Marktgröße und Marktanteil im Bereich KI im Moleküldesign
Marktübersicht
| Studienzeitraum | 2020 - 2031 |
|---|---|
| Marktgröße (2026) | 2.04 Milliarden US-Dollar |
| Marktgröße (2031) | 6.37 Milliarden US-Dollar |
| Wachstumsrate (2026 - 2031) | 25.52% CAGR |
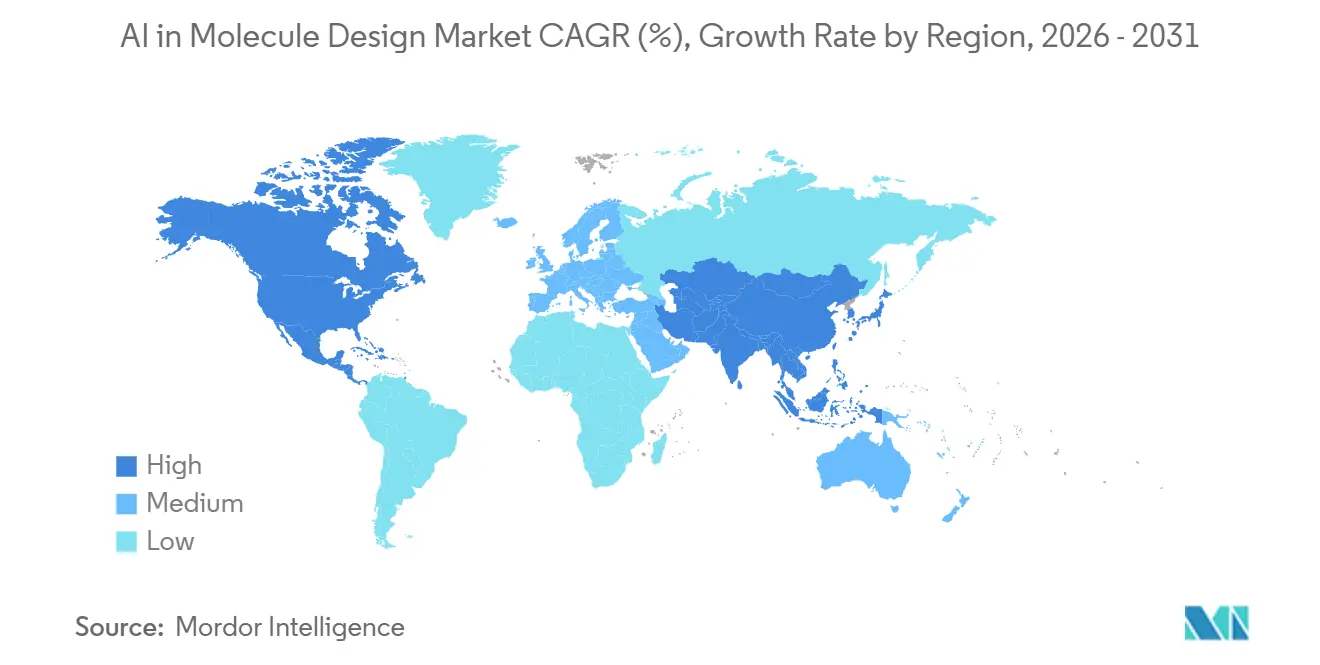
| Schnellstwachsender Markt | Asien-Pazifik |
| Größter Markt | Nordamerika |
| Marktkonzentration | Mittel |
Hauptakteure *Haftungsausschluss: Hauptakteure in keiner bestimmten Reihenfolge sortiert Bild © Mordor Intelligence. Wiederverwendung erfordert Namensnennung gemäß CC BY 4.0. | |
Marktanalyse für KI im Moleküldesign von Mordor Intelligence
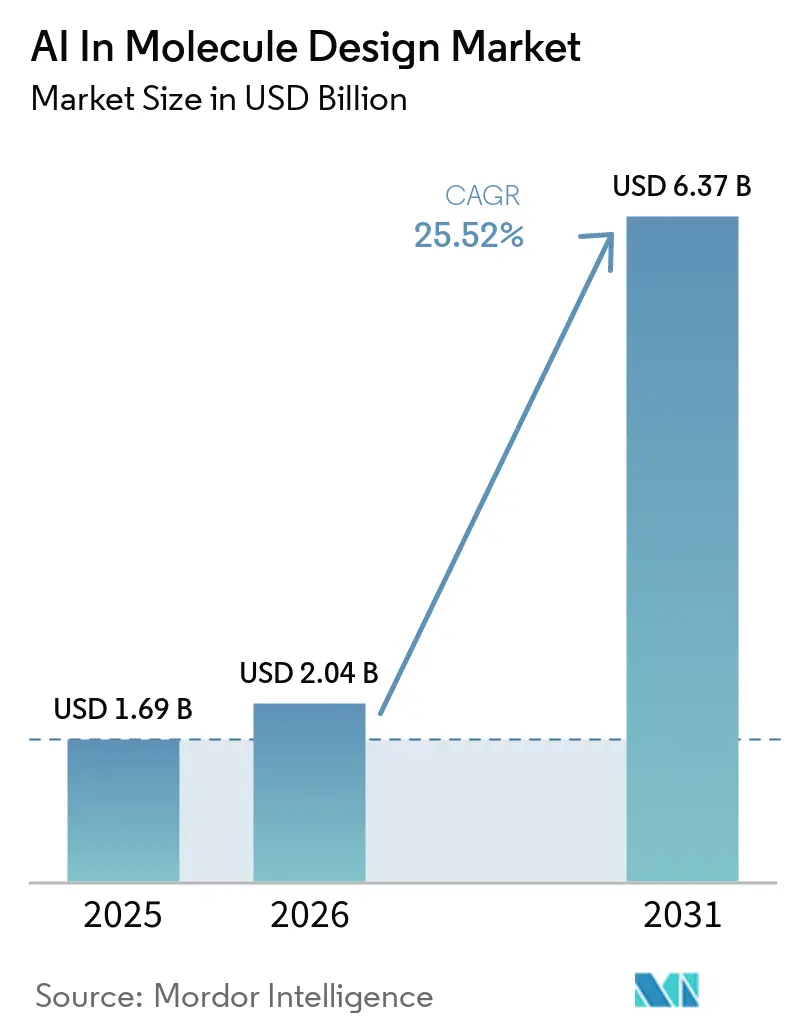
Die Marktgröße für KI im Moleküldesign betrug 2025 1,69 Milliarden USD und wird bis 2031 voraussichtlich 6,37 Milliarden USD bei einer CAGR von 25,52 % erreichen, was einen mehrjährigen Übergang von Pilotprojekten zu eingebetteten Entdeckungs-Workflows in pharmazeutischen Pipelines widerspiegelt. Kapitalzusagen und die Einführung von Plattformen beschleunigen sich, da Basismodelle wie AlphaFold 3 und Cloud-skalierte Mikrodienste Strukturvorhersagen und generative Chemie für große und mittelgroße Forschungs- und Entwicklungsteams zugänglich machen, was die Hürden für Experimente und Iterationen im Design-Herstellen-Testen-Analysieren-Zyklus senkt. Frühe Anwender komprimieren Screening- und Optimierungszyklen durch autonome und halbautonome Laborintegration, die Modellinferenz mit robotergestützter Synthese und Hochdurchsatzanalytik verknüpft, was den Durchsatz erhöht und die Datentreue für aufeinanderfolgende Zyklen verbessert. Fortschritte in der Strukturbiologie erweitern den adressierbaren Anwendungsbereich für KI, wobei AlphaFold-skalierte Ressourcen strukturgeführtes Design über Proteine, Nukleinsäuren und Protein-Ligand-Komplexe hinweg ermöglichen, während Benchmarking weiterhin klärt, wo hybride Physik-KI-Workflows für die Genauigkeit in flexiblen oder ternären Komplexsystemen erforderlich sind. Der Wettbewerbsfokus verlagert sich auf Datenschätze und die Ausführung im Labor-in-der-Schleife, da Unternehmen Nasslab-Validierungspipelines und proprietäre Datensätze formalisieren, die die Plattformdifferenzierung stärken und den Ertrag des De-novo-Designs über kleine Moleküle, Proteine und RNA-Modalitäten hinweg steigern.
Wichtigste Erkenntnisse des Berichts
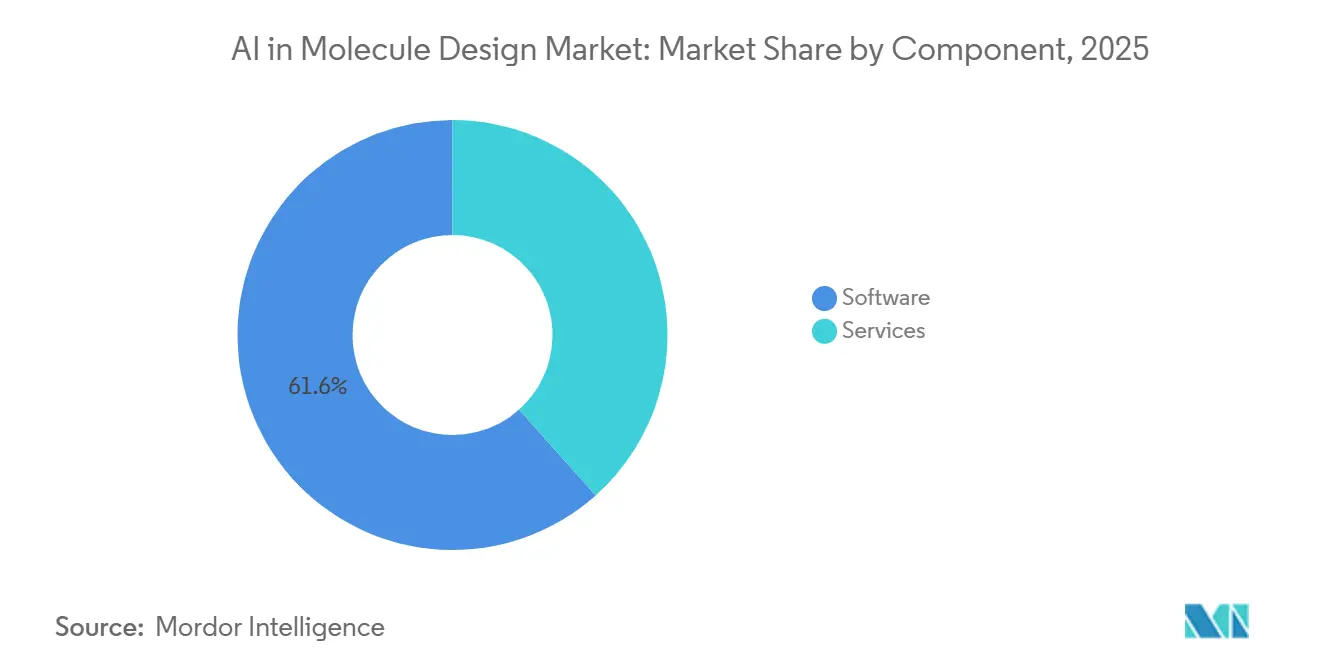
- Nach Komponente führte Software im Jahr 2025 mit einem Anteil von 61,56 %, während Dienstleistungen das schnellste prognostizierte Wachstum mit einer CAGR von 26,14 % bis 2031 verzeichneten.
- Nach Anwendung entfiel auf das Design kleiner Arzneimittelmoleküle im Jahr 2025 ein Anteil von 55,32 %, und das Design von Biologika oder Proteinen wird voraussichtlich bis 2031 mit einer CAGR von 27,10 % wachsen.
- Nach Molekültyp hielten kleine Moleküle im Jahr 2025 einen Anteil von 54,34 %, und Proteine oder Biologika verzeichneten das höchste prognostizierte Wachstum mit einer CAGR von 27,32 %.
- Nach Technologie erfassten generative Modelle im Jahr 2025 einen Einsatzanteil von 48,27 %, während strukturbasiertes Deep Learning voraussichtlich mit einer CAGR von 27,06 % wachsen wird.
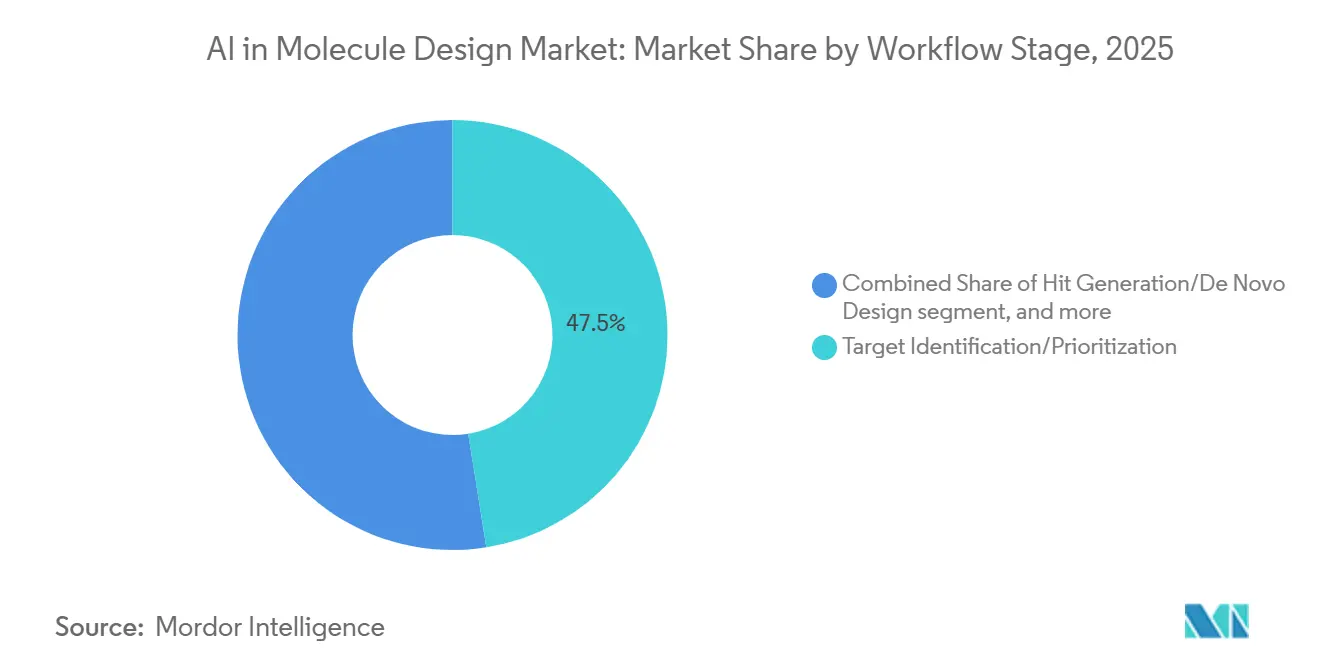
- Nach Workflow-Stufe entfiel auf die Zielidentifizierung im Jahr 2025 ein Anteil von 47,48 % der Einsätze, und die Treffergeneration oder das De-novo-Design schreitet mit einer CAGR von 26,76 % voran.
- Nach Endnutzer repräsentierten pharmazeutische und biotechnologische Unternehmen im Jahr 2025 65,42 %, während CROs und CDMOs voraussichtlich mit einer CAGR von 27,24 % wachsen werden.
- Nach Geografie hielt Nordamerika im Jahr 2025 einen Anteil von 44,54 %, und der asiatisch-pazifische Raum wird voraussichtlich bis 2031 mit einer CAGR von 26,57 % wachsen.
Hinweis: Die Marktgröße und Prognosezahlen in diesem Bericht werden mithilfe des proprietären Schätzungsrahmens von Mordor Intelligence erstellt und mit den neuesten verfügbaren Daten und Erkenntnissen vom Januar 2026 aktualisiert.
Globale Trends und Erkenntnisse im Markt für KI im Moleküldesign
Analyse der Treiberwirkung*
| Treiber | (~) % Auswirkung auf die CAGR-Prognose | Geografische Relevanz | Auswirkungszeitraum |
|---|---|---|---|
| Produktivitätsdruck in der pharmazeutischen Forschung und Entwicklung sowie Imperativ zur Kosten- und Zeitreduzierung | +6.8% | Global, konzentriert in US- und EU-Pharmahochburgen | Kurzfristig (≤ 2 Jahre) |
| Basismodelle und Cloud-skaliertes Computing zur Ermöglichung von generativem Design im großen Maßstab | +5.4% | Global mit Infrastrukturvorteilen in den USA und im asiatisch-pazifischen Raum | Mittelfristig (2–4 Jahre) |
| AlphaFold-Ära-Strukturdaten zur Erschließung von strukturgeführtem und Co-Faltungs-Design | +4.2% | Global, unter Nutzung von AlphaFold-Ressourcen weltweit | Mittelfristig (2–4 Jahre) |
| Kapitalflüsse und Partnerschaften mit großen Pharmaunternehmen zur Validierung von KI-Design-Pipelines | +3.9% | Nordamerika und EU primär; Ausstrahlungseffekte auf den asiatisch-pazifischen Raum über regionale Partnerschaften | Kurzfristig (≤ 2 Jahre) |
| Geschlossene Schleife, in das Labor integrierte automatisierte DMTA-Zyklen zur Verkürzung der Iterationszeit | +3.1% | Nordamerika und asiatisch-pazifischer Raum als Kern; frühe Gewinne in EU-Clustern | Langfristig (≥ 4 Jahre) |
| Regulatorisches Engagement zur Risikoreduzierung beim KI-Einsatz in Entdeckung und Entwicklung | +2.1% | US- und EU-Führung mit nachfolgendem asiatisch-pazifischen Raum | Kurzfristig (≤ 2 Jahre) |
| Quelle: Mordor Intelligence | |||
Produktivitätsdruck in der pharmazeutischen Forschung und Entwicklung sowie Imperativ zur Kosten- und Zeitreduzierung
Die Zeitpläne für die Arzneimittelentwicklung und die Erfolgsquoten stehen weiterhin unter Druck, was die Notwendigkeit verstärkt, Entdeckungszyklen zu komprimieren und die Kandidatenqualität vor der Eskalation klinischer Investitionen zu verbessern. Klinische Erfolgsquoten unter 8 % schränken den ROI weiterhin ein, sodass Entdeckungsfunktionen nach Werkzeugen suchen, die die Zielkonfidenz stärken und Leads früher im Trichter nach mehreren Parametern optimieren. KI-gesteuerte Design-Pipelines unterstützen schnelleres Hypothesentesten über Potenz-, Selektivitäts- und ADMET-Eigenschaften hinweg, was die Attrition verringert und die redundante Synthese von Analoga mit geringem Wert reduziert, wenn sie mit hochpräzisen Rückkopplungsdaten kombiniert werden. Die weit verbreitete Verfügbarkeit skalierbarer Basismodelle und Physik-Verfeinerungs-Workflows senkt die Stückkosten für das In-silico-Screening und die Priorisierung, was zu einem höheren Durchsatz und einer besseren Zuweisung von Nasslab-Ressourcen führt. Da mehr präkompetitive Struktur- und Sequenzdaten in öffentliche Repositorien eingehen und geschlossene Schleifen-Labore qualitativ hochwertigere proprietäre Messungen sammeln, verbessert sich die Modellleistung durch kontinuierliches Feinabstimmen, das reale Assay-Bedingungen widerspiegelt.
Basismodelle und Cloud-skaliertes Computing zur Ermöglichung von generativem Design im großen Maßstab
AlphaFold 3 und verwandte Werkzeuge erweitern die Vorhersagefähigkeit über Proteine, DNA, RNA und Liganden hinaus, was die rechnerische Erkundung von Bindungsmodi und Konformationen ermöglicht, die historisch von langsameren strukturbiologischen Methoden abhingen.[1]Chaim Gartenberg, „Wie wir AlphaFold 3 entwickelt haben, um die Struktur und Wechselwirkung aller Moleküle des Lebens vorherzusagen”, The Keyword, blog.google Cloud-bereitgestellte Mikrodienste wie NVIDIA BioNeMo bringen Diffusions-Docking, Proteinfaltung und molekulare Generierung in standardisierte APIs, was konsistente, skalierbare Einsatzmuster über Entdeckungsportfolios hinweg fördert. Unternehmen berichten von wesentlichen Beschleunigungen und einer breiteren Zielabdeckung, da vortrainierte Modell-Suiten reifen, und die laufende Hardware-Optimierung erhält Durchsatzverbesserungen ohne große Investitionen in lokale Infrastruktur aufrecht. IBMs groß angelegte generative Arbeit veranschaulicht die Gewinne aus dem Training auf SMILES-Korpora im Milliardenmaßstab, mit verbesserter Neuheit und Vielfalt, die erkundete chemische Regionen für das virtuelle Screening erweitert. Basismodelle, die latente chemische und strukturelle Regeln erlernen, generieren Kandidaten, die über überrepräsentierte Gerüste hinausgehen, was Entdeckungsteams hilft, tragfähige First-in-Class-Leads zu finden, wenn sie mit Eigenschaftsfiltern und synthesebewusster Bewertung kombiniert werden. Anbieter-Ökosysteme konsolidieren sich um interoperable Dienste, die Proteinvorhersage, Docking, Generierung und ADMET integrieren, um End-to-End-Workflows mit gemeinsamen Datenverträgen und Versionierung zu ermöglichen.
AlphaFold-Ära-Strukturdaten zur Erschließung von strukturgeführtem und Co-Faltungs-Design
Der Umfang und die Qualität vorhergesagter Strukturen haben das strukturbasierte Design von einer Nische zum Mainstream verschoben, da Forscher Wechselwirkungen über Ziele hinweg erkunden können, ohne auf die experimentelle Strukturbestimmung warten zu müssen. AlphaFold 3 fügte Kapazitäten für Protein-Ligand-Komplexe hinzu, was virtuelles Screening und rationales Design von Bindungsstellenwechselwirkungen unterstützt und gleichzeitig die Priorisierung mit vorhergesagten Konformationen leitet. Benchmarking zeigt eine starke Leistung für statische Wechselwirkungen und hebt die Notwendigkeit hybrider Workflows hervor, wenn die Bindung größere Konformationsänderungen induziert oder wenn ternäre Komplexe modelliert werden, was Teams auf physikbasierte Verfeinerung für die Affinitätseinstufung und Stabilität hinweist. Modellentwickler iterieren schnell mit synthetischen Daten aus Physik-Engines, um die Komplexvorhersage zu verbessern, was Fehler in flexiblen Regionen und membranassoziierten Zielen reduziert, da mehr Trainingsbeispiele diverse biophysikalische Szenarien erfassen. Die kontinuierliche Nutzung zentralisierter Server für die Strukturgenerierung hat Engpässe für die frühe Entdeckung beseitigt, sodass mehrere Zielhypothesen parallel mit konsistenten strukturellen Eingaben vorangetrieben werden können. Da Organisationen Co-Faltungs-, induzierte Anpassungs- und Ensemble-Modellierungsstrategien standardisieren, informieren Strukturdaten nun sowohl die Treffergeneration als auch die Lead-Optimierungsphasen über kleine Moleküle und Biologika hinweg.
Geschlossene Schleife, in das Labor integrierte automatisierte DMTA-Zyklen zur Verkürzung der Iterationszeit
Die Verbindung von Design-Engines mit robotergestützter Synthese und schnellen Assay-Auslesungen verwandelt den Design-Herstellen-Testen-Analysieren-Zyklus in eine kontinuierliche Schleife, die Wochen oder Monate von jeder Iteration abschneidet und die Anzahl der bewertbaren Hypothesen pro Zeiteinheit erweitert. Autonome und halbautonome Systeme haben in Live-Projekten schnellere Optimierungen über Potenz- und Effizienzmetriken hinweg demonstriert, wobei Hochdurchsatzsynthese und Analytik Datensätze liefern, die das Modell-Retraining stärken. Im Protein-Engineering hat autonome Experimentierung messbare Gewinne bei Kosten und Geschwindigkeit erzielt, was veranschaulicht, wie Labor-in-der-Schleife-Pipelines skalieren, wenn Modellinferenz die Experimentierung leitet, anstatt sich auf manuelle Stapelverarbeitung zu verlassen.[3]NVIDIA Corporation, „Erweiterung der computergestützten Arzneimittelentdeckung mit neuen KI-Modellen”, NVIDIA Blog, blogs.nvidia.com Digitale Zwillinge und standardisierte Datenobjekte reduzieren die manuelle Kuratierung weiter und ermöglichen nahezu Echtzeit-Hypothesentests über Synthese- und Prozessparameter hinweg. Hardware-Anbieter adressieren Durchsatzbeschränkungen mit modularen, skalierbaren Arbeitszellen, die mit Simulation für vorausschauende Wartung und Planung integriert sind, was die Betriebszeit für kontinuierliche Zyklen erhöht. Die kombinierte Wirkung ist eine produktivere und datenreichere Schleife, die in die Modellleistung zurückfließt und das Gesamteffizienzprofil des Marktes für KI im Moleküldesign verbessert.
Analyse der Hemmnisauswirkungen*
| Hemmnis | (~) % Auswirkung auf die CAGR-Prognose | Geografische Relevanz | Auswirkungszeitraum |
|---|---|---|---|
| Datenqualität, Verzerrung und fehlende Standards, die die Modellgeneralisierung einschränken | -2.8% | Global, akut in Regionen mit fragmentierter Dateninfrastruktur | Mittelfristig (2–4 Jahre) |
| Hohe Implementierungskosten und Talentbeschränkungen für die Skalierung von Programmen | -2.3% | Asiatisch-pazifischer Raum und aufstrebende EU-Märkte stehen vor größeren Talentdefiziten; USA verfügen über stärkere KI-Talentpools | Langfristig (≥ 4 Jahre) |
| Synthesierbarkeits- lücke zwischen KI-Vorschlägen und ausführbaren Routen | -1.7% | Global, Schweregrad umgekehrt korreliert mit der medizinischen Chemieinfrastruktur | Mittelfristig (2–4 Jahre) |
| Computing- oder GPU-Versorgung und Energieengpässe, die das Training einschränken | -1.4% | National, wo der Hyperscale-Zugang oder die lokale GPU-Versorgung begrenzt ist | Kurzfristig (≤ 2 Jahre) |
| Quelle: Mordor Intelligence | |||
Datenqualität, Verzerrung und fehlende Standards, die die Modellgeneralisierung einschränken
Trainingsdaten bleiben im Verhältnis zum riesigen chemischen Raum spärlich, und Fehler oder inkonsistente Protokolle in öffentlichen Datensätzen führen zu Rauschen, das das Modelllernen verzerren und die externe Validität beeinträchtigen kann. Benchmark-Überprüfungen zeigen nicht triviale Beschriftungsfehlerraten über molekulare Eigenschaftsdatensätze hinweg, was zu Scheinkorrelationen führen und die Genauigkeit in prospektiven Vorhersageeinstellungen reduzieren kann. Heterogene Assay-Bedingungen erschweren das Lernen weiter, da Modelle, die auf aggregierten Quellen trainiert wurden, Messungen über zellfreie, zelluläre oder In-vivo-Kontexte hinweg ohne ausreichende Metadaten zur Normalisierung von Unterschieden vermischen können. Demografische Ungleichgewichte in klinischen Belegen erhöhen die Generalisierbarkeitsrisiken für Sicherheits- und Expositionsvorhersagen, da unterrepräsentierte genetische Hintergründe unerwünschte Wirkungen erfahren können, die von Modellen, die auf engeren Populationen trainiert wurden, schlecht erfasst werden. Aktivitätsklippen und kontextsensitive Bioassay-Ergebnisse erhöhen die Komplexität, und das Fehlen standardisierter Berichtsregeln für Protokolle und Unsicherheit erschwert den Vergleich oder die Wiederverwendung von Datensätzen über Programme hinweg. Organisationen adressieren diese Lücken, indem sie proprietäre experimentelle Daten im großen Maßstab generieren und Metadaten anreichern, um die Modellzuverlässigkeit zu verbessern, was einen besseren Domänentransfer innerhalb des Marktes für KI im Moleküldesign unterstützt.
Synthesierbarkeits-lücke zwischen KI-Vorschlägen und ausführbaren Routen
Generative Modelle können hochbewertete Moleküle ausgeben, die schwer herzustellen sind, da vielen Trainingssets explizite Syntheseannotationen und retrosynthetische Einschränkungen während der Generierung fehlen. Studien, die automatisierte Qualitätsfilter für medizinische Chemie mit Docking und Retrosynthese kombinieren, zeigen, dass nur ein kleiner Bruchteil der generierten Kandidaten alle Hürden besteht, was die Notwendigkeit unterstreicht, synthesebewusste Ziele früher im Design einzubeziehen. Die Einbeziehung von Retrosynthese-Planern in enge Optimierungsschleifen verbessert die Durchführbarkeit, fügt jedoch rechnerischen Overhead hinzu, der die Geschwindigkeitsvorteile der De-novo-Generierung in großem Maßstab mindert. Neue Frameworks, die aus retrosynthetischen Pfaden oder Fragment-Assemblierung lernen, entstehen, um Neuheit mit Routendurchführbarkeit in Einklang zu bringen, obwohl die umfangreiche Nasslab-Validierung im Vergleich zu In-silico-Metriken begrenzt bleibt. Belohnungs-Engineering und synthesegeführte Fragment-Richtlinien können die Lücke verringern, indem unzugängliche Motive bestraft werden, während die Design-Vielfalt für die SAR-Erkundung erhalten bleibt. Da retrosynthetische Dienste und reagenziengestützte Bibliotheken mit Generierungs-Stacks integriert werden, verbessern sich Design-Zyklen und erhöhen den Ertrag von In-silico-Vorschlägen zu bench-getesteten Kandidaten im Markt für KI im Moleküldesign.
*Unsere Prognosen behandeln die Auswirkungen von Treibern und Einschränkungen als richtungsweisend und nicht additiv. Die Wirkungsprognosen berücksichtigen Basiswachstum, Mischungseffekte und Wechselwirkungen zwischen Variablen.
Segmentanalyse
Nach Komponente: Software dominiert, Dienstleistungen beschleunigen sich mit zunehmender Integration
Software hielt im Jahr 2025 61,56 % des Marktes für KI im Moleküldesign, unterstützt durch cloudbasierten Zugang zu Faltungs-, Docking- und generativen Modellen, die es Teams ermöglichen, ohne größere lokale Investitionen zu skalieren. Plattform-Mikrodienste wie BioNeMo stellen Modelle für Docking, Strukturvorhersage und Molekülgenerierung über Standard-APIs bereit, was den Wert in Software-Workflows konzentriert, die über mehrere Entdeckungsprogramme hinweg orchestriert werden können. Wichtige Toolchains in der physikbasierten Verfeinerung aktualisieren weiterhin Funktionen für die Skalierung, einschließlich Verbesserungen bei Freie-Energie-Berechnungen und kategorischer Assay-Handhabung, die mit den Workflows von Entdeckungsteams übereinstimmen. Das Ergebnis ist eine breitere Software-Durchdringung in den Markt für KI im Moleküldesign für Routineschritte wie Treffer-Expansion und frühes ADMET-Filtern, die nun für funktionsübergreifende Benutzer über einheitliche Schnittstellen zugänglich sind.
Dienstleistungen sind die am schnellsten wachsende Komponente mit einer prognostizierten CAGR von 26,14 %, angetrieben durch End-to-End-DMTA-Ausführung, die Sequenz- oder Moleküldesign mit interner Synthese und Charakterisierung verknüpft. RNA-fokussierte Anbieter veranschaulichen diese Verschiebung mit integrierten Angeboten, die KI-unterstütztes Design, skalierbare Herstellung und Deep Sequencing umfassen, die Expression und Funktion innerhalb eines Zyklus validieren. Dienstleistungsgeführte Modelle komprimieren den Zeitplan und reduzieren den Koordinationsaufwand über Anbieter hinweg, während strukturierte Datenerfassung kontinuierliches Modell-Retraining für die nächste Iteration unterstützt. Da Entdeckungsorganisationen Programme skalieren und Betriebsverfahren standardisieren, wird die Dienstleistungsschicht zu einem wichtigen Ausführungspartner, der Laborautomatisierung, Assay-Durchsatz und Dokumentation übernimmt, um Qualitäts- und Compliance-Anforderungen für den Markt für KI im Moleküldesign zu unterstützen.



Nach Anwendung: Dominanz kleiner Moleküle weicht dem Aufschwung von Biologika und Proteindesign
Das Design kleiner Arzneimittelmoleküle entfiel im Jahr 2025 auf 55,32 % der Anwendungen, was etablierte Wege für virtuelles Screening, physikbasierte Verfeinerung und Lead-Optimierung widerspiegelt, die für die frühe Entdeckung zentral bleiben. Generative und Physik-Engines werden häufig in Kombination eingesetzt, um Neuheit mit der Vorhersage der Bindungsaffinität in Einklang zu bringen, was einen effizienten Filter für die Priorisierung von Kandidaten vor der Synthese schafft. Der Stack für kleine Moleküle ist nun über Ziele und Eigenschaften hinweg interoperabler, wobei gemeinsame Datenformate Ensemble-Ansätze ermöglichen, die Docking, Generierung und ADMET verschränken, um die frühe Triage im großen Maßstab im Markt für KI im Moleküldesign voranzutreiben. Diese Tooling-Dichte hält kleine Moleküle als Arbeitspferd-Modalität, auch wenn neue Klassen Investitionen und Aufmerksamkeit auf sich ziehen.
Biologika oder Proteindesign ist die am schnellsten wachsende Anwendung mit einer prognostizierten CAGR von 27,10 %, unterstützt durch Fortschritte in der Strukturvorhersage, inversem Falten und Sequenzoptimierung, die den Bedarf an erschöpfendem Bibliotheks-Screening reduzieren. KI-first-Entwickler haben klinische Fortschritte bei Antikörperprogrammen gemeldet, die mit sequenz- und strukturbewussten großen Sprachmodellen entworfen wurden, was externe Belege liefert, dass Design-first-Workflows Kandidaten generieren können, die für die Entwicklung geeignet sind. RNA- und mRNA-Sequenzdesign-Plattformen integrieren nun KI-gesteuerte Optimierung mit skalierbarer Synthese und Analytik, was den Weg von In-silico-Vorschlägen zu validierten Expressionskonstrukten verkürzt. Da die Labor-in-der-Schleife-Validierung zur Routine wird, nutzen Biologika-Programme Design-Zyklen, die Entwickelbarkeit und Potenz in weniger Iterationen verbessern, was den Anwendungsmix innerhalb des Marktes für KI im Moleküldesign umgestaltet.
Nach Molekültyp: Proteine und Biologika eilen voraus, da Basismodelle reifen
Kleine Moleküle repräsentierten im Jahr 2025 54,34 % des Marktes für KI im Moleküldesign, unterstützt durch die Verfügbarkeit großer virtueller Bibliotheken und skalierbarer Screening-Strategien, die auf Standard-Cloud-Infrastruktur laufen. Strukturinformierte Abruf- und Screening-Frameworks haben Beschleunigungen um Größenordnungen geliefert, was den machbaren Suchraum pro Ziel erweitert und die Trefferquoten verbessert, wenn sie mit Eigenschaftsfiltern kombiniert werden. Dieses Fundament erhält einen starken Durchsatz für medizinische Chemie-Pipelines, die weiterhin von Standard-ADMET-Modellen und klinischer Vertrautheit profitieren.
Proteine und Biologika haben das schnellste prognostizierte Wachstum mit einer CAGR von 27,32 %, angetrieben durch bessere Sequenz-Struktur-Modellierung, Entwickelbarkeitsvorhersage und autonome Experimentierung, die den Ertrag funktionaler Designs erhöht. RNA-zentrierte Modalitäten gewinnen auch durch Labor-in-der-Schleife-Plattformen an Bedeutung, die kodierende und nicht-kodierende Merkmale optimieren, um Expression und Haltbarkeit zu verbessern, was den praktischen Designraum für therapeutische Anwendungen erweitert. Klinische Fortschritte bei Genbearbeitung und Zelltherapie unterstützen kontinuierliche Investitionen in Sequenz-Level-Design-Engines, die mit Validierungs-Workflows und Qualitätsanalytik integriert sind. Da Toolchains reifen, neigt sich der Molekültyp-Mix zu Programmen, die am empfindlichsten auf Struktur- und Sequenzlerngewinne reagieren, was Anteilsverschiebungen innerhalb des Marktes für KI im Moleküldesign beschleunigt.
Nach Technologie: Generative Modelle führen, strukturbasiertes Deep Learning gewinnt an Dynamik
Generative Modelle entfielen im Jahr 2025 auf 48,27 % des Technologieeinsatzes, was ihre Nützlichkeit bei der Vorschlagserstellung diverser, eigenschaftsbewusster Kandidaten für nachgelagerte Filterung und Optimierung widerspiegelt. Diffusions- und transformatorbasierte Generatoren verdrängen Legacy-Methoden für das De-novo-Design aufgrund von Trainingsstabilität und Probenqualität, während die Integration mit ADMET und Docking die Entscheidungskonfidenz für Syntheseauswahlen erhöht. Basismodell-Updates erweitern weiterhin die Zielabdeckung und den Modalitätsumfang, was breitere Anwendungen über kleine Moleküle und näherungsbasierte Therapeutika im Markt für KI im Moleküldesign hinweg ermöglicht.
Strukturbasiertes Deep Learning ist die am schnellsten wachsende Technologie mit einer prognostizierten CAGR von 27,06 %, verankert durch Verbesserungen in der Komplexvorhersage und Konformationsmodellierung, die das strukturgeführte Design unterstützen. Modellentwickler kombinieren physikgenerierte synthetische Daten mit erlernten Repräsentationen, um Genauigkeitslücken in flexiblen Systemen zu schließen, was den Nutzen vorhergesagter Strukturen für Design und Priorisierung erhöht. Toolchains, die Retrosynthese und Routendurchführbarkeit in Bewertungsfunktionen integrieren, verfeinern den Kandidatensatz weiter und verbessern die Übergabe vom In-silico-Design zur Werkbank. Dieser Stack ergänzt generative Ansätze und unterstützt End-to-End-Workflows, die Ziele, Strukturen, Generierung und Synthesebewusstsein im Markt für KI im Moleküldesign verbinden.
Nach Workflow-Stufe: Zielidentifizierung dominiert, Treffergeneration beschleunigt sich
Zielidentifizierung oder -priorisierung repräsentierte im Jahr 2025 47,48 % der Einsätze, da die Auswahl hochkonfidenter Ziele der am stärksten genutzte Entscheidungspunkt für die nachgelagerte Entdeckung und Entwicklung ist. Multimodale Datenintegration und prädiktive Modellierung erhöhen die Stärke von Zielhypothesen und ermöglichen es Teams, Anstrengungen auf die vielversprechendste Biologie auszurichten, was die Attrition in späten Phasen reduziert. Struktur- und Sequenzressourcen ermöglichen nun eine schnellere Triage von Zielklassen und Bindungsstellendurchführbarkeit, was einen klareren Weg für die nachgelagerte Treffergeneration im Markt für KI im Moleküldesign schafft.
Treffergeneration oder De-novo-Design ist der am schnellsten wachsende Schritt mit einer prognostizierten CAGR von 26,76 %, angetrieben durch Modell-Ensembles, die große Chargen chemisch diverser Kandidaten vorschlagen, die auf Potenz- und Entwickelbarkeits-Eigenschaften konditioniert sind. Bei Integration mit geschlossenen Schleifen-Laboren produziert diese Stufe sofortiges Feedback, das nachfolgende Generationen schärft und die Zeit bis zu qualifizierten Treffern reduziert. Die Lead-Optimierung profitiert dann von physikbasierter Verfeinerung und kalibrierten Freie-Energie-Vorhersagen, die kleinere, gezieltere Synthesen für die SAR-Expansion unterstützen. End-to-End-Workflows bündeln zunehmend ADMET-, Retrosynthese- und Strukturvorhersage-Mikrodienste, sodass Entdeckungsteams kontinuierliche Zyklen innerhalb standardisierter Datenpipelines im Markt für KI im Moleküldesign betreiben können.
Nach Endnutzer: Pharma oder Biotech führt, CROs oder CDMOs steigen auf, da Outsourcing zunimmt
Pharmazeutische und biotechnologische Unternehmen hielten im Jahr 2025 65,42 %, was die Konzentration von Entdeckungsbudgets und den strategischen Bedarf widerspiegelt, Pipelines aufzufüllen, da sich der Modalitätsmix weiterentwickelt. Entdeckungsteams innerhalb großer Organisationen setzen standardisierte KI-Stacks über Ziele und Modalitäten hinweg ein, um das rechnerische Design mit der Laborkapazität abzustimmen, was den Durchsatz und die Datenqualität für iterative Zyklen im Markt für KI im Moleküldesign verbessert.
CROs und CDMOs sind die am schnellsten wachsenden Endnutzer mit einer prognostizierten CAGR von 27,24 %, da Auftraggeber-Unternehmen Arbeit an Partner verlagern, die KI-erweiterte Chemie und Biologie mit integrierter Laborautomatisierung durchführen können. Anbieter, die Design-Engines mit Synthese und Analytik bündeln, reduzieren den Auftraggeber-Overhead und beschleunigen Zyklen, während standardisierte Dokumentation den Technologietransfer und die regulatorische Bereitschaft unterstützt. Der Effekt ist ein skalierbareres Dienstleistungs-Ökosystem, das den Zugang zu fortgeschrittenen Workflows innerhalb des Marktes für KI im Moleküldesign erweitert.
Geografische Analyse
Nordamerika entfiel im Jahr 2025 auf 44,54 % des Marktes für KI im Moleküldesign, unterstützt durch eine kritische Masse an Entdeckungsbudgets, rechnerischem Talent und Laborinfrastruktur, die KI mit automatisierter Experimentierung integriert. Die Region verfügt über aktiven Einsatz von Basismodell-Mikrodiensten und Physik-Toolchains, was schnelleres Screening und Priorisierung über Ziele und Modalitäten hinweg ermöglicht. Anbieter-Ökosysteme, die GPU-beschleunigte Cloud-Plattformen und Modell-Hubs umfassen, haben den Zugang zu leistungsstarken Werkzeugen erhöht, was groß angelegte Experimente über therapeutische Bereiche im Markt für KI im Moleküldesign unterstützt.
Der asiatisch-pazifische Raum ist die am schnellsten wachsende Region mit einer prognostizierten CAGR von 26,57 % bis 2031, verankert durch staatlich geförderte Initiativen und akademisch-industrielle Plattformen, die den Zugang zu Zielanalyse, generativem Design und Bewertungswerkzeugen erweitern. China startete eine vollständige KI-Plattform, die kostenlosen Zugang für Zielanalyse, Molekülgenerierung und ADMET-Optimierung bietet, was die Hürden für akademische Labore und Startups senkt. Mit der Tsinghua-Universität verbundene Programme berichteten von millionenfachen Beschleunigungen beim virtuellen Screening und öffneten große Protein-Ligand-Datenbanken für die Gemeinschaft, was den durchsuchbaren Raum für Entdeckungsprojekte im Markt für KI im Moleküldesign erweitert. Japans Ministerium für Wirtschaft, Handel und Industrie und die Neue Energie- und Industrietechnologie-Entwicklungsorganisation unterstützten Arbeiten an groß angelegten Basismodellen für das Arzneimitteldesign, was das Engagement des öffentlichen Sektors für die Skalierung der KI-first-Entdeckung signalisiert.
Europa profitiert von koordinierter öffentlicher Finanzierung und einem dichten Netzwerk von Pharma-, Biotech- und akademischen Zentren, die Entdeckungsmodellierung mit translationaler Infrastruktur verbinden. Nationale Programme haben gezielte Finanzierung eingeführt, um KI-gestützte Arzneimittelentdeckung zu beschleunigen, mit starker Infrastruktur in Ländern, die wichtige Pharma- und Forschungseinrichtungen beherbergen. In der gesamten Region expandiert der Markt für KI im Moleküldesign, da Stakeholder Basismodelle, Laborautomatisierung und Prozessanalytik verbinden, um Entdeckung und frühe Entwicklung über mehrere Modalitäten hinweg zu unterstützen.

Wettbewerbslandschaft
Der Wettbewerb im Markt für KI im Moleküldesign ist mäßig fragmentiert über Technologie-Stacks, therapeutische Modalitäten und Markteinführungsmodelle hinweg, wobei sich die Differenzierung auf Datenbestände und die Ausführung im Labor-in-der-Schleife verlagert, die den Design-Ertrag im Laufe der Zeit verbessern. Konsolidierung gestaltet Fähigkeiten durch Kombinationen aus generativer Chemie, Phänomik und Zielidentifizierung unter einem Dach um, was eine skalierte Entdeckung über Portfolios hinweg unterstützt. Datenschätze sind zentral, da Unternehmen in proprietäre, hochwertige Datensätze und Automatisierung investieren, die Rückkopplungsschleifen für verbesserte Modellleistung im Markt für KI im Moleküldesign schaffen.
Ökosystem-Führende standardisieren auch den Modellzugang über Cloud-Mikrodienste, was Netzwerkeffekte schafft, da mehr Benutzer zur Abstimmung und Bewertung beitragen. RNA- und Protein-Engineering-Plattformen entstehen als hochwertige Nischen, gestärkt durch Investoreninteresse und Labor-in-der-Schleife-Fähigkeiten, die Design mit Synthese und Analytik in einer Umgebung verbinden. Unternehmen betonen auch Erklärbarkeit und Herkunft, um Anforderungen von Auftraggebern an interne Governance und regulatorisch bereite Dokumentation zu unterstützen, was die Technologiedifferenzierung mit operativen Bedürfnissen in Entdeckung und Entwicklung in Einklang bringt.
Ausgewählte strategische Schritte veranschaulichen den Wettbewerbsbogen des Marktes für KI im Moleküldesign, während er skaliert. Eine hochkarätige Biotech-Kombination integrierte große proprietäre Datensätze und Multi-Modalitäts-Entdeckungs-Engines unter einer Unternehmensstruktur, um industrialisierte Entdeckung zu beschleunigen. Zugangshubs für Basismodelle sicherten breite Akzeptanz bei über hundert Unternehmen und bestätigten die zentrale Rolle standardisierter APIs und GPU-Cloud für molekulare Generierung, Docking und Faltung im großen Maßstab. Autonome Experimentierungs-Benchmarks im Protein-Engineering demonstrierten Kosten- und Geschwindigkeitsgewinne durch KI-gesteuerte Laborworkflows und validierten die Integration von Modellinferenz mit automatisierten Laborsystemen in kommerziellen Umgebungen.
Marktführer im Bereich KI im Moleküldesign
Schrödinger
Exscientia
Insilico Medicine
Recursion
XtalPi
- *Haftungsausschluss: Hauptakteure in keiner bestimmten Reihenfolge sortiert

Jüngste Branchenentwicklungen
- April 2026: Isomorphic Labs, der DeepMind-Ableger, treibt das KI-gesteuerte Moleküldesign in eine neue Phase voran, indem es seine ersten klinischen Humanstudien mit KI-entworfenen Arzneimittelkandidaten vorbereitet. Mit seinen KI-Systemen, die auf AlphaFold und generativen Modellen aufgebaut sind, entwirft und optimiert das Unternehmen neuartige Moleküle für Krankheiten wie Krebs und Immunerkrankungen. Nach der Sicherung wichtiger Pharmapartnerschaften und Finanzierung geht es nun vom In-silico-Moleküldesign zur realen Validierung über, wobei Humanstudien für etwa 2026 erwartet werden. Dies markiert einen wichtigen Meilenstein, bei dem KI-entworfene Moleküle von der rechnerischen Entdeckung zur klinischen Erprobung am Menschen übergehen.
- März 2026: Roche startete in Zusammenarbeit mit NVIDIA eine KI-„Fabrik” für die Arzneimittelentwicklung, um das KI-gesteuerte Moleküldesign und die Arzneimittelentdeckung zu skalieren. Das System nutzt groß angelegte GPU-Infrastruktur, um generative KI-Modelle auszuführen, die beim Design neuer Arzneimittelmoleküle helfen, Ziele identifizieren und biologisches Verhalten effizienter simulieren. Es integriert diese Fähigkeiten in Roches Forschungs- und Entwicklungs- sowie Herstellungspipeline und ermöglicht einen stärker automatisierten und datengesteuerten Ansatz zur Entwicklung von Medikamenten.
- März 2026: Eli Lilly schloss eine Vereinbarung über 2,75 Milliarden USD mit Insilico Medicine, um das KI-gesteuerte Moleküldesign für die Arzneimittelentdeckung voranzutreiben. Die Zusammenarbeit konzentrierte sich auf den Einsatz generativer KI zur Erstellung und Optimierung neuartiger Arzneimittelmoleküle, die Lilly zu potenziellen Therapien entwickelt, insbesondere in Bereichen wie Onkologie und Stoffwechselerkrankungen. Dieser Deal unterstreicht das wachsende Vertrauen der Pharmaindustrie in KI-entworfene Moleküle als tragfähige präklinische Arzneimittelkandidaten.


Umfang des globalen Berichts über den Markt für KI im Moleküldesign
Gemäß dem Umfang des Berichts bezieht sich KI im Moleküldesign auf den Einsatz von maschinellen Lern- und generativen Modellen zur Vorhersage, Erstellung und Optimierung molekularer Strukturen durch Lernen aus großen chemischen Datensätzen, was eine schnellere Erkundung des chemischen Raums und eine Beschleunigung des Design-Herstellen-Test-Zyklus ermöglicht. Es unterstützt Aufgaben wie Eigenschaftsvorhersage, De-novo-Molekülgenerierung und automatisierte Optimierung und hilft Wissenschaftlern, neuartige Arzneimittelkandidaten und Materialien effizienter zu entwerfen.
Der Markt für KI im Moleküldesign ist nach Komponente, Anwendung, Molekültyp, Technologie, Workflow-Stufe, Endnutzer und Geografie segmentiert. Nach Komponente ist der Markt in Software und Dienstleistungen segmentiert. Nach Anwendung ist der Markt in Design kleiner Arzneimittelmoleküle, Biologika/Proteindesign, Design von Materialien und Spezialchemikalien sowie Agrochemikaliendesign segmentiert. Nach Molekültyp ist der Markt in kleine Moleküle, Peptide, Proteine/Biologika, RNA/Oligonukleotide und Materialmoleküle/Polymere segmentiert. Nach Technologie ist der Markt in generative Modelle, strukturbasiertes Deep Learning, Eigenschaftsvorhersage/ADMET ML sowie Syntheseplanung und Retrosynthese-KI segmentiert. Nach Workflow-Stufe ist der Markt in Zielidentifizierung/Priorisierung, Treffergeneration/De-novo-Design, Treffer-zu-Lead und Lead-Optimierung sowie Sonstiges segmentiert. Nach Endnutzer ist der Markt in pharmazeutische und biotechnologische Unternehmen, CROs und CDMOs, Chemikalien- und Materialhersteller sowie Sonstiges segmentiert. Nach Geografie ist der Markt in Nordamerika, Europa, asiatisch-pazifischen Raum, Nahen Osten und Afrika sowie Südamerika segmentiert. Der Bericht deckt auch die geschätzten Marktgrößen und Trends für 17 Länder in den wichtigsten Regionen weltweit ab. Der Bericht bietet Werte (USD) für alle oben genannten Segmente.
| Software |
| Dienstleistungen |
| Design kleiner Arzneimittelmoleküle |
| Biologika/Proteindesign |
| Design von Materialien und Spezialchemikalien |
| Agrochemikaliendesign |
| Kleine Moleküle |
| Peptide |
| Proteine/Biologika |
| RNA/Oligonukleotide |
| Materialmoleküle/Polymere |
| Generative Modelle |
| Strukturbasiertes Deep Learning |
| Eigenschaftsvorhersage/ADMET ML |
| Syntheseplanung und Retrosynthese-KI |
| Zielidentifizierung/Priorisierung |
| Treffergeneration/De-novo-Design |
| Treffer-zu-Lead |
| Lead-Optimierung |
| Sonstiges |
| Pharmazeutische und biotechnologische Unternehmen |
| CROs und CDMOs |
| Chemikalien- und Materialhersteller |
| Sonstiges |
| Nordamerika | Vereinigte Staaten |
| Kanada | |
| Mexiko | |
| Europa | Deutschland |
| Vereinigtes Königreich | |
| Frankreich | |
| Italien | |
| Spanien | |
| Übriges Europa | |
| Asiatisch-pazifischer Raum | China |
| Japan | |
| Indien | |
| Australien | |
| Südkorea | |
| Übriger asiatisch-pazifischer Raum | |
| Naher Osten und Afrika | Golfkooperationsrat |
| Südafrika | |
| Übriger Naher Osten und Afrika | |
| Südamerika | Brasilien |
| Argentinien | |
| Übriges Südamerika |
| Nach Komponente | Software | |
| Dienstleistungen | ||
| Nach Anwendung | Design kleiner Arzneimittelmoleküle | |
| Biologika/Proteindesign | ||
| Design von Materialien und Spezialchemikalien | ||
| Agrochemikaliendesign | ||
| Nach Molekültyp | Kleine Moleküle | |
| Peptide | ||
| Proteine/Biologika | ||
| RNA/Oligonukleotide | ||
| Materialmoleküle/Polymere | ||
| Nach Technologie | Generative Modelle | |
| Strukturbasiertes Deep Learning | ||
| Eigenschaftsvorhersage/ADMET ML | ||
| Syntheseplanung und Retrosynthese-KI | ||
| Nach Workflow-Stufe | Zielidentifizierung/Priorisierung | |
| Treffergeneration/De-novo-Design | ||
| Treffer-zu-Lead | ||
| Lead-Optimierung | ||
| Sonstiges | ||
| Nach Endnutzer | Pharmazeutische und biotechnologische Unternehmen | |
| CROs und CDMOs | ||
| Chemikalien- und Materialhersteller | ||
| Sonstiges | ||
| Nach Geografie | Nordamerika | Vereinigte Staaten |
| Kanada | ||
| Mexiko | ||
| Europa | Deutschland | |
| Vereinigtes Königreich | ||
| Frankreich | ||
| Italien | ||
| Spanien | ||
| Übriges Europa | ||
| Asiatisch-pazifischer Raum | China | |
| Japan | ||
| Indien | ||
| Australien | ||
| Südkorea | ||
| Übriger asiatisch-pazifischer Raum | ||
| Naher Osten und Afrika | Golfkooperationsrat | |
| Südafrika | ||
| Übriger Naher Osten und Afrika | ||
| Südamerika | Brasilien | |
| Argentinien | ||
| Übriges Südamerika | ||


Im Bericht beantwortete Schlüsselfragen
Wie groß ist der aktuelle Markt für KI im Moleküldesign und wie sind die Wachstumsaussichten?
Die Marktgröße für KI im Moleküldesign betrug 2025 1,69 Milliarden USD und wird bis 2031 voraussichtlich 6,37 Milliarden USD bei einer CAGR von 25,52 % erreichen, was auf mehrjährige Dynamik über Entdeckungs-Workflows hinweg hindeutet.
Welche Regionen werden bis 2031 das schnellste Wachstum vorantreiben?
Der asiatisch-pazifische Raum ist die am schnellsten wachsende Region mit einer prognostizierten CAGR von 26,57 %, unterstützt durch staatlich geförderte Plattformen und akademisch-industrielle Programme, die den Zugang zu KI-gestützten Design-Werkzeugen erweitern.
Welche Anwendungen und Molekültypen werden am stärksten wachsen?
Biologika oder Proteindesign ist die am schnellsten wachsende Anwendung mit einer CAGR von 27,10 %, während Proteine oder Biologika das Wachstum nach Molekültyp mit 27,32 % anführen, wobei Labor-in-der-Schleife und strukturbewusste Modelle den Ertrag verbessern.
Welche Technologien werden heute am häufigsten im KI-gestützten Design eingesetzt?
Generative Modelle führen mit einem Einsatzanteil von 48,27 %, und strukturbasiertes Deep Learning wächst am schnellsten mit einer CAGR von 27,06 %, unterstützt durch Fortschritte in der Komplexvorhersage und Cloud-bereitgestellte Mikrodienste.
Seite zuletzt aktualisiert am:




