Tamanho e Participação do Mercado de IA no Design de Moléculas
Visão Geral do Mercado
| Período de Estudo | 2020 - 2031 |
|---|---|
| Tamanho do Mercado (2026) | 2.04 Bilhões de dólares |
| Tamanho do Mercado (2031) | 6.37 Bilhões de dólares |
| Taxa de crescimento (2026 - 2031) | 25.52% CAGR |
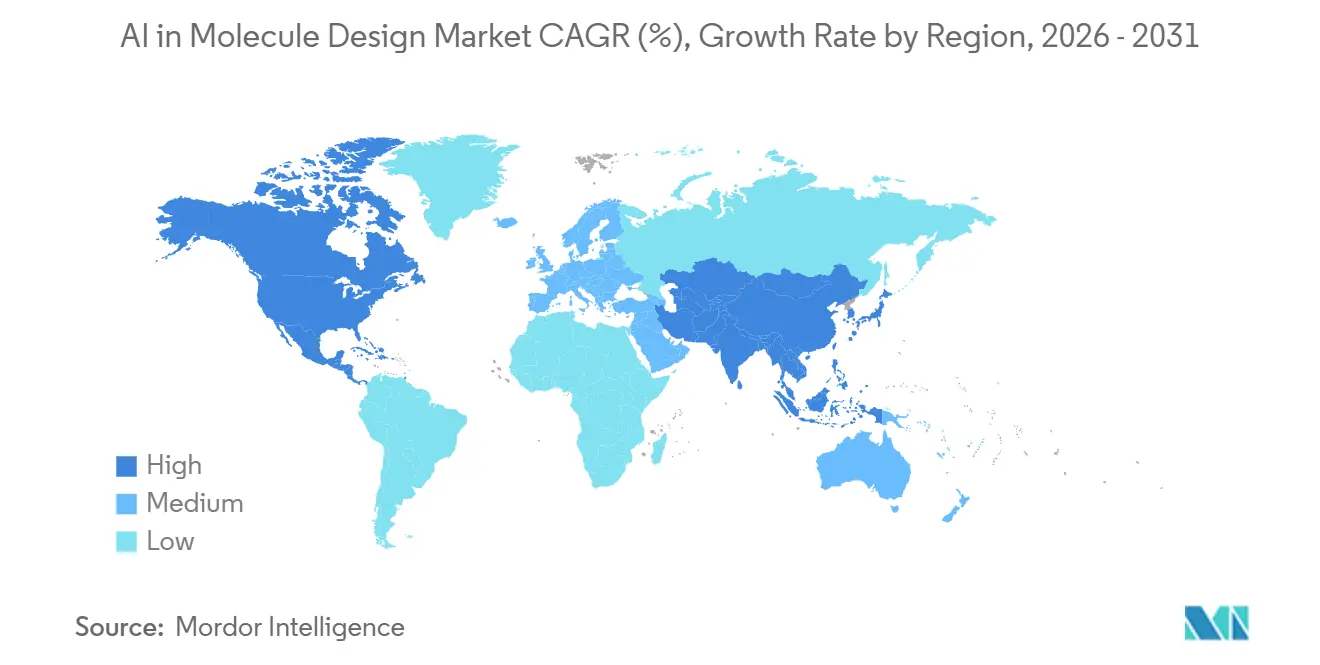
| Mercado de Crescimento Mais Rápido | Ásia-Pacífico |
| Maior Mercado | América do Norte |
| Concentração do Mercado | Médio |
Principais jogadores *Isenção de responsabilidade: Principais participantes classificados em nenhuma ordem específica Imagem © Mordor Intelligence. O reuso requer atribuição conforme CC BY 4.0. | |
Análise do Mercado de IA no Design de Moléculas por Mordor Intelligence
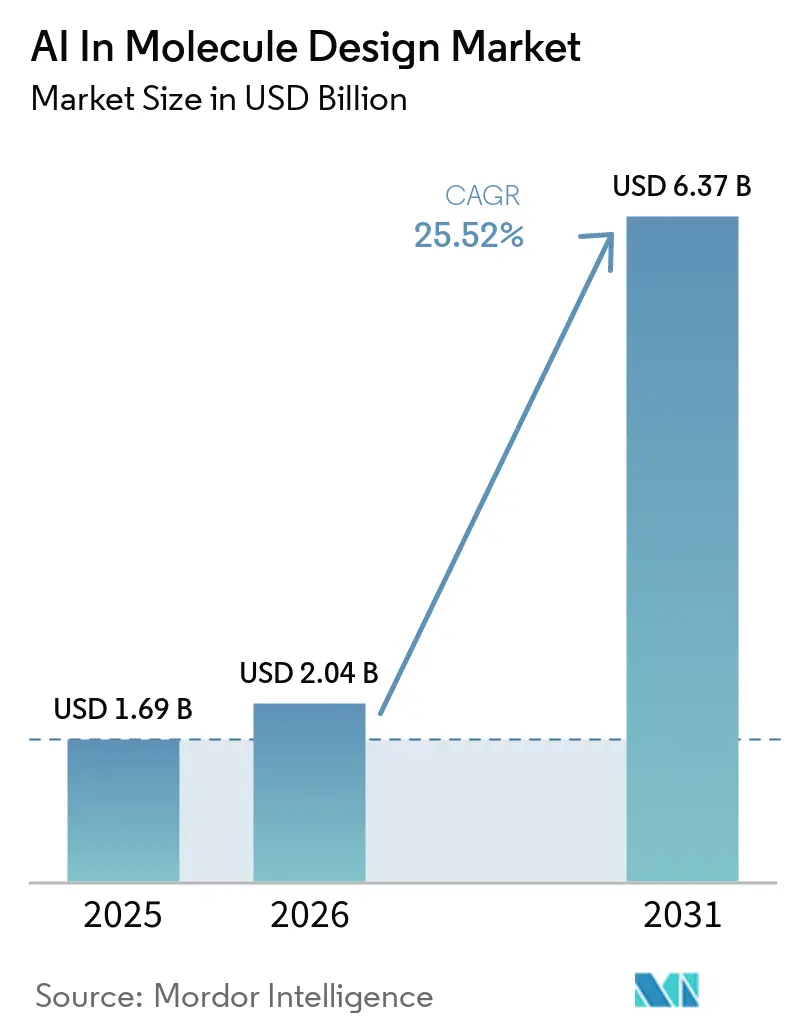
O tamanho do mercado de IA no design de moléculas foi de USD 1,69 bilhão em 2025 e está previsto para atingir USD 6,37 bilhões até 2031 a um CAGR de 25,52%, refletindo uma transição plurianual de projetos-piloto para fluxos de trabalho de descoberta integrados em pipelines farmacêuticos. Os compromissos de capital e a adoção de plataformas estão se acelerando à medida que modelos de base como o AlphaFold 3 e microsserviços em escala de nuvem tornam a previsão de estruturas e a química generativa acessíveis a equipes de P&D de grande e médio porte, reduzindo as barreiras à experimentação e à iteração no ciclo de design-fabricação-teste-análise. Os primeiros adotantes estão comprimindo os ciclos de triagem e otimização por meio de integração laboratorial autônoma e semiautônoma que conecta a inferência de modelos à síntese robótica e à análise de alto rendimento, o que aumenta o throughput e melhora a fidelidade dos dados para ciclos sucessivos. Os avanços em biologia estrutural estão ampliando o escopo endereçável para a IA, com recursos em escala AlphaFold permitindo o design guiado por estrutura em proteínas, ácidos nucleicos e complexos proteína-ligante, enquanto os benchmarks continuam a esclarecer onde os fluxos de trabalho híbridos de física-IA são necessários para precisão em sistemas flexíveis ou de complexos ternários. O foco competitivo está se deslocando para ativos de dados e execução de laboratório em ciclo fechado, à medida que as empresas formalizam pipelines de validação em laboratório úmido e conjuntos de dados proprietários que reforçam a diferenciação de plataformas e aumentam o rendimento do design de novo em modalidades de moléculas pequenas, proteínas e RNA.
Principais Conclusões do Relatório
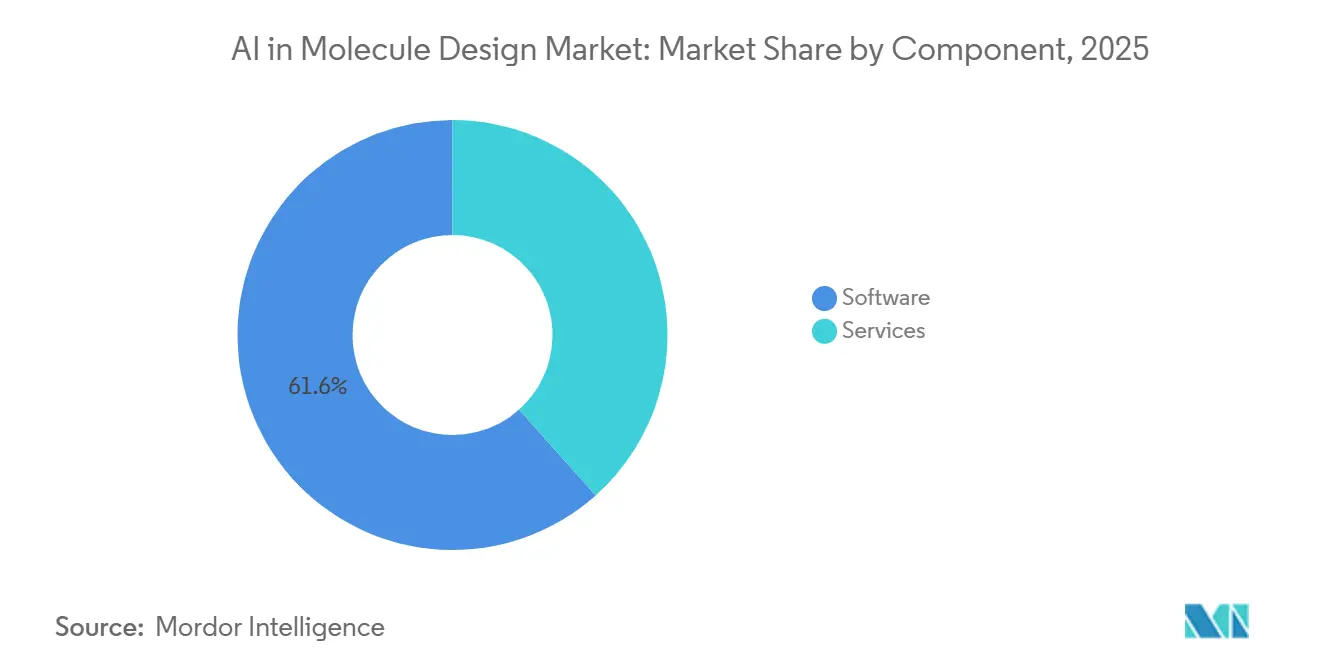
- Por componente, o software liderou com 61,56% de participação em 2025, enquanto os serviços registraram o crescimento projetado mais rápido a um CAGR de 26,14% até 2031.
- Por aplicação, o design de fármacos de moléculas pequenas representou 55,32% de participação em 2025, e o design de biológicos ou proteínas está previsto para expandir a um CAGR de 27,10% até 2031.
- Por tipo de molécula, as moléculas pequenas detinham 54,34% em 2025, e as proteínas ou biológicos registraram o maior crescimento projetado a um CAGR de 27,32%.
- Por tecnologia, os modelos generativos capturaram 48,27% da implantação em 2025, enquanto o aprendizado profundo baseado em estrutura está projetado para crescer a um CAGR de 27,06%.
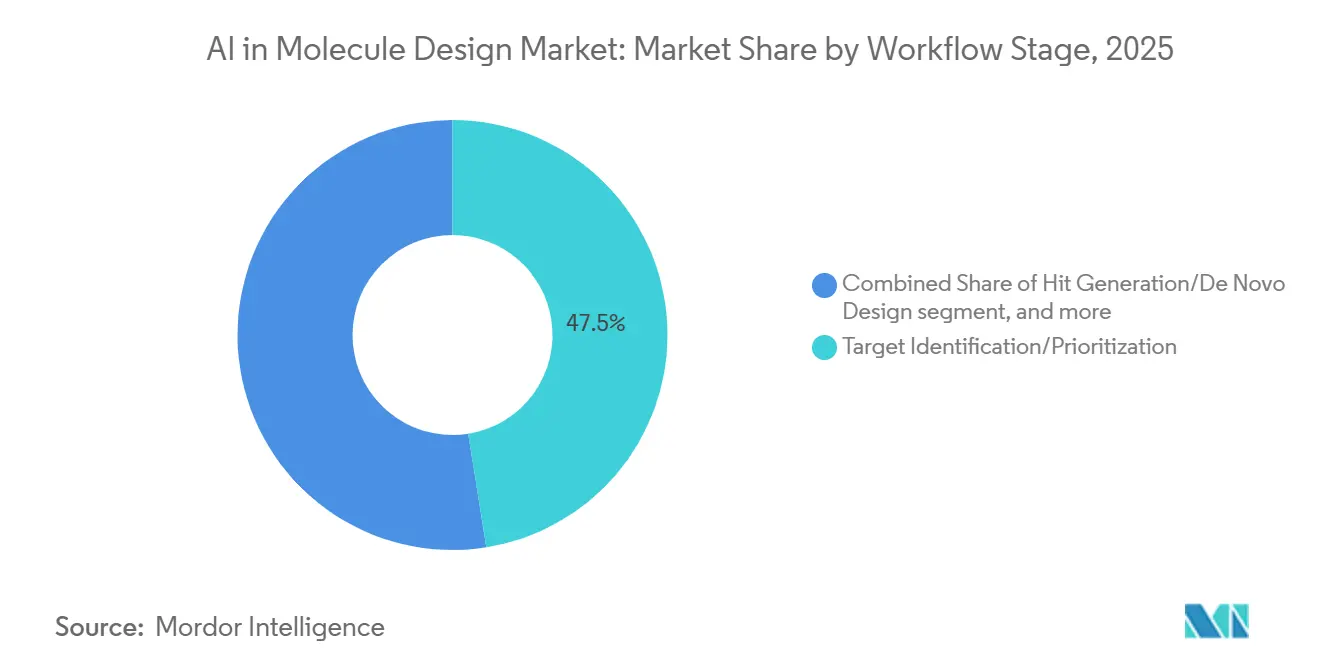
- Por etapa de fluxo de trabalho, a identificação de alvos representou 47,48% das implantações em 2025, e a geração de hits ou design de novo está avançando a um CAGR de 26,76%.
- Por usuário final, as empresas farmacêuticas e de biotecnologia representaram 65,42% em 2025, enquanto as CROs e CDMOs estão definidas para crescer a um CAGR de 27,24%.
- Por geografia, a América do Norte detinha 44,54% em 2025, e a Ásia-Pacífico está projetada para expandir a um CAGR de 26,57% até 2031.
Nota: O tamanho do mercado e os números de previsão neste relatório são gerados usando a estrutura de estimativa proprietária da Mordor Intelligence, atualizada com os dados e percepções mais recentes disponíveis em janeiro de 2026.
Tendências e Perspectivas do Mercado Global de IA no Design de Moléculas
Análise de Impacto dos Impulsionadores*
| Impulsionador | (~) % de Impacto na Previsão do CAGR | Relevância Geográfica | Prazo de Impacto |
|---|---|---|---|
| Pressão sobre a Produtividade de P&D Farmacêutico e Imperativo de Redução de Custo/Tempo | +6.8% | Global, concentrado nos polos farmacêuticos dos EUA e da UE | Curto prazo (≤ 2 anos) |
| Modelos de Base e Computação em Escala de Nuvem Habilitando o Design Generativo em Escala | +5.4% | Global com vantagens de infraestrutura nos EUA e na APAC | Médio prazo (2-4 anos) |
| Dados Estruturais da Era AlphaFold Desbloqueando o Design Guiado por Estrutura e Cofolding | +4.2% | Global, aproveitando os recursos do AlphaFold em todo o mundo | Médio prazo (2-4 anos) |
| Fluxos de Capital e Parcerias com Grandes Farmacêuticas Validando Pipelines de Design com IA | +3.9% | América do Norte e UE principalmente; transbordamento para a APAC via parcerias regionais | Curto prazo (≤ 2 anos) |
| Ciclos DMTA Integrados com Automação Laboratorial em Ciclo Fechado Reduzindo o Tempo de Iteração | +3.1% | América do Norte e APAC como núcleo; ganhos iniciais em clusters da UE | Longo prazo (≥ 4 anos) |
| Engajamento Regulatório Reduzindo Riscos do Uso de IA na Descoberta e no Desenvolvimento | +2.1% | Liderança dos EUA e da UE com a APAC seguindo | Curto prazo (≤ 2 anos) |
| Fonte: Mordor Intelligence | |||
Pressão sobre a Produtividade de P&D Farmacêutico e Imperativo de Redução de Custo/Tempo
Os prazos de desenvolvimento de fármacos e as taxas de sucesso permanecem sob pressão, reforçando a necessidade de comprimir os ciclos de descoberta e melhorar a qualidade dos candidatos antes que o investimento clínico se intensifique. As taxas de sucesso clínico abaixo de 8% continuam a restringir o retorno sobre o investimento, de modo que as funções de descoberta buscam ferramentas que aumentem a confiança nos alvos e otimizem os leads em múltiplos parâmetros mais cedo no funil. Os pipelines de design orientados por IA apoiam testes de hipóteses mais rápidos em relação a potência, seletividade e propriedades ADMET, o que reduz o atrito e diminui a síntese redundante de análogos de baixo valor quando combinados com dados de feedback de alta fidelidade. A ampla disponibilidade de modelos de base escaláveis e fluxos de trabalho de refinamento físico reduz os custos unitários para triagem e priorização in silico, levando a maior throughput e melhor alocação de recursos de laboratório úmido. À medida que mais dados estruturais e de sequência pré-competitivos entram em repositórios públicos, e à medida que laboratórios em ciclo fechado coletam medições proprietárias de maior qualidade, o desempenho dos modelos melhora por meio de ajuste fino contínuo que reflete as condições reais dos ensaios.
Modelos de Base e Computação em Escala de Nuvem Habilitando o Design Generativo em Escala
O AlphaFold 3 e ferramentas relacionadas ampliam a capacidade preditiva em proteínas, DNA, RNA e ligantes, o que permite a exploração computacional de modos de ligação e conformações que historicamente dependiam de métodos mais lentos de biologia estrutural.[1]Chaim Gartenberg, "Como Construímos o AlphaFold 3 para Prever a Estrutura e a Interação de Todas as Moléculas da Vida," The Keyword, blog.google Microsserviços entregues na nuvem, como o NVIDIA BioNeMo, integram docking por difusão, dobramento de proteínas e geração molecular em APIs padronizadas, o que incentiva padrões de implantação consistentes e escaláveis em portfólios de descoberta. As empresas relatam acelerações materiais e maior cobertura de alvos à medida que os conjuntos de modelos pré-treinados amadurecem, e a otimização contínua de hardware sustenta melhorias de throughput sem grandes investimentos de capital em instalações locais. O trabalho generativo em larga escala da IBM ilustra os ganhos obtidos com o treinamento em corpora de SMILES em escala de bilhões, com maior novidade e diversidade que expande as regiões químicas exploradas para triagem virtual. Os modelos de base que aprendem regras químicas e estruturais latentes geram candidatos que se estendem além dos scaffolds superamostrados, o que ajuda as equipes de descoberta a localizar leads viáveis de primeira classe quando combinados com filtros de propriedades e pontuação com consciência de síntese. Os ecossistemas de fornecedores estão se consolidando em torno de serviços interoperáveis que integram previsão de proteínas, docking, geração e ADMET para habilitar fluxos de trabalho de ponta a ponta com contratos de dados comuns e versionamento.
Dados Estruturais da Era AlphaFold Desbloqueando o Design Guiado por Estrutura e Cofolding
A escala e a qualidade das estruturas previstas deslocaram o design baseado em estrutura de nicho para o mainstream, uma vez que os pesquisadores podem explorar interações em alvos sem aguardar a determinação experimental da estrutura. O AlphaFold 3 adicionou capacidade para complexos proteína-ligante, o que apoia a triagem virtual e o design racional de interações no sítio de ligação, enquanto orienta a priorização com conformações previstas. Os benchmarks indicam forte desempenho para interações estáticas e destacam a necessidade de fluxos de trabalho híbridos quando a ligação induz mudanças conformacionais maiores ou quando se modelam complexos ternários, o que direciona as equipes para o refinamento baseado em física para classificação de afinidade e estabilidade. Os desenvolvedores de modelos estão iterando rapidamente com dados sintéticos de motores físicos para melhorar a previsão de complexos, o que reduz erros em regiões flexíveis e alvos associados a membranas à medida que mais exemplos de treinamento capturam cenários biofísicos diversos. O uso contínuo de servidores centralizados para geração de estruturas removeu gargalos para a descoberta inicial, de modo que múltiplas hipóteses de alvos podem ser progredidas em paralelo com entradas estruturais consistentes. À medida que as organizações padronizam estratégias de cofolding, ajuste induzido e modelagem de ensemble, os dados estruturais agora informam tanto as etapas de geração de hits quanto as de otimização de leads em moléculas pequenas e biológicos.
Ciclos DMTA Integrados com Automação Laboratorial em Ciclo Fechado Reduzindo o Tempo de Iteração
Conectar os motores de design à síntese robótica e às leituras rápidas de ensaios transforma o ciclo de design-fabricação-teste-análise em um loop contínuo, o que reduz semanas ou meses de cada iteração e expande o número de hipóteses avaliáveis por unidade de tempo. Sistemas autônomos e semiautônomos demonstraram otimização mais rápida em métricas de potência e eficiência em projetos ativos, com síntese de alto rendimento e análises fornecendo conjuntos de dados que fortalecem o retreinamento dos modelos. Na engenharia de proteínas, a experimentação autônoma gerou ganhos mensuráveis em custo e velocidade, ilustrando como os pipelines de laboratório em ciclo fechado escalam quando a inferência do modelo direciona a experimentação em vez de depender de lotes manuais.[3]NVIDIA Corporation, "Expandindo a Descoberta de Fármacos Assistida por Computador com Novos Modelos de IA," NVIDIA Blog, blogs.nvidia.com Gêmeos digitais e objetos de dados padronizados reduzem ainda mais a curadoria manual e permitem testes de hipóteses em tempo quase real em parâmetros de síntese e processo. Os fornecedores de hardware estão abordando os limites de throughput com células de trabalho modulares e escaláveis que se integram à simulação para manutenção preditiva e agendamento, o que aumenta o tempo de atividade para ciclos contínuos. O impacto combinado é um loop mais produtivo e rico em dados que retroalimenta o desempenho dos modelos e melhora o perfil geral de eficiência do mercado de IA no design de moléculas.
Análise de Impacto das Restrições*
| Restrição | (~) % de Impacto na Previsão do CAGR | Relevância Geográfica | Prazo de Impacto |
|---|---|---|---|
| Qualidade dos Dados, Viés e Falta de Padrões Limitando a Generalização dos Modelos | -2.8% | Global, agudo em regiões com infraestrutura de dados fragmentada | Médio prazo (2-4 anos) |
| Altos Custos de Implementação e Restrições de Talentos para Escalar Programas | -2.3% | A APAC e os mercados emergentes da UE enfrentam déficits de talentos mais acentuados; os EUA têm reservas mais fortes de talentos em IA | Longo prazo (≥ 4 anos) |
| Lacuna de Sintetizabilidade entre as Propostas de IA e as Rotas Executáveis | -1.7% | Global, com gravidade inversamente correlacionada à infraestrutura de química medicinal | Médio prazo (2-4 anos) |
| Gargalos de Fornecimento de Computação/GPU e Energia Restringindo o Treinamento | -1.4% | Nacional, onde o acesso a hiperscale ou o fornecimento local de GPU é limitado | Curto prazo (≤ 2 anos) |
| Fonte: Mordor Intelligence | |||
Qualidade dos Dados, Viés e Falta de Padrões Limitando a Generalização dos Modelos
Os dados de treinamento permanecem escassos em relação ao vasto espaço químico, e erros ou protocolos inconsistentes em conjuntos de dados públicos introduzem ruído que pode enviesar o aprendizado dos modelos e prejudicar a validade externa. As revisões de benchmark mostram taxas de erro de rótulo não triviais em conjuntos de dados de propriedades moleculares, o que pode induzir correlações espúrias e reduzir a precisão em configurações de previsão prospectiva. As condições heterogêneas dos ensaios complicam ainda mais o aprendizado, porque os modelos treinados em fontes agregadas podem confundir medições em contextos livres de células, celulares ou in vivo sem metadados adequados para normalizar as diferenças. O desequilíbrio demográfico nas evidências clínicas levanta riscos de generalização para previsões de segurança e exposição, uma vez que origens genéticas sub-representadas podem experimentar efeitos adversos que são mal capturados por modelos treinados em populações mais restritas. Os penhasco de atividade e os resultados de bioensaios sensíveis ao contexto adicionam complexidade, e a falta de regras padronizadas de relatório para protocolos e incerteza torna mais difícil comparar ou reutilizar conjuntos de dados entre programas. As organizações estão abordando essas lacunas gerando dados experimentais proprietários em escala e enriquecendo metadados para melhorar a confiabilidade dos modelos, o que apoia uma melhor transferência de domínio dentro do mercado de IA no design de moléculas.
Lacuna de Sintetizabilidade entre as Propostas de IA e as Rotas Executáveis
Os modelos generativos podem gerar moléculas com alta pontuação que são difíceis de sintetizar, porque muitos conjuntos de treinamento carecem de anotações explícitas de síntese e restrições retrossintéticas durante a geração. Estudos que combinam filtros automatizados de qualidade em química medicinal com docking e retrossíntese mostram que apenas uma pequena fração dos candidatos gerados passa por todos os filtros, sublinhando a necessidade de injetar objetivos com consciência de síntese mais cedo no design. A incorporação de planejadores de retrossíntese em loops de otimização estreitos melhora a tratabilidade, mas adiciona sobrecarga computacional que corrói os benefícios de velocidade da geração de novo em grandes escalas. Novos frameworks que aprendem a partir de caminhos retrossintéticos ou montagem de fragmentos estão emergindo para equilibrar novidade com viabilidade de rota, embora a validação extensiva em laboratório úmido permaneça limitada em comparação com as métricas in silico. A engenharia de recompensas e as políticas de fragmentos guiadas por síntese podem reduzir a lacuna penalizando motivos inacessíveis, enquanto mantêm a diversidade de design para exploração de SAR. À medida que os serviços de retrossíntese e as bibliotecas com consciência de reagentes se integram aos stacks de geração, os ciclos de design estão melhorando o rendimento das propostas in silico para candidatos testados em bancada no mercado de IA no design de moléculas.
*Nossas previsões tratam os impactos dos impulsionadores e restrições como direcionais, e não aditivos. As previsões de impacto refletem o crescimento de base, os efeitos de composição e as interações entre variáveis.
Análise de Segmentos
Por Componente: O Software Domina, os Serviços Aceleram à Medida que a Integração se Aprofunda
O software detinha 61,56% do mercado de IA no design de moléculas em 2025, apoiado pelo acesso baseado em nuvem a modelos de dobramento, docking e generativos que permitem às equipes escalar sem grandes investimentos em instalações locais. Microsserviços de plataforma como o BioNeMo expõem modelos para docking, previsão de estrutura e geração de moléculas via APIs padrão, o que concentra valor em fluxos de trabalho de software que podem ser orquestrados em múltiplos programas de descoberta. As principais cadeias de ferramentas em refinamento baseado em física continuam a atualizar recursos para escala, incluindo melhorias em cálculos de energia livre e tratamento de ensaios categóricos que se alinham com os fluxos de trabalho das equipes de descoberta. O resultado é uma penetração mais ampla do software no mercado de IA no design de moléculas para etapas de rotina, como expansão de hits e filtragem inicial de ADMET, que agora são acessíveis a usuários multifuncionais por meio de interfaces unificadas.
Os serviços são o componente de crescimento mais rápido, com um CAGR projetado de 26,14%, impulsionados pela execução de DMTA de ponta a ponta que conecta o design de sequências ou moléculas com síntese e caracterização internas. Os provedores focados em RNA ilustram essa mudança com ofertas integradas que abrangem design assistido por IA, fabricação escalável e sequenciamento profundo que validam a expressão e a função dentro de um ciclo. Os modelos liderados por serviços comprimem o prazo e reduzem o atrito de coordenação entre fornecedores, enquanto a captura estruturada de dados apoia o retreinamento contínuo dos modelos para a próxima iteração. À medida que as organizações de descoberta escalam programas e padronizam procedimentos operacionais, a camada de serviços torna-se um parceiro de execução fundamental que lida com automação laboratorial, throughput de ensaios e documentação para apoiar as necessidades de qualidade e conformidade do mercado de IA no design de moléculas.



Por Aplicação: A Dominância das Moléculas Pequenas Cede Espaço ao Avanço do Design de Biológicos e Proteínas
O design de fármacos de moléculas pequenas representou 55,32% das aplicações em 2025, refletindo caminhos estabelecidos para triagem virtual, refinamento baseado em física e otimização de leads que permanecem centrais para a descoberta inicial. Os motores generativos e de física são amplamente usados em conjunto para equilibrar novidade com previsão de afinidade de ligação, o que cria um filtro eficiente para priorizar candidatos antes da síntese. O stack de moléculas pequenas é agora mais interoperável entre alvos e propriedades, com formatos de dados compartilhados permitindo abordagens de ensemble que intercalam docking, geração e ADMET para impulsionar a triagem inicial em escala no mercado de IA no design de moléculas. Essa densidade de ferramentas mantém as moléculas pequenas como uma modalidade de trabalho, mesmo que novas classes atraiam investimento e atenção.
O design de biológicos ou proteínas é a aplicação de crescimento mais rápido, com um CAGR projetado de 27,10%, apoiado por avanços em previsão de estrutura, dobramento inverso e otimização de sequências que reduzem a necessidade de triagem exaustiva de bibliotecas. Desenvolvedores com abordagem de IA em primeiro lugar relataram progresso clínico em programas de anticorpos projetados com LLMs com consciência de sequência e estrutura, fornecendo evidências externas de que os fluxos de trabalho de design em primeiro lugar podem gerar candidatos adequados para o desenvolvimento. As plataformas de design de sequências de RNA e mRNA estão agora integrando a otimização orientada por IA com síntese escalável e análises, o que encurta o caminho das propostas in silico para construtos de expressão validados. À medida que a validação em laboratório em ciclo fechado se torna rotineira, os programas de biológicos aproveitam os ciclos de design que melhoram a desenvolvibilidade e a potência em menos iterações, remodelando o mix de aplicações dentro do mercado de IA no design de moléculas.
Por Tipo de Molécula: Proteínas e Biológicos Avançam Rapidamente à Medida que os Modelos de Base Amadurecem
As moléculas pequenas representaram 54,34% do mercado de IA no design de moléculas em 2025, apoiadas pela disponibilidade de grandes bibliotecas virtuais e estratégias de triagem escaláveis que funcionam em infraestrutura de nuvem padrão. Os frameworks de recuperação e triagem informados por estrutura entregaram acelerações de ordens de magnitude, expandindo o espaço de busca viável por alvo e melhorando as taxas de hits quando combinados com filtros de propriedades. Essa base mantém alto throughput para pipelines de química medicinal, que ainda se beneficiam de modelos ADMET padrão e familiaridade clínica.
As proteínas e os biológicos têm o crescimento projetado mais rápido, a um CAGR de 27,32%, impulsionados por melhor modelagem de sequência-estrutura, previsão de desenvolvibilidade e experimentação autônoma que aumenta o rendimento de designs funcionais. As modalidades centradas em RNA também estão ganhando tração por meio de plataformas de laboratório em ciclo fechado que otimizam características codificantes e não codificantes para melhorar a expressão e a durabilidade, o que expande o espaço de design prático para aplicações terapêuticas. O progresso clínico em edição genética e terapia celular apoia o investimento contínuo em motores de design em nível de sequência que se integram a fluxos de trabalho de validação e análises de qualidade. À medida que as cadeias de ferramentas amadurecem, o mix de tipos de moléculas se inclina para programas mais sensíveis aos ganhos de aprendizado de estrutura e sequência, acelerando as mudanças de participação dentro do mercado de IA no design de moléculas.
Por Tecnologia: Os Modelos Generativos Lideram, o Aprendizado Profundo Baseado em Estrutura Ganha Impulso
Os modelos generativos representaram 48,27% da implantação de tecnologia em 2025, refletindo sua utilidade em propor candidatos diversos e com consciência de propriedades para filtragem e otimização a jusante. Os geradores baseados em difusão e transformadores estão deslocando os métodos legados para o design de novo devido à estabilidade do treinamento e à qualidade das amostras, enquanto a integração com ADMET e docking aumenta a confiança nas decisões para seleções de síntese. As atualizações dos modelos de base continuam a expandir a cobertura de alvos e o escopo de modalidades, permitindo aplicação mais ampla em moléculas pequenas e terapêuticos baseados em proximidade no mercado de IA no design de moléculas.
O aprendizado profundo baseado em estrutura é a tecnologia de crescimento mais rápido, com um CAGR projetado de 27,06%, ancorado por melhorias na previsão de complexos e na modelagem conformacional que apoiam o design guiado por estrutura. Os desenvolvedores de modelos estão combinando dados sintéticos gerados por física com representações aprendidas para fechar lacunas de precisão em sistemas flexíveis, o que aumenta a utilidade das estruturas previstas para design e priorização. As cadeias de ferramentas que integram retrossíntese e viabilidade de rota em funções de pontuação refinam ainda mais o conjunto de candidatos, melhorando a transição do design in silico para a bancada. Esse stack complementa as abordagens generativas e apoia fluxos de trabalho de ponta a ponta que conectam alvos, estruturas, geração e consciência de síntese no mercado de IA no design de moléculas.
Por Etapa de Fluxo de Trabalho: A Identificação de Alvos Domina, a Geração de Hits Acelera
A identificação ou priorização de alvos representou 47,48% das implantações em 2025, uma vez que selecionar alvos de alta confiança é o ponto de decisão mais alavancado para a descoberta e o desenvolvimento a jusante. A integração de dados multimodais e a modelagem preditiva elevam a força das hipóteses de alvos e permitem que as equipes alinhem esforços com a biologia mais promissora, o que reduz o atrito em estágios tardios. Os recursos de estrutura e sequência agora permitem uma triagem mais rápida de classes de alvos e viabilidade do sítio de ligação, o que cria um caminho mais claro para a geração de hits a jusante no mercado de IA no design de moléculas.
A geração de hits ou o design de novo é a etapa de crescimento mais rápido, com um CAGR projetado de 26,76%, alimentado por ensembles de modelos que propõem grandes lotes de candidatos quimicamente diversos condicionados a propriedades de potência e desenvolvibilidade. Quando integrada a laboratórios em ciclo fechado, essa etapa produz feedback imediato que aprimora as gerações subsequentes e reduz o tempo para hits qualificados. A otimização de leads então se beneficia do refinamento baseado em física e das previsões calibradas de energia livre, que apoiam sínteses menores e mais direcionadas para a expansão de SAR. Os fluxos de trabalho de ponta a ponta agrupam cada vez mais microsserviços de ADMET, retrossíntese e previsão de estrutura para que as equipes de descoberta possam operar ciclos contínuos dentro de pipelines de dados padronizados no mercado de IA no design de moléculas.
Por Usuário Final: Farmacêutica/Biotecnologia Lidera, CROs/CDMOs Avançam com a Aceleração da Terceirização
As empresas farmacêuticas e de biotecnologia detinham 65,42% em 2025, refletindo a concentração de orçamentos de descoberta e a necessidade estratégica de reabastecer pipelines à medida que o mix de modalidades evolui. As equipes de descoberta dentro de grandes organizações implantam stacks de IA padronizados em alvos e modalidades para alinhar o design computacional com a capacidade laboratorial, o que melhora o throughput e a qualidade dos dados para ciclos iterativos no mercado de IA no design de moléculas.
As CROs e CDMOs são os usuários finais de crescimento mais rápido, com um CAGR projetado de 27,24%, à medida que as empresas patrocinadores transferem trabalho para parceiros capazes de executar química e biologia aumentadas por IA com automação laboratorial integrada. Os provedores que agrupam motores de design com síntese e análises reduzem a sobrecarga dos patrocinadores e aceleram os ciclos, enquanto a documentação padronizada apoia a transferência de tecnologia e a prontidão regulatória. O efeito é um ecossistema de serviços mais escalável que amplia o acesso a fluxos de trabalho avançados dentro do mercado de IA no design de moléculas.
Análise Geográfica
A América do Norte representou 44,54% do mercado de IA no design de moléculas em 2025, apoiada por uma massa crítica de orçamentos de descoberta, talentos computacionais e infraestrutura laboratorial que integra IA com experimentação automatizada. A região tem implantação ativa de microsserviços de modelos de base e cadeias de ferramentas de física, permitindo triagem e priorização mais rápidas em alvos e modalidades. Os ecossistemas de fornecedores que abrangem plataformas de nuvem aceleradas por GPU e hubs de modelos aumentaram o acesso a ferramentas de alto desempenho, o que apoia a experimentação em larga escala em áreas terapêuticas no mercado de IA no design de moléculas.
A Ásia-Pacífico é a região de crescimento mais rápido, com um CAGR projetado de 26,57% até 2031, ancorada por iniciativas apoiadas pelo governo e plataformas acadêmico-industriais que ampliam o acesso a análise de alvos, design generativo e ferramentas de avaliação. A China lançou uma plataforma de IA de processo completo que oferece acesso gratuito para análise de alvos, geração de moléculas e otimização de ADMET, o que reduz as barreiras para laboratórios acadêmicos e startups. Programas vinculados à Universidade de Tsinghua relataram acelerações de um milhão de vezes na triagem virtual e abriram grandes bancos de dados de complexos proteína-ligante para a comunidade, o que expande o espaço pesquisável para projetos de descoberta no mercado de IA no design de moléculas. O METI e o NEDO do Japão apoiaram trabalhos em modelos de base de larga escala para design de fármacos, sinalizando o compromisso do setor público em escalar a descoberta com IA em primeiro lugar.
A Europa se beneficia de financiamento público coordenado e de uma densa rede de centros farmacêuticos, de biotecnologia e acadêmicos que conectam a modelagem de descoberta com a infraestrutura translacional. Programas nacionais introduziram financiamento direcionado para acelerar a descoberta de fármacos habilitada por IA, com forte infraestrutura em países que sediam grandes farmacêuticas e instituições de pesquisa. Em toda a região, o mercado de IA no design de moléculas se expande à medida que as partes interessadas conectam modelos de base, automação laboratorial e análises de processos para apoiar a descoberta e o desenvolvimento inicial em múltiplas modalidades.

Cenário Competitivo
A concorrência no mercado de IA no design de moléculas é moderadamente fragmentada entre stacks de tecnologia, modalidades terapêuticas e modelos de entrada no mercado, com a diferenciação se deslocando para ativos de dados e execução de laboratório em ciclo fechado que melhoram o rendimento do design ao longo do tempo. A consolidação está remodelando as capacidades por meio de combinações de química generativa, fenômica e identificação de alvos sob um mesmo teto, o que apoia a descoberta em escala em portfólios. Os ativos de dados são centrais à medida que as empresas investem em conjuntos de dados proprietários de alta qualidade e automação que criam loops de feedback para melhorar o desempenho dos modelos no mercado de IA no design de moléculas.
Os líderes do ecossistema também estão padronizando o acesso aos modelos por meio de microsserviços em nuvem, o que cria efeitos de rede à medida que mais usuários contribuem para o ajuste e a avaliação. As plataformas de engenharia de RNA e proteínas estão emergindo como nichos de alto crescimento, reforçadas pelo interesse dos investidores e pelas capacidades de laboratório em ciclo fechado que conectam o design à síntese e às análises em um único ambiente. As empresas também estão enfatizando a explicabilidade e a proveniência para apoiar os requisitos dos patrocinadores em termos de governança interna e documentação pronta para regulamentação, o que alinha a diferenciação tecnológica com as necessidades operacionais na descoberta e no desenvolvimento.
Movimentos estratégicos selecionados ilustram o arco competitivo do mercado de IA no design de moléculas à medida que ele escala. Uma combinação de biotecnologia de alto perfil integrou grandes conjuntos de dados proprietários e motores de descoberta multimodalidade sob uma única estrutura corporativa para acelerar a descoberta industrializada. Os hubs de acesso a modelos de base garantiram ampla adoção em mais de cem empresas, confirmando o papel central das APIs padronizadas e da nuvem GPU para geração molecular, docking e dobramento em escala. Os benchmarks de experimentação autônoma em engenharia de proteínas demonstraram ganhos de custo e velocidade a partir de fluxos de trabalho laboratoriais dirigidos por IA, validando a integração da inferência de modelos com sistemas laboratoriais automatizados em ambientes comerciais.
Líderes do Setor de IA no Design de Moléculas
Schrödinger
Exscientia
Insilico Medicine
Recursion
XtalPi
- *Isenção de responsabilidade: Principais participantes classificados em nenhuma ordem específica

Desenvolvimentos Recentes do Setor
- Abril de 2026: A Isomorphic Labs, a empresa derivada da DeepMind, está avançando o design de moléculas orientado por IA para uma nova fase ao preparar seus primeiros ensaios clínicos em humanos de candidatos a fármacos projetados por IA. Usando seus sistemas de IA construídos sobre o AlphaFold e modelos generativos, a empresa projeta e otimiza novas moléculas para doenças como câncer e distúrbios imunológicos. Após garantir grandes parcerias farmacêuticas e financiamento, está agora fazendo a transição da geração de moléculas in silico para a validação no mundo real, com ensaios em humanos esperados por volta de 2026. Isso marca um marco fundamental em que as moléculas projetadas por IA passam da descoberta computacional para os testes clínicos em humanos.
- Março de 2026: A Roche lançou uma "fábrica" de IA para o desenvolvimento de fármacos em colaboração com a NVIDIA para escalar o design de moléculas orientado por IA e a descoberta de fármacos. O sistema usa infraestrutura de GPU em larga escala para executar modelos de IA generativa que ajudam a projetar novas moléculas de fármacos, identificar alvos e simular o comportamento biológico de forma mais eficiente. Ele integra essas capacidades em todo o pipeline de P&D e fabricação da Roche, permitindo uma abordagem mais automatizada e orientada por dados para o desenvolvimento de medicamentos.
- Março de 2026: A Eli Lilly firmou um acordo de USD 2,75 bilhões com a Insilico Medicine para avançar o design de moléculas orientado por IA para a descoberta de fármacos. A colaboração focou no uso de IA generativa para criar e otimizar novas moléculas de fármacos, que a Lilly desenvolve em potenciais terapias, particularmente em áreas como oncologia e doenças metabólicas. Este acordo destaca a crescente confiança da indústria farmacêutica em moléculas projetadas por IA como candidatos pré-clínicos viáveis.


Escopo do Relatório Global do Mercado de IA no Design de Moléculas
De acordo com o escopo do relatório, a IA no design de moléculas refere-se ao uso de modelos de aprendizado de máquina e generativos para prever, criar e otimizar estruturas moleculares aprendendo a partir de grandes conjuntos de dados químicos, permitindo uma exploração mais rápida do espaço químico e acelerando o ciclo de design-fabricação-teste. Ela apoia tarefas como previsão de propriedades, geração de novo de moléculas e otimização automatizada, ajudando os cientistas a projetar novos candidatos a fármacos e materiais de forma mais eficiente.
O mercado de IA no design de moléculas é segmentado por componente, aplicação, tipo de molécula, tecnologia, etapa de fluxo de trabalho, usuário final e geografia. Por componente, o mercado é segmentado em software e serviços. Por aplicação, o mercado é segmentado em design de fármacos de moléculas pequenas, design de biológicos/proteínas, design de materiais e produtos químicos especiais, e design de agroquímicos. Por tipo de molécula, o mercado é segmentado em moléculas pequenas, peptídeos, proteínas/biológicos, RNA/oligonucleotídeos e moléculas de materiais/polímeros. Por tecnologia, o mercado é segmentado em modelos generativos, aprendizado profundo baseado em estrutura, previsão de propriedades/ADMET por aprendizado de máquina, e IA de planejamento de síntese e retrossíntese. Por etapa de fluxo de trabalho, o mercado é segmentado em identificação/priorização de alvos, geração de hits/design de novo, hit-to-lead, otimização de leads e outros. Por usuário final, o mercado é segmentado em empresas farmacêuticas e de biotecnologia, CROs e CDMOs, fabricantes de produtos químicos e materiais, e outros. Por geografia, o mercado é segmentado em América do Norte, Europa, Ásia-Pacífico, Oriente Médio e África, e América do Sul. O relatório também abrange os tamanhos de mercado estimados e as tendências para 17 países nas principais regiões do mundo. O relatório oferece valores (USD) para todos os segmentos acima.
| Software |
| Serviços |
| Design de Fármacos de Moléculas Pequenas |
| Design de Biológicos/Proteínas |
| Design de Materiais e Produtos Químicos Especiais |
| Design de Agroquímicos |
| Moléculas Pequenas |
| Peptídeos |
| Proteínas/Biológicos |
| RNA/Oligonucleotídeos |
| Moléculas de Materiais/Polímeros |
| Modelos Generativos |
| Aprendizado Profundo Baseado em Estrutura |
| Previsão de Propriedades/ADMET por Aprendizado de Máquina |
| IA de Planejamento de Síntese e Retrossíntese |
| Identificação/Priorização de Alvos |
| Geração de Hits/Design de Novo |
| Hit-to-Lead |
| Otimização de Leads |
| Outros |
| Empresas Farmacêuticas e de Biotecnologia |
| CROs e CDMOs |
| Fabricantes de Produtos Químicos e Materiais |
| Outros |
| América do Norte | Estados Unidos |
| Canadá | |
| México | |
| Europa | Alemanha |
| Reino Unido | |
| França | |
| Itália | |
| Espanha | |
| Restante da Europa | |
| Ásia-Pacífico | China |
| Japão | |
| Índia | |
| Austrália | |
| Coreia do Sul | |
| Restante da Ásia-Pacífico | |
| Oriente Médio e África | CCG |
| África do Sul | |
| Restante do Oriente Médio e África | |
| América do Sul | Brasil |
| Argentina | |
| Restante da América do Sul |
| Por Componente | Software | |
| Serviços | ||
| Por Aplicação | Design de Fármacos de Moléculas Pequenas | |
| Design de Biológicos/Proteínas | ||
| Design de Materiais e Produtos Químicos Especiais | ||
| Design de Agroquímicos | ||
| Por Tipo de Molécula | Moléculas Pequenas | |
| Peptídeos | ||
| Proteínas/Biológicos | ||
| RNA/Oligonucleotídeos | ||
| Moléculas de Materiais/Polímeros | ||
| Por Tecnologia | Modelos Generativos | |
| Aprendizado Profundo Baseado em Estrutura | ||
| Previsão de Propriedades/ADMET por Aprendizado de Máquina | ||
| IA de Planejamento de Síntese e Retrossíntese | ||
| Por Etapa de Fluxo de Trabalho | Identificação/Priorização de Alvos | |
| Geração de Hits/Design de Novo | ||
| Hit-to-Lead | ||
| Otimização de Leads | ||
| Outros | ||
| Por Usuário Final | Empresas Farmacêuticas e de Biotecnologia | |
| CROs e CDMOs | ||
| Fabricantes de Produtos Químicos e Materiais | ||
| Outros | ||
| Por Geografia | América do Norte | Estados Unidos |
| Canadá | ||
| México | ||
| Europa | Alemanha | |
| Reino Unido | ||
| França | ||
| Itália | ||
| Espanha | ||
| Restante da Europa | ||
| Ásia-Pacífico | China | |
| Japão | ||
| Índia | ||
| Austrália | ||
| Coreia do Sul | ||
| Restante da Ásia-Pacífico | ||
| Oriente Médio e África | CCG | |
| África do Sul | ||
| Restante do Oriente Médio e África | ||
| América do Sul | Brasil | |
| Argentina | ||
| Restante da América do Sul | ||


Principais Perguntas Respondidas no Relatório
Qual é o tamanho atual e as perspectivas de crescimento do mercado de IA no design de moléculas?
O tamanho do mercado de IA no design de moléculas foi de USD 1,69 bilhão em 2025 e está projetado para atingir USD 6,37 bilhões até 2031 a um CAGR de 25,52%, sinalizando impulso plurianual em fluxos de trabalho de descoberta.
Quais regiões impulsionarão a expansão mais rápida até 2031?
A Ásia-Pacífico é a região de crescimento mais rápido, com um CAGR projetado de 26,57%, apoiada por plataformas apoiadas pelo governo e programas acadêmico-industriais que ampliam o acesso a ferramentas de design habilitadas por IA.
Quais aplicações e tipos de moléculas estão definidos para crescer mais?
O design de biológicos ou proteínas é a aplicação de crescimento mais rápido, a um CAGR de 27,10%, enquanto as proteínas ou biológicos lideram o crescimento por tipo de molécula a 27,32%, com modelos de laboratório em ciclo fechado e com consciência de estrutura melhorando o rendimento.
Quais tecnologias são mais amplamente utilizadas hoje no design habilitado por IA?
Os modelos generativos lideram com 48,27% de implantação, e o aprendizado profundo baseado em estrutura é o de crescimento mais rápido, com um CAGR de 27,06%, auxiliado por avanços na previsão de complexos e microsserviços entregues na nuvem.
Página atualizada pela última vez em:




