Größe und Anteil des Marktes für Datenobservierbarkeit
Marktübersicht
| Studienzeitraum | 2020 - 2031 |
|---|---|
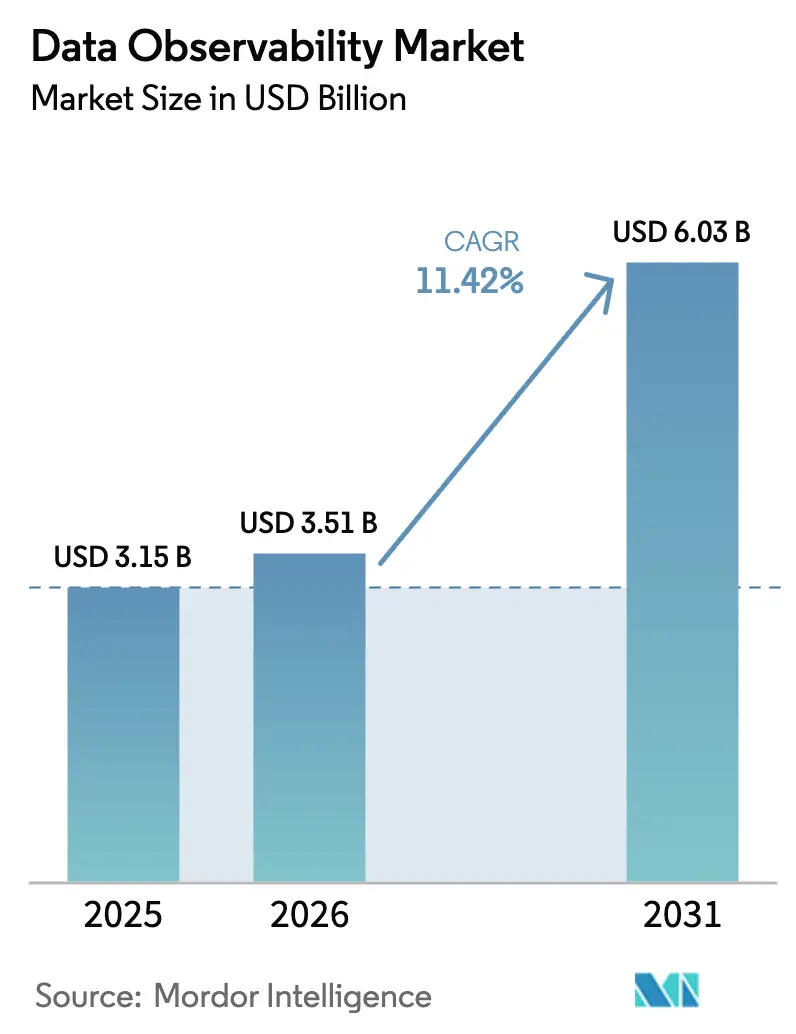
| Marktgröße (2026) | 3.51 Milliarden US-Dollar |
| Marktgröße (2031) | 6.03 Milliarden US-Dollar |
| Wachstumsrate (2026 - 2031) | 11.42% CAGR |
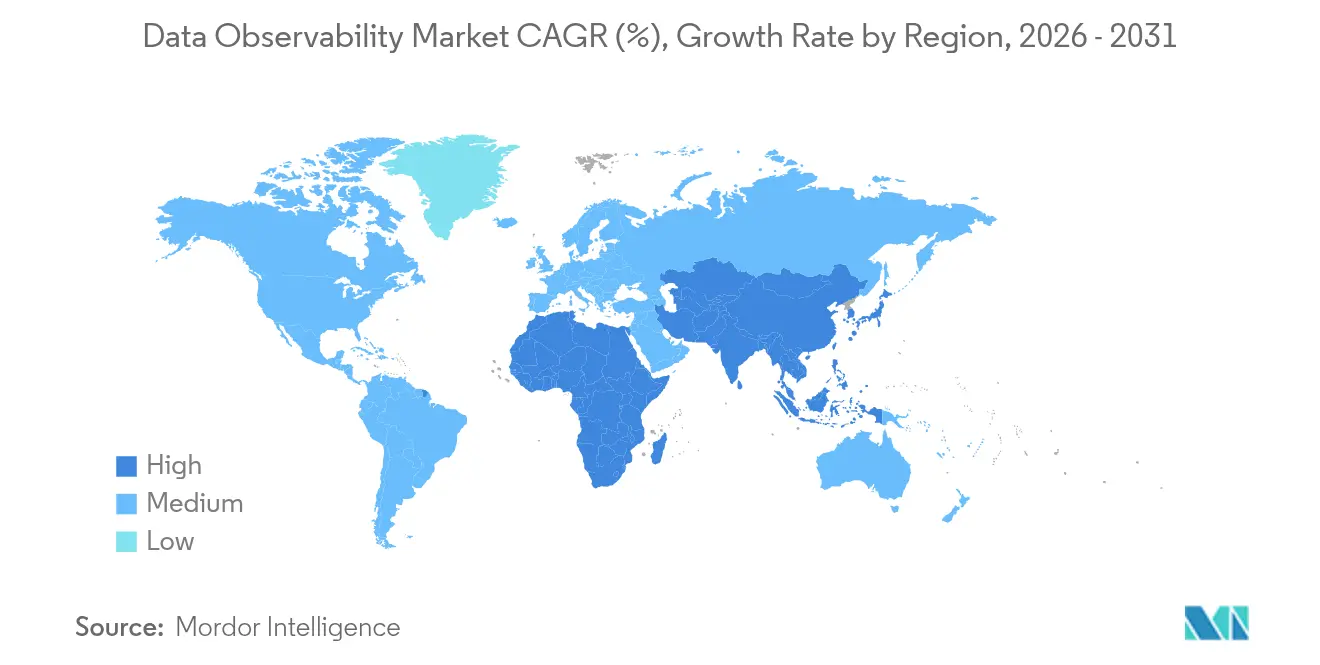
| Schnellstwachsender Markt | Asien-Pazifik |
| Größter Markt | Nordamerika |
| Marktkonzentration | Mittel |
Hauptakteure *Haftungsausschluss: Hauptakteure in keiner bestimmten Reihenfolge sortiert Bild © Mordor Intelligence. Wiederverwendung erfordert Namensnennung gemäß CC BY 4.0. | |
Analyse des Marktes für Datenobservierbarkeit von Mordor Intelligence
Die Größe des Marktes für Datenobservierbarkeit wird im Jahr 2026 auf 3,51 Milliarden USD geschätzt, ausgehend vom Wert des Jahres 2025 von 3,15 Milliarden USD, mit Projektionen für 2031 von 6,03 Milliarden USD, was einem Wachstum von 11,42 % CAGR über den Zeitraum 2026–2031 entspricht. Das Wachstum spiegelt eine entscheidende Verlagerung von reaktivem Monitoring hin zu proaktivem Datenzuverlässigkeits-Engineering wider, beschleunigt durch KI-Workloads, die kompromisslose Qualitätsstandards erfordern, sowie durch Compliance-Vorgaben wie den EU-KI-Act. Anbieter integrieren Echtzeit-Analysen, cloudnative Instrumentierung und KI-gestützte Ursachenanalyse, um Unternehmen dabei zu helfen, nachgelagerte Modellausfälle und Reputationsschäden zu vermeiden. Die Akzeptanz ist in Nordamerika am stärksten, doch die Nachfrage im asiatisch-pazifischen Raum steigt am schnellsten, da aufstrebende Volkswirtschaften neue Rechenzentren aufbauen und veraltete Systeme modernisieren. Strategische Akquisitionen unter Plattformanbietern signalisieren eine Marktreife, während Open-Source-Frameworks wie OpenTelemetry die Anbieterabhängigkeit mindern und die Akzeptanzbarrieren senken.
Wichtigste Erkenntnisse des Berichts
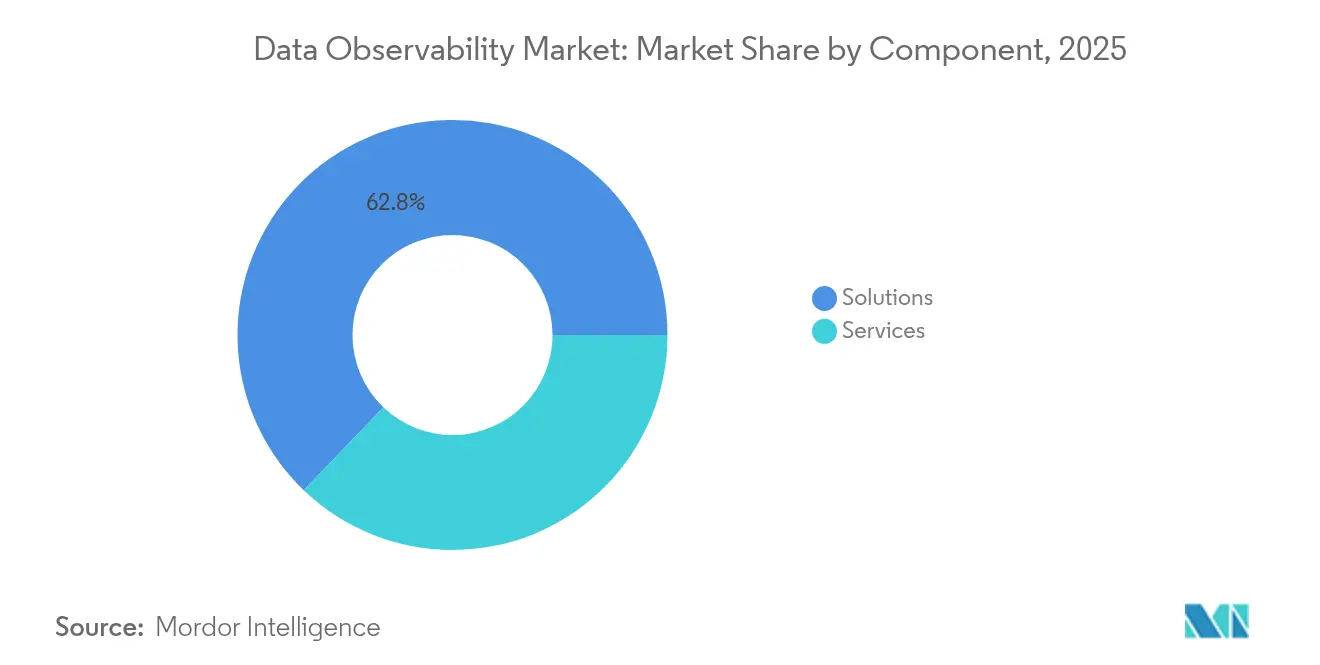
- Nach Komponente dominierten Lösungen mit einem Anteil von 62,84 % am Markt für Datenobservierbarkeit im Jahr 2025; Dienste werden voraussichtlich bis 2031 mit einer CAGR von 20,22 % wachsen.
- Nach Bereitstellungsmodell führte Public Cloud im Jahr 2025 mit einem Anteil von 69,55 %, während die Akzeptanz von Hybrid Cloud bis 2031 mit einer CAGR von 24,05 % prognostiziert wird.
- Nach Endnutzerbranche führte BFSI im Jahr 2025 mit einem Anteil von 22,05 %, während das Gesundheitswesen und die Biowissenschaften bis 2031 mit einer CAGR von 20,85 % wachsen sollen.
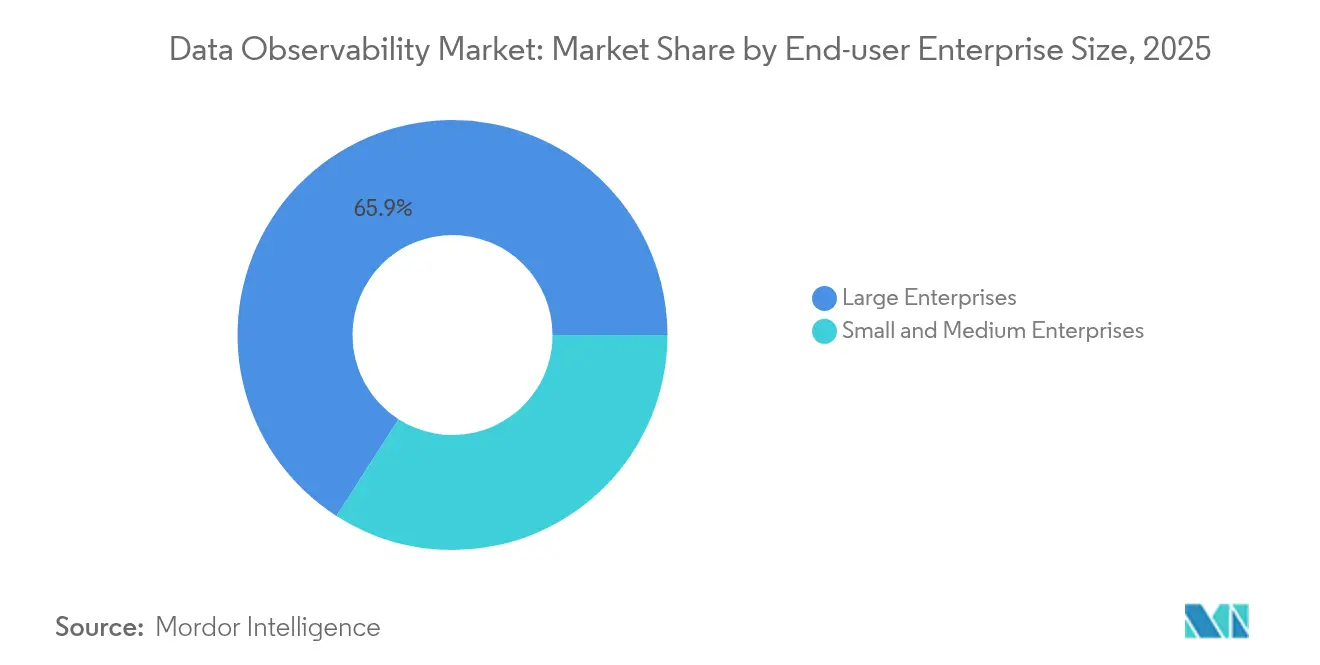
- Nach Endnutzer-Unternehmensgröße hielten Großunternehmen im Jahr 2025 einen Anteil von 65,92 %, während KMU bis 2031 mit einer CAGR von 17,55 % wachsen sollen.
- Nach Datenpipeline-Typ entfiel auf die Stapelverarbeitung ein Anteil von 53,60 % an der Marktgröße für Datenobservierbarkeit im Jahr 2025; Streaming/Echtzeit soll mit einer CAGR von 27,45 % wachsen.
- Nach Geografie behielt Nordamerika im Jahr 2025 einen Umsatzanteil von 38,12 %, während der asiatisch-pazifische Raum bis 2031 eine CAGR von 18,15 % erzielen soll.
Hinweis: Die Marktgrößen- und Prognosezahlen in diesem Bericht werden mithilfe des proprietären Schätzrahmens von Mordor Intelligence erstellt und mit den neuesten verfügbaren Daten und Erkenntnissen bis 2026 aktualisiert.
Globale Trends und Erkenntnisse zum Markt für Datenobservierbarkeit
Analyse der Auswirkungen von Treibern*
| Treiber | (~) % Auswirkung auf die CAGR-Prognose | Geografische Relevanz | Zeithorizont der Auswirkung |
|---|---|---|---|
| Beschleunigung cloudnativer Datenpipelines | +2.8% | Global, Nordamerika und asiatisch-pazifischer Raum | Mittelfristig (2–4 Jahre) |
| Verbreitung von KI/ML-Anforderungen an zuverlässige Daten | +3.2% | Global, Nordamerika und EU | Kurzfristig (≤ 2 Jahre) |
| Zunehmende Compliance mit Datenverwaltungs-Frameworks | +2.1% | EU und Nordamerika, Ausweitung auf den asiatisch-pazifischen Raum | Langfristig (≥ 4 Jahre) |
| Aufstieg von Datenverträgen zur Förderung proaktiver Observierbarkeit | +1.8% | Nordamerika und EU als Vorreiter, globale Expansion | Mittelfristig (2–4 Jahre) |
| Wachsende Akzeptanz von LLMOps mit tiefem Lineage-Bedarf | +2.5% | Globale Technologiezentren | Kurzfristig (≤ 2 Jahre) |
| OpenTelemetry-Standardisierung zur Reduzierung der Anbieterabhängigkeit | +1.9% | Global | Mittelfristig (2–4 Jahre) |
| Quelle: Mordor Intelligence | |||
Beschleunigung cloudnativer Datenpipelines
Unternehmen, die Multi-Cloud-Strategien umsetzen, benötigen Observierbarkeits-Tools, die Microservices, Ereignisströme und serverlose Funktionen nahezu in Echtzeit instrumentieren können. Siebenundneunzig Prozent der globalen Unternehmen betreiben heute vernetzte Cloud-Umgebungen, was fragile, selbst erstellte Monitore offenlegt, die knotenübergreifende Anomalien übersehen[1]VMware Tanzu, "State of Cloud-Native Survey 2025," tanzu.vmware.com. Das Telemetrievolumen steigt jährlich um 35 %, was Käufer dazu zwingt, intelligentes Sampling, abgestufte Aufbewahrung und Kostenanalysen zu priorisieren. Einheitliche Steuerungsebenen, die Metriken, Traces und Lineage über Kubernetes-Cluster hinweg aggregieren, liefern greifbaren ROI, indem sie die mittlere Zeit bis zur Lösung verkürzen und datengetriebene KI-Modellabweichungen vermeiden.
Verbreitung von KI/ML-Anforderungen an zuverlässige Trainingsdaten
Generative KI-Modelle verstärken die Kosten schlechter Datenqualität; das durchschnittliche Unternehmen erlitt im Jahr 2024 Verluste von 12,9 Millionen USD durch unentdeckte Fehler. LLMOps-Teams operationalisieren nun den MOOD-Stack – Modelle, Observierbarkeit, Orchestrierung, Daten – um kontinuierliche Lineage-Validierung und Bias-Erkennung durchzuführen. Organisationen, die mehr als 1.000 gleichzeitige Modelle verwalten, sind auf ereignisgesteuerte Warnmeldungen angewiesen, um Schema-Verschiebungen vor Beginn der Trainingszyklen zu erkennen. Standardisierungsbemühungen rund um OpenTelemetry für KI-Workloads gewinnen Konsens, wobei 76 % der Anwender die Anbieterneutralität als zentralen Vorteil nennen.
Zunehmende Compliance mit Datenverwaltungs-Frameworks
Der EU-KI-Act stuft Algorithmen im Gesundheitswesen, im Finanzwesen und im Transportwesen als hochriskant ein und verpflichtet Verantwortliche dazu, detaillierte Protokolle über Datenherkunft, Vorverarbeitungsschritte und Zugriffshistorie zu führen. Nichteinhaltung kann Bußgelder von bis zu 4 % des weltweiten Umsatzes auslösen, was Unternehmensinvestitionen in prüfungsbereite Observierbarkeits-Baselines katalysiert [2]Amt für Veröffentlichungen der Europäischen Union, "Verordnung (EU) 2024/1234 über harmonisierte Regeln für künstliche Intelligenz," eur-lex.europa.eu. Parallel dazu verweisen US-amerikanische Regulierungsbehörden auf kontinuierliches Monitoring in aufkommenden KI-Risikomanagement-Frameworks, während das NIST ein Datenverwaltungsprofil entwirft, das Lineage, Reproduzierbarkeit und Qualitätsbewertung als zentrale Kontrollen hervorhebt.
Aufstieg von Datenverträgen zur Förderung proaktiver Observierbarkeit
Formale Vereinbarungen zwischen Datenproduzenten und -konsumenten stehen nun im Mittelpunkt föderierter Architekturen. Schemata, Aktualitätsschwellenwerte und Qualitäts-SLAs werden in CI/CD-Pipelines kodifiziert; automatisierte Scanner kennzeichnen Abweichungen zum Zeitpunkt des Commits und vermeiden so nachgelagerte Dienstausfälle. Frühe Anwender berichten von bis zu 40 % weniger Incident-Tickets nach der Vertragsdurchsetzung, wodurch Engineering-Aufwand von der Fehlerbehebung hin zur Feature-Entwicklung umgeleitet wird. Anbieter integrieren Vertrags-Compliance-Ansichten in Lineage-Graphen, damit Betreiber Verletzungskaskaden über Geschäftsbereiche hinweg visualisieren können.
Analyse der Auswirkungen von Hemmnissen*
| Hemmnis | (~) % Auswirkung auf die CAGR-Prognose | Geografische Relevanz | Zeithorizont der Auswirkung |
|---|---|---|---|
| Anhaltende Datenschutz- und Datensouveränitätsbedenken | -1.5% | Global, ausgeprägt in der EU und im asiatisch-pazifischen Raum | Langfristig (≥ 4 Jahre) |
| Integrationskomplexität über heterogene Stacks hinweg | -2.2% | Global, Großunternehmen | Mittelfristig (2–4 Jahre) |
| Fachkräftemangel im Bereich Data Engineering | -1.8% | Global | Mittelfristig (2–4 Jahre) |
| Kostenoptimierungsdruck bei der Telemetrieaufbewahrung | -1.6% | Global | Kurzfristig (≤ 2 Jahre) |
| Quelle: Mordor Intelligence | |||
Anhaltende Datenschutz- und Datensouveränitätsbedenken
Strenge Lokalisierungsgesetze in China und Indien schränken den ausgehenden Telemetrieverkehr ein und zwingen Unternehmen dazu, regionale Sammler mit lokaler Speicherung und Anonymisierungsschichten vor der zentralen Aggregation einzusetzen. Widersprüchliche Frameworks wie DSGVO, CCPA und Brasiliens LGPD schaffen multilaterale Genehmigungsworkflows, die Einführungen verlangsamen und Compliance-Budgets aufblähen. Edge Computing verlagert die Verarbeitung näher an die Datenquellen, doch Betreiber müssen dennoch eine lückenlose Transparenz nachweisen, ohne sensible Daten über Grenzen hinweg zu übertragen.
Integrationskomplexität über heterogene Stacks hinweg
Unternehmen jonglieren mit fünf oder mehr Monitoring-Tools, denen gemeinsame Schemata fehlen, was zu Dashboard-Wildwuchs und blinden Flecken führt. Legacy-Mainframes, proprietäre Middleware und polyglotte Datenbanken erfordern eine individuelle Instrumentierung, die knappe Plattformteams strapaziert. Hybride Topologien erfordern die Korrelation von lokalen SNMP-Metriken mit SaaS-Trace-Daten, eine Aufgabe, die heute nur wenige Organisationen automatisieren. Die Akzeptanz von OpenTelemetry verringert die Reibung, doch die Qualifikationslücke bleibt bestehen; 48 % der Unternehmen berichten von unbesetzten Stellen im Bereich Observierbarkeits-Engineering, was die Zeit bis zur Wertschöpfung verlängert.
*Unsere Prognosen behandeln die Auswirkungen von Treibern und Einschränkungen als richtungsweisend und nicht additiv. Die Wirkungsprognosen berücksichtigen Basiswachstum, Mischungseffekte und Wechselwirkungen zwischen Variablen.
Segmentanalyse
Nach Komponente: Dienste steigen inmitten der Plattformreife
Lösungen behielten im Jahr 2025 einen Anteil von 62,84 % am Umsatz, was darauf hindeutet, dass Full-Stack-Plattformen, Datenqualitätsmonitore und Lineage-Graphen das wesentliche Werkzeugset im Kern des Marktes für Datenobservierbarkeit bilden. Dienste expandieren mit einer CAGR von 20,22 %, da Unternehmen schlüsselfertige Bereitstellungen suchen, die Integrationsrisiken mindern und Compliance-Audits beschleunigen. Professionelle Beratungsleistungen konzentrieren sich auf die Zuordnung von Datenverträgen zu geschäftlichen SLAs, während verwaltete Angebote einen 24-Stunden-Betrieb an 7 Tagen der Woche, automatisierte Upgrades und verbrauchsbasierte Abrechnung liefern.
KI-gestützte Anomalieerkennung entwickelt sich von einem Add-on zu einer Standardfunktion, wobei Anbieter Vektorsuche und kausale Inferenz integrieren, um führende Indikatoren für Abweichungen zu erkennen. Die Nachfrage nach Kosten- und Nutzungsanalysen wächst ebenfalls, da die Vorschriften zur Telemetrieaufbewahrung strenger werden. Lineage-Module integrieren nun Bias-Erkennungswerte, um sich am EU-KI-Act auszurichten. Der Dienstleistungsboom unterstreicht die Marktreife: Kunden erkennen, dass spezialisierte Partner die Einführungszeit im Vergleich zu internen Entwicklungen um die Hälfte verkürzen, wodurch Ingenieure für die Produktentwicklung statt für die Wartung von Tools freigestellt werden.
Notiz: Segmentanteile aller einzelnen Segmente sind nach dem Berichtskauf verfügbar


Nach Bereitstellungsmodell: Hybrid Cloud entwickelt sich zur strategischen Wahl
Public Cloud erfasste im Jahr 2025 69,55 % der Ausgaben, da SaaS-Modelle die Kapitalkosten für Zeitreihendatenspeicher und Tracing-Backends eliminieren. Dennoch adressieren Hybridstrategien, die jährlich um 24,05 % wachsen sollen, Anforderungen an Datenresidenz, Zero-Trust-Sicherheit und latenzempfindliche KI-Inferenz vor Ort. Anbieter reagieren mit bereitstellungsagnostischen Agenten und Steuerungsebenen, die identische Dashboards liefern, unabhängig davon, ob Sammler zu regionalen SaaS-Clustern oder zu selbst gehosteten Speichern hinter Firewalls streamen.
Edge-Knoten erhöhen die Komplexität: Observierbarkeitsverkehr muss eingeschränkte Bandbreitenverbindungen durchqueren, ohne an Granularität einzubüßen. Käufer priorisieren Komprimierung, lokales Caching und adaptives Sampling, um Egress-Gebühren zu begrenzen.
Nach Endnutzerbranche: Gesundheitswesen führt die digitale Transformation an
BFSI bleibt ein starker Ausgabenbereich mit einem Umsatzanteil von 22,05 %, wobei Betrugsmodelle und Basel-Compliance die nahezu echtzeitbasierte Anomalieerkennung vorantreiben. Das Gesundheitswesen und die Biowissenschaften hingegen entwickeln sich mit einer CAGR von 20,85 % – dem steilsten aller Sektoren – vorangetrieben durch Telemedizin, elektronische Gesundheitsakten und KI-gestützte Diagnostik, die keine Datenabweichungen tolerieren können. Lineage-Graphen bilden Quell-zu-Senke-Transformationen ab, um FDA-Leitlinien für klinische Entscheidungen und ISO-13485-Qualitätsmanagement-Audits zu erfüllen.
Die Fertigungsindustrie nutzt Streaming-Sensortelemetrie für die vorausschauende Wartung, während der Einzelhandel Observierbarkeit einsetzt, um sicherzustellen, dass Personalisierungsalgorithmen genaue Bestands- und Clickstream-Feeds erhalten. Jede Branche priorisiert domänenspezifische Erweiterungen – HIPAA-Schwärzungsrichtlinien im Gesundheitswesen, FIX-Protokoll-Parser in den Kapitalmärkten – was die Spezialisierung der Anbieter unterstützt.
Nach Endnutzer-Unternehmensgröße: KMU treiben die Demokratisierung voran
Großunternehmen hielten im Jahr 2025 65,92 % der Ausgaben, da sie die weitläufigen Datenbestände betreiben, die das höchste Compliance-Risiko erzeugen. Kleine und mittlere Unternehmen werden voraussichtlich mit einer CAGR von 17,55 % wachsen, da SaaS-Lizenzierung, automatische Instrumentierung und nutzungsbasierte Tarife historische Barrieren beseitigen. Großunternehmen kämpfen weiterhin mit heterogenen Beständen und strengen Anforderungen an souveräne Clouds und entscheiden sich häufig für hybride Sammler und erstklassige Dienstleistungsengagements. Der Fachkräftemangel ist bei KMU ausgeprägter; daher bündeln Anbieter assistentengesteuerte Richtlinien-Builder und automatisierte Ursachenerkenntnisse, die den Bedarf an fest angestellten Site-Reliability-Engineers überflüssig machen.
Zweiundsiebzig Prozent der KMU treffen strategische Entscheidungen bereits auf Basis von Daten, und 18 % haben generative KI innerhalb eines Jahres nach dem Start von ChatGPT eingeführt, was Qualitätsrisiken verstärkt. SaaS-Observierbarkeits-Konsolen mit geführter Einrichtung verkürzen die Bereitstellung von Wochen auf Stunden, während voreingestellte Dashboards Geschäftsanwendern helfen, Anomalieereignisse ohne tiefgreifende DevOps-Kenntnisse zu interpretieren.
Notiz: Segmentanteile aller einzelnen Segmente sind nach dem Berichtskauf verfügbar
Nach Datenpipeline-Typ: Echtzeitverarbeitung transformiert den Betrieb
Batch-Workflows behielten im Jahr 2025 einen Anteil von 53,60 %, doch Streaming-Pipelines beschleunigen sich mit einer CAGR von 27,45 %, da Organisationen sofortige Personalisierung und operationale KI anstreben. Apache-Kafka-Cluster fungieren nun sowohl als Telemetrie-Transport als auch als Analyse-Engine, wobei Unternehmen eine um 40 % schnellere Incident-Lösung angeben, wenn Echtzeit-Observierbarkeit vorhanden ist.
Hybride Lambda-Muster verbinden Batch-Dauerhaftigkeit mit Streaming-Agilität und erfordern eine Instrumentierung, die Spark-Jobs, Flink-Streams und Objekt-Speicher-Lakehouses zusammenführt. Edge Computing verlagert die Inferenz in Fabriken und Verkaufsstellen, was latenzarme Warnmeldungen unerlässlich macht. Anbieter bieten leichtgewichtige Sammler an, die offline arbeiten und sich synchronisieren, sobald die Verbindung wiederhergestellt ist, um eine kontinuierliche Lineage trotz intermittierender Verbindungen sicherzustellen.
Geografische Analyse
Nordamerika erzielte im Jahr 2025 38,12 % der Umsätze dank reifer Hyperscale-Cloud-Regionen, früher KI-Akzeptanz und robuster Regulierung des Finanzsektors. Unternehmen priorisieren SOC-2-fähige Observierbarkeits-Stacks und integrieren Lineage-Tracker in Sarbanes-Oxley-Audit-Workflows. Bundesbehörden erproben KI-Risikomanagement-Frameworks, die explizit eine kontinuierliche Datenqualitätsbewertung fordern, was die Nachfrage im öffentlichen Sektor ankurbelt.
Der asiatisch-pazifische Raum ist die am schnellsten wachsende Region mit einer prognostizierten CAGR von 18,15 %, angetrieben durch den Aufbau neuer Rechenzentren in Indien, Indonesien und Vietnam. Staatliche Fördermittel fördern die KI-Akzeptanz für Smart-City- und Industrie-4.0-Programme und machen Observierbarkeit zu einem Teil der Ausschreibungsanforderungen. Die Tool-Fragmentierung bleibt jedoch hoch; Unternehmen im asiatisch-pazifischen Raum betreiben im Median neun Monitoring-Produkte, was dem doppelten globalen Durchschnitt entspricht und die Ausfallkosten auf jährlich 19,07 Millionen USD treibt. Anbieter, die End-to-End-Suiten mit lokalem Sprachsupport und verbrauchsbasierter Preisgestaltung anbieten, gewinnen Marktanteile.
Europa ist stabil, aber compliance-intensiv: DSGVO und EU-KI-Act erhöhen die Budgets für Datenobservierbarkeit trotz makroökonomischer Vorsicht. Finanzregulatoren fordern Echtzeit-Dashboards der Eingaben für den algorithmischen Handel und zwingen Banken dazu, jede Schema-Änderung und jeden Pipeline-Ausfall zu protokollieren. Datensouveränitätsregeln fördern die Akzeptanz regionaler SaaS-Cluster in Frankfurt, Paris und Mailand, während grenzüberschreitende Fragmentierung die Tool-Konsolidierung erschwert. Lateinamerikanische und afrikanische Märkte befinden sich noch in einer früheren Phase, zeigen jedoch eine steigende SaaS-Akzeptanz, da Telekommunikationsbetreiber 5G-Backbones aufbauen und öffentliche Cloud-Zugänge erweitern. Lokalisierte Compliance-Frameworks wie Brasiliens LGPD spiegeln DSGVO-Bestimmungen wider und beschleunigen die Nachfrage nach End-to-End-Lineage-Trackern, die Bewertungen vereinfachen. Partnerschaften mit regionalen Systemintegratoren sind für Anbieter, die in diesen Märkten expandieren, von entscheidender Bedeutung.

Wettbewerbslandschaft
Der Markt für Datenobservierbarkeit ist mäßig konsolidiert. Datadogs Übernahme von Metaplane für 23 Millionen USD ergänzt sein APM-Erbe um Schema-Drift-Erkennung und signalisiert eine Plattformkonvergenzstrategie [5]Datadog, "Datadog Acquires Metaplane to Expand Data Observability Capabilities," datadoghq.com. ClickHouse übernahm HyperDX, um spaltenbasierte Analysen mit Session-Replay in einem Open-Source-Stack zu verbinden und preissensible Käufer anzusprechen. Snowflake investierte in Ökosystem-Startups, um die Telemetrie-Aufnahme in seine Daten-Cloud zu vertiefen, während Dynatrace Grail-Lakehouse-Erweiterungen einführte, die Protokolle und Lineage unter einem einheitlichen Schema normalisieren.
Die Wettbewerbsdifferenzierung dreht sich um KI-Automatisierung, Einhaltung offener Standards und TCO-Management. Reine Anbieter wie Monte Carlo und Acceldata setzen verstärkt auf probabilistische Anomaliemodelle und domänenspezifische Datengesundheits-Dashboards. Etablierte APM-Suiten betonen einheitliche Lizenzierung und bereichsübergreifende Korrelation, die Anwendungs-, Infrastruktur- und Datenschichten umfasst. Cloud-Dienstanbieter integrieren native Sammler in verwaltete Warehouses und ermöglichen so eine Ein-Klick-Einbindung, werfen aber Fragen zur Portabilität auf.
Zu den Chancen in unerschlossenen Bereichen gehören Edge-Observierbarkeit an satellitenverbundenen Standorten, Echtzeit-Vertragsvalidierung für dezentralisierte Daten-Meshes und vertikale Lösungen, die regulatorische Workflows kapseln. Verbrauchsbasierte Preisgestaltung und Open-Core-Pakete ermöglichen es Herausforderer-Marken, kostenbewusste Segmente zu durchdringen, insbesondere bei KMU und Käufern in aufstrebenden Märkten. Die zunehmende Akzeptanz von OpenTelemetry senkt die Wechselkosten und zwingt Anbieter dazu, bei der Genauigkeit von Erkenntnissen, der Behebungsanleitung und Ökosystem-Partnerschaften statt bei proprietären Agenten zu konkurrieren.
Marktführer im Bereich Datenobservierbarkeit
Dynatrace LLC.
IBM Corporation
Datadog, Inc.
Splunk Inc.
Monte Carlo Data Inc.
- *Haftungsausschluss: Hauptakteure in keiner bestimmten Reihenfolge sortiert

Jüngste Branchenentwicklungen
- April 2025: Monte Carlo lancierte KI-Agenten, die Monitoring-Regeln generieren und Ursachen autonom diagnostizieren.
- April 2025: Datadog übernahm Metaplane und fügte seiner Observierbarkeits-Cloud ein End-to-End-Datenqualitätsmonitoring hinzu.
- März 2025: Actian stellte Actian Data Observability vor und setzt KI ein, um die Anomalieerkennung zu automatisieren und Lösungszyklen zu beschleunigen.
- März 2025: ClickHouse erwarb HyperDX, um Session-Replay, Protokolle, Metriken und Traces in seine Open-Source-Plattform zu integrieren.


Rahmen der Forschungsmethodik und Umfang des Berichts
Marktdefinitionen und wichtige Abdeckung
Unsere Studie definiert den Markt für Datenobservierbarkeit als alle kommerziell verkauften Software- und zugehörigen verwalteten Dienstleistungsangebote, die Datenqualität, Lineage und Pipeline-Leistung in lokalen, Cloud- und Hybridumgebungen überwachen, verfolgen und diagnostizieren. Datenplattformen für Zuverlässigkeit, Schema-Drift-Monitore, Anomalieerkennungs-Tools und automatisierte Warnmeldungs-Engines sind vollständig in diesem Umfang enthalten.
Ausschluss aus dem Umfang: Eigenständige Tools für das Anwendungsleistungsmanagement oder die Protokollanalyse, denen eine explizite Observierbarkeit auf Datenschicht-Ebene fehlt, sind nicht abgedeckt.
Segmentierungsübersicht
- Nach Komponente
- Lösungen
- Plattform
- Datenqualitätsmonitoring
- Lineage und Katalogisierung
- Nutzungs- und Kostenanalyse
- Dienste
- Professional Services
- Verwaltete Dienste
- Lösungen
- Nach Bereitstellungsmodell
- Public Cloud (SaaS)
- Private Cloud
- Hybrid Cloud
- Nach Endnutzerbranche
- BFSI
- IT und Telekommunikation
- Regierung und öffentlicher Sektor
- Energie und Versorgungsunternehmen
- Fertigung
- Gesundheitswesen und Biowissenschaften
- Einzelhandel und Konsumgüter
- Medien und Unterhaltung
- Logistik und Transport
- Nach Endnutzer-Unternehmensgröße
- Großunternehmen
- Kleine und mittlere Unternehmen
- Nach Datenpipeline-Typ
- Stapelverarbeitung
- Streaming / Echtzeit
- Lambda / Hybrid
- Nach Geografie
- Nordamerika
- Vereinigte Staaten
- Kanada
- Mexiko
- Südamerika
- Brasilien
- Argentinien
- Übriges Südamerika
- Europa
- Deutschland
- Vereinigtes Königreich
- Frankreich
- Italien
- Spanien
- Russland
- Übriges Europa
- Asiatisch-pazifischer Raum
- China
- Japan
- Indien
- Südkorea
- Australien und Neuseeland
- Übriger asiatisch-pazifischer Raum
- Naher Osten und Afrika
- Naher Osten
- Saudi-Arabien
- Vereinigte Arabische Emirate
- Türkei
- Übriger Naher Osten
- Afrika
- Südafrika
- Nigeria
- Ägypten
- Übriges Afrika
- Naher Osten
- Nordamerika
Detaillierte Forschungsmethodik und Datenvalidierung
Desk Research
Wir haben grundlegende Metriken aus öffentlichen Quellen wie Eurostat, US-Volkszählungs-IKT-Erhebungen, den OECD-Ausblicken zur digitalen Wirtschaft und Branchenverbänden wie der Cloud Native Computing Foundation gesammelt. Regulatorische Texte (zum Beispiel der EU-KI-Act), Patentanalysen von Questel und Unternehmens-10-Ks lieferten Trendsignale zu Akzeptanz, Preisgestaltung und Ausgaben. Zusätzlicher Kontext zu den Bereitstellungszahlen in Unternehmen floss über Abonnementdatenbanken wie D&B Hoovers und Dow Jones Factiva ein. Die hier zitierten Quellen veranschaulichen, ohne den breiteren Satz zu erschöpfen, den wir zur Bestätigung und Lückenfüllung durchforstet haben.
In einem zweiten Durchgang wurden Rohindikatoren, Kapazitätslieferungen von Cloud-Data-Warehouses, Spark-Workload-Jobs und OpenTelemetry-Download-Volumen den im Inhaltsverzeichnis aufgezeigten Segmentierungsgrenzen zugeordnet, um sicherzustellen, dass die Desk-Research-Eingaben den Umfang des Berichts widerspiegeln.
Primärforschung
Mordor-Analysten führten Interviews mit Cloud-Architekten, Datenplattform-Leitern und Observierbarkeits-Produktmanagern in Nordamerika, Europa und dem asiatisch-pazifischen Raum durch. Diese Gespräche validierten Preisspannen, durchschnittliche Pipeline-Anzahlen pro Unternehmen und aufkommende Kaufauslöser, auf die Sekundärquellen nur andeutungsweise hinwiesen.
Marktgrößenbestimmung und Prognose
Wir haben einen Top-down-Nachfragepool auf Basis der globalen Unternehmensausgaben für Analysen erstellt und Anteile nach Pipeline-Prävalenz und Verhältnissen der Anzahl von Data Engineers zugeteilt, die dann durch Stichproben von Anbieter-Durchschnittsverkaufspreisen multipliziert mit Bereitstellungszahlen einem Stresstest unterzogen werden. Schlüsselvariablen wie Cloud-Migrationsraten, KI-Modell-Akzeptanz, Akzeptanz offener Telemetriestandards und mittlere Datenfehler-Vorfälle pro TB treiben das Modell an. Multivariate Regression verknüpft diese Eingaben mit Umsatzergebnissen und projiziert sie bis 2030, während kleine Bottom-up-Gegenprüfungen aus Lieferanten-Rollups Überschreitungen dämpfen und Datenlücken schließen.
Datenvalidierung und Aktualisierungszyklus
Ergebnisse werden Varianzprüfungen gegenüber unabhängigen Ausgabenindizes unterzogen; Anomalien veranlassen eine erneute Überprüfung durch Analysten vor der Freigabe. Mordor Intelligence aktualisiert jährlich und gibt Zwischenrevisionen heraus, wenn wichtige Anbieterprognosen oder regulatorische Änderungen die Nachfrageaussichten verändern.
Warum Mordors Baseline für Datenobservierbarkeit sichere Entscheidungen ermöglicht
Veröffentlichte Zahlen unterscheiden sich, weil Unternehmen unterschiedliche Funktionsumfänge, Umrechnungswährungen und Aktualisierungsrhythmen wählen. Einige zählen nur Softwarelizenzen, während andere Beratungsstunden einbeziehen; einige stützen sich noch auf Annahmen zur Akzeptanz vor der Cloud-Ära.
Zu den wichtigsten Treibern von Abweichungen gehören hier (a) engerer Serviceumfang, (b) Stichproben aus einer einzigen Region, die globale Gesamtwerte verzerren, und (c) aggressive oder konservative Pipeline-Wachstumsmultiplikatoren, die nicht durch Experteninterviews getestet wurden. Unsere disziplinierte Umfangsausrichtung und der jährliche Modellneuaufbau minimieren solche Abweichungen.
Benchmark-Vergleich
| Marktgröße | Anonymisierte Quelle | Primärer Treiber der Abweichung |
|---|---|---|
| 3,15 Mrd. USD (2025) | ||
| 2,37 Mrd. USD (2024) | Globale Unternehmensberatung A | Schließt verwaltete Dienste und Hybridbereitstellungen aus |
| 2,94 Mrd. USD (2025) | Branchenverband B | Verwendet festen Durchschnittsverkaufspreis, lässt Nachfrage im asiatisch-pazifischen Mittelmarkt außer Acht |
| 2,30 Mrd. USD (2023) | Regionale Unternehmensberatung C | Veraltetes Basisjahr und begrenzte Primärvalidierung |
Diese Kontraste zeigen, dass unser ausgewogener Variablensatz, zeitnahe Aktualisierungen und die Zwei-Wege-Validierung Entscheidungsträgern eine transparente, wiederholbare und damit zuverlässigere Marktbasis bieten.


Im Bericht beantwortete Schlüsselfragen
Wie groß ist der aktuelle Markt für Datenobservierbarkeit?
Der Markt für Datenobservierbarkeit hat im Jahr 2026 einen Wert von 3,51 Milliarden USD und soll bis 2031 einen Wert von 6,03 Milliarden USD erreichen.
Welche Region wächst am schnellsten?
Der asiatisch-pazifische Raum expandiert mit einer CAGR von 18,15 %, angetrieben durch den raschen digitalen Wandel und neue Rechenzentrumskapazitäten.
Warum übertreffen Dienste Lösungen beim Wachstum?
Dienste wachsen mit einer CAGR von 20,22 %, da Organisationen verwaltete Bereitstellungen bevorzugen, die Integrationskomplexität und Fachkräftemangel überwinden.
Wie beeinflusst der EU-KI-Act die Ausgaben für Observierbarkeit?
Der Act schreibt eine umfassende Daten-Lineage und Qualitätsprotokollierung für hochriskante KI-Systeme vor und zwingt Unternehmen dazu, in prüfungsbereite Observierbarkeits-Frameworks zu investieren.
Welches Bereitstellungsmodell verzeichnet das höchste Wachstum?
Hybrid Cloud führt das zukünftige Wachstum mit einer CAGR von 24,05 % an, da Unternehmen die Skalierbarkeit der Public Cloud mit lokalen Anforderungen an die Datensouveränität in Einklang bringen.
Wie gestaltet OpenTelemetry den Wettbewerb unter Anbietern?
Die breite Akzeptanz von OpenTelemetry standardisiert die Instrumentierung, senkt die Wechselkosten und zwingt Anbieter dazu, bei der Genauigkeit von KI-Analysen statt bei proprietären Agenten zu konkurrieren.
Seite zuletzt aktualisiert am:




