Taille et part du marché du web scraping
VUE D’ENSEMBLE DU MARCHÉ
| Période d'étude | 2020 - 2031 |
|---|---|
| Taille du Marché (2026) | 1.56 Milliards de dollars |
| Taille du Marché (2031) | 3.49 Milliards de dollars |
| Taux de croissance (2026 - 2031) | 17.39% CAGR |
| Marché à la Croissance la Plus Rapide | Asie-Pacifique |
| Plus Grand Marché | Amérique du Nord |
| Concentration du Marché | Moyen |
Acteurs majeurs *Avis de non-responsabilité : les principaux acteurs sont triés sans ordre particulier Image © Mordor Intelligence. La réutilisation nécessite une attribution sous CC BY 4.0. | |
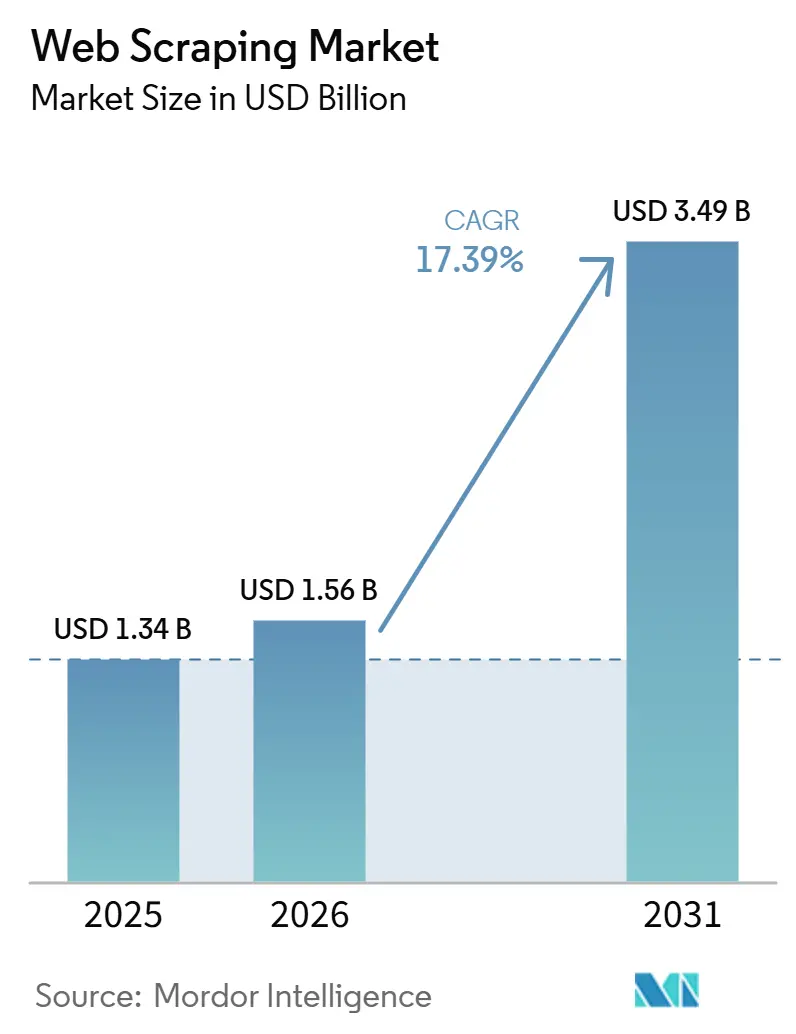
Analyse du marché du web scraping par Mordor Intelligence
La taille du marché du web scraping était évaluée à 1,34 milliard USD en 2025 et devrait croître de 1,56 milliard USD en 2026 pour atteindre 3,49 milliards USD d'ici 2031, à un CAGR de 17,39 % durant la période de prévision (2026-2031). La demande soutenue provient des entreprises qui s'empressent de remplacer l'accès aux API en déclin, de préparer des modèles d'IA générative et de suivre le rythme des besoins en veille concurrentielle en temps réel. Les guerres de prix dans le commerce électronique, l'essor des données alternatives dans les services financiers et l'adoption accélérée du cloud créent un flux constant de charges de travail d'extraction à grand volume. Dans le même temps, la surveillance réglementaire et les défenses anti-bot sophistiquées poussent les acheteurs vers des solutions à plus haute valeur ajoutée, conformes aux exigences réglementaires, capables de maintenir des taux de réussite dans un contexte de contraintes techniques et juridiques de plus en plus strictes. Les fournisseurs capables de combiner l'échelle, l'adaptabilité pilotée par l'IA et le soutien à la conformité spécifique à chaque région sont en mesure de capter des revenus disproportionnés à mesure que le marché du web scraping évolue de la collecte de données banalisée vers une infrastructure de données stratégique.
Points clés du rapport
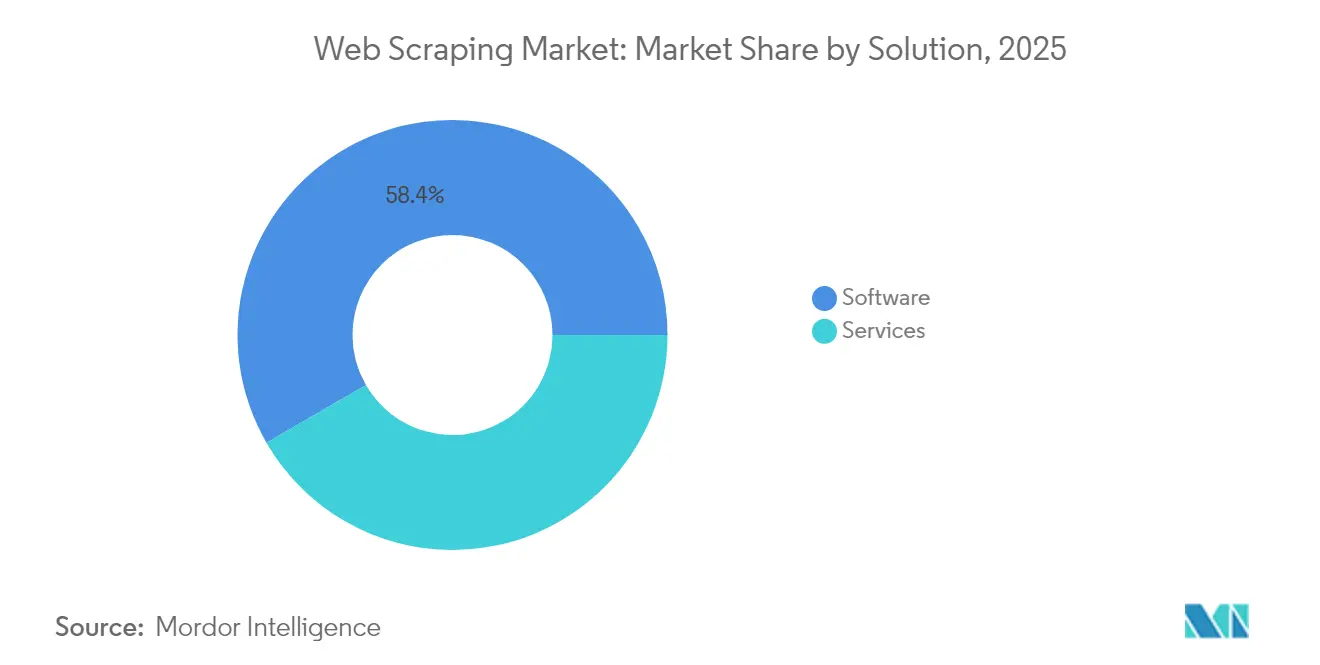
- Par type de solution, les logiciels ont maintenu une part de revenus de 58,35 % en 2025, tandis que les services devraient enregistrer un CAGR de 18,62 % d'ici 2031.
- Par mode de déploiement, les modèles cloud représentaient 67,45 % de la taille du marché du web scraping en 2025 et devraient se développer à un CAGR de 17,80 %.
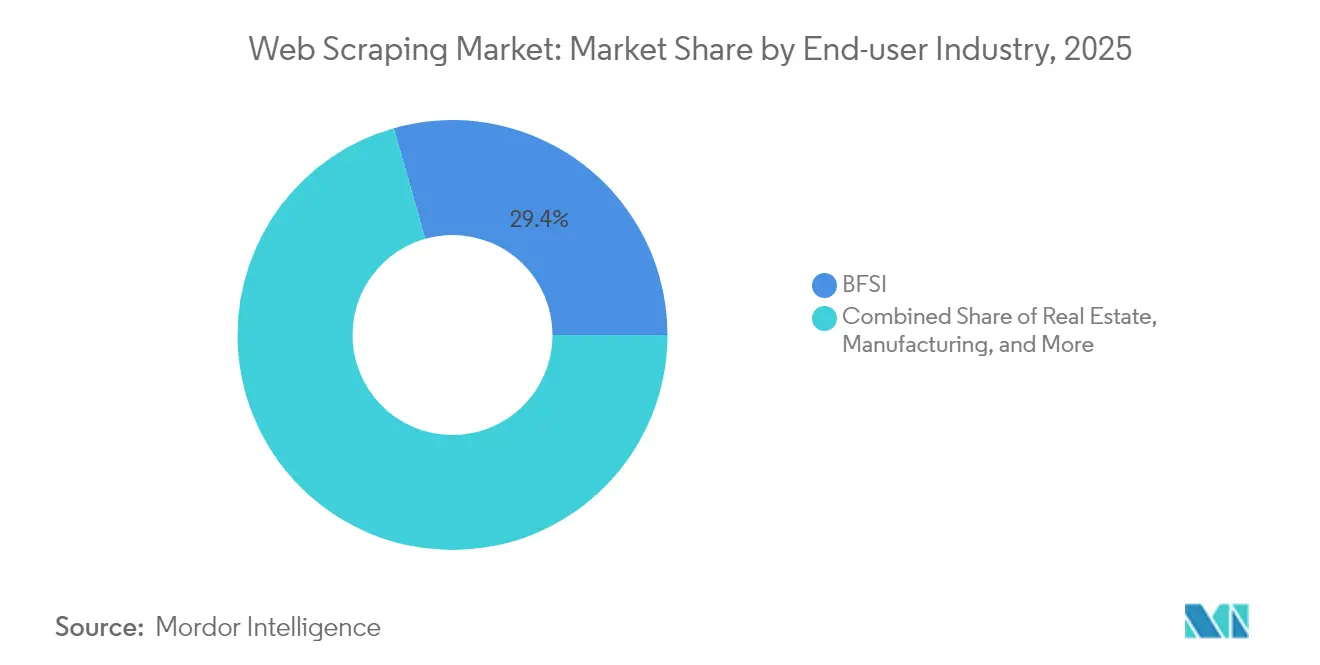
- Par secteur d'utilisateur final, la Banque, les Services Financiers et l'Assurance ont capté 29,40 % de la taille du marché du web scraping en 2025 ; la Publicité et les Médias progressent à un CAGR de 18,80 % jusqu'en 2031.
- Par cas d'usage, le web scraping de données et l'ETL représentaient 36,20 % du marché du web scraping en 2025, tandis que le segment de la surveillance des prix et de la veille concurrentielle croît à un CAGR de 18,34 %.
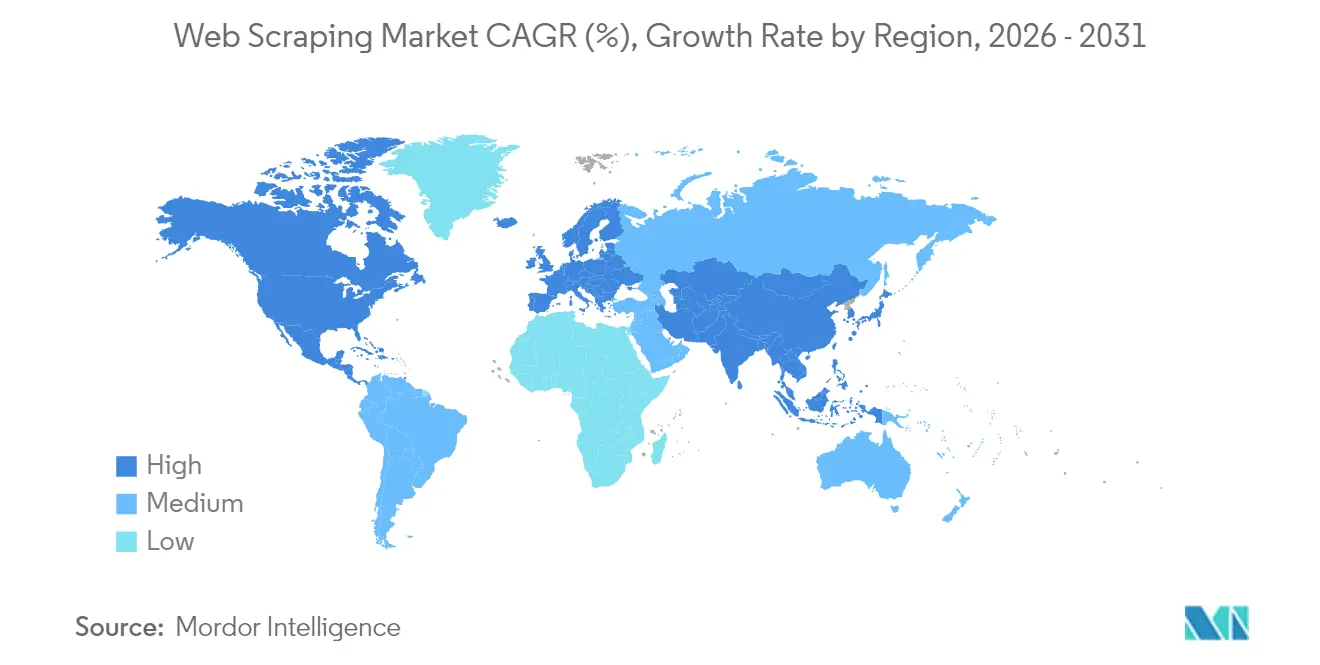
- Par zone géographique, l'Amérique du Nord était en tête avec 34,08 % de la part de marché du web scraping en 2025 ; l'Asie-Pacifique devrait afficher le CAGR le plus rapide de 18,66 % jusqu'en 2031.
Remarque : Les chiffres de la taille du marché et des prévisions de ce rapport sont générés à l’aide du cadre d’estimation propriétaire de Mordor Intelligence, mis à jour avec les données et analyses les plus récentes disponibles en 2026.
Tendances et perspectives mondiales du marché du web scraping
Analyse de l'impact des moteurs de croissance*
| Moteur de croissance | (~) % d'impact sur les prévisions de CAGR | Pertinence géographique | Horizon temporel de l'impact |
|---|---|---|---|
| Croissance du commerce électronique et des places de marché en ligne | +3.2% | Mondial (concentré en Amérique du Nord et en Asie-Pacifique) | Moyen terme (2 à 4 ans) |
| Avancées de l'IA/ML pour l'extraction de données | +2.8% | Mondial (Amérique du Nord et Europe en tête) | Long terme (≥ 4 ans) |
| Demande croissante de données alternatives dans la finance | +2.1% | Amérique du Nord, Europe, Asie-Pacifique en expansion | Moyen terme (2 à 4 ans) |
| Dépréciation des API sur les principales plateformes | +1.9% | Mondial (réseaux sociaux et plateformes de contenu les plus touchés) | Court terme (≤ 2 ans) |
| Besoins en données d'entraînement pour l'IA générative | +1.7% | Mondial (pôles de développement de l'IA) | Long terme (≥ 4 ans) |
| Mandats de données ouvertes révélant des lacunes en matière de données | +0.8% | Europe et Amérique du Nord | Moyen terme (2 à 4 ans) |
| Source: Mordor Intelligence | |||
Croissance du commerce électronique et des places de marché en ligne
Les guerres de prix en temps réel ont poussé 81 % des détaillants américains vers le scraping automatisé des prix pour des stratégies de tarification dynamique, contre 34 % en 2020 [1]Actowiz Solutions, "Retail Price Scraping Adoption Statistics 2025," actowiz.com. Les formats de places de marché imprègnent désormais l'immobilier, l'épicerie et les annonces automobiles, chacun exigeant une visibilité sur les stocks à la milliseconde. L'escalade des mesures d'atténuation des bots sur les sites de vente au détail alimente paradoxalement une demande premium pour des scrapers résilients capables de contourner les empreintes digitales des appareils et les défis JavaScript. Les modèles de commerce rapide et de ventes flash élargissent encore l'opportunité adressable à mesure que les marchands pivotent vers des promotions pilotées par les données sur les places de marché régionales.
Avancées de l'IA/ML pour l'extraction de données
Soixante-cinq pour cent des entreprises ont utilisé le web scraping pour alimenter des projets d'IA et d'apprentissage automatique en 2024, signalant un passage des scripts basés sur des règles à des algorithmes adaptatifs qui réduisent les frais de maintenance de 40 % [2]BrowserCat, "AI & Web Scraping Survey 2024," browsercat.com. Le mimétisme comportemental alimenté par l'IA améliore les taux de réussite à 80-95 % sur les sites fortement protégés, tandis que la détection dynamique de modèles réduit les temps d'arrêt lorsque les mises en page changent. Les fournisseurs intégrant l'apprentissage par renforcement et des empreintes digitales de navigateur synthétiques ont transformé l'extraction intelligente en un différenciateur premium plutôt qu'en une offre banalisée.
Demande croissante de données alternatives dans la finance
Le web scraping sous-tend 67 % des programmes de données alternatives des conseillers en investissement américains, un chiffre qui a bondi de 20 points de pourcentage en 2024. La collecte en temps réel d'actualités, de dépôts réglementaires et de flux de sentiment alimente les desks de trading algorithmique et les moteurs d'évaluation du risque de crédit. Des budgets dynamiques — 94 % des utilisateurs prévoient d'augmenter leurs dépenses — signalent un flux de revenus durable pour les fournisseurs qui associent des pipelines de données propres à des pistes d'audit exigées par les régulateurs et les allocateurs de fonds.
Dépréciation des API sur les principales plateformes
Les réseaux sociaux et les éditeurs de contenu continuent d'ériger des barrières payantes autour des interfaces programmatiques, faisant du HTML scrapé et du rendu dynamique la voie économique vers une couverture de données à grande échelle. Twitter, Reddit et d'autres services ont supprimé les niveaux d'accès gratuits, incitant les entreprises à redéployer leurs dépenses vers des navigateurs sans interface graphique et des flottes de proxies distribués. Le modèle d'accès payant de Cloudflare pour les bots d'IA souligne un pivot plus large vers la monétisation des points de terminaison de données, faisant pencher l'économie de manière décisive en faveur de solutions sophistiquées de web scraping.
Analyse de l'impact des freins*
| Frein | (~) % d'impact sur les prévisions de CAGR | Pertinence géographique | Horizon temporel de l'impact |
|---|---|---|---|
| Incertitude juridique et éthique | -2.3% | Mondial (plus stricte en Europe) | Moyen terme (2 à 4 ans) |
| Coûts élevés et complexité technique | -1.8% | Mondial (PME les plus touchées) | Court terme (≤ 2 ans) |
| Outils avancés d'atténuation des bots | -1.5% | Mondial (focus sur les grandes plateformes) | Court terme (≤ 2 ans) |
| API officielles cannibalisent certains cas d'utilisation | -0.9% | Mondial (variable selon le secteur) | Moyen terme (2 à 4 ans) |
| Source: Mordor Intelligence | |||
Incertitude juridique et éthique
La position stricte de l'autorité néerlandaise de protection des données sur le RGPD concernant le scraping de données personnelles pour l'entraînement de l'IA et les orientations 2024 de l'Assemblée mondiale pour la protection de la vie privée exigent une base juridique, une transparence et une conservation minimisée, augmentant les dépenses de conformité de 86 %. L'amende de 20 millions EUR infligée par l'Italie à un fournisseur de reconnaissance faciale signale un risque négatif important, tandis que le Département de justice des États-Unis interdit désormais aux entités de pays préoccupants d'accéder à des données personnelles sensibles, ajoutant des couches de contrôle géopolitique. La navigation dans ces contraintes transfrontalières retarde les projets et augmente les coûts d'examen juridique.
Coûts élevés et complexité technique
Akamai rapporte que sa suite de gestion des bots peut bloquer 82,3 % du trafic automatisé sur certaines pages de produits, obligeant les scrapers à investir dans des pools de proxies plus importants, des fermes de navigateurs personnalisés et des piles d'évasion alimentées par l'IA. Les PME manquant de capital peinent à suivre la course aux armements, cédant souvent les demandes de données de niche à des prestataires de services bien financés. Les défis JavaScript multicouches et les CAPTCHA adaptatifs gonflent les budgets de calcul et prolongent les cycles d'extraction, érodant le retour sur investissement pour les opérations moins optimisées.
*Nos prévisions considèrent les impacts des moteurs et des contraintes comme directionnels et non additifs. Les prévisions d'impact reflètent la croissance de référence, les effets de composition et les interactions entre variables.
Analyse des segments
Par solution : les services gagnent en dynamisme tandis que les logiciels conservent leur échelle
Les produits logiciels ont représenté 58,35 % des revenus en 2025, soulignant l'aisance des entreprises avec les frameworks d'orchestration internes et les extracteurs sans code. Pourtant, les services progressent à un CAGR de 18,62 % à mesure que les acheteurs externalisent les vérifications de conformité complexes, la maintenance des proxies rotatifs et le réglage anti-bot. Les schémas de dépenses révèlent un glissement vers une adoption hybride, où les équipes internes utilisent des logiciels packagés pour les listes courantes tandis que des entreprises spécialisées traitent les jeux de données transfrontaliers ou juridiquement sensibles. La normalisation et la validation des données par l'IA augmentent les tarifs facturables pour les prestataires de services complets, renforçant la fidélité et les marges. Cette dynamique garantit que le marché du web scraping reste équilibré entre les boîtes à outils et les offres gérées, répondant à la fois aux analystes autonomes et aux entreprises averses au risque.
La catégorie des logiciels a bénéficié d'une vague de publications open source et low-code, notamment Thunderbit et Crawlee pour Python, qui ont abaissé les barrières à l'entrée pour les analystes métier. Les équipes de sécurité des entreprises, cependant, exigent de plus en plus des audits externes et des validations juridiques, incitant beaucoup d'entre elles à opter pour des abonnements à des services assortis d'artefacts de conformité documentés. Par conséquent, la taille du marché du web scraping pour les services est appelée à croître de manière significative, réduisant l'écart de revenus avec les logiciels d'ici 2031.



Par mode de déploiement : l'infrastructure cloud accélère l'adoption
Les déploiements basés sur le cloud ont capté 67,45 % du marché du web scraping en 2025 et surpasseront les autres modes à un CAGR de 17,80 %. Les pools de calcul élastiques distribuent les navigateurs sans interface graphique sur des points de présence mondiaux, ce qui est crucial lorsque les pages servent du contenu géo-spécifique ou bloquent les adresses IP répétitives. Des fournisseurs tels qu'Oxylabs proposent désormais des proxies résidentiels rotatifs, la gestion des sessions et la surveillance de la conformité réglementaire sous forme d'API prêtes à l'emploi. Cette abstraction permet aux clients de faire évoluer des milliers de requêtes parallèles sans provisionner de serveurs physiques.
Les implémentations sur site subsistent dans les secteurs fortement réglementés, notamment la santé et la banque de détail, où les clauses de souveraineté des données imposent un stockage local. Même dans ces secteurs, les scrapers conteneurisés s'étendent de plus en plus vers des régions de cloud public autorisées lors des pics de trafic. À l'avenir, les modules complémentaires de calcul en périphérie qui traitent le HTML brut au plus près du point de collecte devraient réduire la latence pour les mises à jour des enchères ou des tarifs aériens, renforçant le rôle central du cloud dans le marché du web scraping.
Par secteur d'utilisateur final : les services financiers ancrent la demande, les médias progressent rapidement
La Banque, les Services Financiers et l'Assurance ont conservé 29,40 % de la taille du marché du web scraping en 2025, les fonds, les prêteurs et les assureurs alimentant les algorithmes de risque de crédit et de trading avec des actualités extraites, des données d'offres d'emploi et le sentiment des consommateurs. Les exigences strictes en matière d'audit favorisent les fournisseurs qui intègrent le suivi de la traçabilité des données et les alertes réglementaires. La Publicité et les Médias, bien que plus modestes aujourd'hui, enregistrent le CAGR le plus rapide à 18,80 %. Les agences recherchent des flux unifiés de performances de campagnes, de tarification des éditeurs et de signaux de sécurité de marque livrés en quasi temps réel. Les récits à destination des investisseurs dans le secteur du web scraping mettent de plus en plus en avant ces deux secteurs verticaux comme piliers jumeaux : l'un offre des budgets importants et des dépenses récurrentes, l'autre fournit des volumes à croissance rapide de contenu non structuré.
Le commerce de détail et le commerce électronique restent essentiels mais sont désormais des utilisateurs matures. La croissance provient moins des primo-acheteurs que des cas d'usage avancés, tels que la correspondance dynamique de coupons, la surveillance des créneaux de livraison et le suivi concurrentiel hyperlocal. Les secteurs de la fabrication, de la santé et du secteur public élargissent collectivement la base adressable en superposant la surveillance des chaînes d'approvisionnement, les flux de recherche d'essais cliniques et les projets de données ouvertes imposés par la gouvernance aux installations existantes.
Par cas d'utilisation : l'ETL domine, la surveillance des prix progresse le plus rapidement
Les charges de travail de web scraping de données et d'ETL représentaient 36,20 % de la taille du marché du web scraping en 2025, consolidant leur rôle d'intégrateurs de back-office alimentant les entrepôts de données, les hubs MDM et les lakehouses. Ces pipelines comportent généralement des crawls planifiés sur des milliers de domaines, une logique de différentiel incrémentiel et un mappage automatisé des schémas. L'extraction des prix et de la veille concurrentielle, cependant, progresse à un CAGR de 18,34 %, portée par les moteurs de repricing algorithmique et les moteurs de promotion pilotés par l'IA qui actualisent les catalogues toutes les heures ou plus fréquemment. Les équipes de données financières exploitent plusieurs clusters de cas d'usage — actualités, dépôts réglementaires et sentiment — brouillant les frontières entre les données alternatives pures et les flux de référence traditionnels. Ensemble, ces tendances garantissent que le marché du web scraping continue de se diversifier bien au-delà de la simple collecte d'URL.
Les extractions pour la génération de leads, l'écoute des réseaux sociaux et la recherche ESG complètent la demande. Chacune ajoute des demandes de fonctionnalités uniques — intégrations CRM, détection de langue ou modélisation thématique — poussant les fournisseurs vers des architectures modulaires. En conséquence, le marché du web scraping reste fortement axé sur l'innovation, avec des feuilles de route produit guidées par les lacunes de flux de travail spécifiques aux secteurs verticaux.
Analyse géographique
L'Amérique du Nord contrôlait 34,08 % des revenus en 2025, soutenue par l'empreinte profonde des services financiers aux États-Unis et les pôles d'analyse à croissance rapide du Canada. Les acheteurs régionaux accordent une valeur premium à la conformité documentée, comme en témoigne le fait que 67 % des conseillers intègrent des flux de données alternatives dans leurs processus d'investissement. Les nouvelles règles du Département de Justice américain restreignant les flux de données sensibles vers des adversaires étrangers ajoutent des niveaux de diligence raisonnable, mais élargissent simultanément les opportunités pour les bureaux de services nationaux spécialisés dans l'ingestion transfrontalière légale.
L'Asie-Pacifique est le territoire à la croissance la plus rapide, progressant à un CAGR de 18,66 % jusqu'en 2031. Les exportateurs manufacturiers chinois s'appuient sur des flux de données extraites des douanes et de l'expédition pour calibrer leurs prix, tandis que les champions des services informatiques indiens intègrent l'acquisition de données à grande échelle dans les contrats d'externalisation analytique. Les programmes de transformation numérique des entreprises japonaises stimulent la demande locale de frameworks d'extraction multilingues. Les places de marché d'Asie du Sud-Est accélèrent l'adoption à mesure que les super-applications de logistique, de voyage et de fintech se livrent des batailles de tarification en temps réel. L'Australie et la Nouvelle-Zélande complètent l'élan régional grâce aux desks de trading de matières premières qui extraient les données des escales portuaires et des trackers satellites.
L'Europe suit une trajectoire axée sur la conformité. La position restrictive du Comité Européen de la Protection des Données sur les données d'entraînement de l'IA impose des flux de travail évalués par les risques et des pipelines respectueux de la vie privée dès la conception. Les fournisseurs qui intègrent l'anonymisation, la gestion du consentement et les contrôles de minimisation des données bénéficient d'un avantage concurrentiel. Les acheteurs du Royaume-Uni équilibrent l'alignement sur le RGPD avec un appétit croissant pour les données alternatives dans le domaine du fintech, tandis que l'Allemagne et la France privilégient les constructions de cloud souverain pour les extractions critiques. L'hétérogénéité réglementaire à travers le continent soutient la demande de services consultatifs qui localisent les frameworks au cas par cas.

Paysage concurrentiel
Le marché du web scraping reste modérément fragmenté. Bright Data, Zyte, Apify et Oxylabs forment un niveau de spécialistes d'infrastructure à grande échelle, mais aucun ne contrôle une part dominante. La concurrence se déplace de la collecte brute vers la qualité, la disponibilité et la conformité. Les fournisseurs se différencient par leurs taux de réussite face aux suites anti-bot, l'étendue des pools de proxies et les conseils juridiques spécifiques à chaque région. L'orchestration infusée d'IA — nouvelles tentatives adaptatives, découverte de sélecteurs CSS pilotée par des modèles et étiquetage automatique — est devenue un prérequis incontournable.
Le positionnement stratégique révèle deux camps. Les plateformes horizontales courtisent chaque secteur vertical avec des API prêtes à l'emploi, tandis que les acteurs de niche ciblent une expertise approfondie sur des domaines uniques tels que les tarifs de voyage ou les classements des boutiques d'applications. La place de marché de Cloudflare avec paiement par bot laisse entendre que les opérateurs de plateformes pourraient bientôt monétiser des flux de données directs, transformant potentiellement d'anciens adversaires en partenaires de distribution. Les fournisseurs capables de pivoter tôt vers des modèles de partage des revenus ou des points de terminaison de première partie organisés protégeront leurs marges.
Les flux d'investissement favorisent les technologies avancées de contournement. Les start-ups spécialisées dans le camouflage de navigateurs sans interface graphique, la rotation dynamique des empreintes digitales et la résolution de CAPTCHA sur l'appareil attirent le capital-risque, anticipant une sophistication croissante du blocage du trafic. En réponse, les acteurs établis acquièrent des solutions ponctuelles pour accélérer leurs feuilles de route IA et intégrer des moniteurs de conformité en temps réel. Sur l'horizon de prévision, les leaders du marché devraient consolider les réseaux de proxies plus petits et les boutiques de conformité régionales pour renforcer la couverture géographique et la profondeur réglementaire.
Leaders du secteur du web scraping
Bright Data Ltd.
Zyte Group Ltd.
Apify Technologies s.r.o.
Octopus Data, Inc.
Import.io Ltd.
- *Avis de non-responsabilité : les principaux acteurs sont triés sans ordre particulier

Développements récents dans le secteur
- Janvier 2025 : Le Département de justice des États-Unis a mis en œuvre des règles complètes de protection des données empêchant l'accès aux données personnelles sensibles par des pays préoccupants, remodelant les flux de travail d'extraction transfrontalière.
- Janvier 2025 : Le Département de la santé et des services sociaux des États-Unis a publié son plan stratégique en matière d'IA, orientant de nouveaux fonds vers la recherche médicale pilotée par les données reposant sur la collecte automatisée.
- Octobre 2024 : Cloudflare a dévoilé une place de marché permettant aux éditeurs de facturer les bots d'IA pour l'accès au scraping, recadrant l'économie de la monétisation des données.
- Juillet 2024 : Apify a lancé Crawlee pour Python, étendant son cadre de crawling open source aux développeurs Python et élargissant l'écosystème de contributeurs.


Research Methodology Framework and Report Scope
Définitions du marché et couverture principale
Notre étude définit le marché du web scraping comme l'ensemble des plateformes logicielles commerciales et des services d'extraction gérés qui crawlent de manière programmatique des pages web publiques, analysent le contenu et livrent des ensembles de données structurées ou des flux en direct à des clients payants. La valorisation couvre les revenus de licences, d'abonnements et de services générés par les fournisseurs spécialisés dans la collecte de données à grande échelle et conforme aux exigences réglementaires.
Exclusion du périmètre : les scripts internes développés en interne et exécutés uniquement au sein d'une entreprise ne sont pas comptabilisés.
Aperçu de la segmentation
- Par solution
- Logiciels
- Services
- Par mode de déploiement
- Cloud
- Sur site
- Par secteur d'utilisateur final
- BFSI
- Commerce de détail et e-commerce
- Immobilier
- Fabrication
- Gouvernement
- Santé
- Publicité et médias
- Autres
- Par cas d'utilisation
- Extraction de données / ETL
- Surveillance des prix et de la concurrence
- Génération de leads et intelligence commerciale
- Données financières alternatives
- Analyse des sentiments et des réseaux sociaux
- Par géographie
- Amérique du Nord
- États-Unis
- Canada
- Mexique
- Amérique du Sud
- Brésil
- Argentine
- Reste de l'Amérique du Sud
- Europe
- Allemagne
- Royaume-Uni
- France
- Italie
- Espagne
- Russie
- Reste de l'Europe
- Asie-Pacifique
- Chine
- Japon
- Inde
- Corée du Sud
- Australie et Nouvelle-Zélande
- Reste de l'Asie-Pacifique
- Moyen-Orient et Afrique
- Moyen-Orient
- Arabie saoudite
- Émirats arabes unis
- Turquie
- Reste du Moyen-Orient
- Afrique
- Afrique du Sud
- Nigéria
- Kenya
- Reste de l'Afrique
- Moyen-Orient
- Amérique du Nord
Méthodologie de recherche détaillée et validation des données
Recherche primaire
Des entretiens structurés avec des responsables de produits de plateformes de données, des fournisseurs de réseaux de proxies et des responsables des achats en Amérique du Nord, en Europe et en Asie-Pacifique ont fourni des fourchettes de prix réelles, des taux de rétention et des coûts de conformité régionaux que les sources documentaires divulguent rarement.
Recherche documentaire
Les analystes de Mordor ont d'abord cartographié l'univers des fournisseurs en utilisant les dépôts publics d'entreprises, les formulaires SEC 10-K et les registres de fournisseurs technologiques tels que l'Office des brevets des États-Unis et les flux de brevets Questel. Nous avons ensuite extrait les signaux d'utilisation et de dépenses des groupes professionnels tels que l'Interactive Advertising Bureau, les associations régionales de commerce électronique et les journaux d'expédition douanière pour le matériel serveur, qui servent d'indicateurs avancés de la capacité des crawlers. Les articles académiques indexés sur IEEE Xplore ont clarifié les courbes d'adoption technique, tandis que les flux d'actualités agrégés dans Dow Jones Factiva ont aidé à dater les événements importants qui influencent les revenus. (Les sources citées illustrent le type utilisé et ne sont pas exhaustives.)
Dimensionnement du marché et prévisions
Un modèle descendant commence par les dépenses mondiales en technologies de l'information pour l'acquisition de données, isole la part attribuable aux flux de données web externes, et est ensuite filtré par la pénétration de l'adoption par secteurs verticaux tels que le commerce électronique et le BFSI. Des vérifications ascendantes sélectionnées — prix de vente moyen et nombre de clients actifs des fournisseurs échantillonnés — valident les totaux. Les variables clés suivies comprennent l'inflation des prix des proxies, les taux de réussite anti-bot, le nombre moyen de pages crawlées par tâche, la fréquence de dépréciation des API et les amendes de type RGPD régionales. Les prévisions utilisent une régression multivariée soutenue par un consensus d'experts pour projeter comment ces facteurs façonnent le volume et les prix jusqu'en 2030.
Validation des données et cycle de mise à jour
Les résultats passent des contrôles de variance par rapport aux flux d'investissement en données alternatives et aux statistiques de bande passante cloud avant qu'un analyste senior ne les valide. Le modèle est actualisé annuellement, avec des mises à jour en cours de cycle déclenchées par des décisions juridiques importantes ou des évolutions technologiques ; une vérification finale est effectuée juste avant la publication du rapport.
Pourquoi la base de référence du web scraping de Mordor est-elle fiable
Les estimations publiées divergent souvent parce que les entreprises découpent le marché différemment, convertissent les devises à des dates variées ou regroupent des segments adjacents dans un même ensemble.
Les principaux facteurs d'écart comprennent la prise en compte ou non des revenus des services, la manière dont les déploiements open source sont traités et la cadence à laquelle les hypothèses de prix de vente moyen sont actualisées. Des études externes situent le marché 2025 entre 0,78 milliard USD et 0,81 milliard USD pour les périmètres logiciels uniquement. Certaines études larges regroupent plusieurs marchés adjacents et publient un chiffre de 6,77 milliards USD pour 2024.
Comparaison de référence
| Taille du marché | Source anonymisée | Principal facteur d'écart |
|---|---|---|
| 1,03 milliard USD (2025) | ||
| 0,78 milliard USD (2025) | Cabinet de conseil régional A | Comptabilise uniquement les logiciels, exclut les services gérés |
| 0,81 milliard USD (2025) | Revue professionnelle B | Ensemble de fournisseurs restreint, pas de normalisation des devises |
| 6,77 milliards USD (2024) | Association professionnelle C | Agrège les logiciels, les services et les revenus des places de marché de données adjacentes |
Ces contrastes montrent que lorsque le périmètre et la cadence d'actualisation diffèrent, les résultats varient considérablement. Les règles d'inclusion équilibrées de Mordor, la modélisation à double trajectoire et les mises à jour annuelles offrent aux décideurs une base de référence transparente et reproductible qui s'aligne étroitement sur les signaux de dépenses observables et les revenus vérifiables des fournisseurs.


Questions clés auxquelles le rapport répond
Quelle est la taille actuelle du marché du web scraping ?
Le marché du web scraping s'élève à 1,56 milliard USD en 2026 et devrait atteindre 3,49 milliards USD d'ici 2031, avec un CAGR de 17,39 %.
Quelle région est en tête du marché du web scraping ?
L'Amérique du Nord détient la plus grande part de revenus de 34,08 % grâce à l'adoption mature des services financiers et à une infrastructure cloud robuste.
Pourquoi les services croissent-ils plus vite que les logiciels dans le web scraping ?
Les entreprises externalisent de plus en plus les défis complexes de conformité et anti-bot, poussant le segment des services à un CAGR de 18,62 % malgré le maintien par les logiciels de revenus absolus plus élevés.
Quel est le cas d'usage en expansion la plus rapide ?
La surveillance des prix et de la veille concurrentielle progresse à un CAGR de 18,34 % à mesure que les détaillants et les plateformes numériques s'appuient sur les données concurrentielles en temps réel pour des stratégies de tarification dynamique.
Comment les réglementations affectent-elles les projets de web scraping ?
Les nouvelles règles telles que les restrictions américaines du Département de Justice sur les données sensibles et les interprétations plus strictes du RGPD en Europe alourdissent les charges juridiques, stimulant la demande de solutions d'extraction gérées et conformes.
Comment les réglementations affectent-elles les projets de web scraping ?
De nouvelles règles telles que les restrictions sur les données sensibles du Département de justice des États-Unis et des interprétations plus strictes du RGPD en Europe augmentent les frais juridiques, stimulant la demande de solutions d'extraction gérées et conformes.
Dernière mise à jour de la page le:




