Taille et Part du Marché de l'IA dans la Conception de Molécules
VUE D’ENSEMBLE DU MARCHÉ
| Période d'étude | 2020 - 2031 |
|---|---|
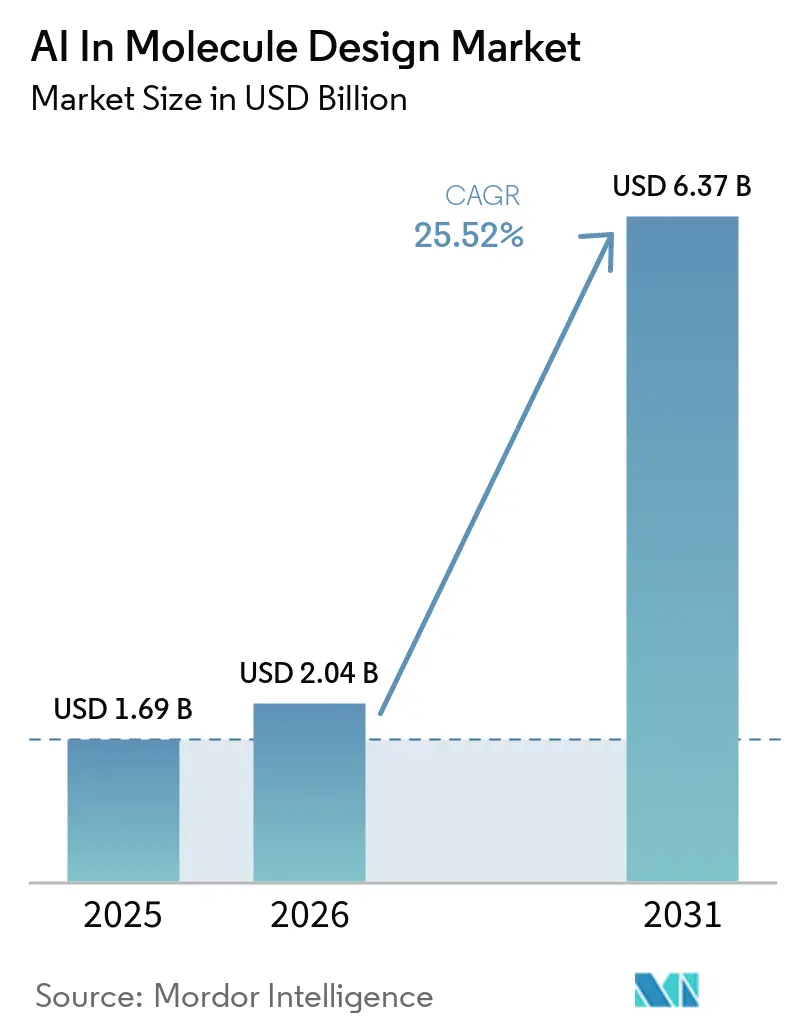
| Taille du Marché (2026) | 2.04 Milliards de dollars |
| Taille du Marché (2031) | 6.37 Milliards de dollars |
| Taux de croissance (2026 - 2031) | 25.52% CAGR |
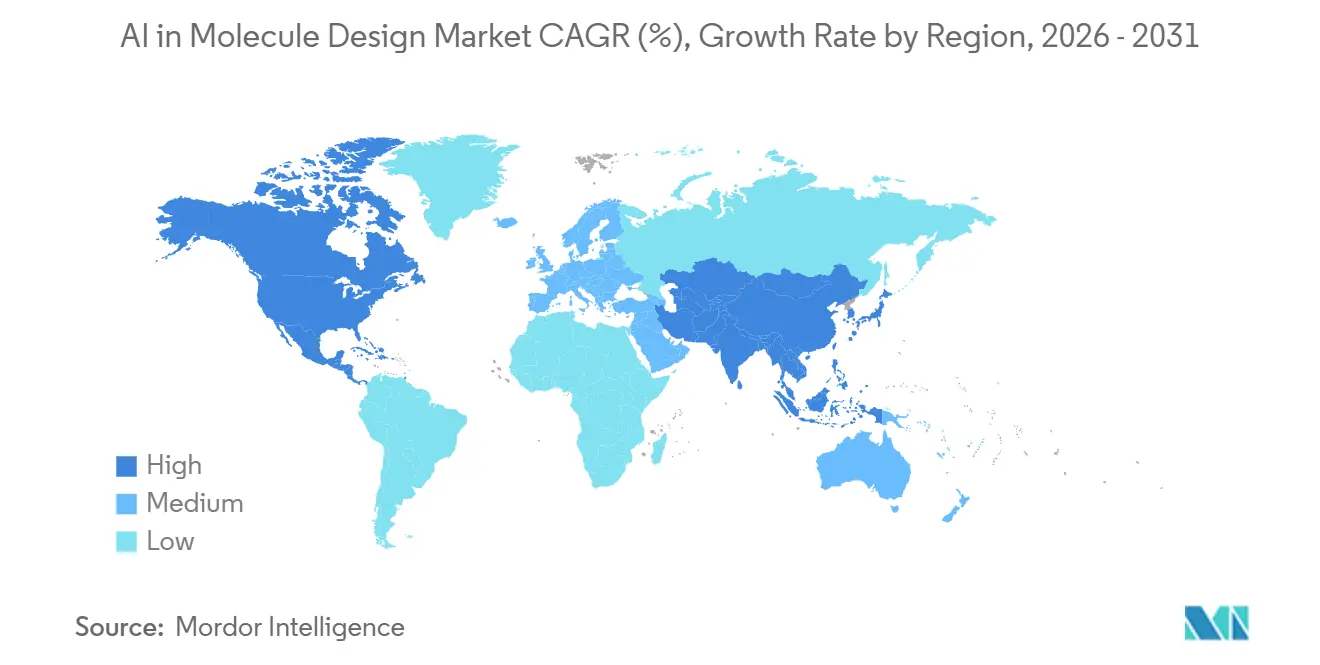
| Marché à la Croissance la Plus Rapide | Asie-Pacifique |
| Plus Grand Marché | Amérique du Nord |
| Concentration du Marché | Moyen |
Acteurs majeurs *Avis de non-responsabilité : les principaux acteurs sont triés sans ordre particulier Image © Mordor Intelligence. La réutilisation nécessite une attribution sous CC BY 4.0. | |
Analyse du Marché de l'IA dans la Conception de Molécules par Mordor Intelligence
La taille du marché de l'IA dans la conception de molécules était de 1,69 milliard USD en 2025 et devrait atteindre 6,37 milliards USD d'ici 2031 à un TCAC de 25,52 %, reflétant une transition pluriannuelle des projets pilotes vers des flux de travail de découverte intégrés dans les pipelines pharmaceutiques. Les engagements en capital et l'adoption des plateformes s'accélèrent à mesure que les modèles de fondation tels qu'AlphaFold 3 et les microservices à l'échelle du cloud rendent la prédiction de structure et la chimie générative accessibles aux équipes de R&D de grande et moyenne taille, réduisant les barrières à l'expérimentation et à l'itération dans la boucle conception-fabrication-test-analyse. Les premiers adoptants compriment les cycles de criblage et d'optimisation grâce à une intégration de laboratoire autonome et semi-autonome qui relie l'inférence de modèles à la synthèse robotique et à l'analyse à haut débit, ce qui augmente le débit et améliore la fidélité des données pour les cycles successifs. Les avancées en biologie structurale élargissent le champ d'application de l'IA, les ressources à l'échelle d'AlphaFold permettant une conception guidée par la structure à travers les protéines, les acides nucléiques et les complexes protéine-ligand, tandis que les évaluations comparatives continuent de clarifier où les flux de travail hybrides physique-IA sont nécessaires pour la précision dans les systèmes flexibles ou les complexes ternaires. L'accent concurrentiel se déplace vers les actifs de données et l'exécution en boucle avec le laboratoire, à mesure que les entreprises formalisent des pipelines de validation en laboratoire humide et des ensembles de données propriétaires qui renforcent la différenciation des plateformes et augmentent le rendement de la conception de novo à travers les petites molécules, les protéines et les modalités ARN.
Points Clés du Rapport
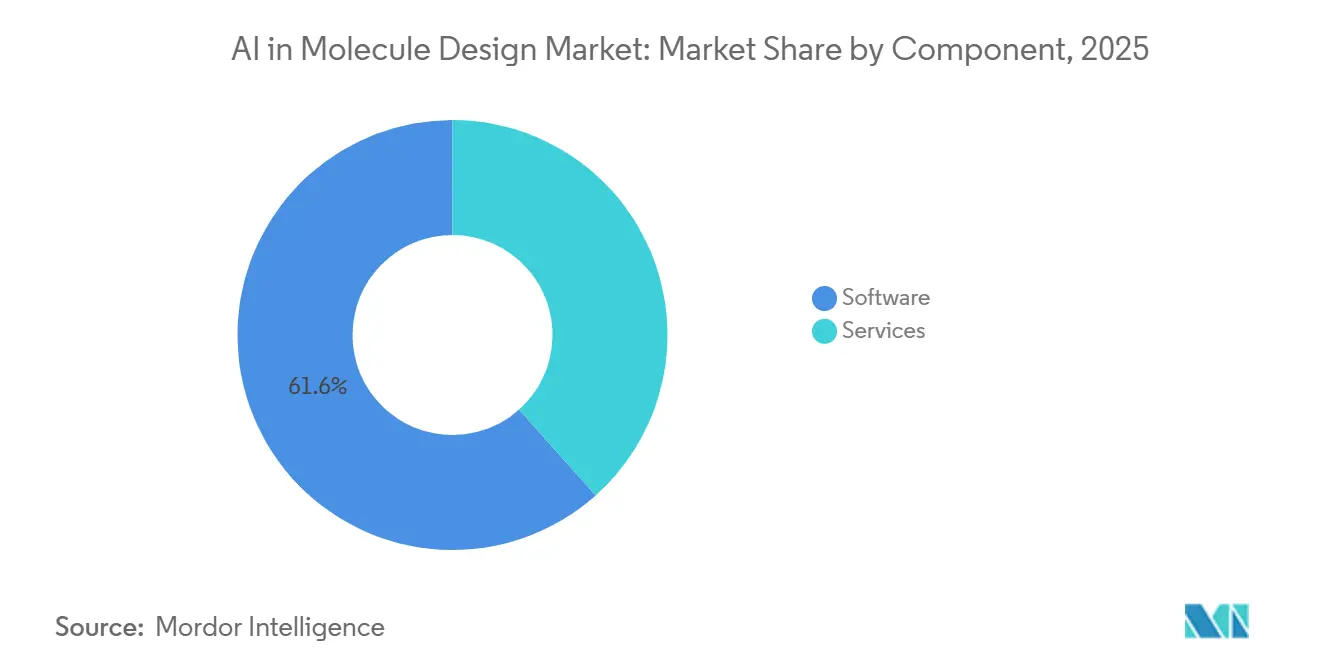
- Par composant, les logiciels ont dominé avec une part de 61,56 % en 2025, tandis que les services ont enregistré la croissance projetée la plus rapide à un TCAC de 26,14 % jusqu'en 2031.
- Par application, la conception de médicaments à petites molécules représentait une part de 55,32 % en 2025 et la conception de produits biologiques ou de protéines devrait se développer à un TCAC de 27,10 % jusqu'en 2031.
- Par type de molécule, les petites molécules représentaient 54,34 % en 2025 et les protéines ou produits biologiques ont affiché la croissance projetée la plus élevée à un TCAC de 27,32 %.
- Par technologie, les modèles génératifs ont capturé 48,27 % du déploiement en 2025, tandis que l'apprentissage profond basé sur la structure devrait croître à un TCAC de 27,06 %.
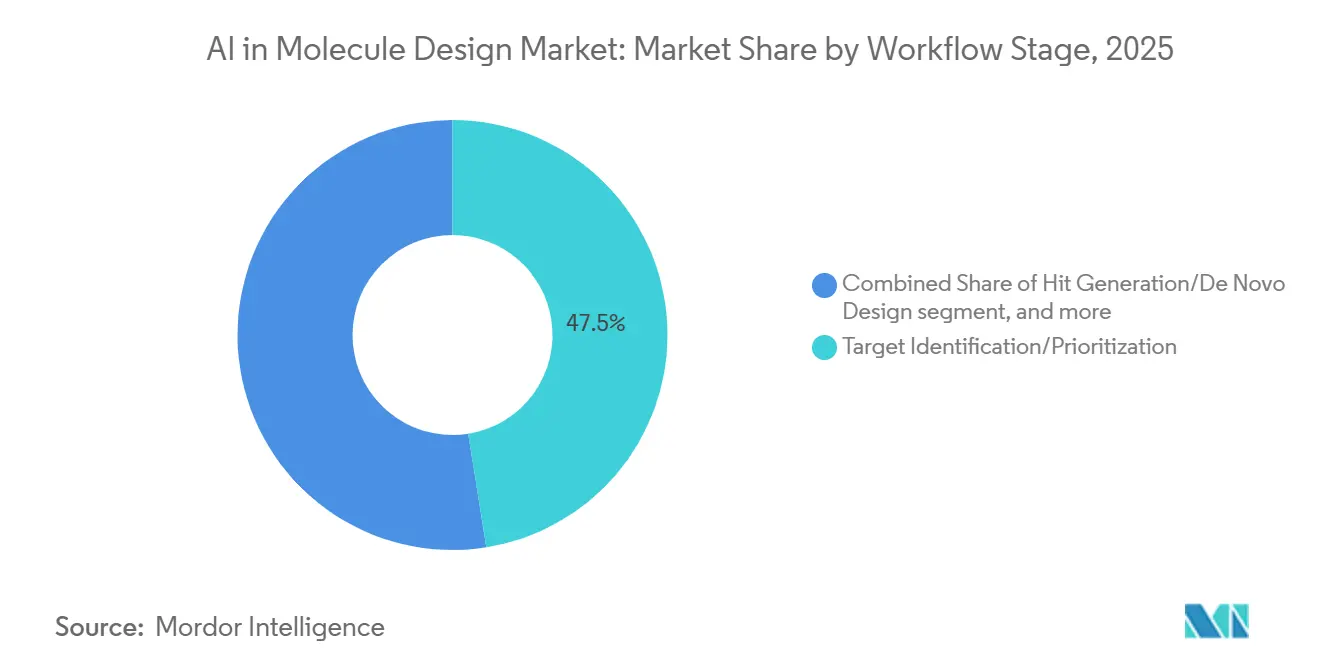
- Par étape de flux de travail, l'identification des cibles représentait 47,48 % des déploiements en 2025 et la génération de hits ou la conception de novo progresse à un TCAC de 26,76 %.
- Par utilisateur final, les entreprises pharmaceutiques et biotechnologiques représentaient 65,42 % en 2025, tandis que les ORC et les CDMO devraient croître à un TCAC de 27,24 %.
- Par géographie, l'Amérique du Nord détenait 44,54 % en 2025 et l'Asie-Pacifique devrait se développer à un TCAC de 26,57 % jusqu'en 2031.
Note : La taille du marché et les prévisions figurant dans ce rapport sont générées à l'aide du cadre d'estimation exclusif de Mordor Intelligence, mis à jour avec les dernières données et informations disponibles en janvier 2026.
Tendances et Perspectives du Marché Mondial de l'IA dans la Conception de Molécules
Analyse de l'Impact des Moteurs*
| Moteur | (~) % Impact sur les Prévisions de TCAC | Pertinence Géographique | Calendrier d'Impact |
|---|---|---|---|
| Pression sur la Productivité de la R&D Pharmaceutique et Impératif de Réduction des Coûts et des Délais | +6.8% | Mondial, concentré dans les pôles pharmaceutiques américains et européens | Court terme (≤ 2 ans) |
| Modèles de Fondation et Calcul à l'Échelle du Cloud Permettant la Conception Générative à Grande Échelle | +5.4% | Mondial avec des avantages d'infrastructure aux États-Unis et en Asie-Pacifique | Moyen terme (2-4 ans) |
| Données Structurelles de l'Ère AlphaFold Débloquant la Conception Guidée par la Structure et la Cofolding | +4.2% | Mondial, tirant parti des ressources AlphaFold dans le monde entier | Moyen terme (2-4 ans) |
| Flux de Capitaux et Partenariats avec les Grandes Entreprises Pharmaceutiques Validant les Pipelines de Conception par IA | +3.9% | Amérique du Nord et UE principalement ; répercussions en Asie-Pacifique via des partenariats régionaux | Court terme (≤ 2 ans) |
| Cycles DMTA Intégrés en Boucle Fermée avec Automatisation de Laboratoire Réduisant le Temps d'Itération | +3.1% | Amérique du Nord et Asie-Pacifique en tête ; gains précoces dans les pôles européens | Long terme (≥ 4 ans) |
| Engagement Réglementaire Réduisant les Risques de l'Utilisation de l'IA dans la Découverte et le Développement | +2.1% | Leadership américain et européen, suivi par l'Asie-Pacifique | Court terme (≤ 2 ans) |
| Source: Mordor Intelligence | |||
Pression sur la Productivité de la R&D Pharmaceutique et Impératif de Réduction des Coûts et des Délais
Les délais de développement des médicaments et les taux de réussite restent sous pression, renforçant la nécessité de comprimer les cycles de découverte et d'améliorer la qualité des candidats avant que l'investissement clinique ne s'intensifie. Des taux de réussite clinique inférieurs à 8 % continuent de contraindre le retour sur investissement, de sorte que les fonctions de découverte recherchent des outils qui renforcent la confiance dans les cibles et optimisent les leads selon plusieurs paramètres plus tôt dans l'entonnoir. Les pipelines de conception pilotés par l'IA soutiennent des tests d'hypothèses plus rapides à travers la puissance, la sélectivité et les propriétés ADMET, ce qui réduit l'attrition et diminue la synthèse redondante d'analogues à faible valeur lorsqu'ils sont associés à des données de rétroaction de haute fidélité. La disponibilité généralisée de modèles de fondation évolutifs et de flux de travail de raffinement physique réduit les coûts unitaires pour le criblage et la priorisation in silico, conduisant à un débit plus élevé et à une meilleure allocation des ressources de laboratoire humide. À mesure que davantage de données structurelles et de séquences précompétitives entrent dans les référentiels publics, et que les laboratoires en boucle fermée collectent des mesures propriétaires de meilleure qualité, les performances des modèles s'améliorent grâce à un affinage continu qui reflète les conditions réelles des tests.
Modèles de Fondation et Calcul à l'Échelle du Cloud Permettant la Conception Générative à Grande Échelle
AlphaFold 3 et les outils associés étendent la capacité prédictive à travers les protéines, l'ADN, l'ARN et les ligands, ce qui permet l'exploration computationnelle des modes de liaison et des conformations qui dépendaient historiquement de méthodes de biologie structurale plus lentes.[1]Chaim Gartenberg, "Comment nous avons construit AlphaFold 3 pour prédire la structure et l'interaction de toutes les molécules du vivant," The Keyword, blog.google Les microservices fournis dans le cloud tels que NVIDIA BioNeMo intègrent l'amarrage par diffusion, le repliement des protéines et la génération moléculaire dans des API standardisées, ce qui encourage des modèles de déploiement cohérents et évolutifs à travers les portefeuilles de découverte. Les entreprises signalent des accélérations significatives et une couverture plus large des cibles à mesure que les suites de modèles pré-entraînés arrivent à maturité, et l'optimisation continue du matériel maintient les améliorations de débit sans grandes dépenses en capital sur site. Les travaux génératifs à grande échelle d'IBM illustrent les gains obtenus en s'entraînant sur des corpus SMILES à l'échelle du milliard, avec une nouveauté et une diversité améliorées qui élargissent les régions chimiques explorées pour le criblage virtuel. Les modèles de fondation qui apprennent les règles chimiques et structurelles latentes génèrent des candidats qui s'étendent au-delà des échafaudages sur-échantillonnés, ce qui aide les équipes de découverte à localiser des leads de première classe viables lorsqu'ils sont combinés avec des filtres de propriétés et une notation tenant compte de la synthèse. Les écosystèmes de fournisseurs se consolident autour de services interopérables qui intègrent la prédiction de protéines, l'amarrage, la génération et l'ADMET pour permettre des flux de travail de bout en bout avec des contrats de données communs et une gestion des versions.
Données Structurelles de l'Ère AlphaFold Débloquant la Conception Guidée par la Structure et la Cofolding
L'échelle et la qualité des structures prédites ont fait passer la conception basée sur la structure de niche à courant dominant, car les chercheurs peuvent explorer les interactions à travers les cibles sans attendre la détermination expérimentale de la structure. AlphaFold 3 a ajouté la capacité pour les complexes protéine-ligand, ce qui soutient le criblage virtuel et la conception rationnelle des interactions du site de liaison tout en guidant la priorisation avec des conformations prédites. Les évaluations comparatives indiquent de bonnes performances pour les interactions statiques et soulignent la nécessité de flux de travail hybrides lorsque la liaison induit des changements conformationnels plus importants ou lors de la modélisation de complexes ternaires, ce qui oriente les équipes vers le raffinement basé sur la physique pour le classement de l'affinité et la stabilité. Les développeurs de modèles itèrent rapidement avec des données synthétiques provenant de moteurs physiques pour améliorer la prédiction des complexes, ce qui réduit les erreurs dans les régions flexibles et les cibles associées aux membranes à mesure que davantage d'exemples d'entraînement capturent des scénarios biophysiques divers. L'utilisation continue de serveurs centralisés pour la génération de structures a supprimé les goulots d'étranglement pour la découverte précoce, de sorte que plusieurs hypothèses de cibles peuvent être avancées en parallèle avec des entrées structurelles cohérentes. À mesure que les organisations se standardisent sur les stratégies de cofolding, d'ajustement induit et de modélisation d'ensemble, les données structurelles informent désormais à la fois les étapes de génération de hits et d'optimisation des leads à travers les petites molécules et les produits biologiques.
Cycles DMTA Intégrés en Boucle Fermée avec Automatisation de Laboratoire Réduisant le Temps d'Itération
Connecter les moteurs de conception à la synthèse robotique et aux lectures rapides des tests transforme le cycle conception-fabrication-test-analyse en une boucle continue, ce qui réduit de semaines ou de mois chaque itération et élargit le nombre d'hypothèses évaluables par unité de temps. Les systèmes autonomes et semi-autonomes ont démontré une optimisation plus rapide à travers les métriques de puissance et d'efficacité dans des projets en cours, avec une synthèse à haut débit et des analyses fournissant des ensembles de données qui renforcent le réentraînement des modèles. En ingénierie des protéines, l'expérimentation autonome a apporté des gains mesurables en coût et en vitesse, illustrant comment les pipelines en boucle avec le laboratoire se développent lorsque l'inférence de modèles dirige l'expérimentation plutôt que de s'appuyer sur le traitement par lots manuel.[3]NVIDIA Corporation, "Élargir la découverte de médicaments assistée par ordinateur avec de nouveaux modèles d'IA," Blog NVIDIA, blogs.nvidia.com Les jumeaux numériques et les objets de données standardisés réduisent davantage la curation manuelle et permettent des tests d'hypothèses en quasi temps réel à travers les paramètres de synthèse et de processus. Les fournisseurs de matériel s'attaquent aux limites de débit avec des cellules de travail modulaires et évolutives qui s'intègrent à la simulation pour la maintenance prédictive et la planification, ce qui augmente le temps de fonctionnement pour les cycles continus. L'impact combiné est une boucle plus productive et riche en données qui alimente les performances des modèles et améliore le profil d'efficacité global du marché de l'IA dans la conception de molécules.
Analyse de l'Impact des Contraintes*
| Contrainte | (~) % Impact sur les Prévisions de TCAC | Pertinence Géographique | Calendrier d'Impact |
|---|---|---|---|
| Qualité des Données, Biais et Manque de Normes Limitant la Généralisation des Modèles | -2.8% | Mondial, aigu dans les régions à infrastructure de données fragmentée | Moyen terme (2-4 ans) |
| Coûts de Mise en Œuvre Élevés et Contraintes de Talents pour la Mise à l'Échelle des Programmes | -2.3% | L'Asie-Pacifique et les marchés européens émergents font face à des déficits de talents plus importants ; les États-Unis disposent de viviers de talents en IA plus solides | Long terme (≥ 4 ans) |
| Écart de Synthétisabilité entre les Propositions de l'IA et les Routes Exécutables | -1.7% | Mondial, la gravité est inversement corrélée à l'infrastructure de chimie médicinale | Moyen terme (2-4 ans) |
| Goulots d'Étranglement liés à l'Approvisionnement en Calcul ou GPU et à l'Énergie Contraignant l'Entraînement | -1.4% | National, où l'accès hyperscale ou l'approvisionnement local en GPU est limité | Court terme (≤ 2 ans) |
| Source: Mordor Intelligence | |||
Qualité des Données, Biais et Manque de Normes Limitant la Généralisation des Modèles
Les données d'entraînement restent rares par rapport au vaste espace chimique, et les erreurs ou les protocoles incohérents dans les ensembles de données publics introduisent du bruit qui peut biaiser l'apprentissage des modèles et nuire à la validité externe. Les examens comparatifs montrent des taux d'erreur d'étiquetage non négligeables à travers les ensembles de données de propriétés moléculaires, ce qui peut induire des corrélations spurieuses et réduire la précision dans les contextes de prédiction prospective. Les conditions de test hétérogènes compliquent davantage l'apprentissage car les modèles entraînés sur des sources agrégées peuvent confondre des mesures à travers des contextes acellulaires, cellulaires ou in vivo sans métadonnées adéquates pour normaliser les différences. Le déséquilibre démographique dans les preuves cliniques soulève des risques de généralisabilité pour les prédictions de sécurité et d'exposition, car les antécédents génétiques sous-représentés peuvent connaître des effets indésirables mal capturés par des modèles entraînés sur des populations plus étroites. Les falaises d'activité et les résultats de bioessais sensibles au contexte ajoutent de la complexité, et l'absence de règles de rapport standardisées pour les protocoles et l'incertitude rend plus difficile la comparaison ou la réutilisation des ensembles de données entre les programmes. Les organisations comblent ces lacunes en générant des données expérimentales propriétaires à grande échelle et en enrichissant les métadonnées pour améliorer la fiabilité des modèles, ce qui soutient un meilleur transfert de domaine au sein du marché de l'IA dans la conception de molécules.
Écart de Synthétisabilité entre les Propositions de l'IA et les Routes Exécutables
Les modèles génératifs peuvent produire des molécules à score élevé qui sont difficiles à fabriquer, car de nombreux ensembles d'entraînement manquent d'annotations de synthèse explicites et de contraintes rétrosynthétiques lors de la génération. Des études qui combinent des filtres de qualité de chimie médicinale automatisés avec l'amarrage et la rétrosynthèse montrent que seule une petite fraction des candidats générés passent toutes les étapes, soulignant la nécessité d'injecter des objectifs tenant compte de la synthèse plus tôt dans la conception. L'incorporation de planificateurs de rétrosynthèse dans des boucles d'optimisation serrées améliore la tractabilité mais ajoute une surcharge computationnelle qui érode les avantages de vitesse de la génération de novo à grande échelle. De nouveaux cadres qui apprennent à partir de chemins rétrosynthétiques ou d'assemblage de fragments émergent pour équilibrer la nouveauté avec la faisabilité des routes, bien que la validation extensive en laboratoire humide reste limitée par rapport aux métriques in silico. L'ingénierie des récompenses et les politiques de fragments guidées par la synthèse peuvent réduire l'écart en pénalisant les motifs inaccessibles, tout en maintenant la diversité de conception pour l'exploration des relations structure-activité. À mesure que les services de rétrosynthèse et les bibliothèques tenant compte des réactifs s'intègrent aux piles de génération, les cycles de conception améliorent le rendement des propositions in silico aux candidats testés en laboratoire dans le marché de l'IA dans la conception de molécules.
*Nos prévisions considèrent les impacts des moteurs et des contraintes comme directionnels et non additifs. Les prévisions d'impact reflètent la croissance de référence, les effets de composition et les interactions entre variables.
Analyse des Segments
Par Composant : Les Logiciels Dominent, les Services s'Accélèrent à Mesure que l'Intégration s'Approfondit
Les logiciels détenaient 61,56 % du marché de l'IA dans la conception de molécules en 2025, soutenus par un accès basé sur le cloud aux modèles de repliement, d'amarrage et génératifs qui permettent aux équipes de se développer sans investissements majeurs sur site. Les microservices de plateforme tels que BioNeMo exposent des modèles pour l'amarrage, la prédiction de structure et la génération de molécules via des API standard, ce qui concentre la valeur dans les flux de travail logiciels pouvant être orchestrés à travers plusieurs programmes de découverte. Les principales chaînes d'outils de raffinement basé sur la physique continuent de mettre à jour les fonctionnalités pour l'échelle, y compris des améliorations dans les calculs d'énergie libre et la gestion des tests catégoriels qui s'alignent sur les flux de travail des équipes de découverte. Le résultat est une pénétration plus large des logiciels dans le marché de l'IA dans la conception de molécules pour les étapes de routine telles que l'expansion des hits et le filtrage ADMET précoce, qui sont désormais accessibles aux utilisateurs transversaux via des interfaces unifiées.
Les services sont le composant à la croissance la plus rapide avec un TCAC projeté de 26,14 %, portés par l'exécution DMTA de bout en bout qui relie la conception de séquences ou de molécules à la synthèse et à la caractérisation internes. Les fournisseurs axés sur l'ARN illustrent ce changement avec des offres intégrées couvrant la conception assistée par l'IA, la fabrication évolutive et le séquençage profond qui valident l'expression et la fonction dans un seul cycle. Les modèles axés sur les services compriment les délais et réduisent les frictions de coordination entre les fournisseurs, tandis que la capture de données structurées soutient le réentraînement continu des modèles pour la prochaine itération. À mesure que les organisations de découverte développent leurs programmes et standardisent leurs procédures opérationnelles, la couche de services devient un partenaire d'exécution clé qui gère l'automatisation de laboratoire, le débit des tests et la documentation pour soutenir les besoins de qualité et de conformité du marché de l'IA dans la conception de molécules.



Par Application : La Domination des Petites Molécules Cède la Place à la Montée en Puissance des Produits Biologiques et de la Conception de Protéines
La conception de médicaments à petites molécules représentait 55,32 % des applications en 2025, reflétant des voies établies pour le criblage virtuel, le raffinement basé sur la physique et l'optimisation des leads qui restent au cœur de la découverte précoce. Les moteurs génératifs et physiques sont largement utilisés en tandem pour équilibrer la nouveauté avec la prédiction de l'affinité de liaison, ce qui crée un filtre efficace pour prioriser les candidats avant la synthèse. La pile de petites molécules est désormais plus interopérable à travers les cibles et les propriétés, avec des formats de données partagés permettant des approches d'ensemble qui entrelacent l'amarrage, la génération et l'ADMET pour conduire le triage précoce à grande échelle dans le marché de l'IA dans la conception de molécules. Cette densité d'outillage maintient les petites molécules comme modalité de référence même si de nouvelles classes attirent des investissements et de l'attention.
La conception de produits biologiques ou de protéines est l'application à la croissance la plus rapide avec un TCAC projeté de 27,10 %, soutenue par des avancées dans la prédiction de structure, le repliement inverse et l'optimisation de séquences qui réduisent le besoin de criblage exhaustif de bibliothèques. Des développeurs axés sur l'IA ont signalé des progrès cliniques sur des programmes d'anticorps conçus avec des LLM tenant compte de la séquence et de la structure, fournissant des preuves externes que les flux de travail axés sur la conception peuvent générer des candidats adaptés au développement. Les plateformes de conception de séquences ARN et ARNm intègrent désormais l'optimisation pilotée par l'IA avec une synthèse et des analyses évolutives, ce qui raccourcit le chemin des propositions in silico aux constructions d'expression validées. À mesure que la validation en boucle avec le laboratoire devient routinière, les programmes de produits biologiques tirent parti de cycles de conception qui améliorent la développabilité et la puissance en moins d'itérations, remodelant le mix d'applications au sein du marché de l'IA dans la conception de molécules.
Par Type de Molécule : Les Protéines et les Produits Biologiques Prennent de l'Avance à Mesure que les Modèles de Fondation Arrivent à Maturité
Les petites molécules représentaient 54,34 % du marché de l'IA dans la conception de molécules en 2025, soutenues par la disponibilité de grandes bibliothèques virtuelles et de stratégies de criblage évolutives fonctionnant sur une infrastructure cloud standard. Les cadres de récupération et de criblage informés par la structure ont apporté des accélérations de plusieurs ordres de grandeur, élargissant l'espace de recherche réalisable par cible et améliorant les taux de hits lorsqu'ils sont couplés à des filtres de propriétés. Cette base maintient un débit solide pour les pipelines de chimie médicinale, qui bénéficient toujours des modèles ADMET standard et de la familiarité clinique.
Les protéines et les produits biologiques ont la croissance projetée la plus rapide à un TCAC de 27,32 %, portée par une meilleure modélisation séquence-structure, la prédiction de la développabilité et l'expérimentation autonome qui augmente le rendement des conceptions fonctionnelles. Les modalités centrées sur l'ARN gagnent également du terrain grâce à des plateformes en boucle avec le laboratoire qui optimisent les caractéristiques codantes et non codantes pour améliorer l'expression et la durabilité, ce qui élargit l'espace de conception pratique pour les applications thérapeutiques. Les progrès cliniques dans l'édition génique et la thérapie cellulaire soutiennent l'investissement continu dans les moteurs de conception au niveau des séquences qui s'intègrent aux flux de travail de validation et aux analyses de qualité. À mesure que les chaînes d'outils arrivent à maturité, le mix de types de molécules s'oriente vers les programmes les plus sensibles aux gains d'apprentissage de structure et de séquence, accélérant les changements de parts au sein du marché de l'IA dans la conception de molécules.
Par Technologie : Les Modèles Génératifs en Tête, l'Apprentissage Profond Basé sur la Structure Prend de l'Élan
Les modèles génératifs représentaient 48,27 % du déploiement technologique en 2025, reflétant leur utilité dans la proposition de candidats diversifiés et tenant compte des propriétés pour le filtrage et l'optimisation en aval. Les générateurs basés sur la diffusion et les transformeurs déplacent les méthodes héritées pour la conception de novo en raison de la stabilité de l'entraînement et de la qualité des échantillons, tandis que l'intégration avec l'ADMET et l'amarrage renforce la confiance dans les décisions pour les sélections de synthèse. Les mises à jour des modèles de fondation continuent d'élargir la couverture des cibles et la portée des modalités, permettant une application plus large à travers les petites molécules et les thérapeutiques basées sur la proximité dans le marché de l'IA dans la conception de molécules.
L'apprentissage profond basé sur la structure est la technologie à la croissance la plus rapide avec un TCAC projeté de 27,06 %, ancré par des améliorations dans la prédiction des complexes et la modélisation conformationnelle qui soutiennent la conception guidée par la structure. Les développeurs de modèles combinent des données synthétiques générées par la physique avec des représentations apprises pour combler les lacunes de précision dans les systèmes flexibles, ce qui augmente l'utilité des structures prédites pour la conception et la priorisation. Les chaînes d'outils qui intègrent la rétrosynthèse et la faisabilité des routes dans les fonctions de notation affinent davantage l'ensemble des candidats, améliorant le transfert de la conception in silico au laboratoire. Cette pile complète les approches génératives et soutient des flux de travail de bout en bout qui connectent les cibles, les structures, la génération et la conscience de la synthèse dans le marché de l'IA dans la conception de molécules.
Par Étape de Flux de Travail : L'Identification des Cibles Domine, la Génération de Hits s'Accélère
L'identification ou la priorisation des cibles représentait 47,48 % des déploiements en 2025, car la sélection de cibles à haute confiance est le point de décision le plus influent pour la découverte et le développement en aval. L'intégration de données multimodales et la modélisation prédictive élèvent la solidité des hypothèses de cibles et permettent aux équipes d'aligner leurs efforts sur la biologie la plus prometteuse, ce qui réduit l'attrition en phase tardive. Les ressources de structure et de séquence permettent désormais un triage plus rapide des classes de cibles et de la faisabilité du site de liaison, ce qui crée un chemin plus clair pour la génération de hits en aval dans le marché de l'IA dans la conception de molécules.
La génération de hits ou la conception de novo est l'étape à la croissance la plus rapide avec un TCAC projeté de 26,76 %, alimentée par des ensembles de modèles qui proposent de grands lots de candidats chimiquement diversifiés conditionnés sur les propriétés de puissance et de développabilité. Lorsqu'elle est intégrée à des laboratoires en boucle fermée, cette étape produit un retour immédiat qui affine les générations suivantes et réduit le temps jusqu'aux hits qualifiés. L'optimisation des leads bénéficie ensuite du raffinement basé sur la physique et des prédictions d'énergie libre calibrées, qui soutiennent des synthèses plus petites et plus ciblées pour l'expansion des relations structure-activité. Les flux de travail de bout en bout regroupent de plus en plus les microservices ADMET, de rétrosynthèse et de prédiction de structure afin que les équipes de découverte puissent opérer des cycles continus dans des pipelines de données standardisés dans le marché de l'IA dans la conception de molécules.
Par Utilisateur Final : Pharma ou Biotech en Tête, les ORC ou CDMO en Forte Croissance à Mesure que l'Externalisation s'Accélère
Les entreprises pharmaceutiques et biotechnologiques détenaient 65,42 % en 2025, reflétant la concentration des budgets de découverte et le besoin stratégique de renouveler les pipelines à mesure que le mix de modalités évolue. Les équipes de découverte au sein des grandes organisations déploient des piles d'IA standardisées à travers les cibles et les modalités pour aligner la conception computationnelle avec la capacité de laboratoire, ce qui améliore le débit et la qualité des données pour les cycles itératifs dans le marché de l'IA dans la conception de molécules.
Les ORC et les CDMO sont les utilisateurs finaux à la croissance la plus rapide avec un TCAC projeté de 27,24 %, car les entreprises commanditaires transfèrent le travail à des partenaires capables d'exécuter une chimie et une biologie augmentées par l'IA avec une automatisation de laboratoire intégrée. Les fournisseurs qui regroupent les moteurs de conception avec la synthèse et les analyses réduisent les frais généraux des commanditaires et accélèrent les cycles, tandis que la documentation standardisée soutient le transfert de technologie et la préparation réglementaire. L'effet est un écosystème de services plus évolutif qui élargit l'accès aux flux de travail avancés au sein du marché de l'IA dans la conception de molécules.
Analyse Géographique
L'Amérique du Nord représentait 44,54 % du marché de l'IA dans la conception de molécules en 2025, soutenue par une masse critique de budgets de découverte, de talents computationnels et d'infrastructure de laboratoire qui intègre l'IA à l'expérimentation automatisée. La région dispose d'un déploiement actif de microservices de modèles de fondation et de chaînes d'outils physiques, permettant un criblage et une priorisation plus rapides à travers les cibles et les modalités. Les écosystèmes de fournisseurs couvrant les plateformes cloud accélérées par GPU et les hubs de modèles ont augmenté l'accès aux outils performants, ce qui soutient l'expérimentation à grande échelle à travers les domaines thérapeutiques dans le marché de l'IA dans la conception de molécules.
L'Asie-Pacifique est la région à la croissance la plus rapide avec un TCAC projeté de 26,57 % jusqu'en 2031, ancrée par des initiatives soutenues par les gouvernements et des plateformes académiques-industrielles qui élargissent l'accès aux outils d'analyse des cibles, de conception générative et d'évaluation. La Chine a lancé une plateforme d'IA à processus complet qui offre un accès gratuit pour l'analyse des cibles, la génération de molécules et l'optimisation ADMET, ce qui abaisse les barrières pour les laboratoires académiques et les startups. Les programmes liés à l'Université Tsinghua ont signalé des accélérations d'un million de fois dans le criblage virtuel et ont ouvert de grandes bases de données protéine-ligand à la communauté, ce qui élargit l'espace de recherche pour les projets de découverte dans le marché de l'IA dans la conception de molécules. Le METI et le NEDO japonais ont soutenu des travaux sur des modèles de fondation à grande échelle pour la conception de médicaments, signalant l'engagement du secteur public à développer la découverte axée sur l'IA.
L'Europe bénéficie d'un financement public coordonné et d'un réseau dense de centres pharmaceutiques, biotechnologiques et académiques qui connectent la modélisation de découverte à l'infrastructure translationnelle. Des programmes nationaux ont introduit des financements ciblés pour accélérer la découverte de médicaments activée par l'IA, avec une infrastructure solide dans les pays qui accueillent les principales entreprises pharmaceutiques et institutions de recherche. À travers la région, le marché de l'IA dans la conception de molécules se développe à mesure que les parties prenantes connectent les modèles de fondation, l'automatisation de laboratoire et les analyses de processus pour soutenir la découverte et le développement précoce à travers plusieurs modalités.

Paysage Concurrentiel
La concurrence sur le marché de l'IA dans la conception de molécules est modérément fragmentée à travers les piles technologiques, les modalités thérapeutiques et les modèles de mise sur le marché, la différenciation se déplaçant vers les actifs de données et l'exécution en boucle avec le laboratoire qui améliorent le rendement de conception au fil du temps. La consolidation remodèle les capacités à travers des combinaisons de chimie générative, de phénomique et d'identification des cibles sous un même toit, ce qui soutient une découverte à grande échelle à travers les portefeuilles. Les actifs de données sont au cœur des préoccupations à mesure que les entreprises investissent dans des ensembles de données propriétaires de haute qualité et dans l'automatisation qui créent des boucles de rétroaction pour améliorer les performances des modèles dans le marché de l'IA dans la conception de molécules.
Les leaders de l'écosystème standardisent également l'accès aux modèles via des microservices cloud, ce qui crée des effets de réseau à mesure que davantage d'utilisateurs contribuent à l'ajustement et à l'évaluation. Les plateformes d'ingénierie de l'ARN et des protéines émergent comme des niches à forte croissance, renforcées par l'intérêt des investisseurs et les capacités en boucle avec le laboratoire qui connectent la conception à la synthèse et aux analyses dans un seul environnement. Les entreprises mettent également l'accent sur l'explicabilité et la provenance pour soutenir les exigences des commanditaires en matière de gouvernance interne et de documentation prête pour la réglementation, ce qui aligne la différenciation technologique avec les besoins opérationnels dans la découverte et le développement.
Des mouvements stratégiques sélectifs illustrent l'arc concurrentiel du marché de l'IA dans la conception de molécules à mesure qu'il se développe. Une combinaison biotech très médiatisée a intégré de grands ensembles de données propriétaires et des moteurs de découverte multi-modalités sous une seule structure d'entreprise pour accélérer la découverte industrialisée. Les hubs d'accès aux modèles de fondation ont sécurisé une adoption large auprès de plus d'une centaine d'entreprises, confirmant le rôle central des API standardisées et du cloud GPU pour la génération moléculaire, l'amarrage et le repliement à grande échelle. Les évaluations comparatives d'expérimentation autonome en ingénierie des protéines ont démontré des gains de coût et de vitesse grâce aux flux de travail de laboratoire dirigés par l'IA, validant l'intégration de l'inférence de modèles avec des systèmes de laboratoire automatisés dans des contextes commerciaux.
Leaders du Secteur de l'IA dans la Conception de Molécules
Schrödinger
Exscientia
Insilico Medicine
Recursion
XtalPi
- *Avis de non-responsabilité : les principaux acteurs sont triés sans ordre particulier

Développements Récents du Secteur
- Avril 2026 : Isomorphic Labs, la filiale de DeepMind, fait progresser la conception de molécules pilotée par l'IA vers une nouvelle phase en préparant ses premiers essais cliniques humains de candidats médicaments conçus par l'IA. Utilisant ses systèmes d'IA construits sur AlphaFold et des modèles génératifs, l'entreprise conçoit et optimise de nouvelles molécules pour des maladies telles que le cancer et les troubles immunitaires. Après avoir sécurisé des partenariats majeurs avec des entreprises pharmaceutiques et des financements, elle passe désormais de la génération de molécules in silico à la validation dans le monde réel, avec des essais humains attendus vers 2026. Cela marque une étape clé où les molécules conçues par l'IA passent de la découverte computationnelle aux tests cliniques chez l'homme.
- Mars 2026 : Roche a lancé une « usine » d'IA pour le développement de médicaments en collaboration avec NVIDIA pour développer la conception de molécules et la découverte de médicaments pilotées par l'IA. Le système utilise une infrastructure GPU à grande échelle pour exécuter des modèles d'IA générative qui aident à concevoir de nouvelles molécules médicamenteuses, à identifier des cibles et à simuler le comportement biologique plus efficacement. Il intègre ces capacités à travers le pipeline de R&D et de fabrication de Roche, permettant une approche plus automatisée et axée sur les données pour le développement de médicaments.
- Mars 2026 : Eli Lilly a conclu un accord de 2,75 milliards USD avec Insilico Medicine pour faire progresser la conception de molécules pilotée par l'IA pour la découverte de médicaments. La collaboration s'est concentrée sur l'utilisation de l'IA générative pour créer et optimiser de nouvelles molécules médicamenteuses, que Lilly développe en thérapies potentielles, notamment dans des domaines tels que l'oncologie et les maladies métaboliques. Cet accord met en évidence la confiance croissante des entreprises pharmaceutiques dans les molécules conçues par l'IA en tant que candidats médicaments précliniques viables.


Portée du Rapport Mondial sur le Marché de l'IA dans la Conception de Molécules
Selon la portée du rapport, l'IA dans la conception de molécules désigne l'utilisation de modèles d'apprentissage automatique et génératifs pour prédire, créer et optimiser des structures moléculaires en apprenant à partir de grands ensembles de données chimiques, permettant une exploration plus rapide de l'espace chimique et accélérant le cycle conception-fabrication-test. Elle soutient des tâches telles que la prédiction de propriétés, la génération de molécules de novo et l'optimisation automatisée, aidant les scientifiques à concevoir de nouveaux candidats médicaments et matériaux plus efficacement.
Le marché de l'IA dans la conception de molécules est segmenté par composant, application, type de molécule, technologie, étape de flux de travail, utilisateur final et géographie. Par composant, le marché est segmenté en logiciels et services. Par application, le marché est segmenté en conception de médicaments à petites molécules, conception de produits biologiques/protéines, conception de matériaux et de produits chimiques spéciaux, et conception d'agrochimiques. Par type de molécule, le marché est segmenté en petites molécules, peptides, protéines/produits biologiques, ARN/oligonucléotides, et molécules de matériaux/polymères. Par technologie, le marché est segmenté en modèles génératifs, apprentissage profond basé sur la structure, prédiction de propriétés/ADMET ML, et IA de planification de synthèse et de rétrosynthèse. Par étape de flux de travail, le marché est segmenté en identification/priorisation des cibles, génération de hits/conception de novo, hit-to-lead, optimisation des leads, et autres. Par utilisateur final, le marché est segmenté en entreprises pharmaceutiques et biotechnologiques, ORC et CDMO, fabricants de produits chimiques et de matériaux, et autres. Par géographie, le marché est segmenté en Amérique du Nord, Europe, Asie-Pacifique, Moyen-Orient et Afrique, et Amérique du Sud. Le rapport couvre également les tailles de marché estimées et les tendances pour 17 pays à travers les principales régions mondiales. Le rapport offre des valeurs (USD) pour tous les segments ci-dessus.
| Logiciels |
| Services |
| Conception de Médicaments à Petites Molécules |
| Conception de Produits Biologiques/Protéines |
| Conception de Matériaux et de Produits Chimiques Spéciaux |
| Conception d'Agrochimiques |
| Petites Molécules |
| Peptides |
| Protéines/Produits Biologiques |
| ARN/Oligonucléotides |
| Molécules de Matériaux/Polymères |
| Modèles Génératifs |
| Apprentissage Profond Basé sur la Structure |
| Prédiction de Propriétés/ADMET ML |
| IA de Planification de Synthèse et de Rétrosynthèse |
| Identification/Priorisation des Cibles |
| Génération de Hits/Conception de Novo |
| Hit-to-Lead |
| Optimisation des Leads |
| Autres |
| Entreprises Pharmaceutiques et Biotechnologiques |
| ORC et CDMO |
| Fabricants de Produits Chimiques et de Matériaux |
| Autres |
| Amérique du Nord | États-Unis |
| Canada | |
| Mexique | |
| Europe | Allemagne |
| Royaume-Uni | |
| France | |
| Italie | |
| Espagne | |
| Reste de l'Europe | |
| Asie-Pacifique | Chine |
| Japon | |
| Inde | |
| Australie | |
| Corée du Sud | |
| Reste de l'Asie-Pacifique | |
| Moyen-Orient et Afrique | CCG |
| Afrique du Sud | |
| Reste du Moyen-Orient et de l'Afrique | |
| Amérique du Sud | Brésil |
| Argentine | |
| Reste de l'Amérique du Sud |
| Par Composant | Logiciels | |
| Services | ||
| Par Application | Conception de Médicaments à Petites Molécules | |
| Conception de Produits Biologiques/Protéines | ||
| Conception de Matériaux et de Produits Chimiques Spéciaux | ||
| Conception d'Agrochimiques | ||
| Par Type de Molécule | Petites Molécules | |
| Peptides | ||
| Protéines/Produits Biologiques | ||
| ARN/Oligonucléotides | ||
| Molécules de Matériaux/Polymères | ||
| Par Technologie | Modèles Génératifs | |
| Apprentissage Profond Basé sur la Structure | ||
| Prédiction de Propriétés/ADMET ML | ||
| IA de Planification de Synthèse et de Rétrosynthèse | ||
| Par Étape de Flux de Travail | Identification/Priorisation des Cibles | |
| Génération de Hits/Conception de Novo | ||
| Hit-to-Lead | ||
| Optimisation des Leads | ||
| Autres | ||
| Par Utilisateur Final | Entreprises Pharmaceutiques et Biotechnologiques | |
| ORC et CDMO | ||
| Fabricants de Produits Chimiques et de Matériaux | ||
| Autres | ||
| Par Géographie | Amérique du Nord | États-Unis |
| Canada | ||
| Mexique | ||
| Europe | Allemagne | |
| Royaume-Uni | ||
| France | ||
| Italie | ||
| Espagne | ||
| Reste de l'Europe | ||
| Asie-Pacifique | Chine | |
| Japon | ||
| Inde | ||
| Australie | ||
| Corée du Sud | ||
| Reste de l'Asie-Pacifique | ||
| Moyen-Orient et Afrique | CCG | |
| Afrique du Sud | ||
| Reste du Moyen-Orient et de l'Afrique | ||
| Amérique du Sud | Brésil | |
| Argentine | ||
| Reste de l'Amérique du Sud | ||


Questions Clés Auxquelles le Rapport Répond
Quelle est la taille actuelle et les perspectives de croissance du marché de l'IA dans la conception de molécules ?
La taille du marché de l'IA dans la conception de molécules était de 1,69 milliard USD en 2025 et devrait atteindre 6,37 milliards USD d'ici 2031 à un TCAC de 25,52 %, signalant une dynamique pluriannuelle à travers les flux de travail de découverte.
Quelles régions stimuleront la croissance la plus rapide jusqu'en 2031 ?
L'Asie-Pacifique est la région à la croissance la plus rapide avec un TCAC projeté de 26,57 %, soutenue par des plateformes soutenues par les gouvernements et des programmes académiques-industriels qui élargissent l'accès aux outils de conception activés par l'IA.
Quelles applications et quels types de molécules sont appelés à connaître la plus forte croissance ?
La conception de produits biologiques ou de protéines est l'application à la croissance la plus rapide à un TCAC de 27,10 %, tandis que les protéines ou les produits biologiques mènent la croissance par type de molécule à 27,32 % grâce aux modèles en boucle avec le laboratoire et tenant compte de la structure qui améliorent le rendement.
Quelles technologies sont les plus largement utilisées aujourd'hui dans la conception activée par l'IA ?
Les modèles génératifs sont en tête avec 48,27 % de déploiement, et l'apprentissage profond basé sur la structure est le plus en croissance avec un TCAC de 27,06 %, aidé par les avancées dans la prédiction des complexes et les microservices fournis dans le cloud.
Dernière mise à jour de la page le:




