Web-Scraping-Markt Größe und Anteil
Marktübersicht
| Studienzeitraum | 2020 - 2031 |
|---|---|
| Marktgröße (2026) | 1.56 Milliarden US-Dollar |
| Marktgröße (2031) | 3.49 Milliarden US-Dollar |
| Wachstumsrate (2026 - 2031) | 17.39% CAGR |
| Schnellstwachsender Markt | Asien-Pazifik |
| Größter Markt | Nordamerika |
| Marktkonzentration | Mittel |
Hauptakteure *Haftungsausschluss: Hauptakteure in keiner bestimmten Reihenfolge sortiert Bild © Mordor Intelligence. Wiederverwendung erfordert Namensnennung gemäß CC BY 4.0. | |
Web-Scraping-Marktanalyse von Mordor Intelligence
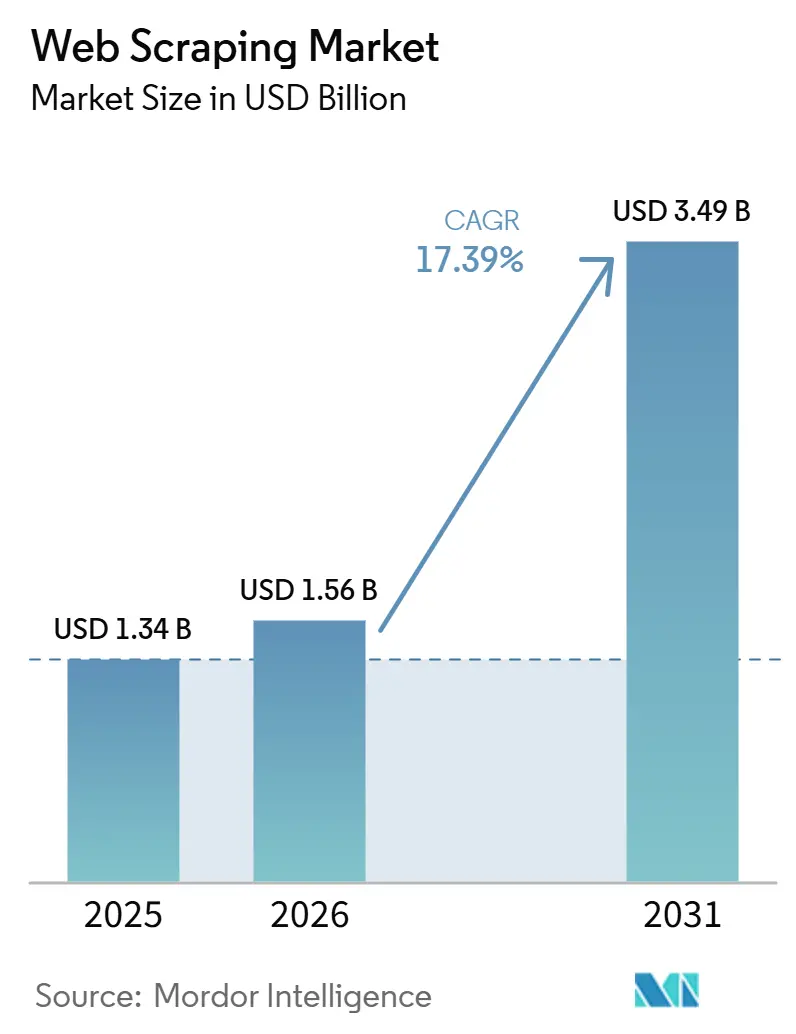
Der Web Scraping-Markt wurde im Jahr 2025 auf einen Wert von 1,34 Milliarden USD geschätzt und soll von 1,56 Milliarden USD im Jahr 2026 auf 3,49 Milliarden USD bis 2031 wachsen, bei einer CAGR von 17,39 % während des Prognosezeitraums (2026–2031). Die solide Nachfrage resultiert aus dem Bestreben von Unternehmen, schwindenden API-Zugang zu ersetzen, generative KI-Modelle vorzubereiten und mit dem Bedarf an Echtzeit-Wettbewerbsinformationen Schritt zu halten. Preiskämpfe im E-Commerce, der Aufstieg alternativer Daten im Finanzdienstleistungsbereich und die zunehmende Cloud-Akzeptanz erzeugen einen stetigen Strom großvolumiger Extraktionsaufgaben. Gleichzeitig treiben regulatorische Kontrolle und ausgefeilte Anti-Bot-Abwehrmechanismen Käufer zu höherwertigen, compliance-fähigen Lösungen, die unter verschärften technischen und rechtlichen Rahmenbedingungen stabile Erfolgsquoten aufrechterhalten können. Anbieter, die Skalierbarkeit, KI-gestützte Anpassungsfähigkeit und regionsspezifische Compliance-Unterstützung kombinieren, sind in der Lage, überproportionale Umsätze zu erzielen, da sich der Web Scraping-Markt von der Massenerfassung hin zu einer unternehmenskritischen Dateninfrastruktur verlagert.
Wichtigste Erkenntnisse des Berichts
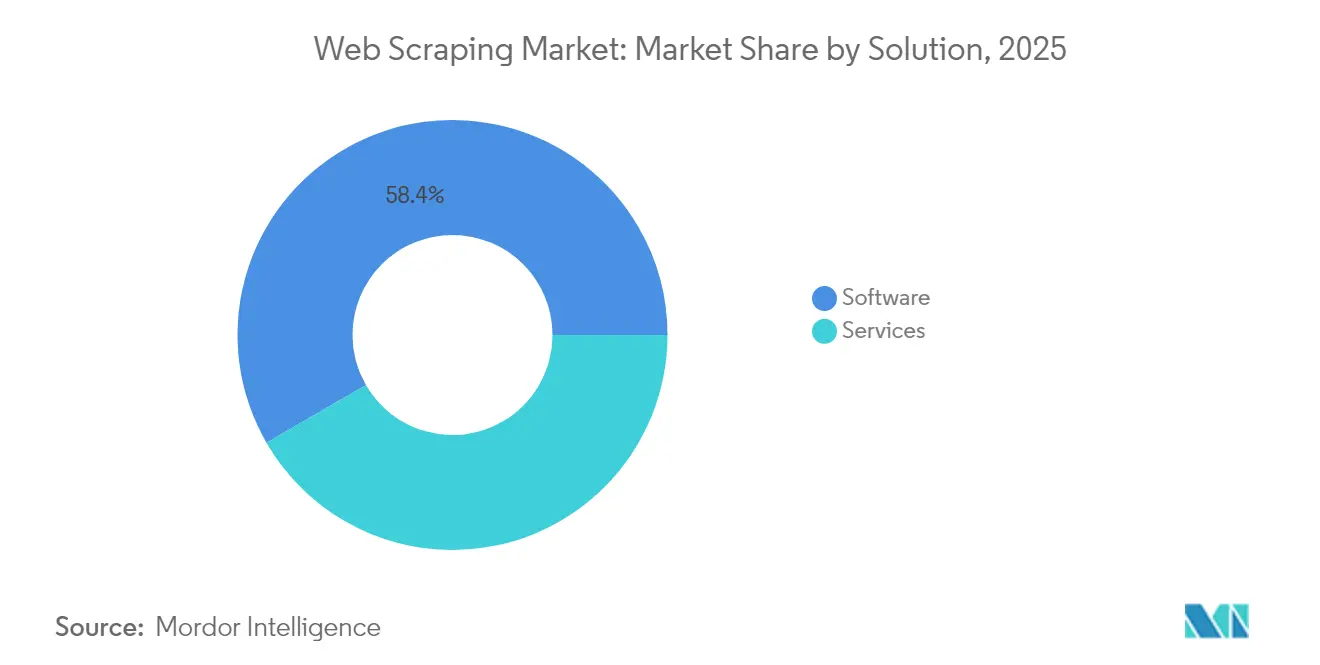
- Nach Lösungstyp hielt Software im Jahr 2025 einen Umsatzanteil von 58,35 %, während Dienstleistungen bis 2031 eine CAGR von 18,62 % verzeichnen sollen.
- Nach Bereitstellungsmodell entfielen im Jahr 2025 67,45 % des Web Scraping-Marktvolumens auf Cloud-Modelle, die mit einer CAGR von 17,80 % wachsen sollen.
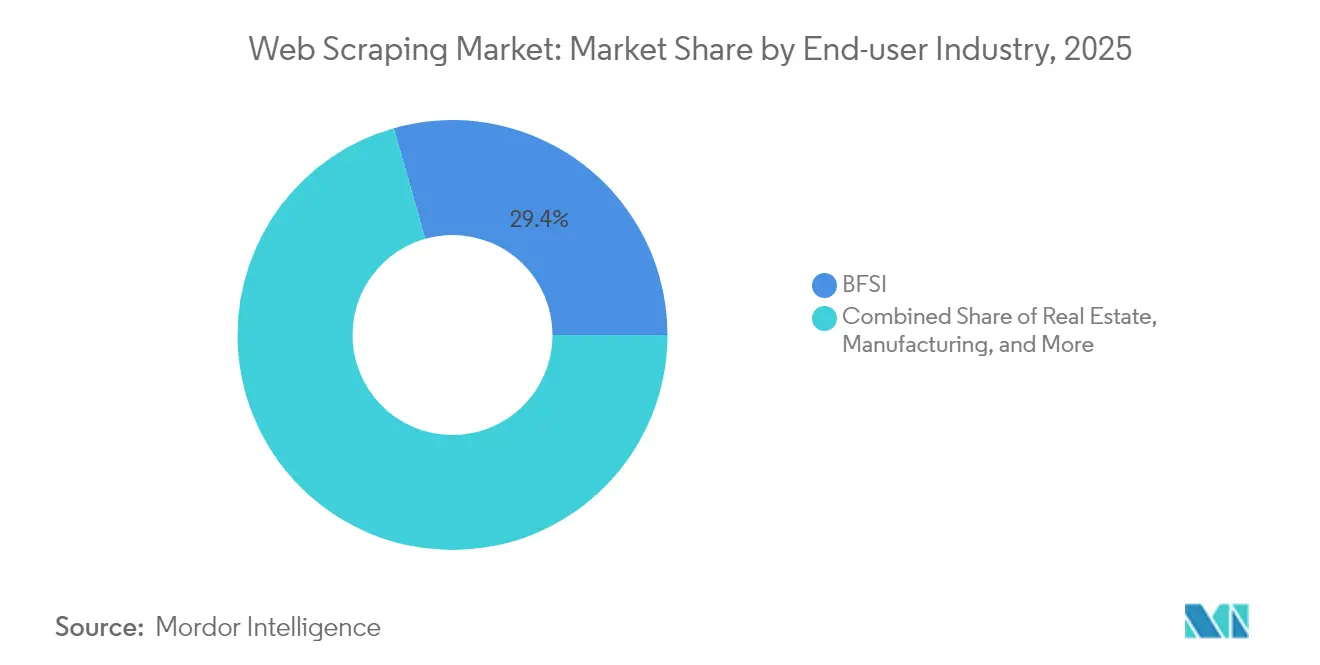
- Nach Endnutzerbranche entfielen im Jahr 2025 29,40 % des Web Scraping-Marktvolumens auf Banking, Finanzdienstleistungen und Versicherungen; Werbung und Medien verzeichnen bis 2031 eine CAGR von 18,80 %.
- Nach Anwendungsfall entfielen im Jahr 2025 36,20 % des Web Scraping-Markts auf Daten-Scraping und ETL, während das Segment Preis- und Wettbewerbsüberwachung mit einer CAGR von 18,34 % wächst.
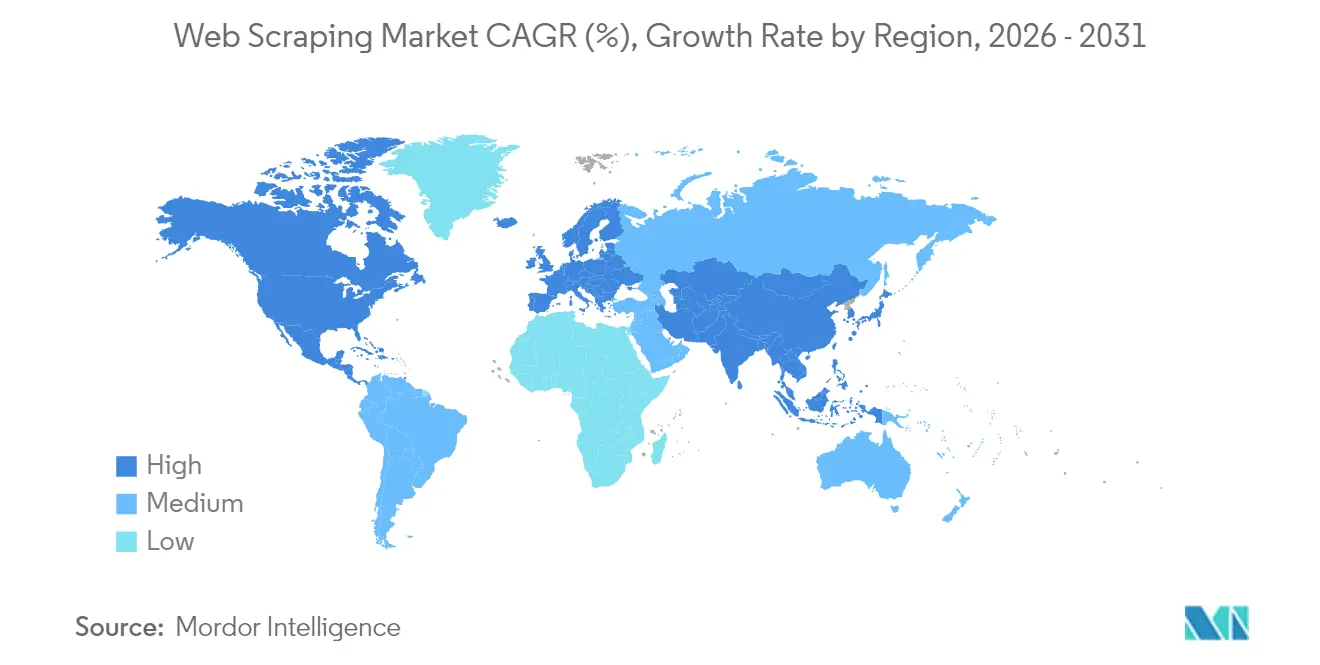
- Nach Geografie führte Nordamerika im Jahr 2025 mit einem Web Scraping-Marktanteil von 34,08 %; Asien-Pazifik soll bis 2031 die schnellste CAGR von 18,66 % erzielen.
Hinweis: Die Marktgrößen- und Prognosezahlen in diesem Bericht werden mithilfe des proprietären Schätzrahmens von Mordor Intelligence erstellt und mit den neuesten verfügbaren Daten und Erkenntnissen bis 2026 aktualisiert.
Globale Web-Scraping-Markttrends und Erkenntnisse
Analyse der Treiberwirkung*
| Treiber | (~) % Auswirkung auf die CAGR-Prognose | Geografische Relevanz | Zeithorizont der Auswirkung |
|---|---|---|---|
| Wachstum des E-Commerce und der Online-Marktplätze | +3.2% | Global (Nordamerika, Asien-Pazifik konzentriert) | Mittelfristig (2–4 Jahre) |
| Fortschritte bei KI/ML für die Datenextraktion | +2.8% | Global (Nordamerika und Europa führend) | Langfristig (≥ 4 Jahre) |
| Steigende Nachfrage nach alternativen Daten im Finanzbereich | +2.1% | Nordamerika, Europa, expandierender Asien-Pazifik-Raum | Mittelfristig (2–4 Jahre) |
| API-Abkündigung auf großen Plattformen | +1.9% | Global (soziale Medien, Inhaltsplattformen am stärksten betroffen) | Kurzfristig (≤ 2 Jahre) |
| Anforderungen an Trainingsdaten für generative KI | +1.7% | Global (KI-Entwicklungszentren) | Langfristig (≥ 4 Jahre) |
| Open-Data-Mandate, die Datenlücken aufdecken | +0.8% | Europa und Nordamerika | Mittelfristig (2–4 Jahre) |
| Quelle: Mordor Intelligence | |||
Wachstum des E-Commerce und der Online-Marktplätze
Preiskämpfe in Echtzeit haben 81 % der Einzelhändler in den Vereinigten Staaten zu automatisiertem Preis-Scraping für dynamische Repricing-Strategien bewogen, gegenüber 34 % im Jahr 2020 [1]Actowiz Solutions, "Statistiken zur Einführung von Einzelhandelspreisscraping 2025," actowiz.com. Marktplatzformate durchdringen mittlerweile Immobilien, Lebensmittel und Fahrzeugangebote, die jeweils eine Bestandstransparenz auf Millisekundenebene erfordern. Die Eskalation der Bot-Abwehr auf Einzelhandelsseiten befeuert paradoxerweise die Premium-Nachfrage nach robusten Scrapern, die Geräte-Fingerprinting und JavaScript-Herausforderungen umgehen. Quick-Commerce- und Flash-Sale-Modelle erweitern die adressierbare Chance zusätzlich, da Händler auf datengesteuerte Aktionen auf regionalen Marktplätzen umsteigen.
Fortschritte bei KI/ML für die Datenextraktion
65 % der Unternehmen nutzten im Jahr 2024 Web-Scraping zur Speisung von KI- und maschinellen Lernprojekten, was einen Wandel von regelbasierten Skripten hin zu adaptiven Algorithmen signalisiert, die den Wartungsaufwand um 40 % reduzieren [2]BrowserCat, "KI & Web-Scraping-Umfrage 2024," browsercat.com. KI-gestützte Verhaltensimitation steigert die Erfolgsquoten auf stark geschützten Seiten auf 80–95 %, während die dynamische Vorlagenerkennung Ausfallzeiten bei Änderungen des Seitenlayouts reduziert. Anbieter, die Reinforcement Learning und synthetische Browser-Fingerprints einbetten, haben die intelligente Extraktion zu einem Premium-Differenzierungsmerkmal statt zu einer Massenware gemacht.
Steigende Nachfrage nach alternativen Daten im Finanzbereich
Web-Scraping bildet die Grundlage für 67 % der Programme für alternative Daten von Anlageberatern in den Vereinigten Staaten, ein Wert, der im Jahr 2024 um 20 Prozentpunkte gestiegen ist. Die Echtzeit-Erfassung von Nachrichten, Einreichungen und Stimmungsdaten speist algorithmische Handelsabteilungen und Kreditrisikomodelle. Robuste Budgets – 94 % der Nutzer planen eine Erhöhung der Ausgaben – signalisieren einen dauerhaften Einnahmestrom für Anbieter, die saubere Datenpipelines mit den von Regulierungsbehörden und Fondsverwaltern geforderten Prüfpfaden verbinden.
API-Abkündigung auf großen Plattformen
Soziale Netzwerke und Inhaltsverlage erhöhen weiterhin die Zugangshürden für programmatische Schnittstellen, wodurch gescraptes HTML und dynamisches Rendering zum wirtschaftlichen Weg für eine Datenabdeckung im großen Maßstab werden. Twitter, Reddit und andere Dienste haben kostenlose Zugangsstufen abgeschafft und veranlassen Unternehmen, ihre Ausgaben auf Headless-Browser und verteilte Proxy-Flotten umzulenken. Cloudflares kostenpflichtiges Zugriffsmodell für KI-Bots unterstreicht einen breiteren Wandel hin zur Monetarisierung von Daten-Endpunkten und verschiebt die wirtschaftlichen Rahmenbedingungen entscheidend zugunsten ausgefeilter Web-Scraping-Marktlösungen.
Analyse der Hemmnisauswirkungen*
| Hemmnis | (~) % Auswirkung auf die CAGR-Prognose | Geografische Relevanz | Zeithorizont der Auswirkung |
|---|---|---|---|
| Rechtliche und ethische Unsicherheit | -2.3% | Global (am strengsten in Europa) | Mittelfristig (2–4 Jahre) |
| Hohe Kosten und technische Komplexität | -1.8% | Global (KMU am stärksten betroffen) | Kurzfristig (≤ 2 Jahre) |
| Fortschrittliche Bot-Abwehr-Tools | -1.5% | Global (Fokus auf große Plattformen) | Kurzfristig (≤ 2 Jahre) |
| Offizielle APIs, die einige Anwendungsfälle kannibalisieren | -0.9% | Global (variiert je nach Sektor) | Mittelfristig (2–4 Jahre) |
| Quelle: Mordor Intelligence | |||
Rechtliche und ethische Unsicherheit
Die strenge DSGVO-Sichtweise der niederländischen Datenschutzbehörde zum Scraping personenbezogener Daten für KI-Training und die Leitlinien der Globalen Datenschutzversammlung von 2024 erfordern eine Rechtsgrundlage, Transparenz und minimierte Datenspeicherung, was die Compliance-Ausgaben um 86 % erhöht. Die Geldstrafe von 20 Millionen EUR, die Italien gegen einen Anbieter von Gesichtserkennung verhängt hat, signalisiert ein erhebliches Abwärtsrisiko, während das Justizministerium der Vereinigten Staaten Einrichtungen aus besorgniserregenden Ländern nun den Zugang zu sensiblen personenbezogenen Daten untersagt und damit geopolitische Prüfungsebenen hinzufügt. Die Bewältigung dieser grenzüberschreitenden Einschränkungen verzögert Projekte und erhöht die Kosten für die Rechtsüberprüfung.
Hohe Kosten und technische Komplexität
Akamai berichtet, dass seine Bot-Manager-Suite 82,3 % des automatisierten Datenverkehrs auf ausgewählten Produktseiten blockieren kann, was Scraper zwingt, in größere Proxy-Pools, benutzerdefinierte Browser-Farmen und KI-gestützte Umgehungsstacks zu investieren. KMU ohne ausreichendes Kapital haben Schwierigkeiten, mit dem Wettrüsten Schritt zu halten, und überlassen Nischendatenanforderungen oft gut finanzierten Dienstleistern. Mehrschichtige JavaScript-Herausforderungen und adaptive CAPTCHAs erhöhen die Rechenbudgets und verlängern die Extraktionszyklen, was den Return on Investment für weniger optimierte Betriebe schmälert.
*Unsere Prognosen behandeln die Auswirkungen von Treibern und Einschränkungen als richtungsweisend und nicht additiv. Die Wirkungsprognosen berücksichtigen Basiswachstum, Mischungseffekte und Wechselwirkungen zwischen Variablen.
Segmentanalyse
Nach Lösung: Dienstleistungen gewinnen an Dynamik, während Software die Skalierung beibehält
Softwareprodukte erzielten im Jahr 2025 einen Umsatzanteil von 58,35 %, was das Vertrauen von Unternehmen in interne Orchestrierungsframeworks und No-Code-Extraktoren unterstreicht. Dennoch wachsen Dienstleistungen mit einer CAGR von 18,62 %, da Käufer komplexe Compliance-Prüfungen, die Verwaltung rotierender Proxys und die Optimierung von Anti-Bot-Maßnahmen auslagern. Die Ausgabenmuster zeigen eine Verlagerung hin zur hybriden Nutzung, bei der interne Teams Standardsoftware für alltägliche Aufgaben einsetzen, während spezialisierte Unternehmen grenzüberschreitende oder rechtlich sensible Datensätze bearbeiten. KI-gestützte Datennormalisierung und -validierung erhöhen die abrechenbaren Sätze für Full-Service-Anbieter und stärken Kundenbindung und Marge. Diese Dynamik stellt sicher, dass der Web Scraping-Markt zwischen Toolkits und verwalteten Angeboten ausgewogen bleibt und sowohl eigenständig arbeitende Analysten als auch risikoaverse Unternehmen bedient.
Die Softwarekategorie hat von einer Welle an Open-Source- und Low-Code-Veröffentlichungen profitiert – darunter Thunderbit und Crawlee für Python –, die die Einstiegshürden für Business-Analysten gesenkt haben. Unternehmenssicherheitsteams fordern jedoch zunehmend externe Prüfungen und rechtliche Freigaben, was viele zu Dienstleistungsabonnements mit dokumentierten Compliance-Nachweisen drängt. Infolgedessen soll das Web Scraping-Marktvolumen für Dienstleistungen deutlich steigen und die Umsatzlücke zur Software bis 2031 verringern.
Notiz: Segmentanteile aller einzelnen Segmente sind nach dem Berichtskauf verfügbar


Nach Bereitstellungsmodell: Cloud-Infrastruktur beschleunigt die Einführung
Cloud-basierte Bereitstellungen entfielen im Jahr 2025 auf 67,45 % des Web Scraping-Markts und werden andere Modelle mit einer CAGR von 17,80 % übertreffen. Elastische Compute-Pools verteilen Headless-Browser über globale Präsenzpunkte – entscheidend, wenn Seiten geospezifische Inhalte ausliefern oder wiederkehrende IP-Adressen blockieren. Anbieter wie Oxylabs bündeln rotierende Residential-Proxys, Session-Management und Regelkonformitätsüberwachung als sofort einsetzbare APIs. Diese Abstraktion ermöglicht es Kunden, Tausende paralleler Anfragen zu skalieren, ohne physische Server bereitstellen zu müssen.
On-Premise-Implementierungen bestehen in stark regulierten Branchen fort, insbesondere im Gesundheitswesen und im Kernbankbereich, wo Datensouveränitätsklauseln eine lokale Speicherung vorschreiben. Selbst in diesen Sektoren werden containerisierte Scraper bei Lastspitzen zunehmend in freigegebene Public-Cloud-Regionen ausgelagert. Zukünftig werden Edge-Computing-Erweiterungen, die rohes HTML näher am Erfassungspunkt verarbeiten, die Latenz bei Auktions- oder Flugpreisaktualisierungen reduzieren und die zentrale Rolle der Cloud im Web Scraping-Markt weiter festigen.
Nach Endnutzerbranche: Finanzdienstleistungen verankern die Nachfrage, Medien wächst stark
Banking, Finanzdienstleistungen und Versicherungen hielten im Jahr 2025 29,40 % des Web Scraping-Marktvolumens, da Fonds, Kreditgeber und Versicherer Kreditrisiko- und Handelsalgorithmen mit gescrapten Nachrichten, Stellenausschreibungsdaten und Verbraucherstimmung versorgten. Strenge Prüfanforderungen begünstigen Anbieter, die Datenherkünfts-Tracking und regulatorische Warnmeldungen integrieren. Werbung und Medien, heute noch kleiner, verzeichnen die schnellste CAGR von 18,80 %. Agenturen benötigen einheitliche Feeds zu Kampagnenleistung, Publisher-Preisen und Markensicherheitssignalen, die nahezu in Echtzeit geliefert werden. Die investorenorientierten Narrative der Web Scraping-Branche rücken diese beiden Branchen zunehmend als zwei tragende Säulen in den Vordergrund: Eine bietet tiefe Taschen und wiederkehrende Ausgaben, die andere liefert schnell wachsende Mengen unstrukturierter Inhalte.
Einzelhandel und E-Commerce bleiben unverzichtbar, sind aber mittlerweile reife Nutzer. Das Wachstum resultiert weniger aus Erstkäufern als aus fortgeschrittenen Anwendungsfällen: dynamisches Coupon-Matching, Überwachung von Lieferzeitfenstern und hyperlokales Wettbewerbs-Tracking. Fertigungsindustrie, Gesundheitswesen und öffentliche Einrichtungen erweitern gemeinsam die adressierbare Basis, indem sie Lieferkettenüberwachung, Feeds für klinische Studien und behördlich vorgeschriebene Open-Data-Projekte auf bestehende Installationen aufsetzen.
Notiz: Segmentanteile aller einzelnen Segmente sind nach dem Berichtskauf verfügbar
Nach Anwendungsfall: ETL dominiert, Preisüberwachung wächst am schnellsten
Daten-Scraping- und ETL-Aufgaben entfielen im Jahr 2025 auf 36,20 % des Web Scraping-Marktvolumens und festigten ihre Rolle als Back-Office-Integratoren, die Data Warehouses, MDM-Hubs und Lakehouses versorgen. Diese Pipelines umfassen typischerweise geplante Crawls über Tausende von Domains, inkrementelle Diff-Logik und automatisiertes Schema-Mapping. Preis- und Wettbewerbsinformationsextraktion hingegen wächst mit einer CAGR von 18,34 %, angetrieben durch algorithmische Repricer und KI-gestützte Promotion-Engines, die Kataloge stündlich oder häufiger aktualisieren. Finanzdaten-Desks nutzen mehrere Anwendungsfall-Cluster – Nachrichten, regulatorische Einreichungen und Stimmungsanalyse –, wodurch die Grenzen zwischen reinen alternativen Daten und traditionellen Referenz-Feeds verschwimmen. Zusammen stellen diese Muster sicher, dass der Web Scraping-Markt weit über die einfache URL-Erfassung hinaus diversifiziert bleibt.
Lead-Generierungs-Scrapes, Social-Media-Listening und ESG-Recherchen runden die Nachfrage ab. Jeder Bereich fügt einzigartige Funktionsanforderungen hinzu – CRM-Integrationen, Spracherkennung oder Topic-Modeling –, was Anbieter zu modularen Architekturen drängt. Infolgedessen bleibt der Web Scraping-Markt innovationsintensiv, wobei Produkt-Roadmaps durch vertikalspezifische Workflow-Lücken geleitet werden.
Geografische Analyse
Nordamerika kontrollierte im Jahr 2025 34,08 % des Umsatzes, gestützt durch die tiefe Präsenz der Vereinigten Staaten im Finanzdienstleistungsbereich und Kanadas schnell wachsende Analyse-Hubs. Regionale Käufer legen großen Wert auf dokumentierte Compliance, wie die Tatsache belegt, dass 67 % der Berater alternative Datenströme in Investitionsprozesse integrieren. Neue Regeln des Justizministeriums der Vereinigten Staaten, die sensible Datenflüsse an ausländische Gegner einschränken, erhöhen den Due-Diligence-Aufwand, eröffnen aber gleichzeitig Chancen für inländische Dienstleistungsbüros, die auf rechtmäßige grenzüberschreitende Datenaufnahme spezialisiert sind.
Asien-Pazifik ist das am schnellsten wachsende Gebiet mit einer CAGR von 18,66 % bis 2031. Chinas Fertigungsexporteure verlassen sich auf Zoll- und Versand-Scrape-Feeds zur Preiskalibrierung, während Indiens IT-Dienstleistungsunternehmen großangelegte Datenerfassung in Analytics-Outsourcing-Verträge integrieren. Japans unternehmensweite Programme zur digitalen Transformation fördern die lokale Nachfrage nach mehrsprachigen Extraktionsframeworks. Südostasiatische Marktplätze beschleunigen die Akzeptanz, da Logistik-, Reise- und fintech-Super-Apps Echtzeit-Preiskämpfe austragen. Australien und Neuseeland runden den regionalen Schwung durch Rohstoffhandels-Desks ab, die Hafenanlauf- und Satelliten-Tracker scrapen.
Europa verfolgt eine Compliance-first-Strategie. Die restriktive Haltung des Europäischen Datenschutzausschusses gegenüber KI-Trainingsdaten erfordert risikobewertete Arbeitsabläufe und datenschutzfreundliche Pipelines. Anbieter, die Anonymisierung, Einwilligungsmanagement und Datensparsamkeitskontrollen integrieren, genießen einen Wettbewerbsvorteil. Käufer im Vereinigten Königreich balancieren die DSGVO-Konformität mit einem wachsenden Appetit auf fintech-Alternative-Daten, während Deutschland und Frankreich souveräne Cloud-Konstrukte für kritische Extraktionen bevorzugen. Die regulatorische Heterogenität auf dem Kontinent hält die Nachfrage nach beratenden Dienstleistungen aufrecht, die Rahmenbedingungen fallweise lokalisieren.

Wettbewerbslandschaft
Der Web-Scraping-Markt bleibt mäßig fragmentiert. Bright Data, Zyte, Apify und Oxylabs bilden eine Ebene skalierter Infrastrukturspezialisten, doch keiner davon kontrolliert einen dominanten Anteil. Der Wettbewerb verlagert sich von der reinen Erfassung hin zu Qualität, Verfügbarkeit und Compliance. Anbieter differenzieren sich durch Erfolgsquoten gegenüber Anti-Bot-Suiten, die Breite der Proxy-Pools und regionsspezifische Rechtsberatung. KI-gestützte Orchestrierung – adaptive Wiederholungsversuche, modellgesteuerte CSS-Selektor-Erkennung und automatische Beschriftung – ist zum Mindeststandard geworden.
Die strategische Positionierung offenbart zwei Lager. Horizontale Plattformen umwerben jede Branche mit Plug-and-Play-APIs, während Nischenanbieter auf tiefes Fachwissen in einzelnen Bereichen wie Reisepreisen oder App-Store-Rankings setzen. Cloudflares Pay-per-Bot-Marktplatz deutet darauf hin, dass Plattformbetreiber direkte Daten-Feeds bald monetarisieren könnten, was frühere Gegner möglicherweise in Kanalpartner verwandelt. Anbieter, die frühzeitig auf Umsatzbeteiligungsmodelle oder kuratierte Erstanbieter-Endpunkte umsteigen, werden ihre Margen schützen.
Investitionsflüsse begünstigen fortschrittliche Umgehungstechnologie. Start-ups, die auf Headless-Browser-Verschleierung, dynamische Fingerprint-Rotation und gerätebasiertes CAPTCHA-Lösen spezialisiert sind, ziehen Risikokapital an und antizipieren eine zunehmende Raffinesse bei der Verkehrsblockierung. Als Reaktion darauf erwerben etablierte Unternehmen Einzellösungen, um KI-Roadmaps zu beschleunigen und Echtzeit-Compliance-Monitore einzubetten. Im Prognosehorizont wird erwartet, dass Marktführer kleinere Proxy-Netzwerke und regionale Compliance-Boutiquen konsolidieren, um geografische Abdeckung und regulatorische Tiefe zu stärken.
Führende Unternehmen der Web-Scraping-Branche
Bright Data Ltd.
Zyte Group Ltd.
Apify Technologies s.r.o.
Octopus Data, Inc.
Import.io Ltd.
- *Haftungsausschluss: Hauptakteure in keiner bestimmten Reihenfolge sortiert

Jüngste Branchenentwicklungen
- Januar 2025: Das Justizministerium der Vereinigten Staaten hat umfassende Datenschutzregeln eingeführt, die den Zugang zu sensiblen personenbezogenen Daten durch besorgniserregende Länder verhindern und grenzüberschreitende Extraktions-Workflows neu gestalten.
- Januar 2025: Das Ministerium für Gesundheit und Soziale Dienste der Vereinigten Staaten hat seinen strategischen KI-Plan veröffentlicht und neue Mittel für datengestützte medizinische Forschung bereitgestellt, die auf automatisierter Erfassung basiert.
- Oktober 2024: Cloudflare hat einen Marktplatz vorgestellt, der es Verlagen ermöglicht, KI-Bots für den Scraping-Zugang zu berechnen, und damit die Wirtschaft der Datenmonetarisierung neu gestaltet.
- Juli 2024: Apify hat Crawlee für Python eingeführt und damit sein Open-Source-Crawling-Framework auf Python-Entwickler ausgeweitet und das Beitragsökosystem verbreitert.


Research Methodology Framework and Report Scope
Marktdefinitionen und wichtige Abdeckung
Unsere Studie definiert den Web-Scraping-Markt als alle kommerziellen Softwareplattformen und verwalteten Extraktionsdienste, die programmatisch öffentliche Webseiten crawlen, Inhalte analysieren und strukturierte Datensätze oder Live-Feeds an zahlende Kunden liefern. Die Bewertung umfasst Lizenz-, Abonnement- und Dienstleistungserlöse, die von Anbietern erzielt werden, die auf groß angelegte, compliance-fähige Datenerfassung spezialisiert sind.
Ausschluss aus dem Umfang: Interne Eigenentwicklungsskripte, die ausschließlich innerhalb eines Unternehmens betrieben werden, werden nicht berücksichtigt.
Segmentierungsübersicht
- Nach Lösung
- Software
- Dienstleistungen
- Nach Bereitstellungsmodell
- Cloud
- On-Premise
- Nach Endnutzerbranche
- BFSI
- Einzelhandel und E-Commerce
- Immobilien
- Fertigung
- Behörden
- Gesundheitswesen
- Werbung und Medien
- Sonstige
- Nach Anwendungsfall
- Daten-Scraping / ETL
- Preis- und Wettbewerbsüberwachung
- Lead-Generierung und Vertriebsinformationen
- Alternative Finanzdaten
- Stimmungs- und Sozialanalysen
- Nach Geografie
- Nordamerika
- Vereinigte Staaten
- Kanada
- Mexiko
- Südamerika
- Brasilien
- Argentinien
- Übriges Südamerika
- Europa
- Deutschland
- Vereinigtes Königreich
- Frankreich
- Italien
- Spanien
- Russland
- Übriges Europa
- Asien-Pazifik
- China
- Japan
- Indien
- Südkorea
- Australien und Neuseeland
- Übriger Asien-Pazifik-Raum
- Naher Osten und Afrika
- Naher Osten
- Saudi-Arabien
- Vereinigte Arabische Emirate
- Türkei
- Übriger Naher Osten
- Afrika
- Südafrika
- Nigeria
- Kenia
- Übriges Afrika
- Naher Osten
- Nordamerika
Detaillierte Forschungsmethodik und Datenvalidierung
Primärforschung
Strukturierte Interviews mit Produktleitern von Datenplattformen, Proxy-Netzwerkanbietern und Beschaffungsverantwortlichen in Nordamerika, Europa und Asien-Pazifik lieferten reale Preisspannen, Bindungsraten und regionale Compliance-Kosten, die Desk-Quellen selten offenlegen.
Desk-Recherche
Mordor-Analysten haben zunächst das Anbieteruniversum mithilfe öffentlicher Unternehmenseinreichungen, SEC 10-Ks und Technologieanbieterregistern wie dem Patentamt der Vereinigten Staaten und Questel-Patentfeeds kartiert. Anschließend wurden Nutzungs- und Ausgabensignale aus Branchenverbänden wie dem Interactive Advertising Bureau, regionalen E-Commerce-Verbänden und Zollversandprotokollen für Server-Hardware gezogen, die als Frühindikatoren für Crawler-Kapazität dienen. Auf IEEE Xplore indexierte wissenschaftliche Arbeiten klärten technische Adoptionskurven, während in Dow Jones Factiva aggregierte Nachrichtenflüsse dazu beitrugen, wesentliche Ereignisse zeitlich einzuordnen, die Umsätze beeinflussen. (Die aufgeführten Quellen veranschaulichen die verwendeten Typen und sind nicht erschöpfend.)
Marktgrößenbestimmung und Prognose
Ein Top-down-Modell beginnt mit den globalen IT-Ausgaben für die Datenerfassung, isoliert den Anteil, der auf externe Web-Daten-Feeds entfällt, und wird weiter durch die Adoptionsdurchdringung nach Branchen wie E-Commerce und BFSI gefiltert. Ausgewählte Bottom-up-Prüfungen – Stichproben von Anbieter-Durchschnittsverkaufspreisen und aktiven Kundenzahlen – validieren die Gesamtwerte. Zu den wichtigsten verfolgten Variablen gehören Proxy-Preisinflation, Anti-Bot-Erfolgsquoten, durchschnittlich gecrawlte Seiten pro Auftrag, API-Abkündigungshäufigkeit und regionale DSGVO-ähnliche Bußgelder. Prognosen verwenden multivariate Regression, unterstützt durch Expertenkonsens, um zu projizieren, wie diese Treiber Volumen und Preisgestaltung bis 2030 beeinflussen.
Datenvalidierung und Aktualisierungszyklus
Ergebnisse werden gegen alternative Dateninvestitionsflüsse und Cloud-Bandbreitenstatistiken auf Varianz geprüft, bevor ein leitender Analyst die Freigabe erteilt. Das Modell wird jährlich aktualisiert, mit Zwischenaktualisierungen, die durch wesentliche Rechtsurteile oder Technologieverschiebungen ausgelöst werden; ein abschließender Durchgang wird kurz vor der Berichtsveröffentlichung abgeschlossen.
Warum Mordors Web-Scraping-Basislinie Zuverlässigkeit verdient
Veröffentlichte Schätzungen weichen oft voneinander ab, weil Unternehmen den Markt unterschiedlich aufteilen, Währungen zu unterschiedlichen Zeitpunkten umrechnen oder angrenzende Segmente in einem Bucket zusammenfassen.
Zu den wichtigsten Ursachen für Abweichungen gehören, ob Dienstleistungserlöse berücksichtigt werden, wie Open-Source-Bereitstellungen behandelt werden und in welchem Rhythmus die Annahmen zu Durchschnittsverkaufspreisen aktualisiert werden. Externe Studien setzen den Markt 2025 für reine Software-Umfänge zwischen USD 0,78 Milliarden und 0,81 Milliarden an. Einige breite Studien fassen mehrere angrenzende Märkte zusammen und veröffentlichen eine Zahl von USD 6,77 Milliarden für 2024.
Benchmarkvergleich
| Marktgröße | Anonymisierte Quelle | Hauptursache für Abweichung |
|---|---|---|
| USD 1,03 Mrd. (2025) | ||
| USD 0,78 Mrd. (2025) | Regionale Beratung A | Zählt nur Software, schließt verwaltete Dienste aus |
| USD 0,81 Mrd. (2025) | Fachzeitschrift B | Enger Anbietersatz, keine Währungsnormalisierung |
| USD 6,77 Mrd. (2024) | Branchenverband C | Aggregiert Software-, Dienstleistungs- und angrenzende Datenmarktplatz-Umsätze |
Diese Kontraste zeigen, dass bei unterschiedlichem Umfang und unterschiedlichem Aktualisierungsrhythmus die Ergebnisse stark schwanken. Mordors ausgewogene Einschlussregeln, die Dual-Pfad-Modellierung und die jährlichen Aktualisierungen geben Entscheidungsträgern eine transparente, wiederholbare Basislinie, die eng mit beobachtbaren Ausgabensignalen und verifizierbaren Anbieterumsätzen übereinstimmt.


Im Bericht beantwortete Schlüsselfragen
Wie groß ist der Web Scraping-Markt derzeit?
Der Web Scraping-Markt beläuft sich im Jahr 2026 auf 1,56 Milliarden USD und soll bis 2031 auf 3,49 Milliarden USD wachsen, mit einer CAGR von 17,39 %.
Welche Region führt den Web Scraping-Markt an?
Nordamerika hält mit 34,08 % den größten Umsatzanteil dank reifer Akzeptanz im Finanzdienstleistungsbereich und robuster Cloud-Infrastruktur.
Warum wachsen Dienstleistungen im Web Scraping schneller als Software?
Unternehmen lagern zunehmend komplexe Compliance- und Anti-Bot-Herausforderungen aus, was das Dienstleistungssegment auf eine CAGR von 18,62 % treibt, obwohl Software einen höheren absoluten Umsatz beibehält.
Was ist der am schnellsten wachsende Anwendungsfall?
Preis- und Wettbewerbsüberwachung wächst mit einer CAGR von 18,34 %, da Einzelhändler und digitale Plattformen auf Echtzeit-Wettbewerbsdaten für dynamische Preisstrategien angewiesen sind.
Wie wirken sich Vorschriften auf Web Scraping-Projekte aus?
Neue Regelungen wie die Einschränkungen des Justizministeriums der Vereinigten Staaten für sensible Datenflüsse und strengere DSGVO-Auslegungen in Europa erhöhen den rechtlichen Aufwand und treiben die Nachfrage nach konformen, verwalteten Extraktionslösungen an.
Wie wirken sich Vorschriften auf Web-Scraping-Projekte aus?
Neue Regeln wie die Einschränkungen des Justizministeriums der Vereinigten Staaten für sensible Daten und strengere DSGVO-Auslegungen in Europa erhöhen den rechtlichen Aufwand und treiben die Nachfrage nach konformen, verwalteten Extraktionslösungen an.
Seite zuletzt aktualisiert am:




