Web Scraping Market Size and Share
Market Overview
| Study Period | 2020 - 2031 |
|---|---|
| Market Size (2026) | USD 1.56 Billion |
| Market Size (2031) | USD 3.49 Billion |
| Growth Rate (2026 - 2031) | 17.39% CAGR |
| Fastest Growing Market | Asia-Pacific |
| Largest Market | North America |
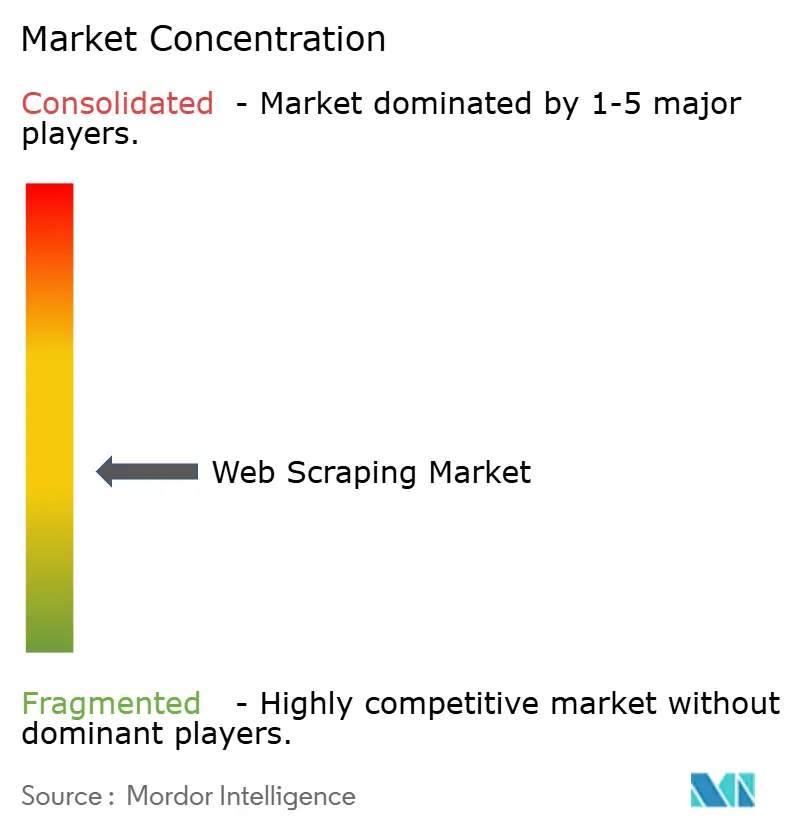
| Market Concentration | Medium |
Major Players *Disclaimer: Major Players sorted in no particular order Image © Mordor Intelligence. Reuse requires attribution under CC BY 4.0. | |
Web Scraping Market Analysis by Mordor Intelligence
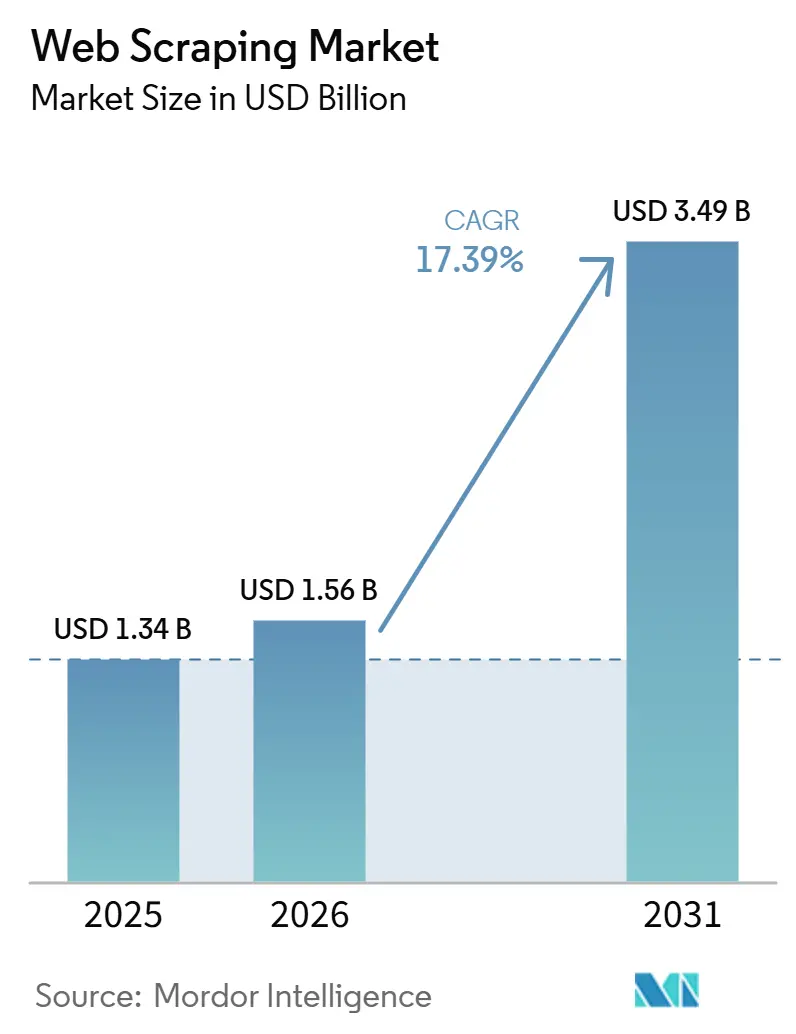
The web scraping market size was valued at USD 1.34 billion in 2025 and estimated to grow from USD 1.56 billion in 2026 to reach USD 3.49 billion by 2031, at a CAGR of 17.39% during the forecast period (2026-2031). Solid demand stems from enterprises racing to replace shrinking API access, prepare generative-AI models, and keep pace with real-time competitive intelligence needs. E-commerce pricing wars, the rise of alternative data in financial services, and accelerating cloud adoption create a steady stream of large-volume extraction workloads. At the same time, regulatory scrutiny and sophisticated anti-bot defenses push buyers toward higher-value, compliance-ready solutions that can sustain success rates under tightening technical and legal constraints. Providers able to combine scale, AI-driven adaptability, and region-specific compliance support stand to capture disproportionate revenue as the web scraping market shifts from commodity harvesting to mission-critical data infrastructure.
Key Report Takeaways
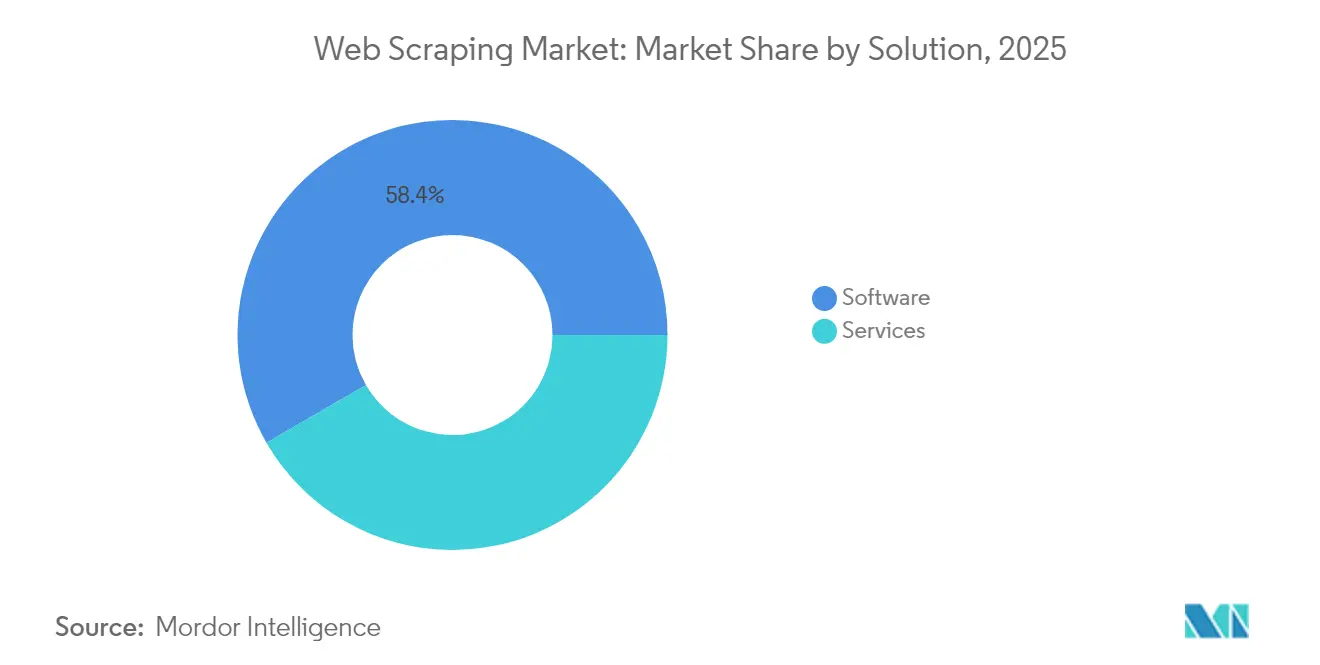
- By solution type, software maintained a 58.35% revenue share in 2025, while services are projected to register a 18.62% CAGR to 2031.
- By deployment mode, cloud models accounted for 67.45% share of the web scraping market size in 2025 and are set to expand at a 17.80% CAGR.
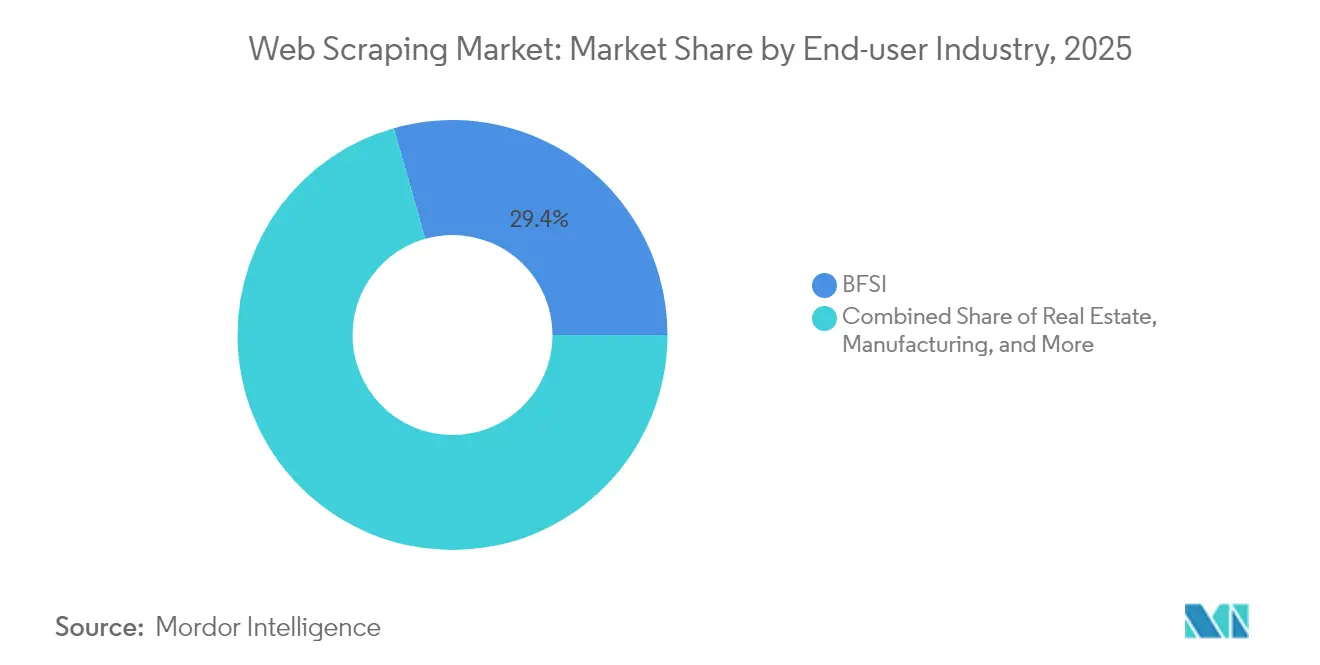
- By end-user industry, Banking, Financial Services, and Insurance captured 29.40% of the web scraping market size in 2025; Advertising and Media is advancing at a 18.80% CAGR through 2031.
- By use case, data scraping and ETL accounted for 36.20% of the web scraping market in 2025, whereas the price and competitive monitoring segment is growing at a 18.34% CAGR.
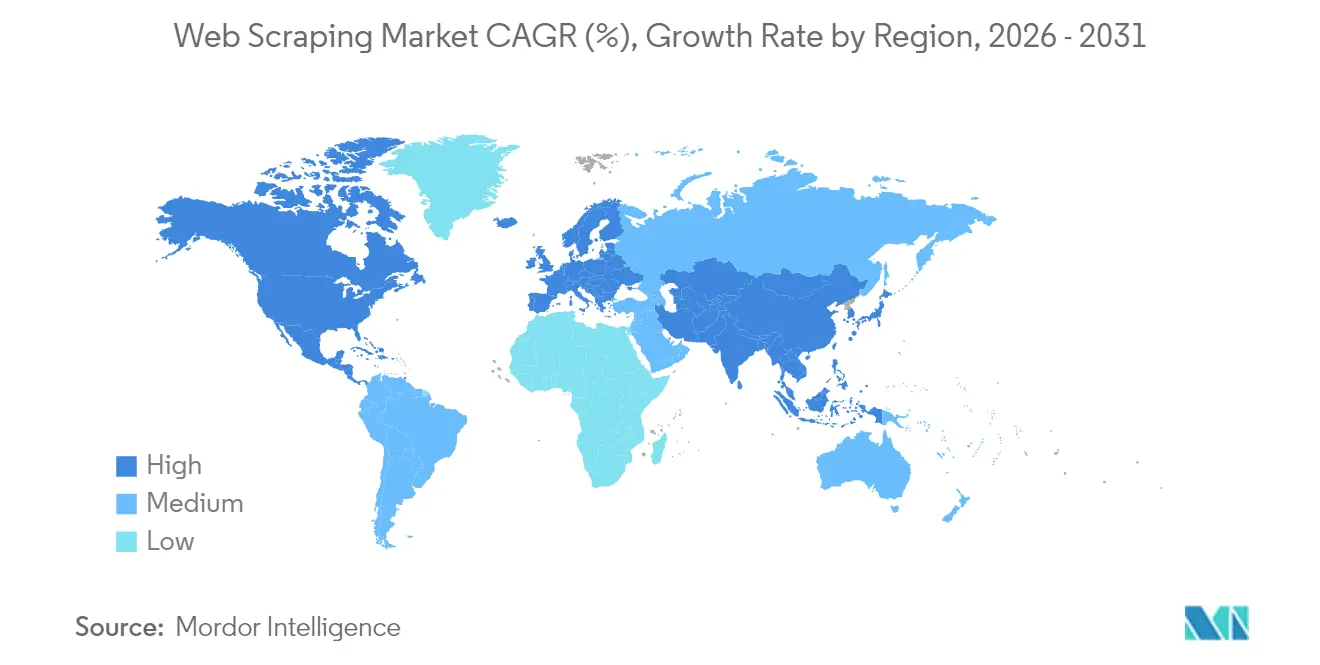
- By geography, North America led with 34.08% of web scraping market share in 2025; Asia-Pacific is forecast to deliver the fastest 18.66% CAGR through 2031.
Note: Market size and forecast figures in this report are generated using Mordor Intelligence’s proprietary estimation framework, updated with the latest available data and insights as of 2026.
Global Web Scraping Market Trends and Insights
Driver Impact Analyis*
| Driver | (~) % Impact on CAGR Forecast | Geographic Relevance | Impact Timeline |
|---|---|---|---|
| Growth of e-commerce and online marketplaces | +3.2% | Global (North America, Asia-Pacific concentrated) | Medium term (2-4 years) |
| Advancements in AI/ML for data extraction | +2.8% | Global (North America and Europe lead) | Long term (≥ 4 years) |
| Rising demand for alternative data in finance | +2.1% | North America, Europe, expanding Asia-Pacific | Medium term (2-4 years) |
| API deprecation on major platforms | +1.9% | Global (social media, content platforms most impacted) | Short term (≤ 2 years) |
| Gen-AI training data requirements | +1.7% | Global (AI development hubs) | Long term (≥ 4 years) |
| Open-data mandates revealing data gaps | +0.8% | Europe and North America | Medium term (2-4 years) |
| Source: Mordor Intelligence | |||
Growth of e-commerce and online marketplaces
Real-time price wars have pushed 81% of United States retailers toward automated price scraping for dynamic repricing strategies, up from 34% in 2020 [1]Actowiz Solutions, “Retail Price Scraping Adoption Statistics 2025,” actowiz.com. Marketplace formats now permeate real estate, groceries, and automotive listings, each demanding millisecond-level inventory visibility. The escalation of bot-mitigation on retail sites paradoxically fuels premium demand for resilient scrapers that bypass device fingerprinting and JavaScript challenges. Quick-commerce and flash-sale models further widen the addressable opportunity as merchants pivot to data-driven promotions across regional marketplaces.
Advancements in AI/ML for data extraction
Sixty-five percent of enterprises used web scraping to feed AI and machine-learning projects in 2024, signalling a shift from rule-based scripts to adaptive algorithms that cut maintenance overhead by 40% [2]BrowserCat, “AI & Web Scraping Survey 2024,” browsercat.com. AI-powered behavioral mimicry boosts success rates to 80–95% on heavily protected sites, while dynamic template detection curbs downtime when page layouts change. Vendors embedding reinforcement learning and synthetic browser fingerprints have turned intelligent extraction into a premium differentiator rather than a commodity.
Rising demand for alternative data in finance
Web scraping underpins 67% of United States investment advisers’ alternative-data programs, a figure that jumped 20 percentage points during 2024. Real-time harvesting of news, filings, and sentiment feeds algorithmic trading desks and credit-risk engines. Buoyant budgets—94% of users plan to boost spending—signal a durable revenue stream for providers that marry clean pipelines with audit trails demanded by regulators and fund allocators.
API deprecation on major platforms
Social networks and content publishers continue to raise paywalls around programmatic interfaces, making scraped HTML and dynamic rendering the economical path to at-scale data coverage. Twitter, Reddit and other services cut free access tiers, spurring enterprises to redeploy spend toward headless browsers and distributed proxy fleets. Cloudflare’s pay-to-access model for AI bots underscores a broader pivot toward monetizing data endpoints, tilting economics decisively in favor of sophisticated web scraping market solutions.
Restraints Impact Analysis*
| Restraint | (~) % Impact on CAGR Forecast | Geographic Relevance | Impact Timeline |
|---|---|---|---|
| Legal and ethical uncertainty | -2.3% | Global (strictest in Europe) | Medium term (2-4 years) |
| High costs and technical complexity | -1.8% | Global (SMEs hardest hit) | Short term (≤ 2 years) |
| Advanced bot-mitigation tools | -1.5% | Global (large platform focus) | Short term (≤ 2 years) |
| Official APIs cannibalizing some use cases | -0.9% | Global (variable by sector) | Medium term (2-4 years) |
| Source: Mordor Intelligence | |||
Legal and ethical uncertainty
The Dutch data-protection authority’s strict GDPR view on scraping personal data for AI training and the Global Privacy Assembly’s 2024 guidance require lawful basis, transparency, and minimized retention, lifting compliance spend by 86%. Italy’s EUR 20 million fine against a facial-recognition vendor signals heavy downside risk, while the United States Department of Justice now bars entities from countries of concern from accessing sensitive personal data, adding geopolitical screening layers. Navigating these cross-border constraints delays projects and raises legal-review costs.
High costs and technical complexity
Akamai reports that its bot-manager suite can block 82.3% of automated traffic on select product pages, forcing scrapers to invest in larger proxy pools, custom browser farms, and AI-filled evasion stacks. SMEs lacking capital struggle to match the arms race, often ceding niche data demands to well-funded service providers. Multi-layer JavaScript challenges and adaptive CAPTCHAs inflate compute budgets and prolong extraction cycles, eroding return on investment for less-optimized operations.
*Our forecasts treat driver/restraint impacts as directional, not additive. The impact forecasts reflect baseline growth, mix effects, and variable interactions.
Segment Analysis
By Solution: Services Gain Momentum While Software Retains Scale
Software products held 58.35% revenue in 2025, underscoring enterprise comfort with in-house orchestration frameworks and no-code extractors. Yet services are advancing at a 18.62% CAGR as buyers outsource complex compliance checks, rotating-proxy maintenance, and anti-bot tuning. Spending patterns show a shift toward hybrid adoption, where internal teams run packaged software for everyday lists while specialized firms tackle cross-border or legally sensitive datasets. AI-enabled data normalization and validation lift billable rates for full-service providers, tightening loyalty and margin. This dynamic ensures the web scraping market remains balanced between toolkits and managed offerings, catering to both do-it-yourself analysts and risk-averse corporations.
The software category has benefited from a wave of open-source and low-code releases, Thunderbit and Crawlee for Python among them, that cut entry barriers for business analysts. Enterprise security teams, however, increasingly demand external audits and legal sign-offs, nudging many toward service subscriptions bundled with documented compliance artifacts. Consequently, the web scraping market size for services is set to climb meaningfully, narrowing the revenue gap with software by 2031.



By Deployment Mode: Cloud Infrastructure Accelerates Adoption
Cloud-based deployments captured 67.45% of the web scraping market in 2025 and will outpace other modes at a 17.80% CAGR. Elastic compute pools distribute headless browsers across global points of presence, crucial when pages serve geo-specific content or block repetitive IP addresses. Providers such as Oxylabs now package rotating residential proxies, session management, and rule-compliance monitoring as click-to-launch APIs. This abstraction lets customers scale thousands of parallel requests without provisioning physical servers.
On-premise implementations survive in highly regulated verticals, particularly healthcare and core banking, where data-sovereignty clauses mandate local storage. Even within these sectors, containerized scrapers increasingly burst into sanctioned public-cloud regions during traffic spikes. Looking forward, edge-computing add-ons that process raw HTML nearer to the point of collection stand to cut latency for auction or flight-fare updates, reinforcing the cloud’s central role in the web scraping market.
By End-user Industry: Financial Services Anchor Demand, Media Surges
Banking, Financial Services and Insurance retained 29.40% of the web scraping market size in 2025 as funds, lenders, and insurers fed credit-risk and trading algorithms with scraped news, job-posting data, and consumer sentiment. Tight audit requirements favor providers that embed data-lineage tracking and regulatory alerts. Advertising and Media, though smaller today, is registering the quickest 18.80% CAGR. Agencies crave unified feeds of campaign performance, publisher pricing, and brand-safety signals delivered in near real time. The web scraping industry’s investor-facing narratives increasingly spotlight these two verticals as twin pillars: one offers deep pockets and recurring spend, the other supplies fast-growing volumes of unstructured content.
Retail and e-commerce remain essential but are now mature users. Growth stems less from first-time buyers and more from advanced use cases, dynamic coupon matching, delivery-slot monitoring, and hyper-local competitive tracking. Manufacturing, healthcare, and public-sector bodies collectively expand the addressable base by layering supply-chain surveillance, clinical-trial finder feeds, and governance-mandated open-data projects onto existing installations.
By Use Case: ETL Dominates, Price Monitoring Climbs Fastest
Data-scraping and ETL workloads accounted for 36.20% of the web scraping market size in 2025, cementing their role as back-office integrators that feed data warehouses, MDM hubs, and lakehouses. These pipelines typically feature scheduled crawls across thousands of domains, incremental diff logic, and automated schema mapping. Price and competitive-intelligence extraction, however, is advancing at a 18.34% CAGR, fueled by algorithmic repricers and AI-driven promotion engines that refresh catalogs hourly or faster. Financial data desks leverage multiple use-case clusters, news, regulatory filings, and sentiment, blurring lines between pure alternative data and traditional reference feeds. Together, these patterns ensure the web scraping market continues to diversify well beyond basic URL harvesting.
Lead-generation scrapes, social-media listening, and ESG research round out demand. Each adds unique feature requests, CRM integrations, language detection, or topic modeling, pushing vendors toward modular architectures. As a result, the web scraping market remains innovation-heavy, with product roadmaps guided by vertical-specific workflow gaps.
Geography Analysis
North America controlled 34.08% of revenue in 2025, underpinned by the United States’ deep financial-services footprint and Canada’s fast-growing analytics hubs. Regional buyers place premium value on documented compliance, evidenced by 67% of advisers embedding alternative-data streams into investment processes . New Department of Justice rules restricting sensitive data flows to foreign adversaries add layers of due diligence but simultaneously expand opportunities for domestic service bureaus specializing in lawful cross-border ingestion.
Asia-Pacific is the fastest-growing territory, advancing at a 18.66% CAGR through 2031. China’s manufacturing exporters rely on customs and shipping scrape-feeds to calibrate pricing, while India’s IT-services champions incorporate large-scale data acquisition into analytics outsourcing contracts. Japan’s corporate digital-transformation programs spur local demand for multilingual extraction frameworks. Southeast Asian marketplaces accelerate adoption as logistics, travel, and fintech super-apps fight real-time pricing battles. Australia and New Zealand round out regional momentum through commodity-trading desks that scrape port-call and satellite trackers.
Europe follows a compliance-first trajectory. The European Data Protection Board’s restrictive stance on AI training data compels risk-assessed workflows and privacy-by-design pipelines. Providers that bake in anonymization, consent management, and data-minimization controls enjoy a competitive edge. United Kingdom buyers balance GDPR alignment with a growing appetite for fintech alternative data, while Germany and France favor sovereign-cloud constructs for critical extractions. Regulatory heterogeneity across the continent sustains demand for consultative services that localize frameworks case by case.

Competitive Landscape
The web scraping market remains moderately fragmented. Bright Data, Zyte, Apify, and Oxylabs form a tier of scaled infrastructure specialists, yet none control a dominant share. Competition is shifting from raw harvesting toward quality, uptime, and compliance. Vendors differentiate on success rates against anti-bot suites, breadth of proxy pools, and region-specific legal guidance. AI-infused orchestration—adaptive retries, model-driven CSS selector discovery, and auto-labeling—has become table stakes.
Strategic positioning reveals two camps. Horizontal platforms court every vertical with plug-and-play APIs, while niche players target deep expertise on single domains such as travel fares or app-store rankings. Cloudflare’s pay-per-bot marketplace hints that platform operators may soon monetize direct data feeds, potentially turning former adversaries into channel partners. Providers able to shift early toward revenue-sharing models or curated first-party endpoints will safeguard margins.
Investment flows favor advanced bypass technology. Start-ups specializing in headless browser cloaking, dynamic fingerprint rotation, and on-device CAPTCHA solving attract venture capital, anticipating rising traffic-blocking sophistication. In response, incumbents acquire point-solutions to accelerate AI roadmaps and embed real-time compliance monitors. Over the forecast horizon, market leaders are expected to consolidate smaller proxy networks and regional compliance boutiques to shore up geographic coverage and regulatory depth.
Web Scraping Industry Leaders
Bright Data Ltd.
Zyte Group Ltd.
Apify Technologies s.r.o.
Octopus Data, Inc.
Import.io Ltd.
- *Disclaimer: Major Players sorted in no particular order

Recent Industry Developments
- January 2025: The United States Department of Justice implemented comprehensive data-protection rules preventing access to sensitive personal data by countries of concern, reshaping cross-border extraction workflows.
- January 2025: The United States Department of Health and Human Services released its AI strategic plan, directing new funds toward data-driven medical research reliant on automated collection.
- October 2024: Cloudflare unveiled a marketplace that enables publishers to charge AI bots for scraping access, reframing data monetization economics.
- July 2024: Apify launched Crawlee for Python, extending its open-source crawling framework to Python developers and broadening the contributor ecosystem.


Research Methodology Framework and Report Scope
Market Definitions and Key Coverage
Our study defines the web-scraping market as all commercial software platforms and managed extraction services that programmatically crawl public web pages, parse content, and deliver structured datasets or live feeds to paying clients. The valuation covers license, subscription, and service revenues generated by vendors that specialize in large-scale, compliance-ready data harvesting.
Scope exclusion: Internal do-it-yourself scripts run solely inside an enterprise are not counted.
Segmentation Overview
- By Solution
- Software
- Services
- By Deployment Mode
- Cloud
- On-Premise
- By End-user Industry
- BFSI
- Retail and e-Commerce
- Real Estate
- Manufacturing
- Government
- Healthcare
- Advertising and Media
- Others
- By Use Case
- Data Scraping / ETL
- Price and Competitive Monitoring
- Lead Generation and Sales Intel
- Alternative Financial Data
- Sentiment and Social Analytics
- By Geography
- North America
- United States
- Canada
- Mexico
- South America
- Brazil
- Argentina
- Rest of South America
- Europe
- Germany
- United Kingdom
- France
- Italy
- Spain
- Russia
- Rest of Europe
- Asia-Pacific
- China
- Japan
- India
- South Korea
- Australia and New Zealand
- Rest of Asia-Pacific
- Middle East and Africa
- Middle East
- Saudi Arabia
- UAE
- Turkey
- Rest of Middle East
- Africa
- South Africa
- Nigeria
- Kenya
- Rest of Africa
- Middle East
- North America
Detailed Research Methodology and Data Validation
Primary Research
Structured interviews with data-platform product heads, proxy network providers, and procurement leads across North America, Europe, and Asia-Pacific supplied real-world pricing bands, retention rates, and regional compliance costs that desk sources rarely disclose.
Desk Research
Mordor analysts first mapped the vendor universe using public company filings, SEC 10-Ks, and technology vendor registries such as the United States Patent Office and Questel patent feeds. We then pulled usage and spend signals from trade groups like the Interactive Advertising Bureau, regional e-commerce associations, and customs shipment logs for server hardware, which act as leading indicators of crawler capacity. Academic papers indexed on IEEE Xplore clarified technical adoption curves, while news flows aggregated in Dow Jones Factiva helped time material events that move revenues. (The sources listed illustrate the type used and are not exhaustive.)
Market-Sizing & Forecasting
A top-down model begins with global IT spending on data acquisition, isolates the share attributable to external web data feeds, and is further filtered through adoption penetration by verticals such as e-commerce and BFSI. Selected bottom-up checks, sampled vendor ASP and active client counts, validate totals. Key variables tracked include proxy price inflation, anti-bot success rates, average pages crawled per job, API deprecation frequency, and regional GDPR-style fines. Forecasts use multivariate regression supported by expert consensus to project how those drivers shape volume and pricing through 2030.
Data Validation & Update Cycle
Outputs pass variance screens against alternative-data investment flows and cloud bandwidth statistics before a senior analyst signs off. The model refreshes annually, with mid-cycle updates triggered by material legal rulings or technology shifts; a final pass is completed just ahead of report release.
Why Mordor's Web Scraping Baseline Commands Reliability
Published estimates often diverge because firms slice the market differently, convert currencies on varied dates, or roll adjacent segments into one bucket.
Key gap drivers include whether services revenue is counted, how open-source deployments are handled, and the cadence at which ASP assumptions are refreshed. External studies put the 2025 market anywhere between USD 0.78 billion and 0.81 billion for software-only scopes. Some broad studies roll multiple adjacent markets together and publish a USD 6.77 billion 2024 figure.
Benchmark comparison
| Market Size | Anonymized source | Primary gap driver |
|---|---|---|
| USD 1.03 B (2025) | Mordor Intelligence | - |
| USD 0.78 B (2025) | Regional Consultancy A | Counts software only, excludes managed services |
| USD 0.81 B (2025) | Trade Journal B | Narrow vendor set, no currency normalization |
| USD 6.77 B (2024) | Industry Association C | Aggregates software, services, and adjacent data-marketplace revenues |
These contrasts show that when scope and refresh cadence differ, outcomes swing widely. Mordor's balanced inclusion rules, dual-path modeling, and yearly updates give decision-makers a transparent, repeatable baseline that aligns closely with observable spend signals and verifiable vendor revenues.


Key Questions Answered in the Report
What is the current size of the web scraping market?
The web scraping market stands at USD 1.56 billion in 2026 and is forecast to reach USD 3.49 billion by 2031, growing at a 17.39% CAGR.
Which region leads the web scraping market?
North America holds the largest 34.08% revenue share thanks to mature financial-services adoption and robust cloud infrastructure.
Why are services growing faster than software in web scraping?
Enterprises increasingly outsource complex compliance and anti-bot challenges, pushing the services segment to a 18.62% CAGR despite software retaining higher absolute revenue.
What is the most rapidly expanding use case?
Price and competitive monitoring is rising at a 18.34% CAGR as retailers and digital platforms rely on real-time competitor data for dynamic pricing strategies.
How are regulations affecting web scraping projects?
New rules such as the United States DOJ sensitive-data restrictions and stricter GDPR interpretations in Europe raise legal overhead, driving demand for compliant, managed extraction solutions.
Page last updated on:






