Taille et part du marché Hadoop aux États-Unis
VUE D’ENSEMBLE DU MARCHÉ
| Période d'étude | 2019 - 2030 |
|---|---|
| Période de Données Prévisionnelles | 2025 - 2030 |
| Période de Données Historiques | 2019 - 2023 |
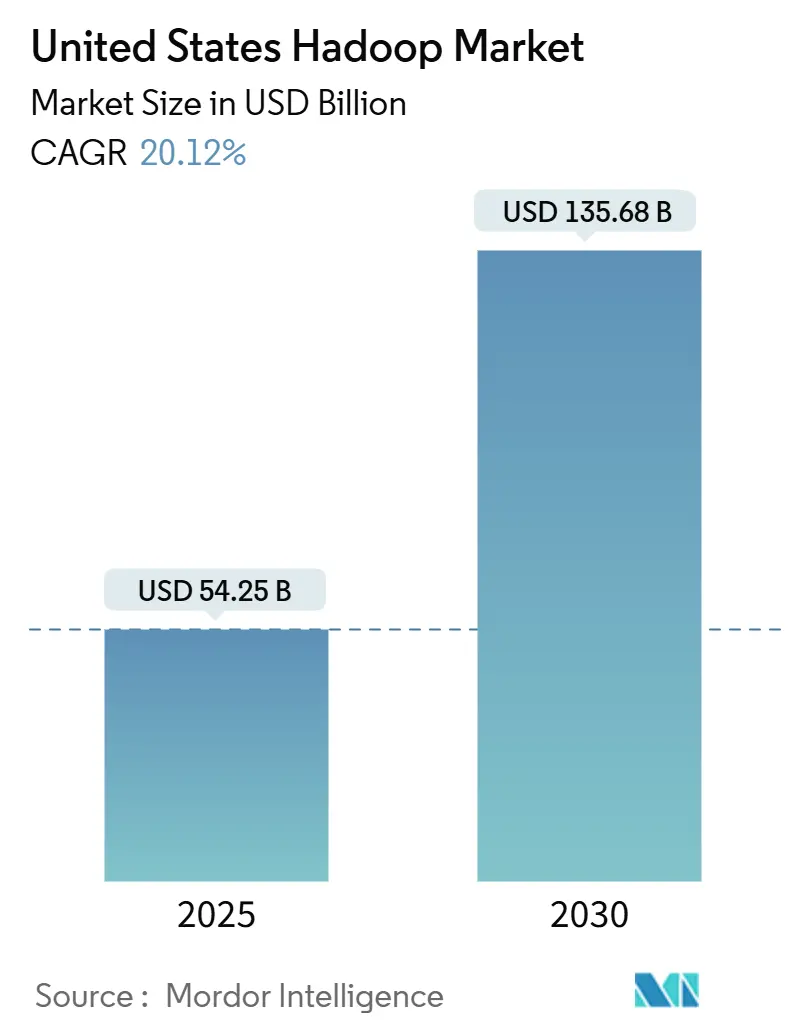
| Taille du Marché (2025) | 54.25 Milliards de dollars |
| Taille du Marché (2030) | 135.68 Milliards de dollars |
| Taux de croissance (2025 - 2030) | 20.12% CAGR |
| Concentration du Marché | Moyen |
Acteurs majeurs *Avis de non-responsabilité : les principaux acteurs sont triés sans ordre particulier Image © Mordor Intelligence. La réutilisation nécessite une attribution sous CC BY 4.0. | |
Analyse du marché Hadoop aux États-Unis par Mordor Intelligence
La taille du marché Hadoop aux États-Unis s'établit à 54,25 milliards USD en 2025 et devrait atteindre 135,68 milliards USD d'ici 2030, ce qui correspond à un CAGR solide de 20,12 % sur la période de prévision. L'explosion des volumes de données, les programmes de transformation numérique agressifs et la transition hors des entrepôts de données traditionnels positionnent le marché Hadoop aux États-Unis comme une infrastructure indispensable pour l'analytique de niveau entreprise. Les composants logiciels restent centraux, mais les services fournis via le cloud captent une part croissante des budgets, les organisations recherchant des clusters gérés qui s'adaptent à la demande. Sur le plan régional, le Sud concentre le plus grand volume de dépenses tandis que l'Ouest accélère le plus rapidement, reflétant le volant d'innovation de la Silicon Valley. La rivalité concurrentielle reste intense, les acteurs établis défendant leurs parts face aux hyperscalers cloud et aux nouveaux entrants de type lakehouse qui promettent une gestion simplifiée et une vitesse de requête améliorée.
Principaux enseignements du rapport
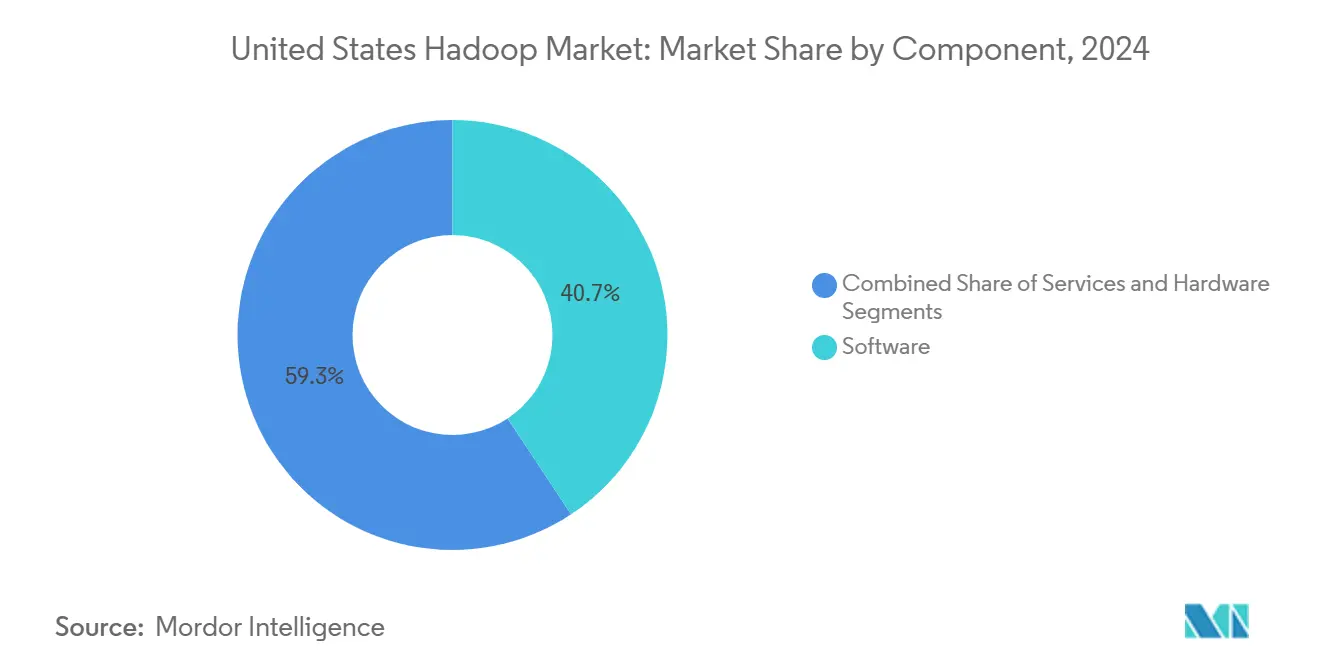
- Par composant, le logiciel a représenté 40,7 % de la part du marché Hadoop aux États-Unis en 2024, tandis que les services progressent à un CAGR de 20,92 % jusqu'en 2030.
- Par modèle de déploiement, les solutions sur site détenaient 52,8 % de la taille du marché Hadoop aux États-Unis en 2024 ; les déploiements cloud s'étendent à un CAGR de 21,3 % jusqu'en 2030.
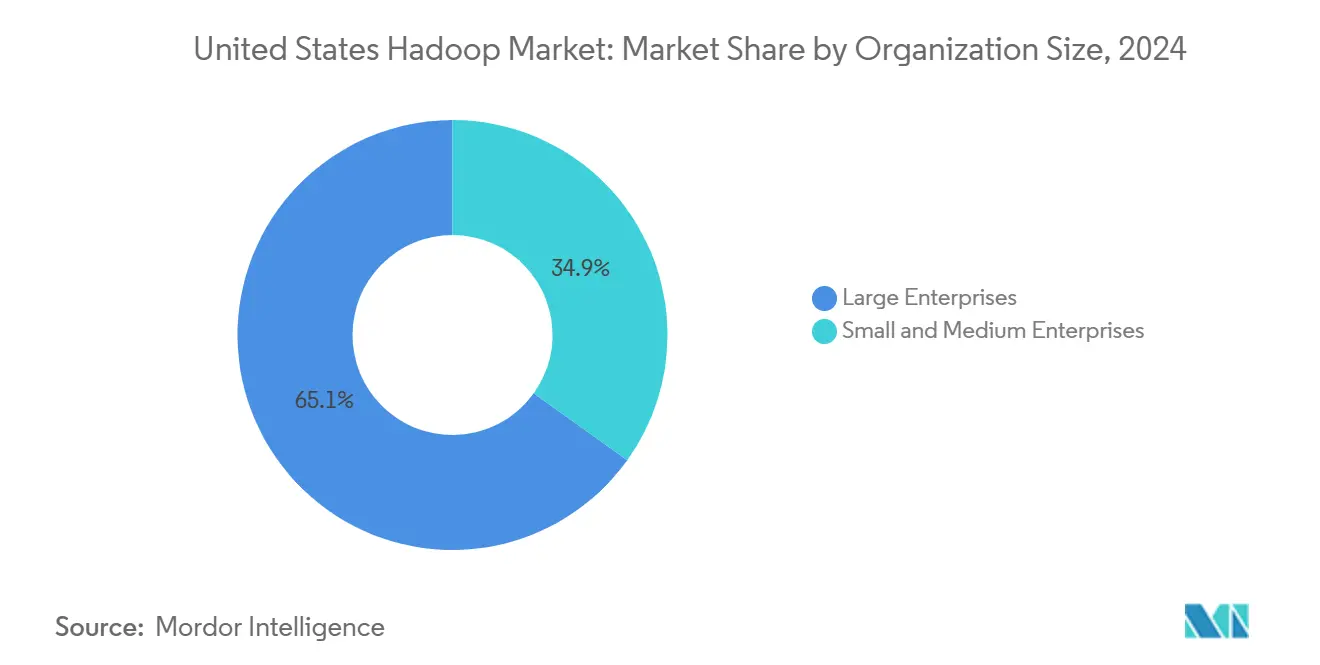
- Par taille d'organisation, les grandes entreprises représentaient une part dominante de 65,1 % du marché Hadoop aux États-Unis en 2024, tandis que les PME devraient afficher un CAGR de 20,7 % jusqu'en 2030.
- Par secteur d'activité des utilisateurs finaux, les technologies de l'information et les télécommunications contrôlaient 30,02 % des dépenses en 2024 sur le marché Hadoop aux États-Unis, tandis que la santé et les sciences de la vie devraient croître à un CAGR de 22,3 % jusqu'en 2030.
- Par région, le Sud était en tête avec une contribution aux revenus de 38,31 % du marché Hadoop aux États-Unis en 2024 ; l'Ouest mène le peloton avec un CAGR de 21,5 % durant la période de prévision.
Tendances et perspectives du marché Hadoop aux États-Unis
Analyse de l'impact des moteurs*
| Moteur | (~) % d'impact sur les prévisions de CAGR | Pertinence géographique | Horizon temporel de l'impact |
|---|---|---|---|
| Explosion des volumes de données d'entreprise et besoin de traitement évolutif | +4.2% | National, avec concentration dans les régions Sud et Ouest | Long terme (≥ 4 ans) |
| Transition vers des modèles Hadoop en tant que service basés sur le cloud | +3.8% | National, avec adoption précoce dans l'Ouest et le Nord-Est | Moyen terme (2 à 4 ans) |
| Avantages en termes de coûts par rapport aux solutions EDW traditionnelles | +2.9% | National, particulièrement dans le segment des PME sensibles aux coûts | Moyen terme (2 à 4 ans) |
| Intégration des charges de travail d'intelligence artificielle et d'apprentissage automatique dans les écosystèmes Hadoop | +3.5% | Pôles technologiques de l'Ouest et du Nord-Est | Long terme (≥ 4 ans) |
| Demande croissante d'analytique de conformité dans les secteurs réglementés | +2.1% | National, avec accent sur les secteurs BFSI et santé | Moyen terme (2 à 4 ans) |
| Ingestion de données en périphérie et IoT stimulant l'analytique Hadoop quasi en temps réel | +1.8% | Régions manufacturières du Midwest et du Sud | Long terme (≥ 4 ans) |
| Source: Mordor Intelligence | |||
L'explosion des volumes de données d'entreprise nécessite un traitement évolutif
Les canaux numériques, les capteurs IoT et les obligations strictes de conservation des données font gonfler les stocks de données à l'échelle du pétaoctet, dépassant le débit des entrepôts conventionnels. Une enquête d'IBM a révélé que 73 % des entreprises américaines ont enregistré une croissance annuelle des données supérieure à 40 %.[1]IBM, "Enquête sur la gestion des données d'entreprise 2024," ibm.com Le système de fichiers distribué de Hadoop et ses capacités de calcul parallélisé permettent aux entreprises de suivre le rythme sans réécrire les schémas ni réarchitecturer le matériel. La possibilité d'ajouter linéairement des nœuds de base transforme la planification de la capacité, qui passe d'un pari en dépenses d'investissement à un exercice incrémental. À mesure que les appareils en périphérie alimentent des données de télémétrie supplémentaires, les clusters Hadoop centralisés deviennent l'agrégateur de choix pour l'analytique en aval, la maintenance prédictive et la détection d'anomalies. Les entreprises considèrent désormais le traitement évolutif non pas comme une expérimentation facultative, mais comme un pilier central de la continuité des activités et de l'agilité concurrentielle.
Les modèles Hadoop en tant que service basés sur le cloud démocratisent l'adoption du big data
Les services gérés tels qu'Amazon EMR et Azure HDInsight abaissent la barrière opérationnelle en abstrayant le provisionnement des clusters, les correctifs et le renforcement de la sécurité. AWS a introduit EMR sans serveur en 2024, permettant aux charges de travail de s'adapter automatiquement et de ne facturer que les ressources consommées.[2]Amazon Web Services, "Amazon EMR sans serveur pour Apache Spark," amazon.com Le modèle de service répond aux besoins des organisations qui manquent d'expertise approfondie en Hadoop, permettant aux équipes de données de se concentrer sur les insights plutôt que sur l'infrastructure. La tarification à la consommation fait passer le budget des dépenses d'investissement aux dépenses d'exploitation, supprimant le choc tarifaire historiquement lié aux déploiements sur site. À mesure que les stratégies multi-cloud se normalisent, la portabilité entre fournisseurs s'améliore, élargissant encore le marché adressable pour le marché Hadoop aux États-Unis.
Avantages en termes de coûts par rapport aux systèmes d'entrepôt de données traditionnels
Une analyse comparative d'Oracle a révélé des économies sur le coût total de possession de 60 à 70 % lorsque Hadoop remplace des appliances d'entrepôt de données propriétaires à échelle comparable. La licence open source élimine les frais de plateforme, tandis que les serveurs de base évitent la prime exigée par le matériel spécialisé. La conception de type schéma à la lecture reporte les décisions de modélisation des données jusqu'au moment de la requête, réduisant la charge ETL et accélérant le lancement des projets. Les entreprises confrontées à des pics d'ingestion de données apprécient que la mise à l'échelle de Hadoop nécessite l'achat de nœuds supplémentaires plutôt que des mises à niveau complètes. Pour les PME sensibles aux coûts, ces économies rendent accessible l'analytique avancée autrefois réservée aux grandes entreprises, renforçant l'attrait de la livraison hébergée dans le cloud.
Intégration des charges de travail d'intelligence artificielle et d'apprentissage automatique dans les écosystèmes Hadoop
Les pipelines d'apprentissage automatique prospèrent sur de vastes ensembles de données étiquetées qui résident nativement dans les clusters Hadoop. Le lien de Google Cloud entre Vertex AI et Dataproc permet l'entraînement des modèles à proximité des données, réduisant considérablement la latence de transfert et les frais de sortie. Des frameworks tels que Spark MLlib et TensorFlow sur YARN exploitent la mémoire distribuée, accélérant la convergence des algorithmes. Les fournisseurs intègrent l'AutoML, des accélérateurs d'ingénierie des caractéristiques et la planification GPU pour rationaliser l'expérimentation. À mesure que les cas d'usage évoluent des tableaux de bord rétrospectifs vers la reconnaissance de modèles en temps réel, Hadoop s'impose comme le terrain de préparation pour le développement itératif, l'évaluation et le déploiement de modèles à grande échelle.
Analyse de l'impact des freins*
| Frein | (~) % d'impact sur les prévisions de CAGR | Pertinence géographique | Horizon temporel de l'impact |
|---|---|---|---|
| Pénurie aiguë de talents Hadoop et courbes d'apprentissage abruptes | -2.8% | National, particulièrement prononcé dans le Midwest et le Sud | Court terme (≤ 2 ans) |
| Migration croissante vers des plateformes lakehouse cloud cannibalisant Hadoop sur site | -3.2% | National, avec concentration dans les régions à forte orientation technologique | Moyen terme (2 à 4 ans) |
| Préoccupations persistantes en matière de sécurité des données et de gouvernance | -1.9% | National, avec accent sur les secteurs réglementés | Moyen terme (2 à 4 ans) |
| Dette technique des clusters existants et coûts de maintenance élevés | -2.1% | National, particulièrement dans les organisations ayant adopté Hadoop en premier | Long terme (≥ 4 ans) |
| Source: Mordor Intelligence | |||
Pénurie aiguë de talents Hadoop
Une étude de l'IEEE a rapporté que 68 % des entreprises peinent à recruter des professionnels Hadoop qualifiés, les postes vacants restant ouverts en moyenne 4,5 mois. L'écosystème exige des compétences en HDFS, YARN, MapReduce, Spark et dans des frameworks de sécurité tels que Ranger et Knox. La reconversion des administrateurs de bases de données s'étend souvent sur 12 à 18 mois, freinant la rapidité de déploiement. Les disparités régionales aggravent la pression : les entreprises situées en dehors des pôles technologiques de premier rang font face à des primes de relocalisation qui réduisent les économies de coûts de Hadoop. Les bootcamps et les programmes universitaires se développent mais pourraient ne pas combler rapidement le déficit, pesant sur l'expansion à court terme du marché Hadoop aux États-Unis.
La migration vers les plateformes lakehouse cloud cannibalise les clusters Hadoop traditionnels
Des plateformes unifiées comme Databricks et Snowflake regroupent le stockage, l'analytique et la gouvernance en un seul service, remettant en cause la complexité multi-composants de Hadoop. L'argumentaire lakehouse de Databricks, offrant des performances de niveau entrepôt sur des lacs de données en format ouvert, séduit les équipes lasses de régler plusieurs moteurs.[3]Databricks, "Architecture de référence Lakehouse," databricks.com Les kits de migration, les crédits promotionnels et les analyses comparatives de performance incitent les entreprises à changer de plateforme plutôt qu'à moderniser leurs clusters sur site. Bien que de nombreuses entreprises adoptent une coexistence hybride, les nouvelles charges de travail pourraient contourner entièrement Hadoop, entraînant une réduction des dépenses adressables à moyen terme.
*Nos prévisions considèrent les impacts des moteurs et des contraintes comme directionnels et non additifs. Les prévisions d'impact reflètent la croissance de référence, les effets de composition et les interactions entre variables.
Analyse des segments
Par composant : les services prennent de l'élan tandis que le logiciel conserve sa position centrale
Le logiciel est resté dominant, captant 40,7 % des dépenses au sein du marché Hadoop aux États-Unis en 2024, les entreprises renouvelant leurs abonnements pour le support de distribution, les correctifs de sécurité et les modules d'analytique complémentaires. Les fournisseurs se sont concentrés sur le renforcement des fonctionnalités, une meilleure compatibilité SQL et un packaging natif cloud pour préserver les bases installées.
Les services, cependant, progressent plus rapidement à un CAGR de 20,92 %, reflétant la préférence des dirigeants pour le déploiement clé en main, le réglage des clusters et les opérations gérées. Cloudera a élargi son équipe de services professionnels de 200 consultants en 2024 pour répondre à cette demande de conseil. À mesure que les obligations réglementaires se renforcent, les acheteurs s'appuient sur des intégrateurs de systèmes maîtrisant HIPAA, PCI-DSS et FedRAMP pour configurer des pipelines conformes. Le matériel s'est restreint à des cas d'usage de niche tels que les nœuds en périphérie durcis, renforçant le passage des dépenses d'investissement aux modèles opérationnels centrés sur les services au sein du marché Hadoop aux États-Unis.



Par modèle de déploiement : la trajectoire cloud remet en cause les droits acquis sur site
Les parcs sur site représentaient encore 52,8 % de la taille du marché Hadoop aux États-Unis en 2024, en raison des investissements déjà réalisés, des mandats de souveraineté des données et du couplage applicatif à faible latence. Les institutions financières et les agences du secteur public maintiennent souvent des clusters isolés pour des raisons d'audit et de sécurité.
Les alternatives cloud s'accélèrent à un CAGR de 21,3 % jusqu'en 2030, portées par EMR sans serveur, HDInsight à mise à l'échelle automatique et les offres de types de machines personnalisés de Google Dataproc. Ces services neutralisent les difficultés de planification de la capacité et réduisent les délais de mise en œuvre de plusieurs mois à quelques heures. Les architectures hybrides, où les ensembles de données sensibles résident sur site tandis que les charges de travail en pic s'exécutent dans le cloud, deviennent la norme. La flexibilité architecturale qui en résulte renforce la diversité des dépenses au sein du marché Hadoop aux États-Unis.
Par taille d'organisation : les PME réduisent l'écart d'utilisation
Les grandes entreprises détenaient une part de 65,1 % en 2024, exploitant de vastes pools de données pour exécuter la détection de fraude, la personnalisation omnicanale et l'optimisation de la chaîne d'approvisionnement sur des clusters multi-pétaoctets. Des équipes de plateforme dédiées appliquent des objectifs de niveau de service qui maintiennent Hadoop au cœur des processus critiques.
Les PME constituent la cohorte à la croissance la plus rapide, avec un CAGR de 20,7 %, alimenté par des licences à la consommation et des assistants de déploiement basés sur des modèles. HDInsight Essentials de Microsoft cible les petites entreprises ayant des besoins de traitement par lots prévisibles et un personnel limité. À mesure que les PME numérisent leurs flux de travail front-office et back-office, Hadoop devient l'épine dorsale analytique qui convertit les données opérationnelles en insights prédictifs, élargissant ainsi la pénétration du marché Hadoop aux États-Unis.
Par secteur d'activité des utilisateurs finaux : la santé mène le classement de la croissance
Les fournisseurs de technologies de l'information et de télécommunications représentaient 30,02 % du chiffre d'affaires total en 2024, utilisant Hadoop pour la télémétrie réseau en temps réel, l'analytique de l'expérience client et la lutte contre la fraude à la facturation. La tolérance à la latence s'est améliorée grâce à Spark Streaming, soutenant l'appétit du secteur pour le calcul distribué.
La santé et les sciences de la vie sont en passe de dépasser leurs pairs avec un CAGR de 22,3 %, car le séquençage génomique, la fusion des données d'essais cliniques et les tableaux de bord de santé des populations exigent une mise à l'échelle rentable. La position croissante de la FDA sur les données probantes du monde réel souligne l'importance de la conformité avec une traçabilité des données vérifiable. Les commanditaires pharmaceutiques s'appuient sur Hadoop pour ingérer des dossiers de santé électroniques, des données de remboursement et des flux de capteurs portables, renforçant la dynamique propre au secteur au sein du marché Hadoop aux États-Unis.
Analyse géographique
Le Sud représentait 38,31 % des revenus nationaux en 2024, porté par de vastes corridors de centres de données au Texas, en Caroline du Nord et en Floride. Les incitations tarifaires sur les services publics, les faibles coûts énergétiques et les régimes fiscaux favorables aux entreprises ont attiré aussi bien les hyperscalers que les locataires d'entreprise. AWS a ajouté de nouvelles zones de disponibilité US-Est en Caroline du Nord en 2025, améliorant la latence régionale et renforçant la confiance dans les charges de travail Hadoop fournies via le cloud.[4]Amazon Web Services, "Expansion de la région US-Est 2025," amazon.com
L'Ouest est le meneur, avec un CAGR de 21,5 % jusqu'en 2030. Le vivier de talents profond de la Silicon Valley, associé au soutien du capital-risque, entretient un pipeline de start-ups d'ingénierie des données qui standardisent sur les fondations Hadoop. Les lois californiennes sur la vie privée, telles que la CPRA, intensifient les investissements dans les outils de gouvernance, stimulant indirectement les dépenses en modules de métadonnées et de sécurité. Les expansions de Google en Oregon et au Nevada privilégient les instances à haute mémoire adaptées aux cas d'usage du big data, renforçant l'épine dorsale cloud régionale.
Les clusters du Nord-Est et du Midwest représentent ensemble une part significative, ancrés par la concentration des services financiers de New York et la ceinture manufacturière des Grands Lacs. Les lancements de zones cloud à Chicago réduisent la latence pour les clients du Midwest, tandis que les fintechs new-yorkaises utilisent Hadoop pour répondre aux exigences de risque et de reporting en temps réel. La disponibilité de la main-d'œuvre et les coûts d'installation plus élevés tempèrent l'accélération à court terme, mais les subventions à la modernisation et les laboratoires d'innovation public-privé visent à maintenir l'engagement envers le marché Hadoop aux États-Unis.
Paysage concurrentiel
La concurrence mêle des fournisseurs d'entreprise historiques, des hyperscalers cloud et des perturbateurs spécialisés. Cloudera, IBM et Oracle renforcent leurs portefeuilles grâce à des certifications de sécurité, à l'accélération GPU et à des suites d'observabilité. Les fournisseurs cloud exploitent les économies d'échelle pour proposer Hadoop géré comme point d'entrée vers des boîtes à outils de plateforme de données plus larges, intensifiant la concurrence sur les prix et les performances. La concentration des parts de marché reste modérée ; les cinq premiers fournisseurs contrôlent collectivement environ 45 % des revenus, favorisant à la fois les opérations de consolidation et les opportunités de niche.
Les acteurs émergents défient la notoriété des acteurs établis. Le modèle lakehouse de Databricks et le traitement des données non structurées de Snowflake captent des charges de travail supplémentaires en offrant la simplicité d'une plateforme unique. Les dépôts de brevets autour de la mise en cache en colonnes, des fédérations de requêtes et du déploiement natif Kubernetes ont fortement augmenté en 2025, signalant une course à la propriété intellectuelle différenciée.
Les partenariats prospèrent comme monnaie stratégique. Oracle prend désormais en charge les déploiements multi-cloud de son service Big Data via AWS Direct Connect et Google Interconnect, aidant les clients qui poursuivent une diversification des fournisseurs. Le rachat de StreamSets par IBM introduit la conception automatisée de pipelines de données, réduisant les frictions à l'intégration. L'injection de 150 millions USD de Cloudera dans des interfaces de recherche alimentées par l'intelligence artificielle vise à réduire le taux d'attrition des clients en intégrant des insights en langage naturel dans son écosystème. Collectivement, ces mouvements illustrent un marché qui pivote des revendications de débit brut vers des propositions de valeur axées sur les résultats au sein du marché Hadoop aux États-Unis.
Leaders du secteur Hadoop aux États-Unis
Cloudera, Inc.
Amazon Web Services, Inc.
Microsoft Corporation
IBM Corporation
Google LLC
- *Avis de non-responsabilité : les principaux acteurs sont triés sans ordre particulier

Développements récents dans le secteur
- Octobre 2025 : Cloudera a annoncé un investissement de 150 millions USD pour intégrer des requêtes par intelligence artificielle générative et une optimisation automatisée des pipelines dans sa distribution phare.
- Septembre 2025 : Microsoft a activé des clusters accélérés par GPU dans Azure HDInsight pour les charges de travail TensorFlow et PyTorch.
- Août 2025 : Amazon Web Services a lancé EMR sans serveur pour Apache Spark, supprimant la charge de gestion des clusters.
- Juillet 2025 : IBM a acquis StreamSets pour 300 millions USD afin de faire progresser ses capacités d'intégration de données en cloud hybride.
- Juin 2025 : Oracle a dévoilé des partenariats avec Databricks et Snowflake, proposant des solutions lakehouse intégrées.


Périmètre du rapport sur le marché Hadoop aux États-Unis
| Logiciel |
| Matériel |
| Services |
| Sur site |
| Cloud |
| Hybride |
| Grandes entreprises |
| Petites et moyennes entreprises |
| BFSI |
| Commerce de détail et biens de consommation |
| Santé et sciences de la vie |
| Technologies de l'information et télécommunications |
| Industrie manufacturière |
| Autres secteurs d'activité des utilisateurs finaux |
| Nord-Est |
| Midwest |
| Sud |
| Ouest |
| Par composant | Logiciel |
| Matériel | |
| Services | |
| Par modèle de déploiement | Sur site |
| Cloud | |
| Hybride | |
| Par taille d'organisation | Grandes entreprises |
| Petites et moyennes entreprises | |
| Par secteur d'activité des utilisateurs finaux | BFSI |
| Commerce de détail et biens de consommation | |
| Santé et sciences de la vie | |
| Technologies de l'information et télécommunications | |
| Industrie manufacturière | |
| Autres secteurs d'activité des utilisateurs finaux | |
| Par région | Nord-Est |
| Midwest | |
| Sud | |
| Ouest |


Questions clés auxquelles le rapport répond
Quelle est la taille du marché Hadoop aux États-Unis en 2025 ?
La taille du marché Hadoop aux États-Unis est de 54,25 milliards USD en 2025.
Quel CAGR est prévu pour les dépenses Hadoop aux États-Unis jusqu'en 2030 ?
Les dépenses devraient croître à un CAGR de 20,12 % entre 2025 et 2030.
Quelle région américaine connaît la croissance la plus rapide pour les déploiements Hadoop ?
L'Ouest devrait afficher un CAGR de 21,5 %, porté par l'écosystème d'innovation de la Silicon Valley.
Quel secteur vertical devrait connaître la croissance la plus rapide ?
La santé et les sciences de la vie devraient progresser à un CAGR de 22,3 % jusqu'en 2030.
Quel est le principal obstacle à une adoption plus large de Hadoop ?
Une pénurie nationale de professionnels Hadoop expérimentés constitue la principale contrainte, entraînant des délais de recrutement et des coûts supplémentaires.
Comment les services cloud influencent-ils l'adoption de Hadoop par les PME ?
Les offres Hadoop en tant que service basées sur le cloud fournissent une évolutivité à la consommation et des opérations gérées, permettant aux PME d'adopter l'analytique big data sans lourds investissements initiaux en capital.
Dernière mise à jour de la page le:




