HBM For AI GPUs Market Size and Share
Market Overview
| Study Period | 2020 - 2031 |
|---|---|
| Market Size (2026) | USD 12.56 Billion |
| Market Size (2031) | USD 46.82 Billion |
| Growth Rate (2026 - 2031) | 30.10% CAGR |
| Fastest Growing Market | Asia-Pacific |
| Largest Market | North America |
| Market Concentration | High |
Major Players *Disclaimer: Major Players sorted in no particular order Image © Mordor Intelligence. Reuse requires attribution under CC BY 4.0. | |
HBM For AI GPUs Market Analysis by Mordor Intelligence
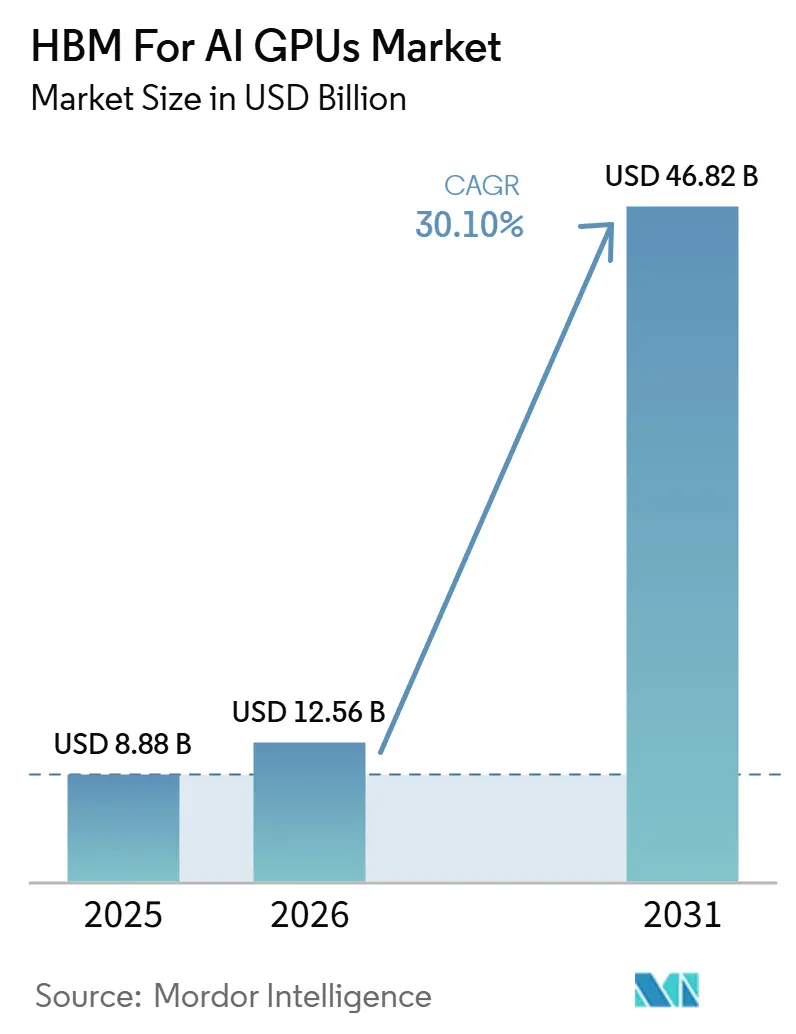
The HBM for AI GPUs market size is expected to increase from USD 8.88 billion in 2025 to USD 12.56 billion in 2026 and reach USD 46.82 billion by 2031, growing at a CAGR of 30.10% over 2026-2031. The HBM for the AI GPU market is expanding because newer accelerator designs require much higher bandwidth and larger on-package memory pools than earlier generations, keeping HBM central to AI server design. The market also remained shaped by supply pressure in 2025 and 2026 because only SK hynix, Samsung Electronics, and Micron Technology supplied qualified HBM at scale, which supported premium pricing and kept volume growth below demand. Advanced packaging remains a practical limit because HBM revenue only materializes when memory stacks are integrated into deployable GPU systems, so packaging availability still influences shipment timing across the HBM for AI GPUs market. Another important shift is that demand now comes from both hyperscaler training clusters and a widening enterprise inference base, which reduces dependence on a single buyer group or a single accelerator cycle. Regulatory review of semiconductor exports and the deep supply link between Korean memory production, Taiwanese packaging, and North American AI data center deployment also keeps the HBM for the AI GPU market closely tied to policy and qualification cycles.
Key Report Takeaways
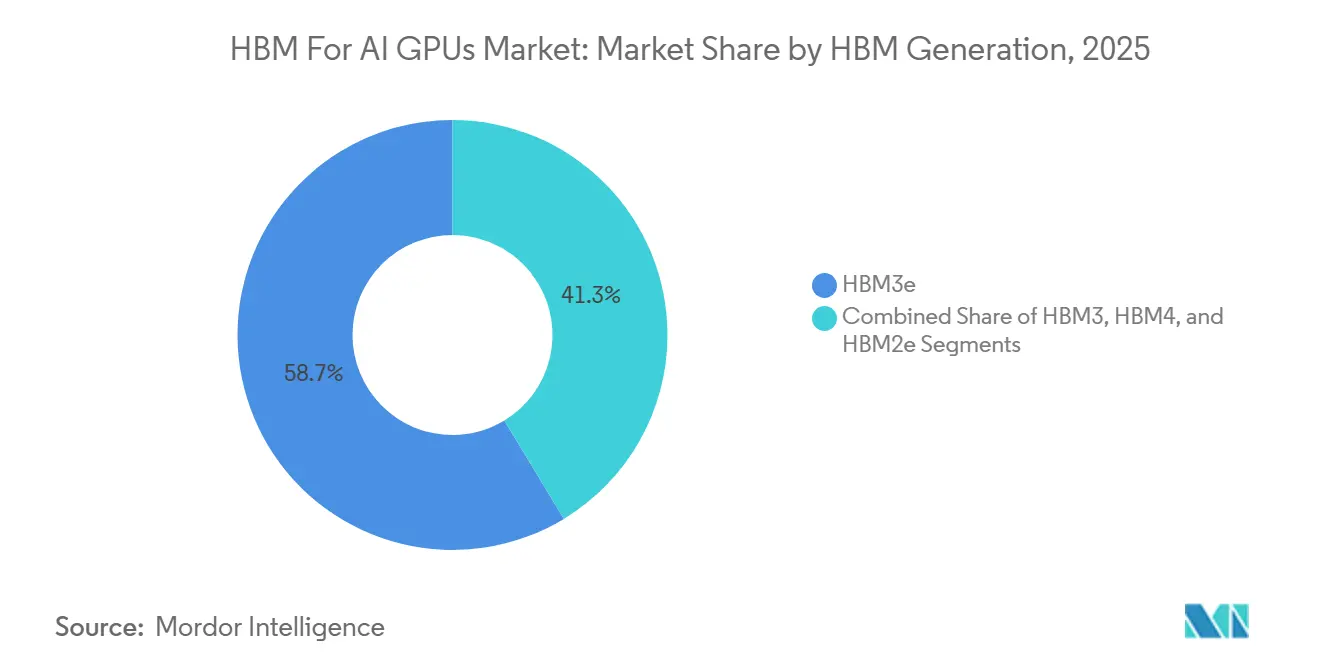
- By HBM generation, HBM3e led with a 58.67% revenue share in 2025, while HBM4 is projected to record the fastest growth at 30.50% through 2031 in the HBM for AI GPUs market.
- By memory capacity, the 64-128 GB tier held a 48.34% share in 2025, while the above 128 GB tier is forecast to expand at the fastest pace of 30.80% over 2026-2031 in the HBM for AI GPUs market.
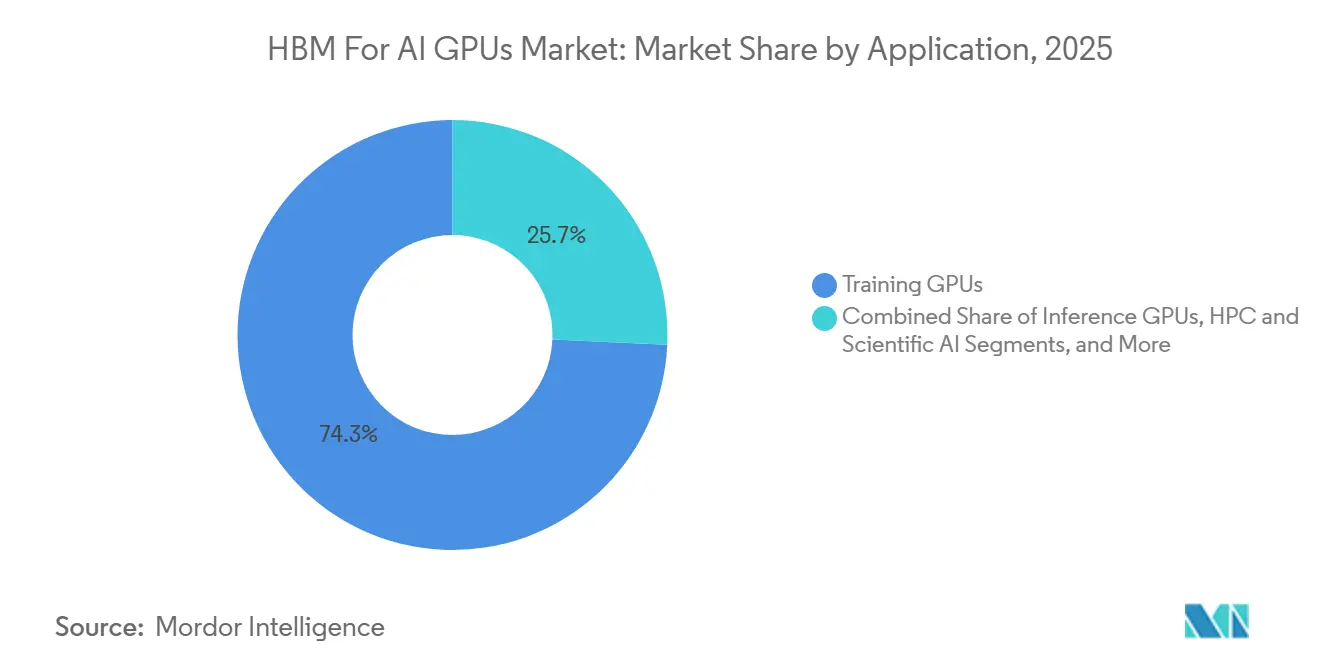
- By application, training GPUs accounted for a 74.28% revenue share in 2025, while inference GPUs are expected to grow by 31.30% through 2031 in the HBM for AI GPUs market.
- By end user, hyperscalers and cloud service providers commanded a 70.66% revenue share in 2025, while enterprise AI deployments are projected to grow at the fastest rate of 30.70% over 2026-2031 in the HBM for AI GPUs market.
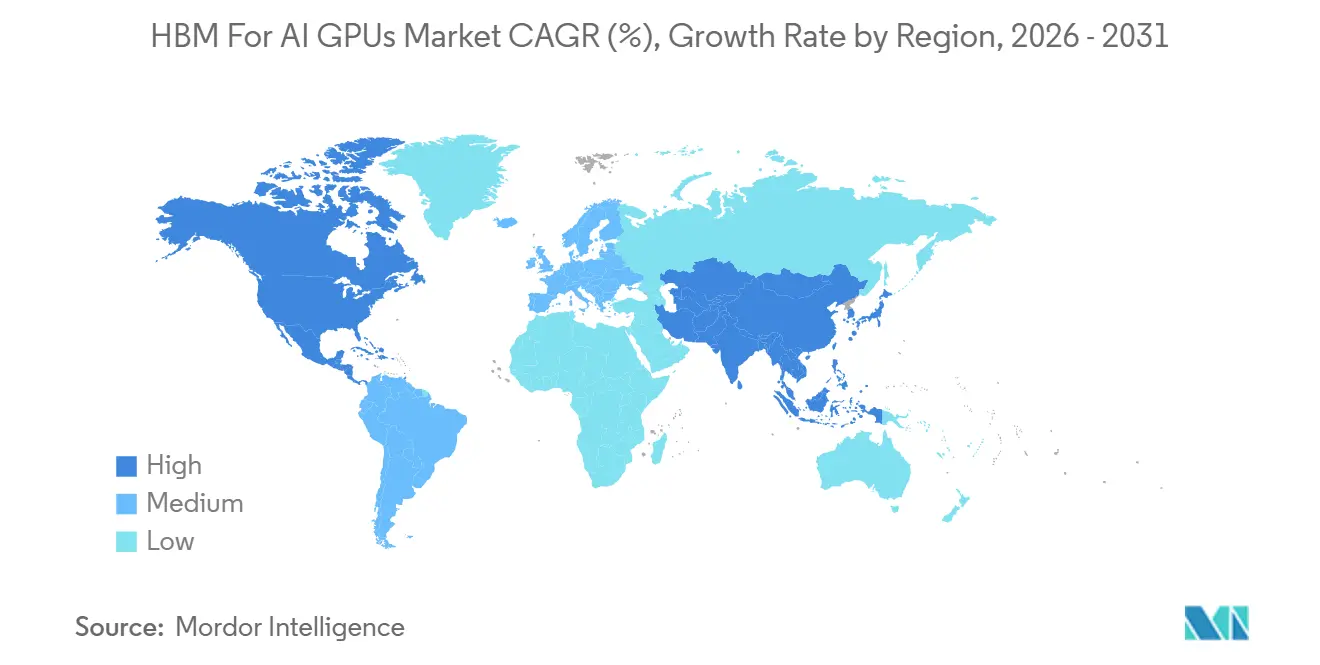
- By geography, North America held a 52.43% share of the HBM for AI GPUs market in 2025, while the Asia-Pacific is expected to register the fastest regional growth of 31.40% through 2031.
Note: Market size and forecast figures in this report are generated using Mordor Intelligence’s proprietary estimation framework, updated with the latest available data and insights as of January 2026.
Global HBM For AI GPUs Market Trends and Insights
Drivers Impact Analysis*
| Driver | (~) % Impact on CAGR Forecast | Geographic Relevance | Impact Timeline |
|---|---|---|---|
| AI GPU Memory Bandwidth Bottlenecks Raising HBM Attach Rates | +8.5% | Global | Medium term (2-4 years) |
| Rapid HBM3e Adoption in Next-Generation Training Clusters | +6.5% | North America, Asia Pacific | Short term (≤ 2 years) |
| Advanced Packaging Capacity Expansion Unlocking HBM Output | +5.0% | Global (TSMC anchor, OSAT spill-over to APAC) | Medium term (2-4 years) |
| HBM4 Roadmap Pulling Forward Qualification and Supply Agreements | +3.5% | North America, South Korea | Short term (≤ 2 years) |
| Hyperscaler Custom Accelerator Programs Increasing HBM Design Wins | +3.0% | North America, Asia Pacific core | Medium term (2-4 years) |
| Rising Multi-Die GPU Architectures Increasing Per-Accelerator Memory Content | +2.5% | Global | Long term (≥ 4 years) |
| Source: Mordor Intelligence | |||
AI GPU Memory Bandwidth Bottlenecks Raising HBM Attach Rates
The HBM for AI GPUs market is moving higher because modern large language model inference is often limited by memory movement rather than raw compute throughput. NVIDIA stated that the GB300 Blackwell Ultra integrates eight 12-high HBM3e stacks, delivering 288GB and 8TB/s per GPU, demonstrating how memory capacity is rising with each new accelerator generation.[1]NVIDIA Corporation, “NVIDIA H200 GPU,” NVIDIA, nvidia.com That design change matters because it is architectural rather than temporary, which means higher HBM content remains tied to each new product cycle, even if unit shipment patterns shift across HBM for the AI GPU market. Longer reasoning contexts also raise key-value cache requirements, so lower-capacity configurations become less suitable for production inference as model context windows expand. This makes bandwidth limits a durable revenue driver for suppliers, as HBM becomes a required design element rather than a premium option in the AI GPU market. The result is that the memory stack keeps gaining strategic weight in accelerator bill of materials as AI hardware moves toward higher-capacity and taller-stack configurations.
Rapid HBM3e Adoption In Next-Generation Training Clusters
HBM3e quickly moved into the lead because it offered a clear bandwidth advantage over HBM3 and became the standard on the most advanced training platforms. NVIDIA listed the H200 with 141GB of HBM3e and 4.8 TB/s of memory bandwidth, which helped define the new performance floor for large-scale training deployments. Google also described Ironwood TPU with 192GB of HBM3e and 7,300GB/s, while AWS presented Trainium3 with 144GB of HBM3e and 4.9TB/s, showing that hyperscaler custom silicon is reinforcing the same memory standard across competing platforms.[2]Amazon Web Services, “AI Accelerator, AWS Trainium,” AWS, aws.amazon.com This matters for the HBM for AI GPU market because HBM demand no longer depends solely on NVIDIA shipments and instead draws support from a broader set of accelerator programs. SK hynix said its FY2025 record results were driven by AI memory demand, underscoring how quickly training-cluster deployment translated into HBM revenue expansion. The wider implication is that HBM3e became the minimum practical specification for frontier AI infrastructure within a single cycle, accelerating supplier utilization and keeping HBM for the AI GPU market on a steep growth path.
Advanced Packaging Capacity Expansion Unlocking HBM Output
The HBM for AI GPUs market cannot convert demand into realized revenue unless HBM stacks are bonded with logic dies through advanced packaging flows. This is why CoWoS availability remains central: memory supply alone does not make an accelerator sellable until packaging capacity is secured. The input material shows that capacity expansion at TSMC and OSAT partners is expanding the packaging base, gradually improving shipment conversion, and giving the HBM for the AI GPU market more room to grow. It also shows that packaging slots remain booked well in advance, so the timing of capacity additions still determines how quickly existing memory supply can move into deployed systems. That constraint keeps packaging from being a background process, making it a direct growth lever for the HBM in the AI GPU market. As a result, every new packaging line or qualified outsourced route has an immediate impact on revenue realization, turning memory inventory into installable AI hardware.
HBM4 Roadmap Pulling Forward Qualification And Supply Agreements
The HBM4 transition is moving faster than earlier generation shifts because qualification and supply planning began well before broad commercial rollout. NVIDIA announced a multiyear technology partnership with SK hynix in June 2026 that spans Vera Rubin AI supercomputers, NVIDIA Vera CPUs, RTX Spark PCs, and Jetson Thor systems, indicating that memory relationships are becoming deeper and longer-lasting. The input also states that all 3 major suppliers qualified for the Vera Rubin platform in 2026, marking the first time simultaneous certification occurred for a single NVIDIA next-generation platform. That event matters because it compressed procurement timelines and pushed customers toward earlier multi-year planning inside the HBM for the AI GPU market. It also underscored the value of early engineering alignment, because suppliers that qualify sooner can secure greater visibility into future programs and a stronger role in platform design decisions. The net effect is that the HBM4 roadmap is not just a product shift, and it is also a commercial shift toward tighter co-development, earlier allocation planning, and more structured supply agreements across the HBM for AI GPUs market.
Restraints Impact Analysis*
| Restraint | (~) % Impact on CAGR Forecast | Geographic Relevance | Impact Timeline |
|---|---|---|---|
| High Cost of HBM Stacks and Interposer Integration | -2.0% | Global | Medium term (2-4 years) |
| Limited CoWoS and Other Advanced-Packaging Capacity | -1.5% | Global (TSMC anchor) | Short term (≤ 2 years) |
| Export Controls and Customer Concentration Risk in AI GPUs | -1.0% | North America, Asia | Medium term (2-4 years) |
| Yield Losses in High-Stack DRAM Assembly | -0.8% | South Korea, Taiwan | Short term (≤ 2 years) |
| Source: Mordor Intelligence | |||
High Cost Of HBM Stacks And Interposer Integration
The HBM for the AI GPU market still faces a meaningful brake from the cost of stacked memory and the advanced packaging needed to make it usable in top-end accelerators. The input material makes clear that HBM remains far more expensive than conventional DRAM, and that the cost rises further when several stacks and complex interposer packaging are added to a single chip. This has an uneven effect across the HBM for AI GPUs market because hyperscalers can absorb higher procurement costs more easily than smaller enterprises, academic buyers, and public-sector programs with fixed budgets. The pressure also flows through the supply chain, as higher memory and packaging costs affect accelerator pricing before systems reach end users. That slows adoption outside the highest-value workloads, even when technical demand is clear, and performance gains are strong. Until cost curves improve, the HBM for AI GPUs market will remain most accessible to buyers who can justify premium systems through large-scale training or production inference economics.
Limited CoWoS And Other Advanced-Packaging Capacity
Limited packaging capacity remains a direct restraint because HBM cannot ship revenue until it is assembled into a qualified AI accelerator. The input shows that demand for CoWoS continued to outpace near-term availability in 2025 and 2026, indicating that memory supply and final accelerator output do not always rise at the same pace. This matters for the HBM in the AI GPU market because a shortage at the packaging stage can delay deployment even when the DRAM wafer starts, stack production is already underway, and customer demand is in place. It also means capacity allocations are often decided well in advance, reducing flexibility for late buyers and keeping lead times elevated. Export compliance adds another layer because advanced-packaged modules may fall under stricter controls in restricted destinations, lengthening planning for affected shipments.[3]Bureau of Industry and Security, “Guidance Regarding Enforcement of License Requirements for Advanced Computing Items,” U.S. Department of Commerce, bis.gov As long as packaging remains the main conversion bottleneck, the HBM for the AI GPU market will continue to grow below its full demand ceiling in the near term.
*Our forecasts treat driver/restraint impacts as directional, not additive. The impact forecasts reflect baseline growth, mix effects, and variable interactions.
Segment Analysis
By HBM Generation: HBM3e Anchors Revenue While HBM4 Reshapes The Next Supply Cycle
HBM3e accounted for 58.67% of revenue in 2025, making it the largest generation in the HBM for the AI GPU market during the current platform cycle. Its lead came from broad deployment across the NVIDIA H200, Blackwell B200, and Google Ironwood TPU, all of which set a higher memory threshold for competitive AI hardware. HBM3 still retained residual demand through ongoing H100 production, while HBM2e remained tied to older HPC and cost-sensitive scientific computing workloads that no longer define the center of the HBM for AI GPUs industry. The structure of this segment is also shaped by qualification rules because JEDEC interoperability standards create a lag between engineering samples and meaningful volume revenue. That lag brings more predictability to generational handovers than in many other semiconductor categories because customers commit earlier and suppliers need a longer validation window. Within that pattern, HBM3e benefited from being the first broadly available generation that aligned with the memory needs of both large training clusters and more demanding inference systems. It therefore served as both the revenue anchor of 2025 and the bridge between legacy HBM3 deployments and the first HBM4 commercial ramps. The result is that HBM3e did not simply replace HBM3, and instead reset the baseline specification across the HBM for AI GPU market.
HBM4 is projected to be the fastest-growing generation through 2031, and that makes it the most important forward driver inside this segment. The input states that HBM4 entered the revenue mix in 2026 with volume shipments tied to NVIDIA Vera Rubin, after all 3 major suppliers qualified for the platform in the same year. SK hynix also said it shipped 12-layer HBM4E samples in June 2026 ahead of its earlier timeline, while Samsung supplied HBM4E samples in late May 2026, which shows how quickly development cycles are compressing. That speed matters because the HBM for AI GPUs market size for next-generation memory is being shaped by shorter recovery windows for each generation's qualification costs and by faster migration toward premium products. The segment also reflects a pricing pattern in which newer memory generations hold elevated average selling prices before cost learning spreads through manufacturing. HBM4 therefore carries both volume growth and mix improvement potential for suppliers that qualify early and scale efficiently. This keeps the HBM for AI GPU market centered on a rapid generational ladder, where leadership depends on qualification timing as much as on raw manufacturing capacity. It also means customers are increasingly planning procurement around future roadmaps instead of only current deployment cycles.



By Memory Capacity: High-Capacity Configurations Become The New Competitive Center
The 64-128 GB tier held a 48.34% revenue share in 2025, which placed it at the center of the HBM for the AI GPU market size during the base year. That position was supported by systems such as the H200 at 141GB and by platforms close to the boundary of the next capacity band, which kept this range commercially broad. The up to 32 GB segment continued to lose importance as older HBM2e designs gave way to denser successors, while the 32-64 GB range remained relevant for mid-tier inference and edge HPC use cases that did not yet require top-end memory pools. The main force in this segment is that model hosting and training requirements are steadily pushing buyers toward larger configurations. In practical terms, higher memory capacity is no longer just a premium feature; it is becoming a baseline requirement for strong performance on larger models. That shift has already influenced replacement cycles, as cloud operators have used H200 upgrades to improve inference latency and capacity compared with H100-based nodes. It also changed the demand profile in the HBM for AI GPUs market, as memory capacity now tracks directly with the commercial usefulness of deployed compute. For that reason, capacity segmentation increasingly mirrors workload complexity instead of price brackets alone.
The above 128 GB band is expected to record the fastest growth through 2031 and is becoming the most strategic capacity tier in the HBM for AI GPUs market. NVIDIA described the GB300 Blackwell Ultra with 288GB per GPU, while Google presented TPU 8t around the same 288GB class, confirming that major vendors are converging on the same high-capacity bracket. NVIDIA also highlighted GB300 NVL72 with 37TB of total HBM3e across 72 GPUs, which shows how rack-scale design is now built around very large aggregate memory pools. This matters because the HBM for AI GPUs market share is shifting toward denser configurations that carry higher per-system memory content and stronger pricing power. The move to 12-high stacks also supports that mix shift because these builds are more complex and keep value concentrated in higher-capacity hardware. Revenue therefore grows faster than unit volume when demand migrates toward the top of the capacity ladder. This reinforces the premium end of the HBM for AI GPU market and raises the importance of suppliers that can maintain yields on taller stacks. It also supports a longer runway for premium pricing as the installed base moves toward memory-heavy inference and training systems.
By Application: Training Still Leads Revenue While Inference Expands The Addressable Base
Training GPUs accounted for 74.28% of revenue in 2025, making them the largest application group in the HBM for AI GPUs market. Their lead reflected the heavy and sustained compute demand of the frontier model pre-training, where memory bandwidth strongly affects utilization and total training efficiency. HBM remains especially important in this segment because training workloads run for long periods at high intensity and reward any reduction in memory bottlenecks. HPC and scientific AI also maintained a stable role through supercomputing programs where similar bandwidth requirements apply, while edge AI remained small because HBM costs and power demands remain difficult to justify outside central data center environments. This application mix shows that the HBM for the AI GPU industry still depends heavily on centralized, capital-intensive infrastructure rather than broad low-cost deployment. It also explains why training clusters generated stable and visible order patterns for suppliers in 2025. The segment, therefore, anchored the HBM for the AI GPU market even as other application types began to gain traction. In revenue terms, training remained the clearest expression of why HBM has become a necessary memory architecture for top-tier AI systems.
Inference GPUs are projected to be the fastest-growing application segment through 2031, and this changes the demand profile of the HBM for AI GPU market in an important way. Broadcom reported in its Private Cloud Outlook 2026 that 56% of enterprises run or plan production AI inference on private cloud, compared with 41% on public cloud, suggesting a broader hardware buying base beyond hyperscalers. Google also introduced TPU 8i as an inference-oriented design with 288GB of HBM and 8,601GB/s per chip, which shows that inference silicon is moving toward memory specifications once associated mainly with training hardware. This means the historical gap in memory content between training and inference is narrowing inside the HBM for AI GPUs market. Longer-context reasoning and production deployment at scale are both pushing inference toward training-like bandwidth intensity. As that happens, HBM demand spreads across a larger set of operational use cases and procurement models. The segment therefore broadens the addressable market rather than simply redistributing demand among existing buyers. It also adds a more durable revenue stream, as production inference systems tend to grow with usage rather than end after a single model training cycle.
By End User: Hyperscaler Spending Dominates Today While Enterprise Adoption Deepens Future Demand
Hyperscalers and cloud service providers commanded a 68-73% revenue share in 2025, which made them the clear revenue anchor of the HBM for AI GPUs market. Their spending reflected the scale of AI infrastructure programs at Amazon, Microsoft, Alphabet, and Meta, where large GPU clusters remain essential for both model training and production services. Research and supercomputing centers also held a steady position because national compute programs continue to favor memory-rich accelerator systems for science and AI workloads. Government and defense buyers stayed smaller in share, but they represent a stable part of demand because procurement priorities often extend across cycles and align with domestic compute objectives. This end-user structure shows why the HBM for AI GPU market was initially shaped by a small number of very large buyers with clear technical needs and long planning horizons. It also explains why supplier qualification and allocation mattered so much, because winning a few hyperscaler programs could materially shift revenue mix. In the current phase, hyperscaler demand still provides the strongest base load for shipments and pricing across the HBM for AI GPU market. That concentration gives suppliers visibility, but it also keeps the market sensitive to platform and budget timing at a narrow set of accounts.
Enterprise AI deployments are expected to be the fastest-growing end-user segment through 2031, which gradually broadens the commercial base of the HBM for AI GPU market. Broadcom cited Deloitte data showing a 50% year-on-year increase in worker access to AI tools in 2025, which signals that enterprise use is moving from pilot activity toward production infrastructure. The same Broadcom survey also pointed to a stronger shift toward private-cloud inference, which supports direct procurement of HBM-equipped systems by enterprises rather than exclusive dependence on public-cloud capacity. This is important because it adds demand from buyers that are smaller than hyperscalers but much more numerous. As enterprise inference grows, the HBM for AI GPUs market becomes less exposed to a single capex cycle and gains a wider installed base across industries. That does not remove the importance of hyperscalers, but it does make demand more balanced over time. The segment also suggests that memory-rich infrastructure is becoming relevant to mainstream business deployment instead of remaining limited to frontier AI labs. In that sense, enterprise growth broadens both the demand foundation and the long-run resilience of the HBM for AI GPU market.
Geography Analysis
North America accounted for 52.43% of the HBM for AI GPUs market in 2025, making it the largest regional contributor by revenue. The region benefits from the concentration of the largest hyperscalers, the leading AI GPU designer, and many of the most advanced model developers in the United States. That combination creates a tight link between hardware design, cloud deployment, and end demand, which keeps the regional base strong across the HBM-based AI GPU market. U.S. export policy also shaped regional demand patterns in 2026, as BIS confirmed that license requirements for advanced computing items extend to entities headquartered in Country Group D:5, even when they are outside China. This narrowed the pool of accessible customers for the most advanced systems and pushed more compliant shipment opportunities toward domestic and allied-country demand. NVIDIA also stated that Microsoft, Oracle Cloud Infrastructure, and CoreWeave are deploying GB300 NVL72 systems, which support near-term shipment visibility tied to Blackwell Ultra platforms. The region, therefore, remains central not only because it buys large volumes, but also because it shapes the timing of platform adoption across the rest of the HBM for the AI GPU market.
Asia Pacific is projected to be the fastest-growing region over 2026-2031, driven by a mix of supply leadership and rising regional compute investment. The region already sits close to the production core of the HBM for the AI GPUs market because South Korea remains the main HBM manufacturing base, and Taiwan remains essential in advanced packaging flows. That supply position matters because regional companies influence qualification pace, allocation decisions, and generational ramp timing across the whole market. At the same time, the input shows growing sovereign and hyperscaler-backed AI infrastructure activity across South Korea, Japan, and India, which adds local demand on top of export-oriented supply. This combination makes Asia Pacific different from North America because it participates heavily on both sides of the HBM for AI GPUs market, as a manufacturing anchor and as a rising deployment destination. It also means that regional policy, capital spending, and technology roadmaps can simultaneously affect both volume availability and end-market absorption. For that reason, Asia Pacific's growth profile is broader than a simple catch-up story and reflects its role as a core operating base for the global HBM chain.
Europe held a meaningful but smaller share in 2025, with Germany, the United Kingdom, and France serving as the main regional centers for AI infrastructure deployment in the input material. The region moved more slowly because procurement cycles are longer and compliance priorities have often preceded large hardware ramps, which kept growth below North America and Asia Pacific in the HBM for AI GPUs market. South America, the Middle East, and Africa remained early-stage contributors, though sovereign compute programs in the Middle East suggest these markets could gain greater weight later in the forecast period. The geographic mix, therefore, remains uneven, with the HBM for the AI GPU market size still concentrated in regions that combine high-end compute demand, platform access, and strong links to the semiconductor supply chain.

Competitive Landscape
The competitive landscape of the HBM for AI GPUs market remains extremely concentrated, as only SK Hynix, Samsung Electronics, and Micron Technology are qualified HBM suppliers at a global scale. SK hynix led with a high revenue share in Q1 2026, while Samsung Electronics and Micron Technology each accounted for a significant market share, indicating that competition is narrowing but remains highly concentrated among 3 vendors. Entry barriers remain high because the process requires complex TSV integration, advanced bonding methods, lengthy yield-learning cycles, and substantial capital expenditures for packaging and stack assembly. This structure keeps the HBM for the AI GPU market closer to a tightly controlled supplier field than to a broad semiconductor category with frequent new entrants. It also means that qualification success carries more weight than simple nameplate capacity, because revenue only follows once a supplier is approved for a leading AI platform. As a result, competitive position depends on yields, technology timing, and the ability to scale alongside customer roadmaps. The market remains concentrated, but the share gap is no longer static and is now shaped by HBM3e execution and early HBM4 readiness.
Several strategic moves in 2026 show how competition is evolving inside the HBM for AI GPU market. NVIDIA and SK hynix announced a multiyear technology partnership in June 2026, which deepened supplier alignment across future AI systems and extended the relationship beyond a standard memory purchase arrangement.[4]NVIDIA Corporation, “NVIDIA and SK hynix Announce Multiyear Technology Partnership to Advance Memory for AI Factories,” NVIDIA Newsroom, nvidianews.nvidia.com SK hynix also shipped 12-layer HBM4E samples ahead of its earlier schedule, which signaled aggressive roadmap execution as suppliers compete for next-wave platform share. The input also notes that all 3 major suppliers qualified for NVIDIA's Vera Rubin generation in 2026, which shifts competition toward allocation, customization depth, and yield leadership rather than simple qualification access. That is a meaningful change because simultaneous qualification reduces the protection that an early sole-source position once offered. It also gives major customers more room to balance supply, manage risk, and negotiate across vendors. In turn, the HBM for AI GPU market becomes more competitive inside a still-concentrated supplier group.
The wider ecosystem around the HBM for AI GPUs market is also becoming more important because packaging, testing, and downstream qualification increasingly influence who can capture demand at scale. Even when a memory supplier has strong technology, final platform access still depends on successful integration into advanced packaging flows and customer-specific validation chains. That gives process reliability and ecosystem fit a larger role in competition than in conventional DRAM categories. Samsung's continuing investment in stack technology and warpage reduction, along with Micron's effort to close the gap through HBM3e and HBM4 progress described in the input, shows that all 3 suppliers are trying to improve their position on the same future ramps. The commercial contest is therefore not about whether the HBM for AI GPUs market will stay concentrated, and it is about how the existing 3 participants divide a rapidly growing revenue pool. This supports a landscape where supplier concentration remains high, but share movement is still possible at each generational shift. It also means customer relationships are becoming deeper, longer, and more technical with every new platform cycle.
HBM For AI GPUs Industry Leaders
SK hynix Inc.
Samsung Electronics Co., Ltd.
Micron Technology, Inc.
- *Disclaimer: Major Players sorted in no particular order

Recent Industry Developments
- June 2026: SK hynix shipped 12-layer HBM4E samples to major customers ahead of its originally guided second-half timeline, delivering a 48 GB configuration at 16 Gbps per pin with over 20% improved power efficiency versus HBM4. Samsung had supplied HBM4E samples in late May 2026, compressing the generational development competition between the 2 suppliers to a matter of weeks.
- June 2026: NVIDIA and SK hynix announced a multiyear technology partnership for next-generation memory aligned to NVIDIA's AI infrastructure roadmap, spanning Vera Rubin AI supercomputers, NVIDIA Vera CPUs, RTX Spark PCs, and Jetson Thor robotic platforms, and extending to the development of fab digital twins using NVIDIA Omniverse for autonomous semiconductor manufacturing.
- May 2026: BIS issued guidance confirming that U.S. license requirements for advanced computing items extend to entities headquartered in Country Group D:5 or Macau, even when located outside China, clarifying enforcement scope with immediate compliance implications for AI GPU and HBM supply chain operators.
- February 2026: SK hynix's board approved KRW 21.61 trillion (USD 16.0 billion) to construct Phases 2 through 6 of its Yongin semiconductor cluster, targeting completion by December 2030 and representing approximately 29.23% of the company's equity capital.
- January 2026: SK hynix reported FY2025 revenue of KRW 97.1467 trillion (USD 70.4 billion) and operating profit of KRW 47.2063 trillion (USD 34.2 billion), surpassing Samsung's FY2025 operating profit of KRW 43.6011 trillion (USD 31.6 billion) for the first time, with HBM margin premiums cited as the primary differentiator.


Global HBM For AI GPUs Market Report Scope
The HBM for AI GPUs Market Report is Segmented by Generation (HBM2e, HBM3, HBM3e, and HBM4), Memory Capacity (Up to 32 GB, 32-64 GB, 64-128 GB, and Above 128 GB), Application (Training GPUs, Inference GPUs, HPC and Scientific AI, and Edge AI), End User (Hyperscalers, Enterprise AI, Research and Supercomputing, and Government and Defense), and Geography (North America, Europe, Asia-Pacific, South America, and Middle East and Africa). The Market Forecasts are Provided in Terms of Value (USD).
| HBM2e |
| HBM3 |
| HBM3e |
| HBM4 |
| Up to 32 GB |
| 32-64 GB |
| 64-128 GB |
| Above 128 GB |
| Training GPUs |
| Inference GPUs |
| HPC and Scientific AI |
| Edge AI |
| Hyperscalers and Cloud Service Providers |
| Enterprise AI Deployments |
| Research and Supercomputing Centers |
| Government and Defense |
| North America | United States |
| Canada | |
| Mexico | |
| Europe | Germany |
| United Kingdom | |
| France | |
| Italy | |
| Rest of Europe | |
| Asia-Pacific | China |
| Japan | |
| South Korea | |
| India | |
| Southeast Asia | |
| Rest of Asia-Pacific | |
| South America | |
| Middle East and Africa |
| By HBM Generation | HBM2e | |
| HBM3 | ||
| HBM3e | ||
| HBM4 | ||
| By Memory Capacity | Up to 32 GB | |
| 32-64 GB | ||
| 64-128 GB | ||
| Above 128 GB | ||
| By Application | Training GPUs | |
| Inference GPUs | ||
| HPC and Scientific AI | ||
| Edge AI | ||
| By End User | Hyperscalers and Cloud Service Providers | |
| Enterprise AI Deployments | ||
| Research and Supercomputing Centers | ||
| Government and Defense | ||
| Geography | North America | United States |
| Canada | ||
| Mexico | ||
| Europe | Germany | |
| United Kingdom | ||
| France | ||
| Italy | ||
| Rest of Europe | ||
| Asia-Pacific | China | |
| Japan | ||
| South Korea | ||
| India | ||
| Southeast Asia | ||
| Rest of Asia-Pacific | ||
| South America | ||
| Middle East and Africa | ||


Key Questions Answered in the Report
What is the projected value of the HBM for AI GPUs market by 2031?
The HBM for AI GPUs market is projected to reach USD 46.82 billion by 2031, rising from USD 12.56 billion in 2026 at a 30.10% CAGR over 2026-2031.
Which HBM generation leads current revenue and which one is growing fastest?
HBM3e led revenue with a 58.67% share in 2025, while HBM4 is expected to record the fastest growth through 2031.
Why is high-bandwidth memory becoming essential for AI accelerators?
Newer training and inference systems need much more memory bandwidth and larger on-package capacity, which makes HBM central to products such as H200, GB300, and advanced TPU platforms.
Which application contributes the most today and which one has the strongest growth outlook?
Training GPUs accounted for 74.28% of revenue in 2025, while inference GPUs are expected to expand the fastest as private-cloud and enterprise deployment rises.
Which region currently leads global demand?
North America held a half of the market share in 2025 because it combines the largest hyperscalers, leading AI platform design, and large-scale deployment of advanced GPU systems.
What is the main supply-side risk for future growth?
The main risk is not weak demand, but the combination of high HBM cost, advanced-packaging constraints, and export-control friction that can delay conversion of memory supply into shipped AI systems.
Page last updated on:






