Tamanho e Participação do Mercado de Web Scraping
Visão Geral do Mercado
| Período de Estudo | 2020 - 2031 |
|---|---|
| Tamanho do Mercado (2026) | 1.56 Bilhões de dólares |
| Tamanho do Mercado (2031) | 3.49 Bilhões de dólares |
| Taxa de crescimento (2026 - 2031) | 17.39% CAGR |
| Mercado de Crescimento Mais Rápido | Ásia-Pacífico |
| Maior Mercado | América do Norte |
| Concentração do Mercado | Médio |
Principais jogadores *Isenção de responsabilidade: Principais participantes classificados em nenhuma ordem específica Imagem © Mordor Intelligence. O reuso requer atribuição conforme CC BY 4.0. | |
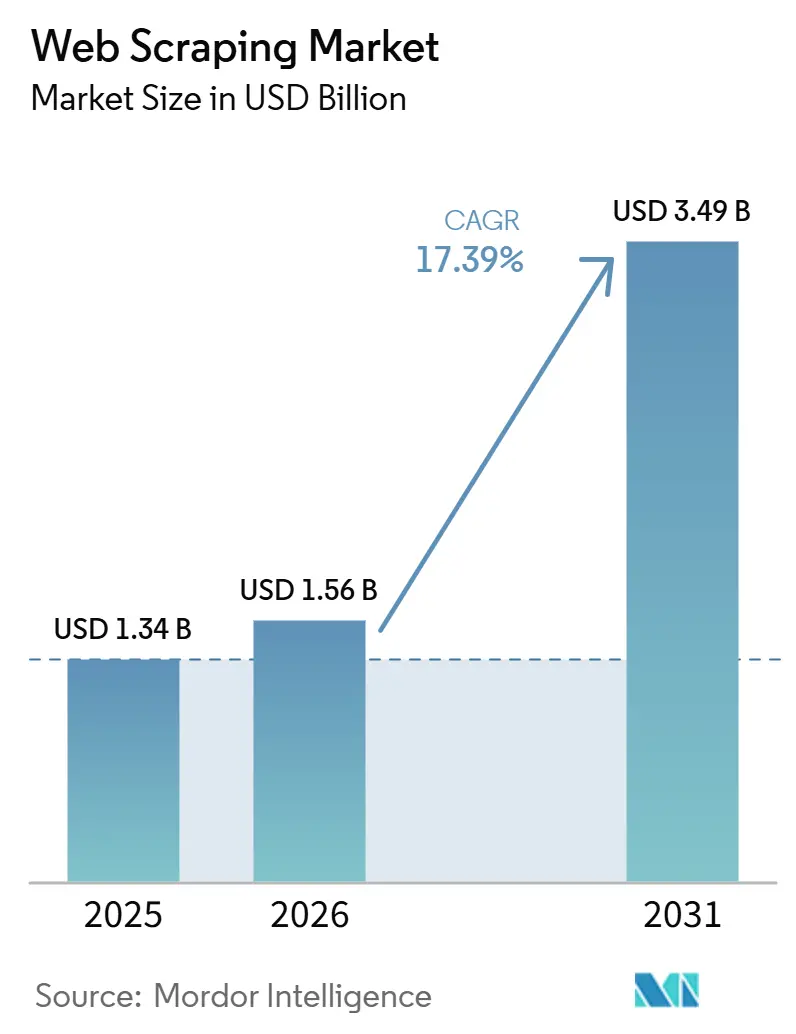
Análise do Mercado de Web Scraping por Mordor Intelligence
O tamanho do mercado de web scraping foi avaliado em 1,34 bilhão de USD em 2025 e estima-se que cresça de 1,56 bilhão de USD em 2026 para atingir 3,49 bilhões de USD até 2031, a um CAGR de 17,39% durante o período de previsão (2026-2031). A demanda sólida decorre de empresas que correm para substituir o acesso reduzido a APIs, preparar modelos de IA generativa e acompanhar as necessidades de inteligência competitiva em tempo real. As guerras de precificação no e-commerce, a ascensão de dados alternativos em serviços financeiros e a acelerada adoção da nuvem criam um fluxo constante de cargas de trabalho de extração em grande volume. Ao mesmo tempo, o escrutínio regulatório e as sofisticadas defesas anti-bot empurram os compradores em direção a soluções de maior valor e prontas para conformidade, capazes de sustentar taxas de sucesso sob restrições técnicas e legais cada vez mais rígidas. Provedores capazes de combinar escala, adaptabilidade orientada por IA e suporte de conformidade específico por região estão posicionados para capturar receitas desproporcionais à medida que o mercado de web scraping migra da coleta de commodities para infraestrutura de dados de missão crítica.
Principais Conclusões do Relatório
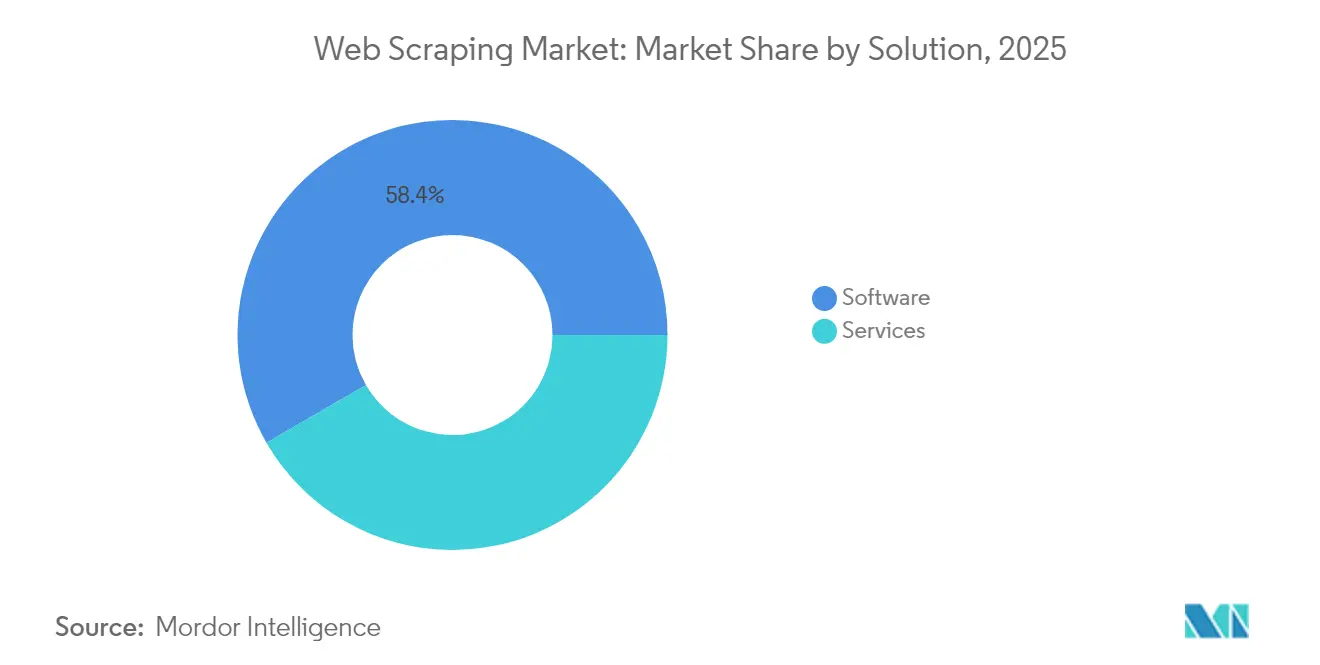
- Por tipo de solução, o software manteve uma participação de receita de 58,35% em 2025, enquanto os serviços devem registrar um CAGR de 18,62% até 2031.
- Por modo de implantação, os modelos em nuvem responderam por 67,45% do tamanho do mercado de web scraping em 2025 e devem se expandir a um CAGR de 17,80%.
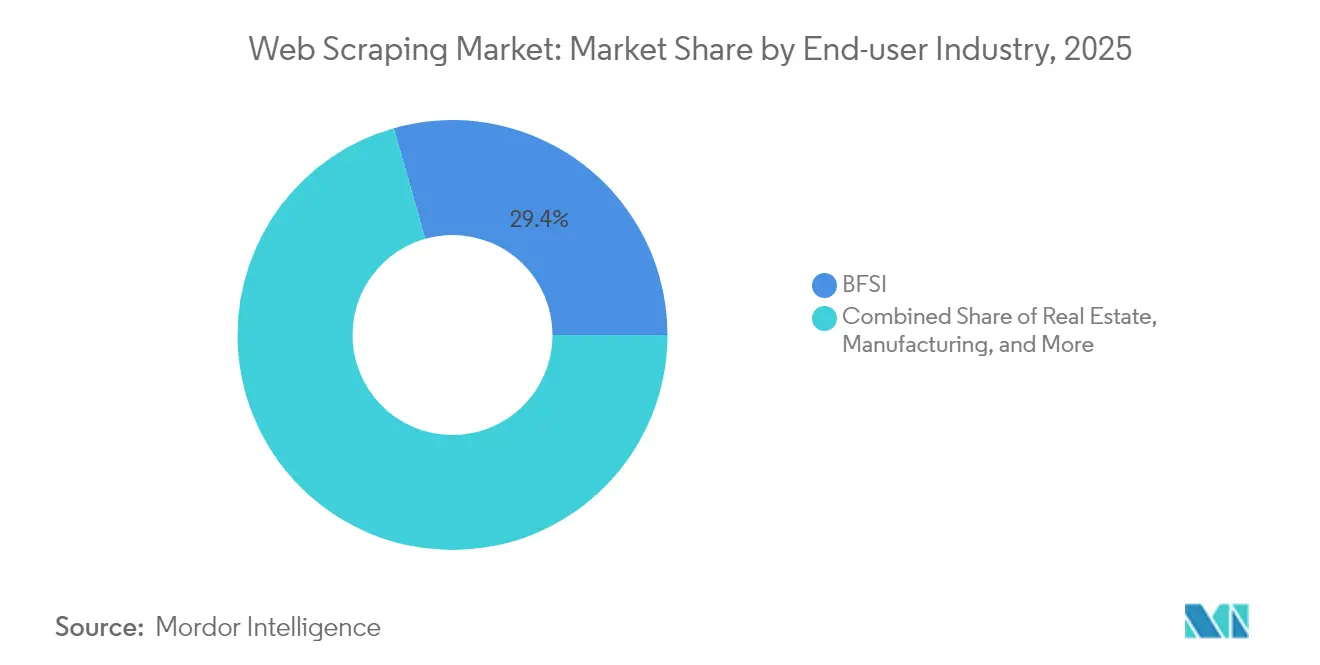
- Por setor de usuário final, Serviços Bancários, Financeiros e de Seguros capturaram 29,40% do tamanho do mercado de web scraping em 2025; Publicidade e Mídia avança a um CAGR de 18,80% até 2031.
- Por caso de uso, raspagem de dados e ETL responderam por 36,20% do mercado de web scraping em 2025, enquanto o segmento de monitoramento de preços e concorrência cresce a um CAGR de 18,34%.
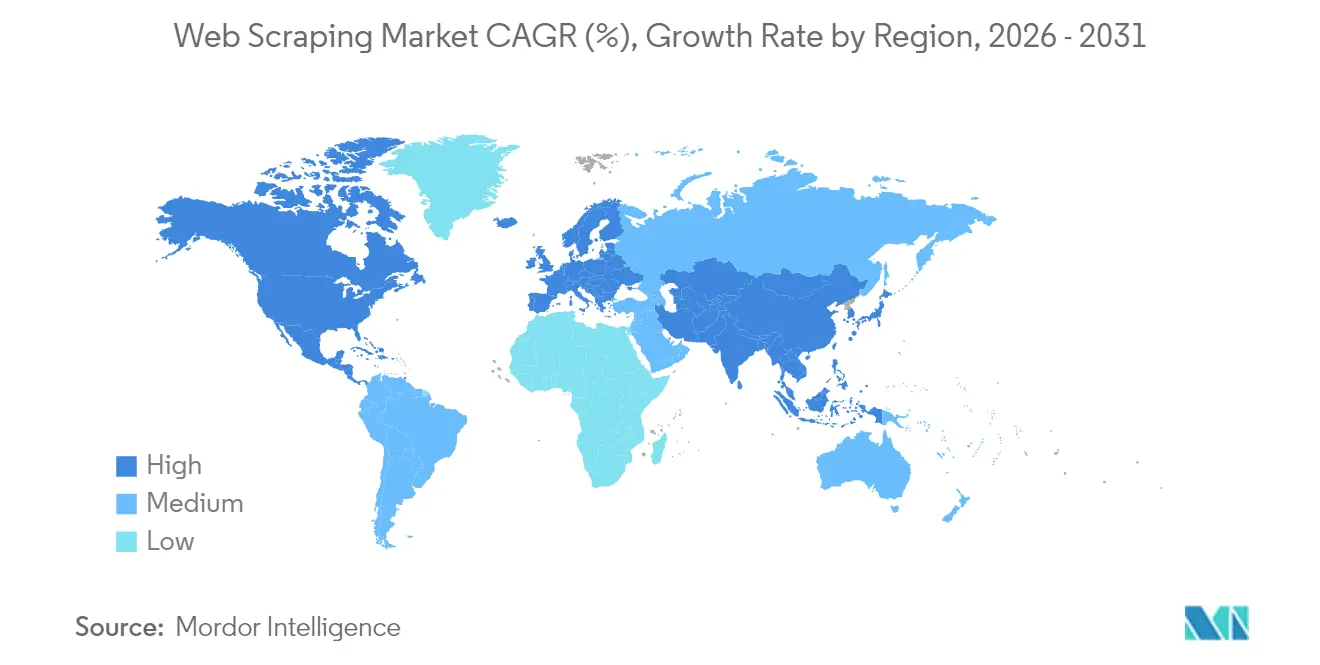
- Por geografia, a América do Norte liderou com 34,08% da participação no mercado de web scraping em 2025; a Ásia-Pacífico deve entregar o CAGR mais rápido de 18,66% até 2031.
Nota: Os números de tamanho de mercado e previsão neste relatório são gerados usando a estrutura de estimativa proprietária da Mordor Intelligence, atualizada com os dados e insights mais recentes disponíveis até 2026.
Tendências e Perspectivas do Mercado Global de Web Scraping
Análise de Impacto dos Impulsionadores*
| Impulsionador | (~) % de Impacto na Previsão de CAGR | Relevância Geográfica | Prazo de Impacto |
|---|---|---|---|
| Crescimento do comércio eletrônico e dos mercados online | +3.2% | Global (América do Norte, Ásia-Pacífico concentrados) | Médio prazo (2-4 anos) |
| Avanços em IA/ML para extração de dados | +2.8% | Global (América do Norte e Europa lideram) | Longo prazo (≥ 4 anos) |
| Demanda crescente por dados alternativos em finanças | +2.1% | América do Norte, Europa, Ásia-Pacífico em expansão | Médio prazo (2-4 anos) |
| Descontinuação de APIs em grandes plataformas | +1.9% | Global (redes sociais e plataformas de conteúdo mais impactadas) | Curto prazo (≤ 2 anos) |
| Requisitos de dados de treinamento para IA generativa | +1.7% | Global (centros de desenvolvimento de IA) | Longo prazo (≥ 4 anos) |
| Mandatos de dados abertos revelando lacunas de dados | +0.8% | Europa e América do Norte | Médio prazo (2-4 anos) |
| Fonte: Mordor Intelligence | |||
Crescimento do comércio eletrônico e dos mercados online
As guerras de preços em tempo real levaram 81% dos varejistas dos Estados Unidos a adotar a extração automatizada de preços para estratégias de reprecificação dinâmica, ante 34% em 2020 [1]Actowiz Solutions, "Estatísticas de Adoção de Extração de Preços no Varejo 2025," actowiz.com. Os formatos de marketplace agora permeiam imóveis, mercearias e listagens automotivas, cada um exigindo visibilidade de estoque em nível de milissegundos. A escalada das medidas de mitigação de bots em sites de varejo paradoxalmente alimenta a demanda premium por scrapers resilientes que contornam a identificação de dispositivos e os desafios de JavaScript. Os modelos de comércio rápido e de vendas relâmpago ampliam ainda mais a oportunidade endereçável à medida que os comerciantes migram para promoções orientadas por dados em marketplaces regionais.
Avanços em IA/ML para extração de dados
Sessenta e cinco por cento das empresas utilizaram web scraping para alimentar projetos de IA e aprendizado de máquina em 2024, sinalizando uma mudança de scripts baseados em regras para algoritmos adaptativos que reduzem a sobrecarga de manutenção em 40% [2]BrowserCat, "Pesquisa sobre IA e Web Scraping 2024," browsercat.com. A mimicagem comportamental impulsionada por IA eleva as taxas de sucesso para 80–95% em sites altamente protegidos, enquanto a detecção dinâmica de modelos reduz o tempo de inatividade quando os layouts de página mudam. Fornecedores que incorporam aprendizado por reforço e impressões digitais sintéticas de navegador transformaram a extração inteligente em um diferencial premium em vez de uma commodity.
Demanda crescente por dados alternativos em finanças
O web scraping sustenta 67% dos programas de dados alternativos de consultores de investimentos dos Estados Unidos, um número que saltou 20 pontos percentuais durante 2024. A coleta em tempo real de notícias, registros e feeds de sentimento alimenta mesas de negociação algorítmica e motores de risco de crédito. Orçamentos robustos — 94% dos usuários planejam aumentar os gastos — sinalizam um fluxo de receita duradouro para provedores que combinam pipelines limpos com trilhas de auditoria exigidas por reguladores e alocadores de fundos.
Descontinuação de APIs em grandes plataformas
Redes sociais e editores de conteúdo continuam a erguer barreiras de pagamento em torno de interfaces programáticas, tornando o HTML extraído e a renderização dinâmica o caminho econômico para cobertura de dados em escala. Twitter, Reddit e outros serviços cortaram os níveis de acesso gratuito, levando as empresas a redirecionar gastos para navegadores headless e frotas de proxies distribuídos. O modelo de acesso pago da Cloudflare para bots de IA sublinha uma mudança mais ampla em direção à monetização de endpoints de dados, inclinando decisivamente a economia em favor de soluções sofisticadas do mercado de web scraping.
Análise de Impacto das Restrições*
| Restrição | (~) % de Impacto na Previsão de CAGR | Relevância Geográfica | Prazo de Impacto |
|---|---|---|---|
| Incerteza jurídica e ética | -2.3% | Global (mais rígida na Europa) | Médio prazo (2-4 anos) |
| Altos custos e complexidade técnica | -1.8% | Global (PMEs mais afetadas) | Curto prazo (≤ 2 anos) |
| Ferramentas avançadas de mitigação de bots | -1.5% | Global (foco em grandes plataformas) | Curto prazo (≤ 2 anos) |
| APIs oficiais canibalizando alguns casos de uso | -0.9% | Global (variável por setor) | Médio prazo (2-4 anos) |
| Fonte: Mordor Intelligence | |||
Incerteza jurídica e ética
A visão estrita da autoridade holandesa de proteção de dados sobre o RGPD em relação à extração de dados pessoais para treinamento de IA e as orientações de 2024 da Assembleia Global de Privacidade exigem base jurídica, transparência e retenção minimizada, elevando os gastos com conformidade em 86%. A multa de EUR 20 milhões da Itália contra um fornecedor de reconhecimento facial sinaliza um risco de queda significativo, enquanto o Departamento de Justiça dos Estados Unidos agora proíbe entidades de países de preocupação de acessar dados pessoais sensíveis, adicionando camadas de triagem geopolítica. Navegar por essas restrições transfronteiriças atrasa projetos e eleva os custos de revisão jurídica.
Altos custos e complexidade técnica
A Akamai relata que seu conjunto de gerenciamento de bots pode bloquear 82,3% do tráfego automatizado em páginas de produtos selecionadas, forçando os scrapers a investir em pools de proxies maiores, fazendas de navegadores personalizados e pilhas de evasão baseadas em IA. As PMEs sem capital lutam para acompanhar a corrida armamentista, frequentemente cedendo demandas de dados de nicho a provedores de serviços bem financiados. Os desafios de JavaScript em múltiplas camadas e os CAPTCHAs adaptativos inflam os orçamentos de computação e prolongam os ciclos de extração, corroendo o retorno sobre o investimento para operações menos otimizadas.
*Nossas previsões tratam os impactos dos impulsionadores e restrições como direcionais, e não aditivos. As previsões de impacto refletem o crescimento de base, os efeitos de composição e as interações entre variáveis.
Análise de Segmentos
Por Solução: Os Serviços Ganham Impulso Enquanto o Software Mantém Escala
Os produtos de software detiveram 58,35% da receita em 2025, evidenciando o conforto das empresas com frameworks de orquestração internos e extratores sem código. No entanto, os serviços avançam a um CAGR de 18,62% à medida que os compradores terceirizam verificações complexas de conformidade, manutenção de proxies rotativos e ajuste anti-bot. Os padrões de gastos mostram uma mudança em direção à adoção híbrida, em que equipes internas executam softwares empacotados para listas cotidianas enquanto empresas especializadas lidam com conjuntos de dados transfronteiriços ou juridicamente sensíveis. A normalização e validação de dados habilitadas por IA elevam as tarifas faturáveis para provedores de serviço completo, fortalecendo a fidelidade e a margem. Essa dinâmica garante que o mercado de web scraping permaneça equilibrado entre kits de ferramentas e ofertas gerenciadas, atendendo tanto a analistas que preferem fazer por conta própria quanto a corporações avessas ao risco.
A categoria de software se beneficiou de uma onda de lançamentos de código aberto e baixo código, entre eles o Thunderbit e o Crawlee para Python, que reduziram as barreiras de entrada para analistas de negócios. As equipes de segurança corporativa, no entanto, exigem cada vez mais auditorias externas e aprovações jurídicas, levando muitos a optarem por assinaturas de serviços acompanhadas de artefatos de conformidade documentados. Consequentemente, o tamanho do mercado de web scraping para serviços deve crescer de forma significativa, reduzindo a diferença de receita em relação ao software até 2031.



Por Modo de Implantação: A Infraestrutura em Nuvem Acelera a Adoção
As implantações baseadas em nuvem capturaram 67,45% do mercado de web scraping em 2025 e superarão outros modos a um CAGR de 17,80%. Pools de computação elástica distribuem navegadores sem interface gráfica por pontos de presença globais, o que é crucial quando as páginas servem conteúdo específico por região ou bloqueiam endereços IP repetitivos. Provedores como a Oxylabs agora empacotam proxies residenciais rotativos, gerenciamento de sessões e monitoramento de conformidade regulatória como APIs prontas para uso. Essa abstração permite que os clientes escalem milhares de requisições paralelas sem provisionar servidores físicos.
As implementações locais sobrevivem em setores altamente regulamentados, particularmente saúde e banco central, onde cláusulas de soberania de dados exigem armazenamento local. Mesmo nesses setores, os raspadores em contêineres aumentam cada vez mais a capacidade em regiões de nuvem pública sancionadas durante picos de tráfego. Olhando para o futuro, complementos de computação de borda que processam HTML bruto mais próximo ao ponto de coleta devem reduzir a latência para atualizações de leilões ou tarifas de passagens aéreas, reforçando o papel central da nuvem no mercado de web scraping.
Por Setor do Usuário Final: Serviços Financeiros Ancoram a Demanda, Mídia Avança
Serviços Bancários, Financeiros e de Seguros retiveram 29,40% do tamanho do mercado de web scraping em 2025, à medida que fundos, credores e seguradoras alimentaram algoritmos de risco de crédito e negociação com notícias raspadas, dados de publicações de vagas de emprego e sentimento do consumidor. Requisitos rigorosos de auditoria favorecem provedores que incorporam rastreamento de linhagem de dados e alertas regulatórios. Publicidade e Mídia, embora menor hoje, registra o CAGR mais rápido de 18,80%. As agências buscam feeds unificados de desempenho de campanhas, precificação de editores e sinais de segurança de marca entregues em tempo quase real. As narrativas voltadas a investidores do setor de web scraping destacam cada vez mais esses dois segmentos como pilares gêmeos: um oferece recursos financeiros robustos e gastos recorrentes, o outro fornece volumes de crescimento acelerado de conteúdo não estruturado.
O varejo e o e-commerce permanecem essenciais, mas agora são usuários maduros. O crescimento decorre menos de compradores de primeira viagem e mais de casos de uso avançados, correspondência dinâmica de cupons, monitoramento de slots de entrega e rastreamento competitivo hiperlocal. Manufatura, saúde e órgãos do setor público expandem coletivamente a base endereçável ao adicionar vigilância da cadeia de suprimentos, feeds de buscadores de ensaios clínicos e projetos de dados abertos exigidos por governança às instalações existentes.
Por Caso de Uso: ETL Domina, Monitoramento de Preços Cresce Mais Rápido
As cargas de trabalho de raspagem de dados e ETL responderam por 36,20% do tamanho do mercado de web scraping em 2025, consolidando seu papel como integradores de back-office que alimentam data warehouses, hubs de MDM e lakehouses. Esses pipelines geralmente apresentam rastreamentos programados em milhares de domínios, lógica de diferencial incremental e mapeamento automatizado de esquemas. A extração de preços e inteligência competitiva, no entanto, avança a um CAGR de 18,34%, impulsionada por reprecificadores algorítmicos e motores de promoção orientados por IA que atualizam catálogos a cada hora ou com maior frequência. As mesas de dados financeiros aproveitam múltiplos clusters de casos de uso — notícias, registros regulatórios e sentimento — borrando as fronteiras entre dados alternativos puros e feeds de referência tradicionais. Em conjunto, esses padrões garantem que o mercado de web scraping continue a se diversificar muito além da coleta básica de URLs.
Raspagens de geração de leads, monitoramento de mídias sociais e pesquisa de ESG completam a demanda. Cada um adiciona solicitações de recursos exclusivos — integrações com CRM, detecção de idioma ou modelagem de tópicos — empurrando os fornecedores em direção a arquiteturas modulares. Como resultado, o mercado de web scraping permanece intensivo em inovação, com roteiros de produtos guiados por lacunas de fluxo de trabalho específicas por setor.
Análise Geográfica
A América do Norte controlou 34,08% da receita em 2025, sustentada pela profunda presença do setor de serviços financeiros dos Estados Unidos e pelos hubs de análise de dados de crescimento acelerado do Canadá. Os compradores regionais atribuem valor premium à conformidade documentada, evidenciada pelo fato de 67% dos consultores incorporarem fluxos de dados alternativos em processos de investimento. As novas regras do Departamento de Justiça dos Estados Unidos que restringem fluxos de dados sensíveis para adversários estrangeiros adicionam camadas de diligência devida, mas simultaneamente ampliam oportunidades para escritórios de serviços domésticos especializados em ingestão transfronteiriça lícita.
A Ásia-Pacífico é o território de crescimento mais rápido, avançando a um CAGR de 18,66% até 2031. Os exportadores manufatureiros da China dependem de feeds de raspagem de alfândega e transporte para calibrar a precificação, enquanto os campeões de serviços de TI da Índia incorporam a aquisição de dados em larga escala em contratos de terceirização de análise. Os programas de transformação digital corporativa do Japão estimulam a demanda local por frameworks de extração multilíngue. Os marketplaces do Sudeste Asiático aceleram a adoção à medida que super-aplicativos de logística, viagens e fintech travam batalhas de precificação em tempo real. Austrália e Nova Zelândia completam o impulso regional por meio de mesas de negociação de commodities que raspam rastreadores de escalas portuárias e satélites.
A Europa segue uma trajetória de conformidade em primeiro lugar. A postura restritiva do Conselho Europeu de Proteção de Dados sobre dados de treinamento de IA obriga fluxos de trabalho com avaliação de risco e pipelines de privacidade por design. Os provedores que incorporam anonimização, gerenciamento de consentimento e controles de minimização de dados desfrutam de uma vantagem competitiva. Os compradores do Reino Unido equilibram o alinhamento com o GDPR com um apetite crescente por dados alternativos de fintech, enquanto Alemanha e França favorecem construções de nuvem soberana para extrações críticas. A heterogeneidade regulatória em todo o continente sustenta a demanda por serviços consultivos que localizam frameworks caso a caso.

Cenário Competitivo
O mercado de web scraping permanece moderadamente fragmentado. Bright Data, Zyte, Apify e Oxylabs formam um nível de especialistas em infraestrutura de escala, mas nenhum controla uma participação dominante. A concorrência está migrando da coleta bruta para qualidade, tempo de atividade e conformidade. Os fornecedores se diferenciam nas taxas de sucesso contra conjuntos anti-bot, na amplitude dos pools de proxies e na orientação jurídica específica por região. A orquestração com infusão de IA — novas tentativas adaptativas, descoberta de seletores CSS orientada por modelos e rotulagem automática — tornou-se um requisito básico.
O posicionamento estratégico revela dois campos. As plataformas horizontais cortejam todos os segmentos com APIs plug-and-play, enquanto os players de nicho visam expertise profunda em domínios únicos, como tarifas de viagens ou classificações de lojas de aplicativos. O marketplace de pagamento por bot da Cloudflare sugere que os operadores de plataforma podem em breve monetizar feeds de dados diretos, potencialmente transformando antigos adversários em parceiros de canal. Os provedores capazes de migrar cedo para modelos de compartilhamento de receita ou endpoints de primeira parte curados protegerão as margens.
Os fluxos de investimento favorecem tecnologia avançada de contorno. Startups especializadas em camuflagem de navegadores headless, rotação dinâmica de impressões digitais e resolução de CAPTCHA no dispositivo atraem capital de risco, antecipando o aumento da sofisticação no bloqueio de tráfego. Em resposta, os incumbentes adquirem soluções pontuais para acelerar os roteiros de IA e incorporar monitores de conformidade em tempo real. Ao longo do horizonte de previsão, espera-se que os líderes de mercado consolidem redes de proxies menores e consultorias regionais de conformidade para reforçar a cobertura geográfica e a profundidade regulatória.
Líderes do Setor de Web Scraping
Bright Data Ltd.
Zyte Group Ltd.
Apify Technologies s.r.o.
Octopus Data, Inc.
Import.io Ltd.
- *Isenção de responsabilidade: Principais participantes classificados em nenhuma ordem específica

Desenvolvimentos Recentes do Setor
- Janeiro de 2025: O Departamento de Justiça dos Estados Unidos implementou regras abrangentes de proteção de dados que impedem o acesso a dados pessoais sensíveis por países de preocupação, reformulando os fluxos de trabalho de extração transfronteiriça.
- Janeiro de 2025: O Departamento de Saúde e Serviços Humanos dos Estados Unidos divulgou seu plano estratégico de IA, direcionando novos fundos para pesquisa médica orientada por dados que depende de coleta automatizada.
- Outubro de 2024: A Cloudflare apresentou um marketplace que permite aos editores cobrar bots de IA pelo acesso de extração, reformulando a economia de monetização de dados.
- Julho de 2024: A Apify lançou o Crawlee para Python, estendendo sua estrutura de rastreamento de código aberto para desenvolvedores Python e ampliando o ecossistema de contribuidores.


Research Methodology Framework and Report Scope
Definições de Mercado e Cobertura Principal
Nosso estudo define o mercado de web scraping como todas as plataformas de software comercial e serviços de extração gerenciados que rastreiam programaticamente páginas da web públicas, analisam conteúdo e entregam conjuntos de dados estruturados ou feeds ao vivo a clientes pagantes. A avaliação abrange receitas de licença, assinatura e serviços geradas por fornecedores especializados em coleta de dados em larga escala e pronta para conformidade.
Exclusão do escopo: Scripts internos de uso próprio executados exclusivamente dentro de uma empresa não são contabilizados.
Visão Geral da Segmentação
- Por Solução
- Software
- Serviços
- Por Modo de Implantação
- Nuvem
- Local
- Por Setor do Usuário Final
- BFSI
- Varejo e Comércio Eletrônico
- Imóveis
- Manufatura
- Governo
- Saúde
- Publicidade e Mídia
- Outros
- Por Caso de Uso
- Extração de Dados / ETL
- Monitoramento de Preços e Concorrência
- Geração de Leads e Inteligência de Vendas
- Dados Financeiros Alternativos
- Análise de Sentimento e Redes Sociais
- Por Geografia
- América do Norte
- Estados Unidos
- Canadá
- México
- América do Sul
- Brasil
- Argentina
- Restante da América do Sul
- Europa
- Alemanha
- Reino Unido
- França
- Itália
- Espanha
- Rússia
- Restante da Europa
- Ásia-Pacífico
- China
- Japão
- Índia
- Coreia do Sul
- Austrália e Nova Zelândia
- Restante da Ásia-Pacífico
- Oriente Médio e África
- Oriente Médio
- Arábia Saudita
- Emirados Árabes Unidos
- Turquia
- Restante do Oriente Médio
- África
- África do Sul
- Nigéria
- Quênia
- Restante da África
- Oriente Médio
- América do Norte
Metodologia de Pesquisa Detalhada e Validação de Dados
Pesquisa Primária
Entrevistas estruturadas com responsáveis por produtos de plataformas de dados, provedores de redes de proxies e responsáveis por aquisições na América do Norte, Europa e Ásia-Pacífico forneceram faixas de preços reais, taxas de retenção e custos de conformidade regionais que fontes de pesquisa de mesa raramente divulgam.
Pesquisa de Mesa
Os analistas da Mordor mapearam primeiro o universo de fornecedores usando registros públicos de empresas, formulários 10-K da SEC e registros de fornecedores de tecnologia, como o Escritório de Patentes dos Estados Unidos e os feeds de patentes da Questel. Em seguida, extraímos sinais de uso e gastos de grupos comerciais como o Interactive Advertising Bureau, associações regionais de comércio eletrônico e registros de remessas alfandegárias de hardware de servidores, que atuam como indicadores antecedentes da capacidade de rastreamento. Artigos acadêmicos indexados no IEEE Xplore esclareceram as curvas de adoção técnica, enquanto os fluxos de notícias agregados no Dow Jones Factiva ajudaram a cronometrar eventos materiais que movem receitas. (As fontes listadas ilustram o tipo utilizado e não são exaustivas.)
Dimensionamento de Mercado e Previsão
Um modelo de cima para baixo começa com os gastos globais de TI em aquisição de dados, isola a parcela atribuível a feeds de dados externos da web e é filtrado ainda mais pela penetração de adoção por segmentos como comércio eletrônico e BFSI. Verificações selecionadas de baixo para cima — preço médio de venda amostrado de fornecedores e contagens de clientes ativos — validam os totais. As principais variáveis rastreadas incluem inflação de preços de proxies, taxas de sucesso anti-bot, média de páginas rastreadas por trabalho, frequência de descontinuação de APIs e multas regionais no estilo RGPD. As previsões usam regressão multivariada apoiada por consenso de especialistas para projetar como esses impulsionadores moldam volume e precificação até 2030.
Validação de Dados e Ciclo de Atualização
Os resultados passam por triagens de variância em relação a fluxos de investimento em dados alternativos e estatísticas de largura de banda de nuvem antes de um analista sênior aprovar. O modelo é atualizado anualmente, com atualizações intermediárias acionadas por decisões jurídicas materiais ou mudanças tecnológicas; uma revisão final é concluída pouco antes do lançamento do relatório.
Por que a Linha de Base de Web Scraping da Mordor Inspira Confiabilidade
As estimativas publicadas frequentemente divergem porque as empresas segmentam o mercado de forma diferente, convertem moedas em datas variadas ou agrupam segmentos adjacentes em um único conjunto.
Os principais fatores de divergência incluem se a receita de serviços é contabilizada, como as implantações de código aberto são tratadas e a cadência com que as premissas de preço médio de venda são atualizadas. Estudos externos situam o mercado de 2025 entre USD 0,78 bilhão e 0,81 bilhão para escopos apenas de software. Alguns estudos amplos agrupam vários mercados adjacentes e publicam um valor de USD 6,77 bilhões para 2024.
Comparação de referência
| Tamanho do Mercado | Fonte anonimizada | Principal fator de divergência |
|---|---|---|
| USD 1,03 B (2025) | ||
| USD 0,78 B (2025) | Consultoria Regional A | Contabiliza apenas software, exclui serviços gerenciados |
| USD 0,81 B (2025) | Publicação Comercial B | Conjunto restrito de fornecedores, sem normalização de moeda |
| USD 6,77 B (2024) | Associação do Setor C | Agrega receitas de software, serviços e mercados de dados adjacentes |
Esses contrastes mostram que quando o escopo e a cadência de atualização diferem, os resultados variam amplamente. As regras de inclusão equilibradas da Mordor, a modelagem de duplo caminho e as atualizações anuais fornecem aos tomadores de decisão uma linha de base transparente e reproduzível que se alinha estreitamente com os sinais de gastos observáveis e as receitas verificáveis dos fornecedores.


Principais Perguntas Respondidas no Relatório
Qual é o tamanho atual do mercado de web scraping?
O mercado de web scraping está em 1,56 bilhão de USD em 2026 e prevê-se que atinja 3,49 bilhões de USD até 2031, crescendo a um CAGR de 17,39%.
Qual região lidera o mercado de web scraping?
A América do Norte detém a maior participação de receita de 34,08% graças à madura adoção de serviços financeiros e à robusta infraestrutura de nuvem.
Por que os serviços crescem mais rapidamente do que o software em web scraping?
As empresas terceirizam cada vez mais os complexos desafios de conformidade e anti-bot, impulsionando o segmento de serviços a um CAGR de 18,62%, apesar de o software reter maior receita absoluta.
Qual é o caso de uso em expansão mais rápida?
O monitoramento de preços e concorrência cresce a um CAGR de 18,34%, à medida que varejistas e plataformas digitais dependem de dados de concorrentes em tempo real para estratégias de precificação dinâmica.
Como as regulamentações afetam os projetos de web scraping?
Novas regras, como as restrições de dados sensíveis do Departamento de Justiça dos Estados Unidos e interpretações mais rígidas do GDPR na Europa, aumentam os custos jurídicos, impulsionando a demanda por soluções de extração gerenciadas e em conformidade.
Como as regulamentações estão afetando os projetos de web scraping?
Novas regras, como as restrições de dados sensíveis do Departamento de Justiça dos Estados Unidos e interpretações mais rígidas do RGPD na Europa, elevam a sobrecarga jurídica, impulsionando a demanda por soluções de extração gerenciadas e em conformidade.
Página atualizada pela última vez em:




