранение голосовых данных в облаке
Голосовые записи считаются биометрическими идентификаторами, которые запускают повышенные обязательства по согласию, хранению и удалению согласно GDPR и Акту о защите цифровых персональных данных Индии. Несоблюдение грозит штрафами до 4% от глобального оборота.[3]HeyData, "Privacy Protection in Voice AI," heydata.eu Облачные поставщики отвечают региональными центрами обработки данных и более сильным шифрованием, однако эти корректировки разрушают преимущество стоимости централизованной обработки и ускоряют миграцию к локальным или гибридным развертываниям.
Сегментный анализ
По развертыванию: доминирование облака обеспечивает масштабируемость
Облачная доставка генерировала 62,1% мирового дохода в 2024 году, и эта доля прогнозируется к расширению, поскольку предприятия приоритизируют быстрое развертывание, непрерывные обновления моделей и широкое языковое покрытие. Финансовые учреждения и поставщики здравоохранения все больше выбирают гибридные архитектуры, которые сохраняют необработанные записи на месте, но объединяют аналитические данные обучения моделей в облаке. Подход балансирует соответствие с производительными преимуществами агрегированного обучения. Локальные развертывания, следовательно, остаются релевантными для мандатов суверенных данных, объясняя, почему сегмент все еще показывает двузначный рост до 2030 года.
Спрос на высокодоступные голосовые конечные точки побудил гиперскейлеров выставлять готовые API. Следовательно, общая стоимость владения падает для средних предприятий, и барьеры входа понижаются для независимых разработчиков. Результатом является более широкая воронка приложений для внедрения рынка распознавания голоса, распространяющаяся за пределы потребительских устройств в автоматизацию процессов, логистику и рабочие процессы полевого обслуживания. Размер рынка распознавания голоса для облачных внедрений готов приблизиться к 32 млрд долл. США к 2030 году, отражая как новые рабочие нагрузки, так и расширение существующих развертываний.
По компонентам: программные платформы обеспечивают интеграцию
Программные платформы захватили 70,7% мирового спроса в 2024 году, решительный марж, который подкрепляет поворот отрасли от проприетарного аппаратного обеспечения к модульному, удобному для разработчиков инструментарию. Доступность RESTful API и предварительно построенных языковых моделей исключает необходимость в специализированном кремнии во многих случаях использования. Услуги, хотя и представляют меньшую базу, растут со среднегодовым темпом роста 23,7%, поскольку предприятия привлекают специализированных поставщиков для настройки домена, адаптации акцента и соответствия безопасности.
Аппаратное обеспечение сохраняет релевантность там, где имеют значение периферийная задержка, офлайн-доступность или акустическое формирование луча, например, в автомобильных информационно-развлекательных системах или промышленных нашлемных дисплеях. Однако большинство новых участников обходят аппаратное обеспечение, потребляя предложения платформы как услуги, иллюстрируя расширяющийся разрыв между горизонтально ориентированными поставщиками программного обеспечения и вертикально интегрированными специалистами по аппаратному обеспечению.
По технологиям: распознавание речи лидирует с ускорением периферийного ИИ
Распознавание речи внесло вклад в 81,2% дохода 2024 года, однако его темп роста все больше исходит от встроенного вывода, который перемещает транскрипцию ближе к микрофону. Прорывы сжатия моделей позволяют многомиллиардным параметрическим сетям, таким как CaLLM Edge, работать на платах автомобильных информационно-развлекательных систем или наборах микросхем умных часов без облачного резервирования. Периферийное выполнение снижает риск конфиденциальности и сетевую задержку, ключевые факторы для рабочих нагрузок здравоохранения и обороны.
Случаи использования верификации говорящего масштабируются параллельно, подкрепленные регулятивным выравниванием по многофакторной аутентификации в финансах. Вместе два под-сегмента укрепляют коммерческую предпосылку, что голос как модальность требует функций как распознавания, так и подтверждения личности для достижения принятия предприятием. Размер рынка распознавания голоса встроенного под-сегмента ожидается превысить 10 млрд долл. США к 2030 году, удерживая лидерство среднегодового темпа роста 25% над альтернативами только облака.
По типу устройств: смартфоны доминируют, носимые устройства ускоряются
Мобильные телефоны оставались якорем, генерируя 47,4% мирового дохода в 2024 году. Их установленная база предлагает как масштаб, так и испытательную площадку для продвижения акустических моделей через федеративное обучение. Между тем, носимые устройства показывают среднегодовой темп роста 24,3%, поскольку OEM-производители встраивают большие массивы микрофонов и нейронные ускорители в наушники и часы. Bose добавил этап формирования луча с тройным микрофоном в свои QuietComfort Earbuds, который обеспечивает обнаружение пробуждающего слова в ветреных условиях. EarFun интегрировал перевод в реальном времени в наушники стоимостью менее 100 долл. США, подчеркивая демократизацию премиальных функций.
Автомобильные системы обеспечивают следующую волну объема, поскольку OEM-производители стандартизируют встроенные микрофоны на всех уровнях комплектации для оповещений о безопасности и персонализации кокпита. Промышленные гарнитуры остаются нишевыми, но стратегическими, со спросом, связанным с инспекцией без рук, удаленной помощью и соответствием безопасности в шумных условиях.
По применению: голосовой поиск и команды лидируют с ростом безопасности
Функции голосового поиска и команд генерировали 38,5% дохода 2024 года, в первую очередь через запросы смартфонов и умных колонок. Однако самый быстрый среднегодовой темп роста 25,5% происходит в аутентификации и безопасности, ответ на мошенничество колл-центров и требования бесконтактного контроля доступа в банковских и инфраструктурных секторах. Услуги транскрипции ускоряются, поскольку мандаты доступности требуют многоязычных субтитров в медиа-стриминге, и поскольку юридические и медицинские профессионалы ищут автоматизированную документацию. Внедрение здравоохранения оказывается долговечным. Dragon Copilot от Microsoft облегчает выгорание врачей, составляя заметки непосредственно в электронные медицинские записи. Британская NHS нацелена на развертывание окружающего голоса к 2027 году, показывая импульс для развертываний национального масштаба.
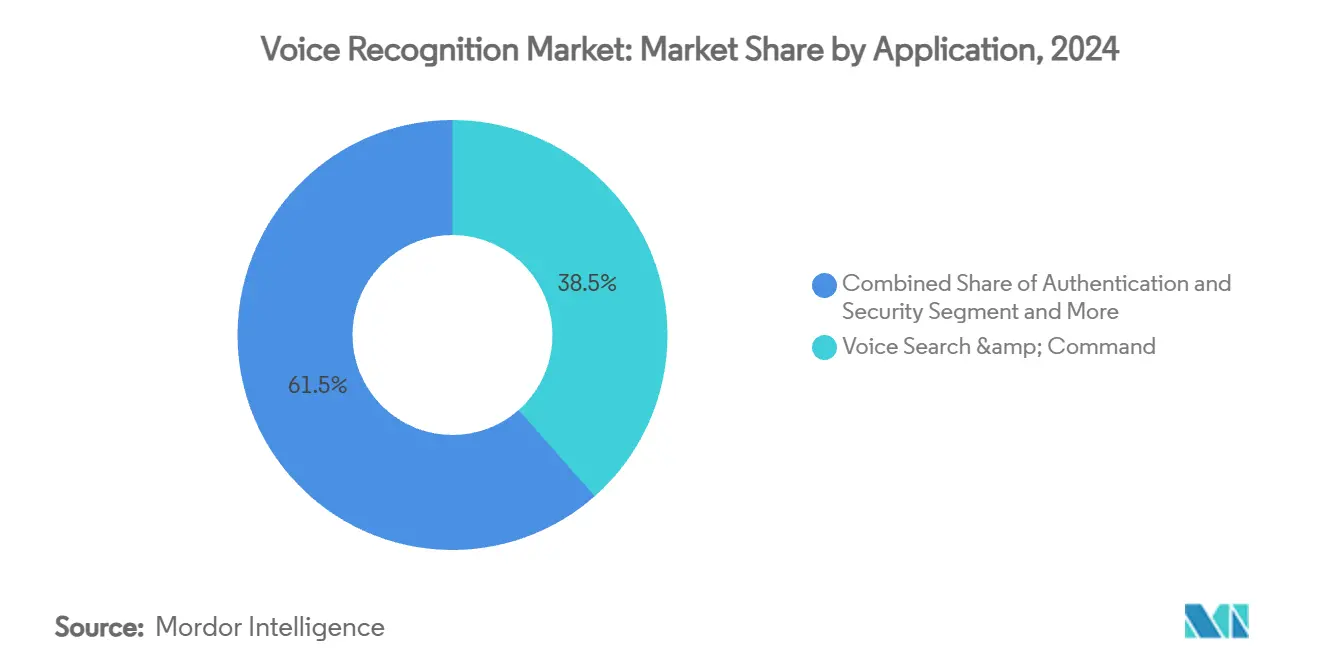
Примечание: Доли сегментов всех отдельных сегментов доступны при покупке отчета
По вертикальным сегментам конечных пользователей: потребительская электроника лидирует с ускорением банковско-финансовых услуг и страхования
Потребительская электроника удерживала долю 41,1% в 2024 году, закрепленную в смартфонах и расширяющуюся в телевизоры, бытовые приборы и хабы умного дома. Автомобильная промышленность следует близко, подпитываемая интеграцией генеративного ИИ, которая контекстуализирует голосовые команды с навигационными, комфортными и развлекательными данными. Банковские и финансовые услуги, однако, отмечают самый быстрый среднегодовой темп роста 23,1%, движимые обязательной регулятором сильной аутентификацией клиентов и императивами оптимизации затрат. Здравоохранение, правительственные и оборонные учреждения внедряют голосовые модальности для доступности и операционной эффективности. Промышленные пользователи остаются ограниченными акустическим шумом, но тестируют модули подавления помех, которые поднимают точность на 18 процентных пунктов в пилотных настройках.
Географический анализ
Азия генерировала 32,5% оборота 2024 года, отражая полупроводниковые мощности региона и лингвистическое разнообразие. Внутренняя политика поддерживает ускорение ИИ; инициатива Японии по финансированию языковых моделей Юго-Восточной Азии является одним примером. Северная Америка остается хабом ранних последователей технологий, но уступила долю Азии из-за агрессивной локализации и более низких затрат на устройства. Европа росла устойчиво, под влиянием тематического внедрения автомобильной промышленности и банковско-финансовых услуг и страхования.
Ближний Восток демонстрирует самый быстрый среднегодовой темп роста 23,1%, поскольку программы умных городов Персидского залива встраивают разговорные киоски в инфраструктуру гражданских услуг. Южная Америка фиксирует рост в средних подростковых цифрах от голосового поиска электронной коммерции и банковской аутентификации. Африка сталкивается с отставанием, поскольку разнообразие акцентов усложняет универсальные модели; однако донорские языковые проекты и обновления телекоммуникаций могут разблокировать скрытый спрос с 2027 года и далее.
Конкурентная среда
Рынок показывает умеренную концентрацию: топ-пять поставщиков составляют примерно 35-40% совокупного дохода, предполагая оценку 6 по 10-балльной шкале концентрации. Технологические инкумбенты обеспечивают свои позиции через широту платформы, проприетарные данные и глубину интеграции, в то время как автомобильные поставщики сотрудничают со специалистами по ИИ для встраивания голосовых ОС в приборные панели. В январе 2025 года Cerence расширила сотрудничество с NVIDIA для оптимизации своего набора CaLLM на TensorRT-LLM, укрепляя свой ров в низкозадержечном автомобильном выводе. Раунд серии C ElevenLabs на 180 млн долл. США при оценке 3,3 млрд долл. США демонстрирует капитал, текущий к нишевым лидерам голосового синтеза, которые монетизируют творческие экономики, а не общие рабочие процессы команд и контроля.
Конкурентная стратегия теперь зависит от четырех рычагов: (1) данные конкретного домена, которые повышают точность в высокоценных вертикалях, (2) многоязычное покрытие для развивающихся рынков, (3) архитектуры, сохраняющие конфиденциальность, такие как федеративное обучение, и (4) кремний-программное обеспечение со-дизайн для периферийных случаев использования. Стартапы дифференцируются, обращаясь к пробелам диалектов или предоставляя ультра-маленькие модели для устройств с батарейным питанием. Крупные облачные поставщики отвечают через приобретения; например, покупка Tenyx компанией Salesforce интегрирует разговорных голосовых агентов в свой стек Service Cloud для защиты от платформ клиентского опыта.
Лидеры индустрии распознавания голоса
-
Apple Inc.
-
Alphabet Inc. (Google LLC)
-
Amazon.com Inc.
-
Nuance Communications Inc. (Microsoft)
-
IBM Corporation
- *Отказ от ответственности: основные игроки отсортированы в произвольном порядке
Последние отраслевые разработки
- Январь 2025: ElevenLabs закрыла раунд серии C на 180 млн долл. США для ускорения исследований индийских языков и расширения корпоративных голосовых ИИ-услуг.
- Январь 2025: PlayAI привлекла 21 млн долл. США и представила многоходовую разговорную модель речи; сообщается, что Meta изучает переговоры о приобретении, сигнализируя о гонке за мультимодальными интерфейсными возможностями.
- Январь 2025: Cerence расширила сотрудничество с NVIDIA для улучшения оптимизации CaLLM на стеке NVIDIA AI Enterprise, нацеливаясь на ответ менее чем за 150 миллисекунд во встроенных приборных панелях.
- Ноябрь 2024: Cerence запустила CaLLM Edge, модель с 3,8 миллиардами параметров, разработанную для офлайн-обработки в автомобиле, уменьшающую зависимость от сотовой связи.
Глобальный охват отчета по рынку распознавания голоса
Способность компьютера или программного обеспечения принимать и анализировать речь или распознавать и следовать устным инструкциям называется распознавание голоса. С появлением ИИ и интеллектуальных помощников, включая Siri от Apple, Alexa от Amazon и Cortana от Microsoft, голосовое управление увеличило свою важность и использование.
Исследование сегментировано по типу развертывания (облачное, локальное), конечному пользователю (автомобильная промышленность, банковские услуги, телекоммуникации, здравоохранение, правительство, потребительские приложения, другие конечные пользователи) и географии (Северная Америка, Европа, Азиатско-Тихоокеанский регион, остальной мир). Размеры рынка и прогнозы предоставлены в стоимостном выражении в млн долл. США для всех вышеуказанных сегментов.
| Облачное |
| Локальное |
| Программное обеспечение/SDK |
| Аппаратное обеспечение (ASIC, DSP, массивы микрофонов) |
| Услуги (управляемые и профессиональные) |
| Распознавание речи |
| Биометрия говорящего/голоса |
| Встроенный/периферийный голосовой ИИ |
| Смартфоны и планшеты |
| Умные колонки и дисплеи |
| Автомобильные информационно-развлекательные системы и телематика |
| Носимые устройства (TWS, умные часы, AR/VR) |
| Коммерческие киоски и POS |
| Аутентификация и безопасность |
| Голосовой поиск и команды |
| Транскрипция и субтитры |
| Виртуальные помощники и чатботы |
| Медицинская документация |
| Автомобильная промышленность |
| Банковские и финансовые услуги |
| Телекоммуникации |
| Поставщики здравоохранения |
| Правительство и оборона |
| Потребительская электроника |
| Розничная торговля и электронная коммерция |
| Промышленность и производство |
| Северная Америка | Соединенные Штаты | |
| Канада | ||
| Мексика | ||
| Южная Америка | Бразилия | |
| Аргентина | ||
| Остальная Южная Америка | ||
| Европа | Соединенное Королевство | |
| Германия | ||
| Франция | ||
| Италия | ||
| Испания | ||
| Остальная Европа | ||
| Азиатско-Тихоокеанский регион | Китай | |
| Япония | ||
| Индия | ||
| Южная Корея | ||
| АСЕАН | ||
| Австралия | ||
| Новая Зеландия | ||
| Остальной Азиатско-Тихоокеанский регион | ||
| Ближний Восток и Африка | Ближний Восток | ССАГПЗ |
| Турция | ||
| Израиль | ||
| Остальной Ближний Восток | ||
| Африка | Южная Африка | |
| Нигерия | ||
| Египет | ||
| Остальная Африка | ||
| По развертыванию | Облачное | ||
| Локальное | |||
| По компонентам | Программное обеспечение/SDK | ||
| Аппаратное обеспечение (ASIC, DSP, массивы микрофонов) | |||
| Услуги (управляемые и профессиональные) | |||
| По технологиям | Распознавание речи | ||
| Биометрия говорящего/голоса | |||
| Встроенный/периферийный голосовой ИИ | |||
| По типу устройств | Смартфоны и планшеты | ||
| Умные колонки и дисплеи | |||
| Автомобильные информационно-развлекательные системы и телематика | |||
| Носимые устройства (TWS, умные часы, AR/VR) | |||
| Коммерческие киоски и POS | |||
| По применению | Аутентификация и безопасность | ||
| Голосовой поиск и команды | |||
| Транскрипция и субтитры | |||
| Виртуальные помощники и чатботы | |||
| Медицинская документация | |||
| По вертикальным сегментам конечных пользователей | Автомобильная промышленность | ||
| Банковские и финансовые услуги | |||
| Телекоммуникации | |||
| Поставщики здравоохранения | |||
| Правительство и оборона | |||
| Потребительская электроника | |||
| Розничная торговля и электронная коммерция | |||
| Промышленность и производство | |||
| По географии | Северная Америка | Соединенные Штаты | |
| Канада | |||
| Мексика | |||
| Южная Америка | Бразилия | ||
| Аргентина | |||
| Остальная Южная Америка | |||
| Европа | Соединенное Королевство | ||
| Германия | |||
| Франция | |||
| Италия | |||
| Испания | |||
| Остальная Европа | |||
| Азиатско-Тихоокеанский регион | Китай | ||
| Япония | |||
| Индия | |||
| Южная Корея | |||
| АСЕАН | |||
| Австралия | |||
| Новая Зеландия | |||
| Остальной Азиатско-Тихоокеанский регион | |||
| Ближний Восток и Африка | Ближний Восток | ССАГПЗ | |
| Турция | |||
| Израиль | |||
| Остальной Ближний Восток | |||
| Африка | Южная Африка | ||
| Нигерия | |||
| Египет | |||
| Остальная Африка | |||
Ключевые вопросы, отвеченные в отчете
Какова текущая оценка рынка распознавания голоса?
Рынок распознавания голоса оценивается в 18,39 млрд долл. США в 2025 году и ожидается достичь 51,72 млрд долл. США к 2030 году при среднегодовом темпе роста 22,97%.
Какая модель развертывания удерживает наибольшую долю?
Облачное развертывание лидирует с долей 62,1% в 2024 году, поскольку предприятия предпочитают масштабируемые архитектуры, управляемые API.
Почему носимые устройства являются самым быстрорастущим сегментом устройств?
Носимые устройства показывают среднегодовой темп роста 24,3% благодаря улучшениям во встроенных микрофонах и ИИ-ускорителях, которые обеспечивают функции перевода и мониторинга здоровья.
Как правила конфиденциальности формируют дизайн продукта?
GDPR и DPDP Индии ограничивают хранение голосовых данных, побуждая поставщиков принимать периферийную или гибридную обработку для минимизации облачного хранилища и затрат на соответствие.
Последнее обновление страницы:

