Tamaño y Participación del Mercado de Web Scraping
Visión General del Mercado
| Período de Estudio | 2020 - 2031 |
|---|---|
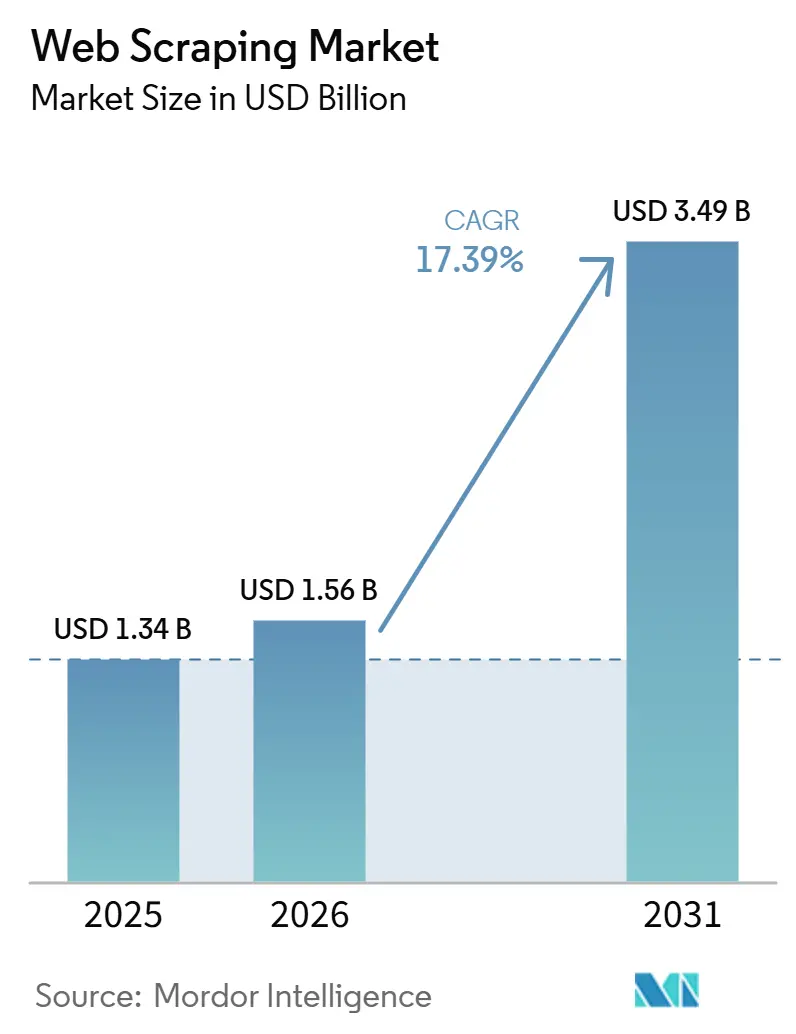
| Tamaño del Mercado (2026) | 1.56 Mil millones de dólares |
| Tamaño del Mercado (2031) | 3.49 Mil millones de dólares |
| Tasa de crecimiento (2026 - 2031) | 17.39% CAGR |
| Mercado de Crecimiento Más Rápido | Asia-Pacífico |
| Mercado Más Grande | América del Norte |
| Concentración del Mercado | Medio |
Jugadores principales *Nota aclaratoria: los principales jugadores no se ordenaron de un modo en especial Imagen © Mordor Intelligence. El uso requiere atribución según CC BY 4.0. | |
Análisis del Mercado de Web Scraping por Mordor Intelligence
El tamaño del mercado de web scraping fue valorado en 1,34 mil millones de USD en 2025 y se estima que crecerá desde 1,56 mil millones de USD en 2026 hasta alcanzar 3,49 mil millones de USD para 2031, a una CAGR del 17,39% durante el período de pronóstico (2026-2031). La sólida demanda proviene de empresas que compiten por reemplazar el acceso reducido a API, preparar modelos de IA generativa y mantenerse al ritmo de las necesidades de inteligencia competitiva en tiempo real. Las guerras de precios en el comercio electrónico, el auge de los datos alternativos en los servicios financieros y la acelerada adopción de la nube crean un flujo constante de cargas de trabajo de extracción de grandes volúmenes. Al mismo tiempo, el escrutinio regulatorio y las sofisticadas defensas anti-bot empujan a los compradores hacia soluciones de mayor valor y listas para el cumplimiento normativo que puedan mantener tasas de éxito bajo restricciones técnicas y legales cada vez más estrictas. Los proveedores capaces de combinar escala, adaptabilidad impulsada por IA y soporte de cumplimiento específico por región están en posición de capturar ingresos desproporcionados a medida que el mercado de web scraping transita de la recolección de datos básica hacia una infraestructura de datos de misión crítica.
Conclusiones Clave del Informe
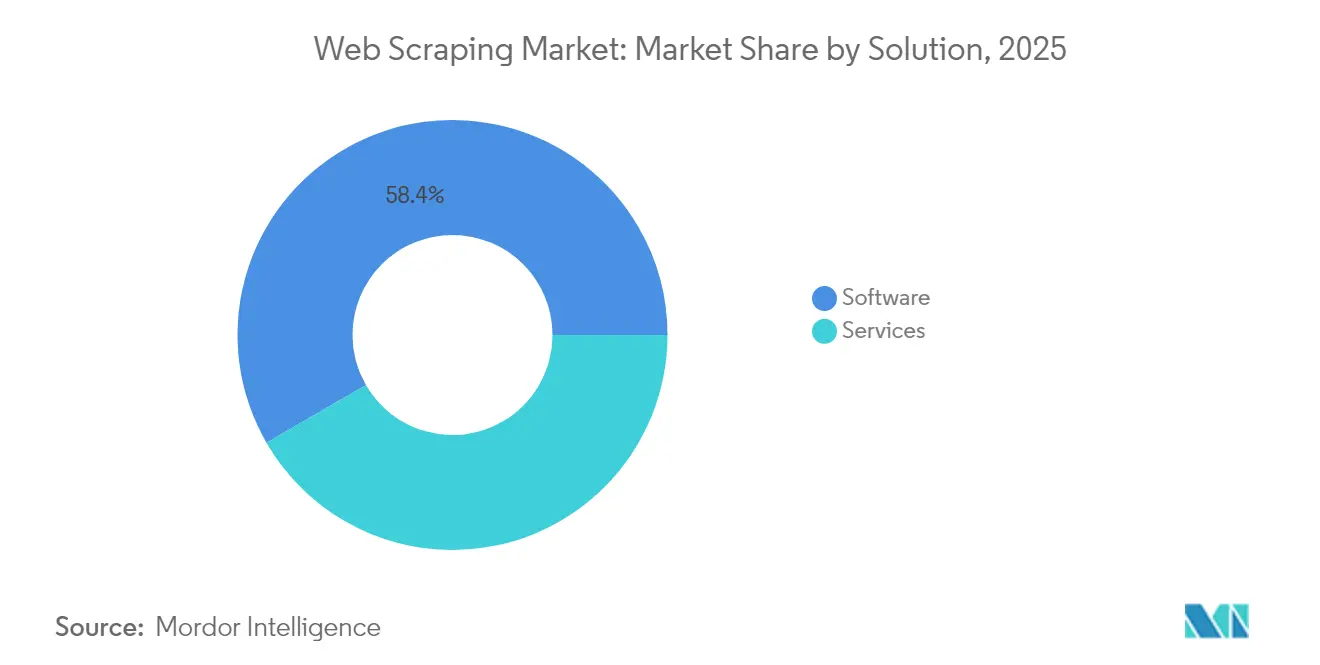
- Por tipo de solución, el software mantuvo una participación de ingresos del 58,35% en 2025, mientras que los servicios proyectan registrar una CAGR del 18,62% hasta 2031.
- Por modo de implementación, los modelos en la nube representaron el 67,45% del tamaño del mercado de web scraping en 2025 y se prevé que se expandan a una CAGR del 17,80%.
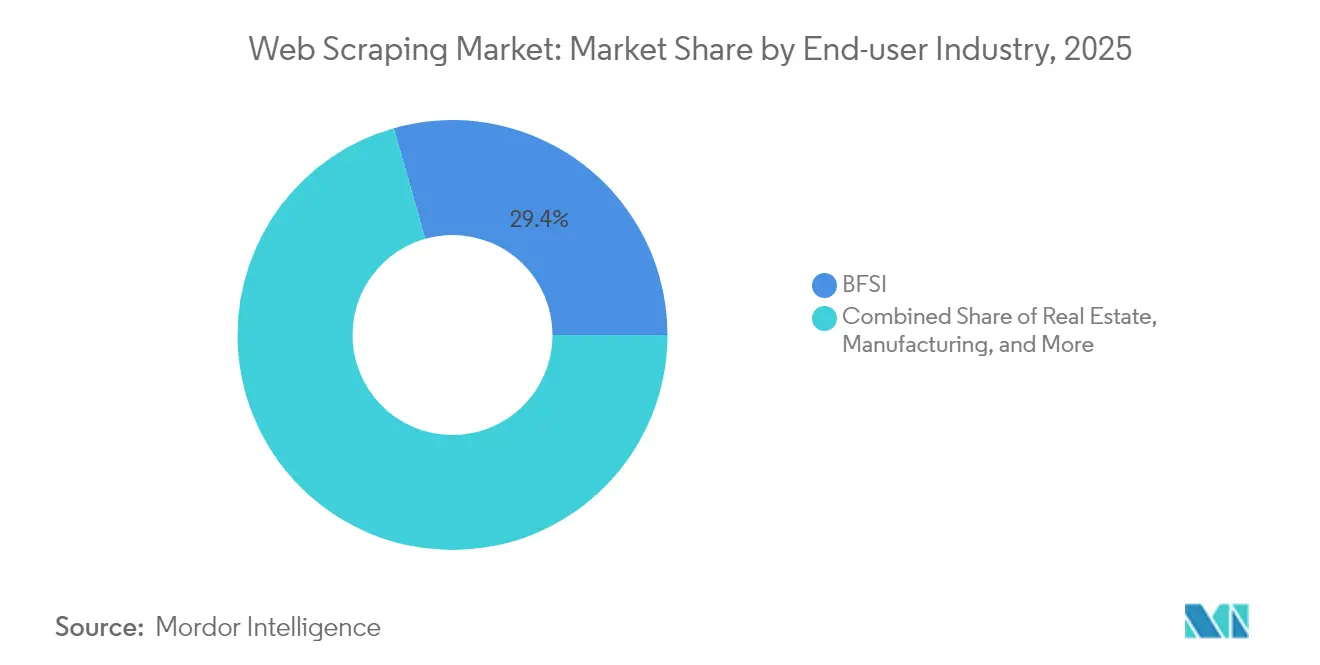
- Por industria de usuario final, Banca, Servicios Financieros y Seguros capturó el 29,40% del tamaño del mercado de web scraping en 2025; Publicidad y Medios avanza a una CAGR del 18,80% hasta 2031.
- Por caso de uso, el scraping de datos y ETL representó el 36,20% del mercado de web scraping en 2025, mientras que el segmento de monitoreo de precios e inteligencia competitiva crece a una CAGR del 18,34%.
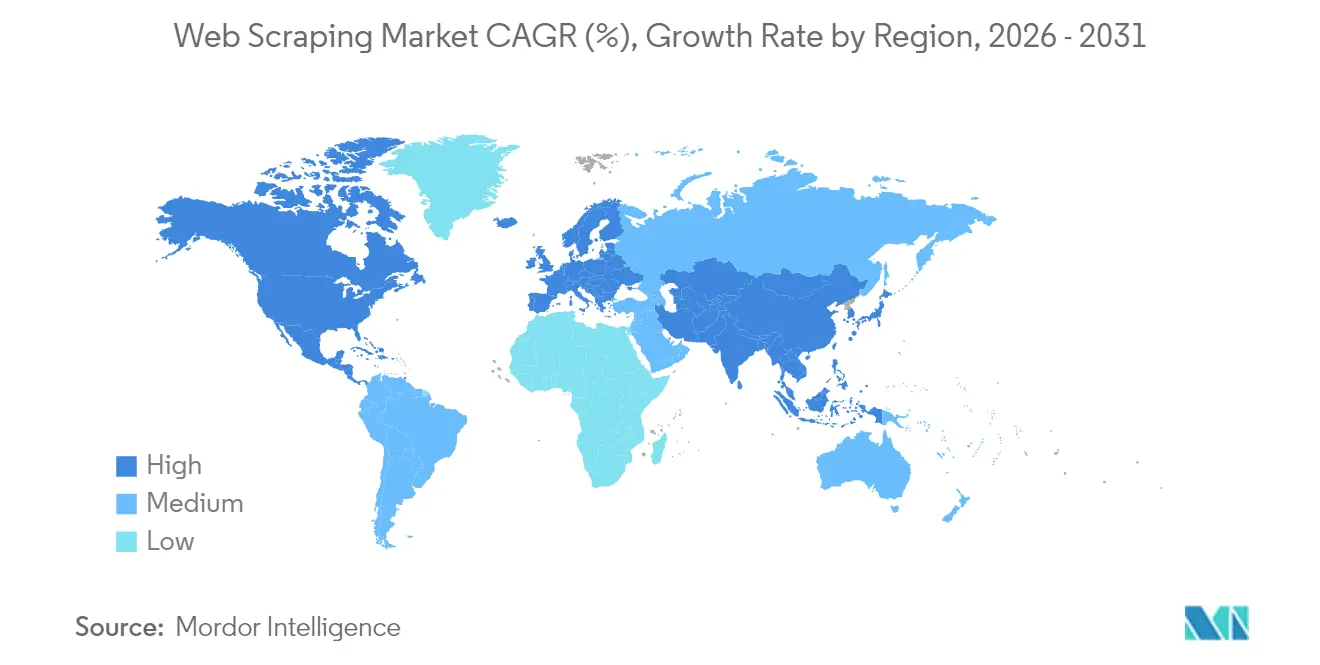
- Por geografía, América del Norte lideró con el 34,08% de la participación del mercado de web scraping en 2025; se pronostica que Asia-Pacífico registrará la CAGR más rápida del 18,66% hasta 2031.
Nota: Las cifras de tamaño del mercado y previsión de este informe se generan utilizando el marco de estimación propietario de Mordor Intelligence, actualizado con los últimos datos e información disponibles a partir de 2026.
Tendencias e Información del Mercado Global de Web Scraping
Análisis del Impacto de los Impulsores*
| Impulsor | (~) % de Impacto en el Pronóstico de CAGR | Relevancia Geográfica | Horizonte Temporal del Impacto |
|---|---|---|---|
| Crecimiento del comercio electrónico y los mercados en línea | +3.2% | Global (concentrado en América del Norte y Asia-Pacífico) | Mediano plazo (2-4 años) |
| Avances en inteligencia artificial y aprendizaje automático para la extracción de datos | +2.8% | Global (América del Norte y Europa lideran) | Largo plazo (≥ 4 años) |
| Demanda creciente de datos alternativos en finanzas | +2.1% | América del Norte, Europa, Asia-Pacífico en expansión | Mediano plazo (2-4 años) |
| Depreciación de API en plataformas principales | +1.9% | Global (redes sociales y plataformas de contenido más afectadas) | Corto plazo (≤ 2 años) |
| Requisitos de datos de entrenamiento para inteligencia artificial generativa | +1.7% | Global (centros de desarrollo de inteligencia artificial) | Largo plazo (≥ 4 años) |
| Mandatos de datos abiertos que revelan brechas de datos | +0.8% | Europa y América del Norte | Mediano plazo (2-4 años) |
| Fuente: Mordor Intelligence | |||
Crecimiento del comercio electrónico y los mercados en línea
Las guerras de precios en tiempo real han impulsado al 81% de los minoristas de Estados Unidos hacia el raspado automatizado de precios para estrategias de reajuste dinámico, frente al 34% en 2020 [1]Actowiz Solutions, "Estadísticas de Adopción de Raspado de Precios Minoristas 2025," actowiz.com. Los formatos de mercado ahora permean bienes raíces, comestibles y listados automotrices, cada uno exigiendo visibilidad de inventario a nivel de milisegundos. La escalada de la mitigación de bots en sitios minoristas paradójicamente impulsa la demanda premium de raspadores resilientes que eluden la toma de huellas digitales de dispositivos y los desafíos de JavaScript. Los modelos de comercio rápido y ventas flash amplían aún más la oportunidad direccionable a medida que los comerciantes pivotan hacia promociones basadas en datos en mercados regionales.
Avances en inteligencia artificial y aprendizaje automático para la extracción de datos
El sesenta y cinco por ciento de las empresas utilizaron web scraping para alimentar proyectos de inteligencia artificial y aprendizaje automático en 2024, lo que señala un cambio de scripts basados en reglas a algoritmos adaptativos que reducen la sobrecarga de mantenimiento en un 40% [2]BrowserCat, "Encuesta de Inteligencia Artificial y Web Scraping 2024," browsercat.com. La imitación conductual impulsada por inteligencia artificial eleva las tasas de éxito al 80-95% en sitios fuertemente protegidos, mientras que la detección dinámica de plantillas reduce el tiempo de inactividad cuando cambian los diseños de página. Los proveedores que incorporan aprendizaje por refuerzo y huellas digitales sintéticas de navegador han convertido la extracción inteligente en un diferenciador premium en lugar de un producto básico.
Demanda creciente de datos alternativos en finanzas
El web scraping sustenta el 67% de los programas de datos alternativos de los asesores de inversión de Estados Unidos, una cifra que aumentó 20 puntos porcentuales durante 2024. La recolección en tiempo real de noticias, presentaciones y señales de sentimiento alimenta los escritorios de negociación algorítmica y los motores de riesgo crediticio. Los presupuestos boyantes —el 94% de los usuarios planea aumentar el gasto— señalan un flujo de ingresos duradero para los proveedores que combinan canalizaciones limpias con registros de auditoría exigidos por reguladores y asignadores de fondos.
Depreciación de API en plataformas principales
Las redes sociales y los editores de contenido continúan elevando muros de pago alrededor de las interfaces programáticas, convirtiendo el HTML raspado y la representación dinámica en el camino económico hacia la cobertura de datos a escala. Twitter, Reddit y otros servicios eliminaron los niveles de acceso gratuito, impulsando a las empresas a redirigir el gasto hacia navegadores sin interfaz gráfica y flotas de proxies distribuidos. El modelo de pago por acceso de Cloudflare para bots de inteligencia artificial subraya un pivote más amplio hacia la monetización de puntos de acceso a datos, inclinando la economía decisivamente a favor de soluciones sofisticadas del mercado de web scraping.
Análisis del Impacto de las Restricciones*
| Restricción | (~) % de Impacto en el Pronóstico de CAGR | Relevancia Geográfica | Horizonte Temporal del Impacto |
|---|---|---|---|
| Incertidumbre legal y ética | -2.3% | Global (más estricta en Europa) | Mediano plazo (2-4 años) |
| Altos costos y complejidad técnica | -1.8% | Global (las pymes son las más afectadas) | Corto plazo (≤ 2 años) |
| Herramientas avanzadas de mitigación de bots | -1.5% | Global (enfoque en grandes plataformas) | Corto plazo (≤ 2 años) |
| Las API oficiales canibalizan algunos casos de uso | -0.9% | Global (variable por sector) | Mediano plazo (2-4 años) |
| Fuente: Mordor Intelligence | |||
Incertidumbre legal y ética
La estricta visión de la autoridad neerlandesa de protección de datos sobre el RGPD en relación con el raspado de datos personales para el entrenamiento de inteligencia artificial y la orientación de 2024 de la Asamblea Global de Privacidad requieren base legal, transparencia y retención minimizada, elevando el gasto en cumplimiento en un 86%. La multa de EUR 20 millones de Italia contra un proveedor de reconocimiento facial señala un alto riesgo a la baja, mientras que el Departamento de Justicia de Estados Unidos ahora prohíbe a entidades de países de interés acceder a datos personales sensibles, añadiendo capas de escrutinio geopolítico. Navegar estas restricciones transfronterizas retrasa los proyectos y eleva los costos de revisión legal.
Altos costos y complejidad técnica
Akamai informa que su suite de gestión de bots puede bloquear el 82,3% del tráfico automatizado en páginas de productos seleccionadas, obligando a los raspadores a invertir en grupos de proxies más grandes, granjas de navegadores personalizados y pilas de evasión con inteligencia artificial. Las pymes que carecen de capital luchan por igualar la carrera armamentista, cediendo a menudo las demandas de datos de nicho a proveedores de servicios bien financiados. Los desafíos de JavaScript de múltiples capas y los CAPTCHA adaptativos inflan los presupuestos de cómputo y prolongan los ciclos de extracción, erosionando el retorno de la inversión para las operaciones menos optimizadas.
*Nuestras previsiones consideran los impactos de impulsores y restricciones como direccionales, no aditivos. Las previsiones de impacto reflejan el crecimiento base, los efectos de mezcla y las interacciones entre variables.
Análisis de Segmentos
Por Solución: Los Servicios Ganan Impulso Mientras el Software Mantiene la Escala
Los productos de software mantuvieron el 58,35% de los ingresos en 2025, lo que subraya la comodidad empresarial con los marcos de orquestación internos y los extractores sin código. Sin embargo, los servicios avanzan a una CAGR del 18,62% a medida que los compradores externalizan verificaciones de cumplimiento complejas, mantenimiento de proxies rotativos y ajuste anti-bot. Los patrones de gasto muestran un cambio hacia la adopción híbrida, donde los equipos internos ejecutan software empaquetado para listas cotidianas mientras que empresas especializadas abordan conjuntos de datos transfronterizos o legalmente sensibles. La normalización y validación de datos habilitada por IA eleva las tarifas facturables para los proveedores de servicio completo, reforzando la lealtad y el margen. Esta dinámica garantiza que el mercado de web scraping permanezca equilibrado entre kits de herramientas y ofertas gestionadas, atendiendo tanto a analistas que prefieren hacerlo por su cuenta como a corporaciones con aversión al riesgo.
La categoría de software se ha beneficiado de una ola de lanzamientos de código abierto y bajo código, entre ellos Thunderbit y Crawlee para Python, que reducen las barreras de entrada para los analistas de negocio. Sin embargo, los equipos de seguridad empresarial exigen cada vez más auditorías externas y aprobaciones legales, lo que empuja a muchos hacia suscripciones de servicios agrupadas con artefactos de cumplimiento documentados. En consecuencia, el tamaño del mercado de web scraping para servicios está destinado a crecer de manera significativa, reduciendo la brecha de ingresos con el software para 2031.



Por Modo de Implementación: La Infraestructura en la Nube Acelera la Adopción
Las implementaciones basadas en la nube capturaron el 67,45% del mercado de web scraping en 2025 y superarán a otros modos a una CAGR del 17,80%. Los grupos de cómputo elástico distribuyen navegadores sin interfaz gráfica en puntos de presencia globales, lo cual es crucial cuando las páginas sirven contenido específico por región o bloquean direcciones IP repetitivas. Proveedores como Oxylabs ahora empaquetan proxies residenciales rotativos, gestión de sesiones y monitoreo de cumplimiento normativo como API de lanzamiento con un clic. Esta abstracción permite a los clientes escalar miles de solicitudes paralelas sin aprovisionar servidores físicos.
Las implementaciones en las instalaciones del cliente persisten en sectores altamente regulados, particularmente en salud y banca central, donde las cláusulas de soberanía de datos exigen almacenamiento local. Incluso dentro de estos sectores, los scrapers en contenedores se expanden cada vez más hacia regiones de nube pública autorizadas durante picos de tráfico. De cara al futuro, los complementos de computación en el borde que procesan HTML sin procesar más cerca del punto de recolección están en posición de reducir la latencia para actualizaciones de subastas o tarifas de vuelos, reforzando el papel central de la nube en el mercado de web scraping.
Por Industria de Usuario Final: Los Servicios Financieros Anclan la Demanda, los Medios Surgen
Banca, Servicios Financieros y Seguros retuvo el 29,40% del tamaño del mercado de web scraping en 2025, ya que fondos, prestamistas y aseguradoras alimentaron algoritmos de riesgo crediticio y negociación con noticias extraídas, datos de publicaciones de empleo y sentimiento del consumidor. Los estrictos requisitos de auditoría favorecen a los proveedores que incorporan seguimiento de linaje de datos y alertas regulatorias. Publicidad y Medios, aunque más pequeño hoy en día, registra la CAGR más rápida del 18,80%. Las agencias anhelan feeds unificados de rendimiento de campañas, precios de editores y señales de seguridad de marca entregados en tiempo casi real. Las narrativas orientadas a inversores de la industria de web scraping destacan cada vez más estos dos sectores verticales como pilares gemelos: uno ofrece bolsillos profundos y gasto recurrente, el otro suministra volúmenes de contenido no estructurado de rápido crecimiento.
El comercio minorista y el comercio electrónico siguen siendo esenciales, pero ahora son usuarios maduros. El crecimiento proviene menos de compradores primerizos y más de casos de uso avanzados: coincidencia dinámica de cupones, monitoreo de franjas horarias de entrega y seguimiento competitivo hiperlocal. Los organismos de manufactura, salud y sector público amplían colectivamente la base direccionable al superponer vigilancia de cadena de suministro, feeds de buscadores de ensayos clínicos y proyectos de datos abiertos mandatados por la gobernanza sobre las instalaciones existentes.
Por Caso de Uso: ETL Domina, el Monitoreo de Precios Escala Más Rápido
Las cargas de trabajo de scraping de datos y ETL representaron el 36,20% del tamaño del mercado de web scraping en 2025, consolidando su papel como integradores de back-office que alimentan almacenes de datos, centros de gestión de datos maestros y lakehouses. Estas canalizaciones típicamente incluyen rastreos programados en miles de dominios, lógica de diferencias incrementales y mapeo automatizado de esquemas. Sin embargo, la extracción de precios e inteligencia competitiva avanza a una CAGR del 18,34%, impulsada por repreciadores algorítmicos y motores de promoción basados en IA que actualizan catálogos cada hora o con mayor frecuencia. Los equipos de datos financieros aprovechan múltiples grupos de casos de uso —noticias, presentaciones regulatorias y sentimiento— difuminando las líneas entre los datos alternativos puros y los feeds de referencia tradicionales. En conjunto, estos patrones garantizan que el mercado de web scraping continúe diversificándose mucho más allá de la recolección básica de URL.
Los scrapes de generación de leads, la escucha en redes sociales y la investigación de ESG completan la demanda. Cada uno añade solicitudes de funciones únicas —integraciones con CRM, detección de idioma o modelado de temas—, lo que empuja a los proveedores hacia arquitecturas modulares. Como resultado, el mercado de web scraping sigue siendo intensivo en innovación, con hojas de ruta de productos guiadas por brechas de flujo de trabajo específicas de cada sector vertical.
Análisis Geográfico
América del Norte controló el 34,08% de los ingresos en 2025, respaldada por la profunda presencia de los servicios financieros de Estados Unidos y los centros de análisis de rápido crecimiento de Canadá. Los compradores regionales otorgan un valor premium al cumplimiento normativo documentado, evidenciado por el 67% de los asesores que incorporan flujos de datos alternativos en los procesos de inversión. Las nuevas normas del Departamento de Justicia de Estados Unidos que restringen los flujos de datos sensibles hacia adversarios extranjeros añaden capas de diligencia debida, pero simultáneamente amplían las oportunidades para las oficinas de servicios domésticos especializadas en la ingestión transfronteriza legal.
Asia-Pacífico es el territorio de más rápido crecimiento, avanzando a una CAGR del 18,66% hasta 2031. Los exportadores manufactureros de China dependen de feeds de scraping de aduanas y envíos para calibrar precios, mientras que los líderes de servicios de TI de India incorporan la adquisición de datos a gran escala en contratos de externalización de análisis. Los programas de transformación digital corporativa de Japón impulsan la demanda local de marcos de extracción multilingüe. Los mercados del Sudeste Asiático aceleran la adopción a medida que las súper-aplicaciones de logística, viajes y fintech libran batallas de precios en tiempo real. Australia y Nueva Zelanda completan el impulso regional a través de mesas de negociación de materias primas que rastrean rastreadores de escalas portuarias y satélites.
Europa sigue una trayectoria de cumplimiento normativo en primer lugar. La postura restrictiva del Comité Europeo de Protección de Datos sobre los datos de entrenamiento de IA obliga a flujos de trabajo evaluados por riesgo y canalizaciones de privacidad por diseño. Los proveedores que incorporan controles de anonimización, gestión del consentimiento y minimización de datos disfrutan de una ventaja competitiva. Los compradores del Reino Unido equilibran la alineación con el RGPD con un creciente apetito por datos alternativos de fintech, mientras que Alemania y Francia favorecen las construcciones de nube soberana para extracciones críticas. La heterogeneidad regulatoria en todo el continente sostiene la demanda de servicios consultivos que localizan marcos caso por caso.

Panorama Competitivo
El mercado de web scraping sigue siendo moderadamente fragmentado. Bright Data, Zyte, Apify y Oxylabs forman un nivel de especialistas en infraestructura a escala, aunque ninguno controla una participación dominante. La competencia está pasando de la recolección bruta hacia la calidad, el tiempo de actividad y el cumplimiento. Los proveedores se diferencian en las tasas de éxito frente a las suites anti-bot, la amplitud de los grupos de proxies y la orientación legal específica por región. La orquestación con inteligencia artificial —reintentos adaptativos, descubrimiento de selectores CSS impulsado por modelos y etiquetado automático— se ha convertido en un requisito básico.
El posicionamiento estratégico revela dos campos. Las plataformas horizontales atraen a todos los sectores con API de fácil implementación, mientras que los actores de nicho apuntan a una experiencia profunda en dominios únicos como tarifas de viajes o clasificaciones de tiendas de aplicaciones. El mercado de pago por bot de Cloudflare sugiere que los operadores de plataformas podrían pronto monetizar feeds de datos directos, convirtiendo potencialmente a antiguos adversarios en socios de canal. Los proveedores capaces de pivotar temprano hacia modelos de participación en ingresos o puntos de acceso de primera parte curados protegerán sus márgenes.
Los flujos de inversión favorecen la tecnología avanzada de evasión. Las empresas emergentes especializadas en enmascaramiento de navegadores sin interfaz gráfica, rotación dinámica de huellas digitales y resolución de CAPTCHA en el dispositivo atraen capital de riesgo, anticipando una creciente sofisticación en el bloqueo de tráfico. En respuesta, los actores establecidos adquieren soluciones puntuales para acelerar las hojas de ruta de inteligencia artificial e incorporar monitores de cumplimiento en tiempo real. A lo largo del horizonte de pronóstico, se espera que los líderes del mercado consoliden redes de proxies más pequeñas y boutiques de cumplimiento regional para reforzar la cobertura geográfica y la profundidad regulatoria.
Líderes de la Industria de Web Scraping
Bright Data Ltd.
Zyte Group Ltd.
Apify Technologies s.r.o.
Octopus Data, Inc.
Import.io Ltd.
- *Nota aclaratoria: los principales jugadores no se ordenaron de un modo en especial

Desarrollos Recientes de la Industria
- Enero de 2025: El Departamento de Justicia de Estados Unidos implementó reglas integrales de protección de datos que impiden el acceso a datos personales sensibles por parte de países de interés, reformando los flujos de trabajo de extracción transfronteriza.
- Enero de 2025: El Departamento de Salud y Servicios Humanos de Estados Unidos publicó su plan estratégico de inteligencia artificial, dirigiendo nuevos fondos hacia la investigación médica basada en datos que depende de la recolección automatizada.
- Octubre de 2024: Cloudflare presentó un mercado que permite a los editores cobrar a los bots de inteligencia artificial por el acceso de raspado, reformulando la economía de monetización de datos.
- Julio de 2024: Apify lanzó Crawlee para Python, extendiendo su marco de rastreo de código abierto a los desarrolladores de Python y ampliando el ecosistema de colaboradores.


Research Methodology Framework and Report Scope
Definiciones del Mercado y Cobertura Clave
Nuestro estudio define el mercado de web scraping como todas las plataformas de software comercial y los servicios de extracción gestionados que rastrean programáticamente páginas web públicas, analizan contenido y entregan conjuntos de datos estructurados o feeds en vivo a clientes de pago. La valoración cubre los ingresos por licencias, suscripciones y servicios generados por proveedores especializados en la recolección de datos a gran escala y lista para el cumplimiento normativo.
Exclusión del alcance: Los scripts internos de elaboración propia ejecutados únicamente dentro de una empresa no se contabilizan.
Descripción General de la Segmentación
- Por Solución
- Software
- Servicios
- Por Modo de Implementación
- Nube
- Local
- Por Industria de Usuario Final
- Banca, Servicios Financieros y Seguros
- Comercio Minorista y Comercio Electrónico
- Bienes Raíces
- Manufactura
- Gobierno
- Salud
- Publicidad y Medios
- Otros
- Por Caso de Uso
- Extracción de Datos / ETL
- Monitoreo de Precios y Competencia
- Generación de Prospectos e Inteligencia de Ventas
- Datos Financieros Alternativos
- Análisis de Sentimiento y Redes Sociales
- Por Geografía
- América del Norte
- Estados Unidos
- Canadá
- México
- América del Sur
- Brasil
- Argentina
- Resto de América del Sur
- Europa
- Alemania
- Reino Unido
- Francia
- Italia
- España
- Rusia
- Resto de Europa
- Asia-Pacífico
- China
- Japón
- India
- Corea del Sur
- Australia y Nueva Zelanda
- Resto de Asia-Pacífico
- Oriente Medio y África
- Oriente Medio
- Arabia Saudita
- Emiratos Árabes Unidos
- Turquía
- Resto de Oriente Medio
- África
- Sudáfrica
- Nigeria
- Kenia
- Resto de África
- Oriente Medio
- América del Norte
Metodología de Investigación Detallada y Validación de Datos
Investigación Primaria
Las entrevistas estructuradas con responsables de productos de plataformas de datos, proveedores de redes de proxies y responsables de adquisiciones en América del Norte, Europa y Asia-Pacífico proporcionaron bandas de precios del mundo real, tasas de retención y costos de cumplimiento regional que las fuentes de escritorio rara vez revelan.
Investigación de Escritorio
Los analistas de Mordor primero mapearon el universo de proveedores utilizando presentaciones públicas de empresas, formularios 10-K de la Comisión de Bolsa y Valores, y registros de proveedores de tecnología como la Oficina de Patentes de Estados Unidos y los feeds de patentes de Questel. Luego extrajeron señales de uso y gasto de grupos comerciales como el Interactive Advertising Bureau, asociaciones regionales de comercio electrónico y registros de envíos de aduanas para hardware de servidores, que actúan como indicadores adelantados de la capacidad de rastreo. Los artículos académicos indexados en IEEE Xplore aclararon las curvas de adopción técnica, mientras que los flujos de noticias agregados en Dow Jones Factiva ayudaron a cronometrar los eventos materiales que mueven los ingresos. (Las fuentes enumeradas ilustran el tipo utilizado y no son exhaustivas.)
Dimensionamiento del Mercado y Pronóstico
Un modelo descendente comienza con el gasto global en tecnología de la información para la adquisición de datos, aísla la participación atribuible a los feeds de datos web externos y se filtra adicionalmente a través de la penetración de adopción por sectores como el comercio electrónico y la banca, los servicios financieros y los seguros. Las verificaciones ascendentes seleccionadas, el precio de venta promedio de proveedores muestreados y los recuentos de clientes activos, validan los totales. Las variables clave rastreadas incluyen la inflación del precio de los proxies, las tasas de éxito anti-bot, el promedio de páginas rastreadas por trabajo, la frecuencia de depreciación de API y las multas de estilo RGPD regionales. Los pronósticos utilizan regresión multivariante respaldada por consenso de expertos para proyectar cómo esos impulsores dan forma al volumen y los precios hasta 2030.
Validación de Datos y Ciclo de Actualización
Los resultados pasan por controles de varianza frente a los flujos de inversión en datos alternativos y las estadísticas de ancho de banda en la nube antes de que un analista senior los apruebe. El modelo se actualiza anualmente, con actualizaciones a mitad de ciclo desencadenadas por fallos legales materiales o cambios tecnológicos; se completa una revisión final justo antes del lanzamiento del informe.
Por Qué la Línea de Base de Web Scraping de Mordor Merece Confianza
Las estimaciones publicadas a menudo divergen porque las empresas segmentan el mercado de manera diferente, convierten divisas en fechas variadas o agrupan segmentos adyacentes en un solo conjunto.
Los principales factores de brecha incluyen si se contabilizan los ingresos por servicios, cómo se manejan las implementaciones de código abierto y la cadencia con la que se actualizan los supuestos de precio de venta promedio. Los estudios externos sitúan el mercado de 2025 en cualquier punto entre USD 0,78 mil millones y 0,81 mil millones para alcances exclusivos de software. Algunos estudios amplios agrupan múltiples mercados adyacentes y publican una cifra de USD 6,77 mil millones para 2024.
Comparación de Referencia
| Tamaño del Mercado | Fuente anonimizada | Principal factor de brecha |
|---|---|---|
| USD 1,03 mil millones (2025) | ||
| USD 0,78 mil millones (2025) | Consultora Regional A | Cuenta solo software, excluye servicios gestionados |
| USD 0,81 mil millones (2025) | Revista Especializada B | Conjunto reducido de proveedores, sin normalización de divisas |
| USD 6,77 mil millones (2024) | Asociación de la Industria C | Agrega software, servicios e ingresos de mercados de datos adyacentes |
Estos contrastes muestran que cuando el alcance y la cadencia de actualización difieren, los resultados varían ampliamente. Las reglas de inclusión equilibradas de Mordor, el modelado de doble vía y las actualizaciones anuales brindan a los tomadores de decisiones una línea de base transparente y repetible que se alinea estrechamente con las señales de gasto observables y los ingresos verificables de los proveedores.


Preguntas Clave Respondidas en el Informe
¿Cuál es el tamaño actual del mercado de web scraping?
El mercado de web scraping se sitúa en 1,56 mil millones de USD en 2026 y se prevé que alcance los 3,49 mil millones de USD para 2031, creciendo a una CAGR del 17,39%.
¿Qué región lidera el mercado de web scraping?
América del Norte ostenta la mayor participación de ingresos del 34,08% gracias a la madura adopción de los servicios financieros y a una sólida infraestructura en la nube.
¿Por qué los servicios crecen más rápido que el software en el web scraping?
Las empresas externalizan cada vez más los complejos desafíos de cumplimiento normativo y anti-bot, lo que impulsa el segmento de servicios a una CAGR del 18,62% a pesar de que el software retiene mayores ingresos absolutos.
¿Cuál es el caso de uso de más rápida expansión?
El monitoreo de precios e inteligencia competitiva crece a una CAGR del 18,34% a medida que los minoristas y las plataformas digitales dependen de los datos de la competencia en tiempo real para estrategias de precios dinámicos.
¿Cómo afectan las regulaciones a los proyectos de web scraping?
Nuevas normas como las restricciones de datos sensibles del Departamento de Justicia de Estados Unidos y las interpretaciones más estrictas del RGPD en Europa incrementan la carga legal, impulsando la demanda de soluciones de extracción gestionadas y conformes con la normativa.
¿Cómo afectan las regulaciones a los proyectos de web scraping?
Nuevas reglas como las restricciones de datos sensibles del Departamento de Justicia de Estados Unidos y las interpretaciones más estrictas del RGPD en Europa elevan la carga legal, impulsando la demanda de soluciones de extracción gestionadas y conformes.
Última actualización de la página el:




