Taille et Part du Marché de l'IA en Bioinformatique
VUE D’ENSEMBLE DU MARCHÉ
| Période d'étude | 2020 - 2031 |
|---|---|
| Taille du Marché (2026) | 11.89 Milliards de dollars |
| Taille du Marché (2031) | 25.21 Milliards de dollars |
| Taux de croissance (2026 - 2031) | 16.23% CAGR |
| Marché à la Croissance la Plus Rapide | Asie-Pacifique |
| Plus Grand Marché | Amérique du Nord |
| Concentration du Marché | Moyen |
Acteurs majeurs *Avis de non-responsabilité : les principaux acteurs sont triés sans ordre particulier Image © Mordor Intelligence. La réutilisation nécessite une attribution sous CC BY 4.0. | |
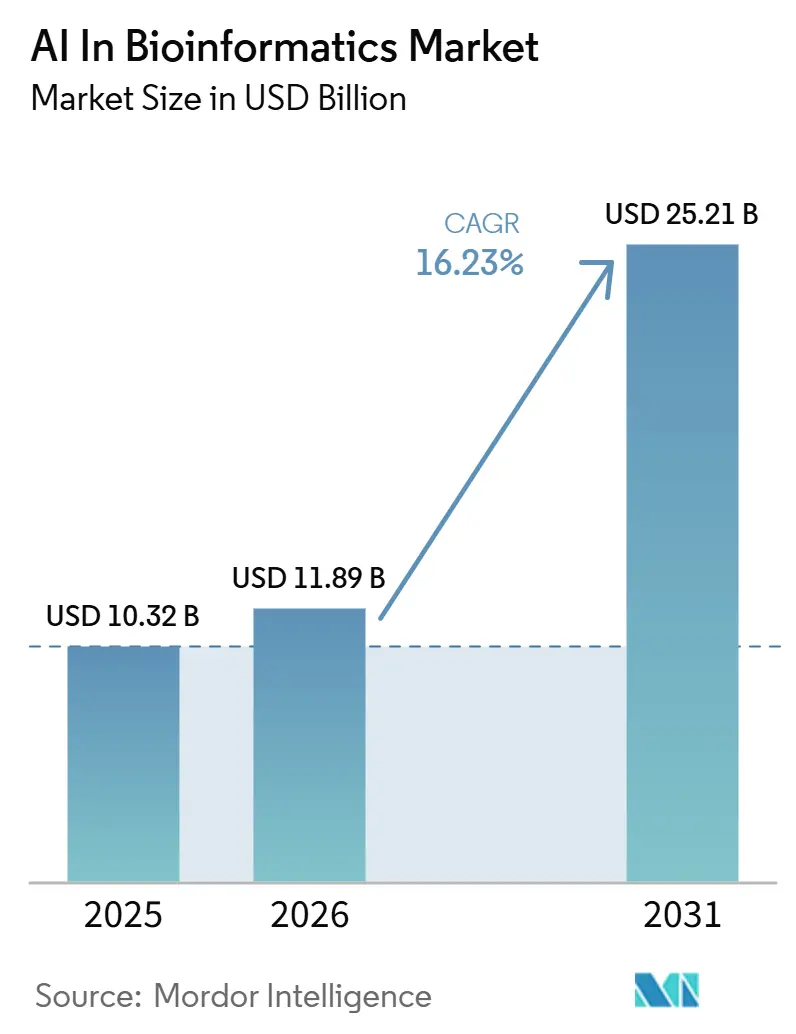
Analyse du Marché de l'IA en Bioinformatique par Mordor Intelligence
Le marché de l'IA en bioinformatique devrait croître de 10,32 milliards USD en 2025 à 11,89 milliards USD en 2026 et est prévu d'atteindre 25,21 milliards USD d'ici 2031 à un CAGR de 16,23 % sur la période 2026-2031. Le marché de l'IA en bioinformatique est reconfiguré par des plateformes natives à l'IA qui remplacent les outils bioinformatiques basés sur des règles dans les flux de travail d'analyse de base. Le marché de l'IA en bioinformatique s'étend également parce que les volumes de séquençage génomique dépassent désormais ce que les analystes humains peuvent interpréter avec des méthodes manuelles ou pilotées par des règles. Les entreprises pharmaceutiques vont au-delà de l'acquisition de logiciels et prennent des participations directes dans l'infrastructure de découverte pilotée par l'IA, ce qui modifie la façon dont la valeur est captée sur l'ensemble du marché de l'IA en bioinformatique. La concurrence reste partagée entre les acteurs établis de la génomique et du diagnostic d'un côté et les spécialistes natifs à l'IA de l'autre, tandis que l'activité d'acquisition montre que les grandes entreprises de santé achètent de plus en plus des capacités d'IA plutôt que de les développer en interne. Les exigences de validation réglementaire restent le principal frein au déploiement dans les environnements cliniques et GxP, ce qui favorise les fournisseurs disposant déjà de solides cadres de conformité, de documentation et d'audit.
Principaux Enseignements du Rapport
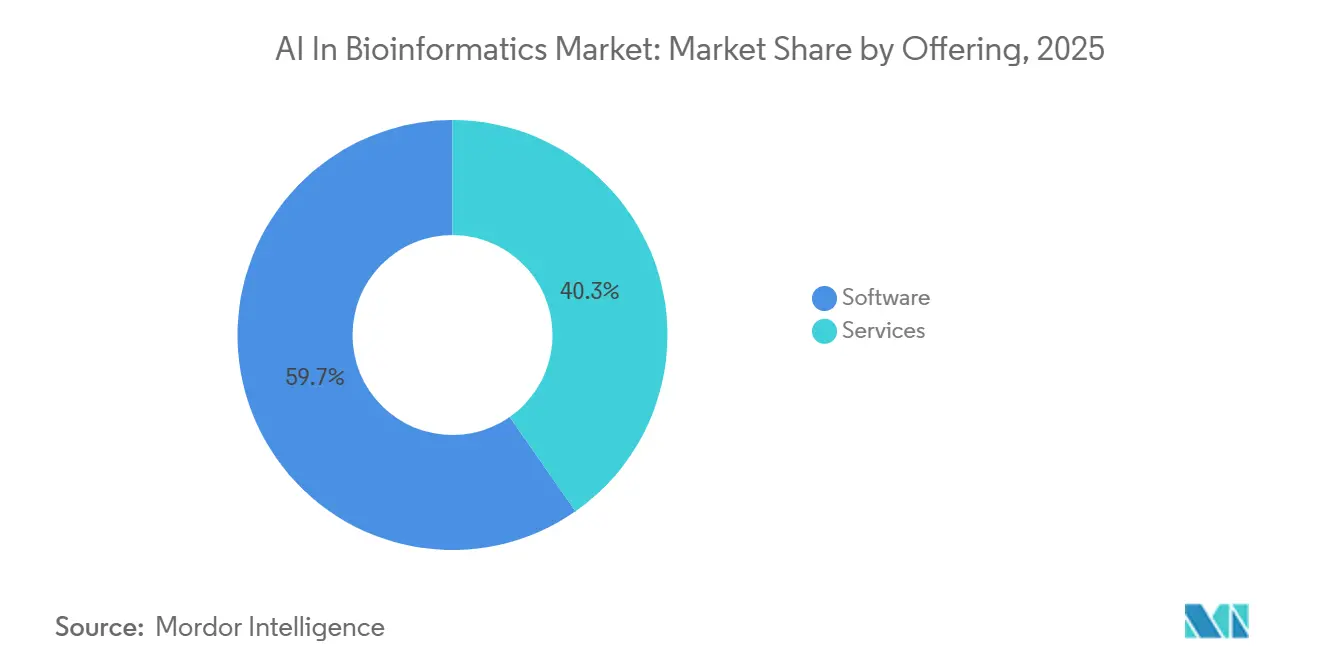
- Par offre, les logiciels ont dominé avec une part de 59,73 %, tandis que les services devraient se développer à un CAGR de 16,58 % jusqu'en 2031.
- Par technologie, l'apprentissage automatique détenait une part de 44,38 % en 2025, tandis que le traitement du langage naturel devrait croître à un CAGR de 16,82 % jusqu'en 2031.
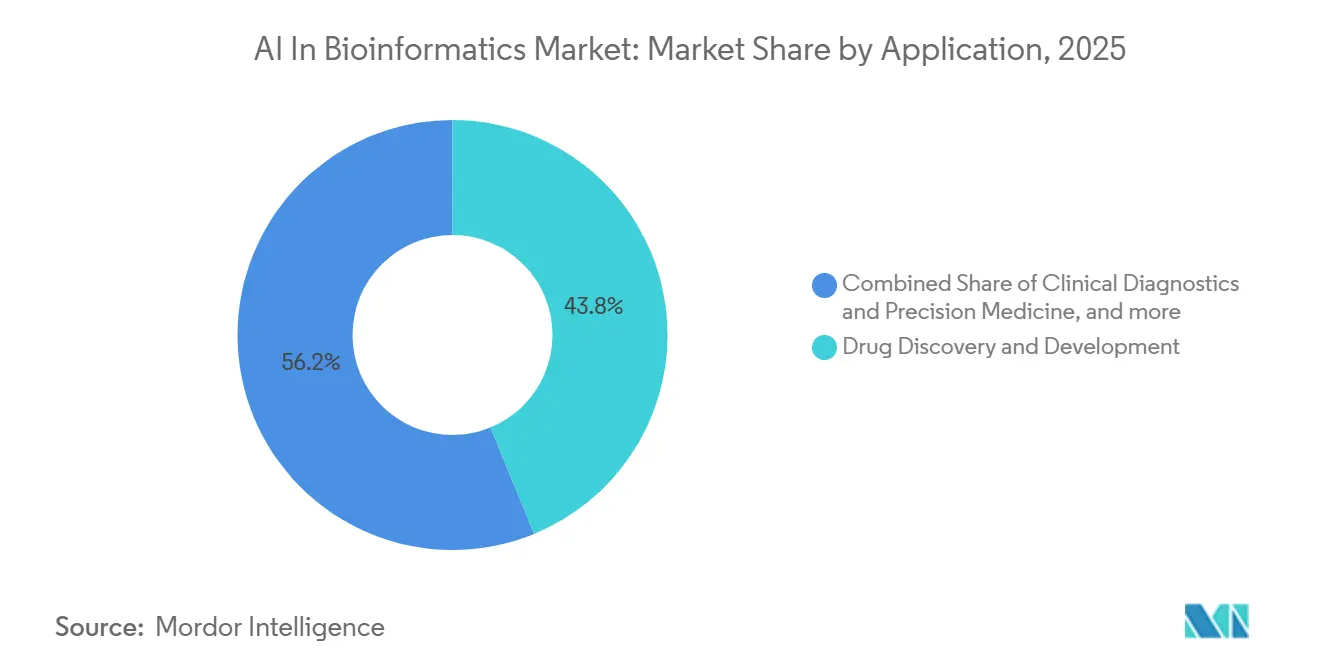
- Par application, la découverte et le développement de médicaments représentaient une part de 43,82 % en 2025, tandis que la découverte et la validation de biomarqueurs devraient se développer à un CAGR de 17,34 % jusqu'en 2031.
- Par utilisateur final, les entreprises pharmaceutiques et biotechnologiques détenaient une part de 51,25 % en 2025, tandis que les instituts académiques et de recherche devraient croître à un CAGR de 17,22 % jusqu'en 2031.
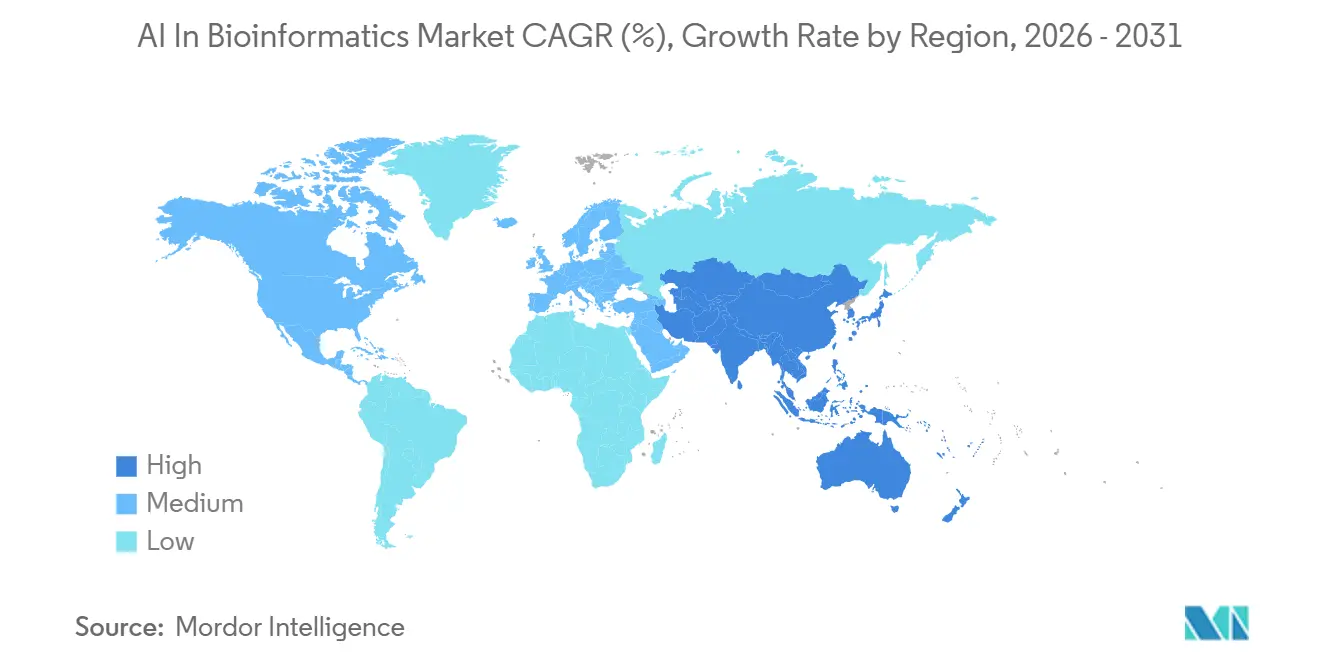
- Par géographie, l'Amérique du Nord détenait 48,55 % de la part du marché de l'IA en bioinformatique en 2025, tandis que l'Asie-Pacifique devrait croître à un CAGR de 18,43 % jusqu'en 2031.
Note : La taille du marché et les prévisions figurant dans ce rapport sont générées à l'aide du cadre d'estimation exclusif de Mordor Intelligence, mis à jour avec les dernières données et informations disponibles en janvier 2026.
Tendances et Perspectives du Marché Mondial de l'IA en Bioinformatique
Analyse de l'Impact des Moteurs*
| Moteur | (~) % Impact sur les Prévisions de CAGR | Pertinence Géographique | Horizon Temporel |
|---|---|---|---|
| Interprétation Pilotée par l'IA des Données Multi-Omiques à Grande Échelle | +3.2% | Mondial, avec des gains concentrés en Amérique du Nord et en Europe | Moyen terme (2-4 ans) |
| Stratification des Essais Cliniques et Appariement des Cohortes | +2.8% | Amérique du Nord et Europe, extension vers l'Asie-Pacifique | Moyen terme (2-4 ans) |
| Modèles Fondamentaux pour la Prédiction de Séquences et de Structures Biologiques | +3.5% | Mondial, porté par l'Amérique du Nord et l'Asie de l'Est | Court terme (≤ 2 ans) et Moyen terme (2-4 ans) |
| Apprentissage Fédéré à Travers les Silos de Données Hospitalières et des Biobanques | +2.2% | Europe, Amérique du Nord, avec une adoption précoce au Japon et en Corée du Sud | Moyen terme (2-4 ans) et Long terme (≥ 4 ans) |
| Automatisation des Flux de Travail en Boucle Fermée entre Laboratoire Humide et Simulation Informatique | +1.8% | Amérique du Nord et Europe | Moyen terme (2-4 ans) |
| Expansion des Modèles Multi-Ascendances pour la Génomique à l'Échelle des Populations | +1.5% | Cœur Asie-Pacifique, extension vers le Moyen-Orient et Afrique et l'Amérique du Sud | Long terme (≥ 4 ans) |
| Source: Mordor Intelligence | |||
Interprétation Pilotée par l'IA des Données Multi-Omiques à Grande Échelle
Le marché de l'IA en bioinformatique est porté en avant par la fusion de la génomique, de la transcriptomique, de la protéomique et de la métabolomique dans des flux de travail d'IA unifiés. L'analyse multi-omique était auparavant limitée parce que les modèles peinaient à réconcilier les différentes propriétés statistiques et les effets de lot entre les types de données. Une étude de 2026 publiée dans Cell Metabolism a montré une modélisation multi-omique unifiée portant sur 425 258 individus, avec de solides performances dans la prédiction des trajectoires de vieillissement, de la santé métabolique et de la réponse aux interventions à une échelle que les approches à modalité unique ne pouvaient pas atteindre.[1]« Un Cadre d'IA Générative Unifie la Multi-Omique Humaine pour Modéliser le Vieillissement, la Santé Métabolique et la Réponse aux Interventions », Cell Metabolism, cell.comCela pousse les entreprises pharmaceutiques vers la multi-omique intégrée à l'IA comme étape plus routinière dans la validation des cibles et réduit la dépendance aux voies de criblage in vitro plus lentes. La boîte à outils Flexynesis de 2025 a également montré comment les données multi-omiques en vrac peuvent soutenir la stratification en oncologie de précision, ce qui indique une utilisation clinique plus précoce dans la sélection des indications cancéreuses.[2]Anne-Christin Hauschild et al., « Flexynesis, Une Boîte à Outils d'Apprentissage Profond pour l'Intégration de Données Multi-Omiques en Vrac pour l'Oncologie de Précision et Au-delà », Nature Communications, nature.comLe défi restant s'est déplacé de la génération de données vers l'harmonisation sémantique, car les fournisseurs doivent désormais aligner les normes incohérentes de phénotypage clinique et de métadonnées à travers de grands ensembles de données de cohortes.
Stratification des Essais Cliniques et Appariement des Cohortes
Le marché de l'IA en bioinformatique bénéficie également du besoin d'améliorer la sélection des sous-groupes de patients dans le développement de médicaments. Les outils épidémiologiques conventionnels échouent souvent à isoler les populations de répondeurs définis pharmacogénomiquement au sein de pools d'essais hétérogènes, et cette faiblesse a contribué aux échecs en Phase II. Le programme pilote de la FDA d'avril 2026 sur l'IA dans les essais cliniques a directement abordé la sélection des doses, la surveillance de la sécurité et les décisions précoces d'avancement ou d'abandon, ce qui apporte un soutien réglementaire plus clair aux outils bioinformatiques d'IA utilisés dans la conception et l'exécution des essais.[3]Agence américaine des produits alimentaires et médicamenteux, « Intelligence Artificielle dans les Essais Cliniques, Programme Pilote », Federal Register, govinfo.govLes plateformes commerciales répondent en combinant des données génomiques, transcriptomiques, d'imagerie et cliniques dans des définitions de cohortes utilisables beaucoup plus rapidement que les flux de travail traditionnels. Cela accroît la demande de logiciels explicables, car les cohortes définies par l'IA qui entrent dans les soumissions réglementaires nécessiteront des paramètres de modèle fixes, une logique auditable et des enregistrements de traçabilité clairs.
Modèles Fondamentaux pour la Prédiction de Séquences et de Structures Biologiques
Le marché de l'IA en bioinformatique évolue rapidement à mesure que les modèles fondamentaux s'étendent de la prédiction de protéines individuelles à la modélisation plus large des séquences biologiques et du génome. NVIDIA a étendu sa plateforme BioNeMo en janvier 2026 à la prédiction de la structure de l'ARN et à l'optimisation de la rétrosynthèse, ce qui montre comment le développement de modèles biologiques est transformé en infrastructure commerciale utilisable. Les modèles EDEN de Basecamp Research, entraînés sur jusqu'à 9,7 billions de jetons nucléotidiques sur 28 milliards de paramètres, ont montré comment la grande échelle des modèles est désormais appliquée à des problèmes difficiles tels que l'insertion de grands segments d'ADN. Les publications de modèles à poids ouverts par des groupes académiques réduisent l'écart avec les systèmes propriétaires, de sorte que les fournisseurs commerciaux sont poussés à se concurrencer davantage sur l'accès exclusif aux données et le déploiement de qualité clinique plutôt que sur la seule propriété des modèles. Ce changement raccourcit la fenêtre de monétisation pour les développeurs de modèles propriétaires sur l'ensemble du marché de l'IA en bioinformatique.
Apprentissage Fédéré à Travers les Silos de Données Hospitalières et des Biobanques
Le marché de l'IA en bioinformatique bénéficie également de l'apprentissage fédéré car il crée une puissance statistique à l'échelle des populations sans nécessiter le déplacement de données génomiques sensibles vers un référentiel central unique. En 2025, SF-GWAS a démontré une analyse d'association pangénomique sécurisée sur une cohorte de la UK Biobank de 410 000 individus avec une amélioration significative du temps d'exécution par rapport aux méthodes fédérées antérieures. L'IIS La Fe d'Espagne a également lancé OmicSpace en tant que plateforme fédérée reliant des biobanques et des registres génomiques cliniques dans 5 communautés autonomes sans centraliser les données, ce qui constitue une preuve de concept nationale directe pour ce modèle de déploiement. La limite pratique est que les cas d'usage des maladies rares souffrent encore lorsque les tailles d'échantillons locaux restent trop petites à chaque nœud, ce qui réduit les performances du modèle même lorsque la fédération est techniquement solide.
Analyse de l'Impact des Freins*
| Frein | (~) % Impact sur les Prévisions de CAGR | Pertinence Géographique | Horizon Temporel |
|---|---|---|---|
| Friction liée à la Souveraineté des Données dans la Collaboration Génomique Transfrontalière | -1.5% | Europe, Asie-Pacifique (Chine spécifiquement), Moyen-Orient et Afrique | Moyen terme (2-4 ans) et Long terme (≥ 4 ans) |
| Charge de Validation des Modèles dans les Cas d'Usage Cliniques, de Recherche et GxP | -1.0% | Mondial, le plus aigu en Amérique du Nord et en Europe | Court terme (≤ 2 ans) et Moyen terme (2-4 ans) |
| Contraintes de GPU et de Calcul Haute Performance pour les Grands Pipelines Omiques | -1.2% | Mondial, le plus limitant dans les contextes à contraintes de coûts au Moyen-Orient et Afrique et en Amérique du Sud | Court terme (≤ 2 ans) |
| Ensembles de Données Biologiques Étiquetés Limités pour les Cas d'Usage de Variants Rares et de Maladies Rares | -0.8% | Mondial | Long terme (≥ 4 ans) |
| Source: Mordor Intelligence | |||
Friction liée à la Souveraineté des Données dans la Collaboration Génomique Transfrontalière
Le marché de l'IA en bioinformatique fait face à une contrainte majeure liée aux règles transfrontalières sur les données génomiques qui ont été élaborées sur des hypothèses différentes concernant la vie privée, le risque de ré-identification et l'utilisation secondaire des données. Le RGPD de l'UE, la Loi chinoise sur la Protection des Informations Personnelles et les règles d'Administration des Ressources Génétiques Humaines, ainsi que le cadre de partage des données génomiques du NIH américain ne s'alignent pas bien en pratique, ce qui allonge les délais de gouvernance pour les programmes multinationaux d'entraînement et de validation de modèles. Les règles chinoises sur les ressources génétiques sont particulièrement restrictives pour la recherche impliquant des entités étrangères car elles imposent des contrôles à l'exportation et des exigences de localisation nationale sur les flux de données pertinents. En conséquence, le marché de l'IA en bioinformatique évolue vers des structures de partenariat de données spécifiques à chaque pays plutôt que vers de simples accords de licence mondiaux. Cela augmente les coûts de développement et prolonge le délai de mise sur le marché pour les fournisseurs souhaitant des ensembles de données d'entraînement pertinents à l'échelle mondiale.
Charge de Validation des Modèles dans les Cas d'Usage Cliniques, de Recherche et GxP
Le marché de l'IA en bioinformatique fait également face à un déploiement plus lent parce que le projet de directive de la FDA de janvier 2025 a introduit un cadre d'évaluation de crédibilité basé sur le risque en 7 étapes pour l'IA utilisée dans le développement de médicaments et de produits biologiques. Les promoteurs doivent désormais définir le contexte d'utilisation, évaluer l'influence du modèle sur la prise de décision et fournir des preuves de validation correspondant au risque du cas d'usage. Cette charge documentaire est beaucoup plus difficile pour les jeunes entreprises natives à l'IA que pour les fournisseurs établis qui opèrent déjà sous des systèmes de management de la qualité. Le problème est amplifié car un modèle validé pour un contexte réglementé ne peut pas être transféré dans un cas d'usage adjacent sans un nouveau cycle de validation. Les exigences GxP telles que la validation des systèmes informatisés, la conformité à la réglementation 21 CFR Partie 11 et l'intégrité des pistes d'audit s'adaptent également mal aux architectures d'apprentissage continu, ce qui crée un travail d'ingénierie supplémentaire avant le déploiement. Cela devrait pousser davantage de parts vers les fournisseurs capables d'offrir des environnements de déploiement réglementé préconstruits sur l'ensemble du marché de l'IA en bioinformatique.
*Nos prévisions considèrent les impacts des moteurs et des contraintes comme directionnels et non additifs. Les prévisions d'impact reflètent la croissance de référence, les effets de composition et les interactions entre variables.
Analyse des Segments
Par Offre : L'Accélération des Services Signale une Chaîne de Valeur en Mutation
Les logiciels détenaient 59,73 % de la part du marché de l'IA en bioinformatique en 2025, soutenus par des plateformes d'interprétation génomique en mode SaaS, des outils d'annotation de variants natifs au cloud et des pipelines d'analyse de séquençage alimentés par l'IA qui s'adaptent efficacement après déploiement. Sa position est également renforcée par les coûts de changement créés par de grandes bases de données génomiques et par des poids de modèles propriétaires intégrés dans les plateformes logicielles. Ces facteurs font des logiciels l'offre la plus ancrée sur le marché de l'IA en bioinformatique à l'heure actuelle. La proposition de valeur a été la plus forte là où les clients ont besoin d'analyses répétables, d'un débit plus rapide et de mises à jour centralisées des modèles sur plusieurs programmes de recherche.
Les services devraient être le sous-segment à la croissance la plus rapide à un CAGR de 16,58 % de 2026 à 2031, ce qui montre que le déploiement complexe de modèles pousse les acheteurs vers un soutien externe. Le secteur de l'IA en bioinformatique évolue vers des contrats groupés de plateforme et de services car la personnalisation des modèles, l'intégration des pipelines et l'analyse gérée sont plus difficiles à standardiser que les logiciels seuls. Les revenus s'éloignent des modèles uniquement logiciels et évoluent vers des structures d'engagement récurrentes basées sur les services sur le marché de l'IA en bioinformatique.


Par Technologie : L'Ascension du Traitement du Langage Naturel Reflète la Littérature Biomédicale comme Couche de Données Exploitable
L'apprentissage automatique détenait une part de 44,38 % en 2025 et est resté la base technologique la plus établie dans les pipelines de séquençage, la classification des variants, les études d'association de biomarqueurs et la prédiction de phénotypes. Les modèles supervisés tels que les arbres à gradient boosté et les forêts aléatoires restent importants car les flux de travail de génomique clinique favorisent souvent l'interprétabilité et la calibration. L'apprentissage profond a fourni de meilleures performances relatives dans la prédiction de la structure des protéines, l'analyse d'images de lames entières et les tâches à cellule unique, ce qui le maintient important même lorsqu'il ne mène pas la part globale. Ce mélange montre que le marché de l'IA en bioinformatique utilise encore plusieurs approches techniques plutôt que de converger vers une classe de modèles dominante unique.
Le traitement du langage naturel devrait être le segment technologique à la croissance la plus rapide à un CAGR de 16,82 % jusqu'en 2031 car la littérature biomédicale, les notes cliniques et les graphes de connaissances deviennent des couches de données actives dans les flux de travail de recherche. La vision par ordinateur reste un segment plus petit, mais il croît parallèlement à la pathologie numérique alimentée par l'IA et à l'imagerie de lames entières dans les flux de travail cliniques. Le secteur de l'IA en bioinformatique s'élargit donc de la seule analyse de séquences vers des tâches de raisonnement textuel, visuel et graphique qui soutiennent davantage le processus de recherche et de diagnostic.
Par Application : La Découverte de Biomarqueurs Émerge comme le Vecteur de Croissance Commerciale le Plus Rapide
La découverte et le développement de médicaments représentaient 43,82 % de la taille du marché de l'IA en bioinformatique en 2025, ce qui reflète les dépenses pharmaceutiques de longue date en identification de cibles, optimisation des leads, informatique translationnelle et prédiction ADMET. Ce segment reste le plus important car il est proche de la création de valeur commerciale et dispose déjà de budgets établis au sein des grandes organisations pharmaceutiques. L'application bénéficie également du mouvement des entreprises pharmaceutiques vers la propriété directe de plateformes plutôt que vers une acquisition limitée de logiciels. Cela maintient la découverte de médicaments au centre de la demande sur le marché de l'IA en bioinformatique.
La découverte et la validation de biomarqueurs devraient être le segment d'application à la croissance la plus rapide à un CAGR de 17,34 % de 2026 à 2031, car les pipelines d'oncologie de précision accordent plus de poids aux diagnostics compagnons et à la biopsie liquide. La demande augmente parce que les modèles multi-omiques pilotés par l'IA peuvent raccourcir les délais de découverte et aider à valider les biomarqueurs dans des groupes de patients plus hétérogènes. Le diagnostic clinique et la médecine de précision, l'informatique de laboratoire et l'automatisation des flux de travail, ainsi que la modélisation des réseaux biologiques restent tous des domaines d'application importants sur le marché de l'IA en bioinformatique.

Par Utilisateur Final : Les Institutions Académiques Accélèrent sur l'Infrastructure de Modèles Fondamentaux Ouverts
Les entreprises pharmaceutiques et biotechnologiques représentaient 51,25 % de la part en 2025 car elles peuvent absorber des coûts d'intégration initiaux élevés et sécuriser des accords de licence de données à grande échelle. Elles ont également la plus forte incitation commerciale à raccourcir les délais de développement et à améliorer la productivité en R&D. Cela en fait le groupe d'acheteurs commercialement le plus important sur le marché de l'IA en bioinformatique aujourd'hui. Les relations stratégiques de plateforme deviennent plus importantes que les achats ponctuels de logiciels à mesure que les fournisseurs se rapprochent du soutien intégré à la R&D.
Les instituts académiques et de recherche devraient être le segment d'utilisateurs finaux à la croissance la plus rapide à un CAGR de 17,22 % jusqu'en 2031, aidés par des modèles fondamentaux biologiques à poids ouverts et en source ouverte qui réduisent le coût des capacités avancées d'IA. Au sein du secteur de l'IA en bioinformatique, cela abaisse la barrière pour les chercheurs non commerciaux qui ne disposent pas de budgets importants pour les licences logicielles. Les hôpitaux et les laboratoires de diagnostic deviennent également un groupe de clients plus important à mesure que l'interprétation génomique alimentée par l'IA et la pathologie numérique s'intègrent dans les environnements cliniques réglementés.
Analyse Géographique
L'Amérique du Nord représentait 48,55 % de la taille du marché de l'IA en bioinformatique en 2025, lui conférant la position régionale la plus importante. La région bénéficie d'une dense activité de R&D pharmaceutique, d'un financement en capital-risque profond et d'une solide infrastructure génomique soutenue par le NIH. Les États-Unis restent l'ancre du marché régional de l'IA en bioinformatique, tandis que le Canada apporte un soutien supplémentaire via Génome Canada et les activités connexes de médecine de précision. L'accès à une infrastructure GPU haut de gamme chez les principaux fournisseurs de cloud renforce également l'avantage de coût et de vitesse de l'Amérique du Nord pour les grandes charges de travail omiques, et le projet EuroHPC MeluXina a montré que l'analyse du génome entier accélérée par GPU peut réduire le temps d'exécution de 14,6 heures à 4,7 heures avec Parabricks sur 3 nœuds GPU.
L'Europe est le deuxième bloc régional en importance sur le marché de l'IA en bioinformatique, porté par l'Allemagne, le Royaume-Uni et la France. Au Royaume-Uni, le programme de dépistage du cancer par analyse sanguine en première intention du NHS England et le partenariat de SOPHiA GENETICS de mai 2026 avec Synnovis montrent comment les systèmes de santé publique peuvent créer une demande directe pour le diagnostic génomique activé par l'IA à grande échelle. L'Allemagne a joué un rôle de premier plan dans la génomique fédérée à travers l'Alliance Allemande des Biobanques et le projet d'Infrastructure de Données Génomiques, qui a achevé en 2026 une démonstration d'analyse d'association pangénomique fédérée préservant la vie privée sur plusieurs nœuds nationaux.
L'Asie-Pacifique devrait être la région à la croissance la plus rapide à un CAGR de 18,43 % de 2026 à 2031, ce qui en fait la partie du marché de l'IA en bioinformatique connaissant la croissance la plus rapide. La croissance est portée par des programmes génomiques soutenus par les gouvernements en Chine, au Japon, en Inde et en Corée du Sud, ainsi que par des investissements continus dans l'infrastructure nationale de données de santé. Une étude de 2025 publiée dans Nature sur l'ascendance Han chinoise a montré comment le calcul du score de risque polygénique spécifique à une population peut soutenir le développement de modèles non européens à grande échelle, ce qui est important pour les outils de médecine de précision spécifiques à une région. Les grands programmes de cohortes de la Chine et la recherche multi-ascendances élargissent la base d'entraînement pour les modèles locaux, tandis que l'Amérique du Sud et le Moyen-Orient et l'Afrique montrent une demande à un stade plus précoce à travers des partenariats hospitaliers et des investissements dans l'infrastructure de médecine de précision, notamment la collaboration de PathAI au Brésil en 2026.

Paysage Concurrentiel
Le marché de l'IA en bioinformatique présente une structure modérément concentrée, avec Illumina, Thermo Fisher Scientific, QIAGEN et Oxford Nanopore formant une solide couche d'infrastructure autour des instruments, du diagnostic, des flux de travail de séquençage et des actifs de données organisées. Dans le même temps, des entreprises natives à l'IA telles qu'Insilico Medicine, Owkin, Tempus AI et SOPHiA GENETICS se concurrencent sur l'accès exclusif aux données, l'architecture des modèles et la profondeur des partenariats pharmaceutiques. Cela crée un schéma concurrentiel à deux niveaux sur le marché de l'IA en bioinformatique où les acteurs établis contrôlent des flux de travail importants et les challengers tentent de capter de la valeur dans les logiciels, l'analytique et les sorties de modèles. Un schéma stratégique clair est que les fournisseurs de plateformes cherchent à convertir les relations de données en revenus en aval dans la découverte de médicaments et les diagnostics compagnons. Cela fait évoluer les modèles commerciaux des frais de plateforme fixes vers des relations à plus long terme liées à la productivité de la recherche et au déploiement clinique.
L'activité de partenariat montre à quelle vitesse le marché de l'IA en bioinformatique est réorganisé autour de l'intégration matérielle, logicielle et des données. La collaboration de QIAGEN de mai 2026 avec NVIDIA a associé l'IA de récupération basée sur des graphes aux actifs de connaissances biomédicales organisées de QIAGEN, tandis que la collaboration d'Illumina de janvier 2025 avec NVIDIA a montré la même poussée vers l'analytique multi-omique à grande échelle. Ces mouvements élèvent la barre concurrentielle car le succès dépend désormais d'un accès combiné au calcul, à des données de haute qualité et à des canaux de déploiement validés.
Les fusions et acquisitions resserrent les frontières sur l'ensemble du marché de l'IA en bioinformatique à mesure que les grandes entreprises de diagnostic et de santé absorbent des capacités d'IA spécialisées. Le même environnement accroît la valeur de la gouvernance, car les fournisseurs dotés d'une meilleure auditabilité et d'un meilleur contrôle des modèles sont mieux positionnés face aux exigences européennes de passation de marchés et de conformité. L'activité de brevets est également en hausse dans les modèles fondamentaux biologiques, les méthodes génomiques tenant compte de l'ascendance et les systèmes fédérés, notamment les travaux PRISM du MIT sur l'intégration de scores polygéniques tenant compte de l'ascendance. Des lacunes commerciales subsistent dans l'apprentissage fédéré pour les tailles d'échantillons de maladies rares, les modèles spécifiques aux populations pour les ascendances non européennes et les outils de soutien à la décision clinique conformes aux exigences GxP, ce qui signifie que le paysage concurrentiel reste actif même si la consolidation s'accélère.
Leaders du Secteur de l'IA en Bioinformatique
Illumina, Inc.
Thermo Fisher Scientific Inc.
QIAGEN N.V.
SOPHiA GENETICS SA
Tempus AI, Inc.
- *Avis de non-responsabilité : les principaux acteurs sont triés sans ordre particulier

Développements Récents du Secteur
- Juin 2026 : Owkin a annoncé une collaboration pluriannuelle avec Sanofi pour co-développer des agents d'IA de nouvelle génération pour la biopharmacie, incluant une licence de cinq ans pour K Pro, la plateforme Scientifique IA d'Owkin. L'accord s'appuie sur un partenariat stratégique antérieur de 90 millions EUR (96 millions USD) couvrant l'identification de cibles en oncologie et le positionnement de médicaments en immunologie, marquant une expansion significative du déploiement d'agents d'IA dans les flux de travail de R&D pharmaceutique.
- Juin 2026 : SOPHiA GENETICS a signé un Protocole d'Accord avec le Memorial Sloan Kettering Cancer Center pour établir une coentreprise combinant l'IA et l'analytique SOPHiA DDM avec le leadership clinique en oncologie de MSK, ciblant le diagnostic d'oncologie de précision de nouvelle génération à l'échelle mondiale.
- Mai 2026 : Roche a conclu un accord de fusion définitif pour acquérir PathAI pour 750 millions USD en amont, plus jusqu'à 300 millions USD en paiements de jalons. La transaction intègre la plateforme de pathologie numérique alimentée par l'IA de PathAI dans Roche Diagnostics, élargissant le développement d'algorithmes de diagnostic compagnon activés par l'IA.
- Mai 2026 : QIAGEN a annoncé une collaboration avec NVIDIA lors de la Conférence Mondiale BIO-IT pour intégrer NVIDIA BioNeMo et GraphRAG accéléré par GPU dans la plateforme de graphe de connaissances biomédicales de QIAGEN Digital Insights, permettant des requêtes en langage naturel sur les gènes, les maladies, les voies métaboliques et les composés pour la découverte de médicaments pilotée par l'IA.


Portée du Rapport Mondial sur le Marché de l'IA en Bioinformatique
Selon la portée du rapport, le marché de l'IA en bioinformatique désigne le secteur axé sur le développement et l'adoption de technologies d'intelligence artificielle, notamment l'apprentissage automatique, l'apprentissage profond et l'IA générative, pour analyser, interpréter et gérer des données biologiques complexes. Ces solutions soutiennent des applications telles que la génomique, la protéomique, la découverte de médicaments, l'identification de biomarqueurs, la prédiction des maladies et la médecine de précision en améliorant la vitesse, la précision et l'évolutivité des flux de travail bioinformatiques.
Le marché de l'IA en bioinformatique est segmenté par offre, technologie, application, utilisateur final et géographie. Par offre, le marché est segmenté en logiciels et services. Par technologie, le marché est segmenté en apprentissage automatique, apprentissage profond, traitement du langage naturel, vision par ordinateur et autres technologies. Par application, le marché est segmenté en découverte et développement de médicaments, diagnostic clinique et médecine de précision, découverte et validation de biomarqueurs, intégration et interprétation de données multi-omiques, modélisation des réseaux biologiques et de la biologie des systèmes, informatique de laboratoire et automatisation des flux de travail, et autres applications. Par utilisateur final, le marché est segmenté en entreprises pharmaceutiques et biotechnologiques, instituts académiques et de recherche, hôpitaux et laboratoires de diagnostic, et autres utilisateurs finaux. Par géographie, le marché est segmenté en Amérique du Nord, Europe, Asie-Pacifique, Moyen-Orient et Afrique, et Amérique du Sud. Le rapport couvre également les tailles de marché estimées et les tendances pour 17 pays dans les principales régions du monde. Le rapport propose des valeurs (USD) pour tous les segments ci-dessus.
| Logiciels |
| Services |
| Apprentissage Automatique |
| Apprentissage Profond |
| Traitement du Langage Naturel |
| Vision par Ordinateur |
| Autres Technologies |
| Découverte et Développement de Médicaments |
| Diagnostic Clinique et Médecine de Précision |
| Découverte et Validation de Biomarqueurs |
| Intégration et Interprétation de Données Multi-Omiques |
| Modélisation des Réseaux Biologiques et de la Biologie des Systèmes |
| Informatique de Laboratoire et Automatisation des Flux de Travail |
| Autres Applications |
| Entreprises Pharmaceutiques et Biotechnologiques |
| Instituts Académiques et de Recherche |
| Hôpitaux et Laboratoires de Diagnostic |
| Autres Utilisateurs Finaux |
| Amérique du Nord | États-Unis |
| Canada | |
| Mexique | |
| Europe | Allemagne |
| Royaume-Uni | |
| France | |
| Italie | |
| Espagne | |
| Reste de l'Europe | |
| Asie-Pacifique | Chine |
| Japon | |
| Inde | |
| Australie | |
| Corée du Sud | |
| Reste de l'Asie-Pacifique | |
| Moyen-Orient et Afrique | GCC |
| Afrique du Sud | |
| Reste du Moyen-Orient et de l'Afrique | |
| Amérique du Sud | Brésil |
| Argentine | |
| Reste de l'Amérique du Sud |
| Par Offre | Logiciels | |
| Services | ||
| Par Technologie | Apprentissage Automatique | |
| Apprentissage Profond | ||
| Traitement du Langage Naturel | ||
| Vision par Ordinateur | ||
| Autres Technologies | ||
| Par Application | Découverte et Développement de Médicaments | |
| Diagnostic Clinique et Médecine de Précision | ||
| Découverte et Validation de Biomarqueurs | ||
| Intégration et Interprétation de Données Multi-Omiques | ||
| Modélisation des Réseaux Biologiques et de la Biologie des Systèmes | ||
| Informatique de Laboratoire et Automatisation des Flux de Travail | ||
| Autres Applications | ||
| Par Utilisateur Final | Entreprises Pharmaceutiques et Biotechnologiques | |
| Instituts Académiques et de Recherche | ||
| Hôpitaux et Laboratoires de Diagnostic | ||
| Autres Utilisateurs Finaux | ||
| Par Géographie | Amérique du Nord | États-Unis |
| Canada | ||
| Mexique | ||
| Europe | Allemagne | |
| Royaume-Uni | ||
| France | ||
| Italie | ||
| Espagne | ||
| Reste de l'Europe | ||
| Asie-Pacifique | Chine | |
| Japon | ||
| Inde | ||
| Australie | ||
| Corée du Sud | ||
| Reste de l'Asie-Pacifique | ||
| Moyen-Orient et Afrique | GCC | |
| Afrique du Sud | ||
| Reste du Moyen-Orient et de l'Afrique | ||
| Amérique du Sud | Brésil | |
| Argentine | ||
| Reste de l'Amérique du Sud | ||


Questions Clés Répondues dans le Rapport
Quelles sont les perspectives 2031 pour l'IA en bioinformatique ?
Le marché de l'IA en bioinformatique devrait atteindre 25,2 milliards USD d'ici 2031, contre 10,32 milliards USD en 2025 et 11,9 milliards USD en 2026, avec une croissance à un CAGR de 16,2 %.
Quel domaine d'application génère le plus de revenus aujourd'hui ?
La découverte et le développement de médicaments dominent avec une part de 43,82 % en 2025, car les dépenses pharmaceutiques restent concentrées dans l'identification de cibles, l'optimisation des leads et l'informatique translationnelle.
Quel segment connaît la croissance la plus rapide ?
La découverte et la validation de biomarqueurs devraient être les applications à la croissance la plus rapide à un CAGR de 17,34 %, tandis que l'Asie-Pacifique devrait être la région à la croissance la plus rapide à un CAGR de 18,43 % jusqu'en 2031.
Pourquoi les entreprises pharmaceutiques et biotechnologiques sont-elles les plus grands acheteurs ?
Les entreprises pharmaceutiques et biotechnologiques détenaient une part de 51,25 % en 2025 car elles peuvent financer l'intégration de plateformes, gérer de grands accords de licence de données et lier directement le déploiement de l'IA à la productivité en R&D.
Dernière mise à jour de la page le:




