Marktgröße und Marktanteil des Hadoop-Marktes der Vereinigten Staaten
Marktübersicht
| Studienzeitraum | 2019 - 2030 |
|---|---|
| Prognosedatenzeitraum | 2025 - 2030 |
| Historischer Datenzeitraum | 2019 - 2023 |
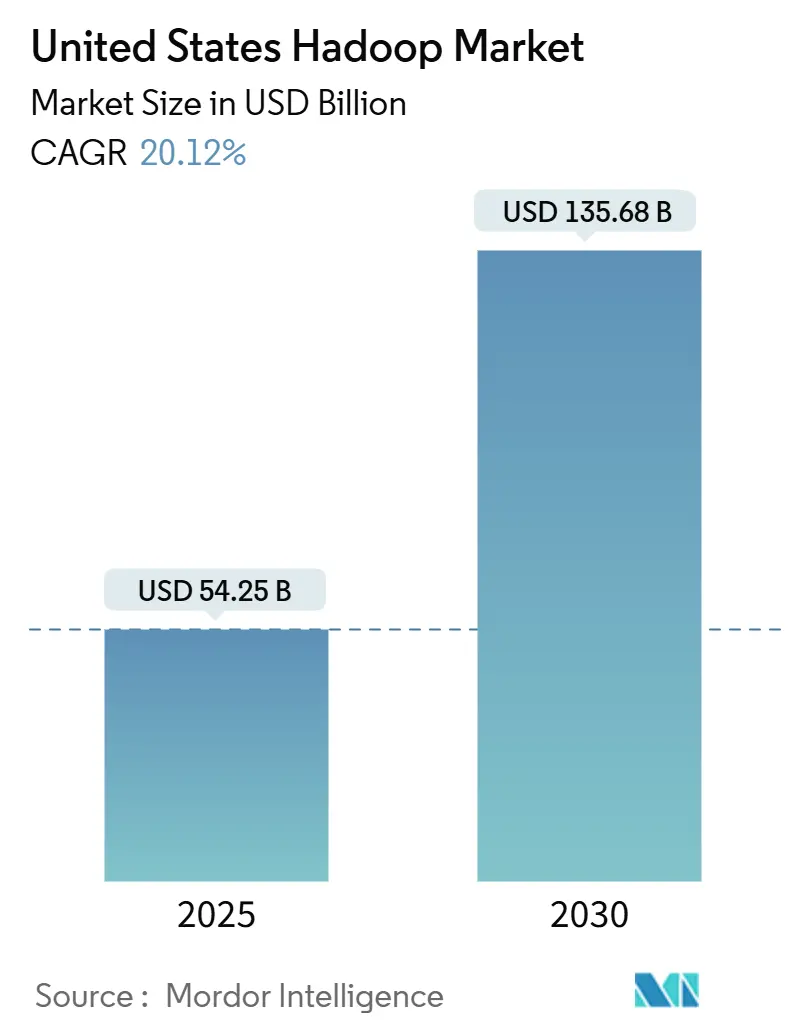
| Marktgröße (2025) | 54.25 Milliarden US-Dollar |
| Marktgröße (2030) | 135.68 Milliarden US-Dollar |
| Wachstumsrate (2025 - 2030) | 20.12% CAGR |
| Marktkonzentration | Mittel |
Hauptakteure *Haftungsausschluss: Hauptakteure in keiner bestimmten Reihenfolge sortiert Bild © Mordor Intelligence. Wiederverwendung erfordert Namensnennung gemäß CC BY 4.0. | |
Analyse des Hadoop-Marktes der Vereinigten Staaten von Mordor Intelligence
Die Marktgröße des Hadoop-Marktes der Vereinigten Staaten beläuft sich im Jahr 2025 auf 54,25 Milliarden USD und soll bis 2030 auf 135,68 Milliarden USD ansteigen, was einer soliden CAGR von 20,12 % über den Prognosezeitraum entspricht. Steigende Datenvolumina, aggressive Programme zur digitalen Transformation und der Wechsel von veralteten Data Warehouses positionieren den Hadoop-Markt der Vereinigten Staaten als unverzichtbare Infrastruktur für unternehmensweite Analysen. Softwarekomponenten bleiben zentral, doch Cloud-basierte Dienste gewinnen Budgetanteile, da Unternehmen nach verwalteten Clustern suchen, die bedarfsgerecht skalieren. Regional gesehen verfügt der Süden über den größten Ausgabenpool, während der Westen am schnellsten wächst, was das Innovationsrad des Silicon Valley widerspiegelt. Der Wettbewerb bleibt intensiv, da etablierte Anbieter ihren Marktanteil gegen Cloud-Hyperscaler und Lakehouse-Newcomer verteidigen, die vereinfachtes Management und verbesserte Abfragegeschwindigkeit versprechen.
Wichtigste Erkenntnisse des Berichts
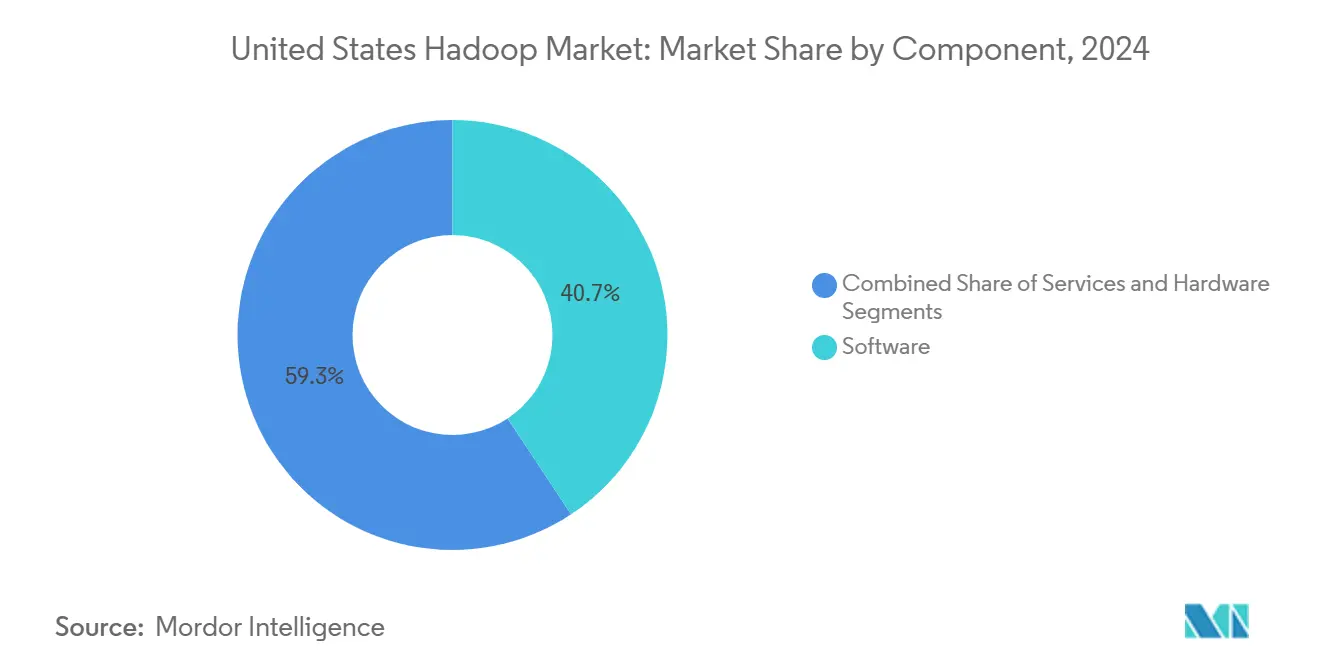
- Nach Komponente entfiel im Jahr 2024 ein Anteil von 40,7 % des Hadoop-Marktanteils der Vereinigten Staaten auf Software, während Dienstleistungen bis 2030 mit einer CAGR von 20,92 % wachsen.
- Nach Bereitstellungsmodell hielten On-Premise-Lösungen im Jahr 2024 einen Anteil von 52,8 % an der Marktgröße des Hadoop-Marktes der Vereinigten Staaten; Cloud-Implementierungen expandieren bis 2030 mit einer CAGR von 21,3 %.
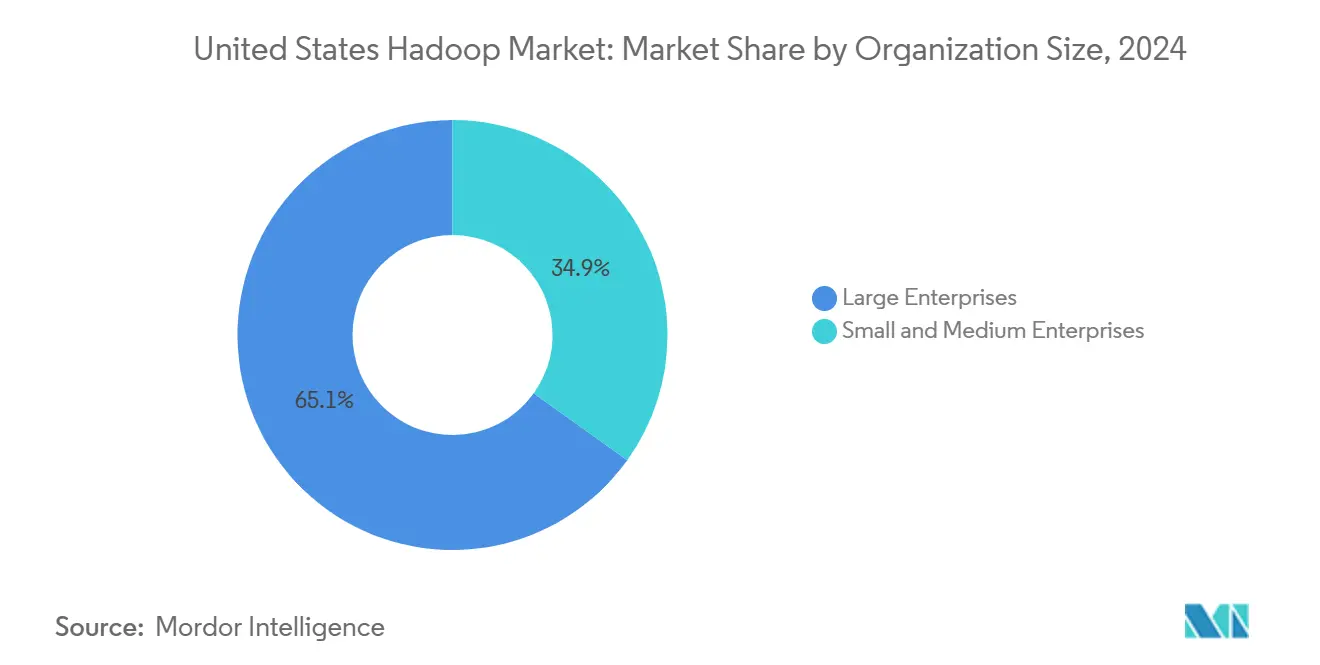
- Nach Unternehmensgröße entfielen im Jahr 2024 auf Großunternehmen ein dominanter Anteil von 65,1 % am Hadoop-Markt der Vereinigten Staaten, während für kleine und mittelständische Unternehmen bis 2030 eine CAGR von 20,7 % prognostiziert wird.
- Nach Endnutzerbranche kontrollierten IT und Telekommunikation im Jahr 2024 einen Anteil von 30,02 % der Ausgaben im Hadoop-Markt der Vereinigten Staaten, während für das Gesundheitswesen und die Biowissenschaften bis 2030 eine CAGR von 22,3 % prognostiziert wird.
- Nach Region führte der Süden im Jahr 2024 mit einem Umsatzbeitrag von 38,31 % am Hadoop-Markt der Vereinigten Staaten; der Westen liegt mit einer CAGR von 21,5 % während des Prognosezeitraums an der Spitze.
Trends und Erkenntnisse des Hadoop-Marktes der Vereinigten Staaten
Analyse der Treiberwirkung*
| Treiber | (~) % Auswirkung auf die CAGR-Prognose | Geografische Relevanz | Zeithorizont der Auswirkung |
|---|---|---|---|
| Explodierende Unternehmensdatenvolumina und Bedarf an skalierbarer Verarbeitung | +4.2% | National, mit Schwerpunkt in den Regionen Süd und West | Langfristig (≥ 4 Jahre) |
| Verlagerung hin zu Cloud-basierten Hadoop-als-Dienst-Modellen | +3.8% | National, mit früher Einführung im Westen und Nordosten | Mittelfristig (2–4 Jahre) |
| Kostenvorteile gegenüber traditionellen Lösungen für unternehmensweite Data Warehouses | +2.9% | National, insbesondere im kostensensiblen Segment kleiner und mittelständischer Unternehmen | Mittelfristig (2–4 Jahre) |
| Integration von KI- und ML-Workloads in Hadoop-Ökosysteme | +3.5% | Technologiezentren im Westen und Nordosten | Langfristig (≥ 4 Jahre) |
| Steigende Nachfrage nach Compliance-Analysen in regulierten Branchen | +2.1% | National, mit Schwerpunkt in den Sektoren BFSI und Gesundheitswesen | Mittelfristig (2–4 Jahre) |
| Edge- und IoT-Datenerfassung treibt nahezu echtzeitfähige Hadoop-Analysen voran | +1.8% | Fertigungsregionen im Mittleren Westen und Süden | Langfristig (≥ 4 Jahre) |
| Quelle: Mordor Intelligence | |||
Explodierende Unternehmensdatenvolumina erfordern skalierbare Verarbeitung
Digitale Kanäle, IoT-Sensoren und strenge Aufzeichnungspflichten lassen Datenspeicher auf Petabyte-Ebene anschwellen und übersteigen den Durchsatz herkömmlicher Warehouses. Eine IBM-Umfrage ergab, dass 73 % der US-amerikanischen Unternehmen ein jährliches Datenwachstum von mehr als 40 % verzeichneten.[1]IBM, "Unternehmensweite Datenverwaltungsumfrage 2024," ibm.com Das verteilte Dateisystem und die parallelisierten Rechenfähigkeiten von Hadoop ermöglichen es Unternehmen, Schritt zu halten, ohne Schemata neu zu schreiben oder Hardware neu zu strukturieren. Die Möglichkeit, handelsübliche Knoten linear hinzuzufügen, verwandelt die Kapazitätsplanung von einem Kapitalaufwandsrisiko in eine schrittweise Übung. Da Edge-Geräte zusätzliche Telemetriedaten liefern, werden zentralisierte Hadoop-Cluster zum bevorzugten Aggregator für nachgelagerte Analysen, vorausschauende Wartung und Anomalieerkennung. Unternehmen betrachten skalierbare Verarbeitung heute nicht mehr als optionales Experiment, sondern als zentralen Pfeiler der Geschäftskontinuität und Wettbewerbsfähigkeit.
Cloud-basierte Hadoop-als-Dienst-Modelle demokratisieren die Einführung von Big Data
Verwaltete Dienste wie Amazon EMR und Azure HDInsight senken die Betriebshürde, indem sie Cluster-Bereitstellung, Patches und Sicherheitshärtung abstrahieren. AWS führte 2024 serverloses EMR ein, das es Workloads ermöglicht, automatisch zu skalieren und nur für die verbrauchten Ressourcen abzurechnen.[2]Amazon Web Services, "Amazon EMR Serverless für Apache Spark," amazon.com Das Dienstleistungsmodell spricht Unternehmen an, denen tiefgreifende Hadoop-Expertise fehlt, und ermöglicht es Datenteams, sich auf Erkenntnisse statt auf Infrastruktur zu konzentrieren. Verbrauchsbasierte Preisgestaltung verlagert das Budget von Kapital- zu Betriebsausgaben und beseitigt den Preisschock, der historisch mit On-Premise-Aufbauten verbunden war. Da Multi-Cloud-Strategien immer normaler werden, verbessert sich die Portabilität zwischen Anbietern, was den adressierbaren Markt für den Hadoop-Markt der Vereinigten Staaten weiter vergrößert.
Kostenvorteile gegenüber traditionellen Data-Warehouse-Systemen
Benchmarking durch Oracle ergab Einsparungen bei den Gesamtbetriebskosten von 60–70 %, wenn Hadoop proprietäre Data-Warehouse-Appliances bei vergleichbarer Skalierung ersetzt. Open-Source-Lizenzierung eliminiert Plattformgebühren, während handelsübliche Server die Aufpreise für spezialisierte Hardware vermeiden. Das Schema-on-Read-Design verschiebt Datenmodellentscheidungen auf den Abfragezeitpunkt, reduziert den ETL-Aufwand und beschleunigt Projekteinführungen. Unternehmen mit steigendem Datenaufkommen schätzen, dass die Skalierung von Hadoop den Kauf zusätzlicher Knoten erfordert, anstatt aufwändige Upgrades durchzuführen. Für kostensensible kleine und mittelständische Unternehmen erschließen diese Wirtschaftlichkeitsvorteile fortschrittliche Analysen, die einst kapitalstarken Konzernen vorbehalten waren, und stärken die Attraktivität der Cloud-basierten Bereitstellung.
Integration von KI- und ML-Workloads in Hadoop-Ökosysteme
Pipelines für maschinelles Lernen gedeihen auf umfangreichen beschrifteten Datensätzen, die nativ in Hadoop-Clustern gespeichert sind. Die Verknüpfung von Google Cloud zwischen Vertex AI und Dataproc ermöglicht es, das Modelltraining direkt neben den Daten auszuführen, was Übertragungslatenzen und Egress-Kosten erheblich reduziert. Frameworks wie Spark MLlib und TensorFlow auf YARN nutzen verteilten Arbeitsspeicher und beschleunigen die Algorithmuskonvergenz. Anbieter integrieren AutoML, Beschleuniger für das Feature-Engineering und GPU-Scheduling, um Experimente zu vereinfachen. Da sich Anwendungsfälle von retrospektiven Dashboards hin zur Echtzeit-Mustererkennung verlagern, entwickelt sich Hadoop zur Staging-Plattform für iterative Modellentwicklung, -bewertung und -bereitstellung im großen Maßstab.
Analyse der Hemmnisse*
| Hemmnis | (~) % Auswirkung auf die CAGR-Prognose | Geografische Relevanz | Zeithorizont der Auswirkung |
|---|---|---|---|
| Akuter Mangel an Hadoop-Fachkräften und steile Lernkurven | -2.8% | National, besonders ausgeprägt im Mittleren Westen und Süden | Kurzfristig (≤ 2 Jahre) |
| Zunehmende Migration zu Cloud-Lakehouse-Plattformen, die On-Premise-Hadoop kannibalisieren | -3.2% | National, mit Schwerpunkt in technologieaffinen Regionen | Mittelfristig (2–4 Jahre) |
| Anhaltende Bedenken hinsichtlich Datensicherheit und Governance | -1.9% | National, mit Schwerpunkt in regulierten Branchen | Mittelfristig (2–4 Jahre) |
| Technische Altlasten bei Legacy-Clustern und hohe Wartungskosten | -2.1% | National, insbesondere bei frühen Anwenderorganisationen | Langfristig (≥ 4 Jahre) |
| Quelle: Mordor Intelligence | |||
Akuter Mangel an Hadoop-Fachkräften
Eine Studie des IEEE berichtete, dass 68 % der Unternehmen Schwierigkeiten haben, qualifizierte Hadoop-Fachkräfte einzustellen, wobei Stellen durchschnittlich 4,5 Monate unbesetzt bleiben. Das Ökosystem erfordert Kenntnisse in HDFS, YARN, MapReduce, Spark sowie Sicherheits-Frameworks wie Ranger und Knox. Die Umschulung von Datenbankadministratoren dauert häufig 12–18 Monate und verlangsamt die Bereitstellungsgeschwindigkeit. Regionale Unterschiede verschärfen den Druck: Unternehmen außerhalb erstklassiger Technologiezentren sehen sich mit Umzugsprämien konfrontiert, die die Kosteneinsparungen von Hadoop schmälern. Bootcamps und Universitätslehrpläne werden ausgebaut, können die Lücke jedoch möglicherweise nicht schnell genug schließen, was die kurzfristige Expansion des Hadoop-Marktes der Vereinigten Staaten belastet.
Migration zu Cloud-Lakehouse-Plattformen kannibalisiert traditionelle Hadoop-Cluster
Einheitliche Plattformen wie Databricks und Snowflake bündeln Speicherung, Analysen und Governance in einem einzigen Dienst und stellen die Komplexität der Mehrkomponentenarchitektur von Hadoop in Frage. Das Lakehouse-Konzept von Databricks, das Warehouse-Leistung auf Basis offener Datenformate bietet, spricht Teams an, die es leid sind, mehrere Engines zu optimieren.[3]Databricks, "Lakehouse-Referenzarchitektur," databricks.com Migrations-Toolkits, Rabattguthaben und Leistungs-Benchmarks verleiten Unternehmen dazu, ihre Plattform zu wechseln, anstatt On-Premise-Cluster zu modernisieren. Während viele Unternehmen eine hybride Koexistenz anstreben werden, könnten neue Workloads Hadoop vollständig umgehen, was mittelfristig zu einem reduzierten adressierbaren Ausgabenvolumen führt.
*Unsere Prognosen behandeln die Auswirkungen von Treibern und Einschränkungen als richtungsweisend und nicht additiv. Die Wirkungsprognosen berücksichtigen Basiswachstum, Mischungseffekte und Wechselwirkungen zwischen Variablen.
Segmentanalyse
Nach Komponente: Dienstleistungen gewinnen an Dynamik, während Software ihre zentrale Position behauptet
Software blieb dominant und erfasste im Jahr 2024 40,7 % der Ausgaben im Hadoop-Markt der Vereinigten Staaten, da Unternehmen Abonnements für Distributionssupport, Sicherheits-Patches und ergänzende Analysemodule erneuerten. Anbieter konzentrierten sich auf die Härtung von Funktionen, eine tiefere SQL-Kompatibilität und Cloud-native Paketierung, um installierte Basen zu erhalten.
Dienstleistungen skalieren jedoch schneller mit einer CAGR von 20,92 %, was die Präferenz der Führungsebene für schlüsselfertige Bereitstellung, Cluster-Optimierung und verwalteten Betrieb widerspiegelt. Cloudera erweiterte seinen Bereich professioneller Dienstleistungen im Jahr 2024 um 200 Berater, um dieser Beratungsnachfrage gerecht zu werden. Da regulatorische Verpflichtungen zunehmen, verlassen sich Käufer auf Systemintegratoren, die mit HIPAA, PCI-DSS und FedRAMP vertraut sind, um konforme Pipelines zu konfigurieren. Hardware hat sich auf Nischenanwendungen wie robuste Edge-Knoten beschränkt, was die Verlagerung von Kapitalausgaben hin zu dienstleistungsorientierten Betriebsmodellen im Hadoop-Markt der Vereinigten Staaten verstärkt.



Nach Bereitstellungsmodell: Cloud-Entwicklung stellt On-Premise-Ansprüche in Frage
On-Premise-Umgebungen repräsentierten im Jahr 2024 noch 52,8 % der Marktgröße des Hadoop-Marktes der Vereinigten Staaten, bedingt durch getätigte Investitionen, Datensouveränitätsanforderungen und latenzarme Anwendungskopplung. Finanzinstitute und Behörden des öffentlichen Sektors unterhalten häufig luftgespaltene Cluster aus Prüfungs- und Sicherheitsgründen.
Cloud-Alternativen beschleunigen sich mit einer CAGR von 21,3 % bis 2030, angetrieben durch serverloses EMR, automatisch skalierendes HDInsight und benutzerdefinierte Maschinentyp-Angebote von Google Dataproc. Diese Dienste beseitigen Kapazitätsplanungsprobleme und verkürzen Vorlaufzeiten von Monaten auf Stunden. Hybride Konzepte, bei denen sensible Datensätze On-Premise verbleiben, während Burst-Workloads in der Cloud ausgeführt werden, werden zur Norm. Die daraus resultierende architektonische Flexibilität stärkt die Ausgabenvielfalt im Hadoop-Markt der Vereinigten Staaten.
Nach Unternehmensgröße: Kleine und mittelständische Unternehmen verringern den Nutzungsrückstand
Großunternehmen hielten im Jahr 2024 einen Anteil von 65,1 % und nutzten umfangreiche Datenpools, um Betrugserkennung, kanalübergreifende Personalisierung und Lieferkettenoptimierung auf Multi-Petabyte-Clustern durchzuführen. Dedizierte Plattformteams setzen Service-Level-Ziele durch, die Hadoop als integralen Bestandteil unternehmenskritischer Prozesse erhalten.
Kleine und mittelständische Unternehmen sind die am schnellsten wachsende Gruppe mit einer CAGR von 20,7 %, angetrieben durch nutzungsbasierte Lizenzierung und vorlagengesteuerte Bereitstellungsassistenten. Microsoft HDInsight Essentials richtet sich an kleinere Unternehmen mit vorhersehbarem Batch-Bedarf und begrenztem Personal. Da kleine und mittelständische Unternehmen ihre Front-Office- und Back-Office-Workflows digitalisieren, wird Hadoop zum analytischen Rückgrat, das operative Daten in prädiktive Erkenntnisse umwandelt und damit die Durchdringung des Hadoop-Marktes der Vereinigten Staaten verbreitert.
Nach Endnutzerbranche: Gesundheitswesen führt die Wachstumsliste an
IT- und Telekommunikationsanbieter machten im Jahr 2024 30,02 % des Gesamtumsatzes aus und nutzten Hadoop für Echtzeit-Netzwerktelemetrie, Kundenerfahrungsanalysen und die Eindämmung von Abrechnungsbetrug. Die Latenztoleranz hat sich durch Spark Streaming verbessert und hält den Appetit der Branche auf verteiltes Computing aufrecht.
Das Gesundheitswesen und die Biowissenschaften sind mit einer CAGR von 22,3 % auf dem Weg, ihre Mitbewerber zu übertreffen, da genomische Sequenzierung, die Zusammenführung klinischer Studiendaten und Dashboards zur Bevölkerungsgesundheit eine kosteneffiziente Skalierung erfordern. Die zunehmend offene Haltung der US-amerikanischen Arzneimittelbehörde gegenüber Real-World-Evidence unterstreicht die Bedeutung der Compliance mit nachvollziehbarer Datenherkunft. Pharmazeutische Auftraggeber verlassen sich auf Hadoop, um elektronische Gesundheitsakten, Abrechnungsdaten und Sensordaten von Wearables zu erfassen, was den branchenspezifischen Schwung im Hadoop-Markt der Vereinigten Staaten verstärkt.
Geografische Analyse
Der Süden trug im Jahr 2024 38,31 % zum nationalen Umsatz bei, angetrieben durch ausgedehnte Rechenzentrumskorridore in Texas, North Carolina und Florida. Versorgungsanreize, niedrige Energiekosten und unternehmensfreundliche Steuerregelungen haben sowohl Hyperscaler als auch Unternehmensmieter angelockt. AWS fügte 2025 neue US-East-Verfügbarkeitszonen in North Carolina hinzu, was die regionale Latenz verbessert und das Vertrauen in Cloud-basierte Hadoop-Workloads stärkt.[4]Amazon Web Services, "US-East-Regionsexpansion 2025," amazon.com
Der Westen ist der Vorreiter mit einer CAGR von 21,5 % bis 2030. Das tiefe Talentreservoir des Silicon Valley, gepaart mit Risikokapitalunterstützung, erhält eine Pipeline von Datentechnik-Start-ups, die auf Hadoop-Grundlagen standardisieren. Datenschutzgesetze in Kalifornien, wie das CPRA, erhöhen die Investitionen in Governance-Tools und steigern indirekt die Ausgaben für Metadaten- und Sicherheitsmodule. Googles Expansionen in Oregon und Nevada priorisieren speicherintensive Instanzen, die auf Big-Data-Anwendungsfälle zugeschnitten sind, und stärken das regionale Cloud-Fundament.
Die Cluster im Nordosten und Mittleren Westen repräsentieren zusammen einen beträchtlichen Anteil, verankert durch die Konzentration von Finanzdienstleistungen in New York und den Fertigungsgürtel der Großen Seen. Die Einführung von Cloud-Zonen in Chicago senkt die Latenz für Kunden im Mittleren Westen, während New Yorker Fintechs Hadoop nutzen, um Echtzeit-Risiko- und Berichtsanforderungen zu erfüllen. Die Verfügbarkeit von Arbeitskräften und höhere Einrichtungskosten dämpfen die kurzfristige Beschleunigung, doch Modernisierungszuschüsse und öffentlich-private Innovationslabore zielen darauf ab, das Engagement im Hadoop-Markt der Vereinigten Staaten aufrechtzuerhalten.
Wettbewerbslandschaft
Der Wettbewerb vereint etablierte Unternehmensanbieter, Cloud-Hyperscaler und spezialisierte Disruptoren. Cloudera, IBM und Oracle stärken ihre Portfolios durch Sicherheitszertifizierungen, GPU-Beschleunigung und Observability-Suiten. Cloud-Anbieter nutzen Skaleneffekte, um verwaltetes Hadoop als Einstieg in umfassendere Datenplattform-Toolkits anzubieten, was den Preis- und Leistungswettbewerb intensiviert. Die Marktkonzentration bleibt moderat; die fünf größten Anbieter kontrollieren zusammen etwa 45 % des Umsatzes, was sowohl Konsolidierungsbestrebungen als auch Nischenmöglichkeiten fördert.
Aufstrebende Akteure fordern die Marktführerschaft etablierter Anbieter heraus. Das Lakehouse-Modell von Databricks und die Verarbeitung unstrukturierter Daten durch Snowflake ziehen schrittweise Workloads ab, indem sie die Einfachheit einer einzigen Plattform bieten. Patentanmeldungen rund um spaltenbasiertes Caching, Abfrageföderationen und Kubernetes-native Bereitstellung stiegen 2025 stark an, was auf ein Rennen um differenziertes geistiges Eigentum hindeutet.
Partnerschaften gedeihen als strategische Währung. Oracle unterstützt jetzt Multi-Cloud-Bereitstellungen seines Big-Data-Dienstes über AWS Direct Connect und Google Interconnect und hilft Kunden, die Anbietervielfalt anstreben. IBMs Übernahme von StreamSets führt automatisiertes Datenpipeline-Design ein und verringert die Onboarding-Hürden. Clouderas Investition von 150 Millionen USD in KI-gestützte Suchoberflächen zielt darauf ab, die Kundenabwanderung zu reduzieren, indem natürlichsprachliche Erkenntnisse in sein Ökosystem eingebettet werden. Insgesamt veranschaulichen diese Schritte einen Markt, der sich von reinen Durchsatzversprechen hin zu ergebnisorientierten Wertversprechen im Hadoop-Markt der Vereinigten Staaten wandelt.
Führende Unternehmen der Hadoop-Branche der Vereinigten Staaten
Cloudera, Inc.
Amazon Web Services, Inc.
Microsoft Corporation
IBM Corporation
Google LLC
- *Haftungsausschluss: Hauptakteure in keiner bestimmten Reihenfolge sortiert

Jüngste Branchenentwicklungen
- Oktober 2025: Cloudera kündigte eine Investition von 150 Millionen USD an, um generative KI-Abfragen und automatisierte Pipeline-Optimierung in seine Flaggschiff-Distribution zu integrieren.
- September 2025: Microsoft ermöglichte GPU-beschleunigte Cluster in Azure HDInsight für TensorFlow- und PyTorch-Workloads.
- August 2025: Amazon Web Services stellte EMR Serverless für Apache Spark vor und beseitigte damit den Verwaltungsaufwand für Cluster.
- Juli 2025: IBM erwarb StreamSets für 300 Millionen USD, um hybride Cloud-Datenintegrationsfähigkeiten voranzutreiben.
- Juni 2025: Oracle gab Partnerschaften mit Databricks und Snowflake bekannt und bietet integrierte Lakehouse-Lösungen an.


Berichtsumfang des Hadoop-Marktes der Vereinigten Staaten
| Software |
| Hardware |
| Dienstleistungen |
| On-Premise |
| Cloud |
| Hybrid |
| Großunternehmen |
| Kleine und mittelständische Unternehmen |
| BFSI |
| Einzel- und Konsumgüter |
| Gesundheitswesen und Biowissenschaften |
| IT und Telekommunikation |
| Fertigung |
| Sonstige Endnutzerbranchen |
| Nordosten |
| Mittlerer Westen |
| Süden |
| Westen |
| Nach Komponente | Software |
| Hardware | |
| Dienstleistungen | |
| Nach Bereitstellungsmodell | On-Premise |
| Cloud | |
| Hybrid | |
| Nach Unternehmensgröße | Großunternehmen |
| Kleine und mittelständische Unternehmen | |
| Nach Endnutzerbranche | BFSI |
| Einzel- und Konsumgüter | |
| Gesundheitswesen und Biowissenschaften | |
| IT und Telekommunikation | |
| Fertigung | |
| Sonstige Endnutzerbranchen | |
| Nach Region | Nordosten |
| Mittlerer Westen | |
| Süden | |
| Westen |


Im Bericht beantwortete Schlüsselfragen
Wie groß ist der Hadoop-Markt der Vereinigten Staaten im Jahr 2025?
Die Marktgröße des Hadoop-Marktes der Vereinigten Staaten beträgt im Jahr 2025 54,25 Milliarden USD.
Welche CAGR wird für die Hadoop-Ausgaben in den Vereinigten Staaten bis 2030 prognostiziert?
Die Ausgaben sollen zwischen 2025 und 2030 mit einer CAGR von 20,12 % wachsen.
Welche US-Region expandiert am schnellsten bei Hadoop-Bereitstellungen?
Für den Westen wird eine CAGR von 21,5 % prognostiziert, angetrieben durch das Innovationsökosystem des Silicon Valley.
Welche Branche wird voraussichtlich am schnellsten wachsen?
Für das Gesundheitswesen und die Biowissenschaften wird bis 2030 eine CAGR von 22,3 % prognostiziert.
Was ist das größte Hindernis für eine breitere Hadoop-Einführung?
Ein landesweiter Mangel an erfahrenen Hadoop-Fachkräften ist die führende Einschränkung, die zu Einstellungsverzögerungen und höheren Kosten führt.
Wie beeinflussen Cloud-Dienste die Hadoop-Einführung bei kleinen und mittelständischen Unternehmen?
Cloud-basierte Hadoop-als-Dienst-Angebote bieten nutzungsbasierte Skalierbarkeit und verwalteten Betrieb, sodass kleine und mittelständische Unternehmen Big-Data-Analysen ohne hohe Vorabinvestitionen einführen können.
Seite zuletzt aktualisiert am:




