Taille et parts du marché de la reconnaissance optique de caractères
VUE D’ENSEMBLE DU MARCHÉ
| Période d'étude | 2020 - 2031 |
|---|---|
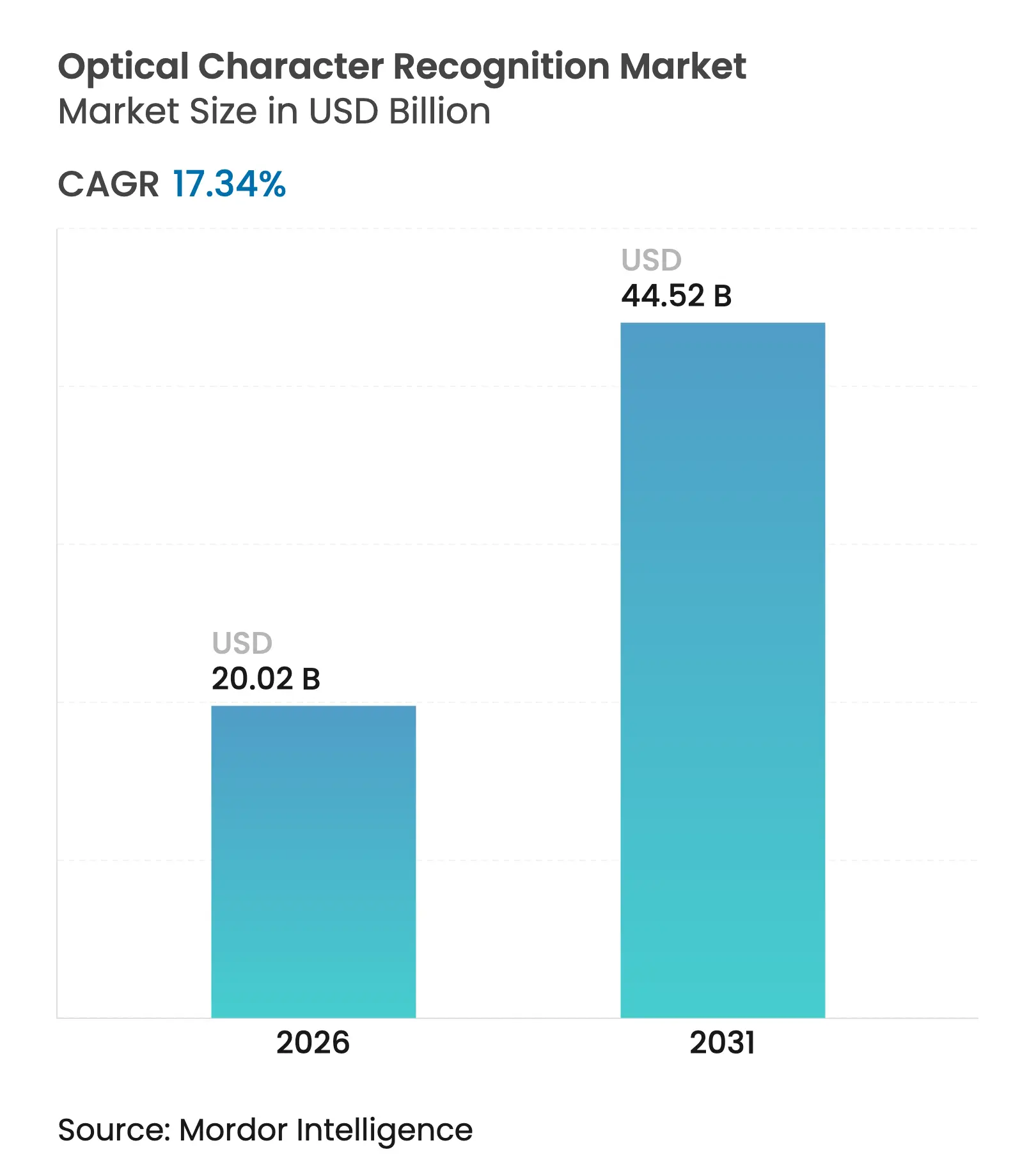
| Taille du Marché (2026) | 20.02 Milliards de dollars |
| Taille du Marché (2031) | 44.52 Milliards de dollars |
| Taux de croissance (2026 - 2031) | 17.34% CAGR |
| Marché à la Croissance la Plus Rapide | Asie-Pacifique |
| Plus Grand Marché | Amérique du Nord |
| Concentration du Marché | Moyen |
Acteurs majeurs *Avis de non-responsabilité : les principaux acteurs sont triés sans ordre particulier Image © Mordor Intelligence. La réutilisation nécessite une attribution sous CC BY 4.0. | |
Analyse du marché de la reconnaissance optique de caractères par Mordor Intelligence
La taille du marché de la reconnaissance optique de caractères devrait passer de 17,06 milliards USD en 2025 à 20,02 milliards USD en 2026 et devrait atteindre 44,52 milliards USD d'ici 2031, à un TCAC de 17,34 % sur la période 2026-2031. La croissance est portée par les gains de précision liés à l'IA, l'expansion du déploiement cloud et des mandats réglementaires plus stricts qui encouragent les contrôles de conformité automatisés. Les fournisseurs de technologies passent des moteurs OCR autonomes à des plateformes d'intelligence documentaire complètes qui combinent reconnaissance, classification et validation dans un flux de travail unique. Les grands modèles de langage multimodaux, capables de lire à la fois des images et du texte, réduisent les coûts de traitement par page et élargissent l'adoption auprès des petites et moyennes entreprises. L'intensification de la concurrence pousse les fournisseurs à se différencier par des modèles spécifiques à un domaine, la prise en charge de langues et des analyses à valeur ajoutée plutôt que par la seule vitesse d'extraction.
Principaux enseignements du rapport
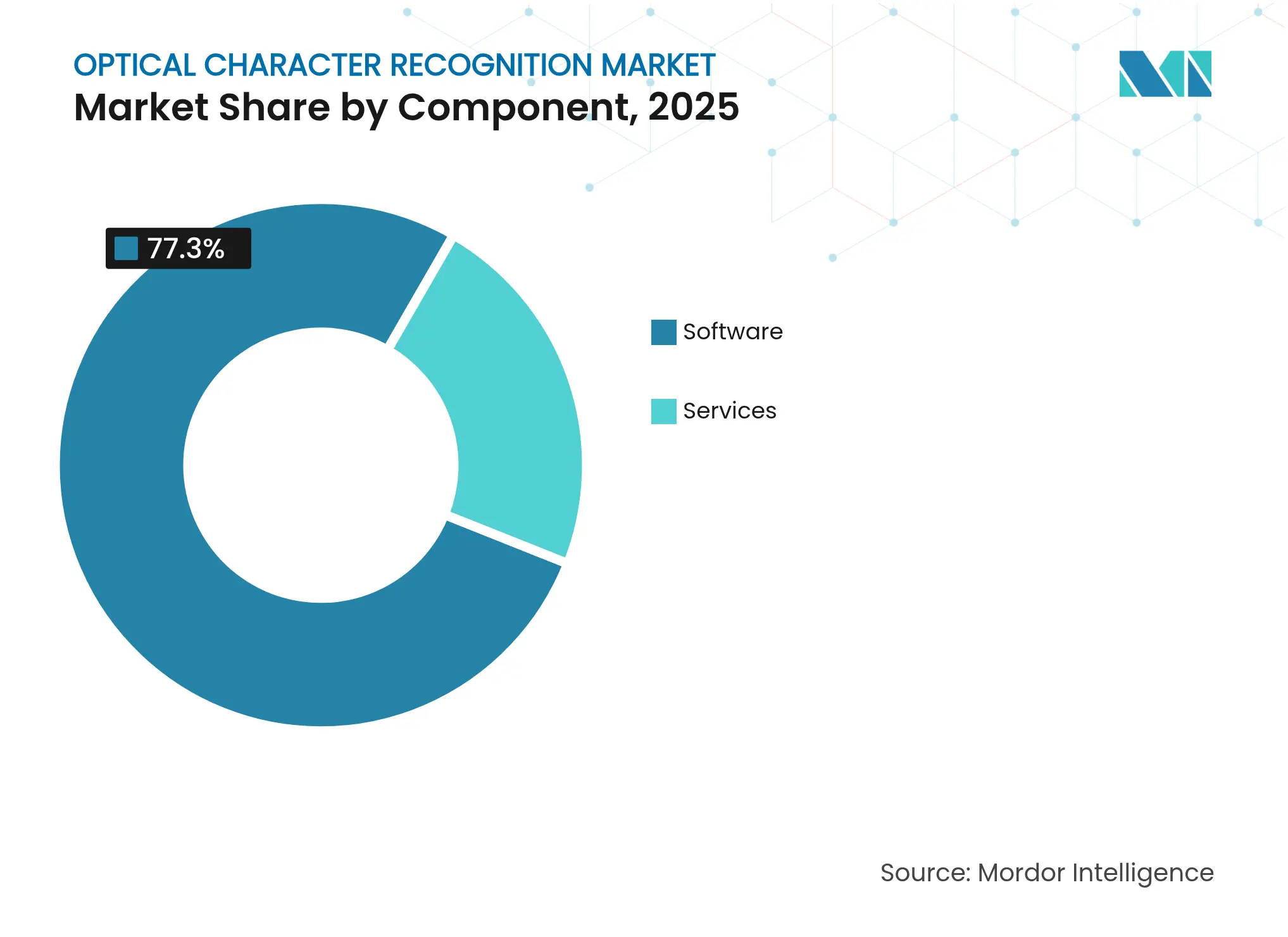
- Par composant, les logiciels ont représenté 77,30 % des revenus en 2025, tandis que les services devraient progresser à un TCAC de 17,36 % jusqu'en 2031.
- Par mode de déploiement, le cloud a représenté 65,20 % de la part du marché de la reconnaissance optique de caractères en 2025 ; les solutions sur site connaissent la croissance la plus rapide avec un TCAC de 15,45 % jusqu'en 2031.
- Par technologie, l'OCR conventionnel a conservé une part de 70,40 % en 2025 ; la reconnaissance intelligente de caractères progresse à un TCAC de 18,95 % sur la période de prévision.
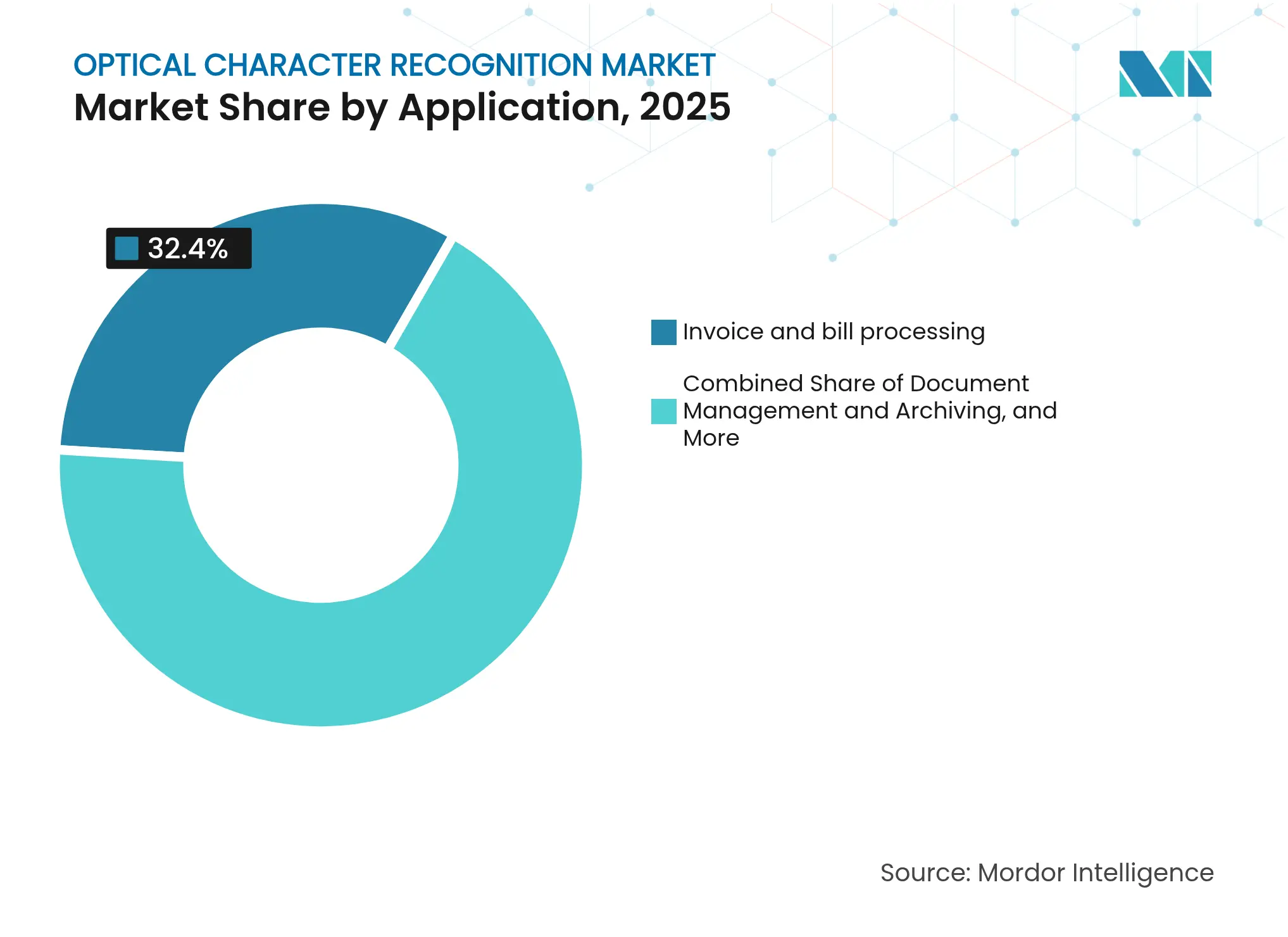
- Par application, le traitement des factures et des notes a représenté 32,40 % de la taille du marché de la reconnaissance optique de caractères en 2025, tandis que la vérification d'identité et la conformité KYC devraient croître à un TCAC de 17,85 %.
- Par secteur d'utilisation finale, le BFSI a représenté 25,60 % de la taille du marché de la reconnaissance optique de caractères en 2025, mais le secteur de la santé devrait afficher le TCAC le plus élevé à 19,45 %.
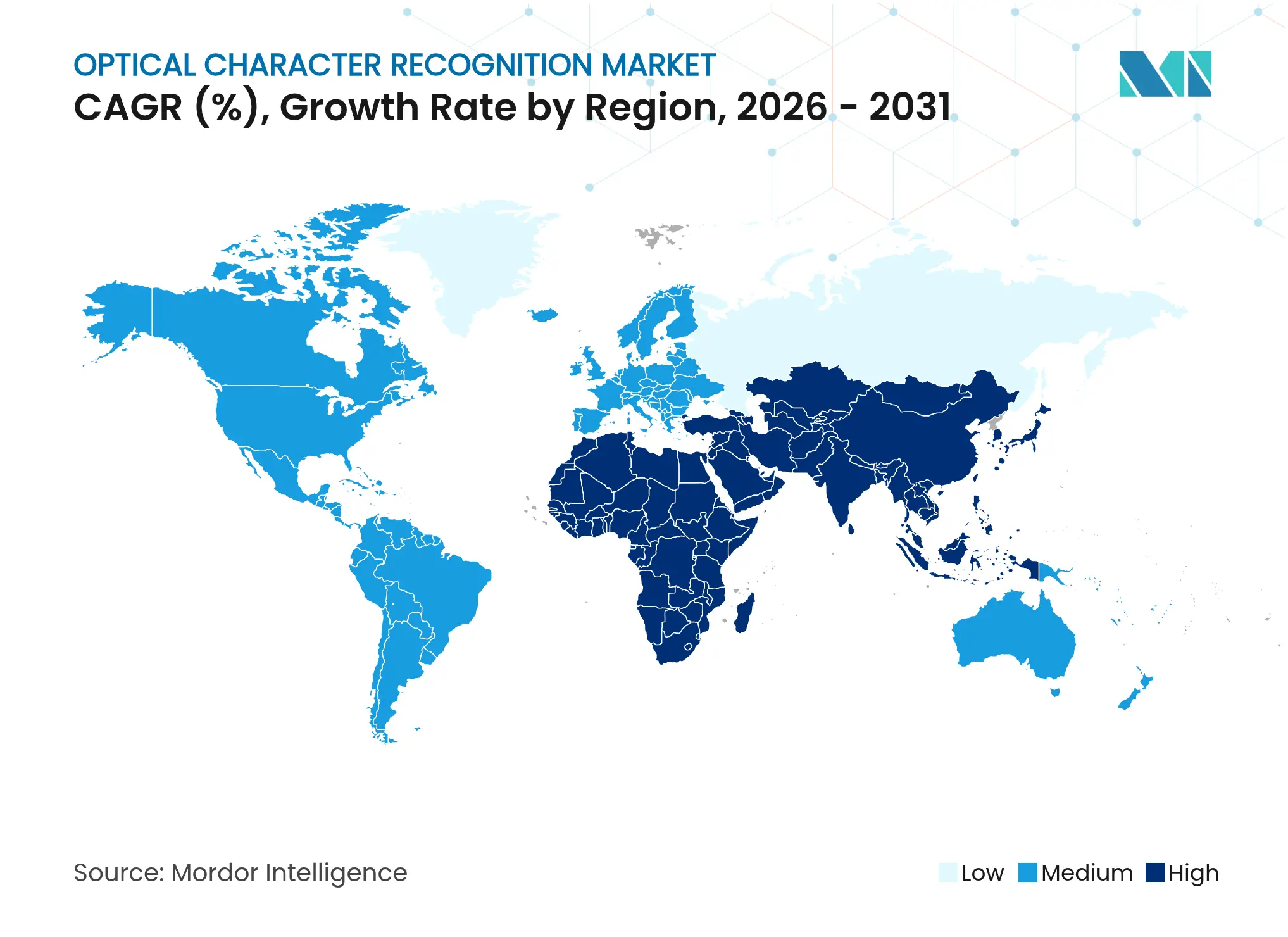
- Par géographie, l'Amérique du Nord a dominé avec 39,50 % des revenus en 2025, mais l'Asie-Pacifique devrait progresser à un TCAC de 17,58 % jusqu'en 2031.
Remarque : Les chiffres de la taille du marché et des prévisions de ce rapport sont générés à l’aide du cadre d’estimation propriétaire de Mordor Intelligence, mis à jour avec les données et analyses les plus récentes disponibles en 2026.
Tendances et perspectives mondiales du marché de la reconnaissance optique de caractères
Analyse de l'impact des moteurs*
| Moteur | (~) % d'impact sur les prévisions de TCAC | Pertinence géographique | Horizon temporel de l'impact |
|---|---|---|---|
| Automatisation croissante dans les industries | +3.5% | Amérique du Nord, Europe | Moyen terme (2-4 ans) |
| Adoption de la technologie cloud | +2.8% | Amérique du Nord (précoce), mondial | Court terme (≤ 2 ans) |
| Intégration avec les plateformes de traitement intelligent de documents | +2.1% | Amérique du Nord, Europe, Asie-Pacifique avancée | Moyen terme (2-4 ans) |
| OCR alimenté par l'IA pour les demandes de remboursement de soins de santé | +1.9% | Amérique du Nord, Europe, Asie-Pacifique avancée | Moyen terme (2-4 ans) |
| Réglementations sur la conformité en matière d'accessibilité | +1.4% | Amérique du Nord, Europe, Asie-Pacifique émergente | Long terme (≥ 4 ans) |
| Adoption des SDK OCR à faible code par les PME | +1.2% | Marchés émergents dans le monde entier | Court terme (≤ 2 ans) |
| Source: Mordor Intelligence | |||
Automatisation croissante dans les industries
Les organisations manufacturières et logistiques intègrent l'OCR piloté par l'IA dans les flux de travail de la chaîne d'approvisionnement pour capturer en temps réel les données des étiquettes d'expédition, des factures et des listes de prélèvement. Des niveaux de précision de 97 % dans des conditions d'éclairage difficiles augmentent le débit et réduisent les points de contact manuels de 50 % [1]Zebra Technologies, "A Deeper Dive on Deep Learning OCR," zebra.com. La reconnaissance automatique des plaques d'immatriculation s'aligne sur les portiques d'entrepôt pour accélérer l'entrée des véhicules, démontrant comment le marché de la reconnaissance optique de caractères s'étend au-delà des documents aux actifs physiques.
Adoption de la technologie cloud
L'OCR cloud à la consommation supprime les exigences de capital initial et fournit des mises à jour instantanées des algorithmes. Azure Form Recognizer illustre cette évolution en proposant une tarification à l'usage qui attire les entreprises dont les volumes de documents sont variables. Les moteurs basés sur navigateur utilisant WebAssembly traitent les pièces d'identité localement pour satisfaire aux règles de confidentialité, permettant aux PME dans des juridictions strictes de bénéficier de la scalabilité du cloud sans envoyer de données hors site.
Intégration avec les plateformes de traitement intelligent de documents
Les fournisseurs regroupent l'OCR, la classification et la validation dans des suites de traitement intelligent de documents de bout en bout. ABBYY FlexiCapture propose des modèles prédéfinis pour les demandes de prêt hypothécaire et les demandes de remboursement de soins de santé, réduisant les délais de traitement de 80 % et les taux d'erreur de 95 % [2]ABBYY, "Recent News & Activity," abbyy.com. Cette orientation plateforme positionne le marché de la reconnaissance optique de caractères comme un élément central des stratégies d'automatisation plus larges.
OCR alimenté par l'IA pour les demandes de remboursement de soins de santé
Les payeurs du secteur de la santé automatisent l'extraction des formulaires d'explication des prestations vers des fichiers ERA structurés, accélérant le remboursement et réduisant les frais administratifs. Les cadres de sécurité conformes à la loi HIPAA garantissent que les informations de santé protégées restent chiffrées tout au long du flux de travail, levant ainsi un obstacle critique à l'adoption.
Analyse de l'impact des freins*
| Frein | (~) % d'impact sur les prévisions de TCAC | Pertinence géographique | Horizon temporel de l'impact |
|---|---|---|---|
| Coûts d'investissement initiaux élevés | -1.2% | Marchés émergents, PME | Court terme (≤ 2 ans) |
| Préoccupations relatives à la confidentialité des données dans l'OCR cloud | -0.8% | Europe, secteurs réglementés dans le monde entier | Moyen terme (2-4 ans) |
| Limites de la reconnaissance de l'écriture manuscrite dans les langues à faibles ressources | -0.7% | Asie-Pacifique, Moyen-Orient et Afrique, Amérique latine | Long terme (≥ 4 ans) |
| Contraintes d'approvisionnement en GPU pour l'OCR par apprentissage profond | -0.5% | Mondial | Court terme (≤ 2 ans) |
| Source: Mordor Intelligence | |||
Coûts d'investissement initiaux élevés
Les déploiements OCR de niveau entreprise impliquent des licences logicielles, une intégration des systèmes et une réingénierie des processus que de nombreuses PME peinent à financer. Si la tarification par abonnement atténue les dépenses d'investissement, la personnalisation des flux de travail et la connexion des systèmes hérités maintiennent le coût total de possession élevé, ralentissant la pénétration dans les segments sensibles aux prix.
Préoccupations relatives à la confidentialité des données dans l'OCR cloud
Les orientations du Comité européen de la protection des données soulignent les risques liés au traitement de données personnelles sensibles avec l'OCR, contraignant de nombreuses entités financières et de santé à conserver des moteurs sur site malgré des frais de maintenance plus élevés. Les fournisseurs répondent en proposant des déploiements conteneurisés et un traitement dans le navigateur pour équilibrer efficacité et conformité.
*Nos prévisions considèrent les impacts des moteurs et des contraintes comme directionnels et non additifs. Les prévisions d'impact reflètent la croissance de référence, les effets de composition et les interactions entre variables.
Analyse des segments
Par composant : la croissance des services dépasse la domination des logiciels
Le segment des logiciels a représenté 77,30 % des revenus en 2025, établissant une base solide pour le marché de la reconnaissance optique de caractères. Les services, en revanche, devraient afficher un TCAC de 17,36 % jusqu'en 2031, les organisations demandant des services de conseil, de personnalisation et d'exploitation gérée pour réaliser un retour sur investissement complet. Cette évolution montre que l'expertise, et non le seul code, déverrouille désormais la valeur des déploiements OCR.
Les prestataires de services professionnels élaborent des guides verticaux qui intègrent la terminologie sectorielle et les modèles réglementaires dans les pipelines OCR. Les intégrateurs du secteur de la santé, par exemple, fournissent des lexiques médicaux pour améliorer la précision de l'extraction, tandis que les spécialistes bancaires se concentrent sur les documents de lutte contre le blanchiment d'argent et de conformité KYC. Les services gérés soulagent les équipes informatiques internes de l'ajustement des modèles de reconnaissance, garantissant que les systèmes restent à jour avec les nouveaux formats de documents.



Par mode de déploiement : le cloud domine tandis que le déploiement sur site gagne en importance stratégique
Les déploiements cloud ont généré 65,20 % des revenus de 2025, reflétant la préférence des clients pour la mise à l'échelle élastique et les améliorations automatiques des algorithmes. Néanmoins, les solutions sur site devraient progresser à un TCAC de 15,45 % car les secteurs réglementés exigent la résidence des données. Les institutions financières conservent souvent le traitement des chèques sur des serveurs locaux tout en transférant les flux de travail moins sensibles vers le cloud.
Les architectures hybrides dominent. Microsoft déploie ses conteneurs OCR dans les centres de données des clients, permettant aux entreprises de traiter les documents localement tout en se connectant à Azure AI pour un post-traitement avancé. Cette configuration positionne le marché de la reconnaissance optique de caractères à la fois comme une offre SaaS et une offre d'appliance, selon les seuils de conformité.
Par technologie : la reconnaissance intelligente de caractères perturbe l'OCR traditionnel
L'OCR conventionnel a conservé 70,40 % des revenus de 2025, mais la reconnaissance intelligente de caractères devrait progresser à un TCAC de 18,95 % car elle déchiffre les scripts cursifs et les formulaires semi-structurés. Les moteurs de reconnaissance intelligente de caractères par apprentissage profond atteignent désormais 85 % de précision sur une écriture manuscrite claire, élargissant la charge de travail adressable au-delà des factures dactylographiées.
Les modules de reconnaissance optique de marques et de reconnaissance intelligente de mots complètent la reconnaissance intelligente de caractères, traitant les cases à cocher et les courtes notes en texte libre. Les modèles d'IA multimodaux, capables de lire des mises en page de documents entiers, estompent davantage la distinction entre OCR et traitement du langage naturel, créant une zone de convergence qui redéfinit le marché de la reconnaissance optique de caractères.
Par application : la vérification d'identité s'impose comme le principal moteur de croissance
Le traitement des factures et des notes a conservé une part de 32,40 % en 2025, ancrant la demande fondamentale, tandis que la vérification d'identité et la conformité KYC devraient progresser à un TCAC de 17,85 %. Les banques et les fintechs intègrent l'OCR à la reconnaissance faciale pour authentifier les documents lors de l'intégration mobile, réduisant les délais d'acquisition des clients de plusieurs jours à quelques minutes.
La gestion documentaire, bien que mature, reste essentielle car les entreprises numérisent leurs archives pour en faciliter la recherche. La reconnaissance des emballages et des étiquettes exploite l'OCR pour la traçabilité sur les lignes de fabrication, tandis que les prestataires de soins de santé combinent l'OCR avec le traitement du langage naturel clinique pour coder les notes non structurées. Ces cas spécialisés élargissent le marché de la reconnaissance optique de caractères au-delà des centres de traitement des comptes fournisseurs.
Par secteur d'utilisation finale : la numérisation de la santé stimule la croissance la plus rapide
Le BFSI a contrôlé 25,60 % des revenus en 2025 grâce aux dossiers de prêts, aux relevés et aux documents de conformité. Le secteur de la santé est en passe d'afficher un TCAC de 19,45 %, porté par les mandats de dossiers de santé électroniques et la nécessité d'automatiser les demandes de remboursement. Les moteurs OCR formés sur des vocabulaires cliniques extraient directement les codes de diagnostic des dossiers numérisés, améliorant la précision de la facturation.
Les entreprises de commerce de détail et d'e-commerce utilisent l'OCR pour la capture des étiquettes de produits et les vérifications d'identité des clients aux points de retrait. Les agences gouvernementales numérisent les registres fonciers et les passeports pour moderniser les services aux citoyens. Les usines de fabrication intègrent l'OCR dans les postes de contrôle qualité, garantissant que les étiquettes réglementaires correspondent aux données de lot.
Analyse géographique
L'Amérique du Nord a représenté 39,50 % des revenus du marché de la reconnaissance optique de caractères en 2025, soutenue par des coûts de main-d'œuvre élevés qui justifient l'automatisation et par une concentration dense de fournisseurs de technologies. Les réglementations HIPAA et KYC accélèrent l'adoption dans les secteurs de la santé et de la banque. Les fournisseurs de la région intègrent l'OCR avec des robots d'automatisation des processus robotiques, générant des gains d'efficacité composés.
L'Asie-Pacifique est le territoire à la croissance la plus rapide avec un TCAC de 17,58 %. Les fournisseurs cloud chinois, tels qu'Alibaba Cloud et Tencent Cloud, regroupent les services de reconnaissance avec des suites d'IA plus larges, abaissant les barrières à l'entrée pour les entreprises locales. Les programmes de numérisation de l'Inde et son secteur bancaire à fort volume créent un terrain fertile pour l'OCR KYC, tandis que le Japon et la Corée du Sud se concentrent sur le contrôle qualité dans la fabrication.
L'Europe affiche une forte adoption dans les secteurs public et privé, mais reste prudente sur la souveraineté des données. L'Allemagne et la France privilégient les installations sur site ou sur cloud souverain pour respecter le RGPD. Les objectifs de résilience de la chaîne d'approvisionnement poussent les entreprises logistiques vers la capture automatisée de documents pour une visibilité de bout en bout, soutenant une croissance régulière dans la région.

Paysage concurrentiel
Le marché de la reconnaissance optique de caractères réunit un mélange de géants des logiciels diversifiés et de nouveaux entrants spécialisés dans l'IA. Adobe, Google et Microsoft intègrent l'OCR dans des suites de productivité plus larges, offrant une large portée. ABBYY, Kofax et UiPath se différencient par des modèles verticaux et l'orchestration des flux de travail. Des startups telles que Mistral AI utilisent de grands modèles de langage pour atteindre 99 % de précision à 1 USD pour 1 000 pages, élevant la barre concurrentielle [3]Campus Technology, "Mistral AI Introduces AI-Powered OCR," campustechnology.com.
Les mouvements stratégiques comprennent des lancements d'API pour les écosystèmes de développeurs, des acquisitions qui ajoutent une expertise réglementaire et des déploiements conteneurisés pour le traitement en périphérie. L'acquisition d'OCR Services par Descartes Systems Group élargit la couverture de la conformité commerciale, tandis que la nouvelle API d'ABBYY cible l'intégration à faible code. Des espaces blancs subsistent dans la prise en charge des langues à faibles ressources et l'authenticité des documents vérifiée par blockchain.
À mesure que les fournisseurs convergent vers des techniques similaires d'apprentissage profond, la différenciation se déplace vers les connaissances de domaine prédéfinies, les fonctionnalités de gouvernance et le coût total de possession. Les partenariats avec les clouds hyperscale et les plateformes d'automatisation des processus robotiques étendent la portée du marché, maintenant une concurrence active tout en empêchant une domination monopolistique.
Leaders du secteur de la reconnaissance optique de caractères
ABBYY Software Ltd.
Google LLC
IBM Corporation
Microsoft Corporation
Adobe Inc.
- *Avis de non-responsabilité : les principaux acteurs sont triés sans ordre particulier

Développements récents dans le secteur
- Avril 2025 : ABBYY a lancé une API OCR qui améliore la précision dans les flux de travail d'automatisation intelligente, renforçant sa position de leader selon l'Everest Group.
- Avril 2025 : OCR Studio a publié un moteur basé sur WebAssembly pour la vérification d'identité dans le navigateur couvrant 220 juridictions.
- Mars 2025 : Mistral AI a introduit une API OCR traitant 2 000 pages par minute avec une précision de 97 à 99,54 % dans 11 langues.
- Mars 2024 : Descartes Systems Group a acquis OCR Services pour 90 millions USD, élargissant sa suite mondiale de conformité commerciale.


Cadre de la méthodologie de recherche et portée du rapport
Définitions du marché et couverture principale
Notre étude définit le marché de la reconnaissance optique de caractères (OCR) comme l'ensemble des logiciels sous licence, des moteurs intégrés et des services groupés qui transforment le texte numérisé ou photographié en données encodées par machine dans des environnements de bureau, mobiles et cloud. Le modèle comptabilise les revenus générés par les licences initiales, les frais d'abonnement et la mise en œuvre reconnue ou le support géré directement lié à la fonctionnalité OCR.
Exclusion du périmètre : les services de transcription manuscrite pure et les lecteurs de codes-barres à usage unique sont exclus de cette évaluation.
Aperçu de la segmentation
- Par composant
- Logiciels
- Logiciels OCR mobiles
- Logiciels OCR de bureau
- Logiciels OCR cloud
- Services
- Services professionnels
- Services gérés
- Logiciels
- Par mode de déploiement
- Sur site
- Cloud
- Par technologie
- OCR conventionnel
- Reconnaissance intelligente de caractères (RIC)
- Reconnaissance optique de marques (ROM)
- Reconnaissance intelligente de mots (RIM)
- Autres
- Par application
- Traitement des factures et des notes
- Vérification d'identité et conformité KYC
- Gestion et archivage de documents
- Traitement des chèques bancaires
- Reconnaissance des emballages et des étiquettes
- Autres
- Par secteur d'utilisation finale
- BFSI
- Commerce de détail et e-commerce
- Gouvernement
- Santé
- Éducation
- Transport et logistique
- Fabrication
- Autres
- Par géographie
- Amérique du Nord
- États-Unis
- Canada
- Mexique
- Amérique du Sud
- Brésil
- Argentine
- Reste de l'Amérique du Sud
- Europe
- Allemagne
- Royaume-Uni
- France
- Italie
- Espagne
- Russie
- Reste de l'Europe
- Asie-Pacifique
- Chine
- Japon
- Inde
- Corée du Sud
- Australie et Nouvelle-Zélande
- Reste de l'Asie-Pacifique
- Moyen-Orient et Afrique
- Moyen-Orient
- Arabie saoudite
- Émirats arabes unis
- Turquie
- Reste du Moyen-Orient
- Afrique
- Afrique du Sud
- Nigéria
- Égypte
- Reste de l'Afrique
- Moyen-Orient
- Amérique du Nord
Méthodologie de recherche détaillée et validation des données
Recherche primaire
Les analystes de Mordor ont interrogé des développeurs de moteurs OCR, des intégrateurs de systèmes, des responsables des opérations bancaires et des administrateurs de dossiers de santé en Amérique du Nord, en Europe et en Asie-Pacifique. Les discussions ont validé les prix de vente moyens, les préférences de déploiement et les obstacles à l'adoption régionale, nous permettant d'affiner des hypothèses que les données publiques seules ne peuvent pas révéler.
Recherche documentaire
Nous avons commencé par collecter des indicateurs fondamentaux à partir de sources ouvertes telles que le Bureau du recensement des États-Unis, les codes commerciaux d'Eurostat pour les logiciels de traitement d'images, les registres d'exportation du MeitY indien et les dépôts auprès de la SEC et des autorités de surveillance financière. L'analyse des brevets via Questel, les données d'expédition via Volza et la couverture médiatique indexée sur Dow Jones Factiva nous ont aidés à retracer la diffusion technologique et les évolutions des prix. Un contexte supplémentaire est venu des associations sectorielles, de l'AIIM pour la gestion documentaire, de la NACHA pour les volumes de traitement des chèques et de l'HIMSS pour la numérisation de la santé. Ces références ancrent les signaux de demande de base, tandis que les rapports annuels et les présentations aux investisseurs des entreprises clarifient les voies de monétisation. Les sources citées sont illustratives ; de nombreuses autres ont alimenté notre collecte de preuves.
Dimensionnement du marché et prévisions
Une construction descendante part des dépenses mondiales en logiciels d'entreprise, qui sont ensuite filtrées par les parts des secteurs à forte intensité documentaire et les taux de pénétration de l'OCR. Des vérifications ascendantes sélectives, des agrégations de fournisseurs et des échantillons de prix de vente moyen × volume pour les géographies clés tempèrent les totaux. Les variables critiques comprennent les volumes de traitement des chèques, les mandats de dossiers médicaux électroniques, le nombre d'utilisateurs de la banque mobile, les tendances de résolution de numérisation moyenne et les taux de migration vers le cloud ; chacune a été projetée à l'aide de modèles ARIMA et vérifiée par régression multivariée lorsque les séries de données le permettent. Les lacunes dans les estimations ascendantes, notamment pour les marchés émergents, ont été comblées en appliquant des courbes d'adoption validées à partir de régions comparables.
Validation des données et cycle de mise à jour
Les résultats passent par des analyses de variance par rapport à des références externes, une révision par un analyste senior et une réunion de réconciliation avant validation. Nous actualisons tous les douze mois, tandis que les événements extraordinaires — changement réglementaire majeur ou acquisition importante — déclenchent des mises à jour intermédiaires, garantissant aux clients les perspectives les plus récentes.
Pourquoi la base de référence de Mordor sur la reconnaissance optique de caractères est-elle fiable
Les chiffres publiés diffèrent souvent parce que les entreprises appliquent des périmètres de service, des points de capture des prix et des rythmes d'actualisation uniques.
En ancrant les estimations dans des indicateurs d'adoption vérifiables et des entretiens intercontinentaux, notre base de référence reste équilibrée et transparente.
Les principaux facteurs d'écart comprennent une couverture des composants plus étroite, des extrapolations historiques non testées ou un rythme d'actualisation plus lent chez d'autres éditeurs.
Comparaison de référence
| Taille du marché | Source anonymisée | Principal facteur d'écart |
|---|---|---|
| 17,06 milliards USD (2025) | ||
| 12,56 milliards USD (2023) | Cabinet de conseil régional A | Exclut les revenus des services et les applications OCR mobiles |
| 12,25 milliards USD (2024) | Revue professionnelle B | S'appuie sur une croissance linéaire à partir de 2020 sans validation terrain |
| 12,21 milliards USD (2024) | Cabinet de conseil mondial C | Ne comptabilise que les déploiements sur site ; l'adoption du cloud est ignorée |
La comparaison montre que lorsque nous appliquons des choix de périmètre cohérents, des signaux multi-sources et un recalibrage annuel, Mordor fournit un point de référence fiable que les décideurs peuvent relier à des variables claires et à des étapes reproductibles.


Questions clés auxquelles le rapport répond
Quelle est la taille actuelle du marché de la reconnaissance optique de caractères ?
Le marché s'élève à 20,02 milliards USD en 2026 et devrait atteindre 44,52 milliards USD d'ici 2031.
Quel segment connaît la croissance la plus rapide au sein du marché de la reconnaissance optique de caractères ?
Les services progressent à un TCAC de 17,36 % car les entreprises recherchent une expertise en mise en œuvre et des opérations gérées.
Pourquoi la vérification d'identité est-elle une application à forte croissance pour l'OCR ?
Les mandats réglementaires KYC et l'intégration numérique stimulent l'adoption, propulsant le segment à un TCAC de 17,85 %.
Comment les déploiements cloud façonnent-ils le secteur de la reconnaissance optique de caractères ?
Le cloud détient 65,20 % de part et permet une tarification à la consommation, des mises à jour rapides et une scalabilité pour des volumes variables.
Quelle région est en tête en termes de revenus globaux ?
L'Amérique du Nord est en tête avec 39,50 % de part de marché grâce à une infrastructure avancée et une forte adoption dans les secteurs de la finance et de la santé.
Quelles stratégies concurrentielles se distinguent parmi les fournisseurs d'OCR ?
Les fournisseurs se concentrent sur des modèles spécifiques à un domaine, des API à faible code et des modèles de déploiement hybrides pour se différencier au-delà de la seule précision brute.
Dernière mise à jour de la page le:




