Tamaño y Participación del Mercado de Hadoop en Estados Unidos
Visión General del Mercado
| Período de Estudio | 2019 - 2030 |
|---|---|
| Período de Datos Pronosticados | 2025 - 2030 |
| Período de Datos Históricos | 2019 - 2023 |
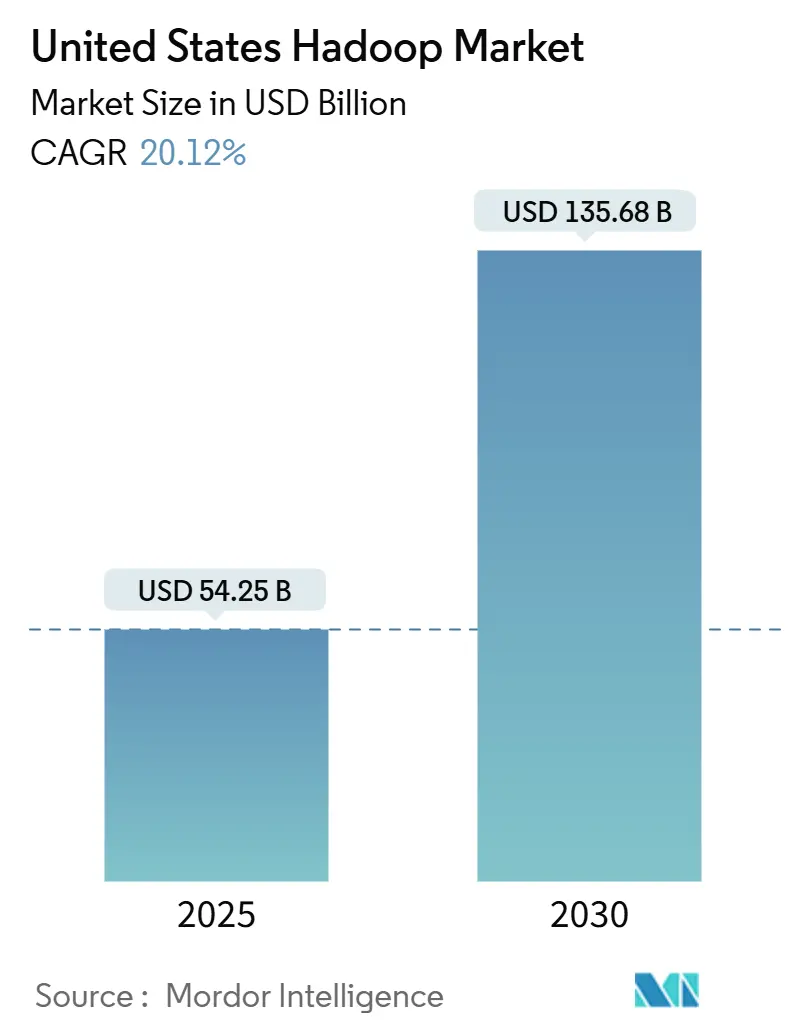
| Tamaño del Mercado (2025) | 54.25 Mil millones de dólares |
| Tamaño del Mercado (2030) | 135.68 Mil millones de dólares |
| Tasa de crecimiento (2025 - 2030) | 20.12% CAGR |
| Concentración del Mercado | Medio |
Jugadores principales *Nota aclaratoria: los principales jugadores no se ordenaron de un modo en especial Imagen © Mordor Intelligence. El uso requiere atribución según CC BY 4.0. | |
Análisis del Mercado de Hadoop en Estados Unidos por Mordor Intelligence
El tamaño del mercado de Hadoop en Estados Unidos se sitúa en USD 54,25 mil millones en 2025 y se proyecta que alcance los USD 135,68 mil millones en 2030, lo que se traduce en una sólida CAGR del 20,12% durante el horizonte de pronóstico. El aumento vertiginoso de los volúmenes de datos, los agresivos programas de transformación digital y la transición desde los almacenes de datos heredados posicionan al mercado de Hadoop en Estados Unidos como una infraestructura indispensable para el análisis de datos a escala empresarial. Los componentes de software siguen siendo centrales, aunque los servicios entregados en la nube están captando presupuesto a medida que las organizaciones buscan clústeres gestionados que escalen bajo demanda. A nivel regional, el Sur concentra el mayor volumen de gasto, mientras que el Oeste acelera con mayor rapidez, reflejando el efecto multiplicador de innovación de Silicon Valley. La rivalidad competitiva se mantiene intensa, ya que los actores establecidos defienden su participación frente a los hiperescaladores de nube y los nuevos participantes del modelo lakehouse que prometen una gestión simplificada y mayor velocidad de consulta.
Conclusiones Clave del Informe
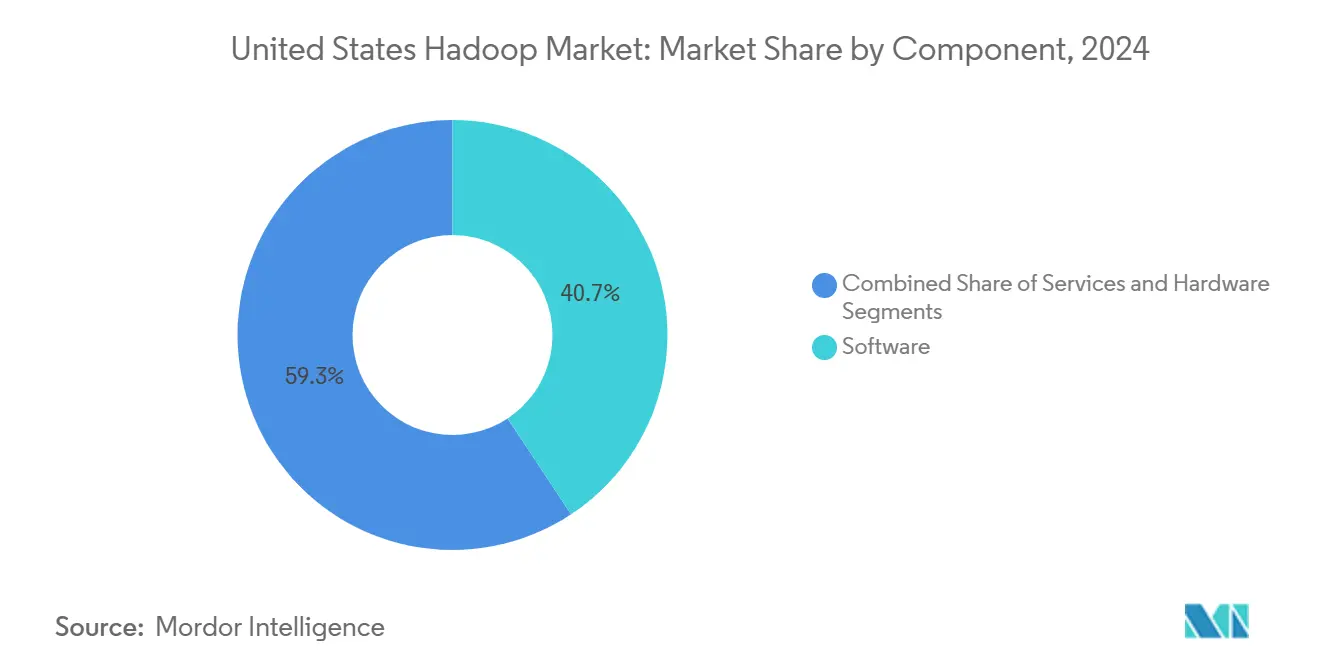
- Por componente, el software representó el 40,7% de la participación del mercado de Hadoop en Estados Unidos en 2024, mientras que los servicios avanzan a una CAGR del 20,92% hasta 2030.
- Por modelo de implementación, las soluciones locales representaron el 52,8% del tamaño del mercado de Hadoop en Estados Unidos en 2024; las implementaciones en la nube se expanden a una CAGR del 21,3% hasta 2030.
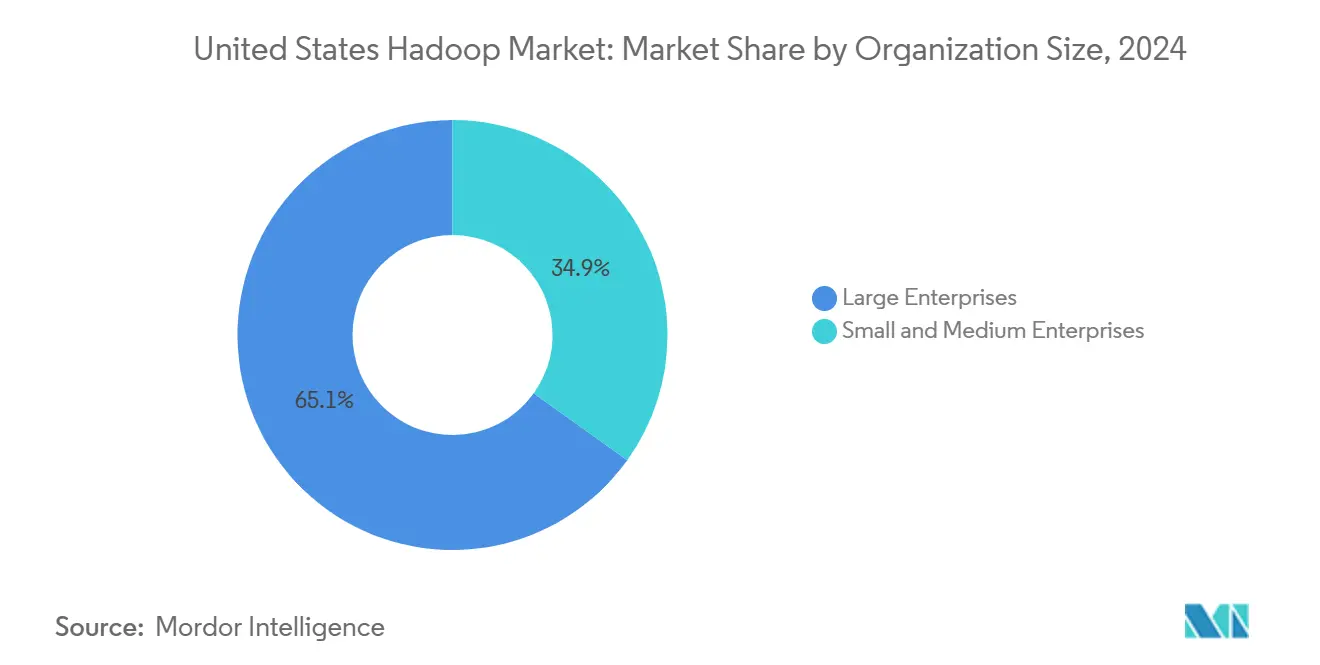
- Por tamaño de organización, las grandes empresas representaron una participación dominante del 65,1% del mercado de Hadoop en Estados Unidos en 2024, mientras que se prevé que las pymes registren una CAGR del 20,7% hasta 2030.
- Por industria de usuario final, el sector de tecnología de la información y telecomunicaciones controló el 30,02% del gasto en 2024 del mercado de Hadoop en Estados Unidos, mientras que se proyecta que la atención médica y las ciencias de la vida crezcan a una CAGR del 22,3% hasta 2030.
- Por región, el Sur lideró con una contribución de ingresos del 38,31% del mercado de Hadoop en Estados Unidos en 2024; el Oeste marca el ritmo del sector con una CAGR del 21,5% durante el período de perspectiva.
Tendencias e Información del Mercado de Hadoop en Estados Unidos
Análisis del Impacto de los Impulsores*
| Impulsor | (~) % de Impacto en el Pronóstico de CAGR | Relevancia Geográfica | Horizonte Temporal del Impacto |
|---|---|---|---|
| Explosión de los volúmenes de datos empresariales y necesidad de procesamiento escalable | +4.2% | Nacional, con concentración en las regiones Sur y Oeste | Largo plazo (≥ 4 años) |
| Transición hacia modelos de Hadoop como Servicio basados en la nube | +3.8% | Nacional, con adopción temprana en el Oeste y el Noreste | Mediano plazo (2-4 años) |
| Ventajas de costos frente a las soluciones tradicionales de almacén de datos empresariales | +2.9% | Nacional, particularmente en el segmento de pymes sensibles al costo | Mediano plazo (2-4 años) |
| Integración de cargas de trabajo de inteligencia artificial y aprendizaje automático en ecosistemas Hadoop | +3.5% | Centros tecnológicos del Oeste y el Noreste | Largo plazo (≥ 4 años) |
| Creciente demanda de análisis de cumplimiento normativo en industrias reguladas | +2.1% | Nacional, con énfasis en los sectores BFSI y de atención médica | Mediano plazo (2-4 años) |
| Ingesta de datos de dispositivos periféricos e IoT que impulsa el análisis Hadoop en tiempo casi real | +1.8% | Regiones manufactureras del Medio Oeste y el Sur | Largo plazo (≥ 4 años) |
| Fuente: Mordor Intelligence | |||
La Explosión de los Volúmenes de Datos Empresariales Requiere un Procesamiento Escalable
Los canales digitales, los sensores de IoT y los estrictos mandatos de mantenimiento de registros están incrementando los almacenes de datos a escala de petabytes, superando el rendimiento de los almacenes convencionales. Una encuesta de IBM reveló que el 73% de las empresas estadounidenses registraron un crecimiento anual de datos superior al 40%.[1]IBM, "Encuesta de Gestión de Datos Empresariales 2024," ibm.com El sistema de archivos distribuido y las capacidades de computación paralelizada de Hadoop permiten a las empresas mantenerse al día sin reescribir esquemas ni rediseñar el hardware. La capacidad de agregar linealmente nodos de hardware estándar transforma la planificación de capacidad de una apuesta de gasto de capital en un ejercicio incremental. A medida que los dispositivos periféricos alimentan telemetría adicional, los clústeres Hadoop centralizados se convierten en el agregador preferido para el análisis posterior, el mantenimiento predictivo y la detección de anomalías. Las empresas tratan ahora el procesamiento escalable no como una experimentación opcional, sino como un pilar fundamental de la continuidad del negocio y la agilidad competitiva.
Los Modelos de Hadoop como Servicio Basados en la Nube Democratizan la Adopción de Big Data
Los servicios gestionados como Amazon EMR y Azure HDInsight reducen la barrera operativa al abstraer el aprovisionamiento de clústeres, la aplicación de parches y el refuerzo de la seguridad. AWS introdujo EMR sin servidor en 2024, permitiendo que las cargas de trabajo escalen automáticamente y facturen solo por los recursos que consumen.[2]Amazon Web Services, "Amazon EMR sin servidor para Apache Spark," amazon.com El modelo de servicio resuena con las organizaciones que carecen de experiencia profunda en Hadoop, permitiendo a los equipos de datos centrarse en los conocimientos en lugar de la infraestructura. Los precios basados en el consumo trasladan el presupuesto del gasto de capital al gasto operativo, eliminando el impacto económico históricamente asociado a las implementaciones locales. A medida que las estrategias multinube se normalizan, la portabilidad entre proveedores mejora, ampliando aún más el mercado direccionable para el mercado de Hadoop en Estados Unidos.
Ventajas de Costos Frente a los Sistemas Tradicionales de Almacén de Datos
Un análisis comparativo de Oracle reveló ahorros en el costo total de propiedad del 60-70% cuando Hadoop reemplaza los dispositivos de almacén de datos propietarios a escala equivalente. Las licencias de código abierto eliminan las tarifas de plataforma, mientras que los servidores estándar evitan la prima que exige el hardware especializado. El diseño de esquema en lectura pospone las decisiones del modelo de datos hasta el momento de la consulta, reduciendo la sobrecarga de ETL y acelerando el lanzamiento de proyectos. Las empresas con una ingesta de datos en aumento aprecian que escalar Hadoop requiere adquirir nodos adicionales en lugar de actualizaciones completas de infraestructura. Para las pymes sensibles al costo, esta economía desbloquea el análisis avanzado que antes estaba reservado para corporaciones con grandes recursos, reforzando el atractivo de la entrega alojada en la nube.
Integración de Cargas de Trabajo de Inteligencia Artificial y Aprendizaje Automático en Ecosistemas Hadoop
Las canalizaciones de aprendizaje automático prosperan con vastos conjuntos de datos etiquetados que residen de forma nativa en los clústeres Hadoop. El vínculo de Google Cloud entre Vertex AI y Dataproc permite que el entrenamiento de modelos se ejecute junto a los datos, reduciendo drásticamente la latencia de transferencia y los cargos de salida. Marcos como Spark MLlib y TensorFlow en YARN explotan la memoria distribuida, acelerando la convergencia de algoritmos. Los proveedores están incorporando AutoML, aceleradores de ingeniería de características y programación de GPU para agilizar la experimentación. A medida que los casos de uso evolucionan de los paneles retrospectivos al reconocimiento de patrones en tiempo real, Hadoop emerge como el terreno de preparación para el desarrollo iterativo de modelos, la evaluación y la implementación a escala.
Análisis del Impacto de las Restricciones*
| Restricción | (~) % de Impacto en el Pronóstico de CAGR | Relevancia Geográfica | Horizonte Temporal del Impacto |
|---|---|---|---|
| Escasez aguda de talento en Hadoop y pronunciadas curvas de aprendizaje | -2.8% | Nacional, particularmente aguda en el Medio Oeste y el Sur | Corto plazo (≤ 2 años) |
| Creciente migración hacia plataformas lakehouse en la nube que canibalizan Hadoop local | -3.2% | Nacional, con concentración en regiones tecnológicamente avanzadas | Mediano plazo (2-4 años) |
| Persistentes preocupaciones sobre seguridad de datos y gobernanza | -1.9% | Nacional, con énfasis en industrias reguladas | Mediano plazo (2-4 años) |
| Deuda técnica de clústeres heredados y altos costos de mantenimiento | -2.1% | Nacional, particularmente en organizaciones adoptantes tempranas | Largo plazo (≥ 4 años) |
| Fuente: Mordor Intelligence | |||
Escasez Aguda de Talento en Hadoop
Un estudio del IEEE informó que el 68% de las empresas tienen dificultades para contratar profesionales calificados en Hadoop, con vacantes que permanecen abiertas un promedio de 4,5 meses. El ecosistema exige competencia en HDFS, YARN, MapReduce, Spark y marcos de seguridad como Ranger y Knox. La reorientación de los administradores de bases de datos suele abarcar entre 12 y 18 meses, lo que dificulta la velocidad de implementación. Las disparidades regionales agravan la presión: las empresas fuera de los principales centros tecnológicos enfrentan primas de reubicación que diluyen los ahorros de costos de Hadoop. Los programas de formación intensiva y los planes de estudio universitarios están aumentando, pero es posible que no cubran el déficit con rapidez, lo que pesa sobre la expansión a corto plazo del mercado de Hadoop en Estados Unidos.
La Migración hacia Plataformas Lakehouse en la Nube Canibaliza los Clústeres Hadoop Tradicionales
Las plataformas unificadas como Databricks y Snowflake consolidan el almacenamiento, el análisis y la gobernanza en un único servicio, desafiando la complejidad de múltiples componentes de Hadoop. La propuesta de lakehouse de Databricks, con rendimiento de nivel de almacén de datos sobre lagos de datos en formato abierto, resuena con los equipos cansados de ajustar múltiples motores.[3]Databricks, "Arquitectura de Referencia de Lakehouse," databricks.com Los kits de herramientas de migración, los créditos con descuento y los análisis comparativos de rendimiento atraen a las empresas a cambiar de plataforma en lugar de modernizar los clústeres locales. Si bien muchas empresas adoptarán la coexistencia híbrida, las nuevas cargas de trabajo pueden omitir Hadoop por completo, lo que resultará en un gasto direccionable reducido a mediano plazo.
*Nuestras previsiones consideran los impactos de impulsores y restricciones como direccionales, no aditivos. Las previsiones de impacto reflejan el crecimiento base, los efectos de mezcla y las interacciones entre variables.
Análisis de Segmentos
Por Componente: Los Servicios Ganan Impulso mientras el Software Mantiene su Posición Central
El software se mantuvo dominante, capturando el 40,7% del gasto dentro del mercado de Hadoop en Estados Unidos en 2024, a medida que las empresas renovaron suscripciones para soporte de distribución, parches de seguridad y módulos de análisis complementarios. Los proveedores se centraron en el refuerzo de características, una mayor compatibilidad con SQL y el empaquetado nativo en la nube para preservar las bases instaladas.
Sin embargo, los servicios están escalando más rápido con una CAGR del 20,92%, lo que refleja la preferencia ejecutiva por la implementación llave en mano, el ajuste de clústeres y las operaciones gestionadas. Cloudera amplió su equipo de servicios profesionales en 200 consultores en 2024 para satisfacer esta demanda de asesoramiento. A medida que las obligaciones regulatorias se intensifican, los compradores recurren a integradores de sistemas con experiencia en HIPAA, PCI-DSS y FedRAMP para configurar canalizaciones conformes. El hardware se ha reducido a casos de uso especializados, como los nodos periféricos reforzados, lo que refuerza el cambio del gasto de capital a los modelos operativos centrados en servicios dentro del mercado de Hadoop en Estados Unidos.



Por Modelo de Implementación: La Trayectoria de la Nube Desafía los Derechos Locales
Las instalaciones locales aún representaron el 52,8% del tamaño del mercado de Hadoop en Estados Unidos en 2024, debido a la inversión ya realizada, los mandatos de soberanía de datos y el acoplamiento de aplicaciones de baja latencia. Las instituciones financieras y las agencias del sector público a menudo mantienen clústeres aislados por razones de auditoría y seguridad.
Las alternativas en la nube se aceleran a una CAGR del 21,3% hasta 2030, impulsadas por EMR sin servidor, HDInsight con escalado automático y las ofertas de tipos de máquinas personalizadas de Google Dataproc. Estos servicios neutralizan los problemas de planificación de capacidad y reducen los plazos de meses a horas. Los esquemas híbridos, donde los conjuntos de datos sensibles residen localmente mientras las cargas de trabajo en picos se ejecutan en la nube, se están convirtiendo en la norma. La flexibilidad arquitectónica resultante refuerza la diversidad del gasto en el mercado de Hadoop en Estados Unidos.
Por Tamaño de Organización: Las Pymes Reducen la Brecha de Utilización
Las grandes empresas mantuvieron una participación del 65,1% en 2024, aprovechando grandes reservas de datos para ejecutar detección de fraudes, personalización omnicanal y optimización de la cadena de suministro en clústeres de múltiples petabytes. Los equipos de plataforma dedicados hacen cumplir los objetivos de nivel de servicio que mantienen a Hadoop como parte integral de los procesos críticos para el negocio.
Las pymes son el segmento de más rápido crecimiento, con una CAGR del 20,7%, impulsadas por licencias de pago por uso y asistentes de implementación basados en plantillas. HDInsight Essentials de Microsoft está dirigido a empresas más pequeñas con necesidades de procesamiento por lotes predecibles y personal limitado. A medida que las pequeñas y medianas empresas digitalizan sus flujos de trabajo de oficina frontal y trasera, Hadoop se convierte en la columna vertebral analítica que convierte los datos operativos en conocimientos predictivos, ampliando así la penetración del mercado de Hadoop en Estados Unidos.
Por Industria de Usuario Final: La Atención Médica Encabeza el Ranking de Crecimiento
Los proveedores de tecnología de la información y telecomunicaciones representaron el 30,02% de los ingresos totales en 2024, aprovechando Hadoop para la telemetría de red en tiempo real, el análisis de la experiencia del cliente y la mitigación del fraude en facturación. La tolerancia a la latencia ha mejorado gracias a Spark Streaming, lo que sostiene el apetito del sector vertical por la computación distribuida.
La atención médica y las ciencias de la vida están preparadas para superar a sus pares con una CAGR del 22,3%, ya que la secuenciación genómica, la fusión de datos de ensayos clínicos y los paneles de salud poblacional exigen un escalado rentable. La postura en expansión de la Administración de Alimentos y Medicamentos sobre la evidencia del mundo real subraya la importancia del cumplimiento con una linaje de datos verificable. Los patrocinadores farmacéuticos dependen de Hadoop para ingerir registros de salud electrónicos, datos de reclamaciones y feeds de sensores de dispositivos portátiles, reforzando el impulso específico del sector vertical dentro del mercado de Hadoop en Estados Unidos.
Análisis Geográfico
El Sur representó el 38,31% de los ingresos nacionales en 2024, impulsado por extensos corredores de centros de datos en Texas, Carolina del Norte y Florida. Los incentivos de servicios públicos, los bajos costos de energía y los regímenes fiscales favorables a los negocios han atraído tanto a hiperescaladores como a inquilinos empresariales. AWS añadió nuevas zonas de disponibilidad en el Este de EE. UU. en Carolina del Norte durante 2025, mejorando la latencia regional y reforzando la confianza en las cargas de trabajo de Hadoop entregadas en la nube.[4]Amazon Web Services, "Expansión de la Región Este de EE. UU. 2025," amazon.com
El Oeste es el líder del ritmo, con una CAGR del 21,5% hasta 2030. El profundo banco de talento de Silicon Valley, junto con el respaldo de capital de riesgo, sostiene una cartera de empresas emergentes de ingeniería de datos que estandarizan en fundamentos Hadoop. Las leyes de privacidad de California, como la CPRA, intensifican la inversión en herramientas de gobernanza, impulsando indirectamente el gasto en módulos de metadatos y seguridad. Las expansiones de Google en Oregón y Nevada priorizan instancias de alta memoria adaptadas a casos de uso de big data, fortaleciendo la columna vertebral de la nube regional.
Los clústeres del Noreste y el Medio Oeste representan conjuntamente una participación considerable, anclados por la concentración de servicios financieros de Nueva York y el cinturón manufacturero de los Grandes Lagos. Los lanzamientos de zonas de nube en Chicago reducen la latencia para los clientes del Medio Oeste, mientras que las empresas de tecnología financiera de Nueva York utilizan Hadoop para cumplir con los requisitos de riesgo e informes en tiempo real. La disponibilidad de mano de obra y los mayores costos de instalaciones moderan la aceleración a corto plazo, aunque las subvenciones de modernización y los laboratorios de innovación público-privados tienen como objetivo mantener el compromiso con el mercado de Hadoop en Estados Unidos.
Panorama Competitivo
La competencia combina proveedores empresariales establecidos, hiperescaladores de nube y disruptores especializados. Cloudera, IBM y Oracle refuerzan sus carteras mediante certificaciones de seguridad, aceleración de GPU y suites de observabilidad. Los proveedores de nube aprovechan las economías de escala para ofrecer Hadoop gestionado como punto de entrada a conjuntos de herramientas de plataforma de datos más amplios, intensificando la competencia en precio y rendimiento. La concentración de participación de mercado se mantiene moderada; los cinco principales proveedores controlan colectivamente alrededor del 45% de los ingresos, fomentando tanto movimientos de consolidación como oportunidades de nicho.
Los actores emergentes desafían la posición mental de los incumbentes. El modelo lakehouse de Databricks y el procesamiento de datos no estructurados de Snowflake captan cargas de trabajo incrementales al ofrecer la simplicidad de una plataforma única. Las solicitudes de patentes relacionadas con el almacenamiento en caché columnar, las federaciones de consultas y la implementación nativa en Kubernetes aumentaron considerablemente en 2025, lo que señala una carrera por la propiedad intelectual diferenciada.
Las asociaciones florecen como moneda estratégica. Oracle ahora admite implementaciones multinube de su Servicio de Big Data a través de AWS Direct Connect y Google Interconnect, ayudando a los clientes que buscan diversidad de proveedores. La adquisición de StreamSets por parte de IBM introduce el diseño automatizado de canalizaciones de datos, reduciendo la fricción de incorporación. La inyección de USD 150 millones de Cloudera en interfaces de búsqueda impulsadas por inteligencia artificial tiene como objetivo reducir la rotación de clientes al incorporar conocimientos en lenguaje natural en su ecosistema. En conjunto, estos movimientos ilustran un mercado que pivota desde las afirmaciones de rendimiento bruto hacia propuestas de valor orientadas a resultados dentro del mercado de Hadoop en Estados Unidos.
Líderes de la Industria de Hadoop en Estados Unidos
Cloudera, Inc.
Amazon Web Services, Inc.
Microsoft Corporation
IBM Corporation
Google LLC
- *Nota aclaratoria: los principales jugadores no se ordenaron de un modo en especial

Desarrollos Recientes de la Industria
- Octubre de 2025: Cloudera anunció una inversión de USD 150 millones para incorporar consultas de inteligencia artificial generativa y optimización automatizada de canalizaciones en su distribución insignia.
- Septiembre de 2025: Microsoft habilitó clústeres acelerados por GPU en Azure HDInsight para cargas de trabajo de TensorFlow y PyTorch.
- Agosto de 2025: Amazon Web Services presentó EMR sin servidor para Apache Spark, eliminando la sobrecarga de gestión de clústeres.
- Julio de 2025: IBM adquirió StreamSets por USD 300 millones para avanzar en las capacidades de integración de datos en nube híbrida.
- Junio de 2025: Oracle presentó asociaciones con Databricks y Snowflake, ofreciendo soluciones lakehouse integradas.


Alcance del Informe del Mercado de Hadoop en Estados Unidos
| Software |
| Hardware |
| Servicios |
| Local |
| Nube |
| Híbrido |
| Grandes Empresas |
| Pequeñas y Medianas Empresas |
| BFSI |
| Comercio Minorista y Bienes de Consumo |
| Atención Médica y Ciencias de la Vida |
| Tecnología de la Información y Telecomunicaciones |
| Manufactura |
| Otras Industrias de Usuarios Finales |
| Noreste |
| Medio Oeste |
| Sur |
| Oeste |
| Por Componente | Software |
| Hardware | |
| Servicios | |
| Por Modelo de Implementación | Local |
| Nube | |
| Híbrido | |
| Por Tamaño de Organización | Grandes Empresas |
| Pequeñas y Medianas Empresas | |
| Por Industria de Usuario Final | BFSI |
| Comercio Minorista y Bienes de Consumo | |
| Atención Médica y Ciencias de la Vida | |
| Tecnología de la Información y Telecomunicaciones | |
| Manufactura | |
| Otras Industrias de Usuarios Finales | |
| Por Región | Noreste |
| Medio Oeste | |
| Sur | |
| Oeste |


Preguntas Clave Respondidas en el Informe
¿Cuál es el tamaño del mercado de Hadoop en Estados Unidos en 2025?
El tamaño del mercado de Hadoop en Estados Unidos es de USD 54,25 mil millones en 2025.
¿Qué CAGR se pronostica para el gasto en Hadoop en Estados Unidos hasta 2030?
Se proyecta que el gasto crezca a una CAGR del 20,12% entre 2025 y 2030.
¿Qué región de EE. UU. se expande más rápidamente en implementaciones de Hadoop?
Se prevé que el Oeste registre una CAGR del 21,5%, impulsado por el ecosistema de innovación de Silicon Valley.
¿Qué sector vertical de la industria se espera que crezca más rápidamente?
Se proyecta que la atención médica y las ciencias de la vida avancen a una CAGR del 22,3% hasta 2030.
¿Cuál es el principal obstáculo para una adopción más amplia de Hadoop?
La escasez a nivel nacional de profesionales experimentados en Hadoop es la principal restricción, que añade demoras en la contratación y costos adicionales.
¿Cómo influyen los servicios en la nube en la adopción de Hadoop entre las pymes?
Las ofertas de Hadoop como Servicio basadas en la nube proporcionan escalabilidad de pago por uso y operaciones gestionadas, lo que permite a las pymes adoptar el análisis de big data sin un capital inicial elevado.
Última actualización de la página el:




